 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Geometry and Kinematics of the Matrix Lie Group $SE_K(3)$
Dec 02, 2020
Currently state estimation is very important for the robotics, and the uncertainty representation based Lie group is natural for the state estimation problem. It is necessary to exploit the geometry and kinematic of matrix Lie group sufficiently. Therefore, this note gives a detailed derivation of the recently proposed matrix Lie group $SE_K(3)$ for the first time, our results extend the results in Barfoot \cite{barfoot2017state}. Then we describe the situations where this group is suitable for state representation. We also have developed code based on Matlab framework for quickly implementing and testing.
Learning With Context Feedback Loop for Robust Medical Image Segmentation
Mar 04, 2021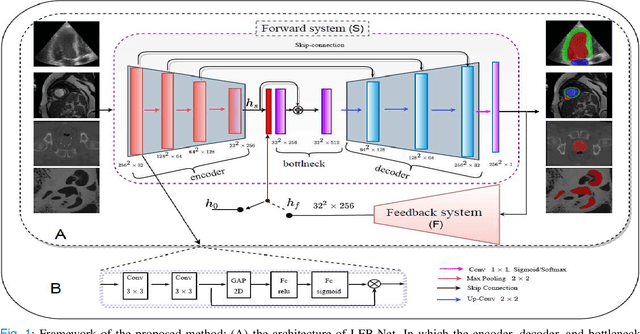
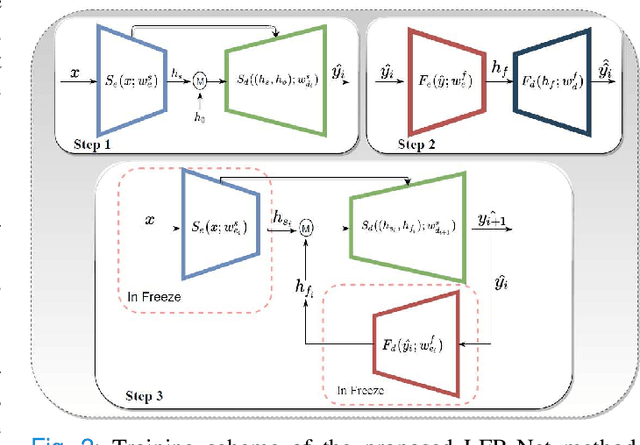
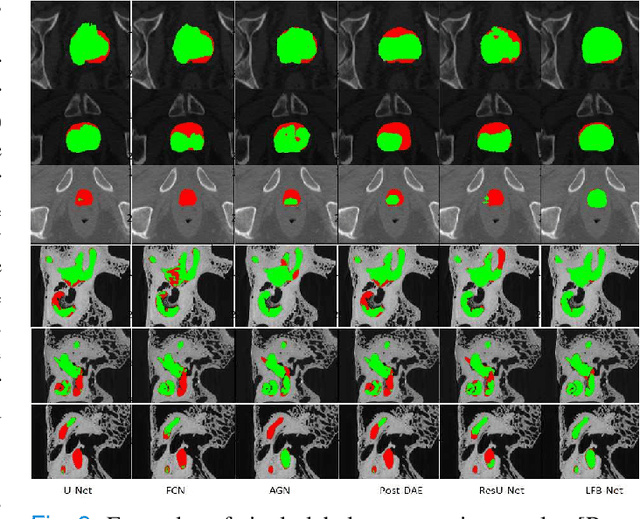
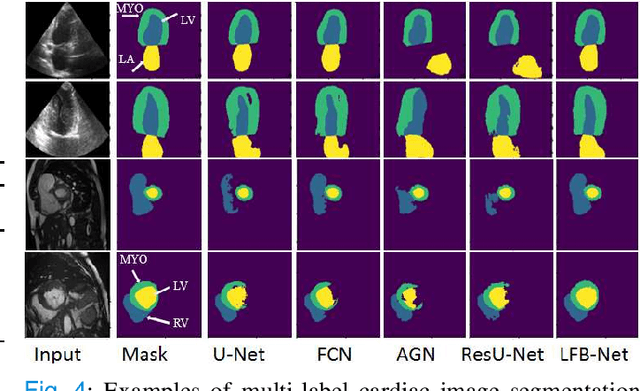
Deep learning has successfully been leveraged for medical image segmentation. It employs convolutional neural networks (CNN) to learn distinctive image features from a defined pixel-wise objective function. However, this approach can lead to less output pixel interdependence producing incomplete and unrealistic segmentation results. In this paper, we present a fully automatic deep learning method for robust medical image segmentation by formulating the segmentation problem as a recurrent framework using two systems. The first one is a forward system of an encoder-decoder CNN that predicts the segmentation result from the input image. The predicted probabilistic output of the forward system is then encoded by a fully convolutional network (FCN)-based context feedback system. The encoded feature space of the FCN is then integrated back into the forward system's feed-forward learning process. Using the FCN-based context feedback loop allows the forward system to learn and extract more high-level image features and fix previous mistakes, thereby improving prediction accuracy over time. Experimental results, performed on four different clinical datasets, demonstrate our method's potential application for single and multi-structure medical image segmentation by outperforming the state of the art methods. With the feedback loop, deep learning methods can now produce results that are both anatomically plausible and robust to low contrast images. Therefore, formulating image segmentation as a recurrent framework of two interconnected networks via context feedback loop can be a potential method for robust and efficient medical image analysis.
