 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Regularization-Agnostic Compressed Sensing MRI Reconstruction with Hypernetworks
Jan 06, 2021
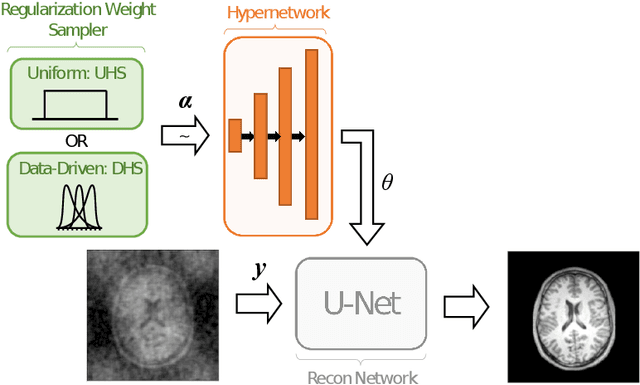


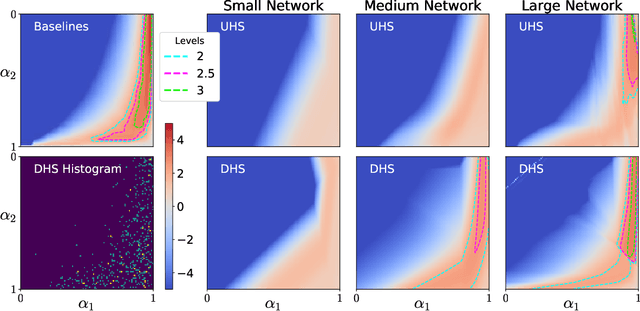
Reconstructing under-sampled k-space measurements in Compressed Sensing MRI (CS-MRI) is classically solved with regularized least-squares. Recently, deep learning has been used to amortize this optimization by training reconstruction networks on a dataset of under-sampled measurements. Here, a crucial design choice is the regularization function(s) and corresponding weight(s). In this paper, we explore a novel strategy of using a hypernetwork to generate the parameters of a separate reconstruction network as a function of the regularization weight(s), resulting in a regularization-agnostic reconstruction model. At test time, for a given under-sampled image, our model can rapidly compute reconstructions with different amounts of regularization. We analyze the variability of these reconstructions, especially in situations when the overall quality is similar. Finally, we propose and empirically demonstrate an efficient and data-driven way of maximizing reconstruction performance given limited hypernetwork capacity. Our code is publicly available at https://github.com/alanqrwang/RegAgnosticCSMRI.
Accelerating COVID-19 research with graph mining and transformer-based learning
Feb 10, 2021In 2020, the White House released the, "Call to Action to the Tech Community on New Machine Readable COVID-19 Dataset," wherein artificial intelligence experts are asked to collect data and develop text mining techniques that can help the science community answer high-priority scientific questions related to COVID-19. The Allen Institute for AI and collaborators announced the availability of a rapidly growing open dataset of publications, the COVID-19 Open Research Dataset (CORD-19). As the pace of research accelerates, biomedical scientists struggle to stay current. To expedite their investigations, scientists leverage hypothesis generation systems, which can automatically inspect published papers to discover novel implicit connections. We present an automated general purpose hypothesis generation systems AGATHA-C and AGATHA-GP for COVID-19 research. The systems are based on graph-mining and the transformer model. The systems are massively validated using retrospective information rediscovery and proactive analysis involving human-in-the-loop expert analysis. Both systems achieve high-quality predictions across domains (in some domains up to 0.97% ROC AUC) in fast computational time and are released to the broad scientific community to accelerate biomedical research. In addition, by performing the domain expert curated study, we show that the systems are able to discover on-going research findings such as the relationship between COVID-19 and oxytocin hormone.
