 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Automatic Manipulation of Intra-cardiac Echocardiography Catheter
Sep 12, 2020
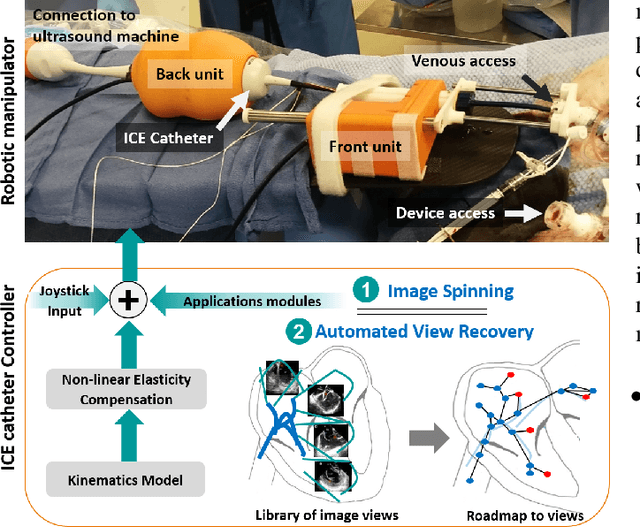
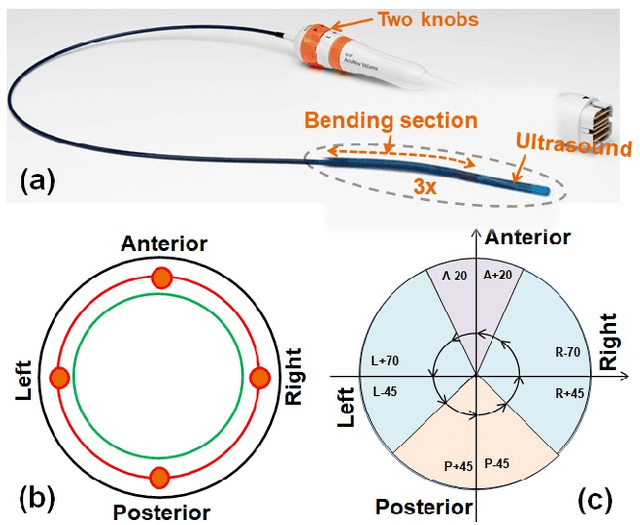
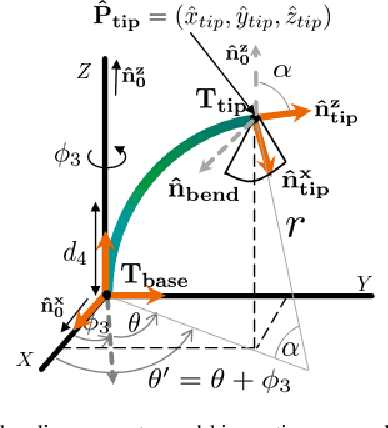
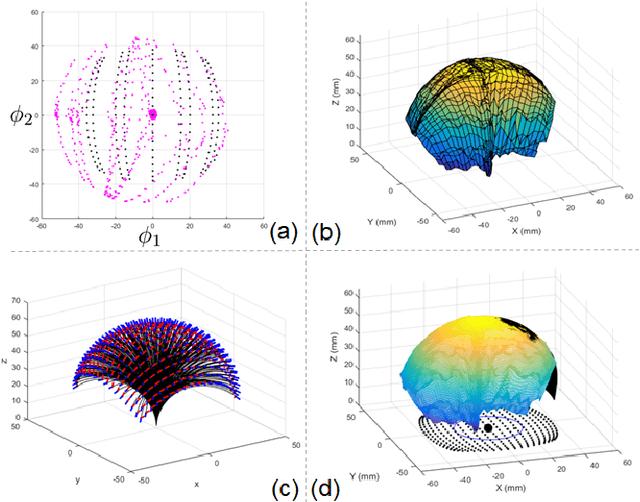
Intra-cardiac Echocardiography (ICE) has been evolving as a real-time imaging modality of choice for guiding electrophiosology and structural heart interventions. ICE provides real-time imaging of anatomy, catheters, and complications such as pericardial effusion or thrombus formation. However, there now exists a high cognitive demand on physicians with the increased reliance on intraprocedural imaging. In response, we present a robotic manipulator for AcuNav ICE catheters to alleviate the physician's burden and support applied methods for more automated. Herein, we introduce two methods towards these goals: (1) a data-driven method to compensate kinematic model errors due to non-linear elasticity in catheter bending, providing more precise robotic control and (2) an automated image recovery process that allows physicians to bookmark images during intervention and automatically return with the push of a button. To validate our error compensation method, we demonstrate a complex rotation of the ultrasound imaging plane evaluated on benchtop. Automated view recovery is validated by repeated imaging of landmarks on benchtop and in vivo experiments with position- and image-based analysis. Results support that a robotic-assist system for more autonomous ICE can provide a safe and efficient tool, potentially reducing the execution time and allowing more complex procedures to become common place.
