 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Feature Engineering for Scalable Application-Level Post-Silicon Debugging
Feb 08, 2021
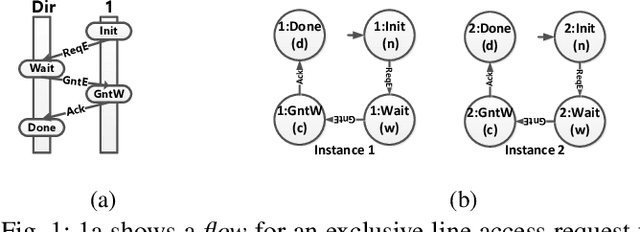
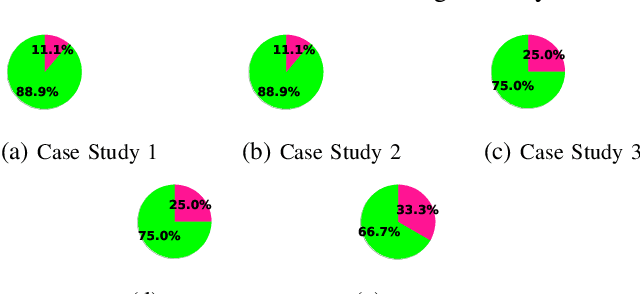
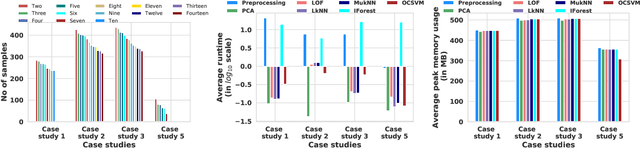
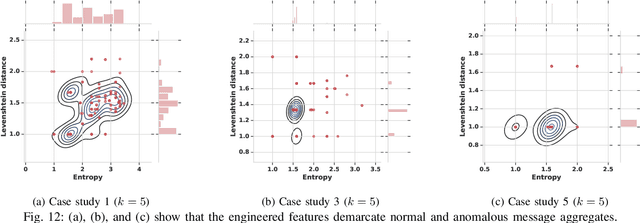
We present systematic and efficient solutions for both observability enhancement and root-cause diagnosis of post-silicon System-on-Chips (SoCs) validation with diverse usage scenarios. We model specification of interacting flows in typical applications for message selection. Our method for message selection optimizes flow specification coverage and trace buffer utilization. We define the diagnosis problem as identifying buggy traces as outliers and bug-free traces as inliers/normal behaviors, for which we use unsupervised learning algorithms for outlier detection. Instead of direct application of machine learning algorithms over trace data using the signals as raw features, we use feature engineering to transform raw features into more sophisticated features using domain specific operations. The engineered features are highly relevant to the diagnosis task and are generic to be applied across any hardware designs. We present debugging and root cause analysis of subtle post-silicon bugs in industry-scale OpenSPARC T2 SoC. We achieve a trace buffer utilization of 98.96\% with a flow specification coverage of 94.3\% (average). Our diagnosis method was able to diagnose up to 66.7\% more bugs and took up to 847$\times$ less diagnosis time as compared to the manual debugging with a diagnosis precision of 0.769.
