 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Orthogonal Least Squares Based Fast Feature Selection for Linear Classification
Jan 21, 2021
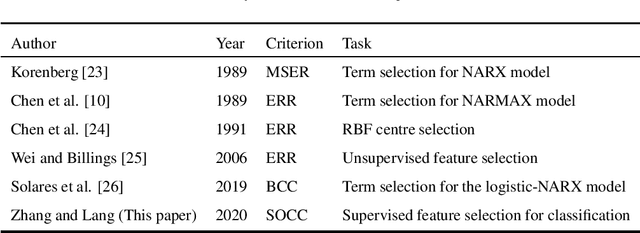
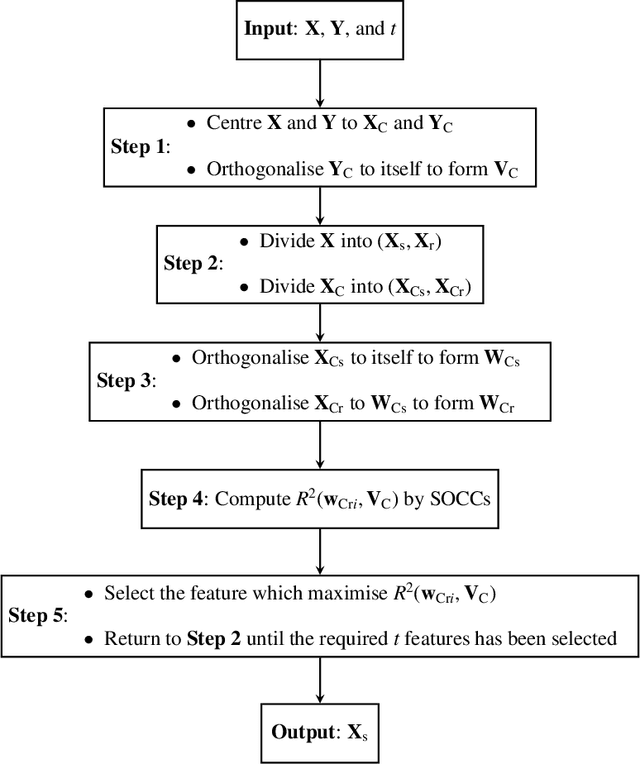
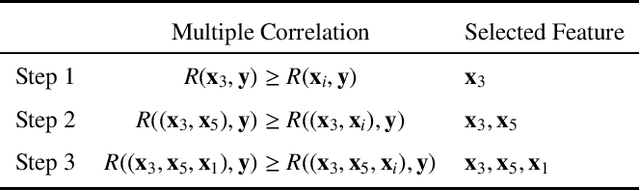
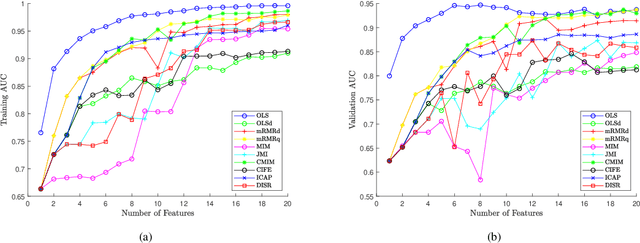
An Orthogonal Least Squares (OLS) based feature selection method is proposed for both binomial and multinomial classification. The novel Squared Orthogonal Correlation Coefficient (SOCC) is defined based on Error Reduction Ratio (ERR) in OLS and used as the feature ranking criterion. The equivalence between the canonical correlation coefficient, Fisher's criterion, and the sum of the SOCCs is revealed, which unveils the statistical implication of ERR in OLS for the first time. It is also shown that the OLS based feature selection method has speed advantages when applied for greedy search. The proposed method is comprehensively compared with the mutual information based feature selection methods in 2 synthetic and 7 real world datasets. The results show that the proposed method is always in the top 5 among the 10 candidate methods. Besides, the proposed method can be directly applied to continuous features without discretisation, which is another significant advantage over mutual information based methods.
