 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semi-Supervised Action Recognition with Temporal Contrastive Learning
Feb 04, 2021
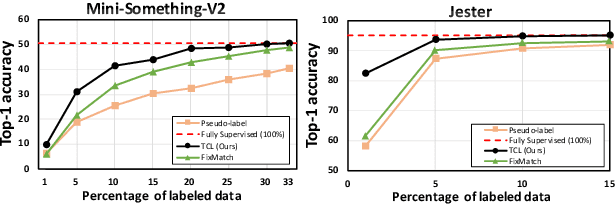
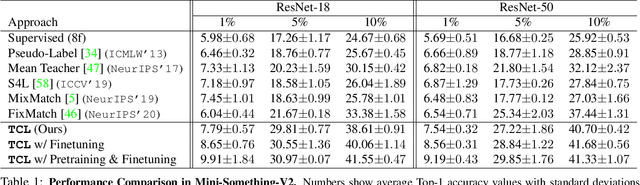
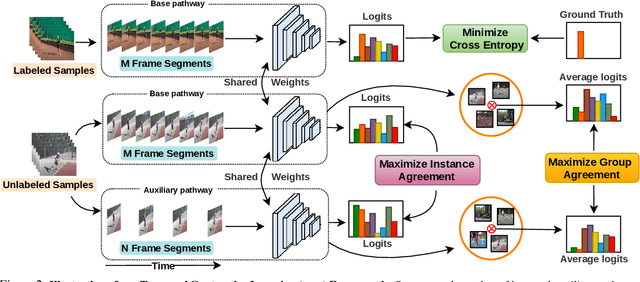
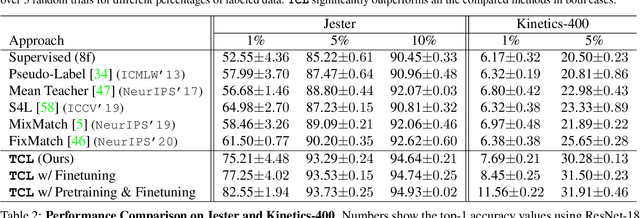
Learning to recognize actions from only a handful of labeled videos is a challenging problem due to the scarcity of tediously collected activity labels. We approach this problem by learning a two-pathway temporal contrastive model using unlabeled videos at two different speeds leveraging the fact that changing video speed does not change an action. Specifically, we propose to maximize the similarity between encoded representations of the same video at two different speeds as well as minimize the similarity between different videos played at different speeds. This way we use the rich supervisory information in terms of 'time' that is present in otherwise unsupervised pool of videos. With this simple yet effective strategy of manipulating video playback rates, we considerably outperform video extensions of sophisticated state-of-the-art semi-supervised image recognition methods across multiple diverse benchmark datasets and network architectures. Interestingly, our proposed approach benefits from out-of-domain unlabeled videos showing generalization and robustness. We also perform rigorous ablations and analysis to validate our approach.
Is preprocessing of text really worth your time for online comment classification?