ReconResNet: Regularised Residual Learning for MR Image Reconstruction of Undersampled Cartesian and Radial Data
Mar 16, 2021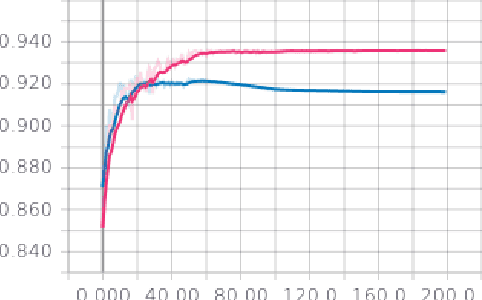
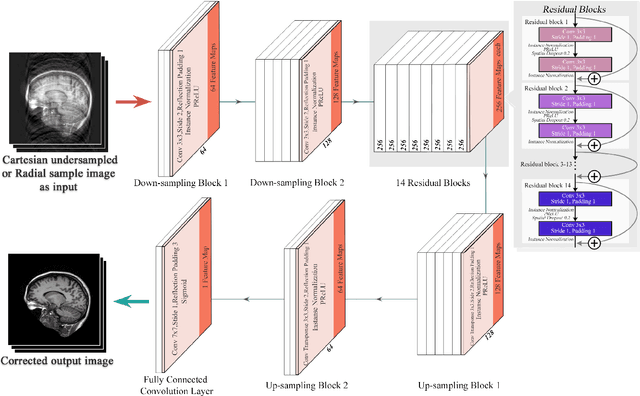
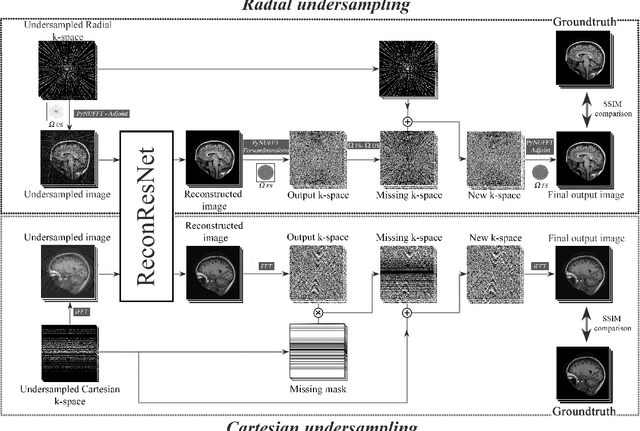
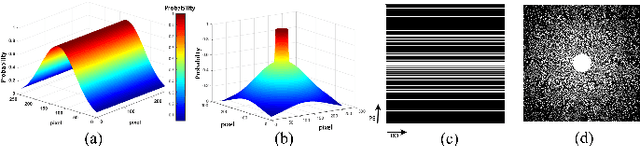
MRI is an inherently slow process, which leads to long scan time for high-resolution imaging. The speed of acquisition can be increased by ignoring parts of the data (undersampling). Consequently, this leads to the degradation of image quality, such as loss of resolution or introduction of image artefacts. This work aims to reconstruct highly undersampled Cartesian or radial MR acquisitions, with better resolution and with less to no artefact compared to conventional techniques like compressed sensing. In recent times, deep learning has emerged as a very important area of research and has shown immense potential in solving inverse problems, e.g. MR image reconstruction. In this paper, a deep learning based MR image reconstruction framework is proposed, which includes a modified regularised version of ResNet as the network backbone to remove artefacts from the undersampled image, followed by data consistency steps that fusions the network output with the data already available from undersampled k-space in order to further improve reconstruction quality. The performance of this framework for various undersampling patterns has also been tested, and it has been observed that the framework is robust to deal with various sampling patterns, even when mixed together while training, and results in very high quality reconstruction, in terms of high SSIM (highest being 0.990$\pm$0.006 for acceleration factor of 3.5), while being compared with the fully sampled reconstruction. It has been shown that the proposed framework can successfully reconstruct even for an acceleration factor of 20 for Cartesian (0.968$\pm$0.005) and 17 for radially (0.962$\pm$0.012) sampled data. Furthermore, it has been shown that the framework preserves brain pathology during reconstruction while being trained on healthy subjects.