On the Exploration of Incremental Learning for Fine-grained Image Retrieval
Oct 15, 2020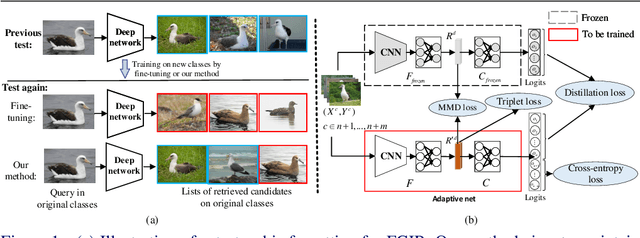
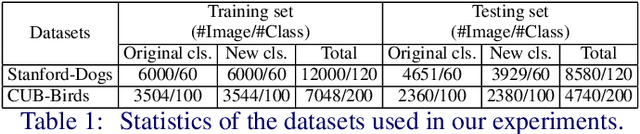
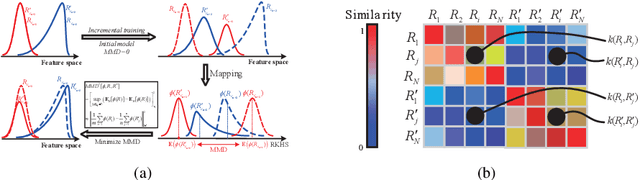
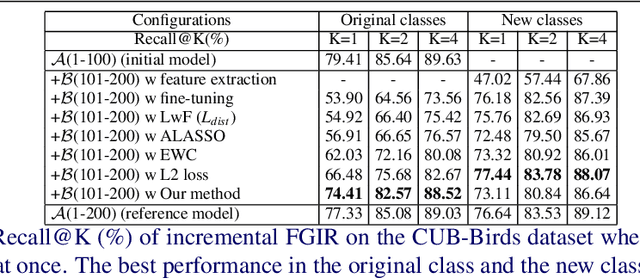
In this paper, we consider the problem of fine-grained image retrieval in an incremental setting, when new categories are added over time. On the one hand, repeatedly training the representation on the extended dataset is time-consuming. On the other hand, fine-tuning the learned representation only with the new classes leads to catastrophic forgetting. To this end, we propose an incremental learning method to mitigate retrieval performance degradation caused by the forgetting issue. Without accessing any samples of the original classes, the classifier of the original network provides soft "labels" to transfer knowledge to train the adaptive network, so as to preserve the previous capability for classification. More importantly, a regularization function based on Maximum Mean Discrepancy is devised to minimize the discrepancy of new classes features from the original network and the adaptive network, respectively. Extensive experiments on two datasets show that our method effectively mitigates the catastrophic forgetting on the original classes while achieving high performance on the new classes.
Scalable Scene Flow from Point Clouds in the Real World
Mar 03, 2021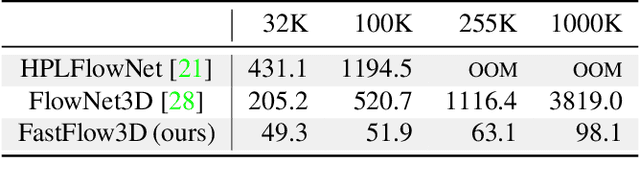
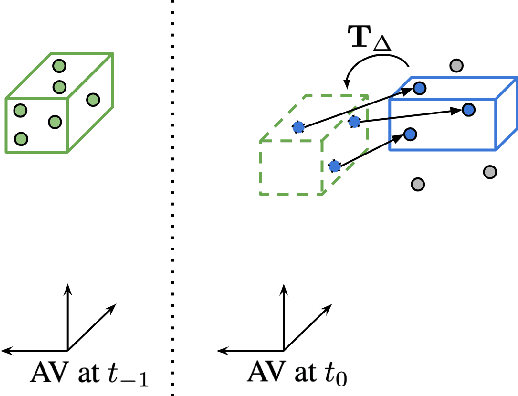
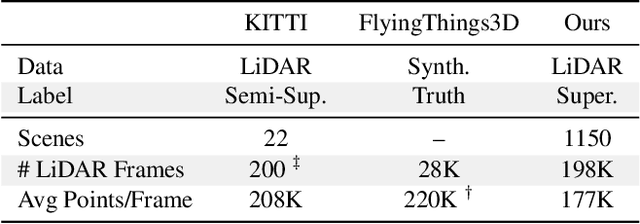
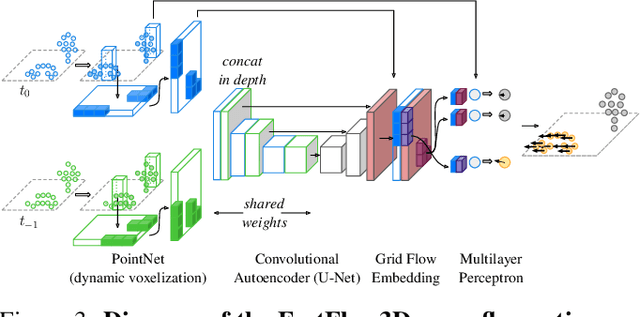
Autonomous vehicles operate in highly dynamic environments necessitating an accurate assessment of which aspects of a scene are moving and where they are moving to. A popular approach to 3D motion estimation -- termed scene flow -- is to employ 3D point cloud data from consecutive LiDAR scans, although such approaches have been limited by the small size of real-world, annotated LiDAR data. In this work, we introduce a new large scale benchmark for scene flow based on the Waymo Open Dataset. The dataset is $\sim$1,000$\times$ larger than previous real-world datasets in terms of the number of annotated frames and is derived from the corresponding tracked 3D objects. We demonstrate how previous works were bounded based on the amount of real LiDAR data available, suggesting that larger datasets are required to achieve state-of-the-art predictive performance. Furthermore, we show how previous heuristics for operating on point clouds such as artificial down-sampling heavily degrade performance, motivating a new class of models that are tractable on the full point cloud. To address this issue, we introduce the model architecture FastFlow3D that provides real time inference on the full point cloud. Finally, we demonstrate that this problem is amenable to techniques from semi-supervised learning by highlighting open problems for generalizing methods for predicting motion on unlabeled objects. We hope that this dataset may provide new opportunities for developing real world scene flow systems and motivate a new class of machine learning problems.
