 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Incremental Beam Manipulation for Natural Language Generation
Feb 04, 2021
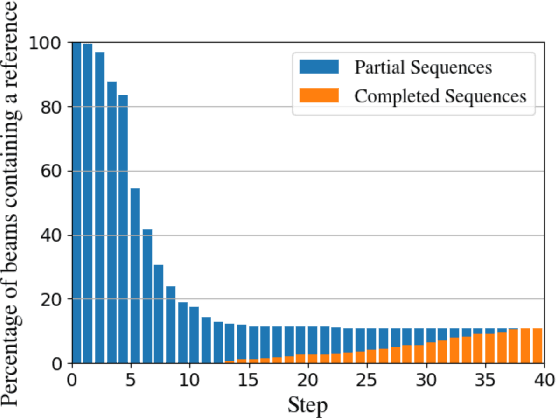
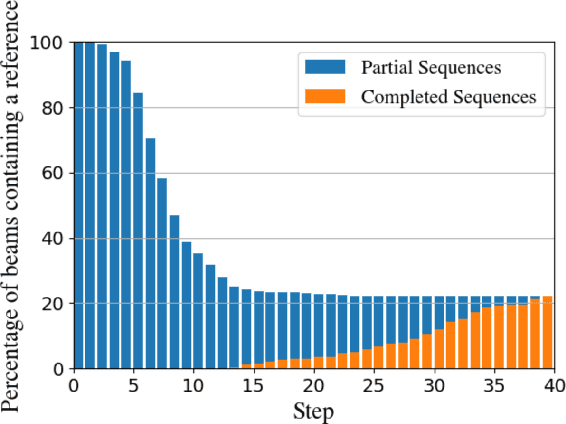
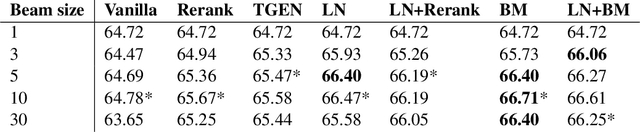

The performance of natural language generation systems has improved substantially with modern neural networks. At test time they typically employ beam search to avoid locally optimal but globally suboptimal predictions. However, due to model errors, a larger beam size can lead to deteriorating performance according to the evaluation metric. For this reason, it is common to rerank the output of beam search, but this relies on beam search to produce a good set of hypotheses, which limits the potential gains. Other alternatives to beam search require changes to the training of the model, which restricts their applicability compared to beam search. This paper proposes incremental beam manipulation, i.e. reranking the hypotheses in the beam during decoding instead of only at the end. This way, hypotheses that are unlikely to lead to a good final output are discarded, and in their place hypotheses that would have been ignored will be considered instead. Applying incremental beam manipulation leads to an improvement of 1.93 and 5.82 BLEU points over vanilla beam search for the test sets of the E2E and WebNLG challenges respectively. The proposed method also outperformed a strong reranker by 1.04 BLEU points on the E2E challenge, while being on par with it on the WebNLG dataset.