Texture image classification based on a pseudo-parabolic diffusion model
Nov 14, 2020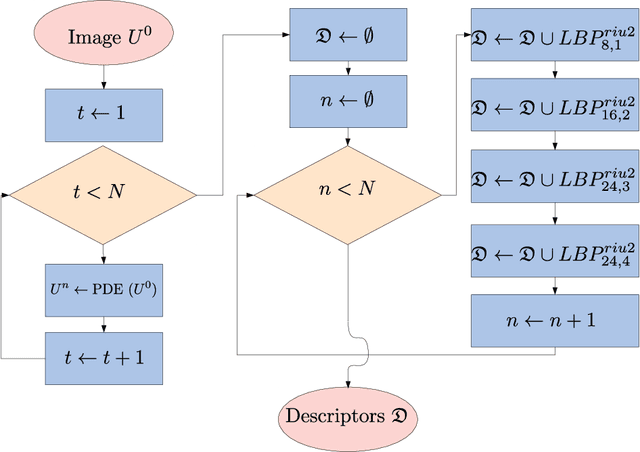
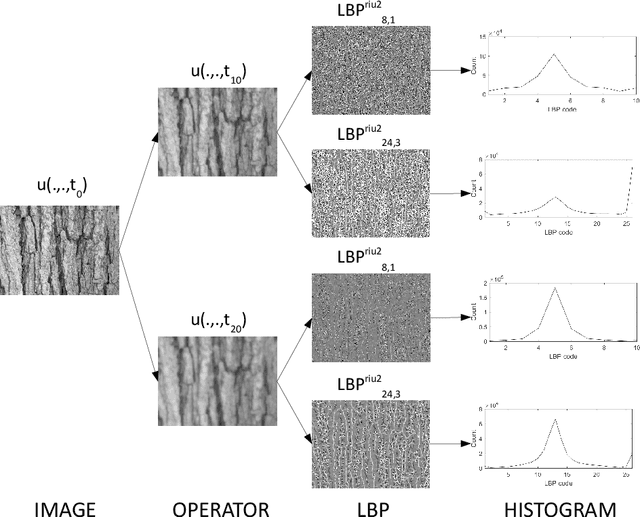
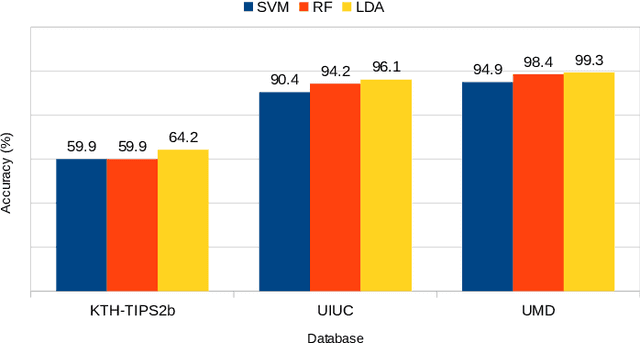
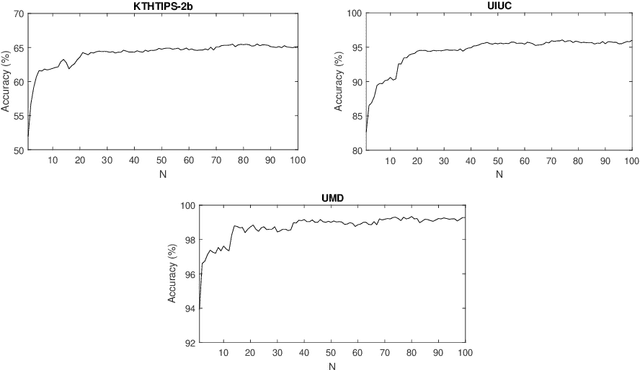
This work proposes a novel method based on a pseudo-parabolic diffusion process to be employed for texture recognition. The proposed operator is applied over a range of time scales giving rise to a family of images transformed by nonlinear filters. Therefore each of those images are encoded by a local descriptor (we use local binary patterns for that purpose) and they are summarized by a simple histogram, yielding in this way the image feature vector. The proposed approach is tested on the classification of well established benchmark texture databases and on a practical task of plant species recognition. In both cases, it is compared with several state-of-the-art methodologies employed for texture recognition. Our proposal outperforms those methods in terms of classification accuracy, confirming its competitiveness. The good performance can be justified to a large extent by the ability of the pseudo-parabolic operator to smooth possibly noisy details inside homogeneous regions of the image at the same time that it preserves discontinuities that convey critical information for the object description. Such results also confirm that model-based approaches like the proposed one can still be competitive with the omnipresent learning-based approaches, especially when the user does not have access to a powerful computational structure and a large amount of labeled data for training.
