 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast accuracy estimation of deep learning based multi-class musical source separation
Oct 19, 2020
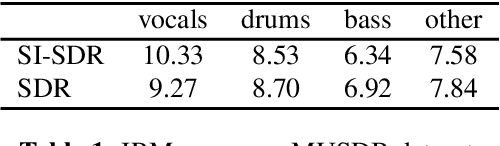
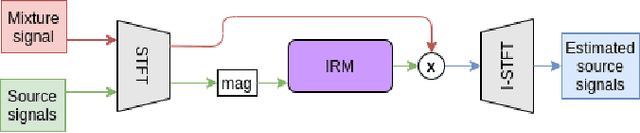
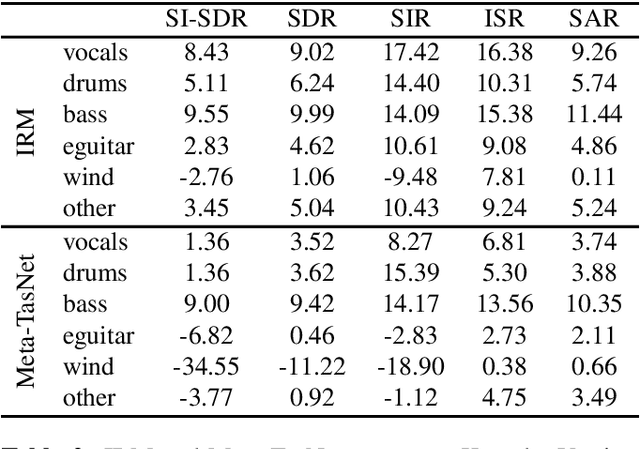
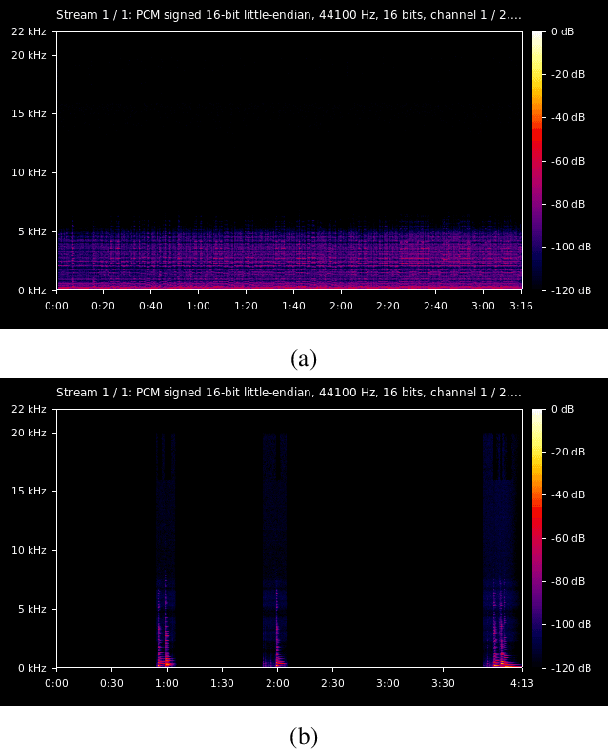
Music source separation represents the task of extracting all the instruments from a given song. Recent breakthroughs on this challenge have gravitated around a single dataset, MUSDB, that is limited to four instrument classes only. New datasets are required to extend to other instruments and increase the performances. However larger datasets are costly and time-consuming in terms of collecting data and training deep networks. In this work, we propose a fast method for evaluating the separability of instruments in any dataset or song, and for any instrument without the need to train and tune a deep neural network. This separability measure helps selecting appropriate samples for the efficient training of neural networks. Our approach, based on the oracle principle with an ideal ratio mask, is a good proxy to estimate the separation performances of state-of-the-art deep learning approaches based on time-frequency masking such as TasNet or Open-Unmix. The proposed fast accuracy estimation method can significantly speed up the music source separation system's development process.