Modeling Wildfire Perimeter Evolution using Deep Neural Networks
Sep 08, 2020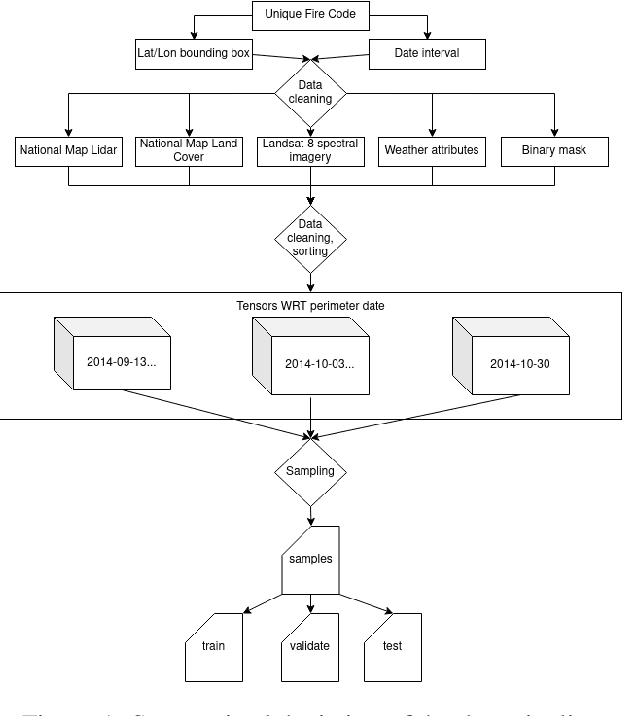
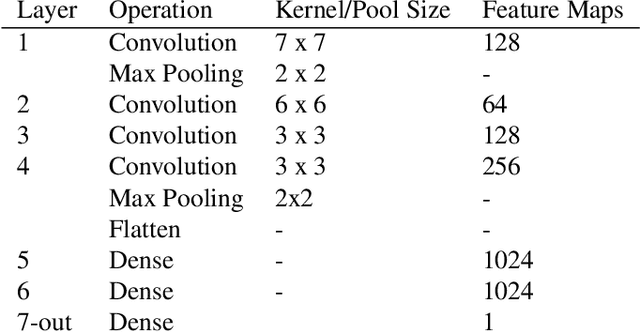

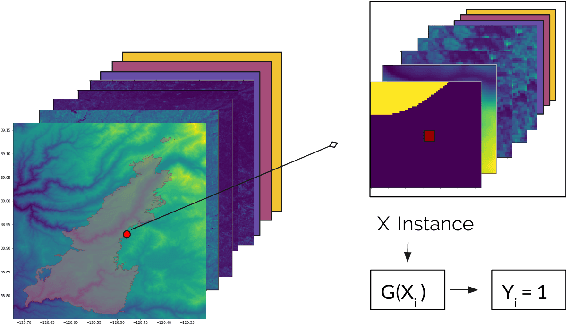
With the increased size and frequency of wildfire eventsworldwide, accurate real-time prediction of evolving wildfirefronts is a crucial component of firefighting efforts and for-est management practices. We propose a wildfire spreadingmodel that predicts the evolution of the wildfire perimeter in24 hour periods. The fire spreading simulation is based ona deep convolutional neural network (CNN) that is trainedon remotely sensed atmospheric and environmental time se-ries data. We show that the model is able to learn wildfirespreading dynamics from real historic data sets from a seriesof wildfires in the Western Sierra Nevada Mountains in Cal-ifornia. We validate the model on a previously unseen wild-fire and produce realistic results that significantly outperformhistoric alternatives with validation accuracies ranging from78% - 98%
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
Oct 12, 2020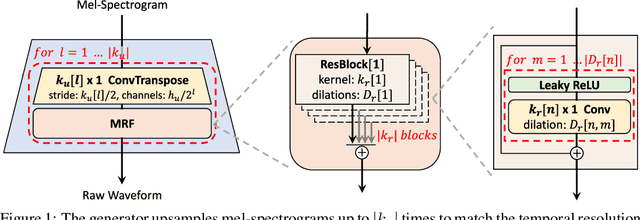
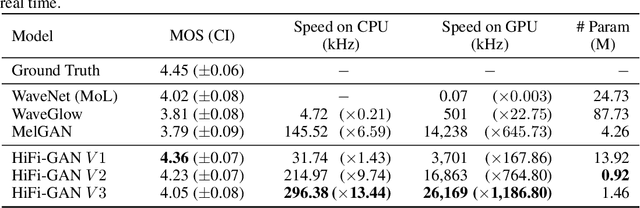
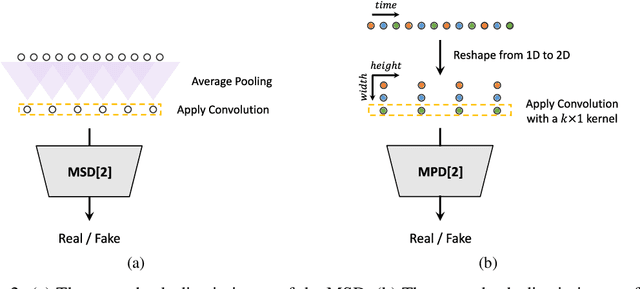
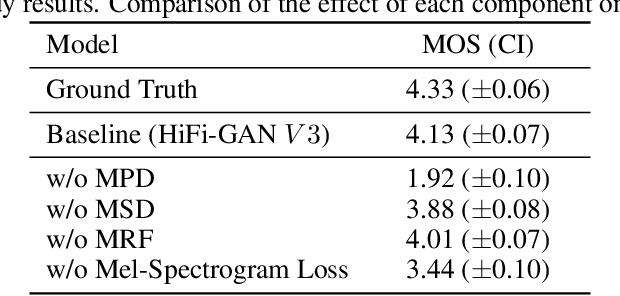
Several recent studies on speech synthesis have employed generative adversarial networks (GANs) to produce raw waveforms. Although such methods improve the sampling efficiency and memory usage, their sample quality has not yet reached that of autoregressive and flow-based generative models. In this study, we propose HiFi-GAN, which achieves both efficient and high-fidelity speech synthesis. As speech audio consists of sinusoidal signals with various periods, we demonstrate that modeling periodic patterns of an audio is crucial for enhancing sample quality. A subjective human evaluation (mean opinion score, MOS) of a single speaker dataset indicates that our proposed method demonstrates similarity to human quality while generating 22.05 kHz high-fidelity audio 167.9 times faster