Optimized 2D CA-CFAR for Drone-Mounted Radar Signal Processing Using Integral Image Algorithm
Dec 21, 2020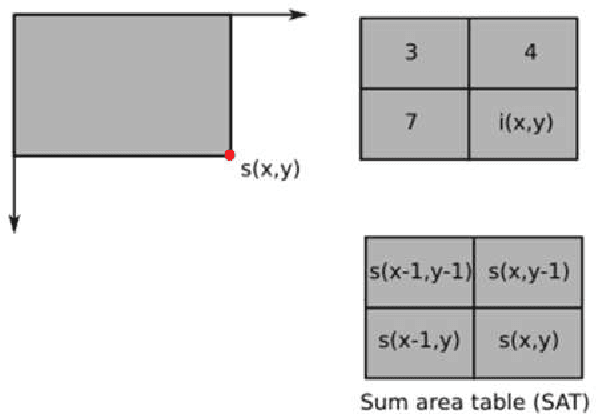
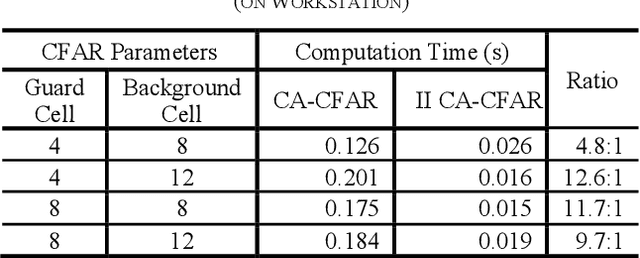

Buried survivor detection in the post-disaster environment by employing radar as sensor is an appealing approach. However, the implementation in the real field is challenging especially for large observation missions. Mounting the radar on the flying drone is the most promising solution. In this case, since the limitations of drones such as low computer specification and limited power resources, an efficient radar data processing is crucially required. Hence, this paper study about the implementation of the integral image technique to optimize the computation of the signal processing step of ultra-wideband impulse radar signatures. The evaluation was held on the single board computer mounted on the developed multisensory drone. The results confirm that the developed method can relatively reduce the data processing time.
Learning Causality: Synthesis of Large-Scale Causal Networks from High-Dimensional Time Series Data
May 06, 2019
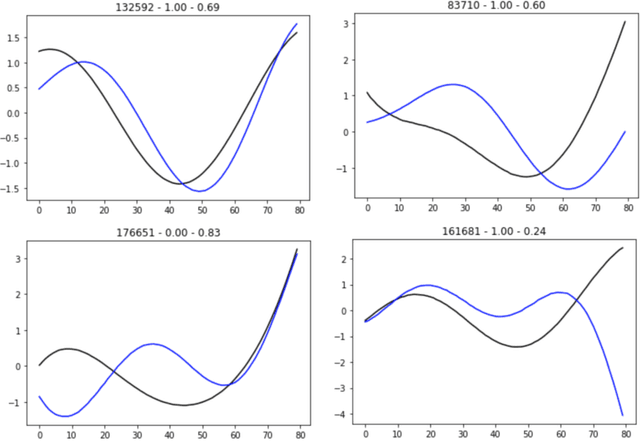
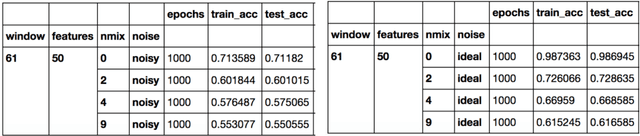
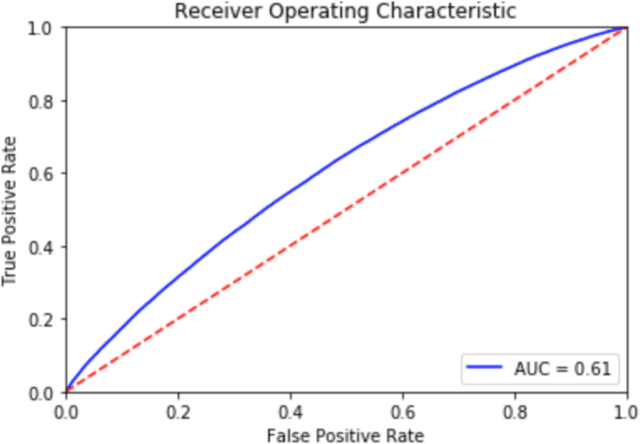
There is an abundance of complex dynamic systems that are critical to our daily lives and our society but that are hardly understood, and even with today's possibilities to sense and collect large amounts of experimental data, they are so complex and continuously evolving that it is unlikely that their dynamics will ever be understood in full detail. Nevertheless, through computational tools we can try to make the best possible use of the current technologies and available data. We believe that the most useful models will have to take into account the imbalance between system complexity and available data in the context of limited knowledge or multiple hypotheses. The complex system of biological cells is a prime example of such a system that is studied in systems biology and has motivated the methods presented in this paper. They were developed as part of the DARPA Rapid Threat Assessment (RTA) program, which is concerned with understanding of the mechanism of action (MoA) of toxins or drugs affecting human cells. Using a combination of Gaussian processes and abstract network modeling, we present three fundamentally different machine-learning-based approaches to learn causal relations and synthesize causal networks from high-dimensional time series data. While other types of data are available and have been analyzed and integrated in our RTA work, we focus on transcriptomics (that is gene expression) data obtained from high-throughput microarray experiments in this paper to illustrate capabilities and limitations of our algorithms. Our algorithms make different but overall relatively few biological assumptions, so that they are applicable to other types of biological data and potentially even to other complex systems that exhibit high dimensionality but are not of biological nature.
