 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exoplanet Detection in Starshade Images
Mar 17, 2021

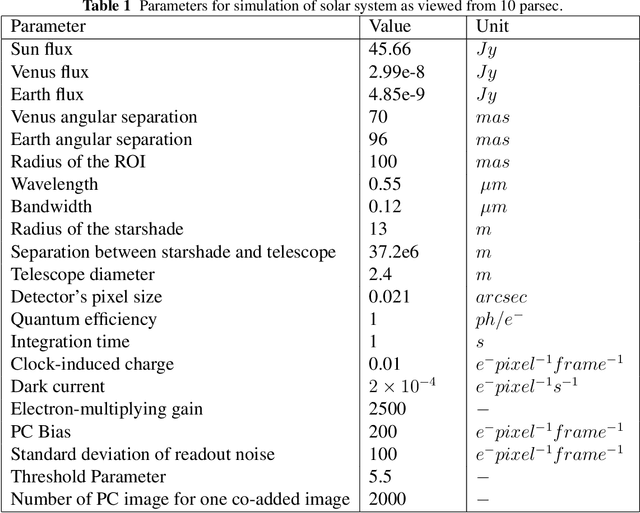
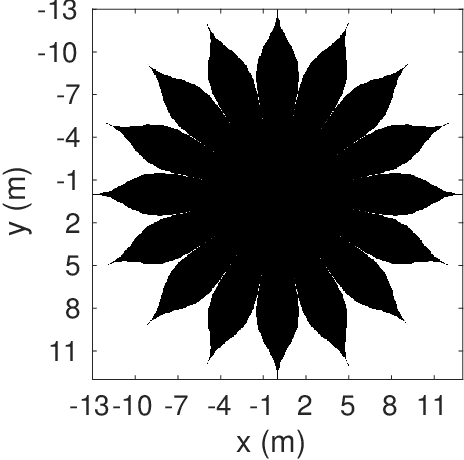

A starshade suppresses starlight by a factor of 1E11 in the image plane of a telescope, which is crucial for directly imaging Earth-like exoplanets. The state of the art in high contrast post-processing and signal detection methods were developed specifically for images taken with an internal coronagraph system and focus on the removal of quasi-static speckles. These methods are less useful for starshade images where such speckles are not present. This paper is dedicated to investigating signal processing methods tailored to work efficiently on starshade images. We describe a signal detection method, the generalized likelihood ratio test (GLRT), for starshade missions and look into three important problems. First, even with the light suppression provided by the starshade, rocky exoplanets are still difficult to detect in reflected light due to their absolute faintness. GLRT can successfully flag these dim planets. Moreover, GLRT provides estimates of the planets' positions and intensities and the theoretical false alarm rate of the detection. Second, small starshade shape errors, such as a truncated petal tip, can cause artifacts that are hard to distinguish from real planet signals; the detection method can help distinguish planet signals from such artifacts. The third direct imaging problem is that exozodiacal dust degrades detection performance. We develop an iterative generalized likelihood ratio test to mitigate the effect of dust on the image. In addition, we provide guidance on how to choose the number of photon counting images to combine into one co-added image before doing detection, which will help utilize the observation time efficiently. All the methods are demonstrated on realistic simulated images.