Modelling Compositionality and Structure Dependence in Natural Language
Nov 22, 2020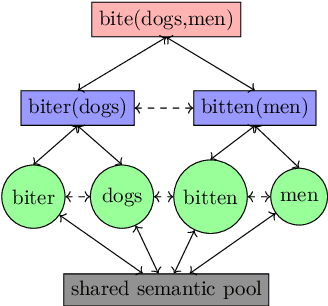

Human beings possess the most sophisticated computational machinery in the known universe. We can understand language of rich descriptive power, and communicate in the same environment with astonishing clarity. Two of the many contributors to the interest in natural language - the properties of Compositionality and Structure Dependence, are well documented, and offer a vast space to ask interesting modelling questions. The first step to begin answering these questions is to ground verbal theory in formal terms. Drawing on linguistics and set theory, a formalisation of these ideas is presented in the first half of this thesis. We see how cognitive systems that process language need to have certain functional constraints, viz. time based, incremental operations that rely on a structurally defined domain. The observations that result from analysing this formal setup are examined as part of a modelling exercise. Using the advances of word embedding techniques, a model of relational learning is simulated with a custom dataset to demonstrate how a time based role-filler binding mechanism satisfies some of the constraints described in the first section. The model's ability to map structure, along with its symbolic-connectionist architecture makes for a cognitively plausible implementation. The formalisation and simulation are together an attempt to recognise the constraints imposed by linguistic theory, and explore the opportunities presented by a cognitive model of relation learning to realise these constraints.
Etat de l'art sur l'application des bandits multi-bras
Jan 04, 2021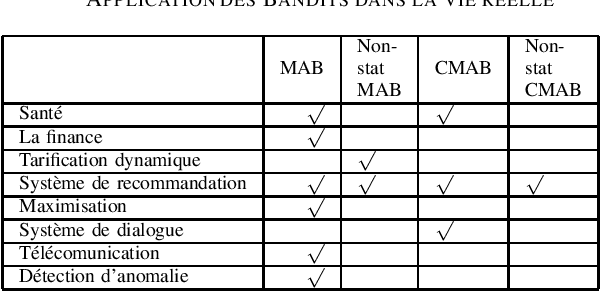
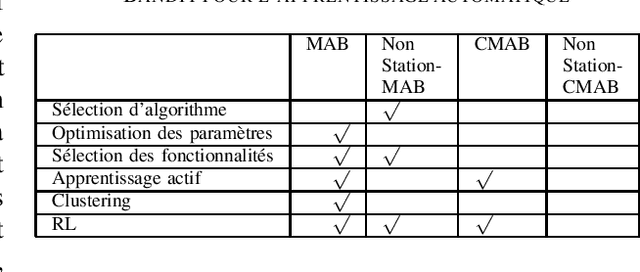
The Multi-armed bandit offer the advantage to learn and exploit the already learnt knowledge at the same time. This capability allows this approach to be applied in different domains, going from clinical trials where the goal is investigating the effects of different experimental treatments while minimizing patient losses, to adaptive routing where the goal is to minimize the delays in a network. This article provides a review of the recent results on applying bandit to real-life scenario and summarize the state of the art for each of these fields. Different techniques has been proposed to solve this problem setting, like epsilon-greedy, Upper confident bound (UCB) and Thompson Sampling (TS). We are showing here how this algorithms were adapted to solve the different problems of exploration exploitation.