than real-time on a single V100 GPU. We further show the generality of HiFi-GAN to the mel-spectrogram inversion of unseen speakers and end-to-end speech synthesis. Finally, a small footprint version of HiFi-GAN generates samples 13.4 times faster than real time on CPU with comparable quality to an autoregressive counterpart.
High-order Differentiable Autoencoder for Nonlinear Model Reduction
Feb 19, 2021
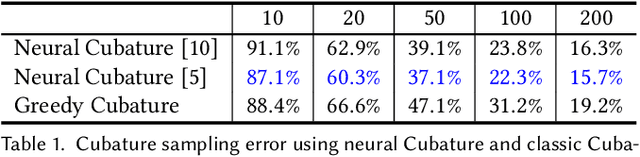

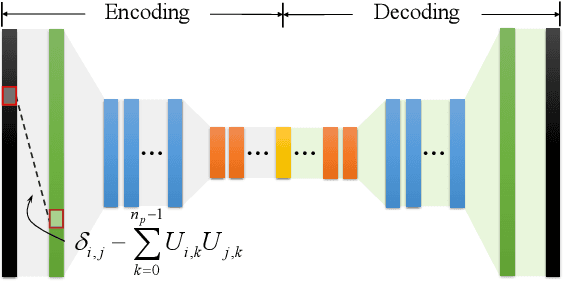
This paper provides a new avenue for exploiting deep neural networks to improve physics-based simulation. Specifically, we integrate the classic Lagrangian mechanics with a deep autoencoder to accelerate elastic simulation of deformable solids. Due to the inertia effect, the dynamic equilibrium cannot be established without evaluating the second-order derivatives of the deep autoencoder network. This is beyond the capability of off-the-shelf automatic differentiation packages and algorithms, which mainly focus on the gradient evaluation. Solving the nonlinear force equilibrium is even more challenging if the standard Newton's method is to be used. This is because we need to compute a third-order derivative of the network to obtain the variational Hessian. We attack those difficulties by exploiting complex-step finite difference, coupled with reverse automatic differentiation. This strategy allows us to enjoy the convenience and accuracy of complex-step finite difference and in the meantime, to deploy complex-value perturbations as collectively as possible to save excessive network passes. With a GPU-based implementation, we are able to wield deep autoencoders (e.g., $10+$ layers) with a relatively high-dimension latent space in real-time. Along this pipeline, we also design a sampling network and a weighting network to enable \emph{weight-varying} Cubature integration in order to incorporate nonlinearity in the model reduction. We believe this work will inspire and benefit future research efforts in nonlinearly reduced physical simulation problems.