High Dynamic Range SLAM with Map-Aware Exposure Time Control
Apr 20, 2018
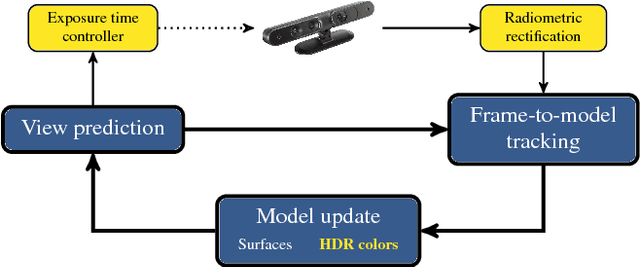
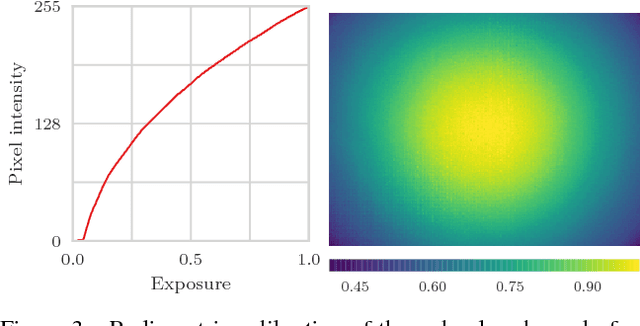
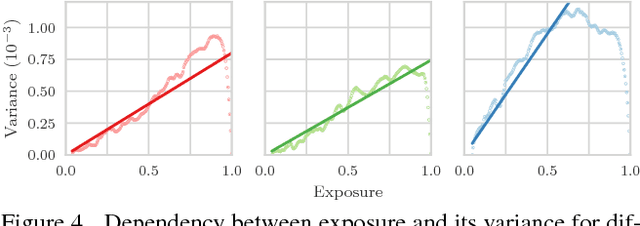
The research in dense online 3D mapping is mostly focused on the geometrical accuracy and spatial extent of the reconstructions. Their color appearance is often neglected, leading to inconsistent colors and noticeable artifacts. We rectify this by extending a state-of-the-art SLAM system to accumulate colors in HDR space. We replace the simplistic pixel intensity averaging scheme with HDR color fusion rules tailored to the incremental nature of SLAM and a noise model suitable for off-the-shelf RGB-D cameras. Our main contribution is a map-aware exposure time controller. It makes decisions based on the global state of the map and predicted camera motion, attempting to maximize the information gain of each observation. We report a set of experiments demonstrating the improved texture quality and advantages of using the custom controller that is tightly integrated in the mapping loop.
