 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Neural Few-Shot Text Classification Reality Check
Jan 28, 2021
Modern classification models tend to struggle when the amount of annotated data is scarce. To overcome this issue, several neural few-shot classification models have emerged, yielding significant progress over time, both in Computer Vision and Natural Language Processing. In the latter, such models used to rely on fixed word embeddings before the advent of transformers. Additionally, some models used in Computer Vision are yet to be tested in NLP applications. In this paper, we compare all these models, first adapting those made in the field of image processing to NLP, and second providing them access to transformers. We then test these models equipped with the same transformer-based encoder on the intent detection task, known for having a large number of classes. Our results reveal that while methods perform almost equally on the ARSC dataset, this is not the case for the Intent Detection task, where the most recent and supposedly best competitors perform worse than older and simpler ones (while all are given access to transformers). We also show that a simple baseline is surprisingly strong. All the new developed models, as well as the evaluation framework, are made publicly available.
Rosella: A Self-Driving Distributed Scheduler for Heterogeneous Clusters
Nov 10, 2020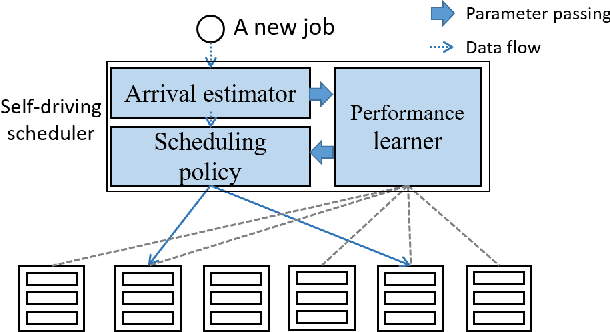
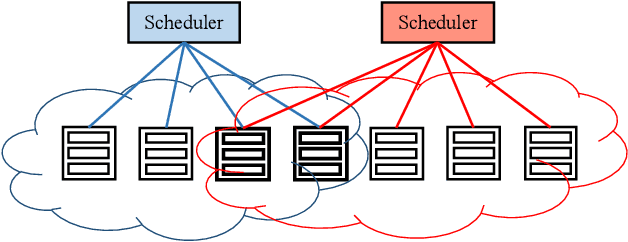
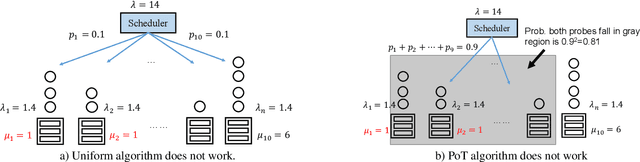
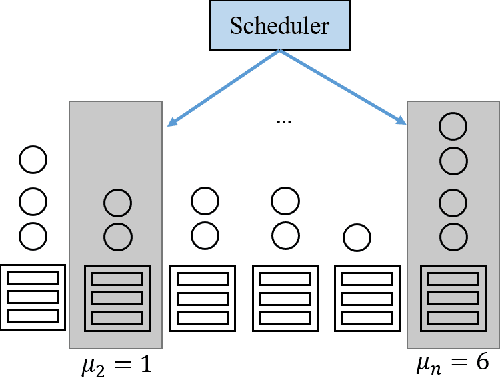
Large-scale interactive web services and advanced AI applications make sophisticated decisions in real-time, based on executing a massive amount of computation tasks on thousands of servers. Task schedulers, which often operate in heterogeneous and volatile environments, require high throughput, i.e., scheduling millions of tasks per second, and low latency, i.e., incurring minimal scheduling delays for millisecond-level tasks. Scheduling is further complicated by other users' workloads in a shared system, other background activities, and the diverse hardware configurations inside datacenters. We present Rosella, a new self-driving, distributed approach for task scheduling in heterogeneous clusters. Our system automatically learns the compute environment and adjust its scheduling policy in real-time. The solution provides high throughput and low latency simultaneously, because it runs in parallel on multiple machines with minimum coordination and only performs simple operations for each scheduling decision. Our learning module monitors total system load, and uses the information to dynamically determine optimal estimation strategy for the backends' compute-power. Our scheduling policy generalizes power-of-two-choice algorithms to handle heterogeneous workers, reducing the max queue length of $O(\log n)$ obtained by prior algorithms to $O(\log \log n)$. We implement a Rosella prototype and evaluate it with a variety of workloads. Experimental results show that Rosella significantly reduces task response times, and adapts to environment changes quickly.
