 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Video action recognition for lane-change classification and prediction of surrounding vehicles
Jan 13, 2021
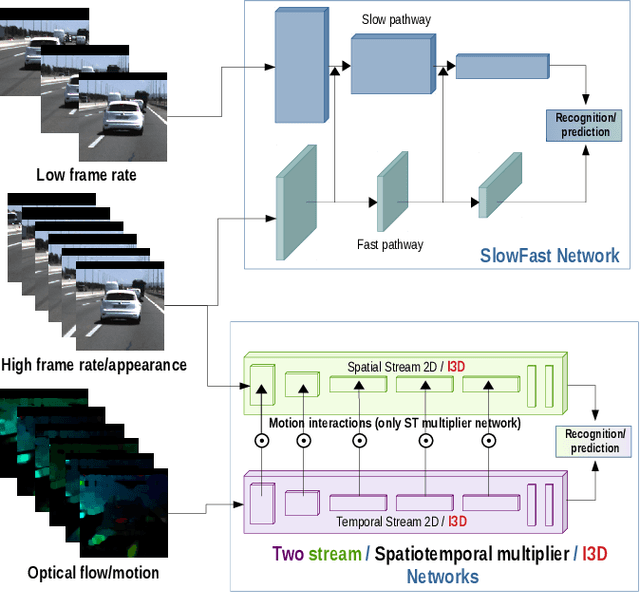
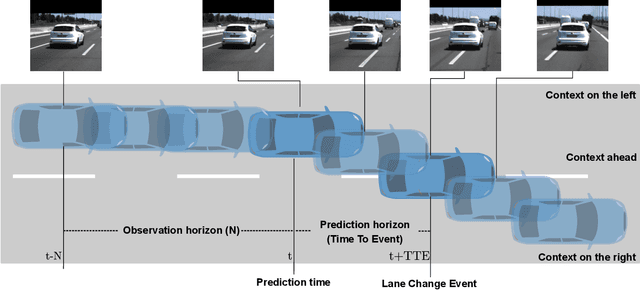


In highway scenarios, an alert human driver will typically anticipate early cut-in/cut-out maneuvers of surrounding vehicles using visual cues mainly. Autonomous vehicles must anticipate these situations at an early stage too, to increase their safety and efficiency. In this work, lane-change recognition and prediction tasks are posed as video action recognition problems. Up to four different two-stream-based approaches, that have been successfully applied to address human action recognition, are adapted here by stacking visual cues from forward-looking video cameras to recognize and anticipate lane-changes of target vehicles. We study the influence of context and observation horizons on performance, and different prediction horizons are analyzed. The different models are trained and evaluated using the PREVENTION dataset. The obtained results clearly demonstrate the potential of these methodologies to serve as robust predictors of future lane-changes of surrounding vehicles proving an accuracy higher than 90% in time horizons of between 1-2 seconds.
Learning to Make Compiler Optimizations More Effective
Feb 24, 2021


Because loops execute their body many times, compiler developers place much emphasis on their optimization. Nevertheless, in view of highly diverse source code and hardware, compilers still struggle to produce optimal target code. The sheer number of possible loop optimizations, including their combinations, exacerbates the problem further. Today's compilers use hard-coded heuristics to decide when, whether, and which of a limited set of optimizations to apply. Often, this leads to highly unstable behavior, making the success of compiler optimizations dependent on the precise way a loop has been written. This paper presents LoopLearner, which addresses the problem of compiler instability by predicting which way of writing a loop will lead to efficient compiled code. To this end, we train a neural network to find semantically invariant source-level transformations for loops that help the compiler generate more efficient code. Our model learns to extract useful features from the raw source code and predicts the speedup that a given transformation is likely to yield. We evaluate LoopLearner with 1,895 loops from various performance-relevant benchmarks. Applying the transformations that our model deems most favorable prior to compilation yields an average speedup of 1.14x. When trying the top-3 suggested transformations, the average speedup even increases to 1.29x. Comparing the approach with an exhaustive search through all available code transformations shows that LoopLearner helps to identify the most beneficial transformations in several orders of magnitude less time.
