 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Artificial Intelligence Advances for De Novo Molecular Structure Modeling in Cryo-EM
Feb 24, 2021
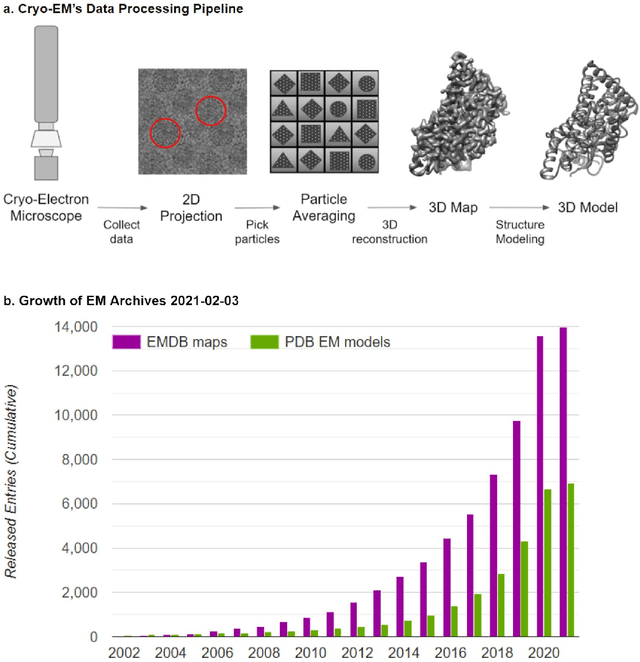
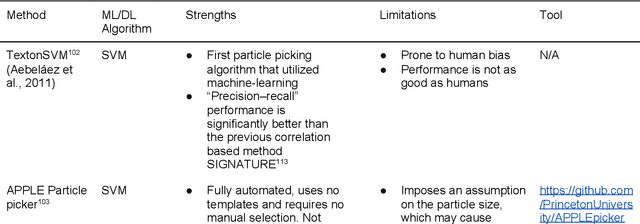


Cryo-electron microscopy (cryo-EM) has become a major experimental technique to determine the structures of large protein complexes and molecular assemblies, as evidenced by the 2017 Nobel Prize. Although cryo-EM has been drastically improved to generate high-resolution three-dimensional (3D) maps that contain detailed structural information about macromolecules, the computational methods for using the data to automatically build structure models are lagging far behind. The traditional cryo-EM model building approach is template-based homology modeling. Manual de novo modeling is very time-consuming when no template model is found in the database. In recent years, de novo cryo-EM modeling using machine learning (ML) and deep learning (DL) has ranked among the top-performing methods in macromolecular structure modeling. Deep-learning-based de novo cryo-EM modeling is an important application of artificial intelligence, with impressive results and great potential for the next generation of molecular biomedicine. Accordingly, we systematically review the representative ML/DL-based de novo cryo-EM modeling methods. And their significances are discussed from both practical and methodological viewpoints. We also briefly describe the background of cryo-EM data processing workflow. Overall, this review provides an introductory guide to modern research on artificial intelligence (AI) for de novo molecular structure modeling and future directions in this emerging field.
Deep Learning for Moving Blockage Prediction using Real Millimeter Wave Measurements
Feb 08, 2021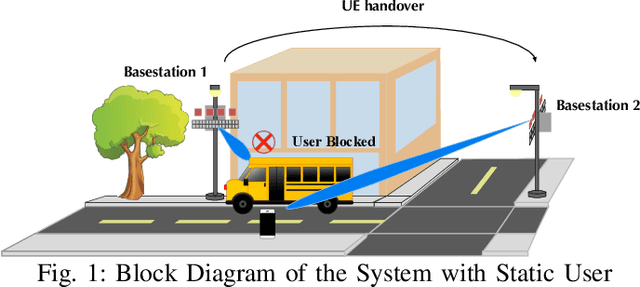
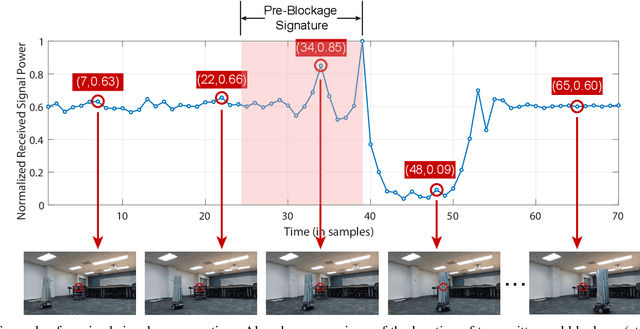
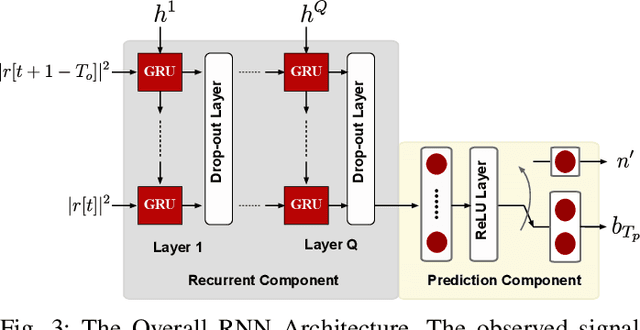

Millimeter wave (mmWave) communication is a key component of 5G and beyond. Harvesting the gains of the large bandwidth and low latency at mmWave systems, however, is challenged by the sensitivity of mmWave signals to blockages; a sudden blockage in the line of sight (LOS) link leads to abrupt disconnection, which affects the reliability of the network. In addition, searching for an alternative base station to re-establish the link could result in needless latency