FedV: Privacy-Preserving Federated Learning over Vertically Partitioned Data
Mar 05, 2021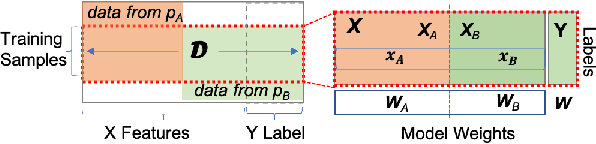


Federated learning (FL) has been proposed to allow collaborative training of machine learning (ML) models among multiple parties where each party can keep its data private. In this paradigm, only model updates, such as model weights or gradients, are shared. Many existing approaches have focused on horizontal FL, where each party has the entire feature set and labels in the training data set. However, many real scenarios follow a vertically-partitioned FL setup, where a complete feature set is formed only when all the datasets from the parties are combined, and the labels are only available to a single party. Privacy-preserving vertical FL is challenging because complete sets of labels and features are not owned by one entity. Existing approaches for vertical FL require multiple peer-to-peer communications among parties, leading to lengthy training times, and are restricted to (approximated) linear models and just two parties. To close this gap, we propose FedV, a framework for secure gradient computation in vertical settings for several widely used ML models such as linear models, logistic regression, and support vector machines. FedV removes the need for peer-to-peer communication among parties by using functional encryption schemes; this allows FedV to achieve faster training times. It also works for larger and changing sets of parties. We empirically demonstrate the applicability for multiple types of ML models and show a reduction of 10%-70% of training time and 80% to 90% in data transfer with respect to the state-of-the-art approaches.
Learning from Sparse Demonstrations