Aug 29, 2018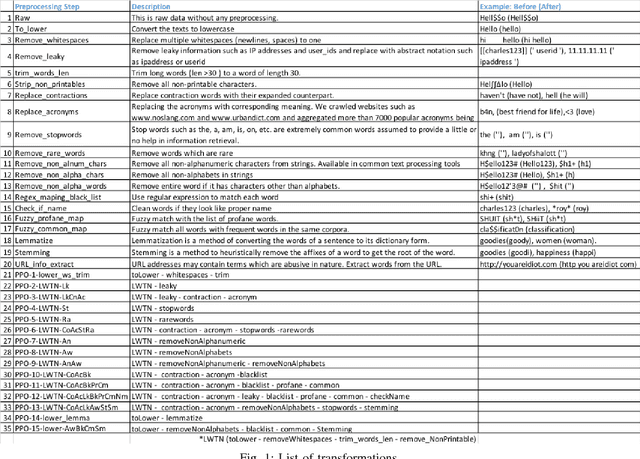
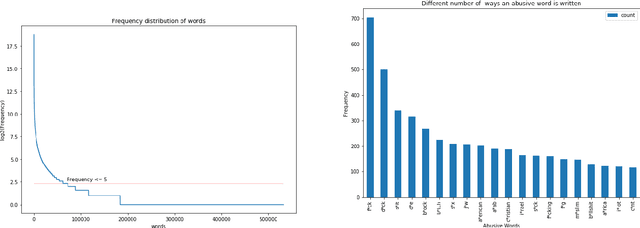
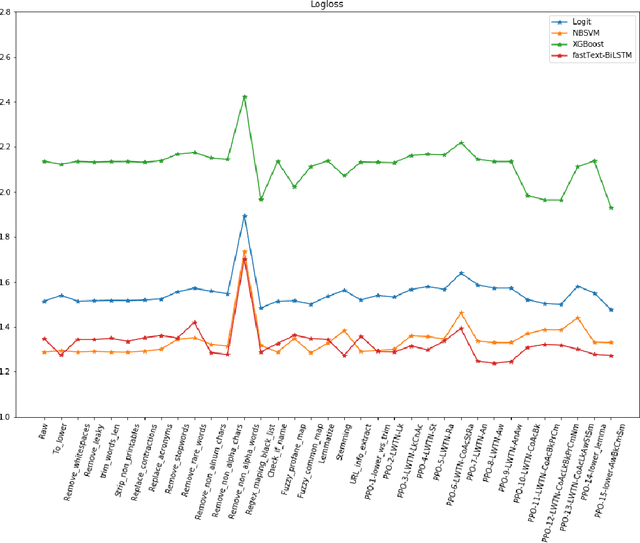
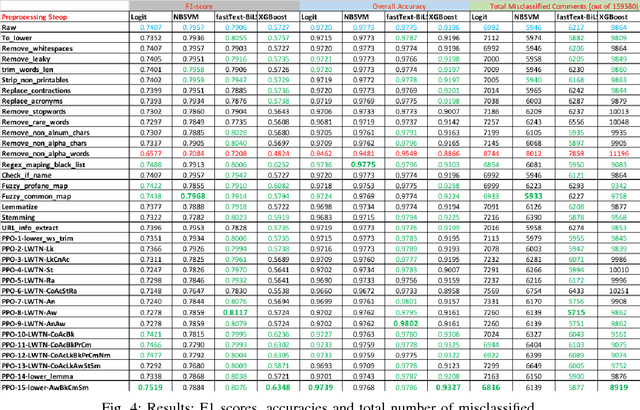
A large proportion of online comments present on public domains are constructive, however a significant proportion are toxic in nature. The comments contain lot of typos which increases the number of features manifold, making the ML model difficult to train. Considering the fact that the data scientists spend approximately 80% of their time in collecting, cleaning and organizing their data [1], we explored how much effort should we invest in the preprocessing (transformation) of raw comments before feeding it to the state-of-the-art classification models. With the help of four models on Jigsaw toxic comment classification data, we demonstrated that the training of model without any transformation produce relatively decent model. Applying even basic transformations, in some cases, lead to worse performance and should be applied with caution.
Adversarial Attacks and Defenses in Physiological Computing: A Systematic Review
Feb 04, 2021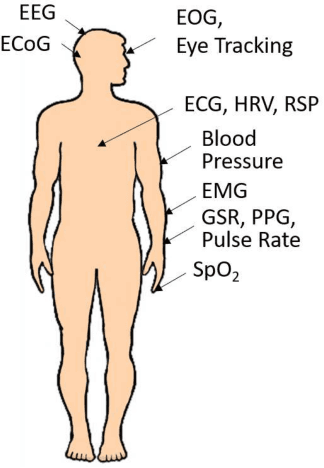
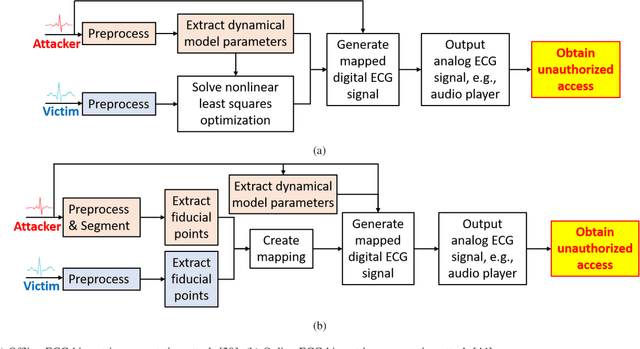
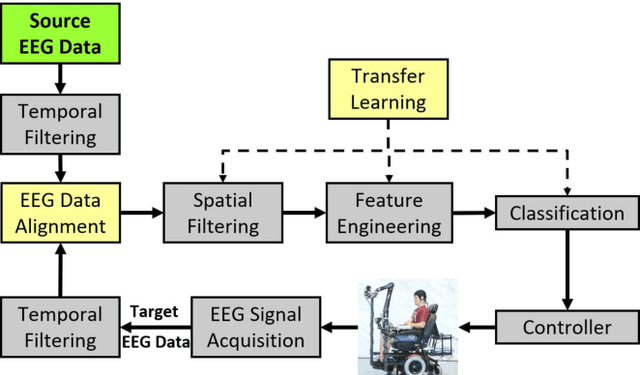
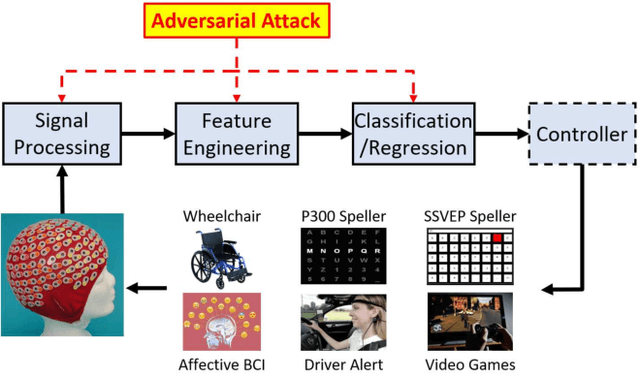
Physiological computing uses human physiological data as system inputs in real time. It includes, or significantly overlaps with, brain-computer interfaces, affective computing, adaptive automation, health informatics, and physiological signal based biometrics. Physiological computing increases the communication bandwidth from the user to the computer, but is also subject to various types of adversarial attacks, in which the attacker deliberately manipulates the training and/or test examples to hijack the machine learning algorithm output, leading to possibly user confusion, frustration, injury, or even death. However, the vulnerability of physiological computing