overhead. In this paper, we address these challenges collectively by utilizing machine learning to anticipate dynamic blockages proactively. The proposed approach sees a machine learning algorithm learning to predict future blockages by observing what we refer to as the pre-blockage signature. To evaluate our proposed approach, we build a mmWave communication setup with a moving blockage and collect a dataset of received power sequences. Simulation results on a real dataset show that blockage occurrence could be predicted with more than 85% accuracy and the exact time instance of blockage occurrence can be obtained with low error. This highlights the potential of the proposed solution for dynamic blockage prediction and proactive hand-off, which enhances the reliability and latency of future wireless networks.
Learning the Noise of Failure: Intelligent System Tests for Robots
Feb 16, 2021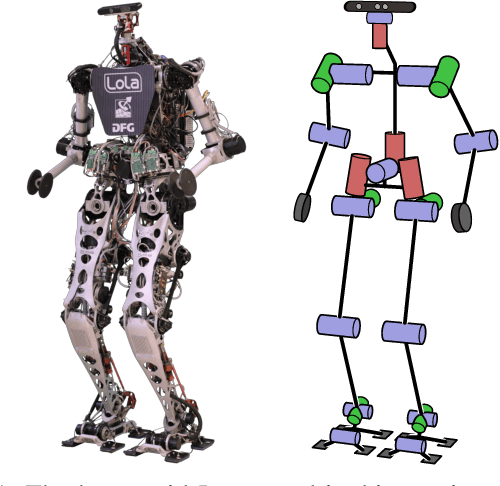
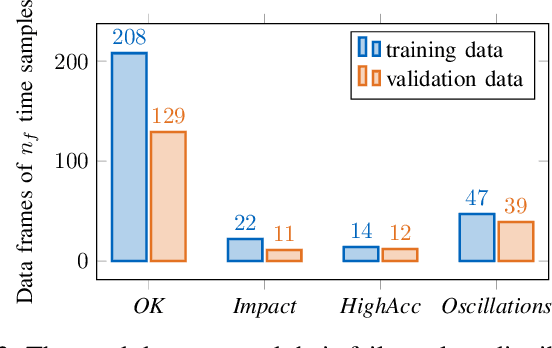
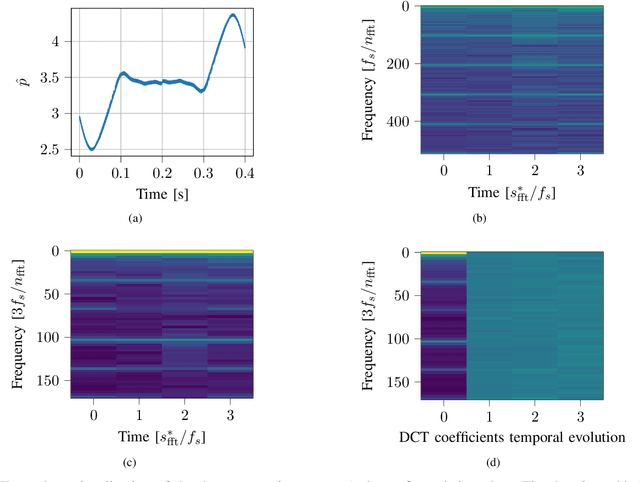
Roboticists usually test new control software in simulation environments before evaluating its functionality on real-world robots. Simulations reduce the risk of damaging the hardware and can significantly increase the development process's efficiency in the form of automated system tests. However, many flaws in the software remain undetected in simulation data, revealing their harmful effects on the system only in time-consuming experiments. In reality, such irregularities are often easily recognized solely by the robot's airborne noise during operation. We propose a simulated noise estimate for the detection of failures in automated system tests of robots. The classification of flaws uses classical machine learning - a support vector machine - to identify different failure classes from the scalar noise estimate. The methodology is evaluated on simulation data from the humanoid robot LOLA. The approach yields high failure detection accuracy with a low false-positive rate, enabling its use for stricter automated system tests. Results indicate that a single trained model may work for different robots. The proposed technique is provided to the community in the form of the open-source tool NoisyTest, making it easy to test data from any robot. In a broader scope, the technique may empower real-world automated system tests without human evaluation of success or failure.