PCA-Based Missing Information Imputation for Real-Time Crash Likelihood Prediction Under Imbalanced Data
Feb 11, 2018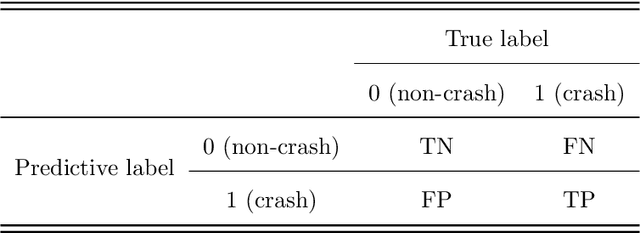
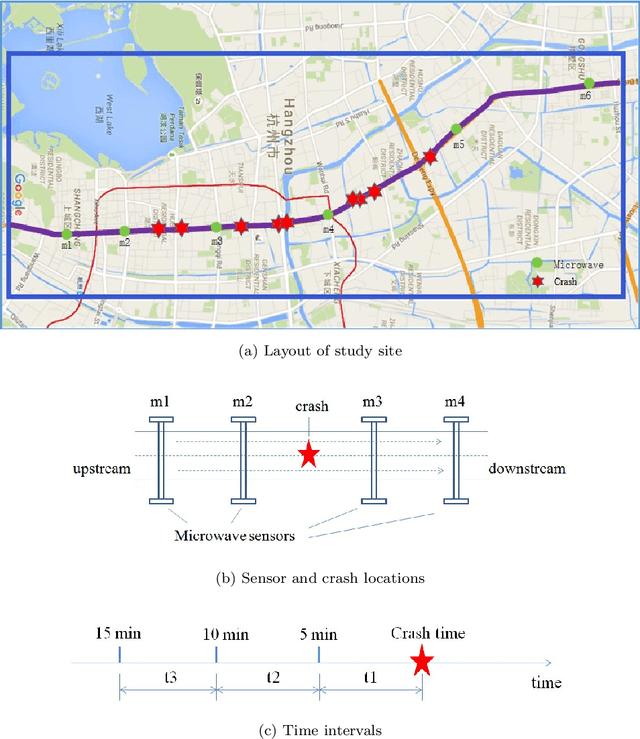
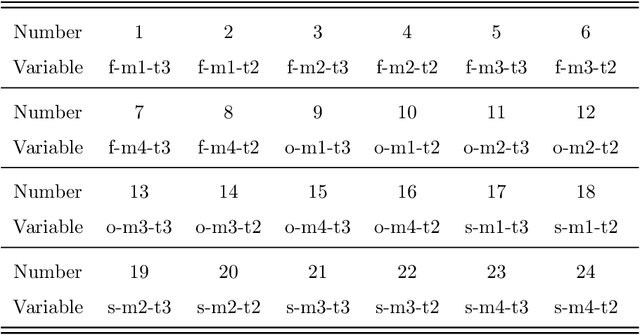
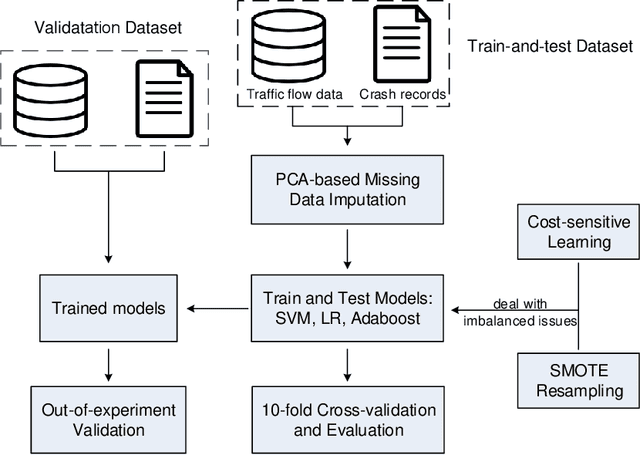
The real-time crash likelihood prediction has been an important research topic. Various classifiers, such as support vector machine (SVM) and tree-based boosting algorithms, have been proposed in traffic safety studies. However, few research focuses on the missing data imputation in real-time crash likelihood prediction, although missing values are commonly observed due to breakdown of sensors or external interference. Besides, classifying imbalanced data is also a difficult problem in real-time crash likelihood prediction, since it is hard to distinguish crash-prone cases from non-crash cases which compose the majority of the observed samples. In this paper, principal component analysis (PCA) based approaches, including LS-PCA, PPCA, and VBPCA, are employed for imputing missing values, while two kinds of solutions are developed to solve the problem in imbalanced data. The results show that PPCA and VBPCA not only outperform LS-PCA and other imputation methods (including mean imputation and k-means clustering