An Empirical Study on Model-agnostic Debiasing Strategies for Robust Natural Language Inference
Oct 17, 2020
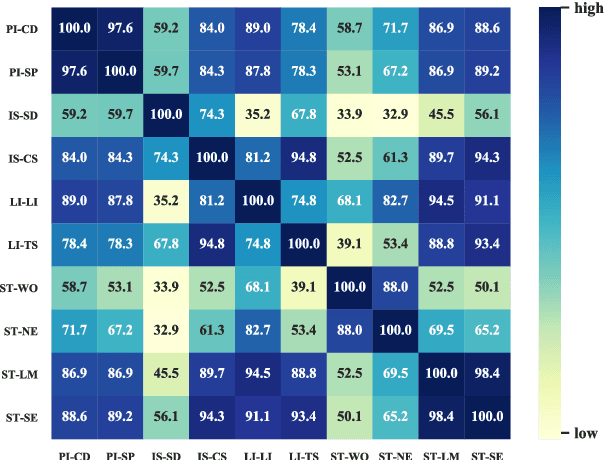
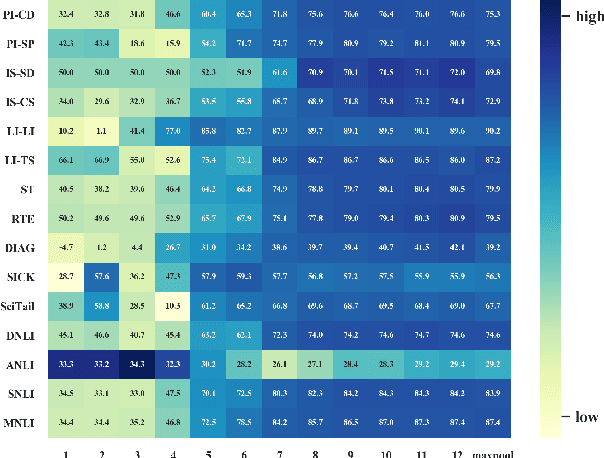
The prior work on natural language inference (NLI) debiasing mainly targets at one or few known biases while not necessarily making the models more robust. In this paper, we focus on the model-agnostic debiasing strategies and explore how to (or is it possible to) make the NLI models robust to multiple distinct adversarial attacks while keeping or even strengthening the models' generalization power. We firstly benchmark prevailing neural NLI models including pretrained ones on various adversarial datasets. We then try to combat distinct known biases by modifying a mixture of experts (MoE) ensemble method and show that it's nontrivial to mitigate multiple NLI biases at the same time, and that model-level ensemble method outperforms MoE ensemble method. We also perform data augmentation including text swap, word substitution and paraphrase and prove its efficiency in combating various (though not all) adversarial attacks at the same time. Finally, we investigate several methods to merge heterogeneous training data (1.35M) and perform model ensembling, which are straightforward but effective to strengthen NLI models.