systems has not been paid enough attention to, and there does not exist a comprehensive review on adversarial attacks to it. This paper fills this gap, by providing a systematic review on the main research areas of physiological computing, different types of adversarial attacks and their applications to physiological computing, and the corresponding defense strategies. We hope this review will attract more research interests on the vulnerability of physiological computing systems, and more importantly, defense strategies to make them more secure.
Towards Precise and Efficient Image Guided Depth Completion
Mar 01, 2021



Image guided depth completion is the task of generating a dense depth map from a sparse depth map and a high quality image. In this task, how to fuse the color and depth modalities plays an important role in achieving good performance. This paper proposes a two-branch backbone that consists of a color-dominant branch and a depth-dominant branch to exploit and fuse two modalities thoroughly. More specifically, one branch inputs a color image and a sparse depth map to predict a dense depth map. The other branch takes as inputs the sparse depth map and the previously predicted depth map, and outputs a dense depth map as well. The depth maps predicted from two branches are complimentary to each other and therefore they are adaptively fused. In addition, we also propose a simple geometric convolutional layer to encode 3D geometric cues. The geometric encoded backbone conducts the fusion of different modalities at multiple stages, leading to good depth completion results. We further implement a dilated and accelerated CSPN++ to refine the fused depth map efficiently. The proposed full model ranks 1st in the KITTI depth completion online leaderboard at the time of submission. It also infers much faster than most of the top ranked methods. The code of this work will be available at https://github.com/JUGGHM/PENet_ICRA2021.