imputation), in terms of the root mean square error (RMSE), but also help the classifiers achieve better predictive performance. The two solutions, i.e., cost-sensitive learning and synthetic minority oversampling technique (SMOTE), help improve the sensitivity by adjusting the classifiers to pay more attention to the minority class.
A comparative evaluation of machine learning methods for robot navigation through human crowds
Dec 16, 2020

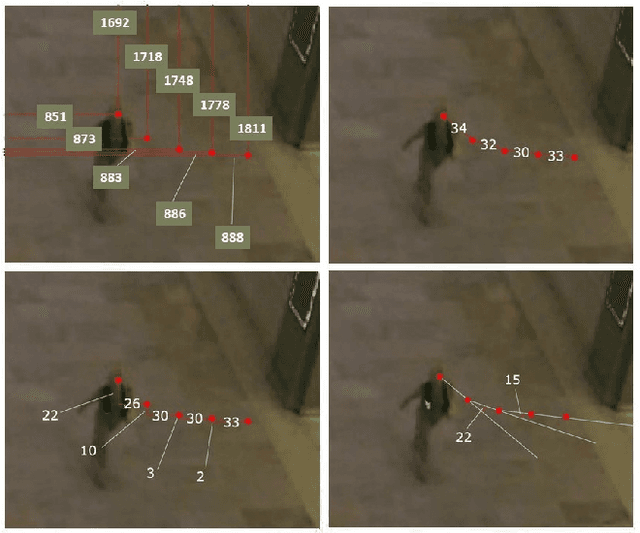
Robot navigation through crowds poses a difficult challenge to AI systems, since the methods should result in fast and efficient movement but at the same time are not allowed to compromise safety. Most approaches to date were focused on the combination of pathfinding algorithms with machine learning for pedestrian walking prediction. More recently, reinforcement learning techniques have been proposed in the research literature. In this paper, we perform a comparative evaluation of pathfinding/prediction and reinforcement learning approaches on a crowd movement dataset collected from surveillance videos taken at Grand Central Station in New York. The results demonstrate the strong superiority of state-of-the-art reinforcement learning approaches over pathfinding with state-of-the-art behaviour prediction techniques.