Orbital Stabilization of Point-to-Point Maneuvers in Underactuated Mechanical Systems
Feb 09, 2021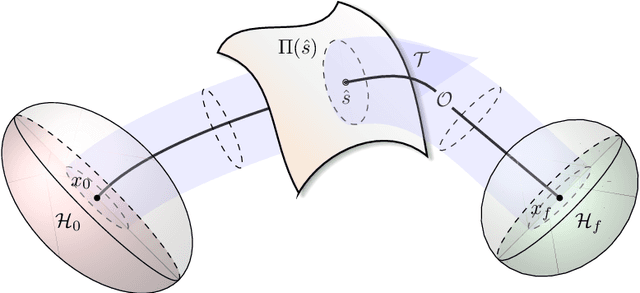
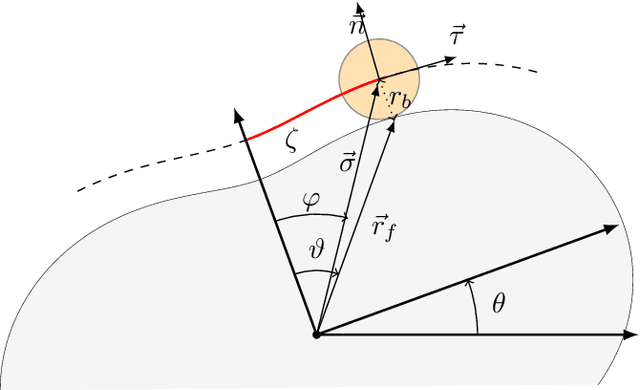
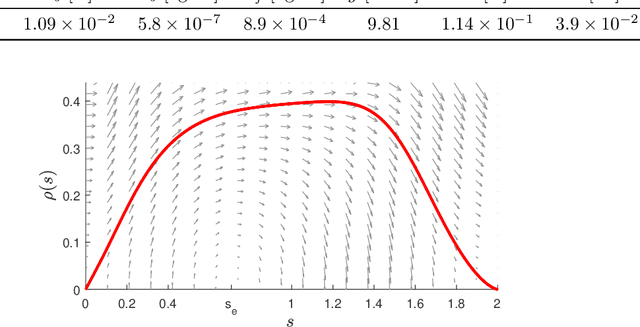
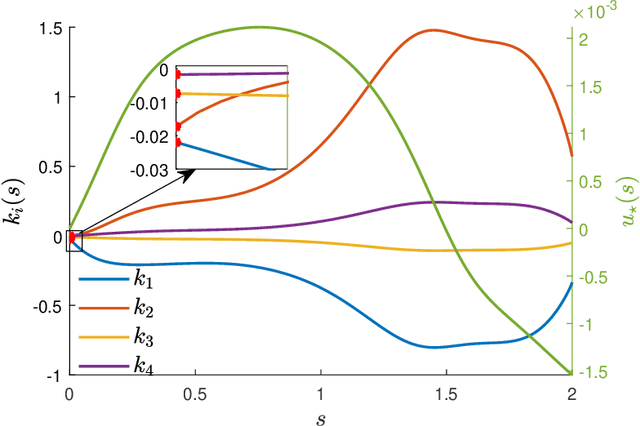
The task of inducing, via continuous static state-feedback, an asymptotically stable heteroclinic orbit in a nonlinear control system is considered in this paper. The main motivation comes from the problem of ensuring convergence to a so-called point-to-point maneuver in an underactuated mechanical system, that is, to a smooth curve in its state--control space that is consistent with the system dynamics and which connects two stabilizable equilibrium points. The proposed method uses a particular parameterization, together with a state projection onto the maneuver's orbit as to combine two linearization techniques for this purpose: the Jacobian linearization at the equilibria on the boundaries and a transverse linearization along the orbit. This allows for the computation of stabilizing control gains offline by solving a semidefinite programming problem. The resulting nonlinear controller, which simultaneously asymptotically stabilizes both the orbit and the final equilibrium, is time-invariant, locally Lipschitz continuous, requires no switching and has a familiar feedforward plus feedback--like structure. The method is also complemented by synchronization function--based arguments for planning such maneuvers for mechanical systems with one degree of underactuation. Numeric simulations of the non-prehensile manipulation task of a ball rolling between two points upon the "butterfly" robot demonstrates the efficacy of the full synthesis.
