 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning transition times in event sequences: the Event-Based Hidden Markov Model of disease progression
Nov 02, 2020
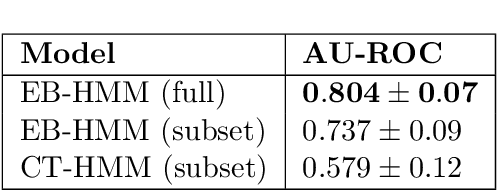
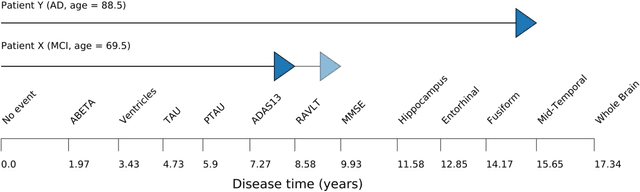
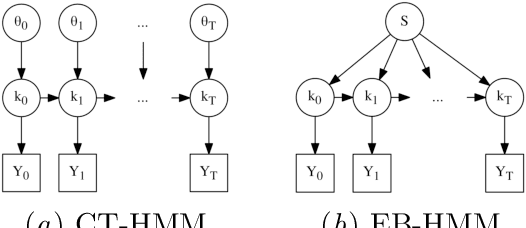
Progressive diseases worsen over time and are characterised by monotonic change in features that track disease progression. Here we connect ideas from two formerly separate methodologies -- event-based and hidden Markov modelling -- to derive a new generative model of disease progression. Our model can uniquely infer the most likely group-level sequence and timing of events (natural history) from limited datasets. Moreover, it can infer and predict individual-level trajectories (prognosis) even when data are missing, giving it high clinical utility. Here we derive the model and provide an inference scheme based on the expectation maximisation algorithm. We use clinical, imaging and biofluid data from the Alzheimer's Disease Neuroimaging Initiative to demonstrate the validity and utility of our model. First, we train our model to uncover a new group-level sequence of feature changes in Alzheimer's disease over a period of ${\sim}17.3$ years. Next, we demonstrate that our model provides improved utility over a continuous time hidden Markov model by area under the receiver operator characteristic curve ${\sim}0.23$. Finally, we demonstrate that our model maintains predictive accuracy with up to $50\%$ missing data. These results support the clinical validity of our model and its broader utility in resource-limited medical applications.
Non-Parametric Adaptive Network Pruning
Jan 20, 2021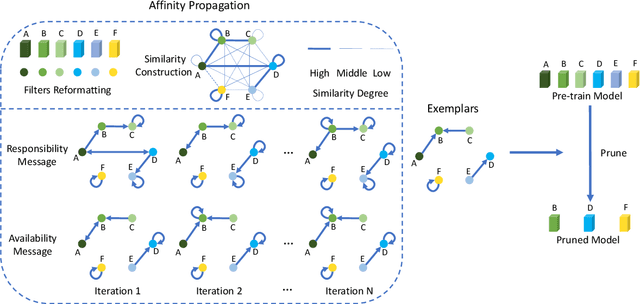