$\textbf{MyoMapNet}$: Accelerated Modified Look-Locker Inversion Recovery Myocardial T1 Mapping via Neural Networks
Mar 31, 2021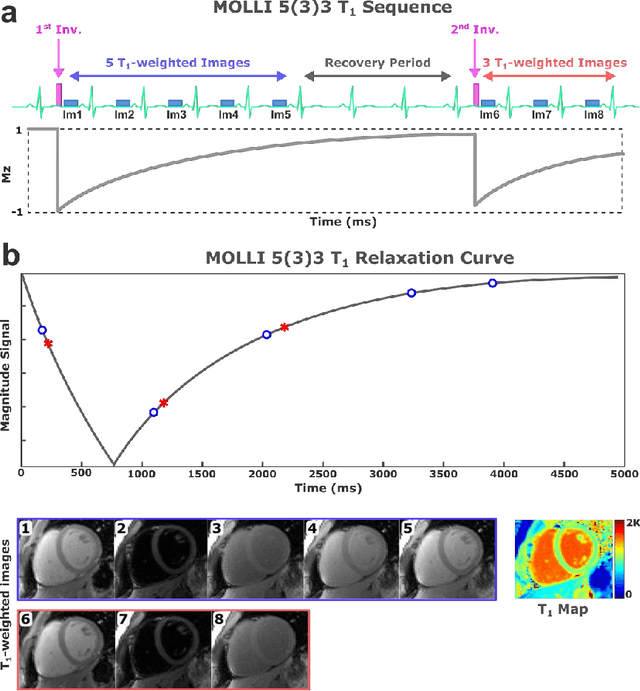
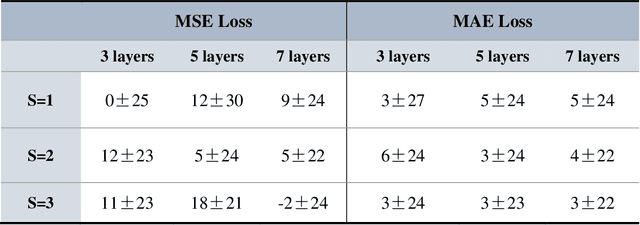
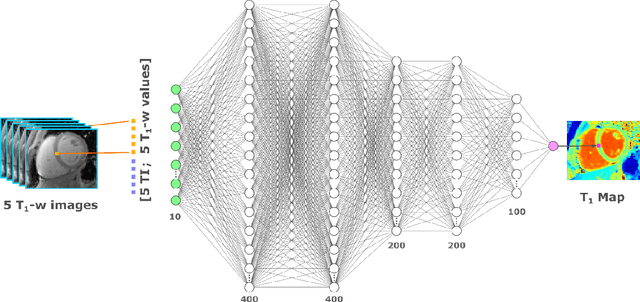
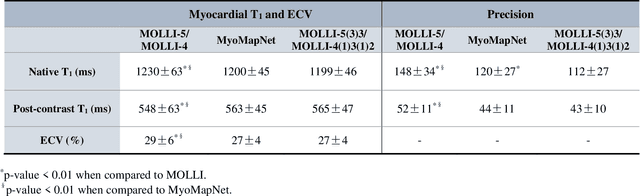
Purpose: To develop and evaluate MyoMapNet, a rapid myocardial T1 mapping approach that uses neural networks (NN) to estimate voxel-wise myocardial T1 and extracellular (ECV) from T1-weighted images collected after a single inversion pulse over 4-5 heartbeats. Method: MyoMapNet utilizes a simple fully-connected NN to estimate T1 values from 5 (native) or 4 (post-contrast) T1-weighted images. Native MOLLI-5(3)3 T1 was collected in 717 subjects (386 males, 55$\pm$16.5 years) and post-contrast MOLLI-4(1)3(1)2 in 535 subjects (232 male, 56.5$\pm$15 years). The dataset was divided into training (80%) and testing (20%), where 20% of the training set was used to optimize MyoMapNet architecture (size and loss functions). We used MyoMapNet to estimate T1 and ECV maps with the first 5 (native) or 4 (post-contrast) T1-weighted images from the corresponding MOLLI sequence compared to the conventional and an abbreviated MOLLI using similar number of T1-weighted images with 3-parameter curve-fitting. Results: In our preliminary optimizaiton step, we determined that a 5-layers NN trained using mean-absolute-error loss yields lower estimation errors and was used subsequently in independent testing study. The myocardial T1 by MyoMapNet was similar to MOLLI (1200$\pm$45ms vs. 1199$\pm$46ms; P=0.3 for native T1, and 27.3$\pm$3.5% vs. 27.1$\pm$4%; P=0.4 for ECV). MyoMapNet had significantly smaller errors in T1 estimations compared to abbreviated-MOLLI (1$\pm$17ms vs. 31$\pm$34ms, P<0.01 for in native T1, and 0.1$\pm$1.3% vs. 1.9$\pm$2.5%, P<0.01 for ECV). The duration of T1 estimation was