Ensuring Progress for Multiple Mobile Robots via Space Partitioning, Motion Rules, and Adaptively Centralized Conflict Resolution
Feb 25, 2021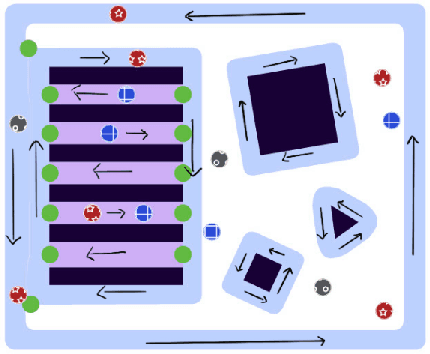

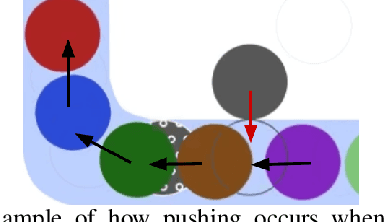
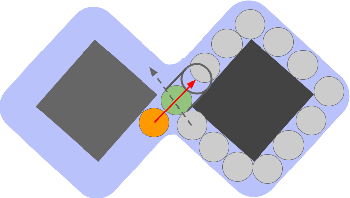
In environments where multiple robots must coordinate in a shared space, decentralized approaches allow for decoupled planning at the cost of global guarantees, while centralized approaches make the opposite trade-off. These solutions make a range of assumptions - commonly, that all the robots share the same planning strategies. In this work, we present a framework that ensures progress for all robots without assumptions on any robot's planning strategy by (1) generating a partition of the environment into "flow", "open", and "passage" regions and (2) imposing a set of rules for robot motion in these regions. These rules for robot motion prevent deadlock through an adaptively centralized protocol for resolving spatial conflicts between robots. Our proposed framework ensures progress for all robots without a grid-like discretization of the environment or strong requirements on robot communication, coordination, or cooperation. Each robot can freely choose how to plan and coordinate for itself, without being vulnerable to other robots or groups of robots blocking them from their goals, as long as they follow the rules when necessary. We describe our space partition and motion rules, prove that the motion rules suffice to guarantee progress in partitioned environments, and demonstrate several cases in simulated polygonal environments. This work strikes a balance between each robot's planning independence and a guarantee that each robot can always reach any goal in finite time.
