 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Text Line Segmentation for Challenging Handwritten Document Images Using Fully Convolutional Network
Jan 20, 2021



This paper presents a method for text line segmentation of challenging historical manuscript images. These manuscript images contain narrow interline spaces with touching components, interpenetrating vowel signs and inconsistent font types and sizes. In addition, they contain curved, multi-skewed and multi-directed side note lines within a complex page layout. Therefore, bounding polygon labeling would be very difficult and time consuming. Instead we rely on line masks that connect the components on the same text line. Then these line masks are predicted using a Fully Convolutional Network (FCN). In the literature, FCN has been successfully used for text line segmentation of regular handwritten document images. The present paper shows that FCN is useful with challenging manuscript images as well. Using a new evaluation metric that is sensitive to over segmentation as well as under segmentation, testing results on a publicly available challenging handwritten dataset are comparable with the results of a previous work on the same dataset.
Lossless Compression of Efficient Private Local Randomizers
Feb 24, 2021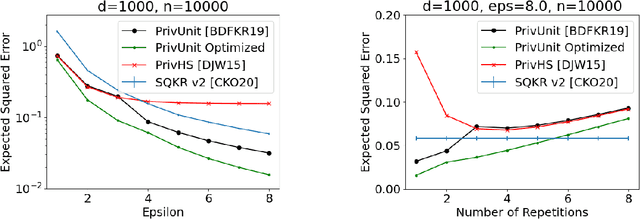
Locally Differentially Private (LDP) Reports are commonly used for collection of statistics and machine learning in the federated setting. In many cases the best known LDP algorithms require sending prohibitively large messages from the client device to the server (such as when constructing histograms over large domain or learning a high-dimensional model). This has led to significant efforts on reducing the communication cost of LDP algorithms. At the same time LDP reports are known to have relatively little information about the user's data due to randomization. Several schemes are known that exploit this fact to design low-communication versions of LDP algorithm but all of them do so at the expense of a significant loss in utility. Here we demonstrate a general approach that, under standard cryptographic assumptions, compresses every efficient LDP algorithm with negligible loss in privacy and utility guarantees. The practical implication of our result is that in typical applications the message can be compressed to the size of the server's pseudo-random generator