approximately 2 ms per slice using MyoMapNet. Conclusion: MyoMapNet T1 mapping enables myocardial T1 quantification in 4-5 heartbeats with near-instantaneous map estimation time with similar accuracy and precision as MOLLI. Keywords: Myocardial T1 mapping, MOLLI, T1 reconstruction, Neural network, Deep Learning.
Frequency-based Automated Modulation Classification in the Presence of Adversaries
Nov 04, 2020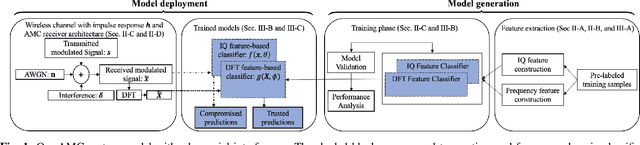
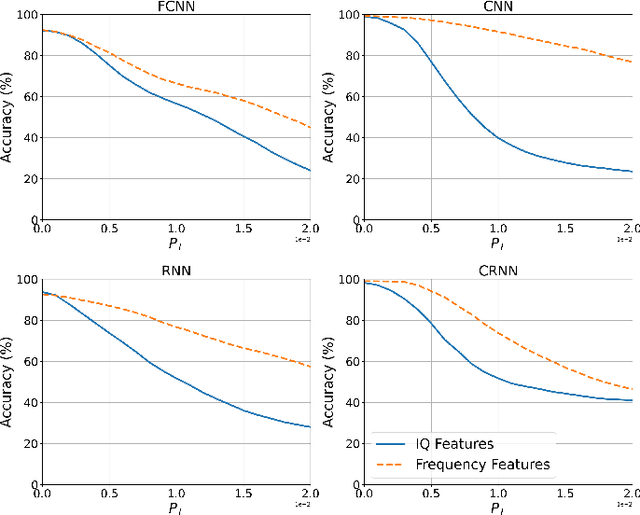
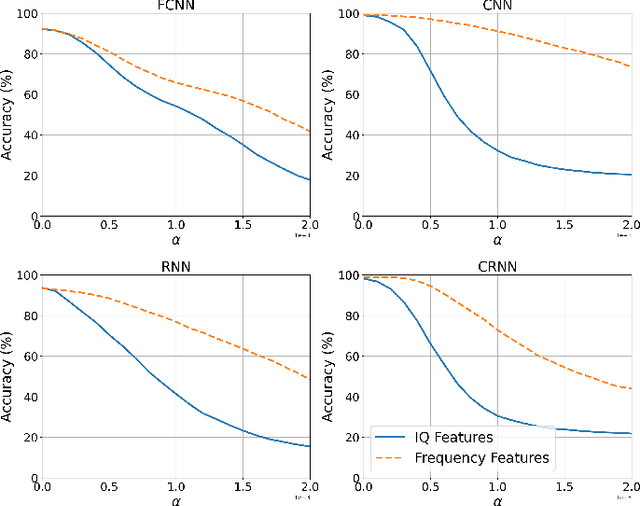
Automatic modulation classification (AMC) aims to improve the efficiency of crowded radio spectrums by automatically predicting the modulation constellation of wireless RF signals. Recent work has demonstrated the ability of deep learning to achieve robust AMC performance using raw in-phase and quadrature (IQ) time samples. Yet, deep learning models are highly susceptible to adversarial interference, which cause intelligent prediction models to misclassify received samples with high confidence. Furthermore, adversarial interference is often transferable, allowing an adversary to attack multiple deep learning models with a single perturbation crafted for a particular classification network. In this work, we present a novel receiver architecture consisting of deep learning models capable of withstanding transferable adversarial interference. Specifically, we show that adversarial attacks crafted to fool models trained on time-domain features are not easily transferable to models trained using frequency-domain features. In this capacity, we demonstrate classification performance improvements greater than 30% on recurrent neural networks (RNNs) and greater than 50% on convolutional neural networks (CNNs). We further demonstrate our frequency feature-based classification models to achieve accuracies greater than 99% in the absence of attacks.