Border Basis Computation with Gradient-Weighted Norm
Jan 14, 2021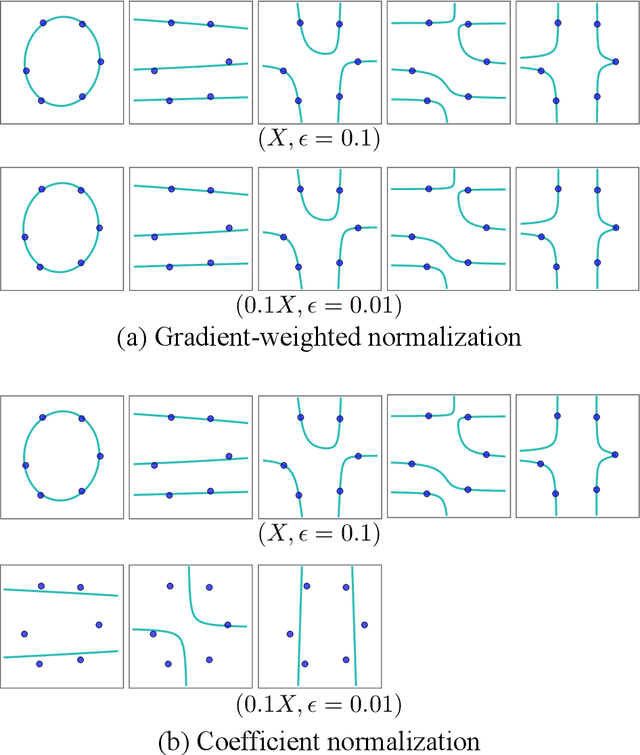
Normalization of polynomials plays an essential role in the approximate basis computation of vanishing ideals. In computer algebra, coefficient normalization, which normalizes a polynomial by its coefficient norm, is the most common method. In this study, we propose gradient-weighted normalization for the approximate border basis computation of vanishing ideals, inspired by the recent results in machine learning. The data-dependent nature of gradient-weighted normalization leads to powerful properties such as better stability against perturbation and consistency in the scaling of input points, which cannot be attained by the conventional coefficient normalization. With a slight modification, the analysis of algorithms with coefficient normalization still works with gradient-weighted normalization and the time complexity does not change. We also provide an upper bound on the coefficient norm based on the gradient-weighted norm, which allows us to discuss the approximate border bases with gradient-weighted normalization from the perspective of the coefficient norm.
Fast Fourier Transformation for Optimizing Convolutional Neural Networks in Object Recognition
Oct 08, 2020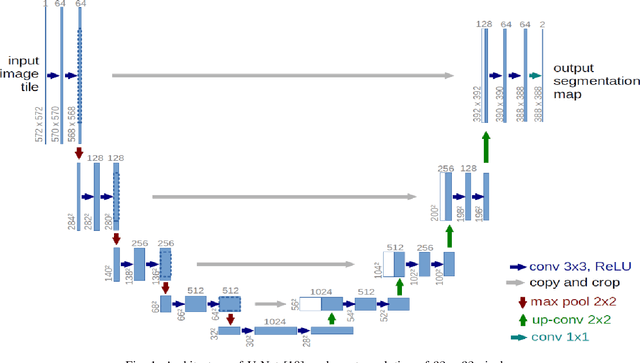
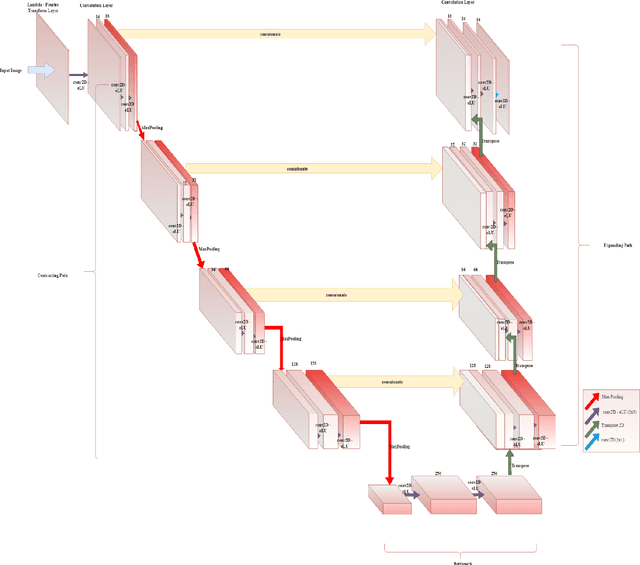
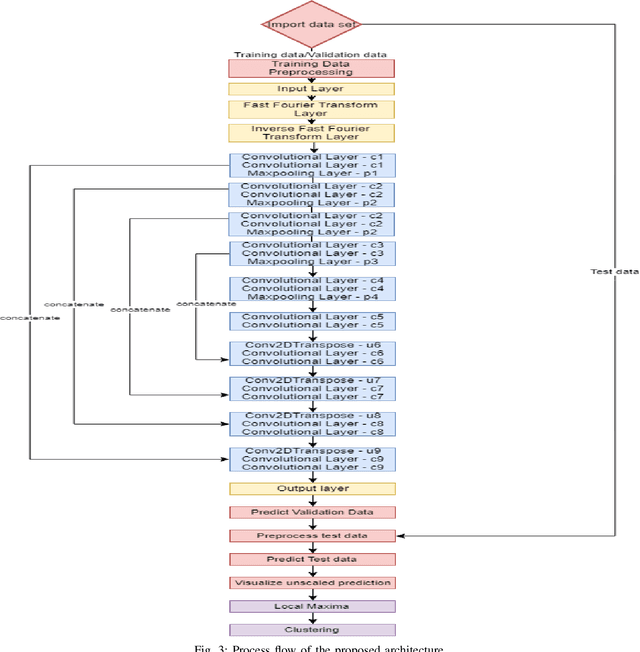