seed. More generally, we relate the properties of an LDP randomizer to the power of a pseudo-random generator that suffices for compressing the LDP randomizer. From this general approach we derive low-communication algorithms for the problems of frequency estimation and high-dimensional mean estimation. Our algorithms are simpler and more accurate than existing low-communication LDP algorithms for these well-studied problems.
Robust Black-box Watermarking for Deep NeuralNetwork using Inverse Document Frequency
Mar 09, 2021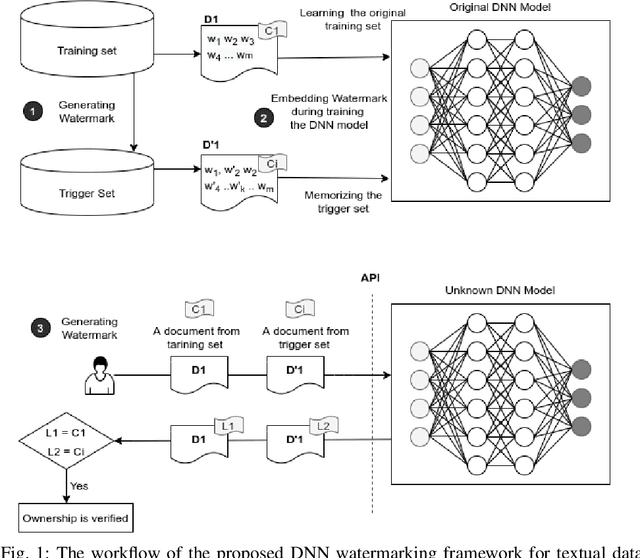
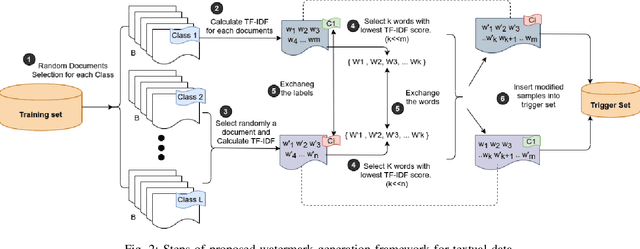

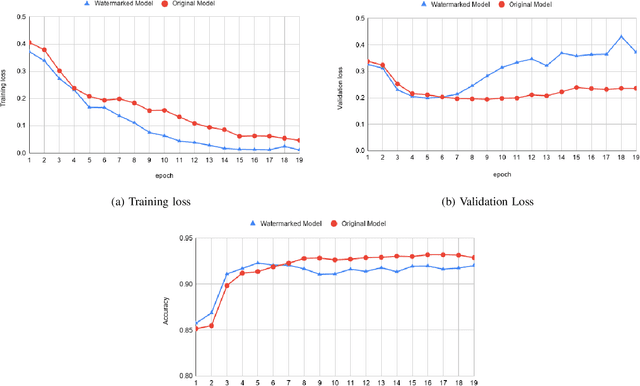
Deep learning techniques are one of the most significant elements of any Artificial Intelligence (AI) services. Recently, these Machine Learning (ML) methods, such as Deep Neural Networks (DNNs), presented exceptional achievement in implementing human-level capabilities for various predicaments, such as Natural Processing Language (NLP), voice recognition, and image processing, etc. Training these models are expensive in terms of computational power and the existence of enough labelled data. Thus, ML-based models such as DNNs establish genuine business value and intellectual property (IP) for their owners. Therefore the trained models need to be protected from any adversary attacks such as illegal redistribution, reproducing, and derivation. Watermarking can be considered as an effective technique for securing a DNN model. However, so far, most of the watermarking algorithm focuses on watermarking the DNN by adding noise to an image. To this end, we propose a framework for watermarking a DNN model designed for a textual domain. The watermark generation scheme provides a secure watermarking method by combining Term Frequency (TF) and Inverse Document Frequency (IDF) of a particular word. The proposed embedding procedure takes place in the model's training time, making the watermark verification stage straightforward by sending the watermarked document to the trained model. The experimental results show that watermarked models have the same accuracy as the original ones. The proposed framework accurately verifies the ownership of all surrogate models without impairing the performance. The proposed algorithm is robust against well-known attacks such as parameter pruning and brute force attack.