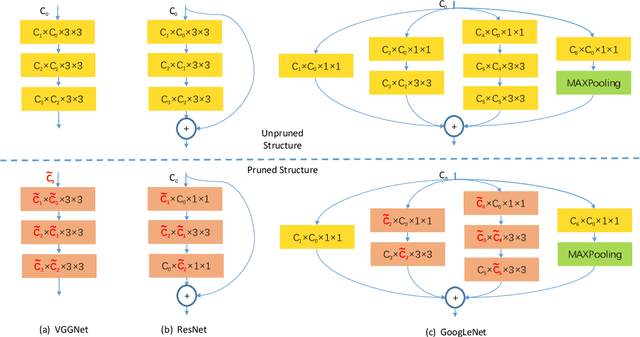
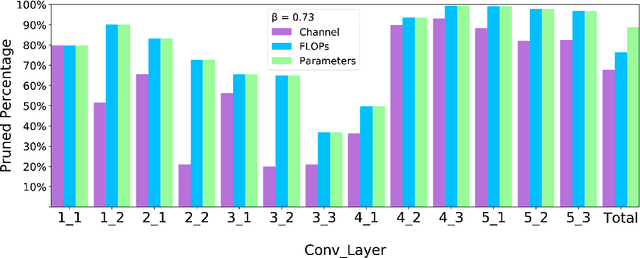
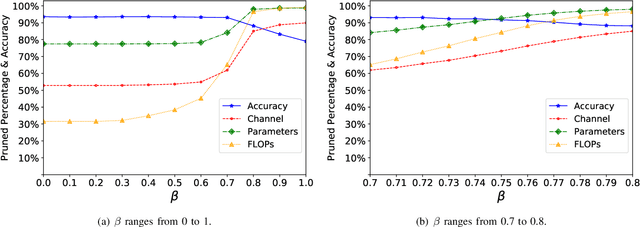
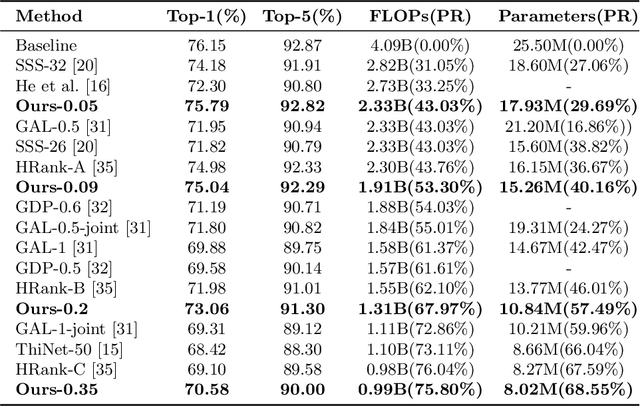
Popular network pruning algorithms reduce redundant information by optimizing hand-crafted parametric models, and may cause suboptimal performance and long time in selecting filters. We innovatively introduce non-parametric modeling to simplify the algorithm design, resulting in an automatic and efficient pruning approach called EPruner. Inspired by the face recognition community, we use a message passing algorithm Affinity Propagation on the weight matrices to obtain an adaptive number of exemplars, which then act as the preserved filters. EPruner breaks the dependency on the training data in determining the "important" filters and allows the CPU implementation in seconds, an order of magnitude faster than GPU based SOTAs. Moreover, we show that the weights of exemplars provide a better initialization for the fine-tuning. On VGGNet-16, EPruner achieves a 76.34%-FLOPs reduction by removing 88.80% parameters, with 0.06% accuracy improvement on CIFAR-10. In ResNet-152, EPruner achieves a 65.12%-FLOPs reduction by removing 64.18% parameters, with only 0.71% top-5 accuracy loss on ILSVRC-2012. Code can be available at https://github.com/lmbxmu/EPruner.
Offer Personalization using Temporal Convolution Network and Optimization
Oct 14, 2020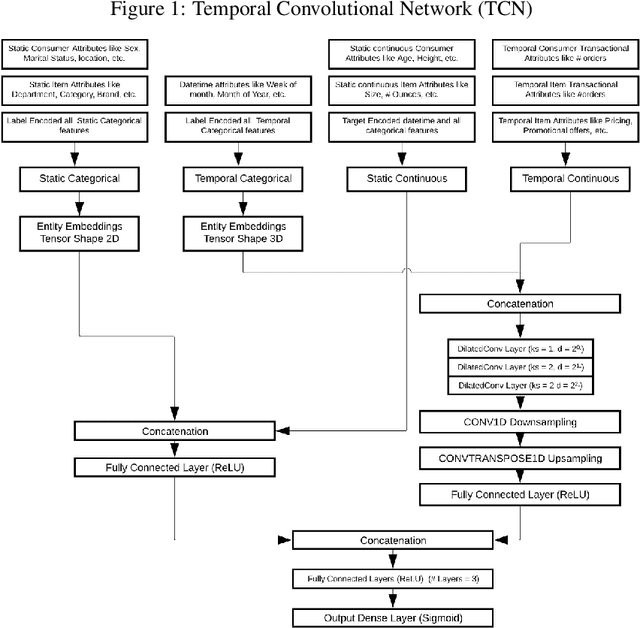
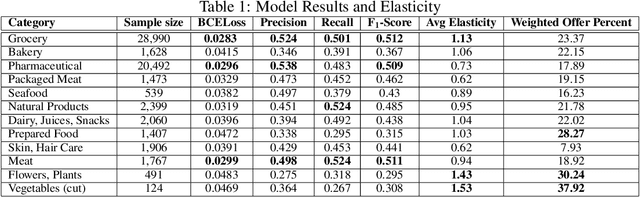
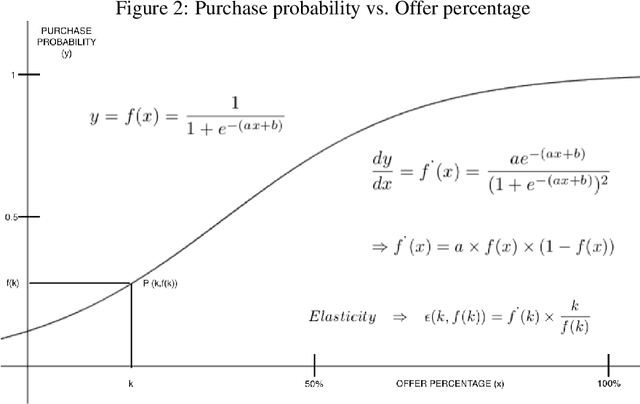
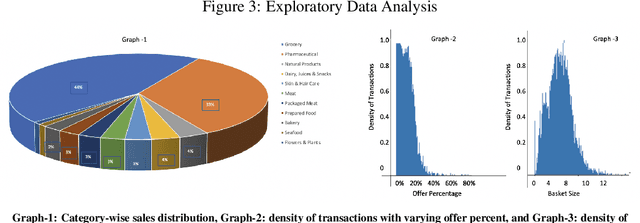
