 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
First-order Stochastic Algorithms for Escaping From Saddle Points in Almost Linear Time
Mar 01, 2018
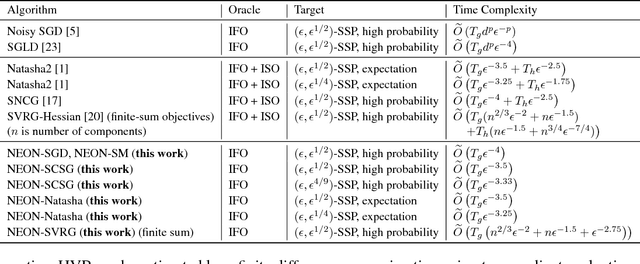
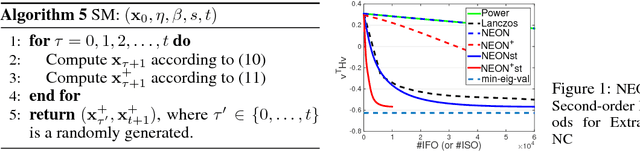
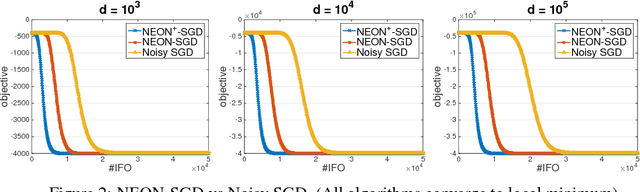
Two classes of methods have been proposed for escaping from saddle points with one using the second-order information carried by the Hessian and the other adding the noise into the first-order information. The existing analysis for algorithms using noise in the first-order information is quite involved and hides the essence of added noise, which hinder further improvements of these algorithms. In this paper, we present a novel perspective of noise-adding technique, i.e., adding the noise into the first-order information can help extract the negative curvature from the Hessian matrix, and provide a formal reasoning of this perspective by analyzing a simple first-order procedure. More importantly, the proposed procedure enables one to design purely first-order stochastic algorithms for escaping from non-degenerate saddle points with a much better time complexity (almost linear time in terms of the problem's dimensionality). In particular, we develop a {\bf first-order stochastic algorithm} based on our new technique and an existing algorithm that only converges to a first-order stationary point to enjoy a time complexity of {$\widetilde O(d/\epsilon^{3.5})$ for finding a nearly second-order stationary point $\bf{x}$ such that $\|\nabla F(bf{x})\|\leq \epsilon$ and $\nabla^2 F(bf{x})\geq -\sqrt{\epsilon}I$ (in high probability), where $F(\cdot)$ denotes the objective function and $d$ is the dimensionality of the problem. To the best of our knowledge, this is the best theoretical result of first-order algorithms for stochastic non-convex optimization, which is even competitive with if not better than existing stochastic algorithms hinging on the second-order information.
A Cooperative Dynamic Task Assignment Framework for COTSBot AUVs
Jan 11, 2021
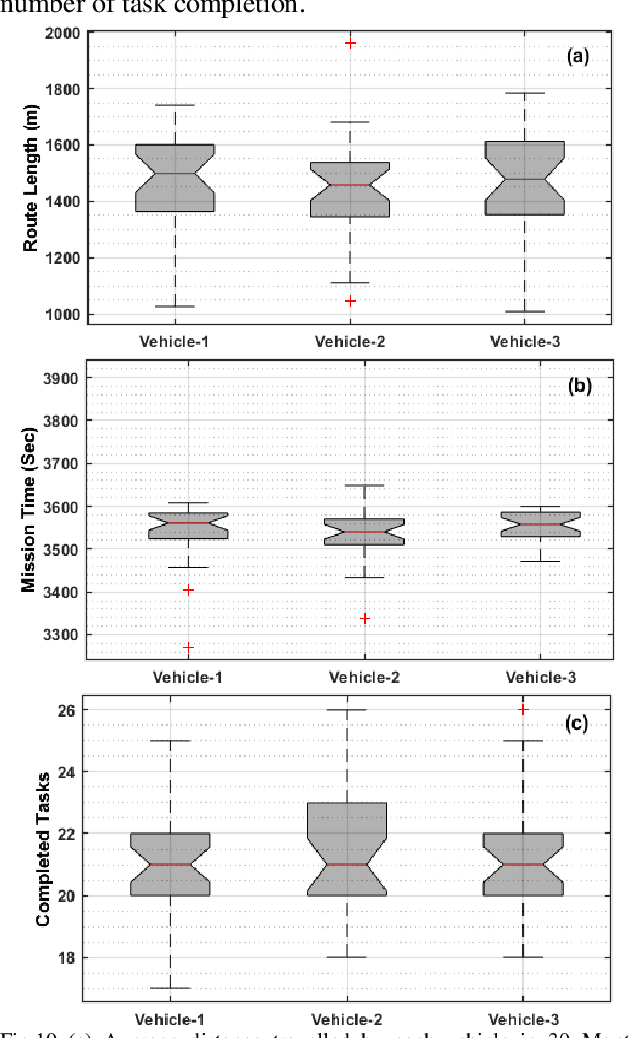
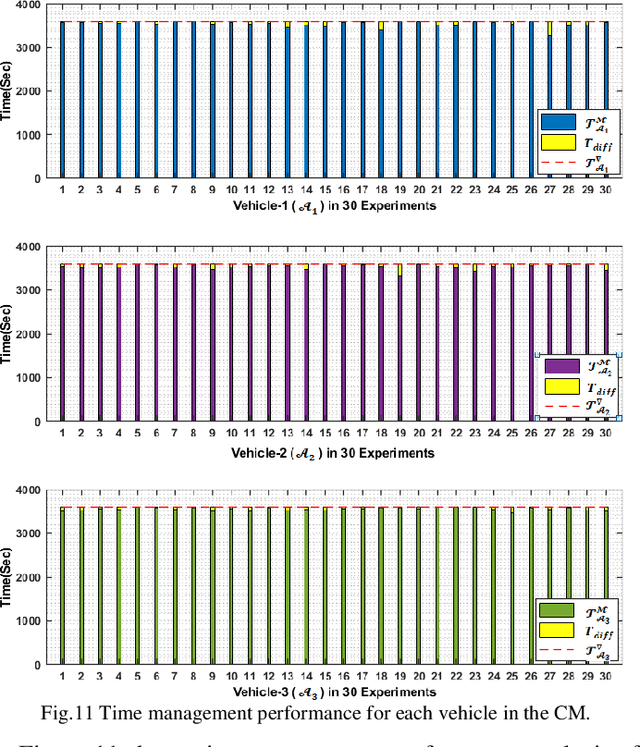
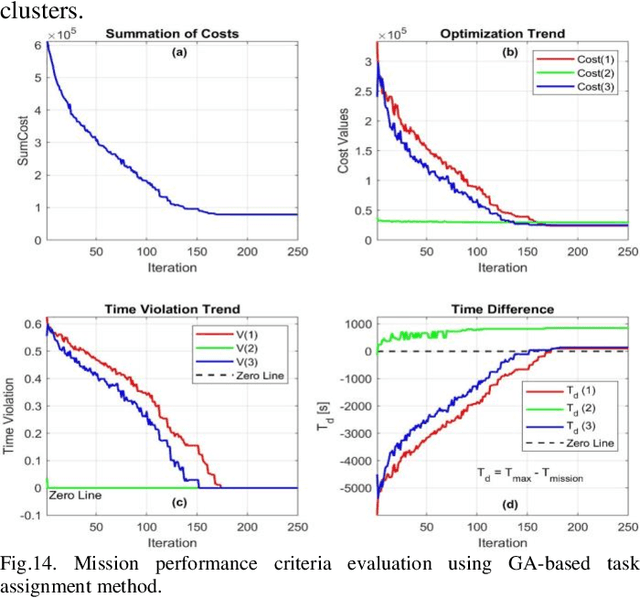
This paper presents a cooperative dynamic task assignment framework for a certain class of Autonomous Underwater Vehicles (AUVs) employed to control outbreak of Crown-Of-Thorns Starfish (COTS) in Australia's Great Barrier Reef. The problem of monitoring and controlling the COTS is transcribed into a constrained task assignment problem in which eradicating clusters of COTS, by the injection system of COTSbot AUVs, is considered as a task. A probabilistic map of the operating environment including seabed terrain, clusters of COTS, and coastlines is constructed. Then, a novel heuristic algorithm called Heuristic Fleet Cooperation (HFC) is developed to provide a cooperative injection of the COTSbot AUVs to the maximum possible COTS in an assigned mission time. Extensive simulation studies together with quantitative performance analysis are conducted to demonstrate the effectiveness and robustness of the proposed cooperative task assignment algorithm in eradicating the COTS in the Great Barrier Reef.