Online Paging with a Vanishing Regret
Nov 19, 2020This paper considers a variant of the online paging problem, where the online algorithm has access to multiple predictors, each producing a sequence of predictions for the page arrival times. The predictors may have occasional prediction errors and it is assumed that at least one of them makes a sublinear number of prediction errors in total. Our main result states that this assumption suffices for the design of a randomized online algorithm whose time-average regret with respect to the optimal offline algorithm tends to zero as the time tends to infinity. This holds (with different regret bounds) for both the full information access model, where in each round, the online algorithm gets the predictions of all predictors, and the bandit access model, where in each round, the online algorithm queries a single predictor. While online algorithms that exploit inaccurate predictions have been a topic of growing interest in the last few years, to the best of our knowledge, this is the first paper that studies this topic in the context of multiple predictors for an online problem with unbounded request sequences. Moreover, to the best of our knowledge, this is also the first paper that aims for (and achieves) online algorithms with a vanishing regret for a classic online problem under reasonable assumptions.
Interpretable Visualization and Higher-Order Dimension Reduction for ECoG Data
Nov 19, 2020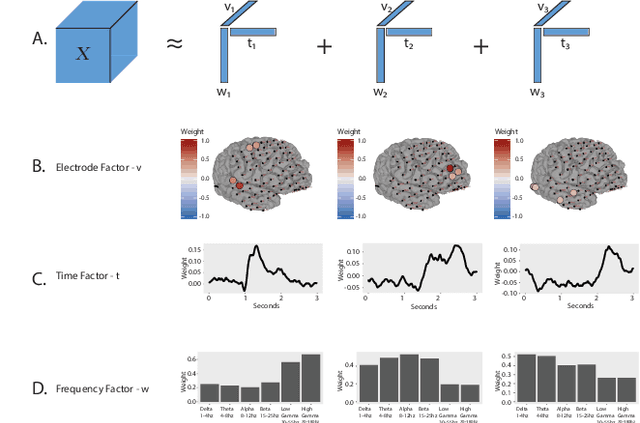
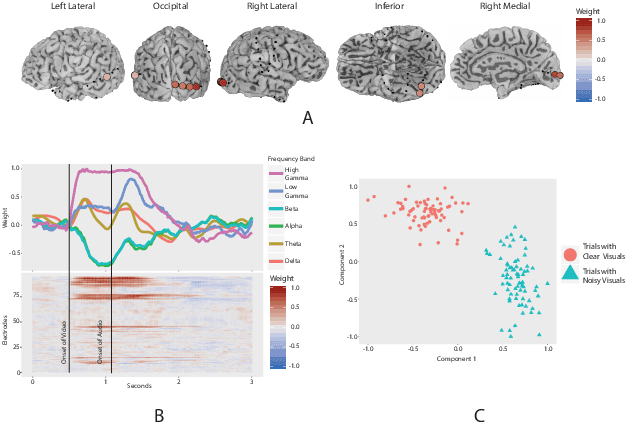
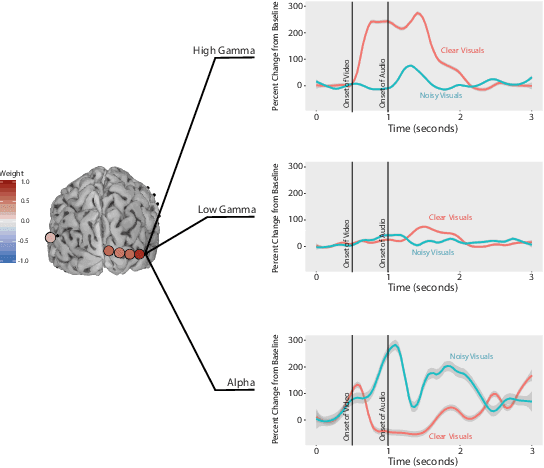
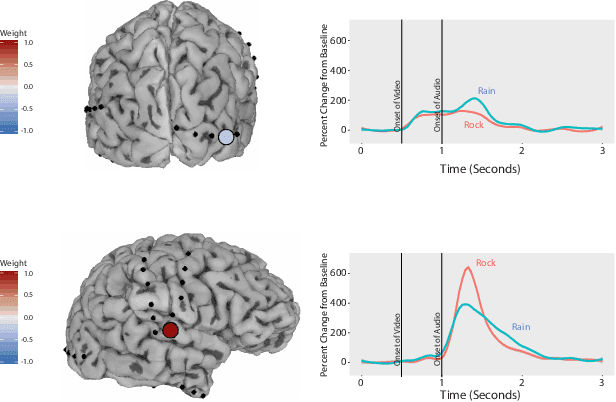
ElectroCOrticoGraphy (ECoG) technology measures electrical activity in the human brain via electrodes placed directly on the cortical surface during neurosurgery. Through its capability to record activity at an extremely fast temporal resolution, ECoG experiments have allowed scientists to better understand how the human brain processes speech. By its nature, ECoG data is extremely difficult for neuroscientists to directly interpret for two major reasons. Firstly, ECoG data tends to be extremely large in size, as each individual experiment yields data up to several GB. Secondly, ECoG data has a complex, higher-order nature; after signal processing, this type of data is typically organized as a 4-way tensor consisting of trials by electrodes by frequency by time. In this paper, we develop an interpretable dimension reduction approach called Regularized Higher Order Principal Components Analysis, as well as an extension to Regularized Higher Order Partial Least Squares, that allows neuroscientists to explore and visualize ECoG data. Our approach employs a sparse and functional Candecomp-Parafac (CP) decomposition that incorporates sparsity to select relevant electrodes and frequency bands, as well as smoothness over time and frequency, yielding directly interpretable factors. We demonstrate both the performance and interpretability of our method with an ECoG case study on audio and visual processing of human speech.