Sparse Approximate Solutions to Max-Plus Equations with Application to Multivariate Convex Regression
Nov 06, 2020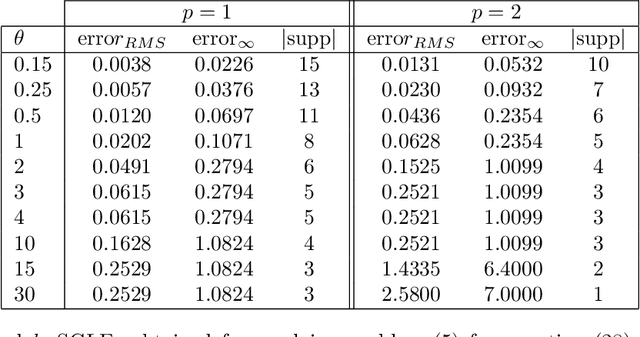
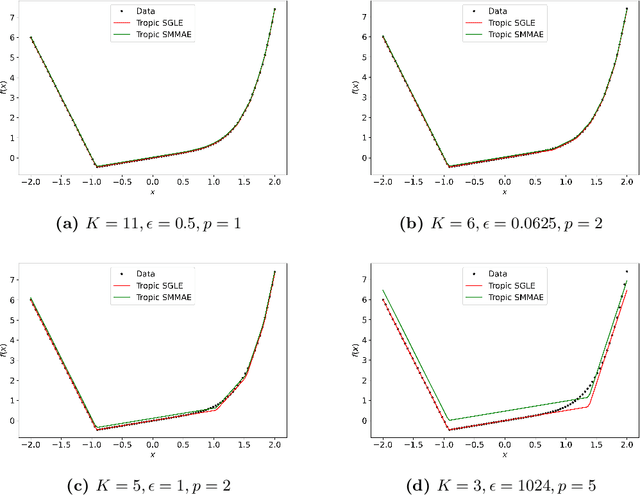
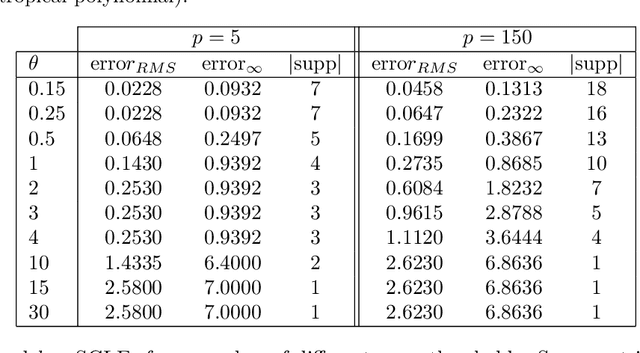
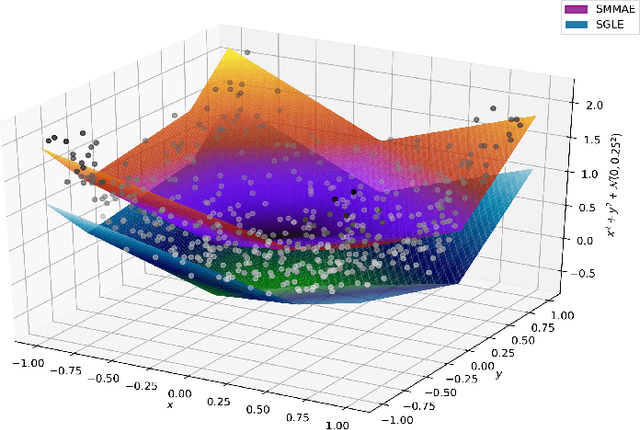
In this work, we study the problem of finding approximate, with minimum support set, solutions to matrix max-plus equations, which we call sparse approximate solutions. We show how one can obtain such solutions efficiently and in polynomial time for any $\ell_p$ approximation error. Based on these results, we propose a novel method for piecewise-linear fitting of convex multivariate functions, with optimality guarantees for the model parameters and an approximately minimum number of affine regions.