FedV: Privacy-Preserving Federated Learning over Vertically Partitioned Data
Mar 05, 2021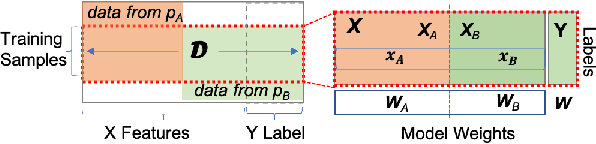


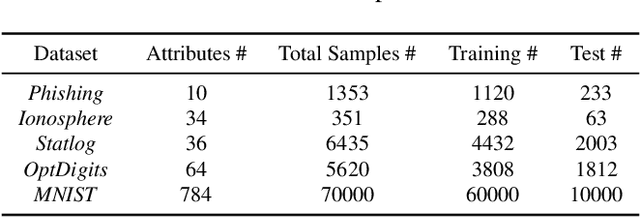
Federated learning (FL) has been proposed to allow collaborative training of machine learning (ML) models among multiple parties where each party can keep its data private. In this paradigm, only model updates, such as model weights or gradients, are shared. Many existing approaches have focused on horizontal FL, where each party has the entire feature set and labels in the training data set. However, many real scenarios follow a vertically-partitioned FL setup, where a complete feature set is formed only when all the datasets from the parties are combined, and the labels are only available to a single party. Privacy-preserving vertical FL is challenging because complete sets of labels and features are not owned by one entity. Existing approaches for vertical FL require multiple peer-to-peer communications among parties, leading to lengthy training times, and are restricted to (approximated) linear models and just two parties. To close this gap, we propose FedV, a framework for secure gradient computation in vertical settings for several widely used ML models such as linear models, logistic regression, and support vector machines. FedV removes the need for peer-to-peer communication among parties by using functional encryption schemes; this allows FedV to achieve faster training times. It also works for larger and changing sets of parties. We empirically demonstrate the applicability for multiple types of ML models and show a reduction of 10%-70% of training time and 80% to 90% in data transfer with respect to the state-of-the-art approaches.
Towards Optimal District Heating Temperature Control in China with Deep Reinforcement Learning
Dec 18, 2020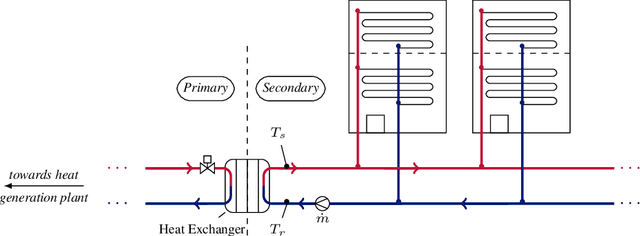

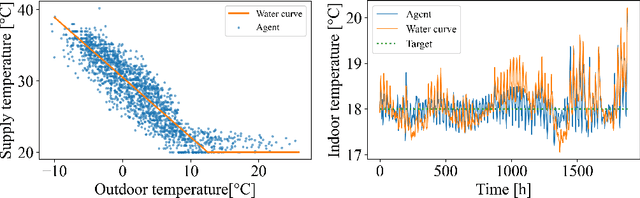

Achieving efficiency gains in Chinese district heating networks, thereby reducing their carbon footprint, requires new optimal control methods going beyond current industry tools. Focusing on the secondary network, we propose a data-driven deep reinforcement learning (DRL) approach to address this task. We build a recurrent neural network, trained on simulated data, to predict the indoor temperatures. This model is then used to train two DRL agents, with or without expert guidance, for the optimal control of the supply water temperature. Our tests in a multi-apartment setting show that both agents can ensure a higher thermal comfort and at the same time a smaller energy cost, compared to an optimized baseline strategy.