Towards All-around Knowledge Transferring: Learning From Task-irrelevant Labels
Nov 17, 2020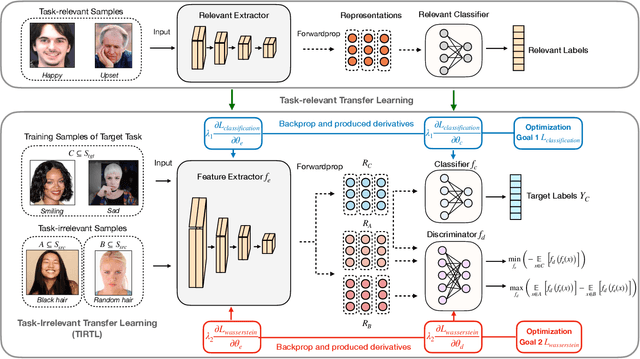
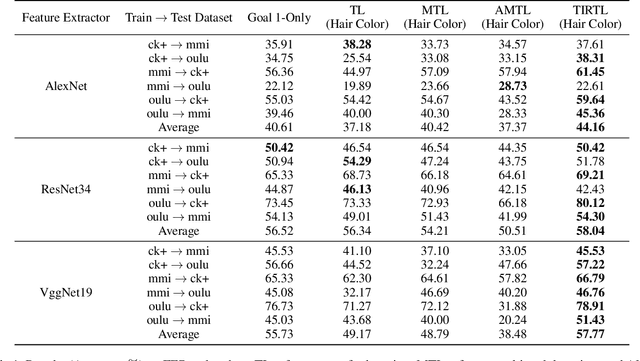
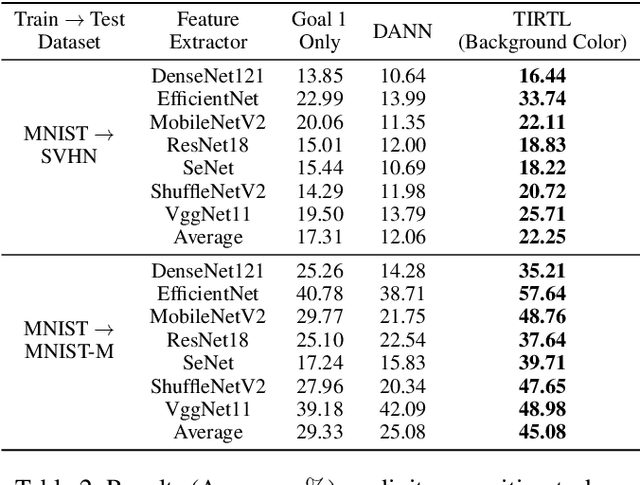
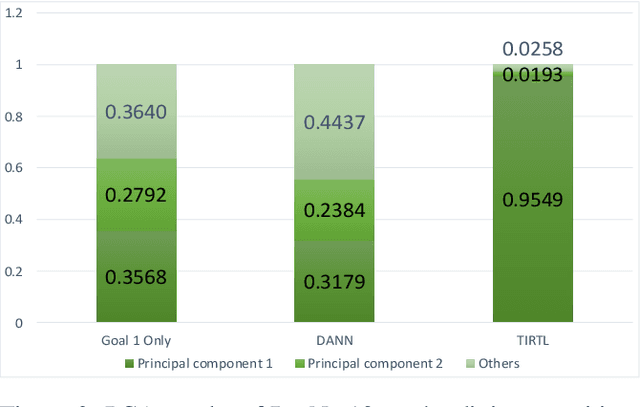
Deep neural models have hitherto achieved significant performances on numerous classification tasks, but meanwhile require sufficient manually annotated data. Since it is extremely time-consuming and expensive to annotate adequate data for each classification task, learning an empirically effective model with generalization on small dataset has received increased attention. Existing efforts mainly focus on transferring task-relevant knowledge from other similar data to tackle the issue. These approaches have yielded remarkable improvements, yet neglecting the fact that the task-irrelevant features could bring out massive negative transfer effects. To date, no large-scale studies have been performed to investigate the impact of task-irrelevant features, let alone the utilization of this kind of features. In this paper, we firstly propose Task-Irrelevant Transfer Learning (TIRTL) to exploit task-irrelevant features, which mainly are extracted from task-irrelevant labels. Particularly, we suppress the expression of task-irrelevant information and facilitate the learning process of classification. We also provide a theoretical explanation of our method. In addition, TIRTL does not conflict with those that have previously exploited task-relevant knowledge and can be well combined to enable the simultaneous utilization of task-relevant and task-irrelevant features for the first time. In order to verify the effectiveness of our theory and method, we conduct extensive experiments on facial expression recognition and digit recognition tasks. Our source code will be also available in the future for reproducibility.