Classification of Complex Systems Based on Transients
Aug 31, 2020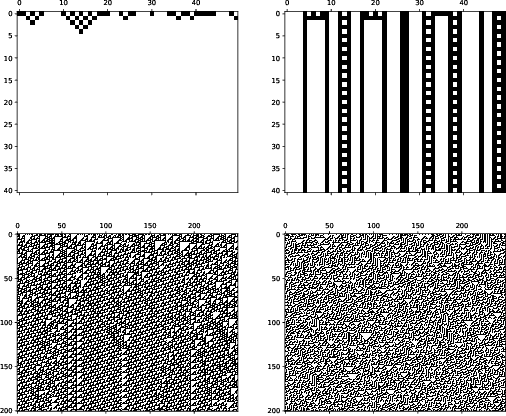
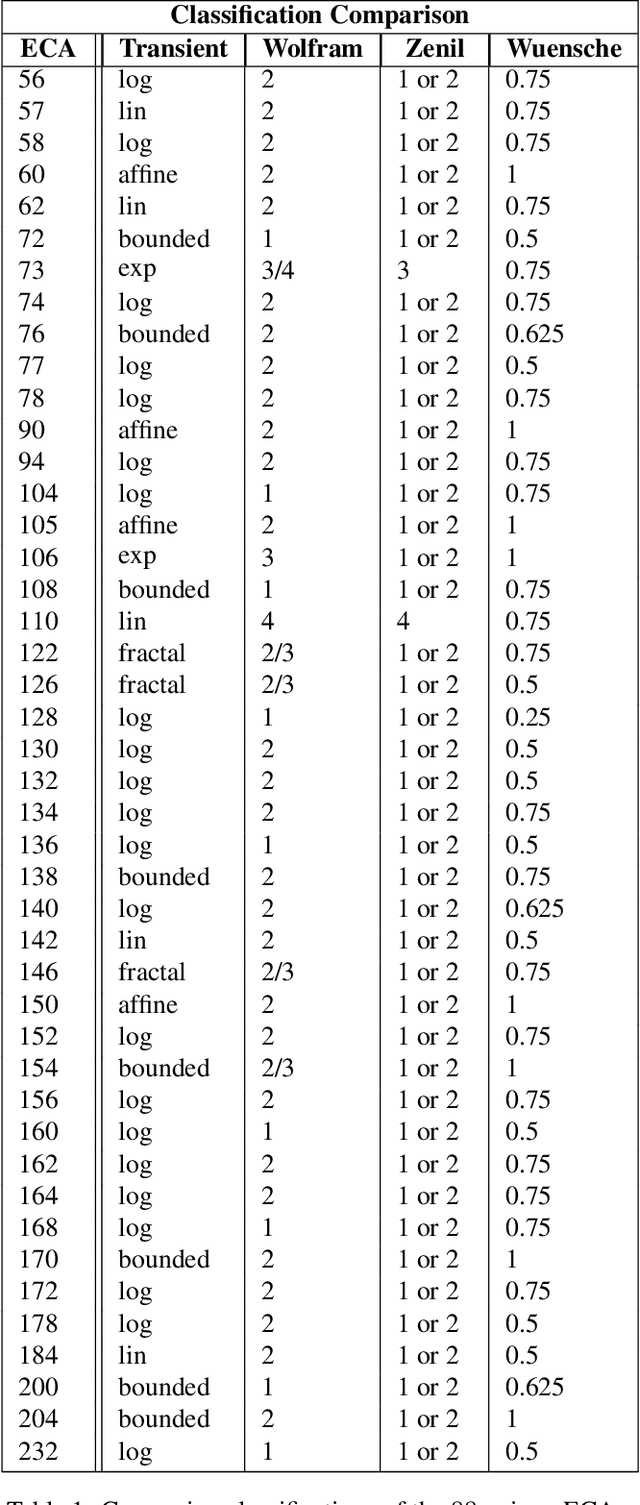
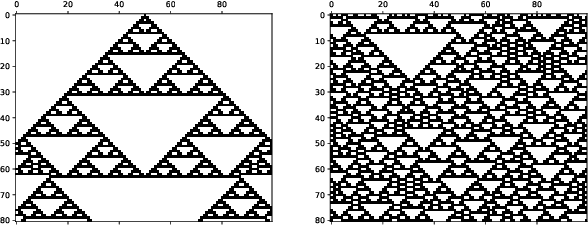
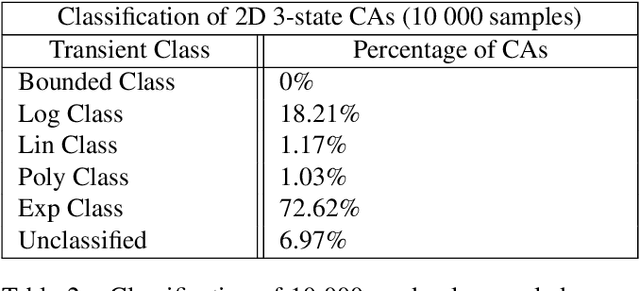
In order to develop systems capable of modeling artificial life, we need to identify, which systems can produce complex behavior. We present a novel classification method applicable to any class of deterministic discrete space and time dynamical systems. The method distinguishes between different asymptotic behaviors of a system's average computation time before entering a loop. When applied to elementary cellular automata, we obtain classification results, which correlate very well with Wolfram's manual classification. Further, we use it to classify 2D cellular automata to show that our technique can easily be applied to more complex models of computation. We believe this classification method can help to develop systems, in which complex structures emerge.
* 9 pages
Highly comparative feature-based time-series classification
May 09, 2014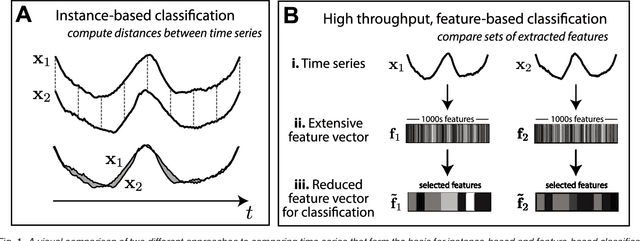
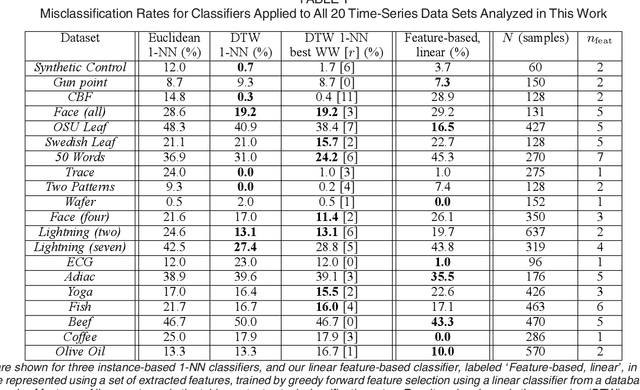
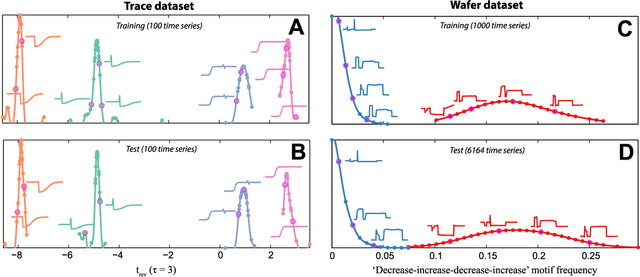
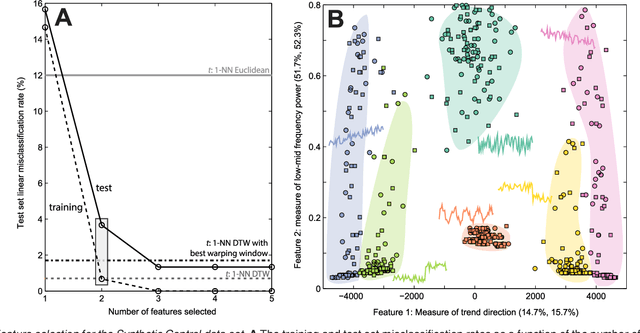
A highly comparative, feature-based approach to time series classification is introduced that uses an extensive database of algorithms to extract thousands of interpretable features from time series. These features are derived from across the scientific time-series analysis literature, and include summaries of time series in terms of their correlation structure, distribution, entropy, stationarity, scaling properties, and fits to a range of time-series models. After computing thousands of features for each time series in a training set, those that are most informative of the class structure are selected using greedy forward feature selection with a linear classifier. The resulting feature-based classifiers automatically learn the differences between classes using a reduced number of time-series properties, and circumvent the need to calculate distances between time series. Representing time series in this way results in orders of magnitude of dimensionality reduction, allowing the method to perform well on very large datasets containing long time series or time series of different lengths. For many of the datasets studied, classification performance exceeded that of conventional instance-based classifiers, including one nearest neighbor classifiers using Euclidean distances and dynamic time warping and, most importantly, the features selected provide an understanding of the properties of the dataset, insight that can guide further scientific investigation.