Active learning for object detection in high-resolution satellite images
Jan 07, 2021
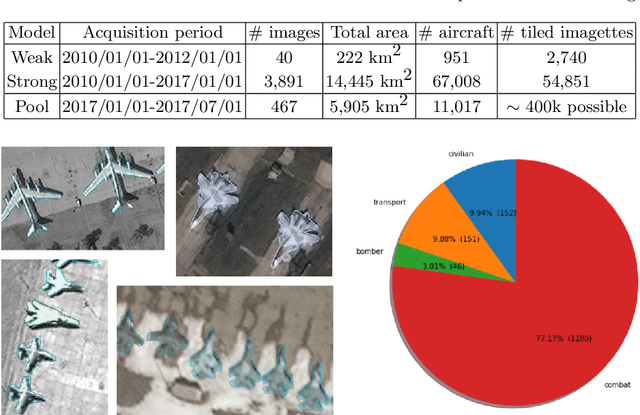
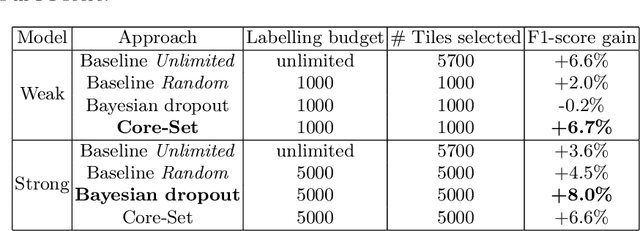
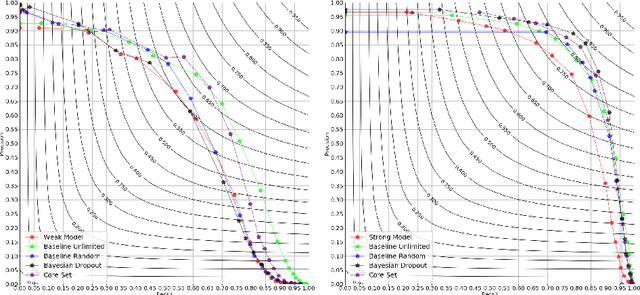
In machine learning, the term active learning regroups techniques that aim at selecting the most useful data to label from a large pool of unlabelled examples. While supervised deep learning techniques have shown to be increasingly efficient on many applications, they require a huge number of labelled examples to reach operational performances. Therefore, the labelling effort linked to the creation of the datasets required is also increasing. When working on defense-related remote sensing applications, labelling can be challenging due to the large areas covered and often requires military experts who are rare and whose time is primarily dedicated to operational needs. Limiting the labelling effort is thus of utmost importance. This study aims at reviewing the most relevant active learning techniques to be used for object detection on very high resolution imagery and shows an example of the value of such techniques on a relevant operational use case: aircraft detection.
Toward Effective Automated Content Analysis via Crowdsourcing
Jan 12, 2021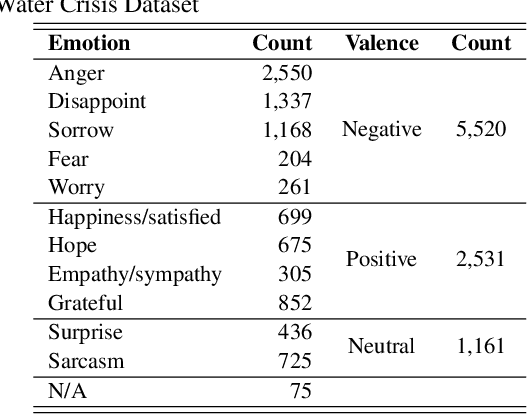
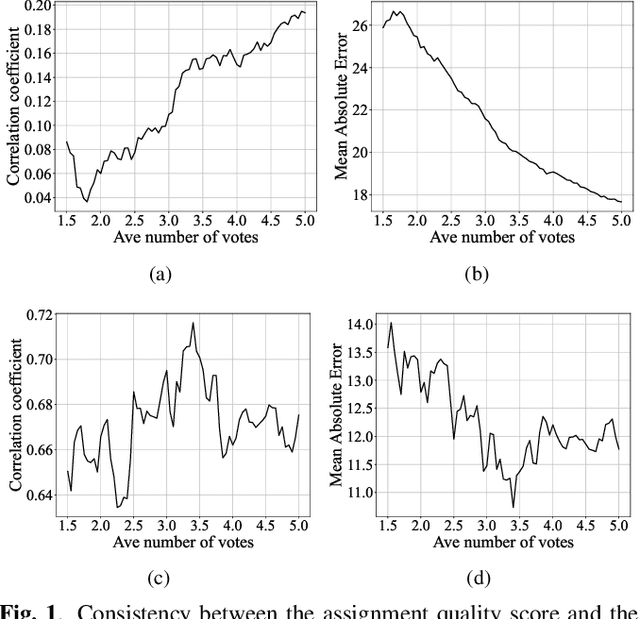
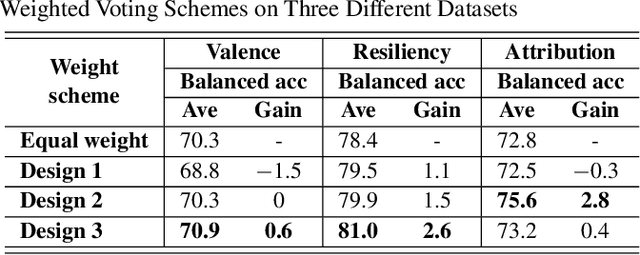
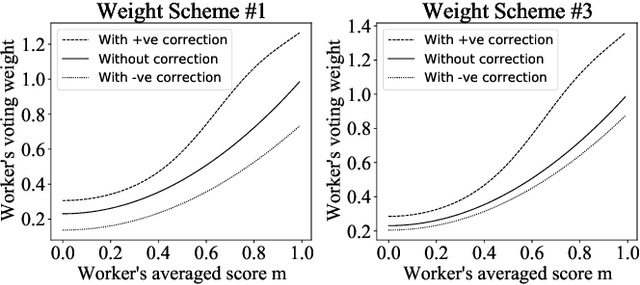
Many computer scientists use the aggregated answers of online workers to represent ground truth. Prior work has shown that aggregation methods such as majority voting are effective for measuring relatively objective features. For subjective features such as semantic connotation, online workers, known for optimizing their hourly earnings, tend to deteriorate in the quality of their responses as they work longer. In this paper, we aim to address this issue by proposing a quality-aware semantic data annotation system. We observe that with timely feedback on workers' performance quantified by quality scores, better informed online workers can maintain the quality of their labeling throughout an extended period of time. We validate the effectiveness of the proposed annotation system through i) evaluating performance based on an expert-labeled dataset, and ii) demonstrating machine learning tasks that can lead to consistent learning behavior with 70%-80% accuracy. Our results suggest that with our system, researchers can collect high-quality answers of subjective semantic features at a large scale.