Exploring the Impact of Tunable Agents in Sequential Social Dilemmas
Jan 28, 2021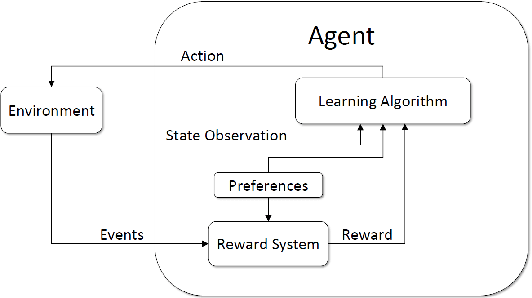
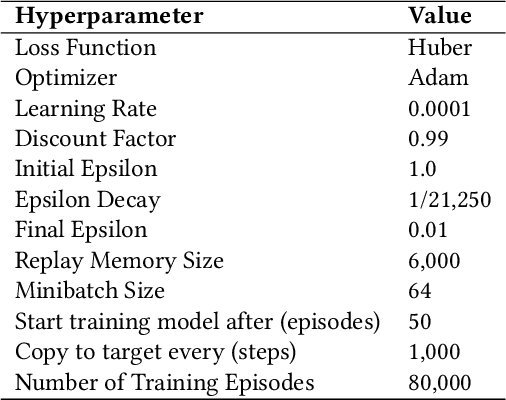
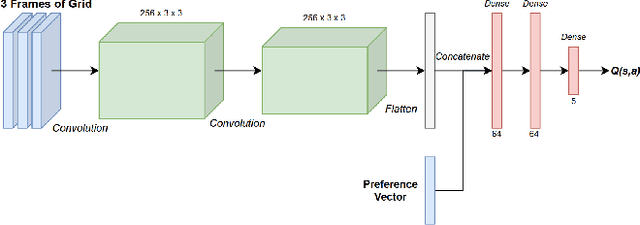

When developing reinforcement learning agents, the standard approach is to train an agent to converge to a fixed policy that is as close to optimal as possible for a single fixed reward function. If different agent behaviour is required in the future, an agent trained in this way must normally be either fully or partially retrained, wasting valuable time and resources. In this study, we leverage multi-objective reinforcement learning to create tunable agents, i.e. agents that can adopt a range of different behaviours according to the designer's preferences, without the need for retraining. We apply this technique to sequential social dilemmas, settings where there is inherent tension between individual and collective rationality. Learning a single fixed policy in such settings leaves one at a significant disadvantage if the opponents' strategies change after learning is complete. In our work, we demonstrate empirically that the tunable agents framework allows easy adaption between cooperative and competitive behaviours in sequential social dilemmas without the need for retraining, allowing a single trained agent model to be adjusted to cater for a wide range of behaviours and opponent strategies.
Trajectory Planning for Autonomous Vehicles Using Hierarchical Reinforcement Learning
Nov 09, 2020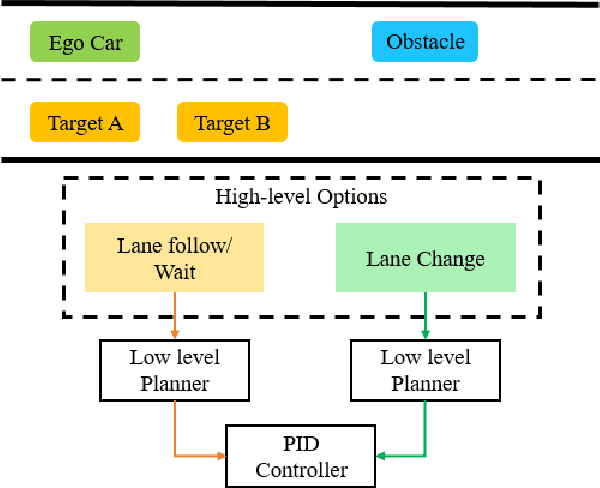
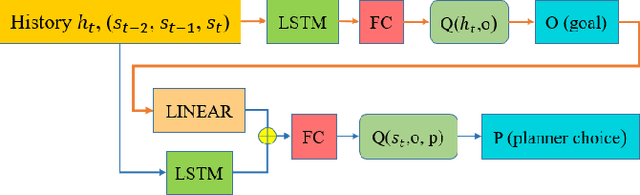
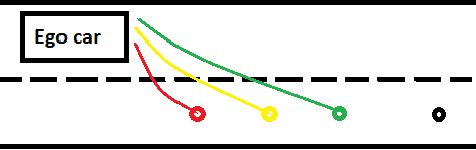
Planning safe trajectories under uncertain and dynamic conditions makes the autonomous driving problem significantly complex. Current sampling-based methods such as Rapidly Exploring Random Trees (RRTs) are not ideal for this problem because of the high computational cost. Supervised learning methods such as Imitation Learning lack generalization and safety guarantees. To address these problems and in order to ensure a robust framework, we propose a Hierarchical Reinforcement Learning (HRL) structure combined with a Proportional-Integral-Derivative (PID) controller for trajectory planning. HRL helps divide the task of autonomous vehicle driving into sub-goals and supports the network to learn policies for both high-level options and low-level trajectory planner choices. The introduction of sub-goals decreases convergence time and enables the policies learned to be reused for other scenarios. In addition, the proposed planner is made robust by guaranteeing smooth trajectories and by handling the noisy perception system of the ego-car. The PID controller is used for tracking the waypoints, which ensures smooth trajectories and reduces jerk. The problem of incomplete observations is handled by using a Long-Short-Term-Memory (LSTM) layer in the network. Results from the high-fidelity CARLA simulator indicate that the proposed method reduces convergence time, generates smoother trajectories, and is able to handle dynamic surroundings and noisy observations.