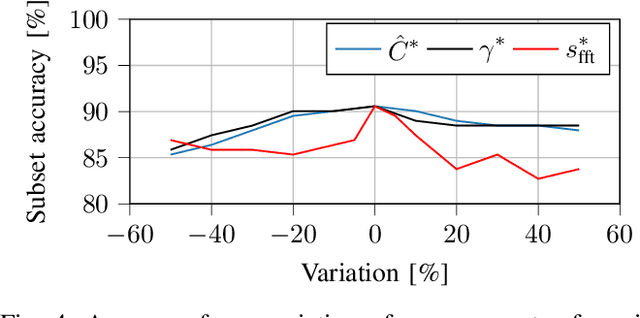
tf.data: A Machine Learning Data Processing Framework
Feb 23, 2021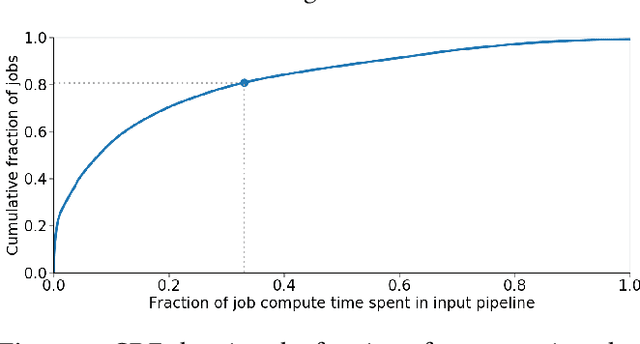

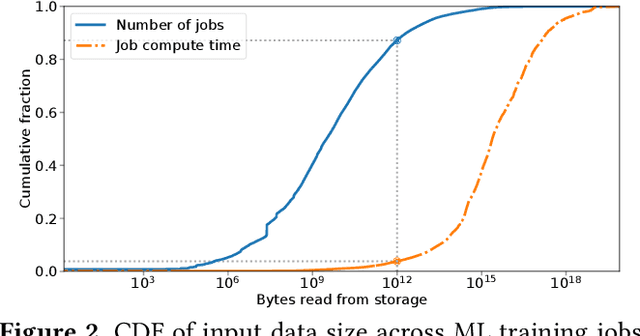
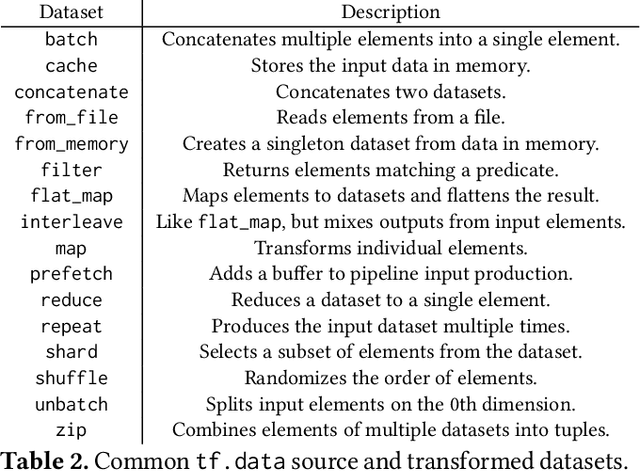
Training machine learning models requires feeding input data for models to ingest. Input pipelines for machine learning jobs are often challenging to implement efficiently as they require reading large volumes of data, applying complex transformations, and transferring data to hardware accelerators while overlapping computation and communication to achieve optimal performance. We present tf.data, a framework for building and executing efficient input pipelines for machine learning jobs. The tf.data API provides operators which can be parameterized with user-defined computation, composed, and reused across different machine learning domains. These abstractions allow users to focus on the application logic of data processing, while tf.data's runtime ensures that pipelines run efficiently. We demonstrate that input pipeline performance is critical to the end-to-end training time of state-of-the-art machine learning models. tf.data delivers the high performance required, while avoiding the need for manual tuning of performance knobs. We show that tf.data features, such as parallelism, caching, static optimizations, and non-deterministic execution are essential for high performance. Finally, we characterize machine learning input pipelines for millions of jobs that ran in Google's fleet, showing that input data processing is highly diverse and consumes a significant fraction of job resources. Our analysis motivates future research directions, such as sharing computation across jobs and pushing data projection to the storage layer.