Lately, personalized marketing has become important for retail/e-retail firms due to significant rise in online shopping and market competition. Increase in online shopping and high market competition has led to an increase in promotional expenditure for online retailers, and hence, rolling out optimal offers has become imperative to maintain balance between number of transactions and profit. In this paper, we propose our approach to solve the offer optimization problem at the intersection of consumer, item and time in retail setting. To optimize offer, we first build a generalized non-linear model using Temporal Convolutional Network to predict the item purchase probability at consumer level for the given time period. Secondly, we establish the functional relationship between historical offer values and purchase probabilities obtained from the model, which is then used to estimate offer-elasticity of purchase probability at consumer item granularity. Finally, using estimated elasticities, we optimize offer values using constraint based optimization technique. This paper describes our detailed methodology and presents the results of modelling and optimization across categories.
Localizing Unsynchronized Sensors with Unknown Sources
Feb 06, 2021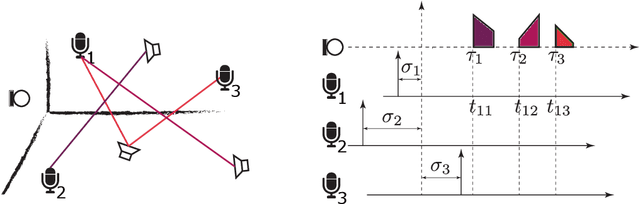
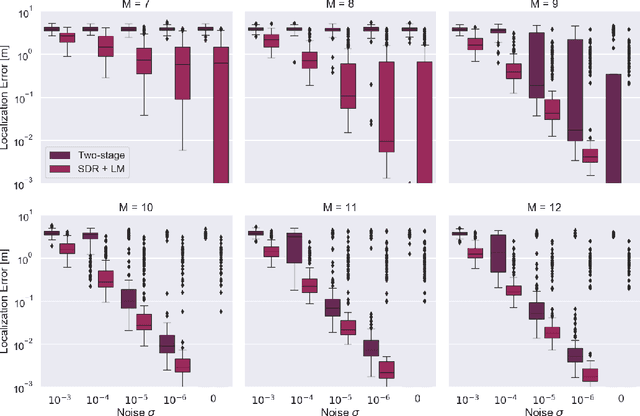
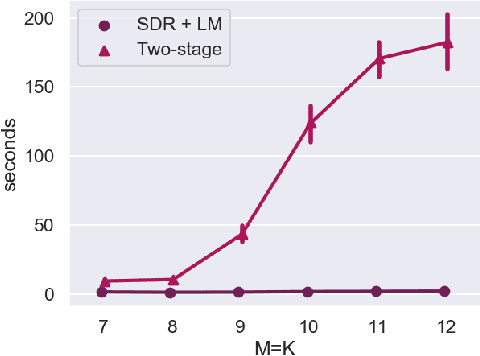
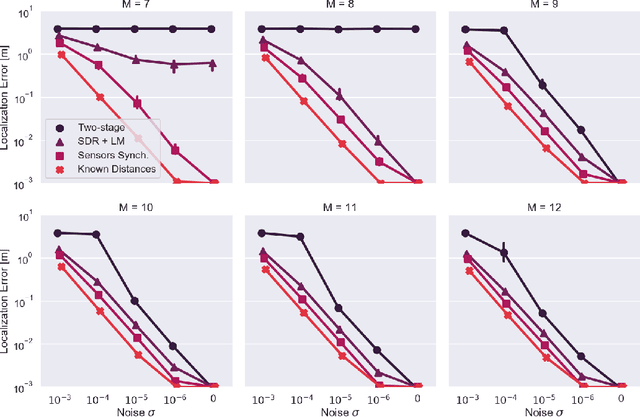
We propose a method for sensor array self-localization using a set of sources at unknown locations. The sources produce signals whose times of arrival are registered at the sensors. We look at the general case where neither the emission times of the sources nor the reference time frames of the receivers are known. Unlike previous work, our method directly recovers the array geometry, instead of first estimating the timing information. The key component is a new loss function which is