Modeling Wildfire Perimeter Evolution using Deep Neural Networks
Sep 08, 2020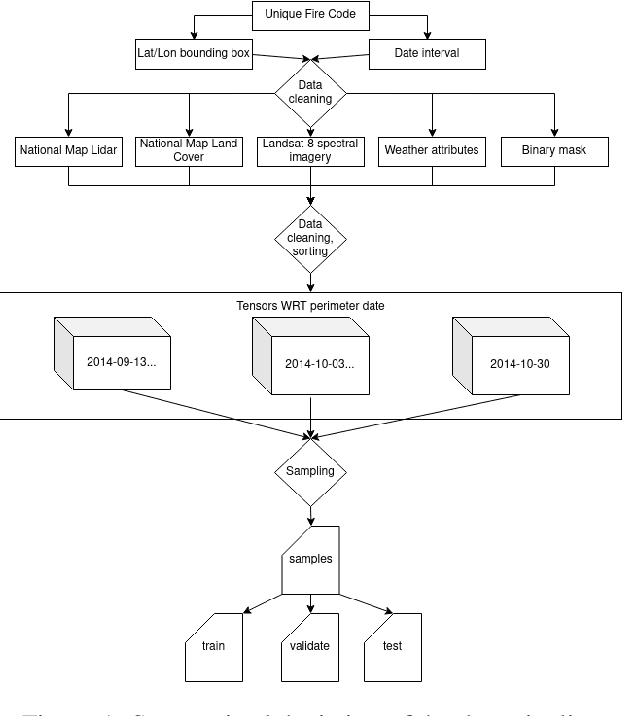
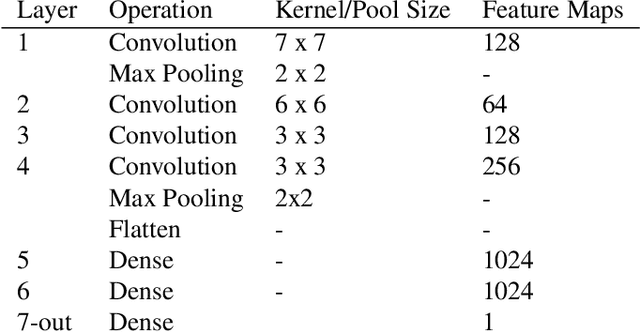

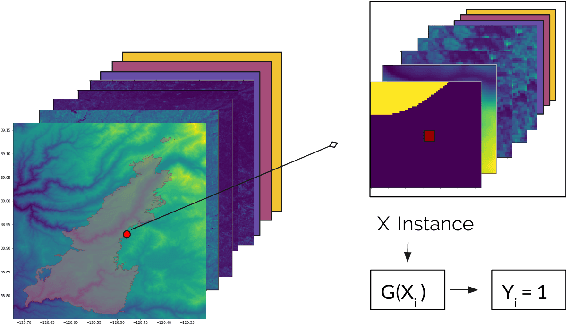
With the increased size and frequency of wildfire eventsworldwide, accurate real-time prediction of evolving wildfirefronts is a crucial component of firefighting efforts and for-est management practices. We propose a wildfire spreadingmodel that predicts the evolution of the wildfire perimeter in24 hour periods. The fire spreading simulation is based ona deep convolutional neural network (CNN) that is trainedon remotely sensed atmospheric and environmental time se-ries data. We show that the model is able to learn wildfirespreading dynamics from real historic data sets from a seriesof wildfires in the Western Sierra Nevada Mountains in Cal-ifornia. We validate the model on a previously unseen wild-fire and produce realistic results that significantly outperformhistoric alternatives with validation accuracies ranging from78% - 98%
Network Support for High-performance Distributed Machine Learning
Feb 05, 2021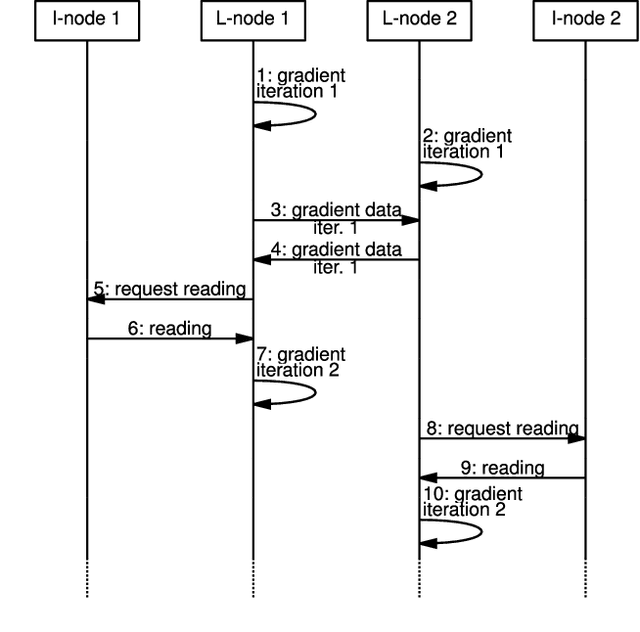

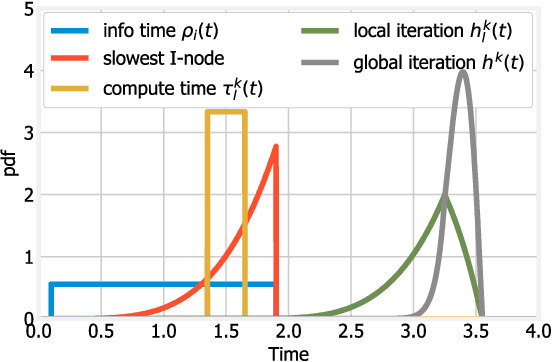
The traditional approach to distributed machine learning is to adapt learning algorithms to the network, e.g., reducing updates to curb overhead. Networks based on intelligent edge, instead, make it possible to follow the opposite approach, i.e., to define the logical network topology em