Challenges and opportunities of inertia estimation and forecasting in low-inertia power systems
Aug 28, 2020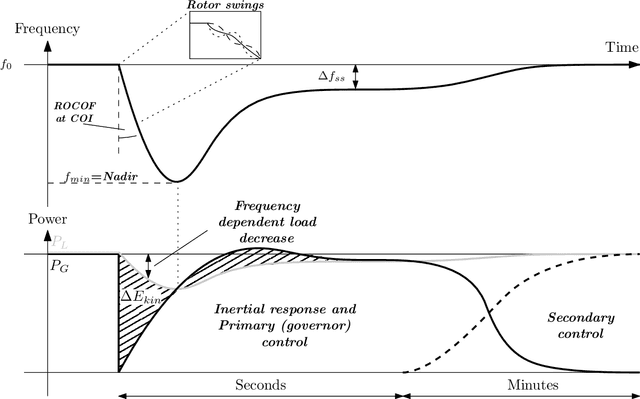
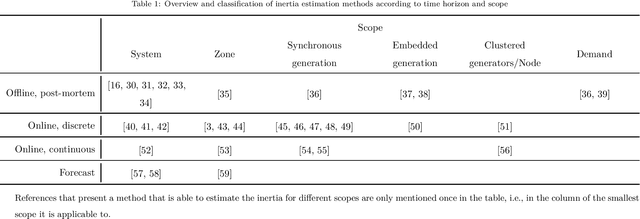
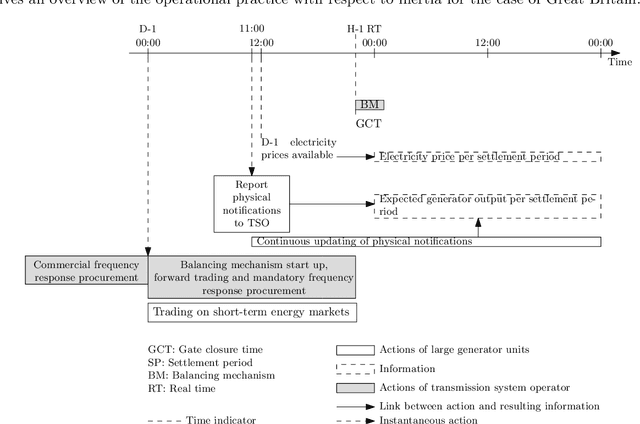

Accurate inertia estimates and forecasts are crucial to support the system operation in future low-inertia power systems. A large literature on inertia estimation methods is available. This paper aims to provide an overview and classification of inertia estimation methods. The classification considers the time horizon the methods are applicable to, i.e., offline post mortem, online real time and forecasting methods, and the scope of the inertia estimation, e.g., system-wide, regional, generation, demand, individual resource. Shortcomings of the existing inertia estimation methods have been identified and suggestions for future work have been made.
Learned Equivariant Rendering without Transformation Supervision
Nov 11, 2020


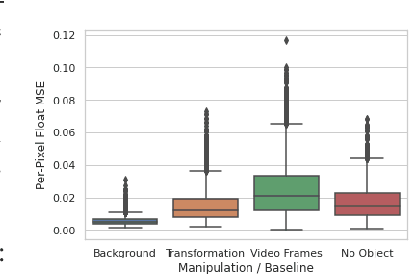
We propose a self-supervised framework to learn scene representations from video that are automatically delineated into objects and background. Our method relies on moving objects being equivariant with respect to their transformation across frames and the background being constant. After training, we can manipulate and render the scenes in real time to create unseen combinations of objects, transformations, and backgrounds. We show results on moving MNIST with backgrounds.
Generative and Discriminative Deep Belief Network Classifiers: Comparisons Under an Approximate Computing Framework
Jan 31, 2021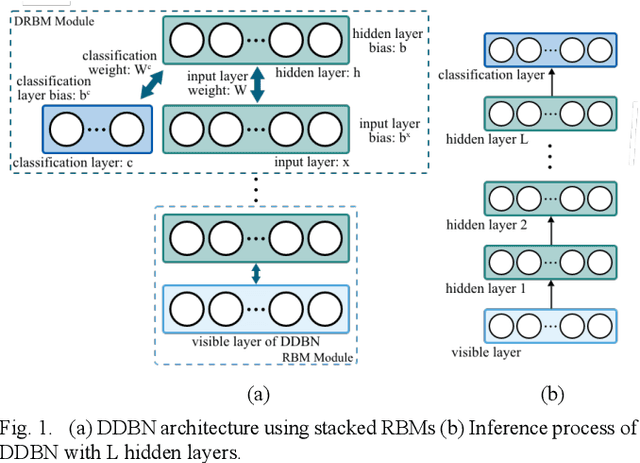
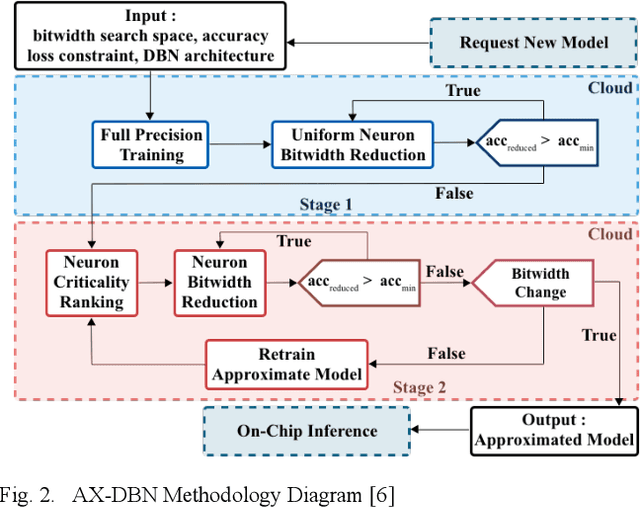

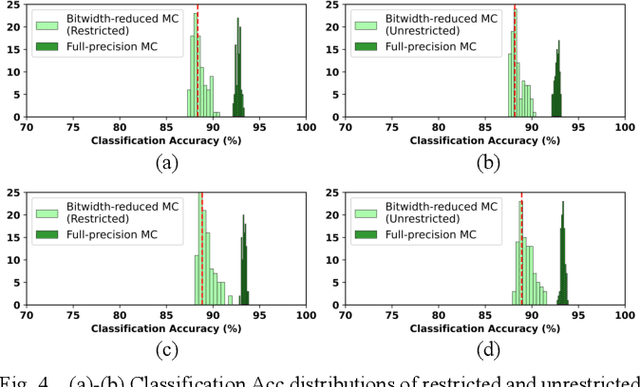
The use of Deep Learning hardware algorithms for embedded applications is characterized by challenges such as constraints on device power consumption, availability of labeled data, and limited internet bandwidth for frequent training on cloud servers. To enable low power implementations, we consider efficient bitwidth reduction and pruning for the class of Deep Learning algorithms known as Discriminative Deep Belief Networks (DDBNs) for embedded-device classification tasks. We train DDBNs with both generative and discriminative objectives under an approximate computing framework and analyze their power-at-performance for