Accurate Learning of Graph Representations with Graph Multiset Pooling
Feb 23, 2021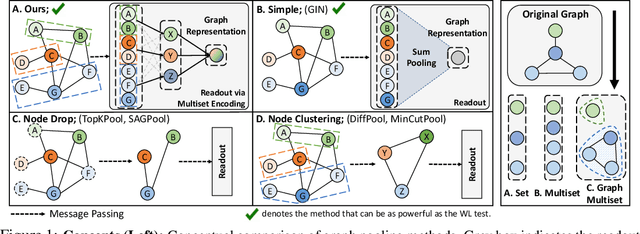
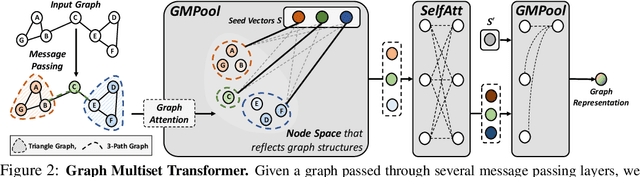
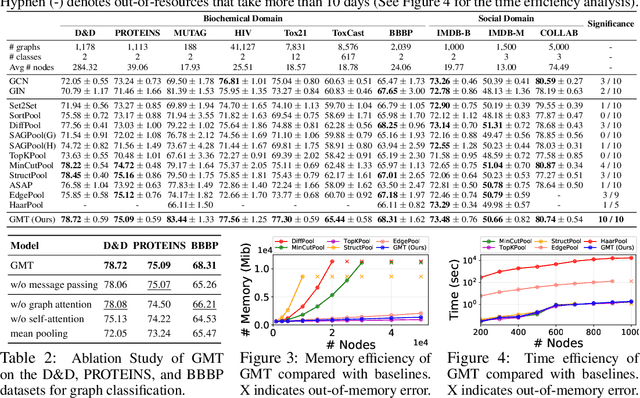
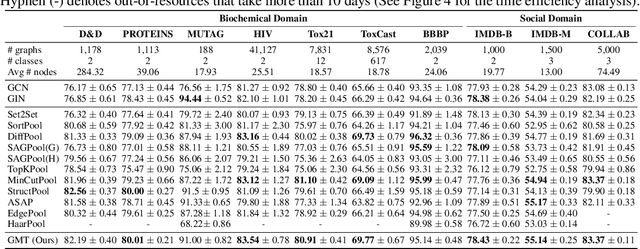
Graph neural networks have been widely used on modeling graph data, achieving impressive results on node classification and link prediction tasks. Yet, obtaining an accurate representation for a graph further requires a pooling function that maps a set of node representations into a compact form. A simple sum or average over all node representations considers all node features equally without consideration of their task relevance, and any structural dependencies among them. Recently proposed hierarchical graph pooling methods, on the other hand, may yield the same representation for two different graphs that are distinguished by the Weisfeiler-Lehman test, as they suboptimally preserve information from the node features. To tackle these limitations of existing graph pooling methods, we first formulate the graph pooling problem as a multiset encoding problem with auxiliary information about the graph structure, and propose a Graph Multiset Transformer (GMT) which is a multi-head attention based global pooling layer that captures the interaction between nodes according to their structural dependencies. We show that GMT satisfies both injectiveness and permutation invariance, such that it is at most as powerful as the Weisfeiler-Lehman graph isomorphism test. Moreover, our methods can be easily extended to the previous node clustering approaches for hierarchical graph pooling. Our experimental results show that GMT significantly outperforms state-of-the-art graph pooling methods on graph classification benchmarks with high memory and time efficiency, and obtains even larger performance gain on graph reconstruction and generation tasks.