Machine Learning for Nondestructive Wear Assessment in Large Internal Combustion Engines
Mar 15, 2021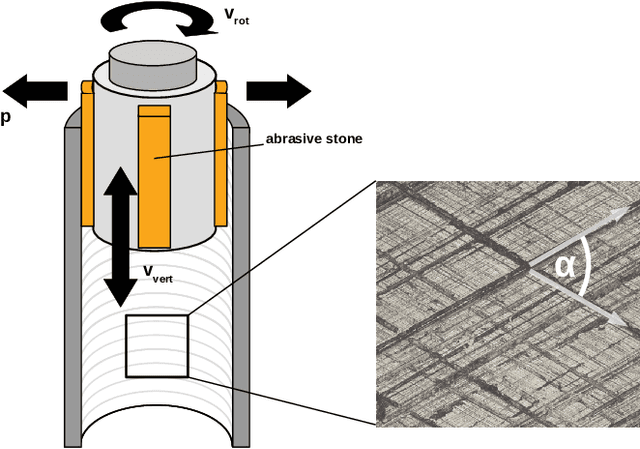
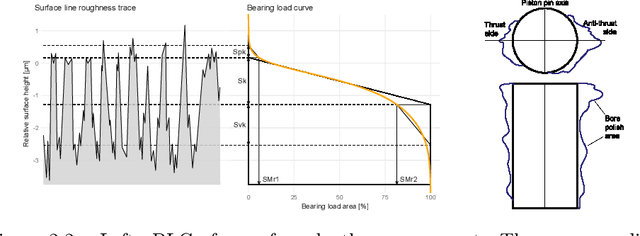

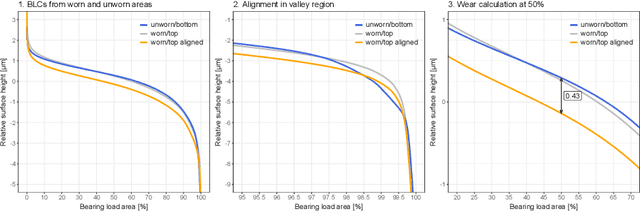
Digitalization offers a large number of promising tools for large internal combustion engines such as condition monitoring or condition-based maintenance. This includes the status evaluation of key engine components such as cylinder liners, whose inner surfaces are subject to constant wear due to their movement relative to the pistons. Existing state-of-the-art methods for quantifying wear require disassembly and cutting of the examined liner followed by a high-resolution microscopic surface depth measurement that quantitatively evaluates wear based on bearing load curves (also known as Abbott-Firestone curves). Such reference methods are destructive, time-consuming and costly. The goal of the research presented here is to develop simpler and nondestructive yet reliable and meaningful methods for evaluating wear condition. A deep-learning framework is proposed that allows computation of the surface-representing bearing load curves from reflection RGB images of the liner surface that can be collected with a simple handheld device, without the need to remove and destroy the investigated liner. For this purpose, a convolutional neural network is trained to estimate the bearing load curve of the corresponding depth profile, which in turn can be used for further wear evaluation. Training of the network is performed using a custom-built database containing depth profiles and reflection images of liner surfaces of large gas engines. The results of the proposed method are visually examined and quantified considering several probabilistic distance metrics and comparison of roughness indicators between ground truth and model predictions. The observed success of the proposed method suggests its great potential for quantitative wear assessment on engines and service directly on site.
STAN: Spatio-Temporal Attention Network for Next Location Recommendation
Feb 08, 2021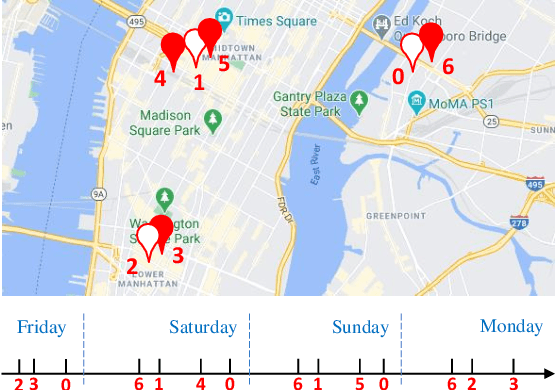
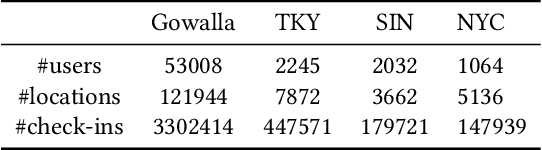
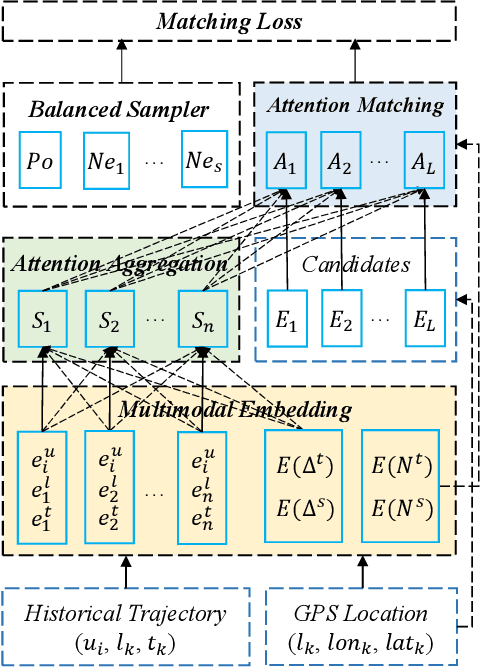
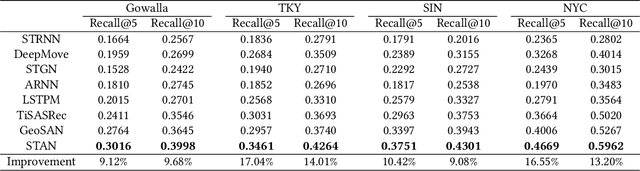