Are Adaptive Face Recognition Systems still Necessary? Experiments on the APE Dataset
Oct 17, 2020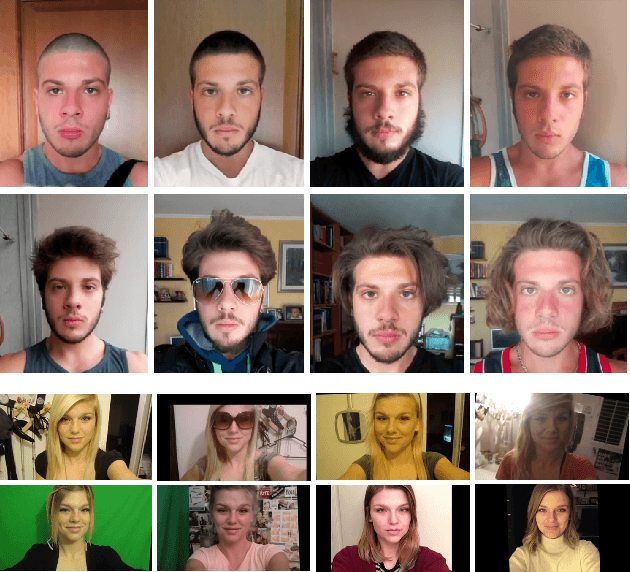

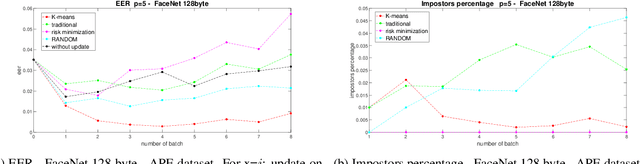
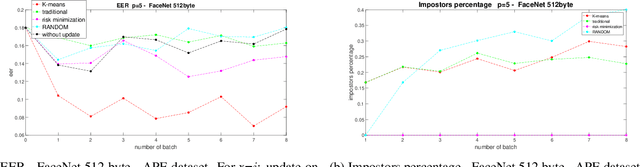
In the last five years, deep learning methods, in particular CNN, have attracted considerable attention in the field of face-based recognition, achieving impressive results. Despite this progress, it is not yet clear precisely to what extent deep features are able to follow all the intra-class variations that the face can present over time. In this paper we investigate the performance the performance improvement of face recognition systems by adopting self updating strategies of the face templates. For that purpose, we evaluate the performance of a well-known deep-learning face representation, namely, FaceNet, on a dataset that we generated explicitly conceived to embed intra-class variations of users on a large time span of captures: the APhotoEveryday (APE) dataset. Moreover, we compare these deep features with handcrafted features extracted using the BSIF algorithm. In both cases, we evaluate various template update strategies, in order to detect the most useful for such kind of features. Experimental results show the effectiveness of "optimized" self-update methods with respect to systems without update or random selection of templates.
Learning Low-Correlation GPS Spreading Codes with a Policy Gradient Algorithm
Jan 08, 2021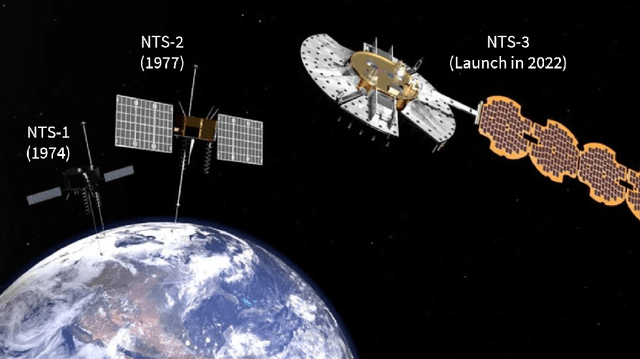
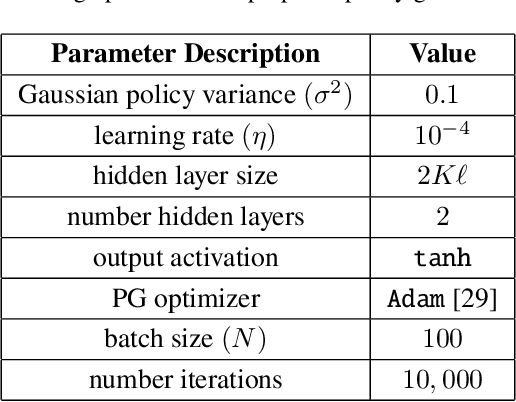
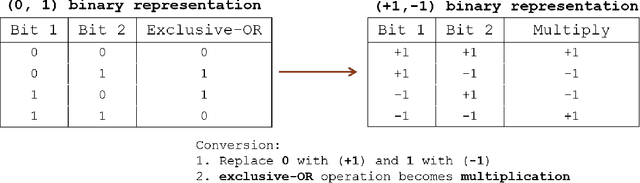
With the birth of the next-generation GPS III constellation and the upcoming launch of the Navigation Technology Satellite-3 (NTS-3) testing platform to explore future technologies for GPS, we are indeed entering a new era of satellite navigation. Correspondingly, it is time to revisit the design methods of the GPS spreading code families. In this work, we develop a Gaussian policy gradient-based reinforcement learning algorithm which constructs high-quality families of spreading code sequences. We demonstrate the ability of our algorithm to achieve better mean-squared auto- and cross-correlation than well-chosen families of equal-length Gold codes and Weil codes. Furthermore, we compare our algorithm with an analogous genetic algorithm implementation assigned the same code evaluation metric. To the best of the authors' knowledge, this is the first work to explore using a machine learning / reinforcement learning approach to design navigation spreading codes.