This paper proposes to use Fast Fourier Transformation-based U-Net (a refined fully convolutional networks) and perform image convolution in neural networks. Leveraging the Fast Fourier Transformation, it reduces the image convolution costs involved in the Convolutional Neural Networks (CNNs) and thus reduces the overall computational costs. The proposed model identifies the object information from the images. We apply the Fast Fourier transform algorithm on an image data set to obtain more accessible information about the image data, before segmenting them through the U-Net architecture. More specifically, we implement the FFT-based convolutional neural network to improve the training time of the network. The proposed approach was applied to publicly available Broad Bioimage Benchmark Collection (BBBC) dataset. Our model demonstrated improvement in training time during convolution from $600-700$ ms/step to $400-500$ ms/step. We evaluated the accuracy of our model using Intersection over Union (IoU) metric showing significant improvements.
Recurrent autoencoder with sequence-aware encoding
Sep 15, 2020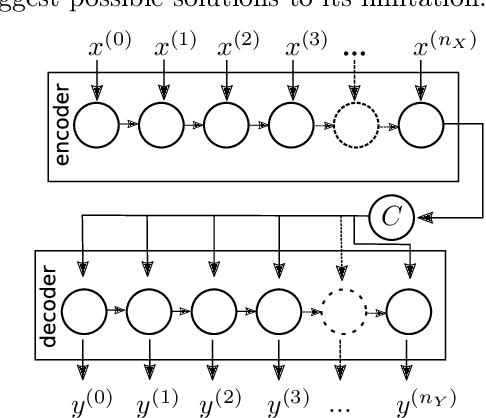
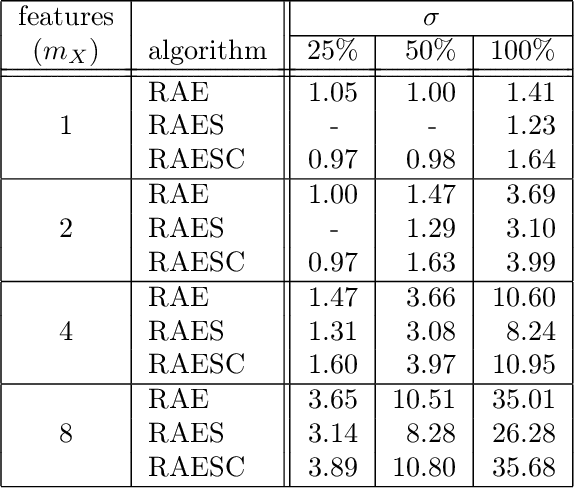
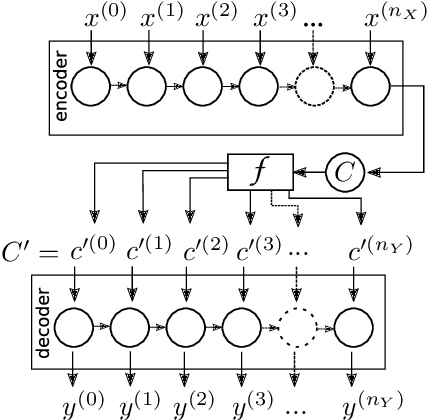
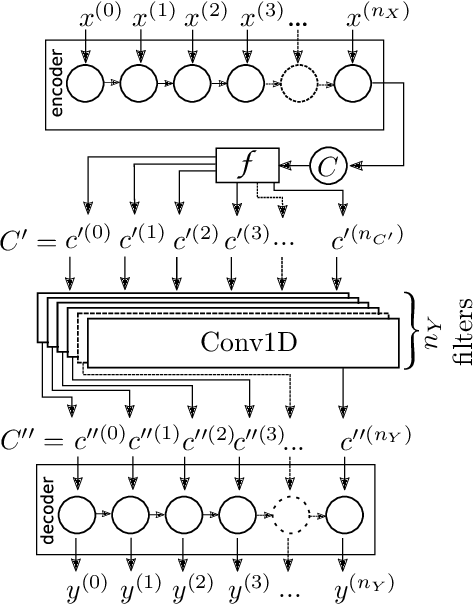
Recurrent Neural Networks (RNN) received a vast amount of attention last decade. Recently, the architectures of Recurrent AutoEncoders (RAE) found many applications in practice. RAE can extract the semantically valuable information, called context that represents a latent space useful for further processing. Nevertheless, recurrent autoencoders are hard to train, and the training process takes much time. In this paper, we propose an autoencoder architecture with sequence-aware encoding, which employs 1D convolutional layer to improve its performance in terms of model training time. We prove