The next location recommendation is at the core of various location-based applications. Current state-of-the-art models have attempted to solve spatial sparsity with hierarchical gridding and model temporal relation with explicit time intervals, while some vital questions remain unsolved. Non-adjacent locations and non-consecutive visits provide non-trivial correlations for understanding a user's behavior but were rarely considered. To aggregate all relevant visits from user trajectory and recall the most plausible candidates from weighted representations, here we propose a Spatio-Temporal Attention Network (STAN) for location recommendation. STAN explicitly exploits relative spatiotemporal information of all the check-ins with self-attention layers along the trajectory. This improvement allows a point-to-point interaction between non-adjacent locations and non-consecutive check-ins with explicit spatiotemporal effect. STAN uses a bi-layer attention architecture that firstly aggregates spatiotemporal correlation within user trajectory and then recalls the target with consideration of personalized item frequency (PIF). By visualization, we show that STAN is in line with the above intuition. Experimental results unequivocally show that our model outperforms the existing state-of-the-art methods by 9-17%.
Deep Reservoir Networks with Learned Hidden Reservoir Weights using Direct Feedback Alignment
Oct 15, 2020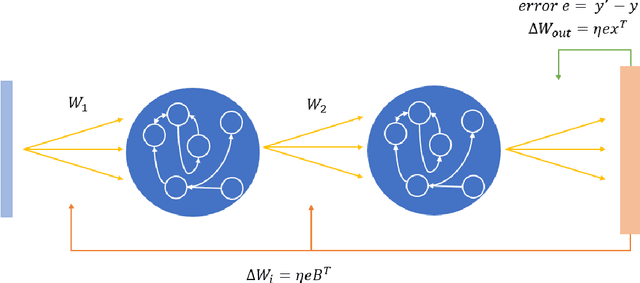

Deep Reservoir Computing has emerged as a new paradigm for deep learning, which is based around the reservoir computing principle of maintaining random pools of neurons combined with hierarchical deep learning. The reservoir paradigm reflects and respects the high degree of recurrence in biological brains, and the role that neuronal dynamics play in learning. However, one issue hampering deep reservoir network development is that one cannot backpropagate through the reservoir layers. Recent deep reservoir architectures do not learn hidden or hierarchical representations in the same manner as deep artificial neural networks, but rather concatenate all hidden reservoirs together to perform traditional regression. Here we present a novel Deep Reservoir Network for time series prediction and classification that learns through the non-differentiable hidden reservoir layers using a biologically-inspired backpropagation alternative called Direct Feedback Alignment, which resembles global dopamine signal broadcasting in the brain. We demonstrate its efficacy on two real world multidimensional time series datasets.