A Survey of Knowledge-based Sequential Decision Making under Uncertainty
Sep 16, 2020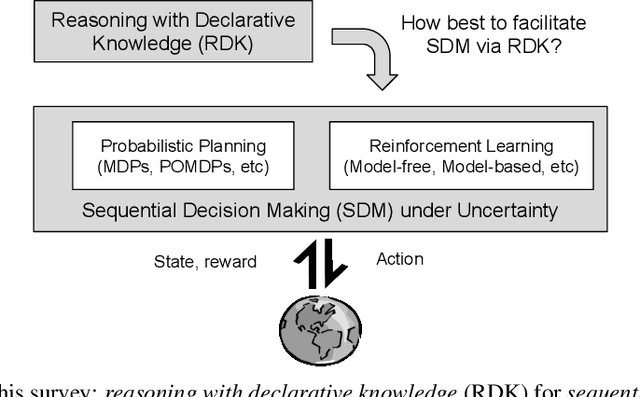
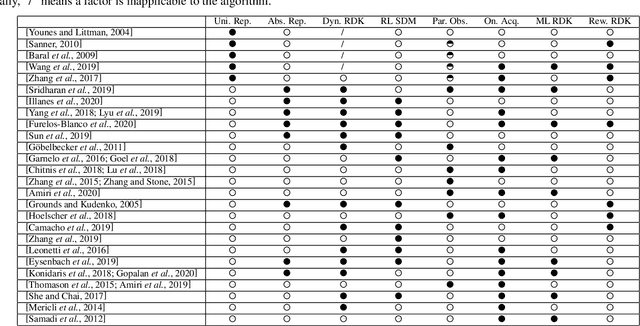
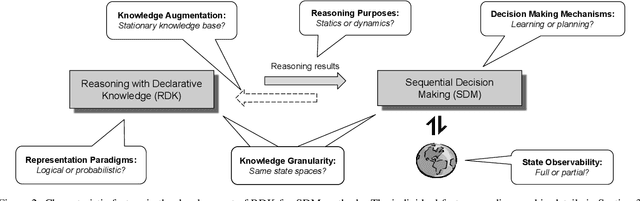
Reasoning with declarative knowledge (RDK) and sequential decision-making (SDM) are two key research areas in artificial intelligence. RDK methods reason with declarative domain knowledge, including commonsense knowledge, that is either provided a priori or acquired over time, while SDM methods (probabilistic planning and reinforcement learning) seek to compute action policies that maximize the expected cumulative utility over a time horizon; both classes of methods reason in the presence of uncertainty. Despite the rich literature in these two areas, researchers have not fully explored their complementary strengths. In this paper, we survey algorithms that leverage RDK methods while making sequential decisions under uncertainty. We discuss significant developments, open problems, and directions for future work.
AttDMM: An Attentive Deep Markov Model for Risk Scoring in Intensive Care Units
Feb 09, 2021



Clinical practice in intensive care units (ICUs) requires early warnings when a patient's condition is about to deteriorate so that preventive measures can be undertaken. To this end, prediction algorithms have been developed that estimate the risk of mortality in ICUs. In this work, we propose a novel generative deep probabilistic model for real-time risk scoring in ICUs. Specifically, we develop an attentive deep Markov model called AttDMM. To the best of our knowledge, AttDMM is the first ICU prediction model that jointly learns both long-term disease dynamics (via attention) and different disease states in health trajectory (via a latent variable model). Our evaluations were based on an established baseline dataset (MIMIC-III) with 53,423 ICU stays. The results confirm that compared to state-of-the-art baselines, our AttDMM was superior: AttDMM achieved an area under the receiver operating characteristic curve (AUROC) of 0.876, which yielded an improvement over the state-of-the-art method by 2.2%. In addition, the risk score from the AttDMM provided warnings several hours earlier. Thereby, our model shows a path towards identifying patients at risk so that health practitioners can intervene early and save patient lives.
Temporal Registration in In-Utero Volumetric MRI Time Series
Aug 12, 2016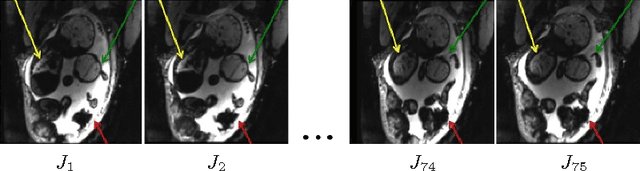
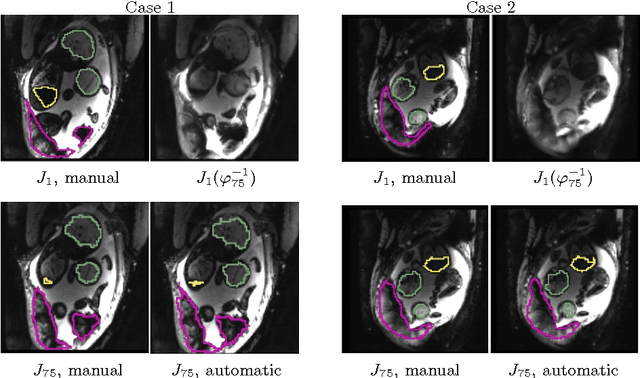
We present a robust method to correct for motion and deformations for in-utero volumetric MRI time series. Spatio-temporal analysis of dynamic MRI requires robust alignment across time in the presence of substantial and unpredictable motion. We make a Markov assumption on the nature of deformations to take advantage of the temporal structure in the image data. Forward message passing in the corresponding hidden Markov model (HMM) yields an estimation algorithm that only has to account for relatively small motion between consecutive frames. We demonstrate the utility of the temporal model by showing that its use improves the accuracy of the segmentation propagation through temporal registration. Our results suggest that the proposed model captures accurately the temporal dynamics of deformations in in-utero MRI time series.