uTHCD: A New Benchmarking for Tamil Handwritten OCR
Mar 13, 2021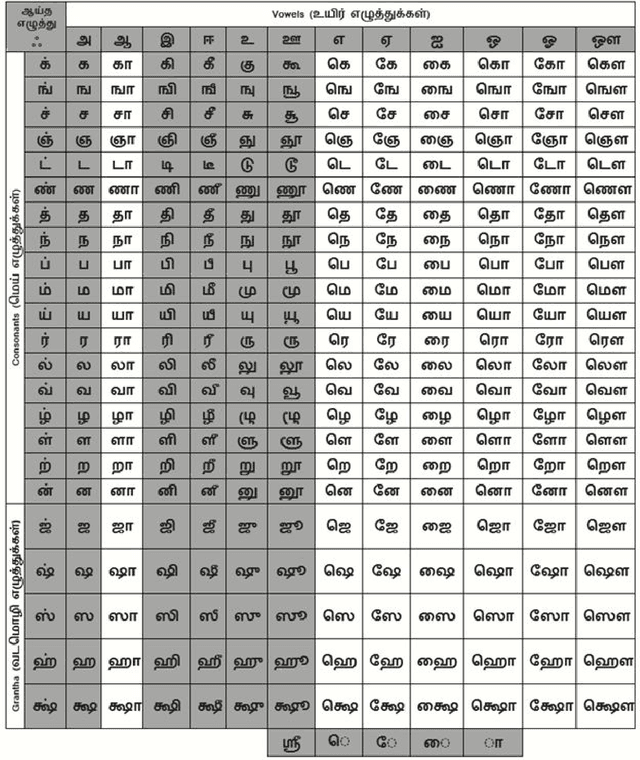
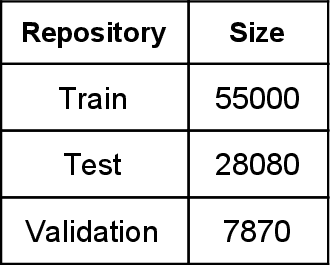
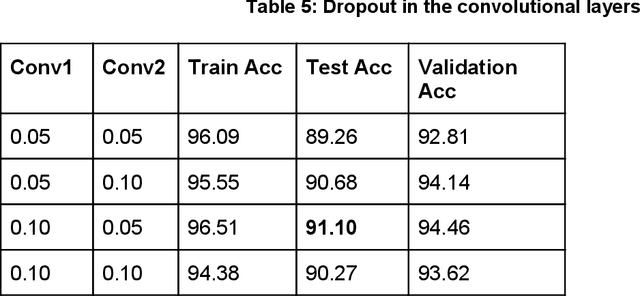
Handwritten character recognition is a challenging research in the field of document image analysis over many decades due to numerous reasons such as large writing styles variation, inherent noise in data, expansive applications it offers, non-availability of benchmark databases etc. There has been considerable work reported in literature about creation of the database for several Indic scripts but the Tamil script is still in its infancy as it has been reported only in one database [5]. In this paper, we present the work done in the creation of an exhaustive and large unconstrained Tamil Handwritten Character Database (uTHCD). Database consists of around 91000 samples with nearly 600 samples in each of 156 classes. The database is a unified collection of both online and offline samples. Offline samples were collected by asking volunteers to write samples on a form inside a specified grid. For online samples, we made the volunteers write in a similar grid using a digital writing pad. The samples collected encompass a vast variety of writing styles, inherent distortions arising from offline scanning process viz stroke discontinuity, variable thickness of stroke, distortion etc. Algorithms which are resilient to such data can be practically deployed for real time applications. The samples were generated from around 650 native Tamil volunteers including school going kids, homemakers, university students and faculty. The isolated character database will be made publicly available as raw images and Hierarchical Data File (HDF) compressed file. With this database, we expect to set a new benchmark in Tamil handwritten character recognition and serve as a launchpad for many avenues in document image analysis domain. Paper also presents an ideal experimental set-up using the database on convolutional neural networks (CNN) with a baseline accuracy of 88% on test data.