around the learning task to perform, so as to meet the desired learning performance. In this paper, we propose a system model that captures such aspects in the context of supervised machine learning, accounting for both learning nodes (that perform computations) and information nodes (that provide data). We then formulate the problem of selecting (i) which learning and information nodes should cooperate to complete the learning task, and (ii) the number of iterations to perform, in order to minimize the learning cost while meeting the target prediction error and execution time. After proving important properties of the above problem, we devise an algorithm, named DoubleClimb, that can find a 1+1/|I|-competitive solution (with I being the set of information nodes), with cubic worst-case complexity. Our performance evaluation, leveraging a real-world network topology and considering both classification and regression tasks, also shows that DoubleClimb closely matches the optimum, outperforming state-of-the-art alternatives.
Environmental Sound Classification on the Edge: Deep Acoustic Networks for Extremely Resource-Constrained Devices
Mar 05, 2021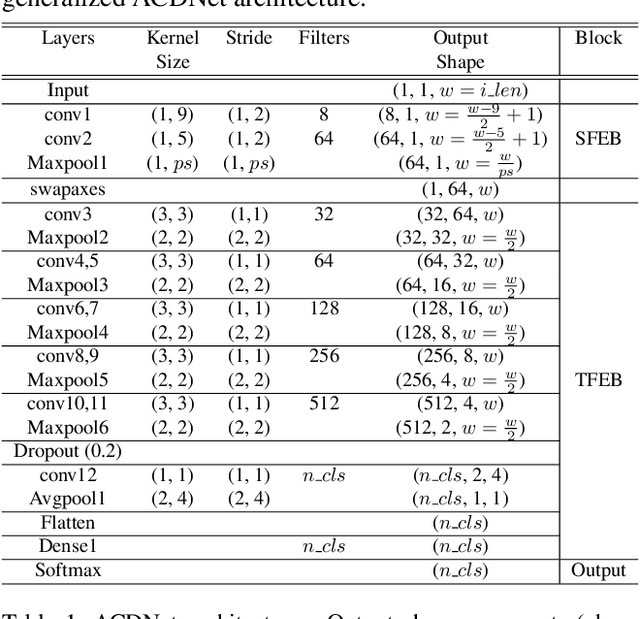
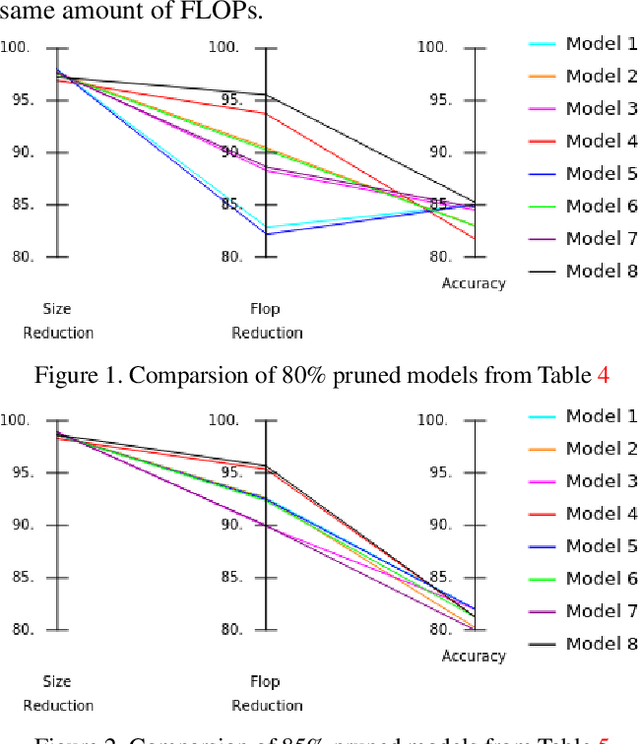
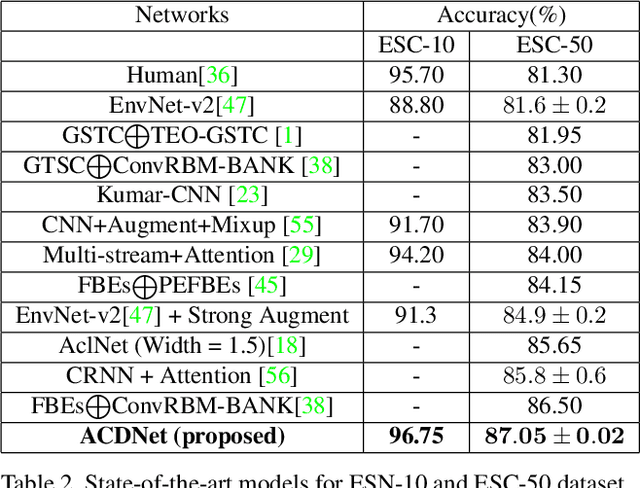
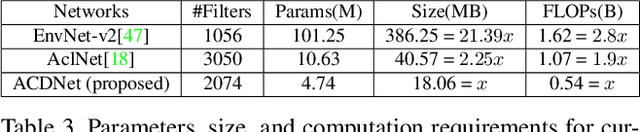