mt5b3: A Framework for Building AutonomousTraders
Jan 20, 2021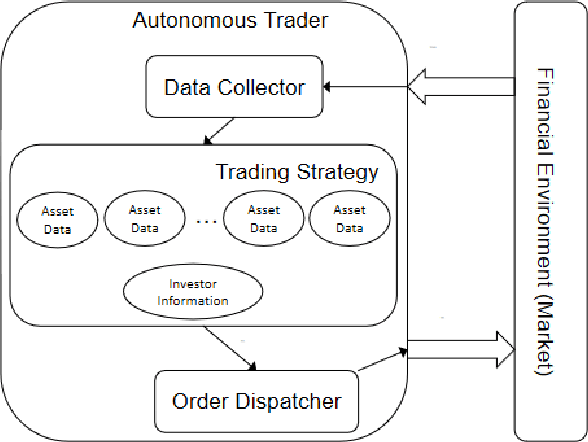
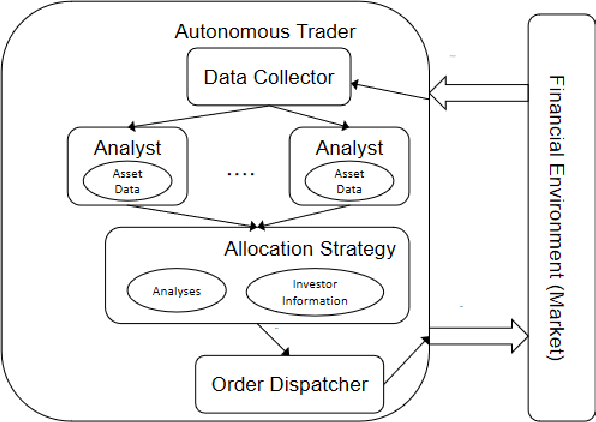
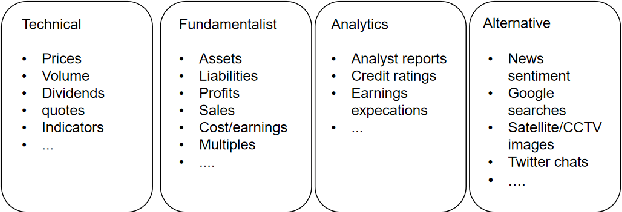
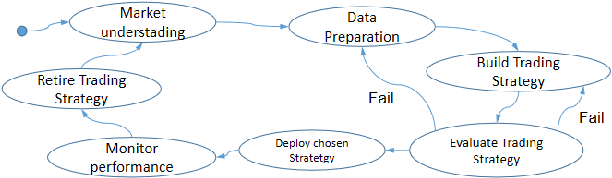
Autonomous trading robots have been studied in ar-tificial intelligence area for quite some time. Many AI techniqueshave been tested in finance field including recent approaches likeconvolutional neural networks and deep reinforcement learning.There are many reported cases, where the developers are suc-cessful in creating robots with great performance when executingwith historical price series, so called backtesting. However, whenthese robots are used in real markets or data not used intheir training or evaluation frequently they present very poorperformance in terms of risks and return. In this paper, wediscussed some fundamental aspects of modelling autonomoustraders and the complex environment that is the financialworld. Furthermore, we presented a framework that helps thedevelopment and testing of autonomous traders. It may also beused in real or simulated operation in financial markets. Finally,we discussed some open problems in the area and pointed outsome interesting technologies that may contribute to advancein such task. We believe that mt5b3 may also contribute todevelopment of new autonomous traders.