When Shall I Be Empathetic? The Utility of Empathetic Parameter Estimation in Multi-Agent Interactions
Nov 03, 2020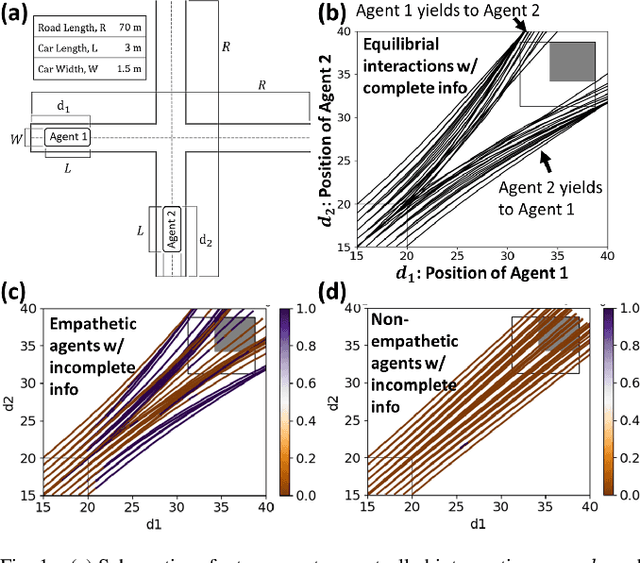
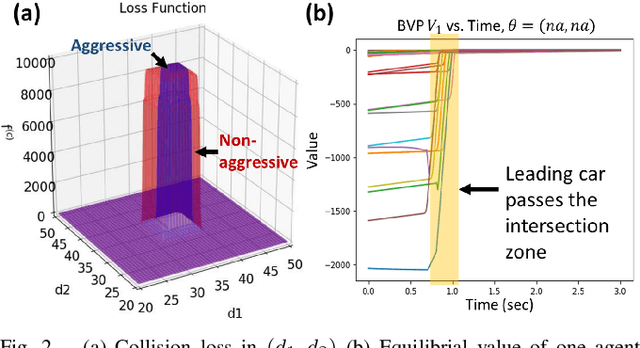
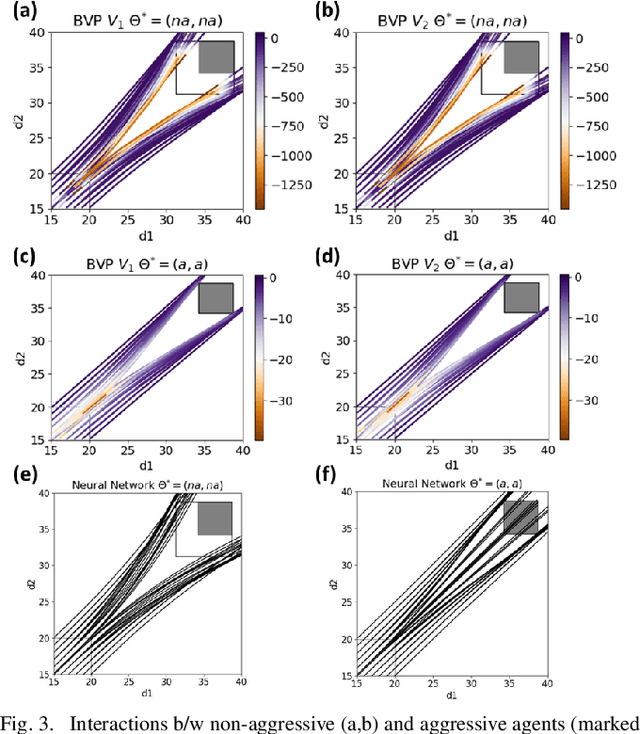
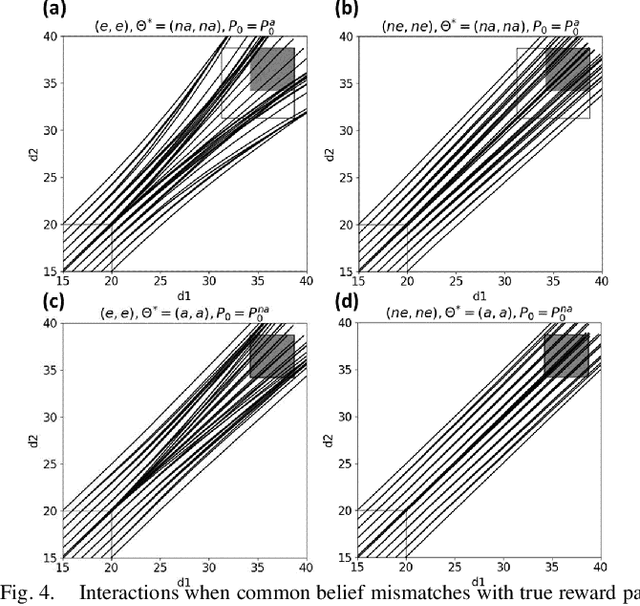
Human-robot interactions (HRI) can be modeled as dynamic or differential games with incomplete information, where each agent holds private reward parameters. Due to the open challenge in finding perfect Bayesian equilibria of such games, existing studies often consider approximated solutions composed of parameter estimation and motion planning steps, in order to decouple the belief and physical dynamics. In parameter estimation, current approaches often assume that the reward parameters of the robot are known by the humans. We argue that by falsely conditioning on this assumption, the robot performs non-empathetic estimation of the humans' parameters, leading to undesirable values even in the simplest interactions. We test this argument by studying a two-vehicle uncontrolled intersection case with short reaction time. Results show that when both agents are unknowingly aggressive (or non-aggressive), empathy leads to more effective parameter estimation and higher reward values, suggesting that empathy is necessary when the true parameters of agents mismatch with their common belief. The proposed estimation and planning algorithms are therefore more robust than the existing approaches, by fully acknowledging the nature of information asymmetry in HRI. Lastly, we introduce value approximation techniques for real-time execution of the proposed algorithms.