Significant efforts are being invested to bring the classification and recognition powers of desktop and cloud systemsdirectly to edge devices. The main challenge for deep learning on the edge is to handle extreme resource constraints(memory, CPU speed and lack of GPU support). We present an edge solution for audio classification that achieves close to state-of-the-art performance on ESC-50, the same benchmark used to assess large, non resource-constrained networks. Importantly, we do not specifically engineer thenetwork for edge devices. Rather, we present a universalpipeline that converts a large deep convolutional neuralnetwork (CNN) automatically via compression and quantization into a network suitable for resource-impoverishededge devices. We first introduce a new sound classification architecture, ACDNet, that produces above state-of-the-art accuracy on both ESC-10 and ESC-50 which are 96.75% and 87.05% respectively. We then compress ACDNet using a novel network-independent approach to obtain an extremely small model. Despite 97.22% size reduction and 97.28% reduction in FLOPs, the compressed network still achieves 82.90% accuracy on ESC-50, staying close to the state-of-the-art. Using 8-bit quantization, we deploy ACD-Net on standard microcontroller units (MCUs). To the best of our knowledge, this is the first time that a deep network for sound classification of 50 classes has successfully been deployed on an edge device. While this should be of interestin its own right, we believe it to be of particular impor-tance that this has been achieved with a universal conver-sion pipeline rather than hand-crafting a network for mini-mal size.