Layer Pruning via Fusible Residual Convolutional Block for Deep Neural Networks
Nov 29, 2020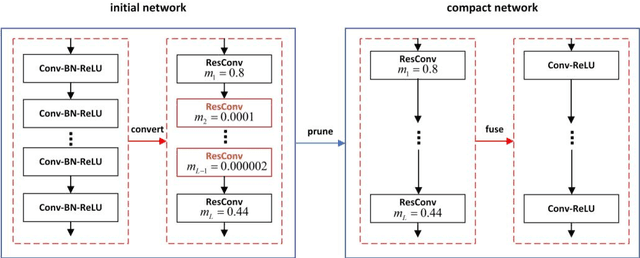
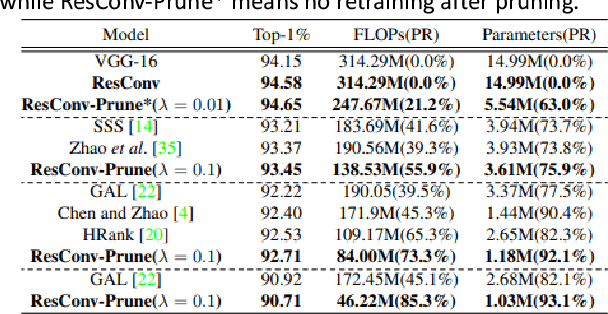
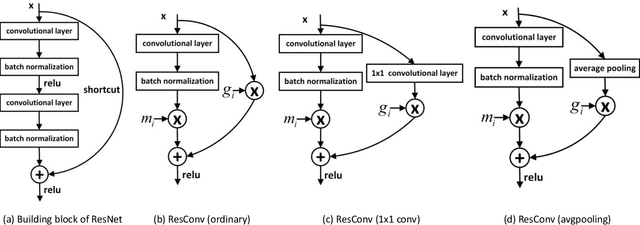
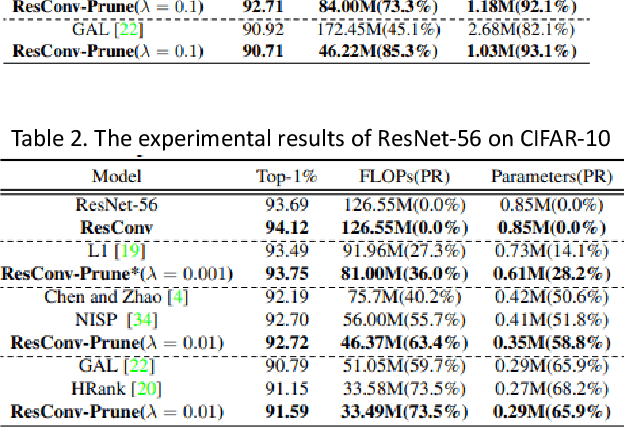
In order to deploy deep convolutional neural networks (CNNs) on resource-limited devices, many model pruning methods for filters and weights have been developed, while only a few to layer pruning. However, compared with filter pruning and weight pruning, the compact model obtained by layer pruning has less inference time and run-time memory usage when the same FLOPs and number of parameters are pruned because of less data moving in memory. In this paper, we propose a simple layer pruning method using fusible residual convolutional block (ResConv), which is implemented by inserting shortcut connection with a trainable information control parameter into a single convolutional layer. Using ResConv structures in training can improve network accuracy and train deep plain networks, and adds no additional computation during inference process because ResConv is fused to be an ordinary convolutional layer after training. For layer pruning, we convert convolutional layers of network into ResConv with a layer scaling factor. In the training process, the L1 regularization is adopted to make the scaling factors sparse, so that unimportant layers are automatically identified and then removed, resulting in a model of layer reduction. Our pruning method achieves excellent performance of compression and acceleration over the state-of-the-arts on different datasets, and needs no retraining in the case of low pruning rate. For example, with ResNet-110, we achieve a 65.5%-FLOPs reduction by removing 55.5% of the parameters, with only a small loss of 0.13% in top-1 accuracy on CIFAR-10.