Aug 05, 2020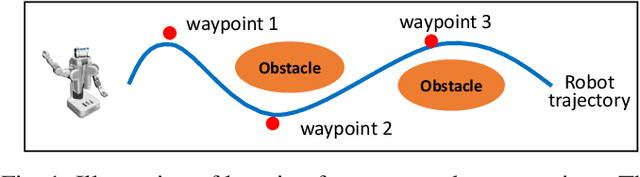
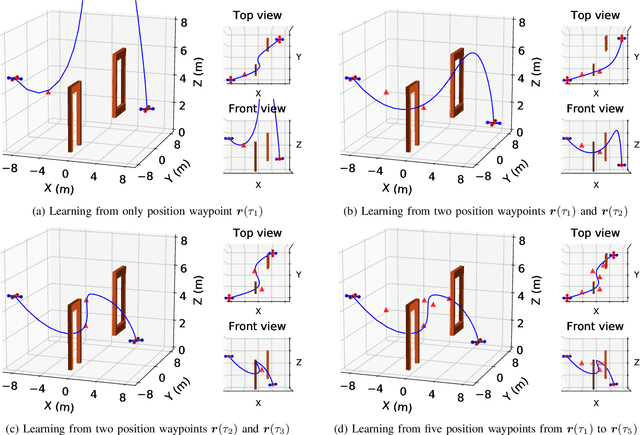
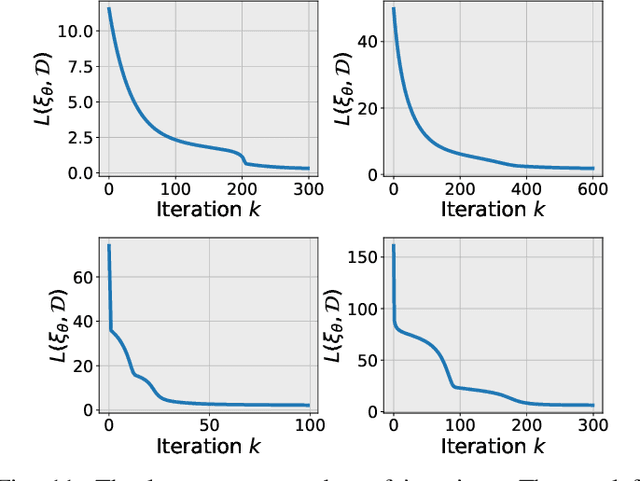
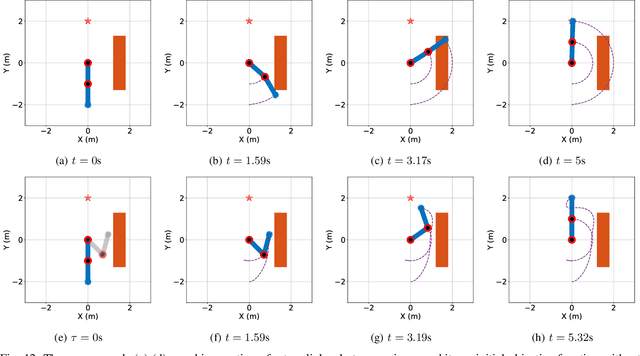
This paper proposes an approach which enables a robot to learn an objective function from sparse demonstrations of an expert. The demonstrations are given by a small number of sparse waypoints; the waypoints are desired outputs of the robot's trajectory at certain time instances, sparsely located within a demonstration time horizon. The duration of the expert's demonstration may be different from the actual duration of the robot's execution. The proposed method enables to jointly learn an objective function and a time-warping function such that the robot's reproduced trajectory has minimal distance to the sparse demonstration waypoints. Unlike existing inverse reinforcement learning techniques, the proposed approach uses the differential Pontryagin's maximum principle, which allows direct minimization of the distance between the robot's trajectory and the sparse demonstration waypoints and enables simultaneous learning of an objective function and a time-warping function. We demonstrate the effectiveness of the proposed approach in various simulated scenarios. We apply the method to learn motion planning/control of a 6-DoF maneuvering unmanned aerial vehicle (UAV) and a robot arm in environments with obstacles. The results show that a robot is able to learn a valid objective function to avoid obstacles with few demonstrated waypoints.
Feature-based visual odometry prior for real-time semi-dense stereo SLAM
Oct 17, 2018
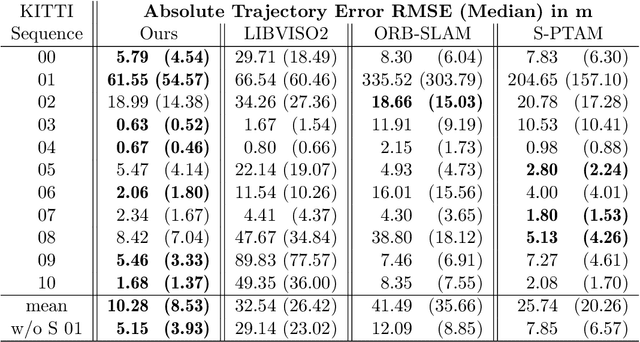
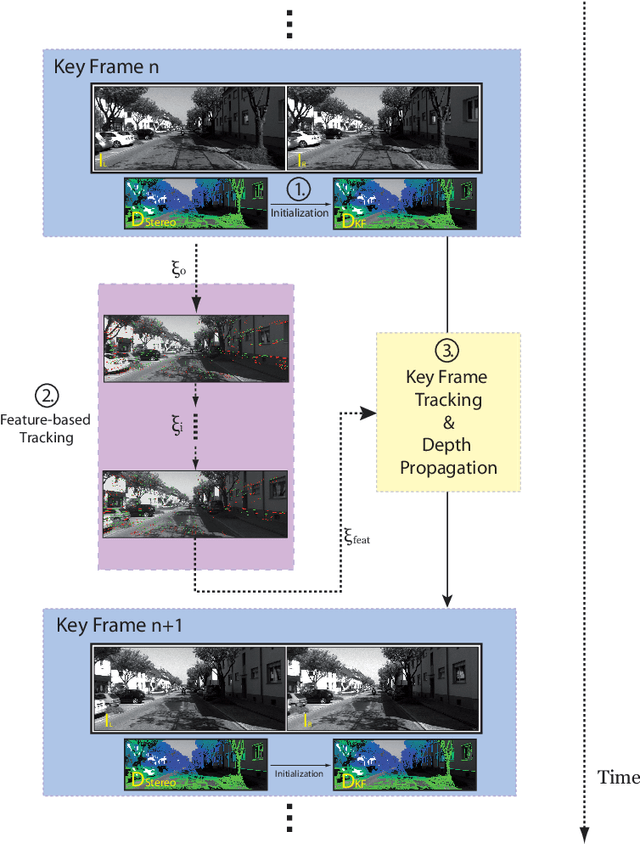
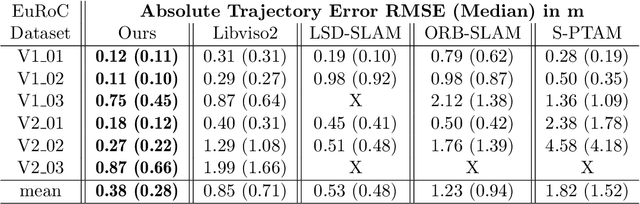