Behavior of linear L2-boosting algorithms in the vanishing learning rate asymptotic
Dec 29, 2020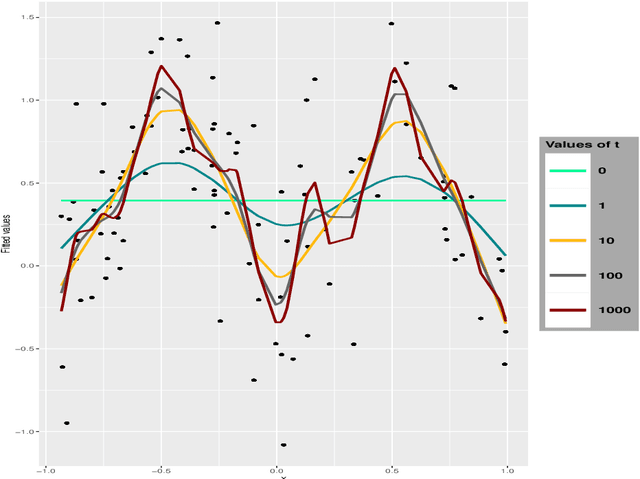
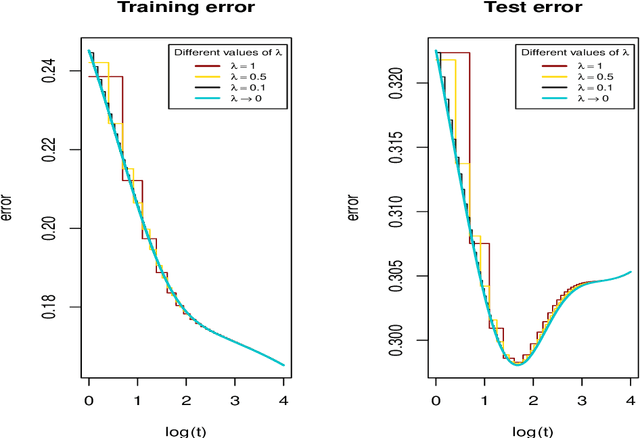
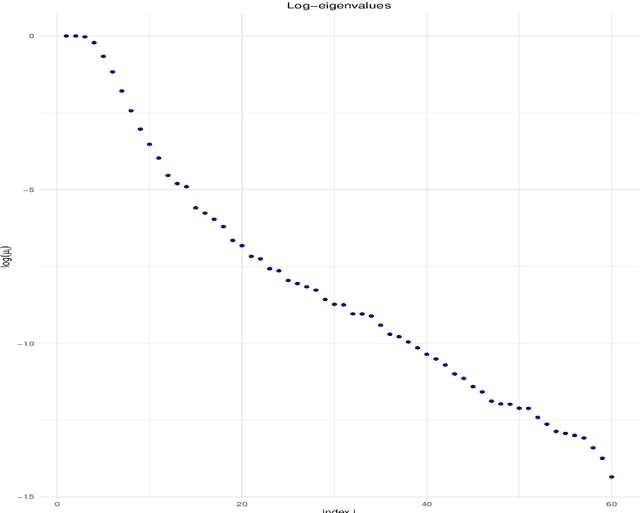
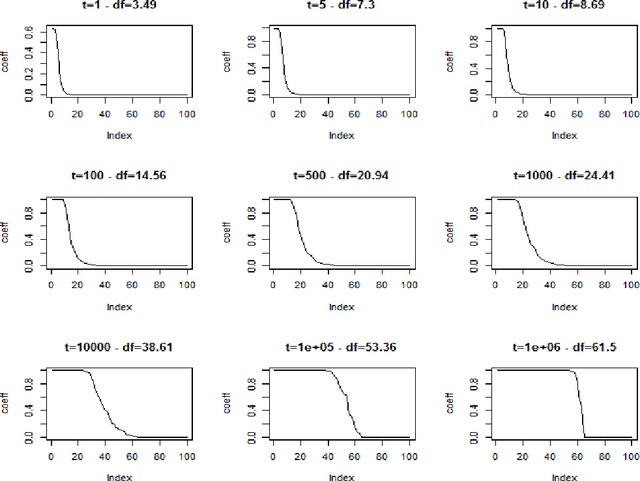
We investigate the asymptotic behaviour of gradient boosting algorithms when the learning rate converges to zero and the number of iterations is rescaled accordingly. We mostly consider L2-boosting for regression with linear base learner as studied in B{\"u}hlmann and Yu (2003) and analyze also a stochastic version of the model where subsampling is used at each step (Friedman 2002). We prove a deterministic limit in the vanishing learning rate asymptotic and characterize the limit as the unique solution of a linear differential equation in an infinite dimensional function space. Besides, the training and test error of the limiting procedure are thoroughly analyzed. We finally illustrate and discuss our result on a simple numerical experiment where the linear L2-boosting operator is interpreted as a smoothed projection and time is related to its number of degrees of freedom.