that the recurrent autoencoder with sequence-aware encoding outperforms a standard RAE in terms of training speed in most cases. The preliminary results show that the proposed solution dominates over the standard RAE, and the training process is order of magnitude faster.
Synthesising a Database of Parameterised Linear and Non-Linear Invariants for Time-Series Constraints
Jan 15, 2019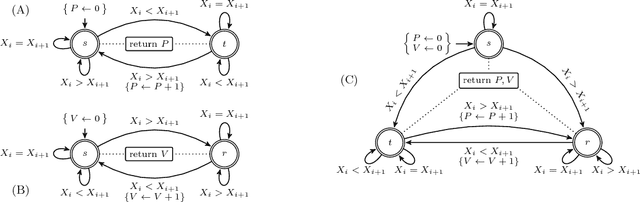
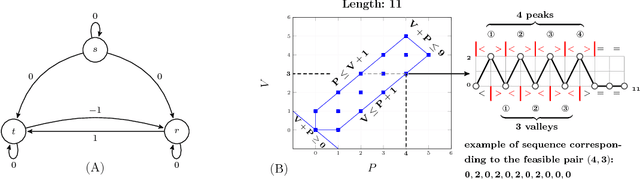
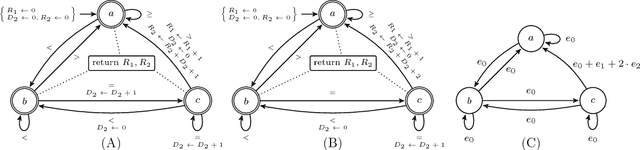
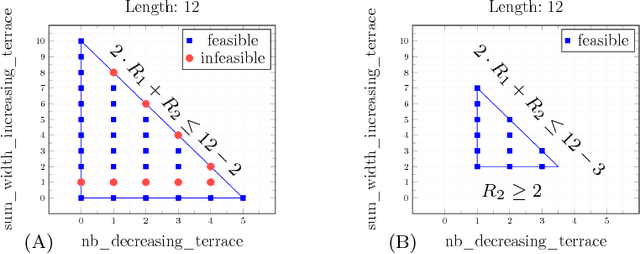
Many constraints restricting the result of some computations over an integer sequence can be compactly represented by register automata. We improve the propagation of the conjunction of such constraints on the same sequence by synthesising a database of linear and non-linear invariants using their register-automaton representation. The obtained invariants are formulae parameterised by a function of the sequence length and proven to be true for any long enough sequence. To assess the quality of such linear invariants, we developed a method to verify whether a generated linear invariant is a facet of the convex hull of the feasible points. This method, as well as the proof of non-linear invariants, are based on the systematic generation of constant-size deterministic finite automata that accept all integer sequences whose result verifies some simple condition. We apply such methodology to a set of 44 time-series constraints and obtain 1400 linear invariants from which 70% are facet defining, and 600 non-linear invariants, which were tested on short-term electricity production problems.