Robust and fast motion estimation and mapping is a key prerequisite for autonomous operation of mobile robots. The goal of performing this task solely on a stereo pair of video cameras is highly demanding and bears conflicting objectives: on one hand, the motion has to be tracked fast and reliably, on the other hand, high-level functions like navigation and obstacle avoidance depend crucially on a complete and accurate environment representation. In this work, we propose a two-layer approach for visual odometry and SLAM with stereo cameras that runs in real-time and combines feature-based matching with semi-dense direct image alignment. Our method initializes semi-dense depth estimation, which is computationally expensive, from motion that is tracked by a fast but robust keypoint-based method. Experiments on public benchmark and proprietary datasets show that our approach is faster than state-of-the-art methods without losing accuracy and yields comparable map building capabilities. Moreover, our approach is shown to handle large inter-frame motion and illumination changes much more robustly than its direct counterparts.
Real-Time Grasp Planning for Multi-Fingered Hands by Finger Splitting
Jul 28, 2018

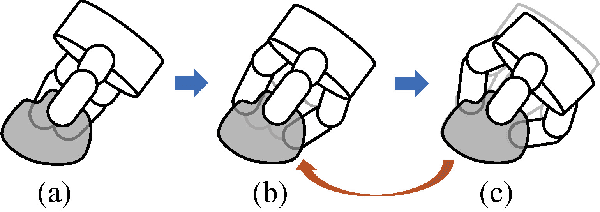
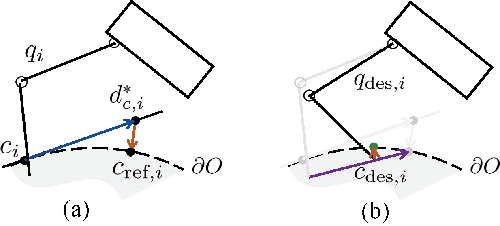
Grasp planning for multi-fingered hands is computationally expensive due to the joint-contact coupling, surface nonlinearities and high dimensionality, thus is generally not affordable for real-time implementations. Traditional planning methods by optimization, sampling or learning work well in planning for parallel grippers but remain challenging for multi-fingered hands. This paper proposes a strategy called finger splitting, to plan precision