Unified Multi-Modal Landmark Tracking for Tightly Coupled Lidar-Visual-Inertial Odometry
Nov 13, 2020
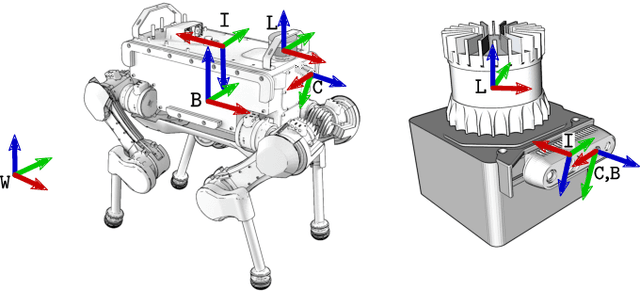
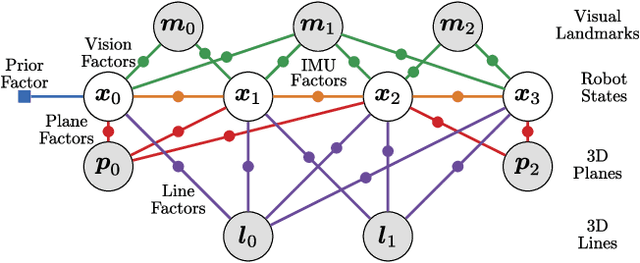
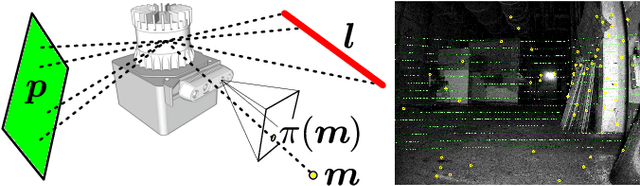
We present an efficient multi-sensor odometry system for mobile platforms that jointly optimizes visual, lidar, and inertial information within a single integrated factor graph. This runs in real-time at full framerate using fixed lag smoothing. To perform such tight integration, a new method to extract 3D line and planar primitives from lidar point clouds is presented. This approach overcomes the suboptimality of typical frame-to-frame tracking methods by treating the primitives as landmarks and tracking them over multiple scans. True integration of lidar features with standard visual features and IMU is made possible using a subtle passive synchronization of lidar and camera frames. The lightweight formulation of the 3D features allows for real-time execution on a single CPU. Our proposed system has been tested on a variety of platforms and scenarios, including underground exploration with a legged robot and outdoor scanning with a dynamically moving handheld device, for a total duration of 96 min and 2.4 km traveled distance. In these test sequences, using only one exteroceptive sensor leads to failure due to either underconstrained geometry (affecting lidar) and textureless areas caused by aggressive lighting changes (affecting vision). In these conditions, our factor graph naturally uses the best information available from each sensor modality without any hard switches.