Sequence-based Dynamic Handwriting Analysis for Parkinson's Disease Detection with One-dimensional Convolutions and BiGRUs
Jan 23, 2021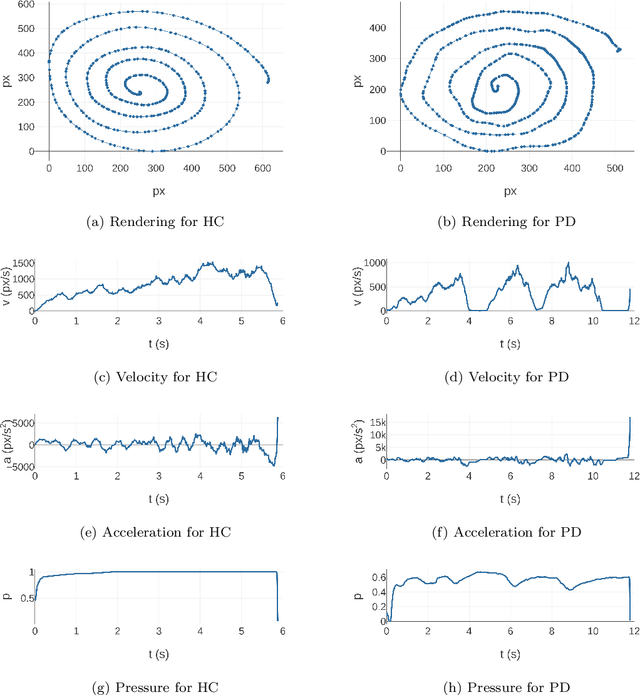

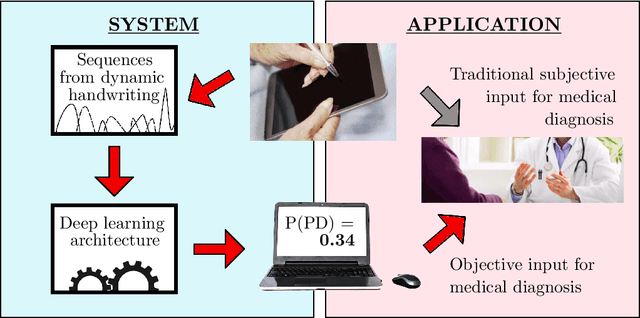
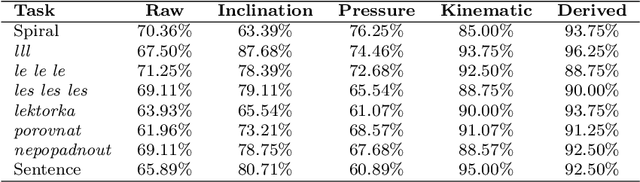
Parkinson's disease (PD) is commonly characterized by several motor symptoms, such as bradykinesia, akinesia, rigidity, and tremor. The analysis of patients' fine motor control, particularly handwriting, is a powerful tool to support PD assessment. Over the years, various dynamic attributes of handwriting, such as pen pressure, stroke speed, in-air time, etc., which can be captured with the help of online handwriting acquisition tools, have been evaluated for the identification of PD. Motion events, and their associated spatio-temporal properties captured in online handwriting, enable effective classification of PD patients through the identification of unique sequential patterns. This paper proposes a novel classification model based on one-dimensional convolutions and Bidirectional Gated Recurrent Units (BiGRUs) to assess the potential of sequential information of handwriting in identifying Parkinsonian symptoms. One-dimensional convolutions are applied to raw sequences as well as derived features; the resulting sequences are then fed to BiGRU layers to achieve the final classification. The proposed method outperformed state-of-the-art approaches on the PaHaW dataset and achieved competitive results on the NewHandPD dataset.