Point process models for sequence detection in high-dimensional neural spike trains
Oct 10, 2020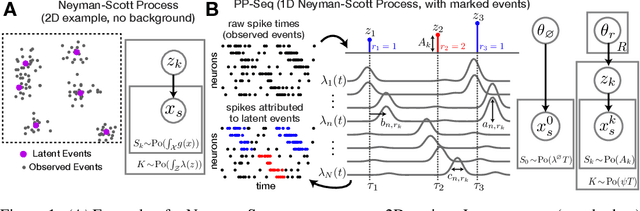
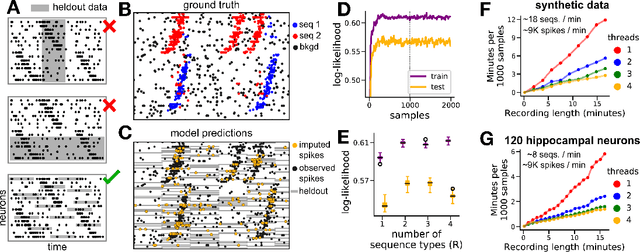
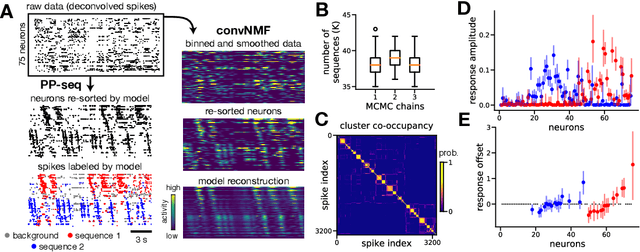
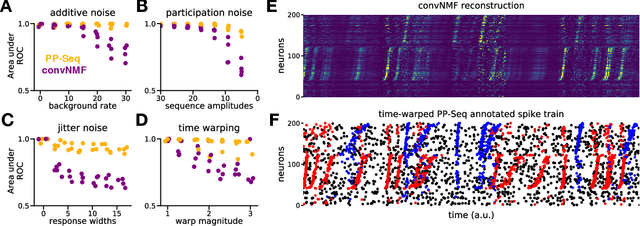
Sparse sequences of neural spikes are posited to underlie aspects of working memory, motor production, and learning. Discovering these sequences in an unsupervised manner is a longstanding problem in statistical neuroscience. Promising recent work utilized a convolutive nonnegative matrix factorization model to tackle this challenge. However, this model requires spike times to be discretized, utilizes a sub-optimal least-squares criterion, and does not provide uncertainty estimates for model predictions or estimated parameters. We address each of these shortcomings by developing a point process model that characterizes fine-scale sequences at the level of individual spikes and represents sequence occurrences as a small number of marked events in continuous time. This ultra-sparse representation of sequence events opens new possibilities for spike train modeling. For example, we introduce learnable time warping parameters to model sequences of varying duration, which have been experimentally observed in neural circuits. We demonstrate these advantages on experimental recordings from songbird higher vocal center and rodent hippocampus.
Persuading Voters in District-based Elections
Dec 10, 2020

We focus on the scenario in which an agent can exploit his information advantage to manipulate the outcome of an election. In particular, we study district-based elections with two candidates, in which the winner of the election is the candidate that wins in the majority of the districts. District-based elections are adopted worldwide (e.g., UK and USA) and are a natural extension of widely studied voting mechanisms (e.g., k-voting and plurality voting). We resort to the Bayesian persuasion framework, where the manipulator (sender) strategically discloses information to the voters (receivers) that update their beliefs rationally. We study both private signaling, in which the sender can use a private communication channel per receiver, and public signaling, in which the sender can use a single communication channel for all the receivers. Furthermore, for the first time, we introduce semi-public signaling in which the sender can use a single communication channel per district. We show that there is a sharp distinction between private and (semi-)public signaling. In particular, optimal private signaling schemes can provide an arbitrarily better probability of victory than (semi-)public ones and can be computed efficiently, while optimal (semi-)public signaling schemes cannot be approximated to within any factor in polynomial time unless P=NP. However, we show that reasonable relaxations allow the design of multi-criteria PTASs for optimal (semi-)public signaling schemes. In doing so, we introduce a novel property, namely comparative stability, and we design a bi-criteria PTAS for public signaling in general Bayesian persuasion problems beyond elections when the sender's utility function is state-dependent.