Optimal Full Ranking from Pairwise Comparisons
Jan 21, 2021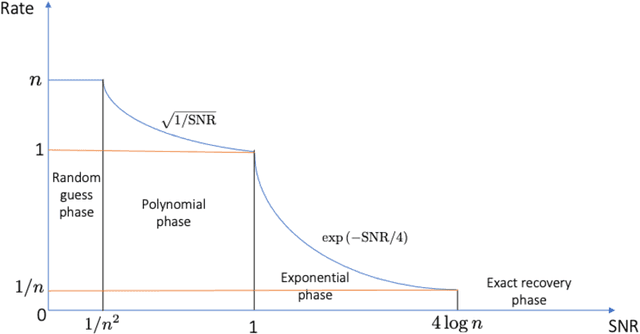
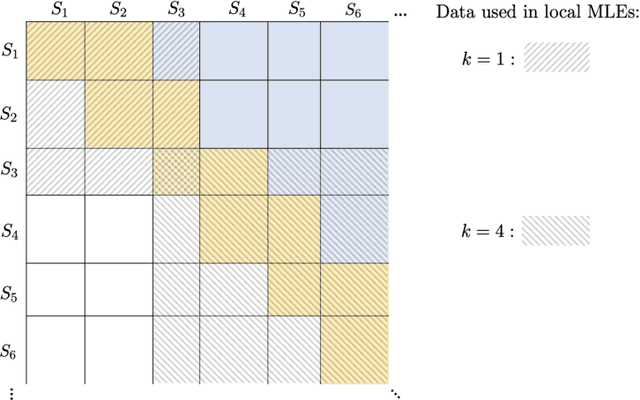
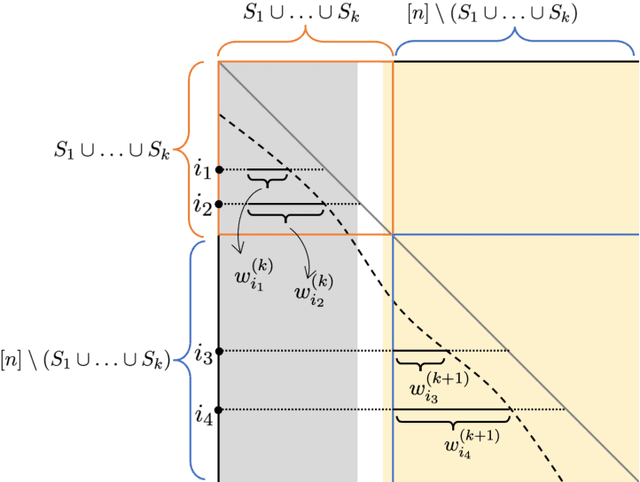
We consider the problem of ranking $n$ players from partial pairwise comparison data under the Bradley-Terry-Luce model. For the first time in the literature, the minimax rate of this ranking problem is derived with respect to the Kendall's tau distance that measures the difference between two rank vectors by counting the number of inversions. The minimax rate of ranking exhibits a transition between an exponential rate and a polynomial rate depending on the magnitude of the signal-to-noise ratio of the problem. To the best of our knowledge, this phenomenon is unique to full ranking and has not been seen in any other statistical estimation problem. To achieve the minimax rate, we propose a divide-and-conquer ranking algorithm that first divides the $n$ players into groups of similar skills and then computes local MLE within each group. The optimality of the proposed algorithm is established by a careful approximate independence argument between the two steps.