A Tree-structure Convolutional Neural Network for Temporal Features Exaction on Sensor-based Multi-resident Activity Recognition
Nov 05, 2020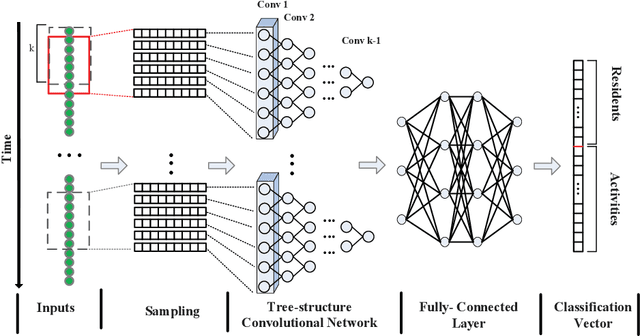
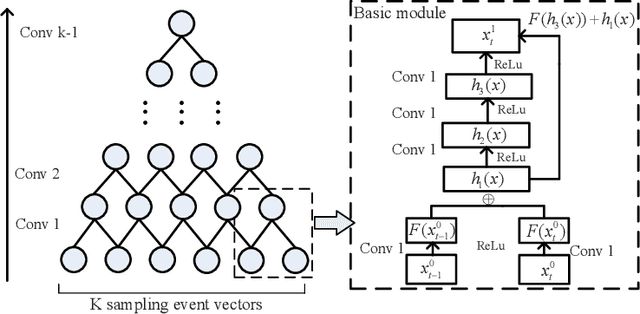
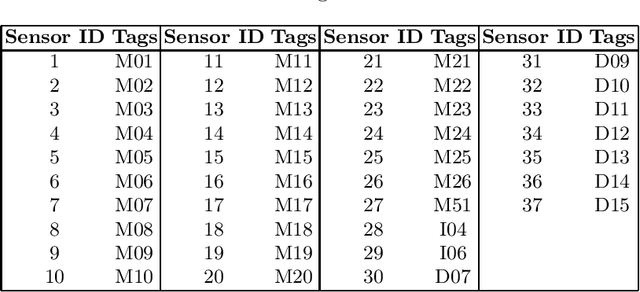
With the propagation of sensor devices applied in smart home, activity recognition has ignited huge interest and most existing works assume that there is only one habitant. While in reality, there are generally multiple residents at home, which brings greater challenge to recognize activities. In addition, many conventional approaches rely on manual time series data segmentation ignoring the inherent characteristics of events and their heuristic hand-crafted feature generation algorithms are difficult to exploit distinctive features to accurately classify different activities. To address these issues, we propose an end-to-end Tree-Structure Convolutional neural network based framework for Multi-Resident Activity Recognition (TSC-MRAR). First, we treat each sample as an event and obtain the current event embedding through the previous sensor readings in the sliding window without splitting the time series data. Then, in order to automatically generate the temporal features, a tree-structure network is designed to derive the temporal dependence of nearby readings. The extracted features are fed into the fully connected layer, which can jointly learn the residents labels and the activity labels simultaneously. Finally, experiments on CASAS datasets demonstrate the high performance in multi-resident activity recognition of our model compared to state-of-the-art techniques.