Marketing Mix Optimization with Practical Constraints
Jan 11, 2021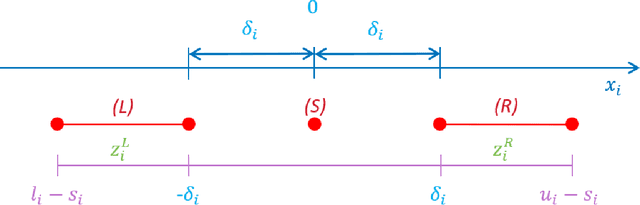
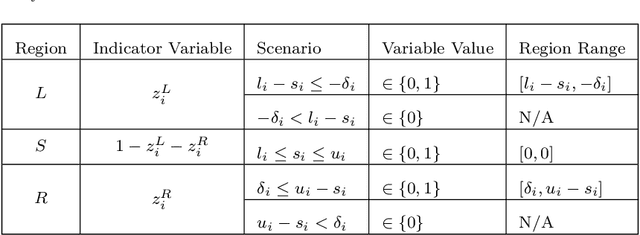
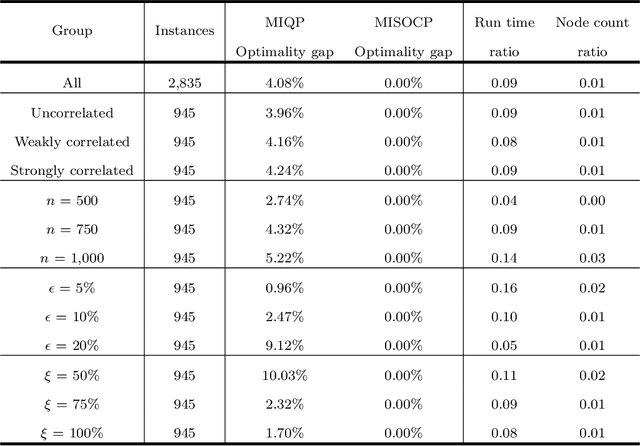
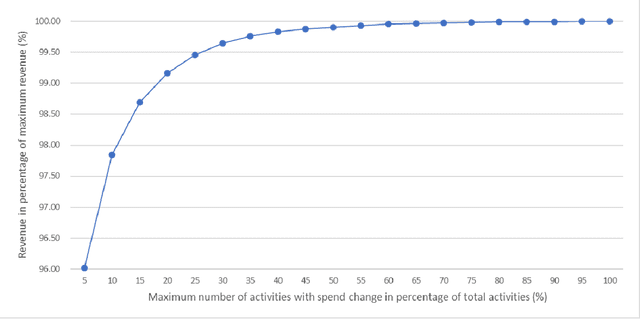
In this paper, we address a variant of the marketing mix optimization (MMO) problem which is commonly encountered in many industries, e.g., retail and consumer packaged goods (CPG) industries. This problem requires the spend for each marketing activity, if adjusted, be changed by a non-negligible degree (minimum change) and also the total number of activities with spend change be limited (maximum number of changes). With these two additional practical requirements, the original resource allocation problem is formulated as a mixed integer nonlinear program (MINLP). Given the size of a realistic problem in the industrial setting, the state-of-the-art integer programming solvers may not be able to solve the problem to optimality in a straightforward way within a reasonable amount of time. Hence, we propose a systematic reformulation to ease the computational burden. Computational tests show significant improvements in the solution process.