Vehicle predictive trajectory patterns from isochronous data
Oct 10, 2020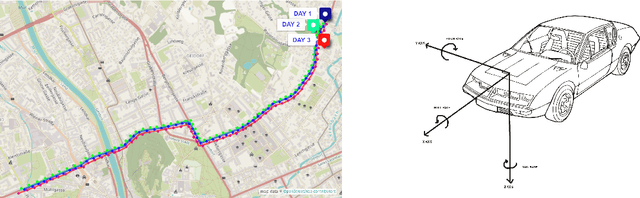
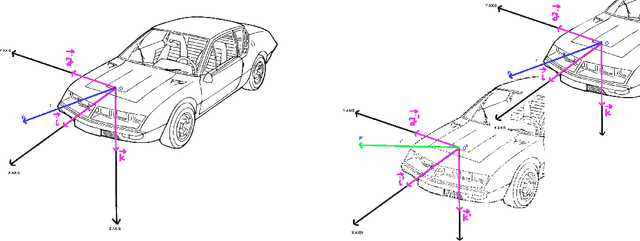
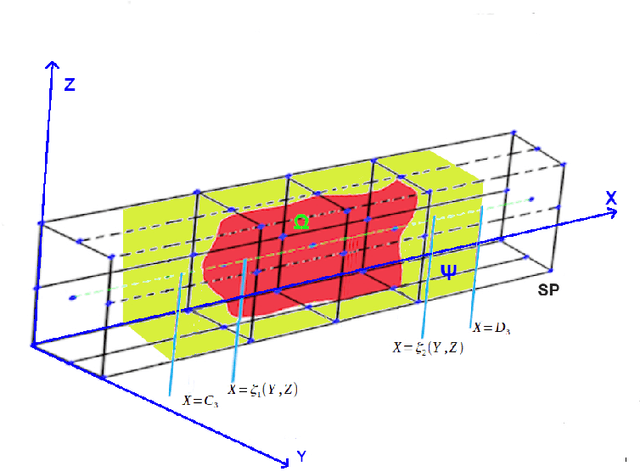
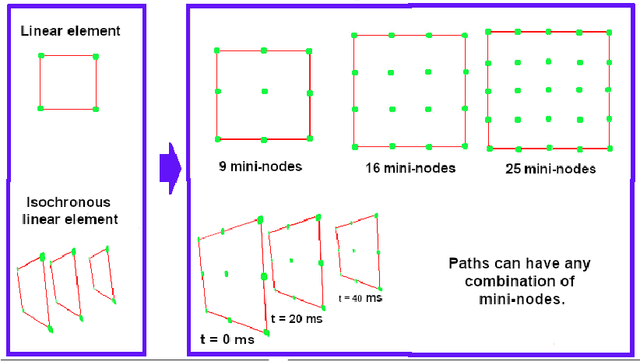
Measuring and analysing sensor data is the basic technique in vehicle dynamics development and with the advancement of embedded and data acquisition systems it is possible to analyze large data sets. In this paper a detailed method is presented for assessing and mapping isochronous trajectory patterns in Graz (Austria) by using data fusion from video, ArduinoUno and the compass sensor HDMM01. The predictive isochronous trajectory patterns are derived from the data values for a pre-defined time horizon. Both extreme driving behaviour and hazardous road geometries can be identified. It is possible to provide instant road sensor data which can be used to compare the data from a trajectory path as well as for different time instances. Results of this study show that the trajectory patterns are successful in predicting the likely evolution of a current trajectory pattern and can provide assessment on future driving situations. The obtained data from this study can be useful as reference in future city planning for energy saving driving pathways as well as vehicle design and engineering improvements based on quantitative and relevant dynamic measurements.