* 12 pages, 4 figures
PECNet: A Deep Multi-Label Segmentation Network for Eosinophilic Esophagitis Biopsy Diagnostics
Mar 02, 2021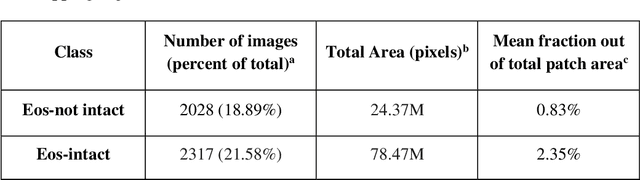
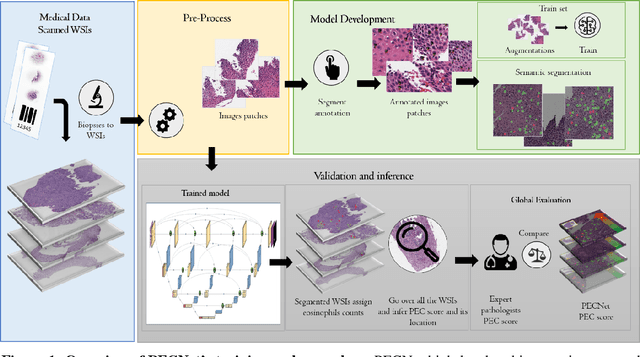
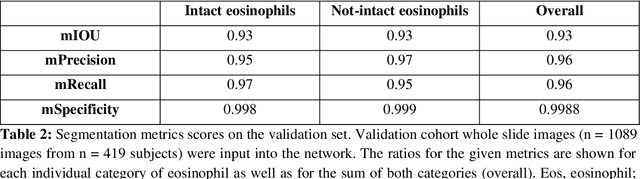
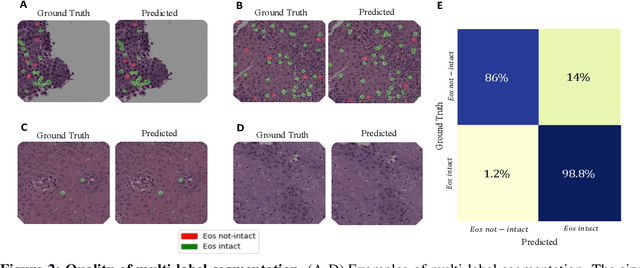
Background. Eosinophilic esophagitis (EoE) is an allergic inflammatory condition of the esophagus associated with elevated numbers of eosinophils. Disease diagnosis and monitoring requires determining the concentration of eosinophils in esophageal biopsies, a time-consuming, tedious and somewhat subjective task currently performed by pathologists. Methods. Herein, we aimed to use machine learning to identify, quantitate and diagnose EoE. We labeled more than 100M pixels of 4345 images obtained by scanning whole slides of H&E-stained sections of esophageal biopsies derived from 23 EoE patients. We used this dataset to train a multi-label segmentation deep network. To validate the network, we examined a replication cohort of 1089 whole slide images from 419 patients derived from multiple institutions. Findings. PECNet segmented both intact and not-intact eosinophils with a mean intersection over union (mIoU) of 0.93. This segmentation was able to quantitate intact eosinophils with a mean absolute error of 0.611 eosinophils and classify EoE disease activity with an accuracy of 98.5%. Using whole slide images from the validation cohort, PECNet achieved an accuracy of 94.8%, sensitivity of 94.3%, and specificity of 95.14% in reporting EoE disease activity. Interpretation. We have developed a deep learning multi-label semantic segmentation network that successfully addresses two of the main challenges in EoE diagnostics and digital pathology, the need to detect several types of small features simultaneously and the ability to analyze whole slides efficiently. Our results pave the way for an automated diagnosis of EoE and can be utilized for other conditions with similar challenges.