insensitive to the unknown timings. We cast the problem as a minimization of a non-convex functional of the Euclidean distance matrix of microphones and sources subject to certain non-convex constraints. After convexification, we obtain a semidefinite relaxation which gives an approximate solution; subsequent refinement on the proposed loss via the Levenberg-Marquardt scheme gives the final locations. Our method achieves state-of-the-art performance in terms of reconstruction accuracy, speed, and the ability to work with a small number of sources and receivers. It can also handle missing measurements and exploit prior geometric and temporal knowledge, for example if either the receiver offsets or the emission times are known, or if the array contains compact subarrays with known geometry.
The Orientation Estimation of Elongated Underground Objects via Multi-Polarization Aggregation and Selection Neural Network
Jan 29, 2021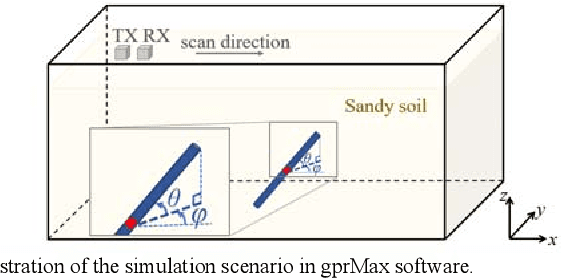
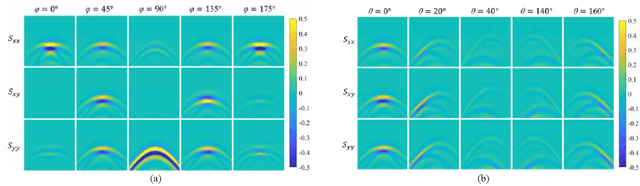
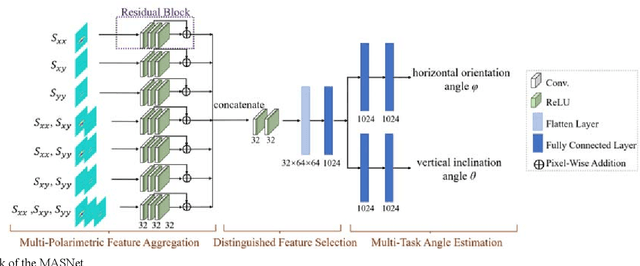
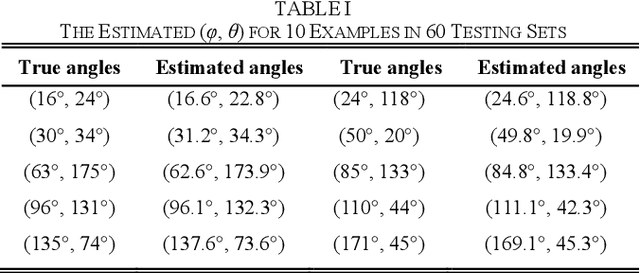
The horizontal orientation angle and vertical inclination angle of an elongated subsurface object are key parameters for object identification and imaging in ground penetration radar (GPR) applications. Conventional methods can only extract the horizontal orientation angle or estimate both angles in narrow ranges due to limited polarimetric information and detection capability. To address these issues, this letter, for the first time, explores the possibility of leveraging neural networks with multi-polarimetric GPR data to estimate both angles of an elongated subsurface object in the entire spatial range. Based on the polarization-sensitive