Tone Mapping Based on Multi-scale Histogram Synthesis
Jan 31, 2021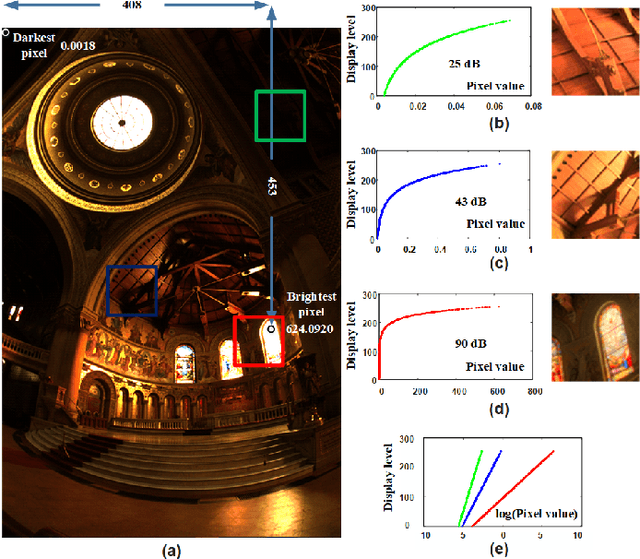
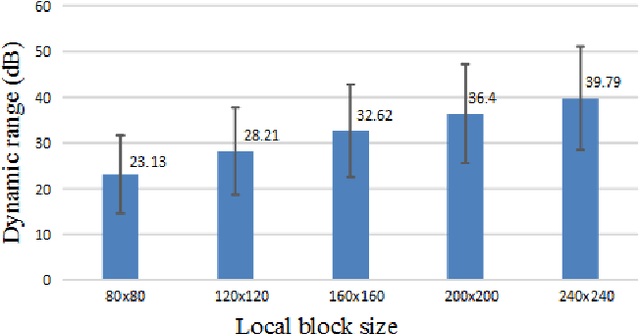
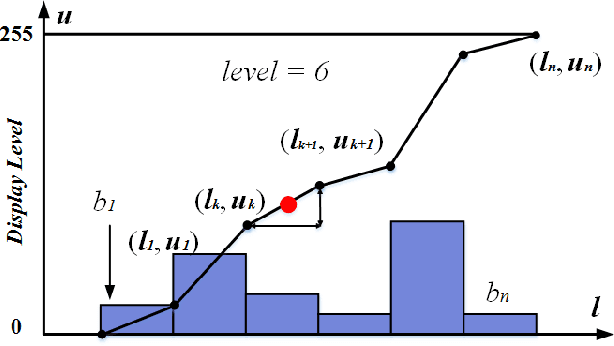
In this paper, we present a novel tone mapping algorithm that can be used for displaying wide dynamic range (WDR) images on low dynamic range (LDR) devices. The proposed algorithm is mainly motivated by the logarithmic response and local adaptation features of the human visual system (HVS). HVS perceives luminance differently when under different adaptation levels, and therefore our algorithm uses functions built upon different scales to tone map pixels to different values. Functions of large scales are used to maintain image brightness consistency and functions of small scales are used to preserve local detail and contrast. An efficient method using local variance has been proposed to fuse the values of different scales and to remove artifacts. The algorithm utilizes integral images and integral histograms to reduce computation complexity and processing time. Experimental results show that the proposed algorithm can generate high brightness, good contrast, and appealing images that surpass the performance of many state-of-the-art tone mapping algorithms. This project is available at https://github.com/jieyang1987/ToneMapping-Based-on-Multi-scale-Histogram-Synthesis.