Predictive Process Model Monitoring using Recurrent Neural Networks
Nov 05, 2020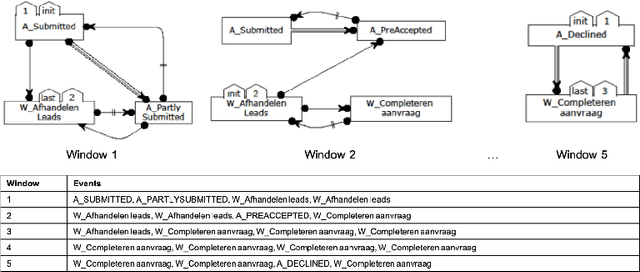
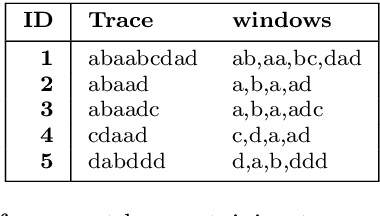
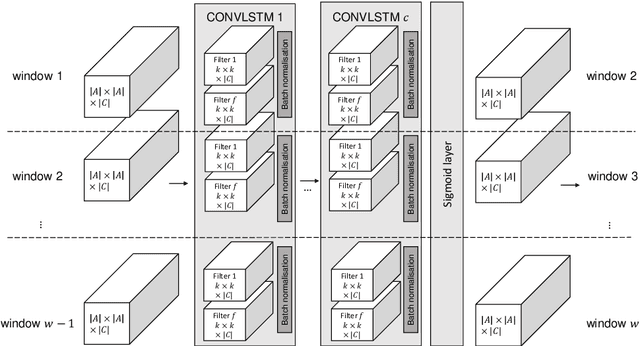
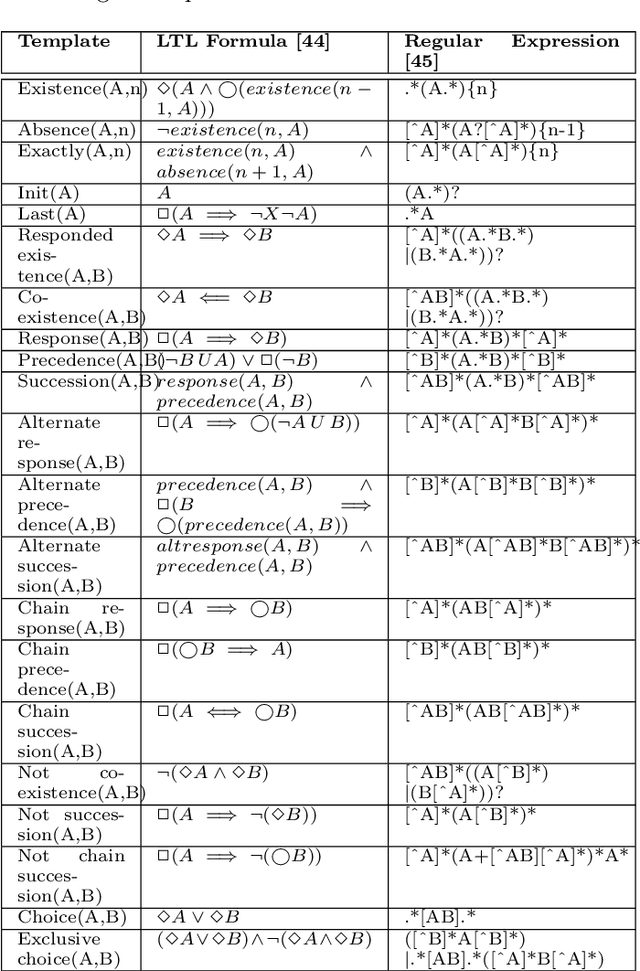
The field of predictive process monitoring focuses on modelling future characteristics of running business process instances, typically by either predicting the outcome of particular objectives (e.g. completion (time), cost), or next-in-sequence prediction (e.g. what is the next activity to execute). This paper introduces Processes-As-Movies (PAM), a technique that provides a middle ground between these predictive monitoring. It does so by capturing declarative process constraints between activities in various windows of a process execution trace, which represent a declarative process model at subsequent stages of execution. This high-dimensional representation of a process model allows the application of predictive modelling on how such constraints appear and vanish throughout a process' execution. Various recurrent neural network topologies tailored to high-dimensional input are used to model the process model evolution with windows as time steps, including encoder-decoder long short-term memory networks, and convolutional long short-term memory networks. Results show that these topologies are very effective in terms of accuracy and precision to predict a process model's future state, which allows process owners to simultaneously verify what linear temporal logic rules hold in a predicted process window (objective-based), and verify what future execution traces are allowed by all the constraints together (trace-based).