grasps for multi-fingered hands starting from optimal parallel grasps. The finger splitting is optimized by a dual-stage iterative optimization including a contact point optimization (CPO) and a palm pose optimization (PPO), to gradually split fingers and adjust both the contact points and the palm pose. The dual-stage optimization is able to consider both the object grasp quality and hand manipulability, address the nonlinearities and coupling, and achieve efficient convergence within one second. Simulation results demonstrate the effectiveness of the proposed approach. The simulation video is available at: http://me.berkeley.edu/\%7Eyongxiangfan/IROS2018/fingersplit.html
Synthesising a Database of Parameterised Linear and Non-Linear Invariants for Time-Series Constraints
Jan 15, 2019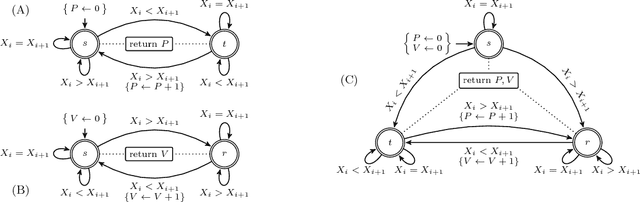
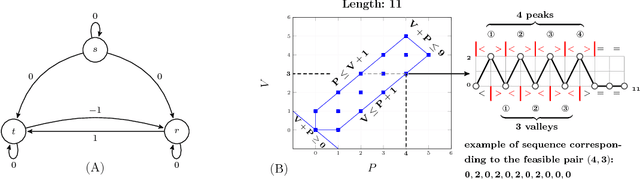
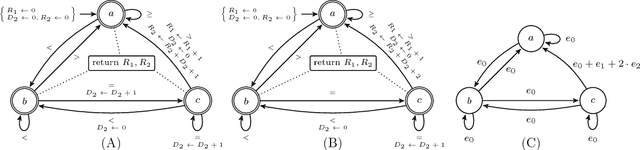
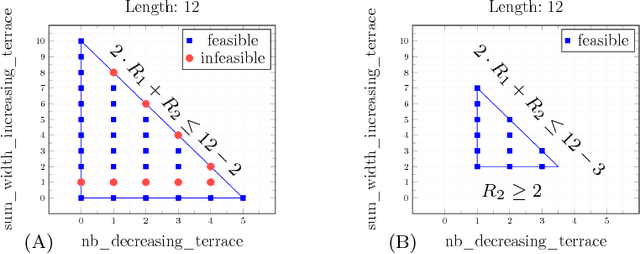
Many constraints restricting the result of some computations over an integer sequence can be compactly represented by register automata. We improve the propagation of the conjunction of such constraints on the same sequence by synthesising a database of linear and non-linear invariants using their register-automaton representation. The obtained invariants are formulae parameterised by a function of the sequence length and proven to be true for any long enough sequence. To assess the quality of such linear invariants, we developed a method to verify whether a generated linear invariant is a facet of the convex hull of the feasible points. This method, as well as the proof of non-linear invariants, are based on the systematic generation of constant-size deterministic finite