Parkinson's Disease Diagnosis Using Deep Learning
Jan 03, 2021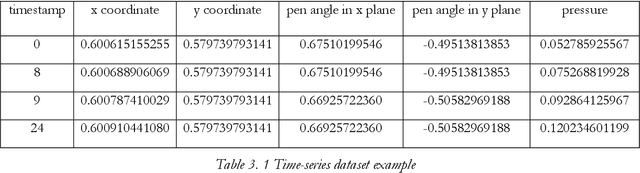
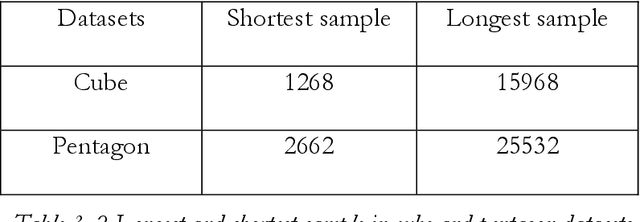

Parkinson's Disease (PD) is a chronic, degenerative disorder which leads to a range of motor and cognitive symptoms. PD diagnosis is a challenging task since its symptoms are very similar to other diseases such as normal ageing and essential tremor. Much research has been applied to diagnosing this disease. This project aims to automate the PD diagnosis process using deep learning, Recursive Neural Networks (RNN) and Convolutional Neural Networks (CNN), to differentiate between healthy and PD patients. Besides that, since different datasets may capture different aspects of this disease, this project aims to explore which PD test is more effective in the discrimination process by analysing different imaging and movement datasets (notably cube and spiral pentagon datasets). In addition, this project evaluates which dataset type, imaging or time series, is more effective in diagnosing PD.
Adapt Everywhere: Unsupervised Adaptation of Point-Clouds and Entropy Minimisation for Multi-modal Cardiac Image Segmentation
Mar 15, 2021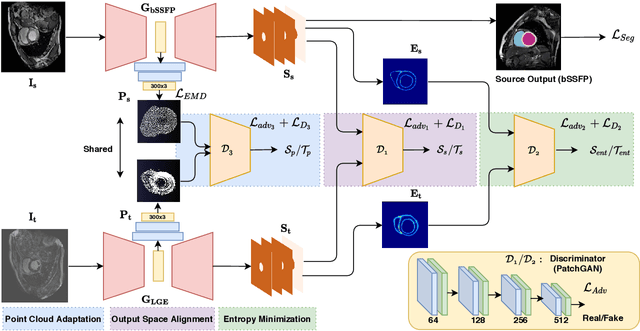
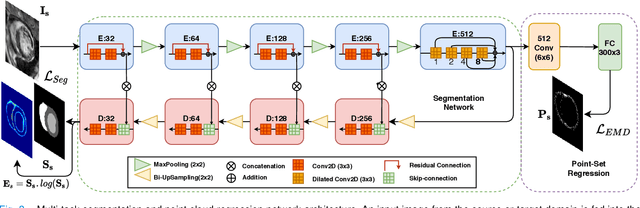
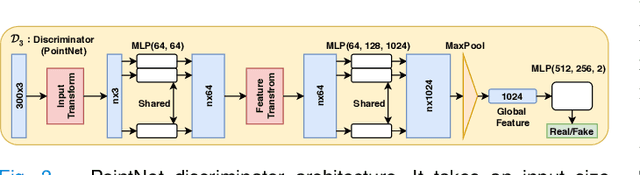
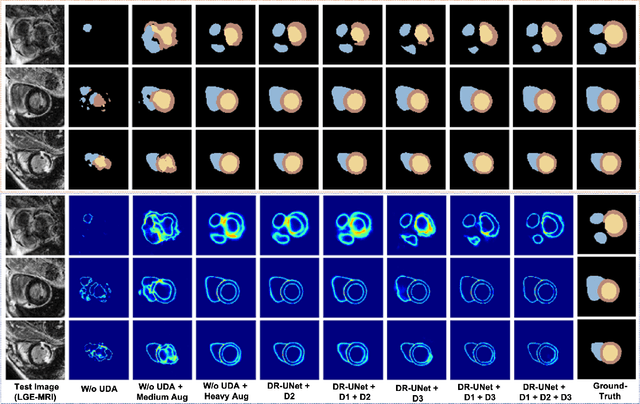
Deep learning models are sensitive to domain shift phenomena. A model trained on images from one domain cannot generalise well when tested on images from a different domain, despite capturing similar anatomical structures. It is mainly because the data distribution between the two domains is different. Moreover, creating annotation for every new modality is a tedious and time-consuming task, which also suffers from high inter- and intra- observer variability. Unsupervised domain adaptation (UDA) methods intend to reduce the gap between source