supervised and semi-supervised applications. We also investigate the out-of-distribution performance of DDBNs when the inference data has the same class structure yet is statistically different from the training data owing to dynamic real-time operating environments. Based on our analysis, we provide novel insights and recommendations for choice of training objectives, bitwidth values, and accuracy sensitivity with respect to the amount of labeled data for implementing DDBN inference with minimum power consumption on embedded hardware platforms subject to accuracy tolerances.
Push recovery with stepping strategy based on time-projection control
Jan 07, 2018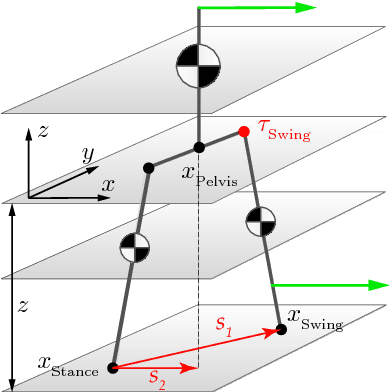
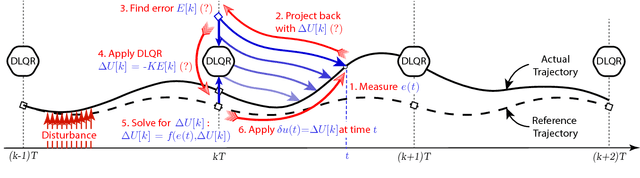
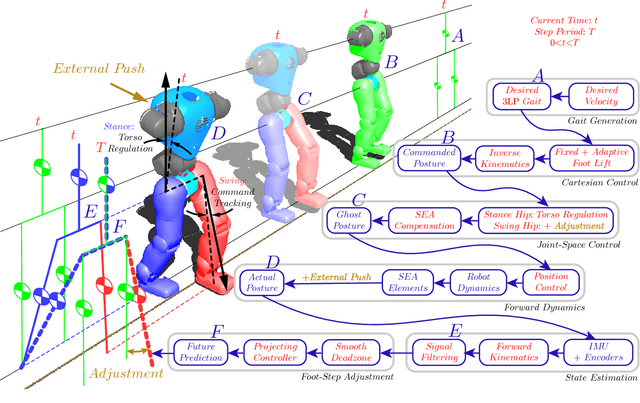
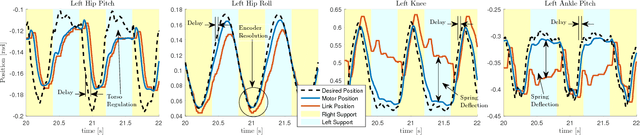
In this paper, we present a simple control framework for on-line push recovery with dynamic stepping properties. Due to relatively heavy legs in our robot, we need to take swing dynamics into account and thus use a linear model called 3LP which is composed of three pendulums to simulate swing and torso dynamics. Based on 3LP equations, we formulate discrete LQR controllers and use a particular time-projection method to adjust the next footstep location on-line during the motion continuously. This adjustment, which is found based on both pelvis and swing foot tracking errors, naturally takes the swing dynamics into account. Suggested adjustments are added to the Cartesian 3LP gaits and converted to joint-space trajectories through inverse kinematics. Fixed and adaptive foot lift strategies also ensure enough ground clearance in perturbed walking conditions. The proposed structure is robust, yet uses very simple state estimation and basic position tracking. We rely on the physical series elastic actuators to absorb impacts while introducing simple laws to compensate their tracking bias. Extensive experiments demonstrate the functionality of different control blocks and prove the effectiveness of time-projection in extreme push recovery scenarios. We also show self-produced and emergent walking gaits when the robot is subject to continuous dragging forces. These gaits feature dynamic walking robustness due to relatively soft springs in the ankles and avoiding any Zero Moment Point (ZMP) control in our proposed architecture.