4D Visualization of Dynamic Events from Unconstrained Multi-View Videos
May 27, 2020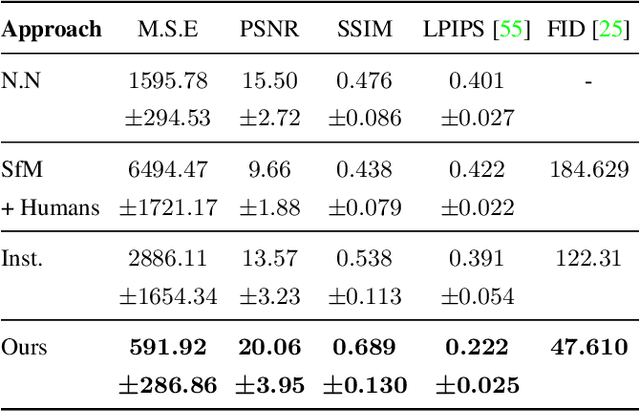



We present a data-driven approach for 4D space-time visualization of dynamic events from videos captured by hand-held multiple cameras. Key to our approach is the use of self-supervised neural networks specific to the scene to compose static and dynamic aspects of an event. Though captured from discrete viewpoints, this model enables us to move around the space-time of the event continuously. This model allows us to create virtual cameras that facilitate: (1) freezing the time and exploring views; (2) freezing a view and moving through time; and (3) simultaneously changing both time and view. We can also edit the videos and reveal occluded objects for a given view if it is visible in any of the other views. We validate our approach on challenging in-the-wild events captured using up to 15 mobile cameras.
Cascaded Continuous Regression for Real-time Incremental Face Tracking
Aug 06, 2016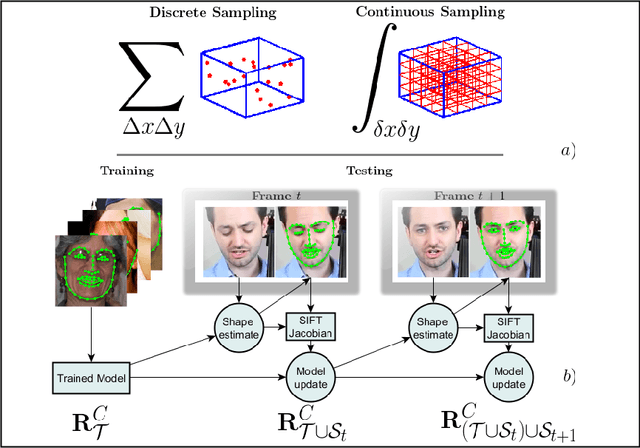
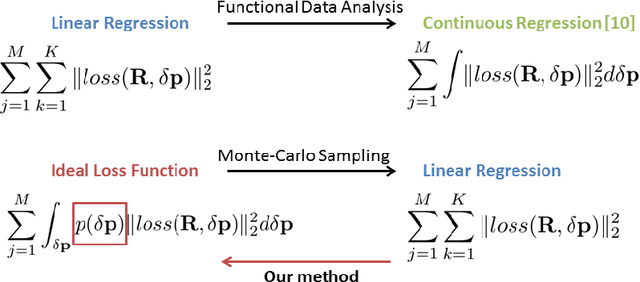
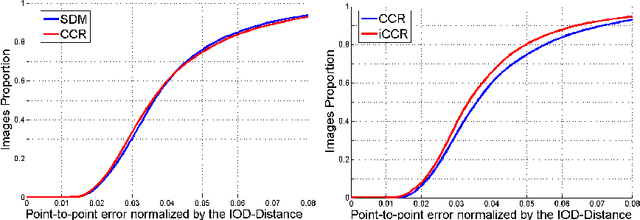
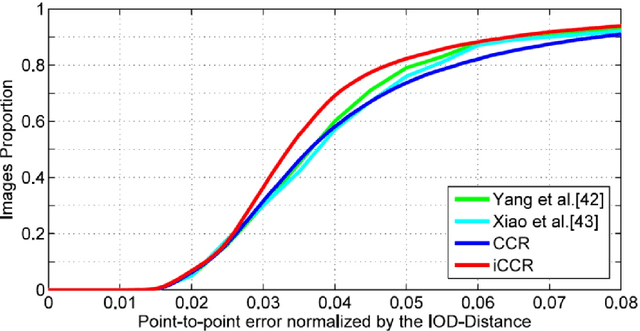
This paper introduces a novel real-time algorithm for facial landmark tracking. Compared to detection, tracking has both additional challenges and opportunities. Arguably the most important aspect in this domain is updating a tracker's models as tracking progresses, also known as incremental (face) tracking. While this should result