automata that accept all integer sequences whose result verifies some simple condition. We apply such methodology to a set of 44 time-series constraints and obtain 1400 linear invariants from which 70% are facet defining, and 600 non-linear invariants, which were tested on short-term electricity production problems.
SAED: Edge-Based Intelligence for Privacy-Preserving Enterprise Search on the Cloud
Mar 11, 2021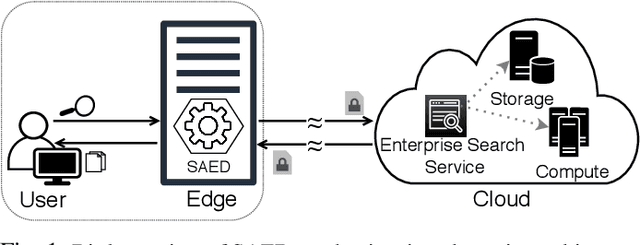
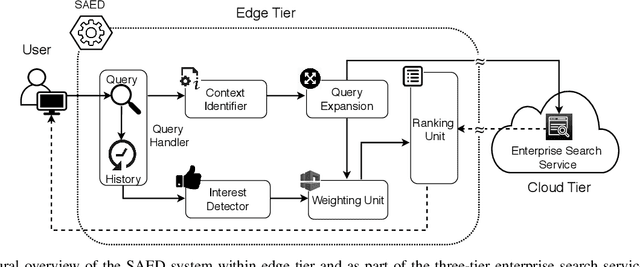
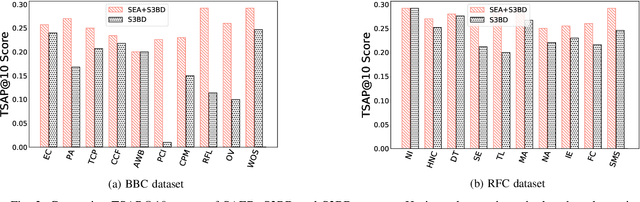
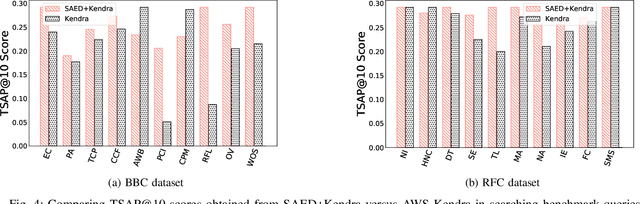
Cloud-based enterprise search services (e.g., AWS Kendra) have been entrancing big data owners by offering convenient and real-time search solutions to them. However, the problem is that individuals and organizations possessing confidential big data are hesitant to embrace such services due to valid data privacy concerns. In addition, to offer an intelligent search, these services access the user search history that further jeopardizes his/her privacy. To overcome the privacy problem, the main idea of this research is to separate the intelligence aspect of the search from its pattern matching aspect. According to this idea, the search intelligence is provided by an on-premises edge tier and the shared cloud tier only serves as an exhaustive pattern matching search utility. We propose Smartness At Edge (SAED mechanism that offers intelligence in the form of semantic and personalized search at the edge tier while maintaining privacy of the search on the cloud tier. At the edge tier, SAED uses a knowledge-based lexical database to expand the query and cover its semantics. SAED personalizes the search via an RNN model that can learn the user interest. A