Using LSTM for the Prediction of Disruption in ADITYA Tokamak
Jul 13, 2020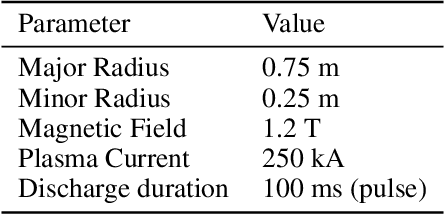
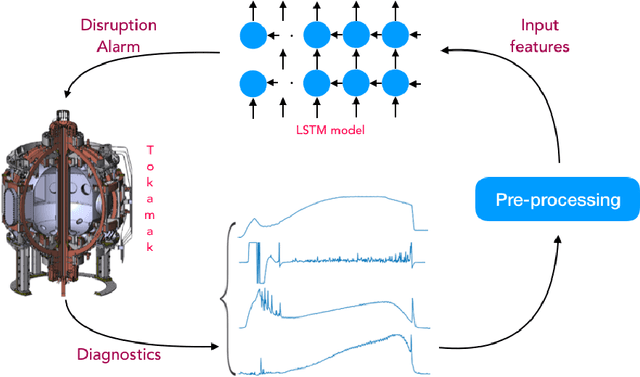
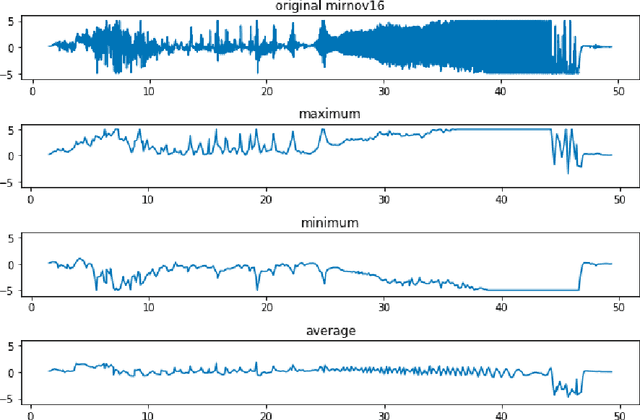
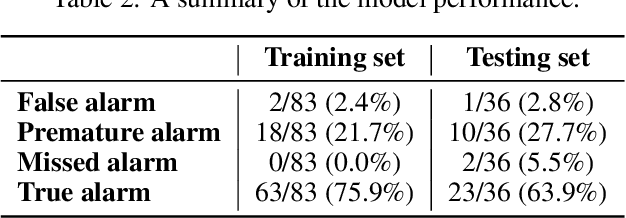
Major disruptions in tokamak pose a serious threat to the vessel and its surrounding pieces of equipment. The ability of the systems to detect any behavior that can lead to disruption can help in alerting the system beforehand and prevent its harmful effects. Many machine learning techniques have already been in use at large tokamaks like JET and ASDEX, but are not suitable for ADITYA, which is comparatively small. Through this work, we discuss a new real-time approach to predict the time of disruption in ADITYA tokamak and validate the results on an experimental dataset. The system uses selected diagnostics from the tokamak and after some pre-processing steps, sends them to a time-sequence Long Short-Term Memory (LSTM) network. The model can make the predictions 12 ms in advance at less computation cost that is quick enough to be deployed in real-time applications.