in more accurate localisation, how to do this online and in real time without causing a tracker to drift is still an important open research question. We address this question in the cascaded regression framework, the state-of-the-art approach for facial landmark localisation. Because incremental learning for cascaded regression is costly, we propose a much more efficient yet equally accurate alternative using continuous regression. More specifically, we first propose cascaded continuous regression (CCR) and show its accuracy is equivalent to the Supervised Descent Method. We then derive the incremental learning updates for CCR (iCCR) and show that it is an order of magnitude faster than standard incremental learning for cascaded regression, bringing the time required for the update from seconds down to a fraction of a second, thus enabling real-time tracking. Finally, we evaluate iCCR and show the importance of incremental learning in achieving state-of-the-art performance. Code for our iCCR is available from http://www.cs.nott.ac.uk/~psxes1
Conditional GAN for timeseries generation
Jun 30, 2020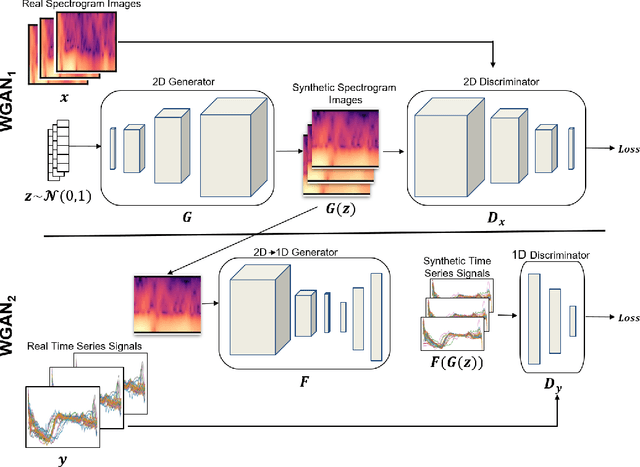
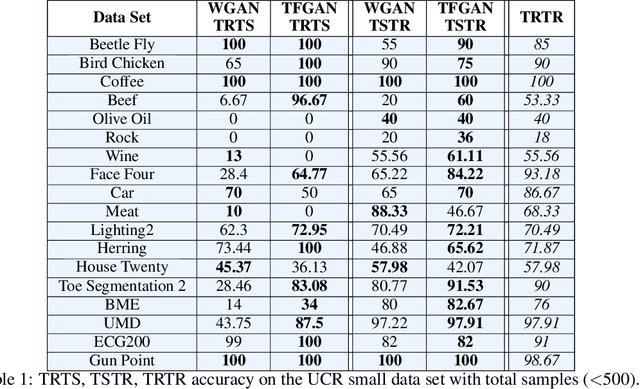
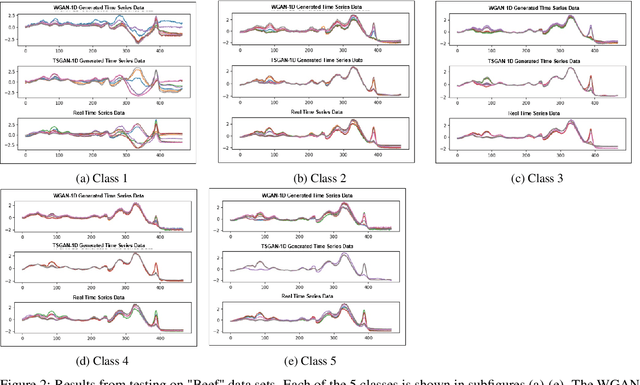
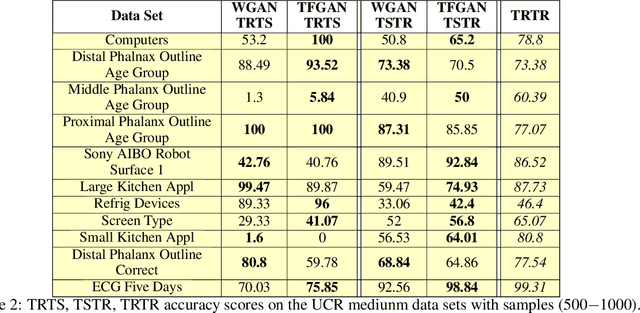
It is abundantly clear that time dependent data is a vital source of information in the world. The challenge has been for applications in machine learning to gain access to a considerable amount of quality data needed for algorithm development