GPSPiChain-Blockchain based Self-Contained Family Security System in Smart Home
Feb 13, 2021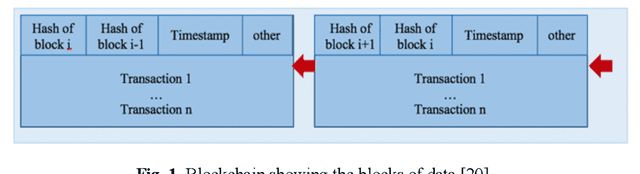
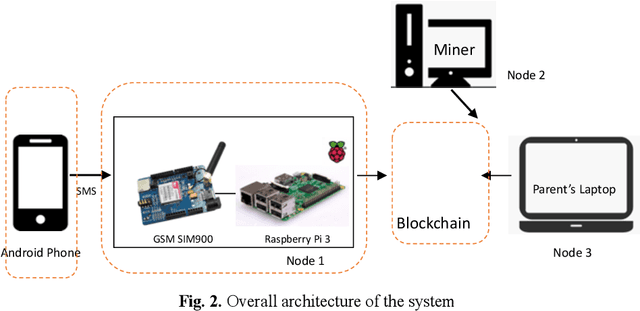
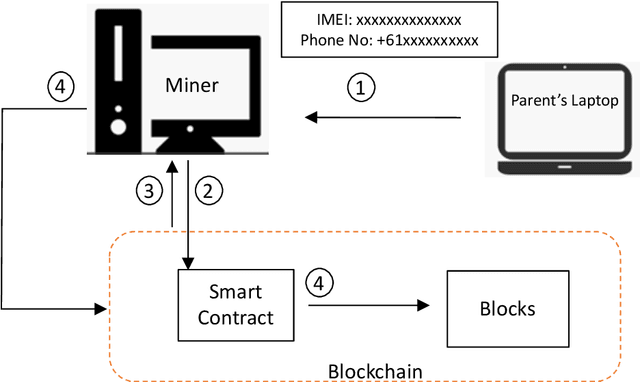
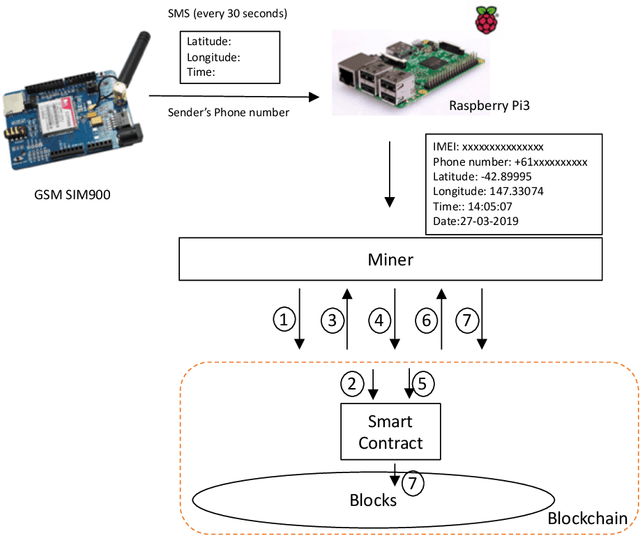
With advancements in technology, personal computing devices are better adapted for and further integrated into people's lives and homes. The integration of technology into society also results in an increasing desire to control who and what has access to sensitive information, especially for vulnerable people including children and the elderly. With blockchain coming in to the picture as a technology that can revolutionise the world, it is now possible to have an immutable audit trail of locational data over time. By controlling the process through inexpensive equipment in the home, it is possible to control whom has access to such personal data. This paper presents a blockchain based family security system for tracking the location of consenting family members' smart phones. The locations of the family members' smart phones are logged and stored in a private blockchain which can be accessed through a node installed in the family home on a computer. The data for the whereabouts of family members stays within the family unit and does not go to any third party. The system is implemented in a small scale (one miner and two other nodes) and the technical feasibility is discussed along with the limitations of the system. Further research will cover the integration of the system into a smart home environment, and ethical implementations of tracking, especially of vulnerable people, using the immutability of blockchain.