characteristic of an elongated object, we propose a multi-polarization aggregation and selection neural network (MASNet), which takes the multi-polarimetric radargrams as inputs, integrates their characteristics in the feature space, and selects discriminative features of reflected signal patterns for accurate orientation estimation. Numerical results show that our proposed MASNet achieves high estimation accuracy with an angle estimation error of less than 5{\deg}, which outperforms conventional methods by a large margin. The promising results obtained by the proposed method encourages one to think of new solutions for GPR related tasks by integrating multi-polarization information with deep learning techniques.
A framework for reinforcement learning with autocorrelated actions
Sep 10, 2020
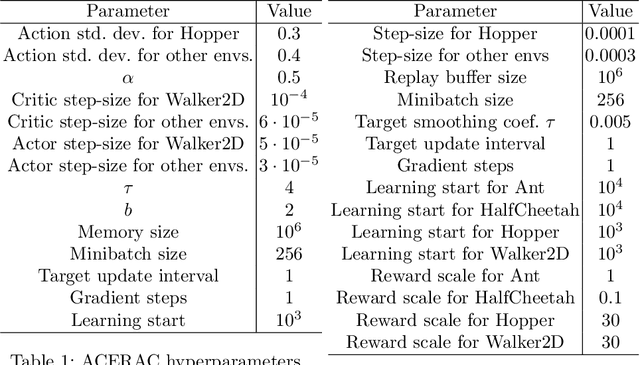
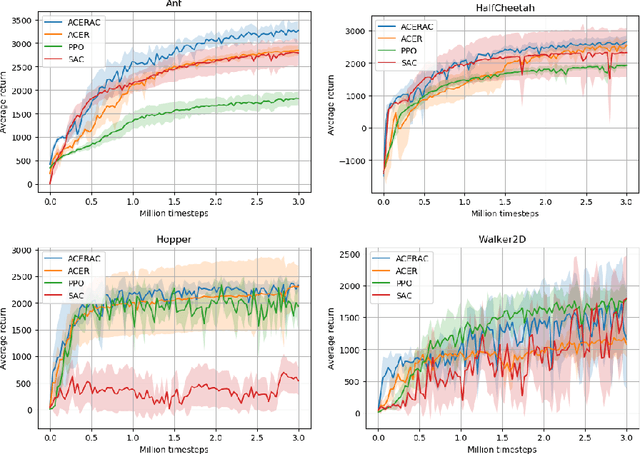
The subject of this paper is reinforcement learning. Policies are considered here that produce actions based on states and random elements autocorrelated in subsequent time instants. Consequently, an agent learns from experiments that are distributed over time and potentially give better clues to policy improvement. Also, physical implementation of such policies, e.g. in robotics, is less problematic, as it avoids making robots shake. This is in opposition to most RL algorithms which add white noise to control causing unwanted shaking of the robots. An algorithm is introduced here that approximately optimizes the aforementioned policy. Its efficiency is verified for four simulated learning control problems (Ant, HalfCheetah, Hopper, and Walker2D) against three other methods (PPO, SAC, ACER). The algorithm outperforms others in three of these problems.