GPUTreeShap: Fast Parallel Tree Interpretability
Oct 27, 2020
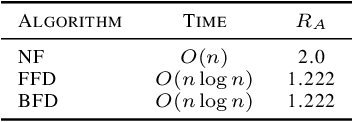

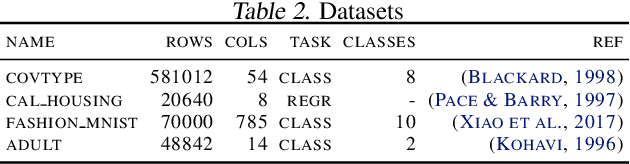
SHAP (SHapley Additive exPlanation) values provide a game theoretic interpretation of the predictions of machine learning models based on Shapley values. While SHAP values are intractable in general, a recursive polynomial time algorithm specialised for decision tree models is available, named TreeShap. Despite its polynomial time complexity, TreeShap can become a significant bottleneck in practical machine learning pipelines when applied to large decision tree ensembles. We present GPUTreeShap, a software package implementing a modified TreeShap algorithm in CUDA for Nvidia GPUs. Our approach first preprocesses the input model to isolate variable sized sub-problems from the original recursive algorithm, then solves a bin packing problem, and finally maps sub-problems to streaming multiprocessors for parallel execution with specialised hardware instructions. With a single GPU, we achieve speedups of up to 19x for SHAP values, and 340x for SHAP interaction values, over a state-of-the-art multi-core CPU implementation. We also experiment with an 8 GPU DGX-1 system, demonstrating throughput of 1.2M rows per second---equivalent CPU-based performance is estimated to require 6850 CPU cores.
Optimal Static Mutation Strength Distributions for the $(1+λ)$ Evolutionary Algorithm on OneMax
Feb 09, 2021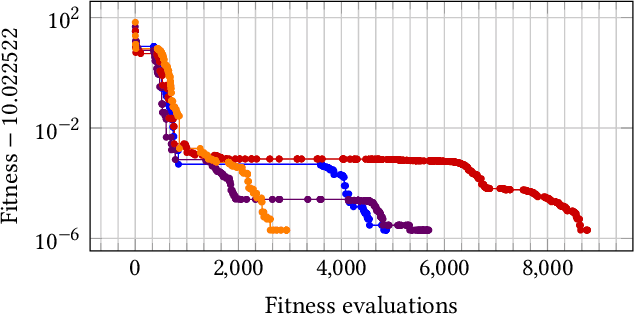
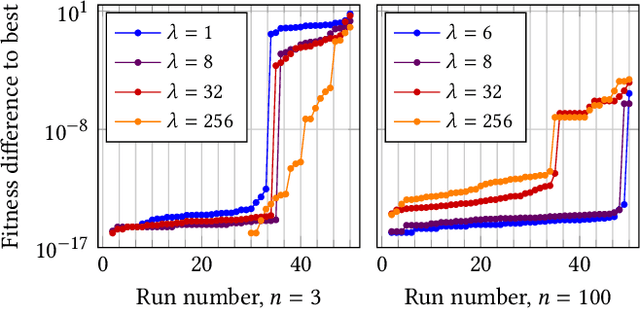
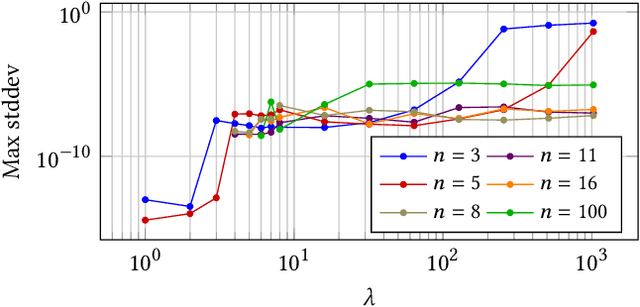
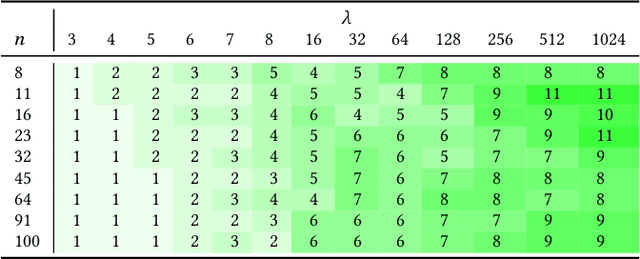
Most evolutionary algorithms have parameters, which allow a great flexibility in controlling their behavior and adapting them to new problems. To achieve the best performance, it is often needed to control some of the parameters during optimization, which gave rise to various parameter control methods. In recent works, however, similar advantages have been shown, and even proven, for sampling parameter values from certain, often heavy-tailed, fixed distributions. This produced a family of algorithms currently known as "fast evolution strategies" and "fast genetic algorithms". However, only little is known so far about the influence of these distributions on the performance of evolutionary algorithms, and about the relationships between (dynamic) parameter control and (static) parameter sampling. We contribute to the body of knowledge by presenting, for the first time, an algorithm that computes the optimal static distributions, which describe the mutation operator used in the well-known simple $(1+\lambda)$ evolutionary algorithm on a classic benchmark problem OneMax. We show that, for large enough population sizes, such optimal distributions may be surprisingly complicated and counter-intuitive. We investigate certain properties of these distributions, and also evaluate the performance regrets of the $(1+\lambda)$ evolutionary algorithm using commonly used mutation distributions.