Heterogeneous Graphlets
Oct 23, 2020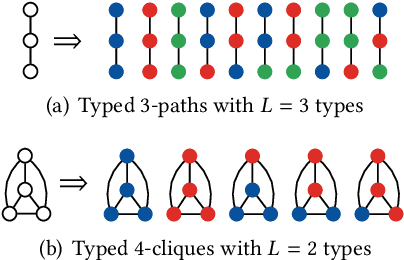


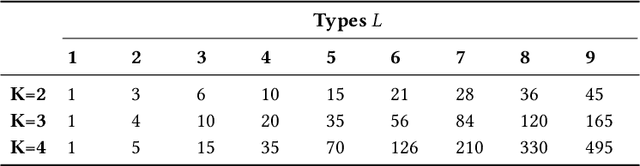
In this paper, we introduce a generalization of graphlets to heterogeneous networks called typed graphlets. Informally, typed graphlets are small typed induced subgraphs. Typed graphlets generalize graphlets to rich heterogeneous networks as they explicitly capture the higher-order typed connectivity patterns in such networks. To address this problem, we describe a general framework for counting the occurrences of such typed graphlets. The proposed algorithms leverage a number of combinatorial relationships for different typed graphlets. For each edge, we count a few typed graphlets, and with these counts along with the combinatorial relationships, we obtain the exact counts of the other typed graphlets in o(1) constant time. Notably, the worst-case time complexity of the proposed approach matches the time complexity of the best known untyped algorithm. In addition, the approach lends itself to an efficient lock-free and asynchronous parallel implementation. While there are no existing methods for typed graphlets, there has been some work that focused on computing a different and much simpler notion called colored graphlet. The experiments confirm that our proposed approach is orders of magnitude faster and more space-efficient than methods for computing the simpler notion of colored graphlet. Unlike these methods that take hours on small networks, the proposed approach takes only seconds on large networks with millions of edges. Notably, since typed graphlet is more general than colored graphlet (and untyped graphlets), the counts of various typed graphlets can be combined to obtain the counts of the much simpler notion of colored graphlets. The proposed methods give rise to new opportunities and applications for typed graphlets.