and target domains by leveraging source domain labelled data to generate labels for the target domain. However, current state-of-the-art (SOTA) UDA methods demonstrate degraded performance when there is insufficient data in source and target domains. In this paper, we present a novel UDA method for multi-modal cardiac image segmentation. The proposed method is based on adversarial learning and adapts network features between source and target domain in different spaces. The paper introduces an end-to-end framework that integrates: a) entropy minimisation, b) output feature space alignment and c) a novel point-cloud shape adaptation based on the latent features learned by the segmentation model. We validated our method on two cardiac datasets by adapting from the annotated source domain, bSSFP-MRI (balanced Steady-State Free Procession-MRI), to the unannotated target domain, LGE-MRI (Late-gadolinium enhance-MRI), for the multi-sequence dataset; and from MRI (source) to CT (target) for the cross-modality dataset. The results highlighted that by enforcing adversarial learning in different parts of the network, the proposed method delivered promising performance, compared to other SOTA methods.
Performance versus Complexity Study of Neural Network Equalizers in Coherent Optical Systems
Mar 15, 2021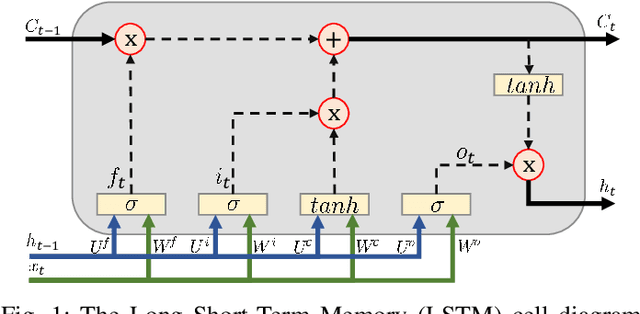
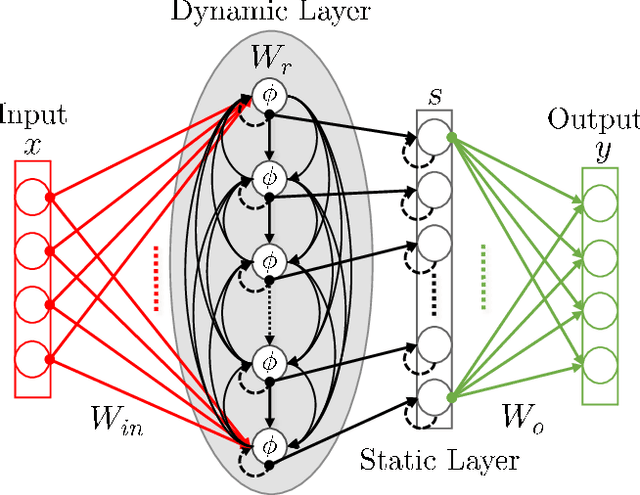
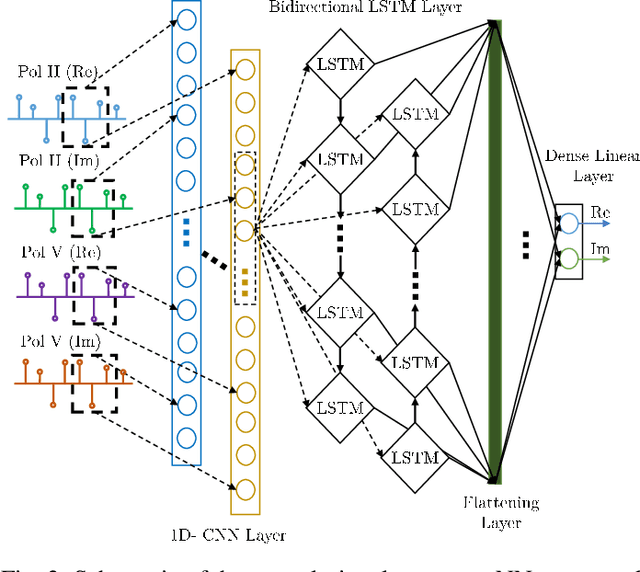
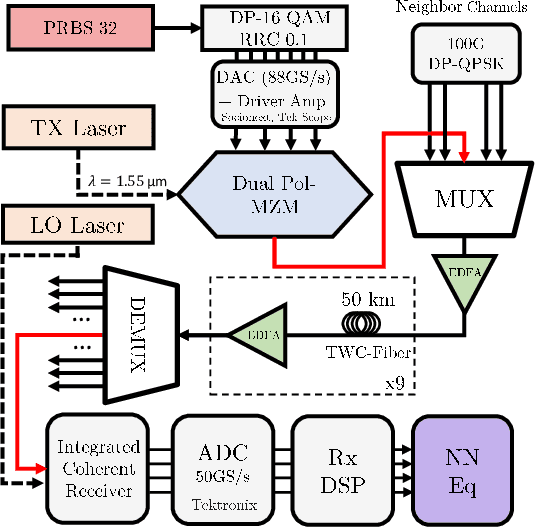
We present the results of the comparative analysis of the performance versus complexity for several types of artificial neural networks (NNs) used for nonlinear channel equalization in coherent optical communication systems. The comparison has been carried out using an experimental set-up with transmission dominated by the Kerr nonlinearity and component imperfections. For the first time, we investigate the application