Intelligent Protection & Classification of Transients in Two-Core Symmetric Phase Angle Regulating Transformers
Jun 17, 2020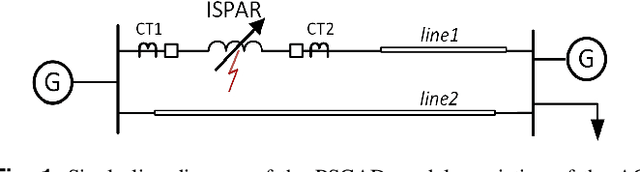

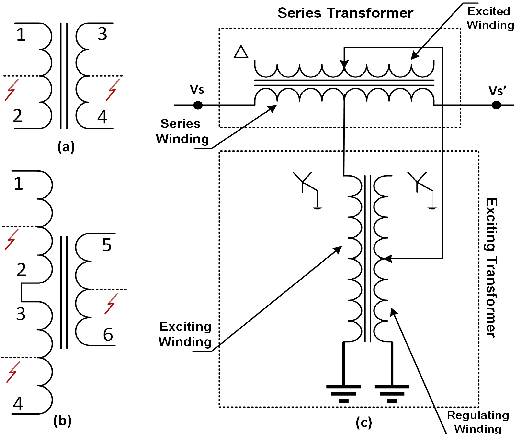

This paper investigates the applicability of time and time-frequency features based classifiers to distinguish internal faults and other transients - magnetizing inrush, sympathetic inrush, external faults with current transformer saturation, and overexcitation - for Indirect Symmetrical Phase Angle Regulating Transformers (ISPAR). Then the faulty transformer unit (series/exciting) of the ISPAR is located, or else the transient disturbance is identified. An event detector detects variation in differential currents and registers one-cycle of 3-phase post transient samples which are used to extract the time and time-frequency features for training seven classifiers. Three different sets of features - wavelet coefficients, time-domain features, and combination of time and wavelet energy - obtained from exhaustive search using Decision Tree, random forest feature selection, and maximum Relevance Minimum Redundancy are used. The internal fault is detected with a balanced accuracy of 99.9%, the faulty unit is localized with balanced accuracy of 98.7% and the no-fault transients are classified with balanced accuracy of 99.5%. The results show potential for accurate internal fault detection and localization, and transient identification. The proposed scheme can supervise the operation of existing microprocessor-based differential relays resulting in higher stability and dependability. The ISPAR is modeled and the transients are simulated in PSCAD/EMTDC by varying several parameters.