word embedding model is used to retrieve documents based on their semantic relevance to the search query. SAED is generic and can be plugged into existing enterprise search systems and enable them to offer intelligent and privacy-preserving search without enforcing any change on them. Evaluation results on two enterprise search systems under real settings and verified by human users demonstrate that SAED can improve the relevancy of the retrieved results by on average 24% for plain-text and 75% for encrypted generic datasets.
A Cooperative Dynamic Task Assignment Framework for COTSBot AUVs
Jan 11, 2021
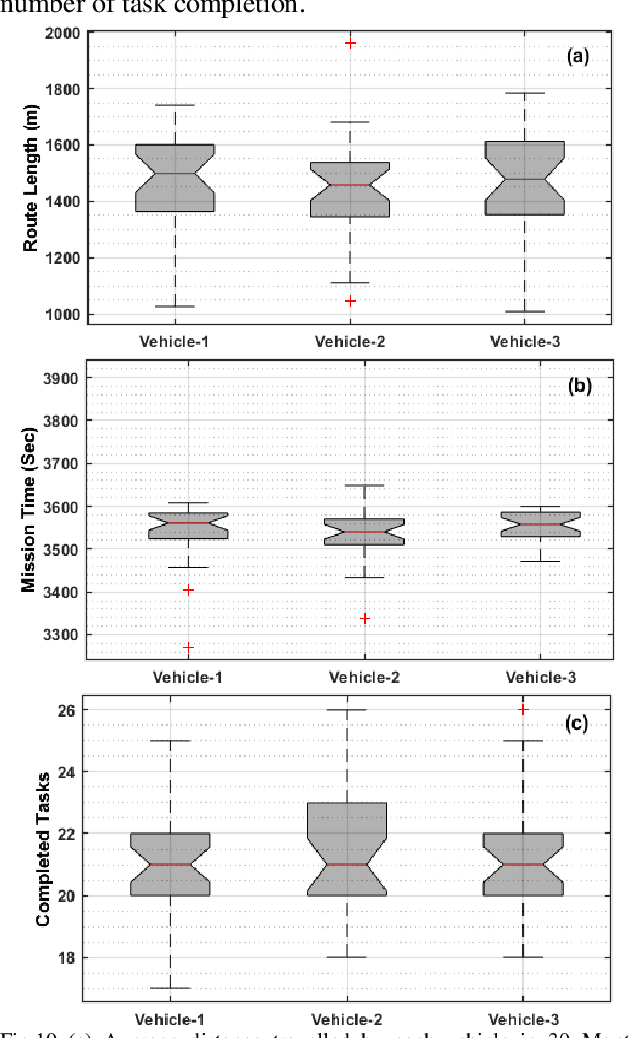
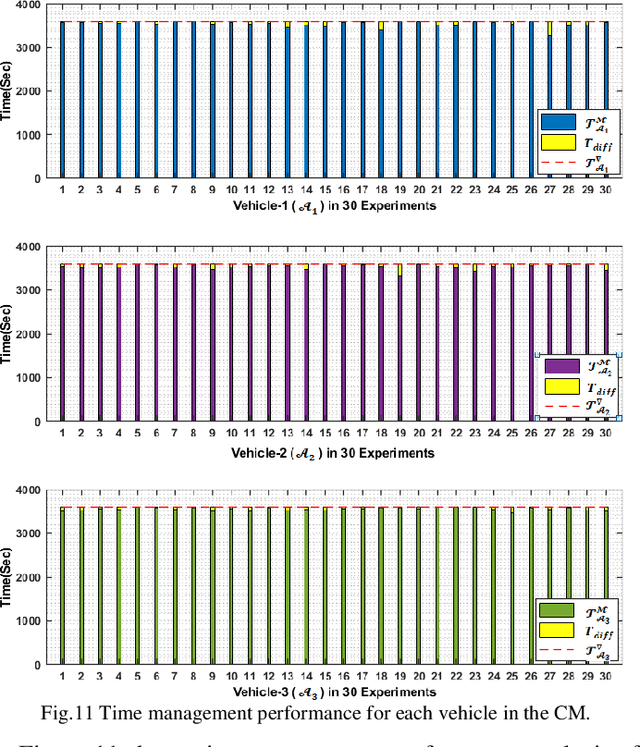
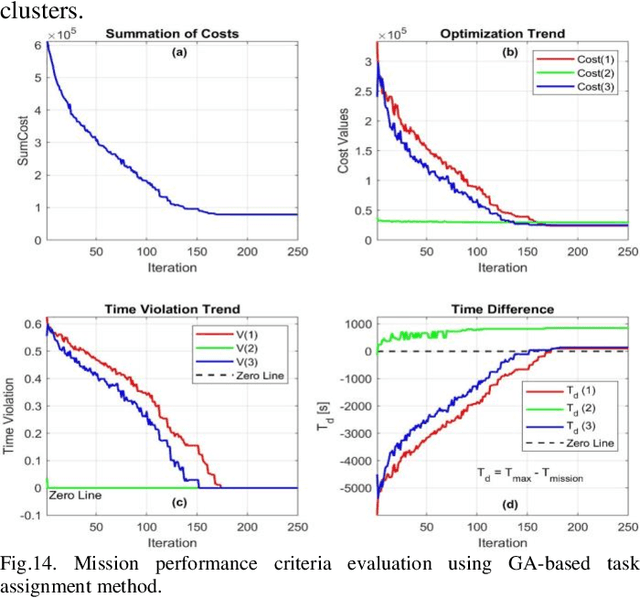
This paper presents a cooperative dynamic task assignment framework for a certain class of Autonomous Underwater Vehicles (AUVs) employed to control outbreak of Crown-Of-Thorns Starfish (COTS) in Australia's Great Barrier Reef. The problem of monitoring and controlling the COTS is transcribed into a constrained task assignment problem in which eradicating clusters of COTS, by the injection system of COTSbot AUVs, is considered as a task. A probabilistic map of the operating environment including seabed terrain, clusters of COTS, and coastlines is constructed. Then, a novel heuristic algorithm called Heuristic Fleet Cooperation (HFC) is developed to provide a cooperative injection of the COTSbot AUVs to the maximum possible COTS in an assigned mission time. Extensive simulation studies together with quantitative performance analysis are conducted to demonstrate the effectiveness and robustness of the proposed cooperative task assignment algorithm in eradicating the COTS in the Great Barrier Reef.