and analysis. Modeling synthetic data using a Generative Adversarial Network (GAN) has been at the heart of providing a viable solution. Our work focuses on one dimensional times series and explores the few shot approach, which is the ability of an algorithm to perform well with limited data. This work attempts to ease the frustration by proposing a new architecture, Time Series GAN (TSGAN), to model realistic time series data. We evaluate TSGAN on 70 data sets from a benchmark time series database. Our results demonstrate that TSGAN performs better than the competition both quantitatively using the Frechet Inception Score (FID) metric, and qualitatively when classification is used as the evaluation criteria.
EventDetectR -- An Open-Source Event Detection System
Nov 16, 2020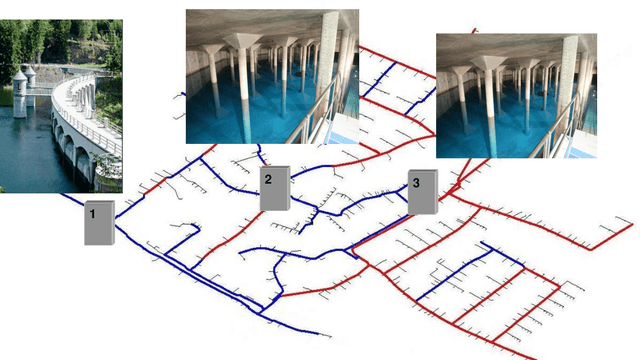
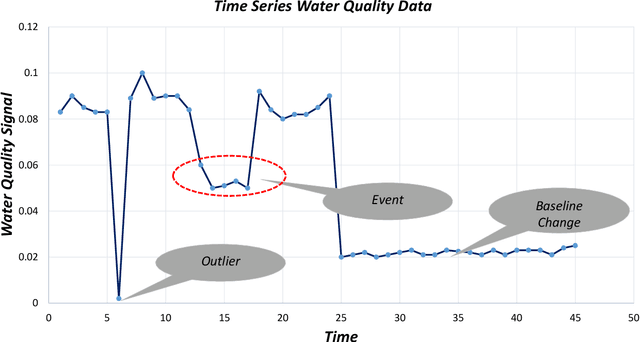
EventDetectR: An efficient Event Detection System (EDS) capable of detecting unexpected water quality conditions. This approach uses multiple algorithms to model the relationship between various multivariate water quality signals. Then the residuals of the models were utilized in constructing the event detection algorithm, which provides a continuous measure of the probability of an event at every time step. The proposed framework was tested for water contamination events with industrial data from automated water quality sensors. The results showed that the framework is reliable with better performance and is highly suitable for event detection.