TriFinger: An Open-Source Robot for Learning Dexterity
Aug 08, 2020



Dexterous object manipulation remains an open problem in robotics, despite the rapid progress in machine learning during the past decade. We argue that a hindrance is the high cost of experimentation on real systems, in terms of both time and money. We address this problem by proposing an open-source robotic platform which can safely operate without human supervision. The hardware is inexpensive (about \SI{5000}[\$]{}) yet highly dynamic, robust, and capable of complex interaction with external objects. The software operates at 1-kilohertz and performs safety checks to prevent the hardware from breaking. The easy-to-use front-end (in C++ and Python) is suitable for real-time control as well as deep reinforcement learning. In addition, the software framework is largely robot-agnostic and can hence be used independently of the hardware proposed herein. Finally, we illustrate the potential of the proposed platform through a number of experiments, including real-time optimal control, deep reinforcement learning from scratch, throwing, and writing.
Towards Optimal Filter Pruning with Balanced Performance and Pruning Speed
Oct 14, 2020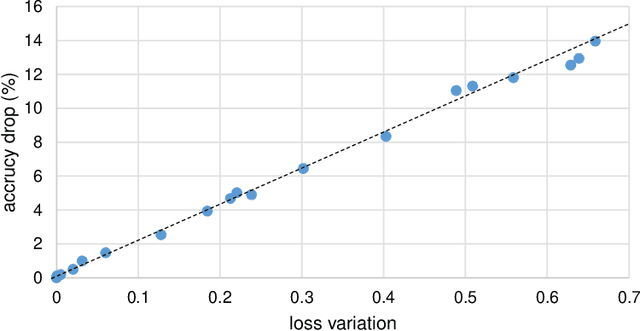

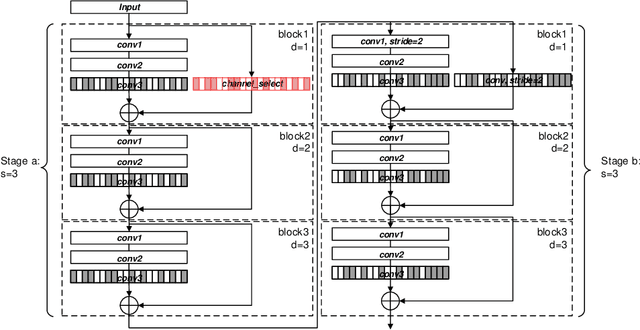
Filter pruning has drawn more attention since resource constrained platform requires more compact model for deployment. However, current pruning methods suffer either from the inferior performance of one-shot methods, or the expensive time cost of iterative training methods. In this paper, we propose a balanced filter pruning method for both performance and pruning speed. Based on the filter importance criteria, our method is able to prune a layer with approximate layer-wise optimal pruning rate at preset loss variation. The network is pruned in the layer-wise way without the time consuming prune-retrain iteration. If a pre-defined pruning rate for the entire network is given, we also introduce a method to find the corresponding loss variation threshold with fast converging speed. Moreover, we propose the layer group pruning and channel selection mechanism for channel alignment in network with short connections. The proposed pruning method is widely applicable to common architectures and does not involve any additional training except the final fine-tuning. Comprehensive experiments show that our method outperforms many state-of-the-art approaches.