Classifying Malware Images with Convolutional Neural Network Models
Oct 30, 2020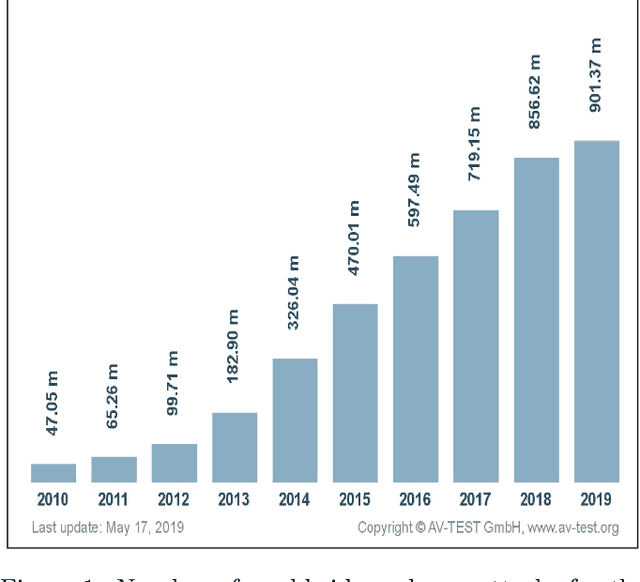
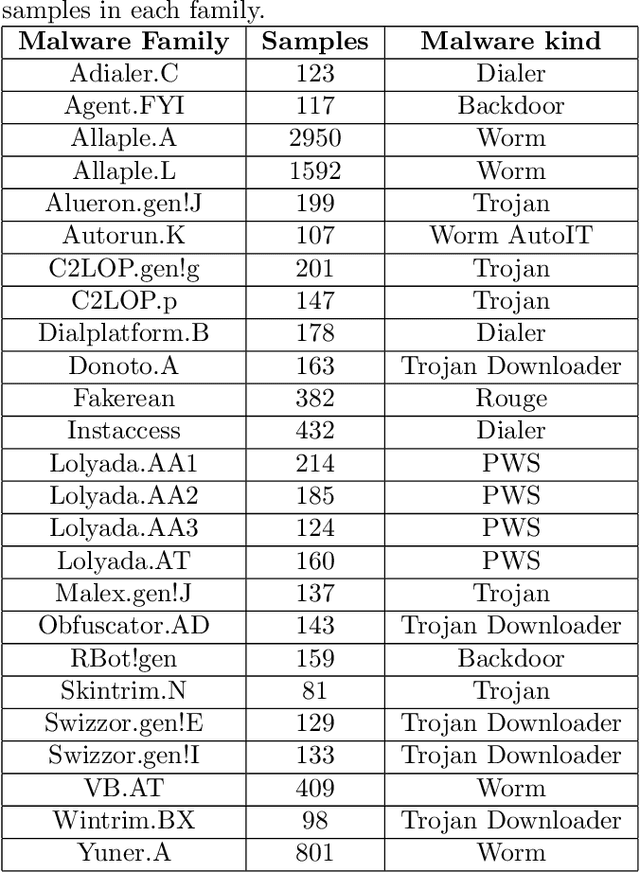

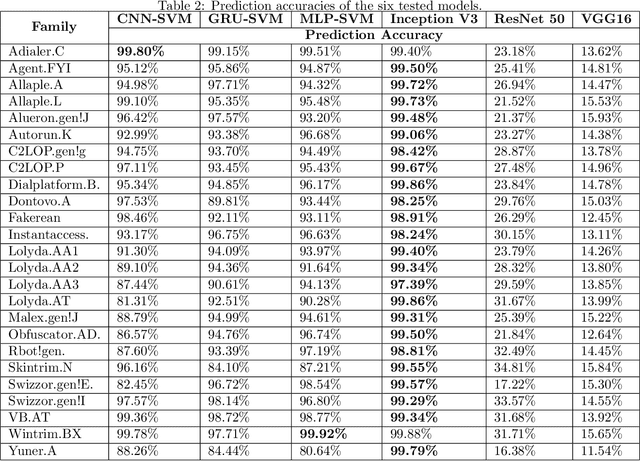
Due to increasing threats from malicious software (malware) in both number and complexity, researchers have developed approaches to automatic detection and classification of malware, instead of analyzing methods for malware files manually in a time-consuming effort. At the same time, malware authors have developed techniques to evade signature-based detection techniques used by antivirus companies. Most recently, deep learning is being used in malware classification to solve this issue. In this paper, we use several convolutional neural network (CNN) models for static malware classification. In particular, we use six deep learning models, three of which are past winners of the ImageNet Large-Scale Visual Recognition Challenge. The other three models are CNN-SVM, GRU-SVM and MLP-SVM, which enhance neural models with support vector machines (SVM). We perform experiments using the Malimg dataset, which has malware images that were converted from Portable Executable malware binaries. The dataset is divided into 25 malware families. Comparisons show that the Inception V3 model achieves a test accuracy of 99.24%, which is better than the accuracy of 98.52% achieved by the current state-of-the-art system called the M-CNN model.