On Theory-training Neural Networks to Infer the Solution of Highly Coupled Differential Equations
Feb 10, 2021
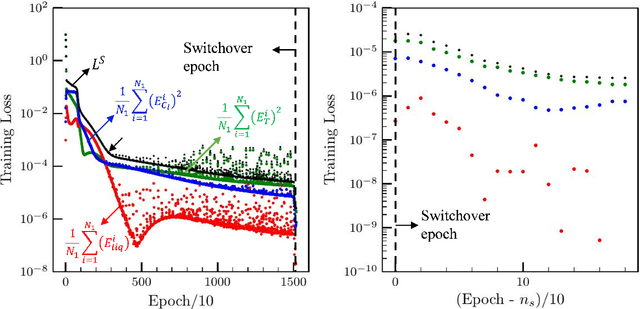
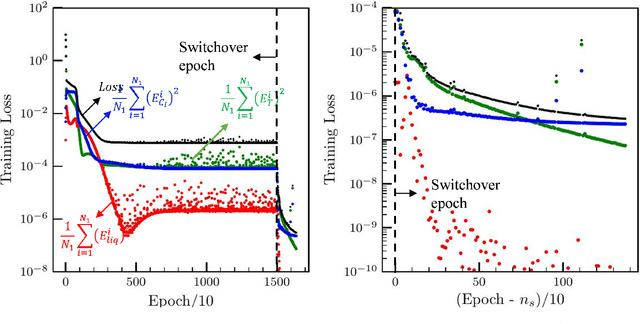
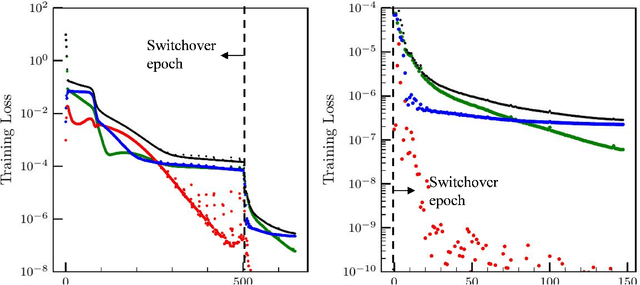
Deep neural networks are transforming fields ranging from computer vision to computational medicine, and we recently extended their application to the field of phase-change heat transfer by introducing theory-trained neural networks (TTNs) for a solidification problem \cite{TTN}. Here, we present general, in-depth, and empirical insights into theory-training networks for learning the solution of highly coupled differential equations. We analyze the deteriorating effects of the oscillating loss on the ability of a network to satisfy the equations at the training data points, measured by the final training loss, and on the accuracy of the inferred solution. We introduce a theory-training technique that, by leveraging regularization, eliminates those oscillations, decreases the final training loss, and improves the accuracy of the inferred solution, with no additional computational cost. Then, we present guidelines that allow a systematic search for the network that has the optimal training time and inference accuracy for a given set of equations; following these guidelines can reduce the number of tedious training iterations in that search. Finally, a comparison between theory-training and the rival, conventional method of solving differential equations using discretization attests to the advantages of theory-training not being necessarily limited to high-dimensional sets of equations. The comparison also reveals a limitation of the current theory-training framework that may limit its application in domains where extreme accuracies are necessary.