to the channel equalization of the convolution layer (CNN) in combination with a bidirectional long short-term memory (biLSTM) layer and the design combining CNN with a multi-layer perceptron. Their performance is compared with the one delivered by the previously proposed NN equalizer models: one biLSTM layer, three-dense-layer perceptron, and the echo state network. Importantly, all architectures have been initially optimized by a Bayesian optimizer. We present the derivation of the computational complexity associated with each NN type -- in terms of real multiplications per symbol so that these results can be applied to a large number of communication systems. We demonstrated that in the specific considered experimental system the convolutional layer coupled with the biLSTM (CNN+biLSTM) provides the highest Q-factor improvement compared to the reference linear chromatic dispersion compensation (2.9 dB improvement). We examine the trade-off between the computational complexity and performance of all equalizers and demonstrate that the CNN+biLSTM is the best option when the computational complexity is not constrained, while when we restrict the complexity to lower levels, the three-layer perceptron provides the best performance. Our complexity analysis for different NNs is generic and can be applied in a wide range of physical and engineering systems.
Mobile Cellular-Connected UAVs: Reinforcement Learning for Sky Limits
Sep 21, 2020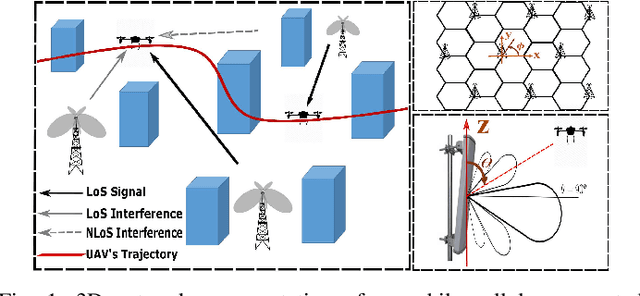
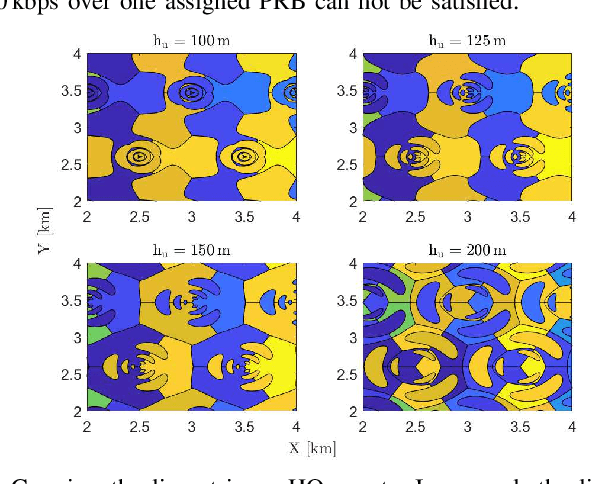
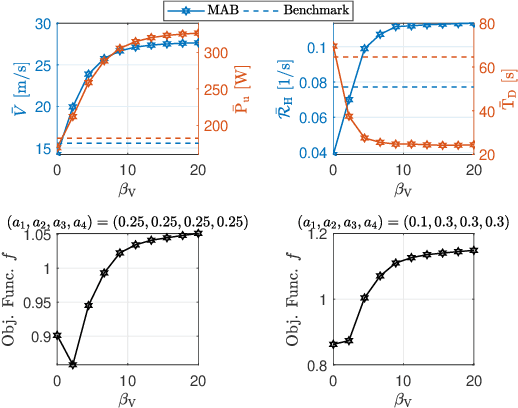
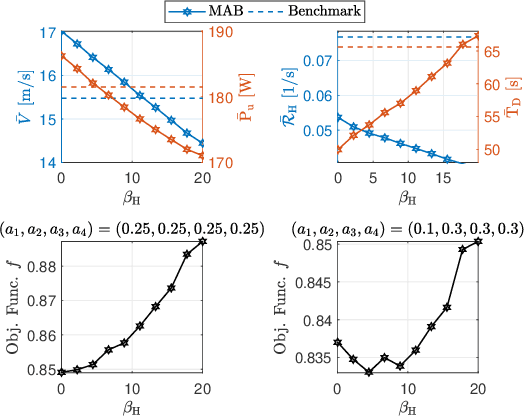