An Automated Machine Learning (AutoML) Method for Driving Distraction Detection Based on Lane-Keeping Performance
Mar 10, 2021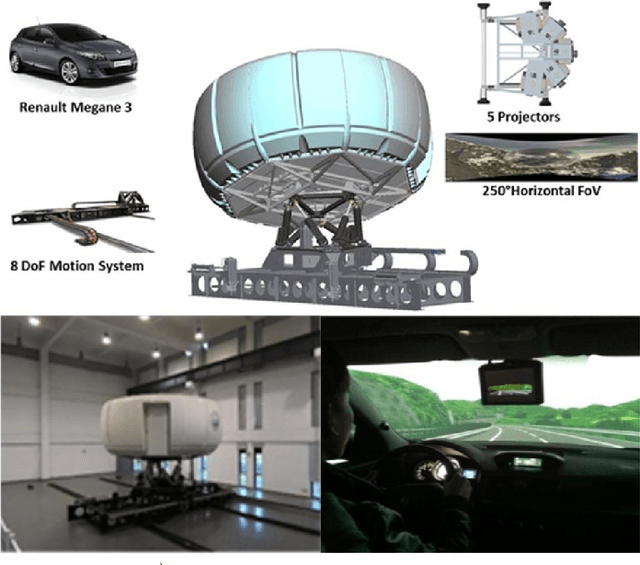
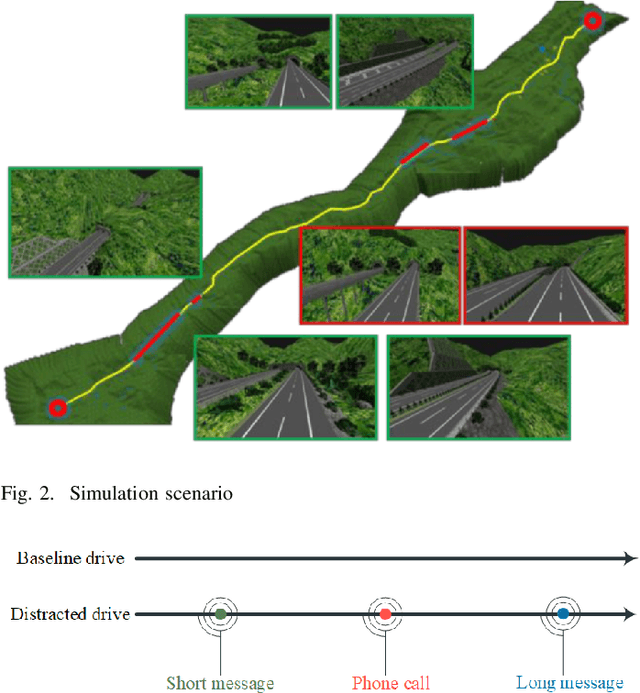
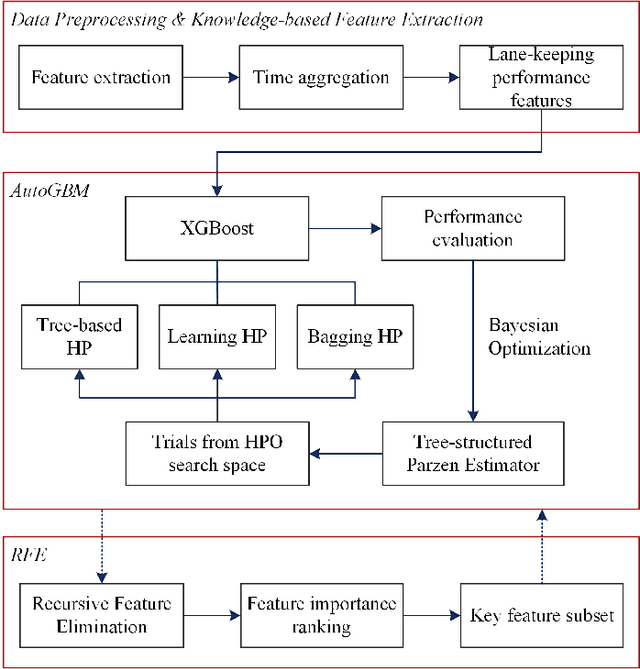
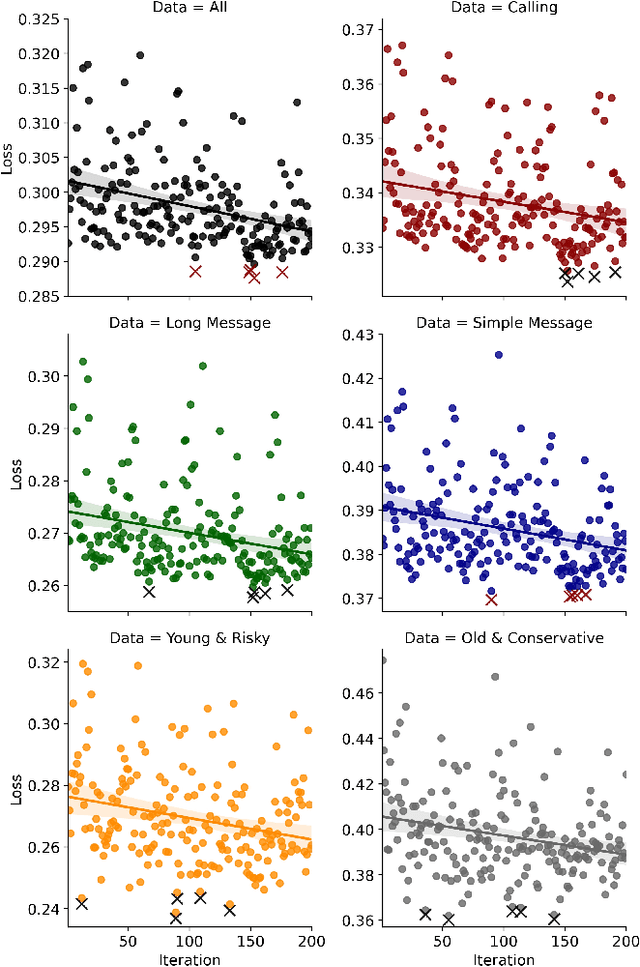
With the enrichment of smartphones, driving distractions caused by phone usages have become a threat to driving safety. A promising way to mitigate driving distractions is to detect them and give real-time safety warnings. However, existing detection algorithms face two major challenges, low user acceptance caused by in-vehicle camera sensors, and uncertain accuracy of pre-trained models due to drivers individual differences. Therefore, this study proposes a domain-specific automated machine learning (AutoML) to self-learn the optimal models to detect distraction based on lane-keeping performance data. The AutoML integrates the key modeling steps into an auto-optimizable pipeline, including knowledge-based feature extraction, feature selection by recursive feature elimination (RFE), algorithm selection, and hyperparameter auto-tuning by Bayesian optimization. An AutoML method based on XGBoost, termed AutoGBM, is built as the classifier for prediction and feature ranking. The model is tested based on driving simulator experiments of three driving distractions caused