Deep NMF Topic Modeling
Feb 24, 2021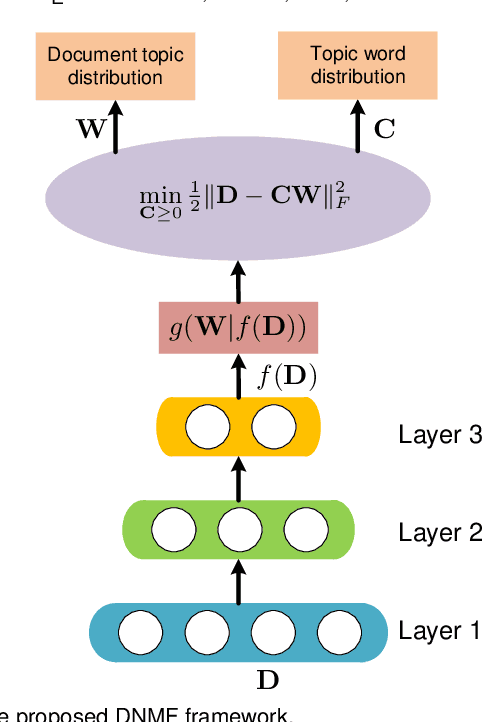
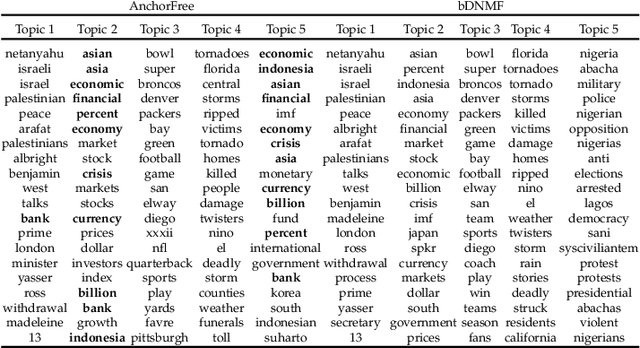
Nonnegative matrix factorization (NMF) based topic modeling methods do not rely on model- or data-assumptions much. However, they are usually formulated as difficult optimization problems, which may suffer from bad local minima and high computational complexity. In this paper, we propose a deep NMF (DNMF) topic modeling framework to alleviate the aforementioned problems. It first applies an unsupervised deep learning method to learn latent hierarchical structures of documents, under the assumption that if we could learn a good representation of documents by, e.g. a deep model, then the topic word discovery problem can be boosted. Then, it takes the output of the deep model to constrain a topic-document distribution for the discovery of the discriminant topic words, which not only improves the efficacy but also reduces the computational complexity over conventional unsupervised NMF methods. We constrain the topic-document distribution in three ways, which takes the advantages of the three major sub-categories of NMF -- basic NMF, structured NMF, and constrained NMF respectively. To overcome the weaknesses of deep neural networks in unsupervised topic modeling, we adopt a non-neural-network deep model -- multilayer bootstrap network. To our knowledge, this is the first time that a deep NMF model is used for unsupervised topic modeling. We have compared the proposed method with a number of representative references covering major branches of topic modeling on a variety of real-world text corpora. Experimental results illustrate the effectiveness of the proposed method under various evaluation metrics.