Improved active output selection strategy for noisy environments
Jan 10, 2021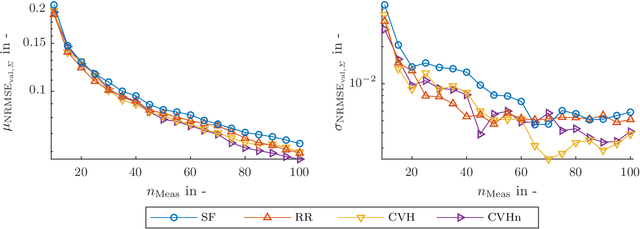
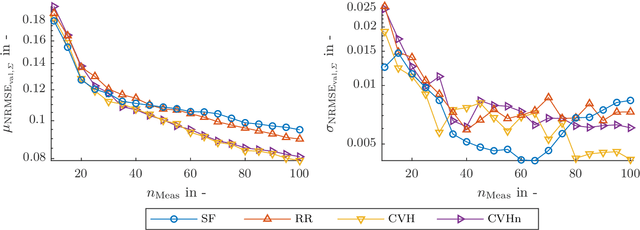
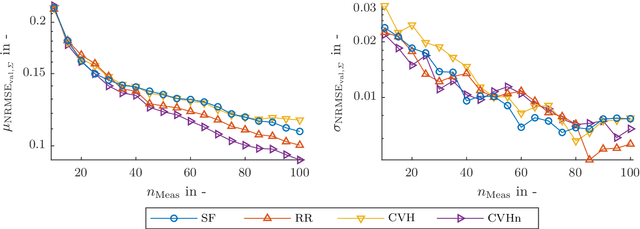
The test bench time needed for model-based calibration can be reduced with active learning methods for test design. This paper presents an improved strategy for active output selection. This is the task of learning multiple models in the same input dimensions and suits the needs of calibration tasks. Compared to an existing strategy, we take into account the noise estimate, which is inherent to Gaussian processes. The method is validated on three different toy examples. The performance compared to the existing best strategy is the same or better in each example. In a best case scenario, the new strategy needs at least 10% less measurements compared to all other active or passive strategies. Further efforts will evaluate the strategy on a real-world application. Moreover, the implementation of more sophisticated active-learning strategies for the query placement will be realized.
Benchmarking of eight recurrent neural network variants for breath phase and adventitious sound detection on a self-developed open-access lung sound database-HF_Lung_V1
Mar 03, 2021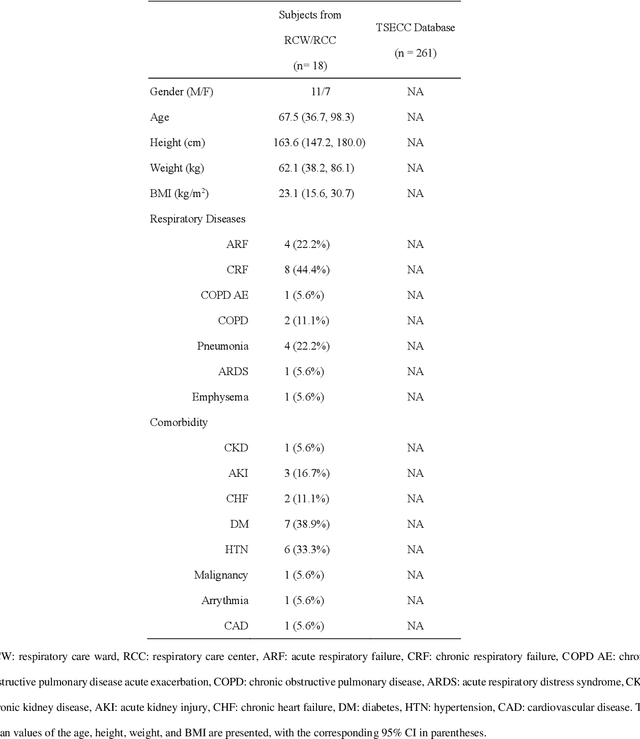

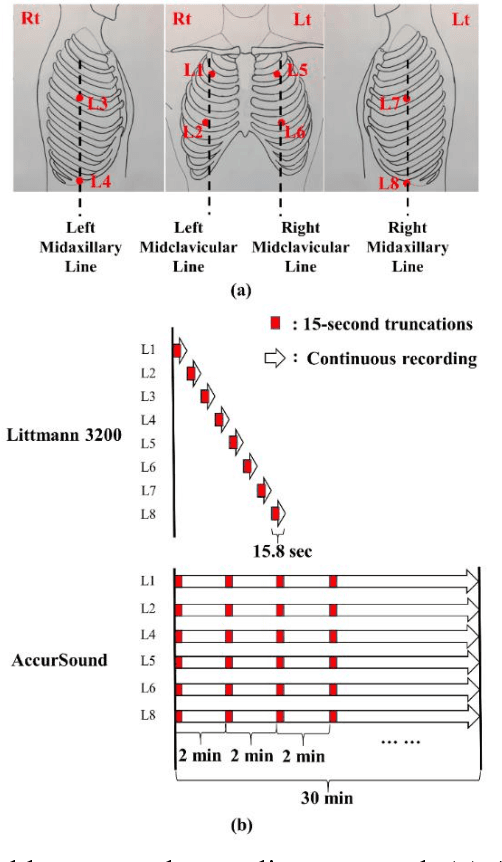
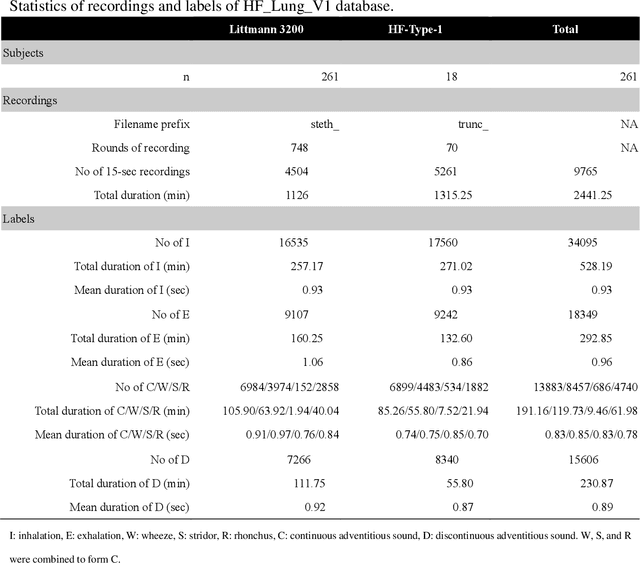