A cellular-connected unmanned aerial vehicle (UAV)faces several key challenges concerning connectivity and energy efficiency. Through a learning-based strategy, we propose a general novel multi-armed bandit (MAB) algorithm to reduce disconnectivity time, handover rate, and energy consumption of UAV by taking into account its time of task completion. By formulating the problem as a function of UAV's velocity, we show how each of these performance indicators (PIs) is improved by adopting a proper range of corresponding learning parameter, e.g. 50% reduction in HO rate as compared to a blind strategy. However, results reveal that the optimal combination of the learning parameters depends critically on any specific application and the weights of PIs on the final objective function.
Distributed Motion Coordination Using Convex Feasible Set Based Model Predictive Control
Jan 20, 2021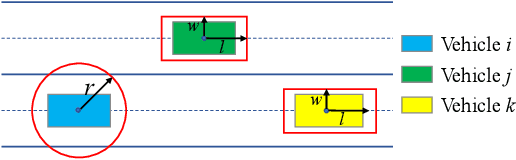
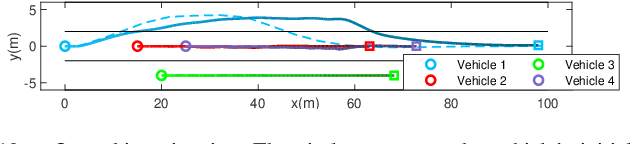
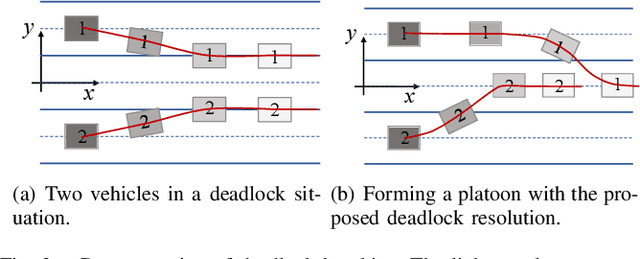
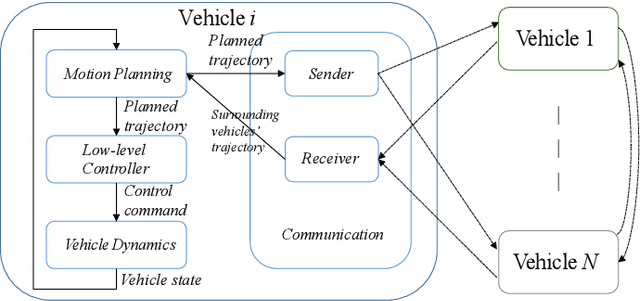
The implementation of optimization-based motion coordination approaches in real world multi-agent systems remains challenging due to their high computational complexity and potential deadlocks. This paper presents a distributed model predictive control (MPC) approach based on convex feasible set (CFS) algorithm for multi-vehicle motion coordination in autonomous driving. By using CFS to convexify the collision avoidance constraints, collision-free trajectories can be computed in real time. We analyze the potential deadlocks and show that a deadlock can be resolved by changing vehicles' desired speeds. The MPC structure ensures that our algorithm is robust to low-level tracking errors. The proposed distributed method has been tested in multiple challenging multi-vehicle environments, including unstructured road, intersection, crossing, platoon formation, merging, and overtaking scenarios. The numerical results and comparison with other approaches (including a centralized MPC and reciprocal velocity obstacles) show that the proposed method is computationally efficient and robust, and avoids deadlocks.