Learning from Natural Noise to Denoise Micro-Doppler Spectrogram
Feb 13, 2021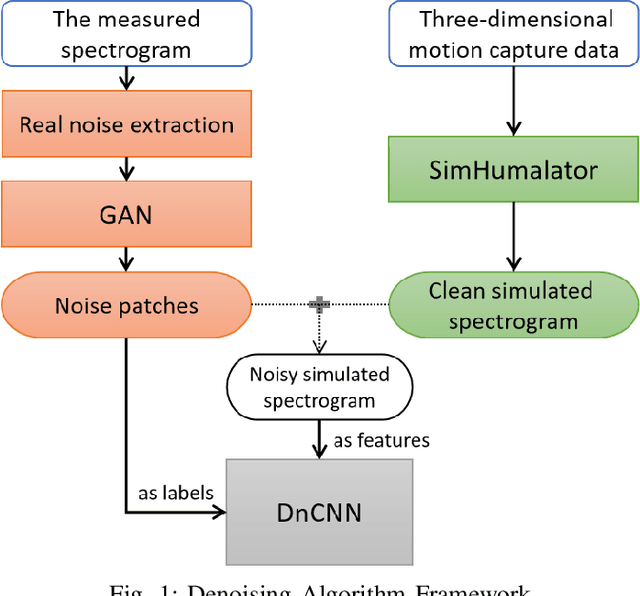
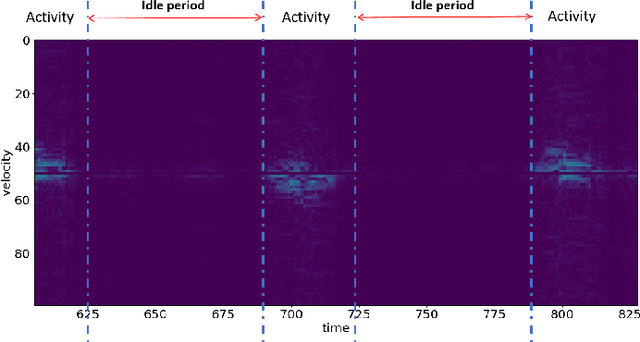
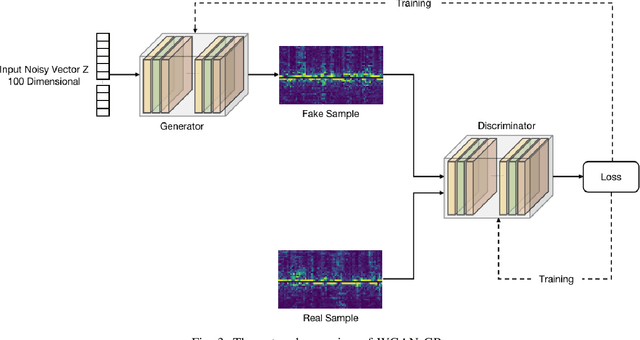
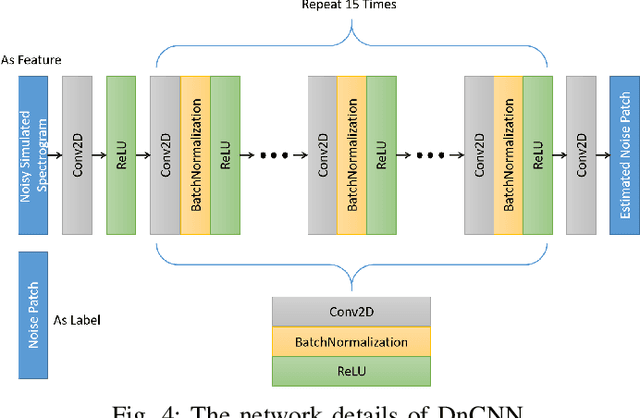
Micro-Doppler analysis has become increasingly popular in recent years owning to the ability of the technique to enhance classification strategies. Applications include recognising everyday human activities, distinguishing drone from birds, and identifying different types of vehicles. However, noisy time-frequency spectrograms can significantly affect the performance of the classifier and must be tackled using appropriate denoising algorithms. In recent years, deep learning algorithms have spawned many deep neural network-based denoising algorithms. For these methods, noise modelling is the most important part and is used to assist in training. In this paper, we decompose the problem and propose a novel denoising scheme: first, a Generative Adversarial Network (GAN) is used to learn the noise distribution and correlation from the real-world environment; then, a simulator is used to generate clean Micro-Doppler spectrograms; finally, the generated noise and clean simulation data are combined as the training data to train a Convolutional Neural Network (CNN) denoiser. In experiments, we qualitatively and quantitatively analyzed this procedure on both simulation and measurement data. Besides, the idea of learning from natural noise can be applied well to other existing frameworks and demonstrate greater performance than other noise models.