Dense Prediction on Sequences with Time-Dilated Convolutions for Speech Recognition
Dec 14, 2016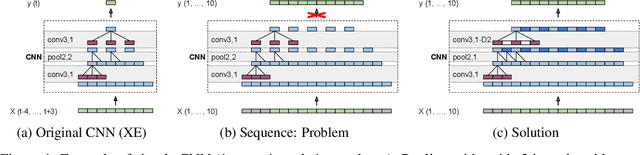
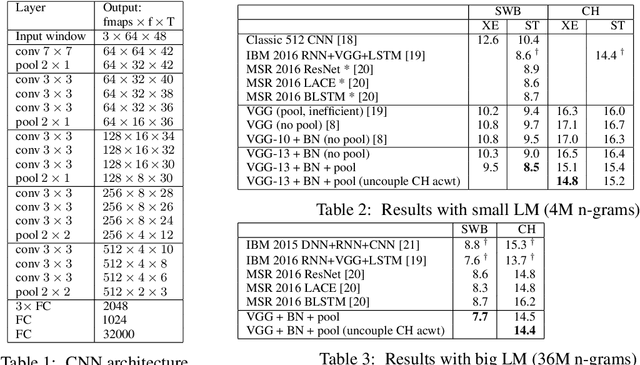
In computer vision pixelwise dense prediction is the task of predicting a label for each pixel in the image. Convolutional neural networks achieve good performance on this task, while being computationally efficient. In this paper we carry these ideas over to the problem of assigning a sequence of labels to a set of speech frames, a task commonly known as framewise classification. We show that dense prediction view of framewise classification offers several advantages and insights, including computational efficiency and the ability to apply batch normalization. When doing dense prediction we pay specific attention to strided pooling in time and introduce an asymmetric dilated convolution, called time-dilated convolution, that allows for efficient and elegant implementation of pooling in time. We show results using time-dilated convolutions in a very deep VGG-style CNN with batch normalization on the Hub5 Switchboard-2000 benchmark task. With a big n-gram language model, we achieve 7.7% WER which is the best single model single-pass performance reported so far.
Analyzing Unaligned Multimodal Sequence via Graph Convolution and Graph Pooling Fusion
Dec 02, 2020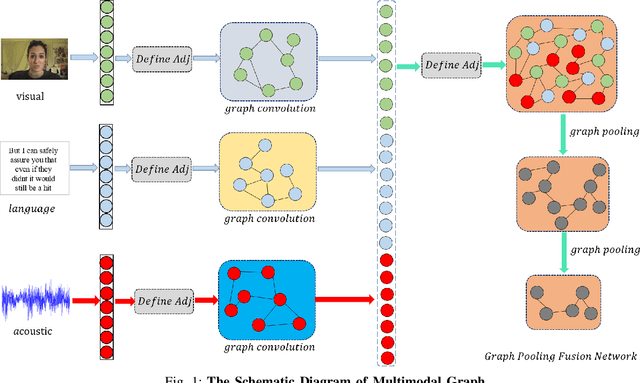

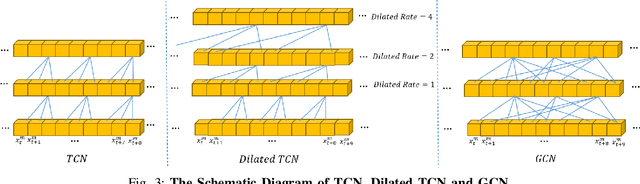
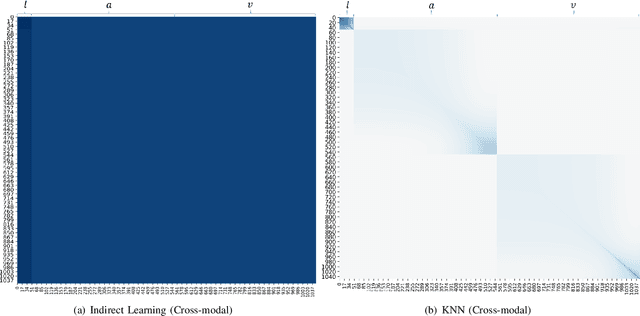
In this paper, we study the task of multimodal sequence analysis which aims to draw inferences from visual, language and acoustic sequences. A majority of existing works generally focus on aligned fusion, mostly at word level, of the three modalities to accomplish this task, which is impractical in real-world scenarios. To overcome this issue, we seek to address the task of multimodal sequence analysis on unaligned modality sequences which is still relatively underexplored and also more challenging. Recurrent neural network (RNN) and its variants are widely used in multimodal sequence analysis, but they are susceptible to the issues of gradient vanishing/explosion and high time complexity due to its recurrent nature. Therefore, we propose a novel model, termed Multimodal Graph, to investigate the effectiveness of graph neural networks (GNN) on modeling multimodal sequential data. The graph-based structure enables parallel computation in time dimension and can learn longer temporal dependency in long unaligned