Urban Change Detection by Fully Convolutional Siamese Concatenate Network with Attention
Jan 31, 2021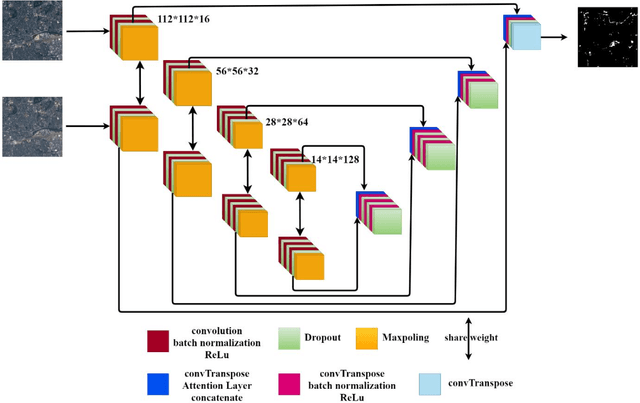
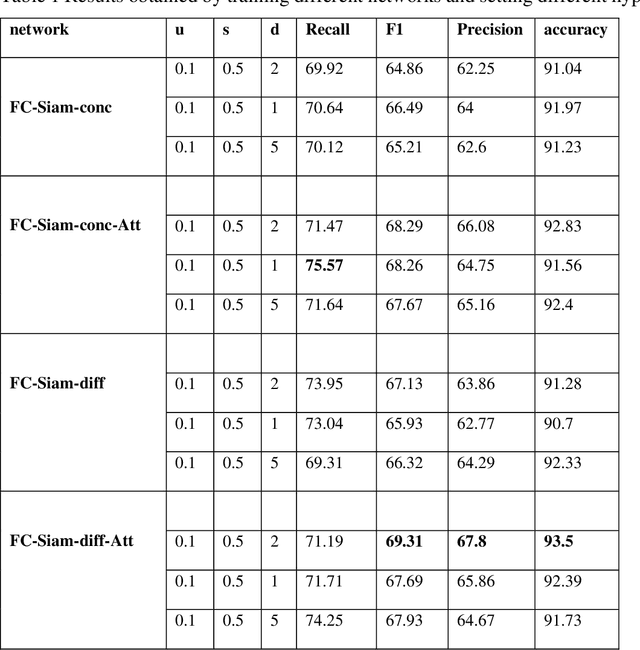
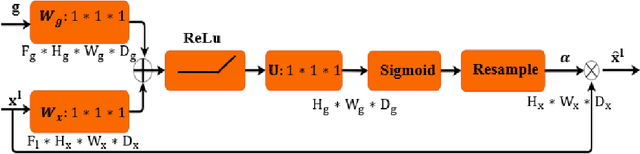
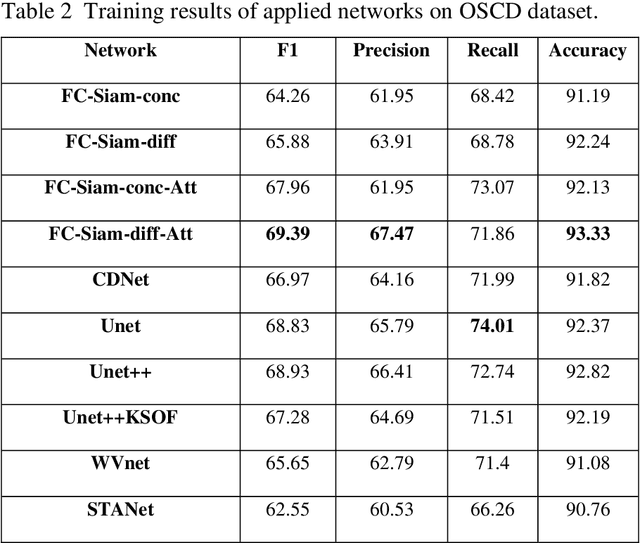
Change detection (CD) is an important problem in remote sensing, especially in disaster time for urban management. Most existing traditional methods for change detection are categorized based on pixel or objects. Object-based models are preferred to pixel-based methods for handling very high-resolution remote sensing (VHR RS) images. Such methods can benefit from the ongoing research on deep learning. In this paper, a fully automatic change-detection algorithm on VHR RS images is proposed that deploys Fully Convolutional Siamese Concatenate networks (FC-Siam-Conc). The proposed method uses preprocessing and an attention gate layer to improve accuracy. Gaussian attention (GA) as a soft visual attention mechanism is used for preprocessing. GA helps the network to handle feature maps like biological visual systems. Since the GA parameters cannot be adjusted during network training, an attention gate layer is introduced to play the role of GA with parameters that can be tuned among other network parameters. Experimental results obtained on Onera Satellite Change Detection (OSCD) and RIVER-CD datasets confirm the superiority of the proposed architecture over the state-of-the-art algorithms.
TicketTalk: Toward human-level performance with end-to-end, transaction-based dialog systems
Dec 23, 2020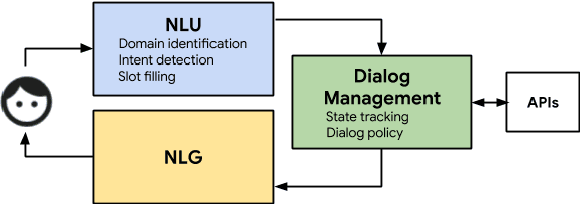
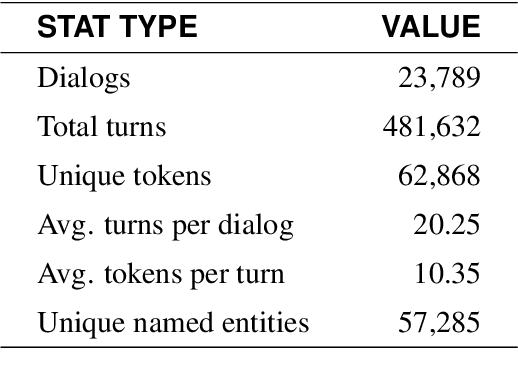