* 12 pages, 11 Figures
Low-latency Federated Learning and Blockchain for Edge Association in Digital Twin empowered 6G Networks
Nov 17, 2020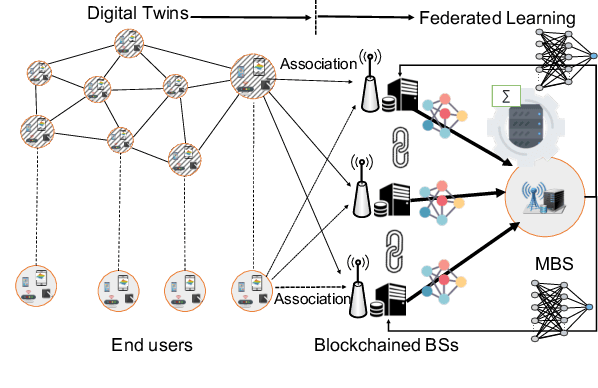
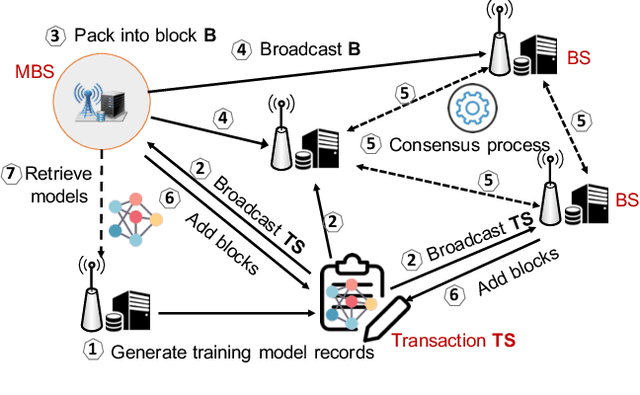
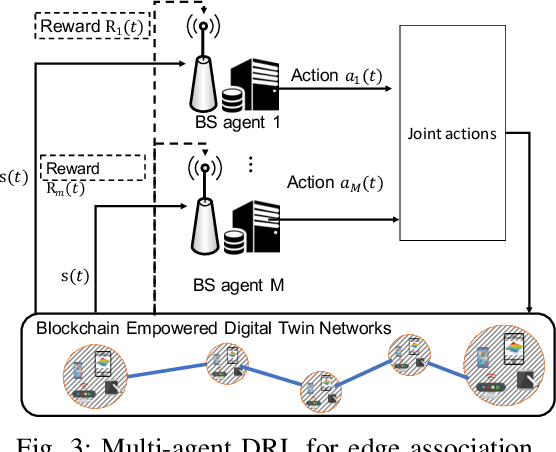
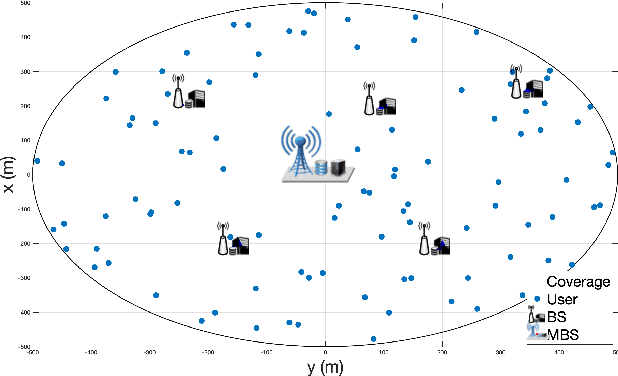
Emerging technologies such as digital twins and 6th Generation mobile networks (6G) have accelerated the realization of edge intelligence in Industrial Internet of Things (IIoT). The integration of digital twin and 6G bridges the physical system with digital space and enables robust instant wireless connectivity. With increasing concerns on data privacy, federated learning has been regarded as a promising solution for deploying distributed data processing and learning in wireless networks. However, unreliable communication channels, limited resources, and lack of trust among users, hinder the effective application of federated learning in IIoT. In this paper, we introduce the Digital Twin Wireless Networks (DTWN) by incorporating digital twins into wireless networks, to migrate real-time data processing and computation to the edge plane. Then, we propose a blockchain empowered federated learning framework running in the DTWN for collaborative computing, which improves the reliability and security of the system, and enhances data privacy. Moreover, to balance the learning accuracy and time cost of the proposed scheme, we formulate an optimization problem for edge association by jointly considering digital twin association, training data batch size, and bandwidth allocation. We exploit multi-agent reinforcement learning to find an optimal solution to the problem. Numerical results on real-world dataset show that the proposed scheme yields improved efficiency and reduced cost compared to benchmark learning method.