An Update of a Progressively Expanded Database for Automated Lung Sound Analysis
Feb 08, 2021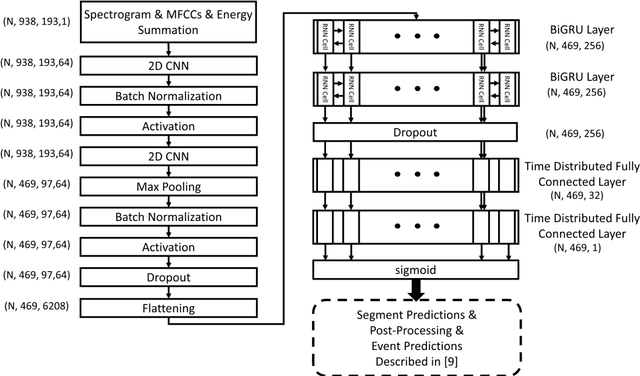
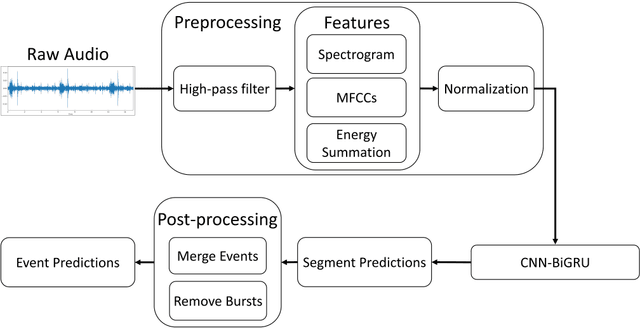
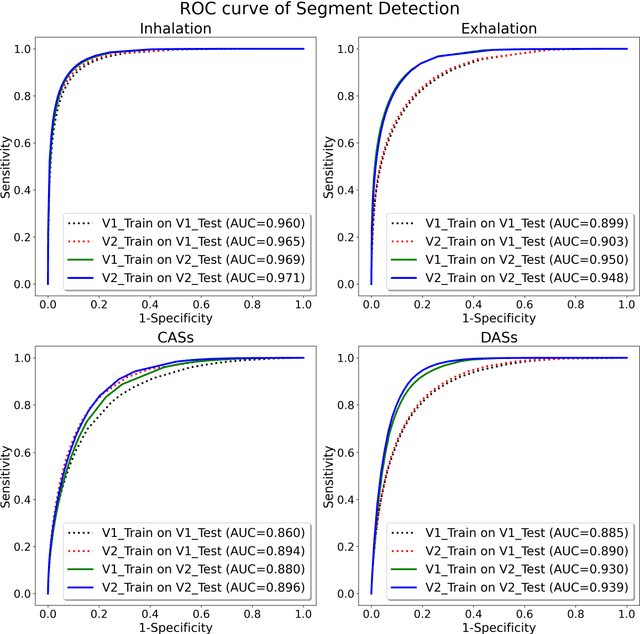
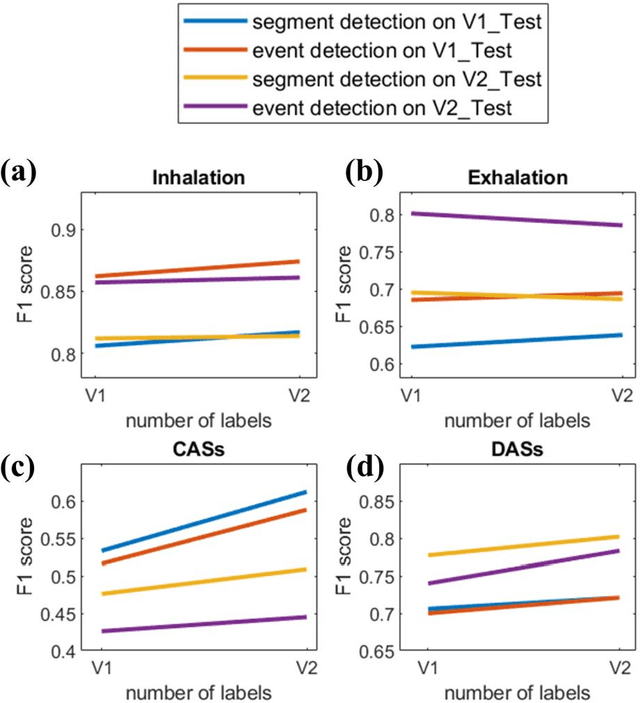
A continuous real-time respiratory sound automated analysis system is needed in clinical practice. Previously, we established an open access lung sound database, HF_Lung_V1, and automated lung sound analysis algorithms capable of detecting inhalation, exhalation, continuous adventitious sounds (CASs) and discontinuous adventitious sounds (DASs). In this study, HF-Lung-V1 has been further expanded to HF-Lung-V2 with 1.45 times of increase in audio files. The convolutional neural network (CNN)-bidirectional gated recurrent unit (BiGRU) model was separately trained with training datasets of HF_Lung_V1 (V1_Train) and HF_Lung_V2 (V2_Train), and then were used for the performance comparisons of segment detection and event detection on both test datasets of HF_Lung_V1 (V1_Test) and HF_Lung_V2 (V2_Test). The performance of segment detection was measured by accuracy, predictive positive value (PPV), sensitivity, specificity, F1 score, receiver operating characteristic (ROC) curve and area under the curve (AUC), whereas that of event detection was evaluated with PPV, sensitivity, and F1 score. Results indicate that the model performance trained by V2_Train showed improvement on both V1_Test and V2_Test in inhalation, CASs and DASs, particularly in CASs, as well as on V1_Test in exhalation.