Lifelong Learning in Multi-Armed Bandits
Dec 28, 2020
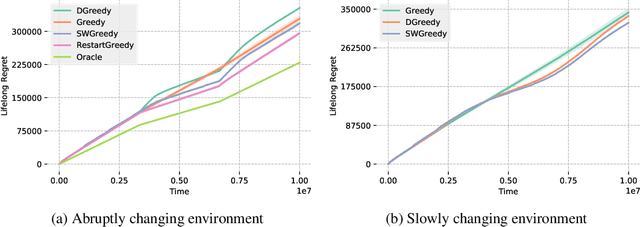
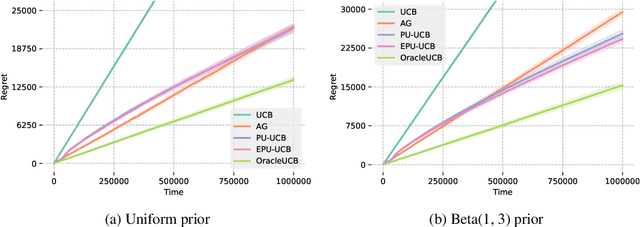
Continuously learning and leveraging the knowledge accumulated from prior tasks in order to improve future performance is a long standing machine learning problem. In this paper, we study the problem in the multi-armed bandit framework with the objective to minimize the total regret incurred over a series of tasks. While most bandit algorithms are designed to have a low worst-case regret, we examine here the average regret over bandit instances drawn from some prior distribution which may change over time. We specifically focus on confidence interval tuning of UCB algorithms. We propose a bandit over bandit approach with greedy algorithms and we perform extensive experimental evaluations in both stationary and non-stationary environments. We further apply our solution to the mortal bandit problem, showing empirical improvement over previous work.
Task-Optimal Exploration in Linear Dynamical Systems
Feb 10, 2021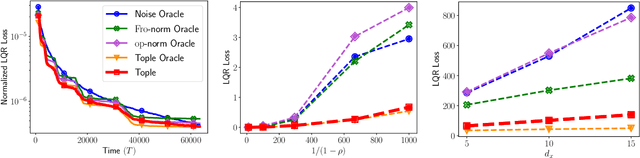
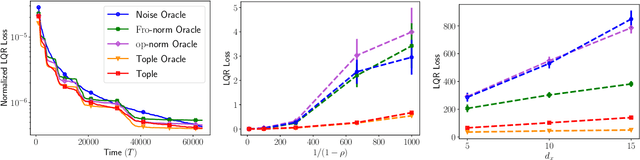
Exploration in unknown environments is a fundamental problem in reinforcement learning and control. In this work, we study task-guided exploration and determine what precisely an agent must learn about their environment in order to complete a particular task. Formally, we study a broad class of decision-making problems in the setting of linear dynamical systems, a class that includes the linear quadratic regulator problem. We provide instance- and task-dependent lower bounds which explicitly quantify the difficulty of completing a task of interest. Motivated by our lower bound, we propose a computationally efficient experiment-design based exploration algorithm. We show that it optimally explores the environment, collecting precisely the information needed to complete the task, and provide finite-time bounds guaranteeing that it achieves the instance- and task-optimal sample complexity, up to constant factors. Through several examples of the LQR problem, we show that performing task-guided exploration provably improves on exploration schemes which do not take into account the task of interest. Along the way, we establish that certainty equivalence decision making is instance- and task-optimal, and obtain the first algorithm for the linear quadratic regulator problem which is instance-optimal. We conclude with several experiments illustrating the effectiveness of our approach in practice.