sequences. Specifically, our Multimodal Graph is hierarchically structured to cater to two stages, i.e., intra- and inter-modal dynamics learning. For the first stage, a graph convolutional network is employed for each modality to learn intra-modal dynamics. In the second stage, given that the multimodal sequences are unaligned, the commonly considered word-level fusion does not pertain. To this end, we devise a graph pooling fusion network to automatically learn the associations between various nodes from different modalities. Additionally, we define multiple ways to construct the adjacency matrix for sequential data. Experimental results suggest that our graph-based model reaches state-of-the-art performance on two benchmark datasets.
Automatic Classification of OSA related Snoring Signals from Nocturnal Audio Recordings
Feb 25, 2021

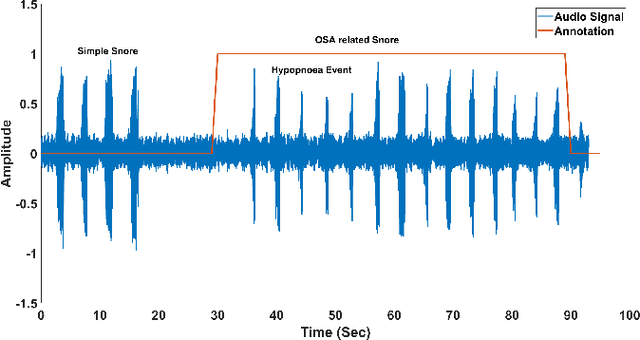
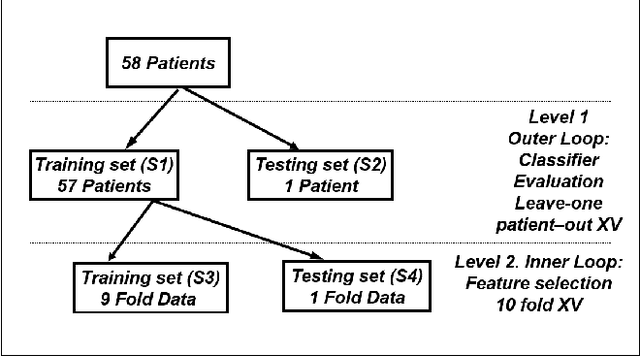
In this study, the development of an automatic algorithm is presented to classify the nocturnal audio recording of an obstructive sleep apnoea (OSA) patient as OSA related snore, simple snore and other sounds. Recent studies has been shown that knowledge regarding the OSA related snore could assist in identifying the site of airway collapse. Audio signal was recorded simultaneously with full-night polysomnography during sleep with a ceiling microphone. Time and frequency features of the nocturnal audio signal were extracted to classify the audio signal into OSA related snore, simple snore and other sounds. Two algorithms were developed to extract OSA related snore using an linear discriminant analysis (LDA) classifier based on the hypothesis that OSA related snoring can assist in identifying the site-of-upper airway collapse. An unbiased nested leave-one patient-out cross-validation process was used to select a high performing feature set from the full set of features. Results indicated that the algorithm achieved an accuracy of 87% for identifying snore events from the audio recordings and an accuracy of 72% for identifying OSA related snore events from the snore events. The direct method to extract OSA-related snore events using a multi-class LDA classifier achieved an accuracy of 64% using the feature selection algorithm. Our results gives a clear indication that OSA-related snore events can be extracted from nocturnal sound recordings, and therefore could potentially be used as a new tool for identifying the site of airway collapse from the nocturnal audio recordings.