Machine Learning enables Ultra-Compact Integrated Photonics through Silicon-Nanopattern Digital Metamaterials
Nov 27, 2020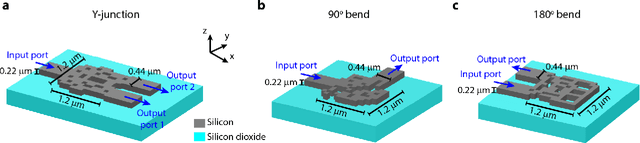
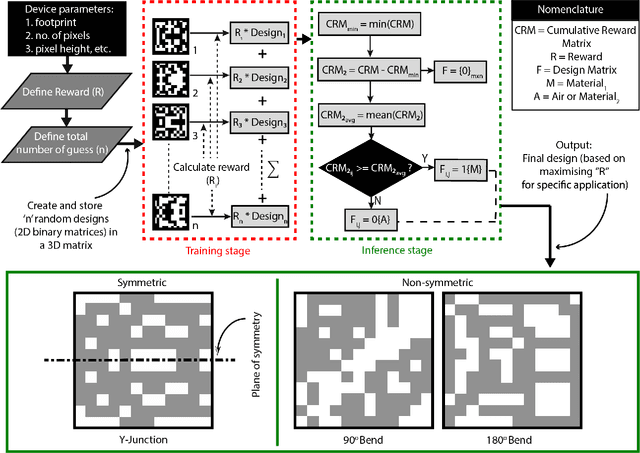
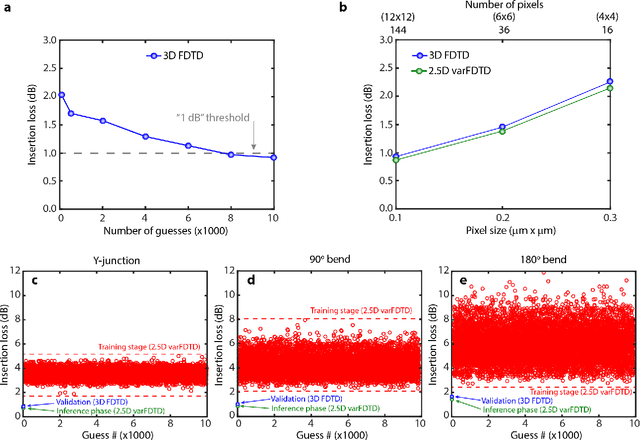
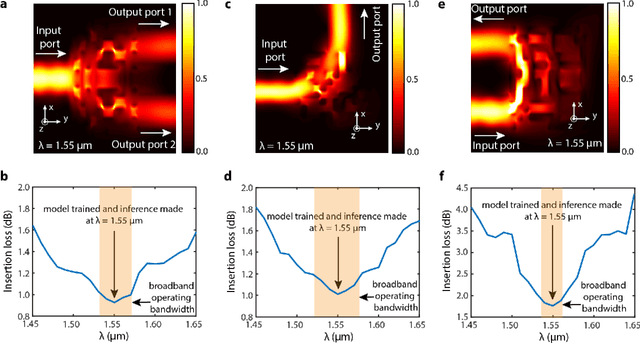
In this work, we demonstrate three ultra-compact integrated-photonics devices, which are designed via a machine-learning algorithm coupled with finite-difference time-domain (FDTD) modeling. Through digitizing the design domain into "binary pixels" these digital metamaterials are readily manufacturable as well. By showing a variety of devices (beamsplitters and waveguide bends), we showcase the generality of our approach. With an area footprint smaller than ${\lambda_0}^2$, our designs are amongst the smallest reported to-date. Our method combines machine learning with digital metamaterials to enable ultra-compact, manufacturable devices, which could power a new "Photonics Moore's Law."
Matrix Completion from $O(n)$ Samples in Linear Time
Aug 22, 2017
We consider the problem of reconstructing a rank-$k$ $n \times n$ matrix $M$ from a sampling of its entries. Under a certain incoherence assumption on $M$ and for the case when both the rank and the condition number of $M$ are bounded, it was shown in \cite{CandesRecht2009, CandesTao2010, keshavan2010, Recht2011, Jain2012, Hardt2014} that $M$ can be recovered exactly or approximately (depending on some trade-off between accuracy and computational complexity) using $O(n \, \text{poly}(\log n))$ samples in super-linear time $O(n^{a} \, \text{poly}(\log n))$ for some constant $a \geq 1$. In this paper, we propose a new matrix completion algorithm using a novel sampling scheme based on a union of independent sparse random regular bipartite graphs. We show that under the same conditions w.h.p. our algorithm recovers an $\epsilon$-approximation of $M$ in terms of the Frobenius norm using $O(n \log^2(1/\epsilon))$ samples and in linear time $O(n \log^2(1/\epsilon))$. This provides the best known bounds both on the sample complexity and computational complexity for reconstructing (approximately) an unknown low-rank matrix. The novelty of our algorithm is two new steps of thresholding singular values and rescaling singular vectors in the application of the "vanilla" alternating minimization algorithm. The structure of sparse random regular graphs is used heavily for controlling the impact of these regularization steps.