A reliable, remote, and continuous real-time respiratory sound monitor with automated respiratory sound analysis ability is urgently required in many clinical scenarios-such as in monitoring disease progression of coronavirus disease 2019-to replace conventional auscultation with a handheld stethoscope. However, a robust computerized respiratory sound analysis algorithm has not yet been validated in practical applications. In this study, we developed a lung sound database (HF_Lung_V1) comprising 9,765 audio files of lung sounds (duration of 15 s each), 34,095 inhalation labels, 18,349 exhalation labels, 13,883 continuous adventitious sound (CAS) labels (comprising 8,457 wheeze labels, 686 stridor labels, and 4,740 rhonchi labels), and 15,606 discontinuous adventitious sound labels (all crackles). We conducted benchmark tests for long short-term memory (LSTM), gated recurrent unit (GRU), bidirectional LSTM (BiLSTM), bidirectional GRU (BiGRU), convolutional neural network (CNN)-LSTM, CNN-GRU, CNN-BiLSTM, and CNN-BiGRU models for breath phase detection and adventitious sound detection. We also conducted a performance comparison between the LSTM-based and GRU-based models, between unidirectional and bidirectional models, and between models with and without a CNN. The results revealed that these models exhibited adequate performance in lung sound analysis. The GRU-based models outperformed, in terms of F1 scores and areas under the receiver operating characteristic curves, the LSTM-based models in most of the defined tasks. Furthermore, all bidirectional models outperformed their unidirectional counterparts. Finally, the addition of a CNN improved the accuracy of lung sound analysis, especially in the CAS detection tasks.