A Hybrid Approach to Audio-to-Score Alignment
Jul 28, 2020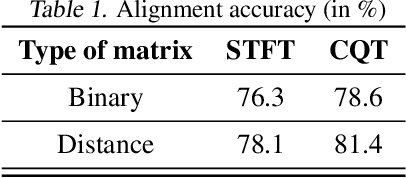
Audio-to-score alignment aims at generating an accurate mapping between a performance audio and the score of a given piece. Standard alignment methods are based on Dynamic Time Warping (DTW) and employ handcrafted features. We explore the usage of neural networks as a preprocessing step for DTW-based automatic alignment methods. Experiments on music data from different acoustic conditions demonstrate that this method generates robust alignments whilst being adaptable at the same time.
Modeling Disease Progression Trajectories from Longitudinal Observational Data
Dec 09, 2020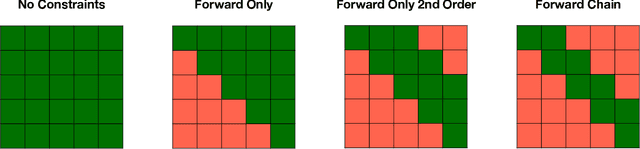
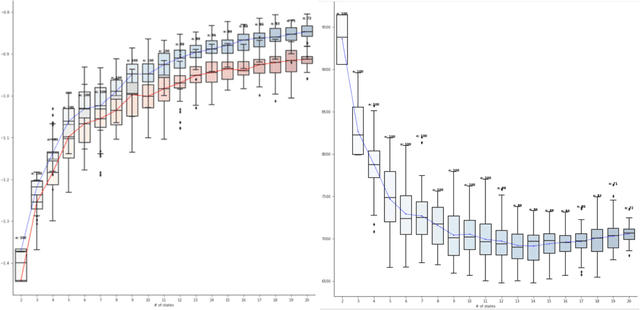
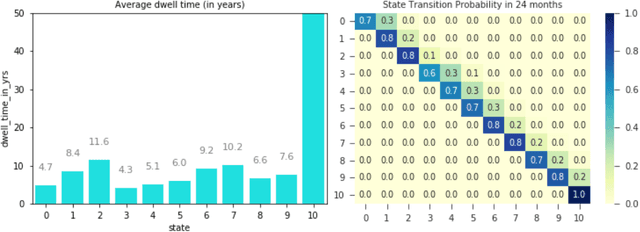

Analyzing disease progression patterns can provide useful insights into the disease processes of many chronic conditions. These analyses may help inform recruitment for prevention trials or the development and personalization of treatments for those affected. We learn disease progression patterns using Hidden Markov Models (HMM) and distill them into distinct trajectories using visualization methods. We apply it to the domain of Type 1 Diabetes (T1D) using large longitudinal observational data from the T1DI study group. Our method discovers distinct disease progression trajectories that corroborate with recently published findings. In this paper, we describe the iterative process of developing the model. These methods may also be applied to other chronic conditions that evolve over time.