We present a data-driven, end-to-end approach to transaction-based dialog systems that performs at near-human levels in terms of verbal response quality and factual grounding accuracy. We show that two essential components of the system produce these results: a sufficiently large and diverse, in-domain labeled dataset, and a neural network-based, pre-trained model that generates both verbal responses and API call predictions. In terms of data, we introduce TicketTalk, a movie ticketing dialog dataset with 23,789 annotated conversations. The movie ticketing conversations range from completely open-ended and unrestricted to more structured, both in terms of their knowledge base, discourse features, and number of turns. In qualitative human evaluations, model-generated responses trained on just 10,000 TicketTalk dialogs were rated to "make sense" 86.5 percent of the time, almost the same as human responses in the same contexts. Our simple, API-focused annotation schema results in a much easier labeling task making it faster and more cost effective. It is also the key component for being able to predict API calls accurately. We handle factual grounding by incorporating API calls in the training data, allowing our model to learn which actions to take and when. Trained on the same 10,000-dialog set, the model's API call predictions were rated to be correct 93.9 percent of the time in our evaluations, surpassing the ratings for the corresponding human labels. We show how API prediction and response generation scores improve as the dataset size incrementally increases from 5000 to 21,000 dialogs. Our analysis also clearly illustrates the benefits of pre-training. We are publicly releasing the TicketTalk dataset with this paper to facilitate future work on transaction-based dialogs.