Active Learning for Sequence Tagging with Deep Pre-trained Models and Bayesian Uncertainty Estimates
Jan 20, 2021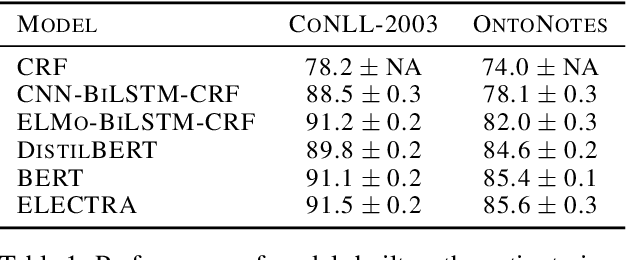
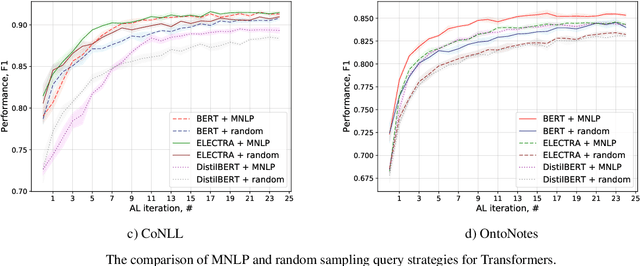
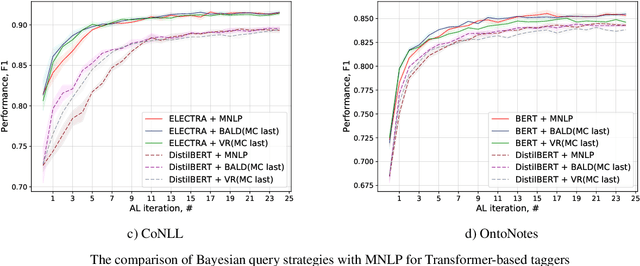
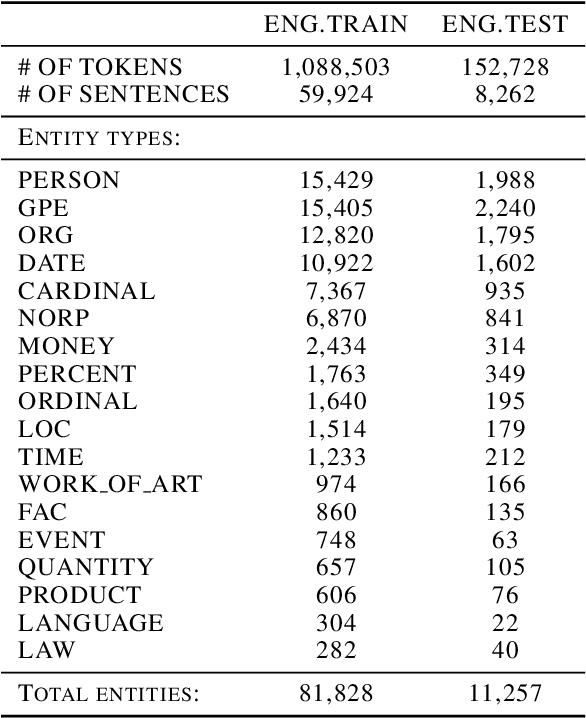
Annotating training data for sequence tagging tasks is usually very time-consuming. Recent advances in transfer learning for natural language processing in conjunction with active learning open the possibility to significantly reduce the necessary annotation budget. We are the first to thoroughly investigate this powerful combination in sequence tagging. We find that taggers based on deep pre-trained models can benefit from Bayesian query strategies with the help of the Monte Carlo (MC) dropout. Results of experiments with various uncertainty estimates and MC dropout variants show that the Bayesian active learning by disagreement query strategy coupled with the MC dropout applied only in the classification layer of a Transformer-based tagger is the best option in terms of quality. This option also has very little computational overhead. We also demonstrate that it is possible to reduce the computational overhead of AL by using a smaller distilled version of a Transformer model for acquiring instances during AL.