A practical algorithm to calculate Cap Discrepancy
Oct 20, 2020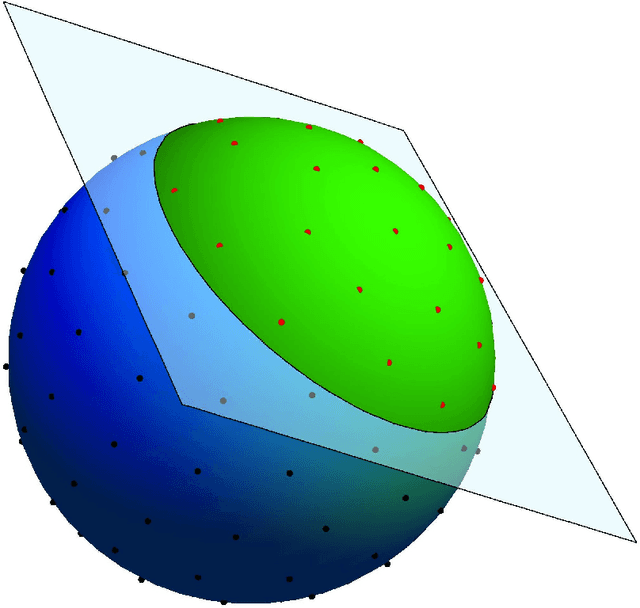
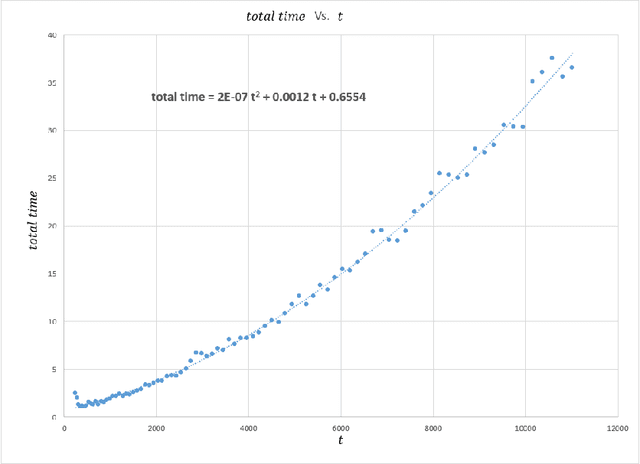
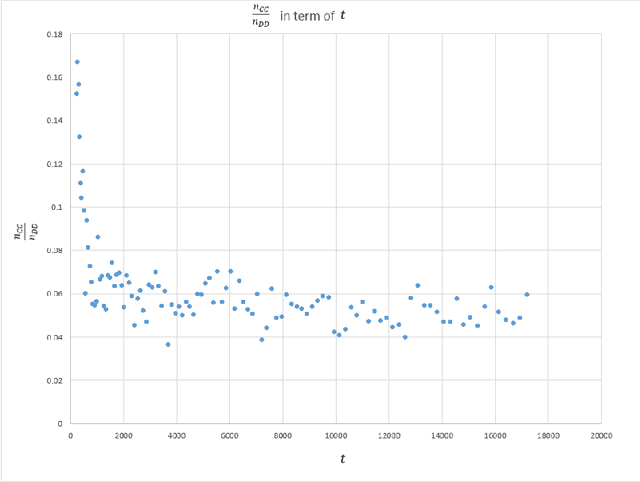
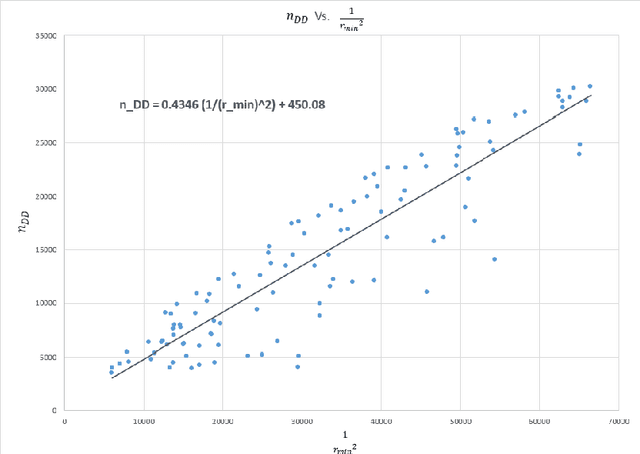
Uniform distribution of the points has been of interest to researchers for a long time and has applications in different areas of Mathematics and Computer Science. One of the well-known measures to evaluate the uniformity of a given distribution is Discrepancy, which assesses the difference between the Uniform distribution and the empirical distribution given by putting mass points at the points of the given set. While Discrepancy is very useful to measure uniformity, it is computationally challenging to be calculated accurately. We introduce the concept of directed Discrepancy based on which we have developed an algorithm, called Directional Discrepancy, that can offer accurate approximation for the cap Discrepancy of a finite set distributed on the unit Sphere, $\mathbb{S}^2.$ We also analyze the time complexity of the Directional Discrepancy algorithm precisely; and practically evaluate its capacity by calculating the Cap Discrepancy of a specific distribution, Polar Coordinates, which aims to distribute points uniformly on the Sphere.