by phone usage: browsing short messages, browsing long messages, and answering a phone call. The proposed AutoGBM method is found to be reliable and promising to predict phone-related driving distractions, which achieves satisfactory results prediction, with a predictive power of 80\% on group level and 90\% on individual level accuracy. Moreover, the results also evoke the fact that each distraction types and drivers require different optimized hyperparameters values, which reconfirm the necessity of utilizing AutoML to detect driving distractions. The purposed AutoGBM not only produces better performance with fewer features; but also provides data-driven insights about system design.
Performance Optimization of Surface Electromyography (sEMG) based Biometric Sensing System for both Verification and Identification
Mar 10, 2021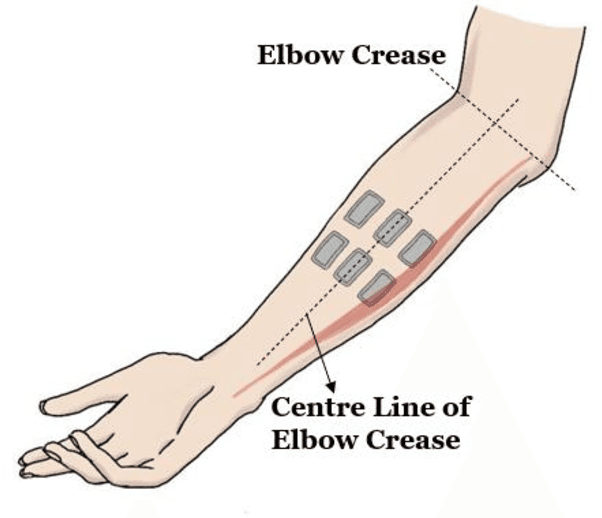
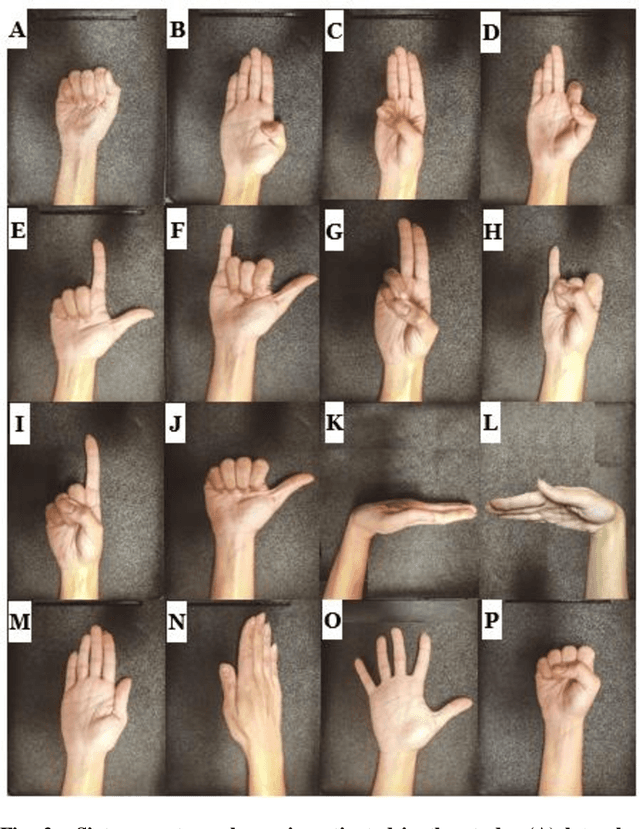
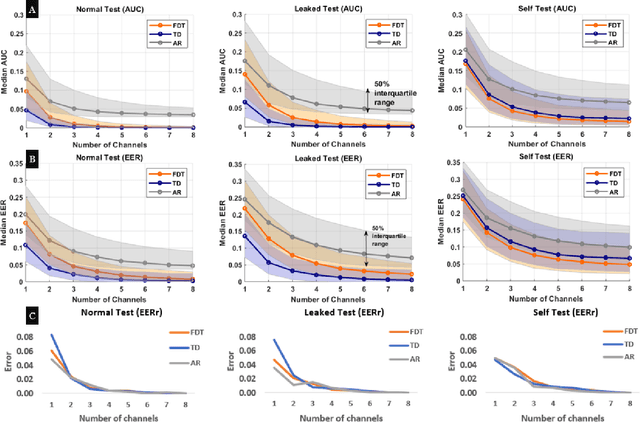
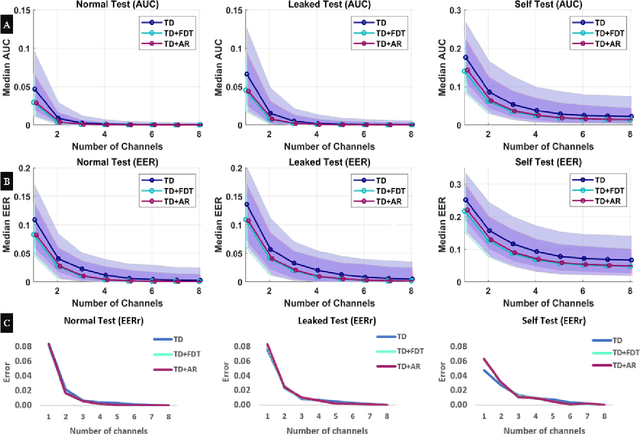
Recently, surface electromyography (sEMG) emerged as a novel biometric authentication method. Since EMG system parameters, such as the feature extraction methods and the number of channels, have been known to affect system performances, it is important to investigate these effects on the performance of the sEMG-based biometric system to determine optimal system parameters. In this study, three robust feature extraction methods, Time-domain (TD) feature, Frequency Division Technique (FDT), and Autoregressive (AR) feature, and their combinations were investigated while the number of channels varying from one to eight. For these system parameters, the performance of sixteen static wrist and hand gestures was systematically investigated in two authentication modes: verification and identification. The results from 24 participants showed that the TD features significantly (p<0.05) and consistently outperformed FDT and AR features for all channel numbers. The results also showed that the performance of a four-channel setup was not significantly different from those with higher number of channels. The average equal error rate (EER) for a four-channel sEMG verification system was 4% for TD features, 5.3% for FDT features, and 10% for AR features. For an identification system, the average Rank-1 error (R1E) for a four-channel configuration was 3% for TD features, 12.4% for FDT features, and 36.3% for AR features. The electrode position on the flexor carpi ulnaris (FCU) muscle had a critical contribution to the authentication performance. Thus, the combination of the TD feature set and a four-channel sEMG system with one of the electrodes positioned on the FCU are recommended for optimal authentication performance.