A Work Zone Simulation Model for Travel Time Prediction in a Connected Vehicle Environment
Jan 20, 2018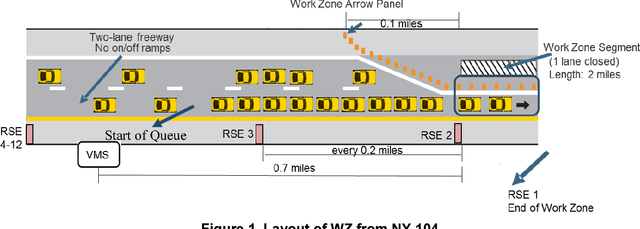

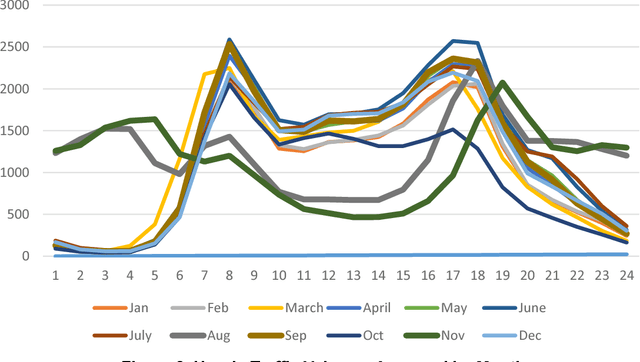
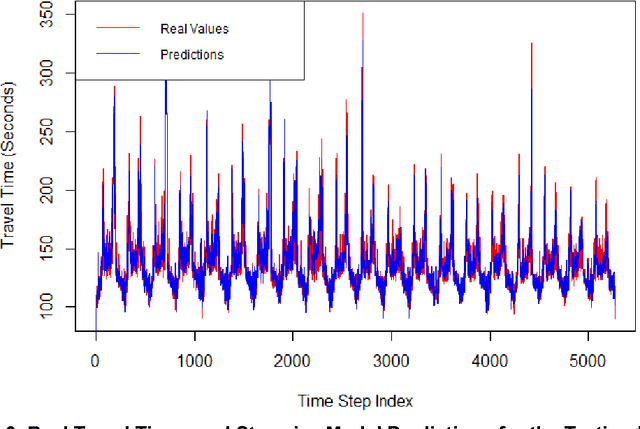
A work zone bottleneck in a roadway network can cause traffic delays, emissions and safety issues. Accurate measurement and prediction of work zone travel time can help travelers make better routing decisions and therefore mitigate its impact. Historically, data used for travel time analyses comes from fixed loop detectors, which are expensive to install and maintain. With connected vehicle technology, such as Vehicle-to-Infrastructure, portable roadside unit (RSU) can be located in and around a work zone segment to communicate with the vehicles and collect traffic data. A PARAMICS simulation model for a prototypical freeway work zone in a connected vehicle environment was built to test this idea using traffic demand data from NY State Route 104. For the simulation, twelve RSUs were placed along the work zone segment and sixteen variables were extracted from the simulation results to explore travel time estimation and prediction. For the travel time analysis, four types of models were constructed, including linear regression, multivariate adaptive regression splines (MARS), stepwise regression and elastic net. The results show that the modeling approaches under consideration have similar performance in terms of the Root of Mean Square Error (RMSE), which provides an opportunity for model selection based on additional factors including the number and locations of the RSUs according to the significant variables identified in the various models. Among the four approaches, the stepwise regression model only needs variables from two RSUs: one placed sufficiently upstream of the work zone and one at the end of the work zone.