Streaming Simultaneous Speech Translation with Augmented Memory Transformer
Oct 30, 2020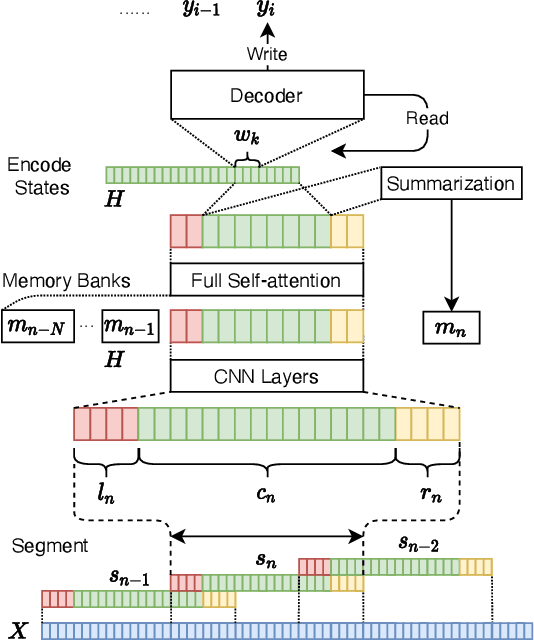
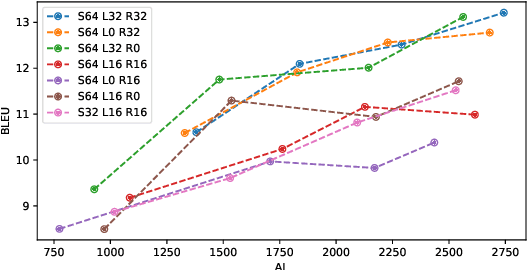
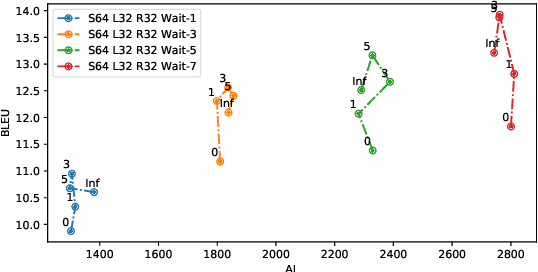
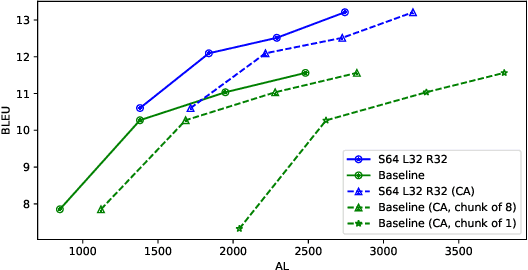
Transformer-based models have achieved state-of-the-art performance on speech translation tasks. However, the model architecture is not efficient enough for streaming scenarios since self-attention is computed over an entire input sequence and the computational cost grows quadratically with the length of the input sequence. Nevertheless, most of the previous work on simultaneous speech translation, the task of generating translations from partial audio input, ignores the time spent in generating the translation when analyzing the latency. With this assumption, a system may have good latency quality trade-offs but be inapplicable in real-time scenarios. In this paper, we focus on the task of streaming simultaneous speech translation, where the systems are not only capable of translating with partial input but are also able to handle very long or continuous input. We propose an end-to-end transformer-based sequence-to-sequence model, equipped with an augmented memory transformer encoder, which has shown great success on the streaming automatic speech recognition task with hybrid or transducer-based models. We conduct an empirical evaluation of the proposed model on segment, context and memory sizes and we compare our approach to a transformer with a unidirectional mask.
Opportunistic Self Organizing Migrating Algorithm for Real-Time Dynamic Traveling Salesman Problem
Sep 12, 2017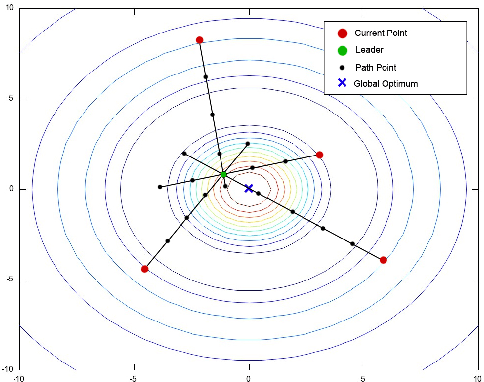
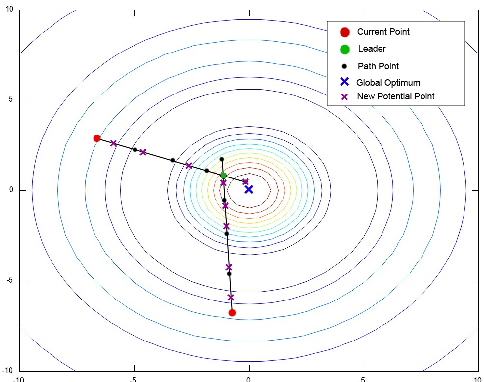
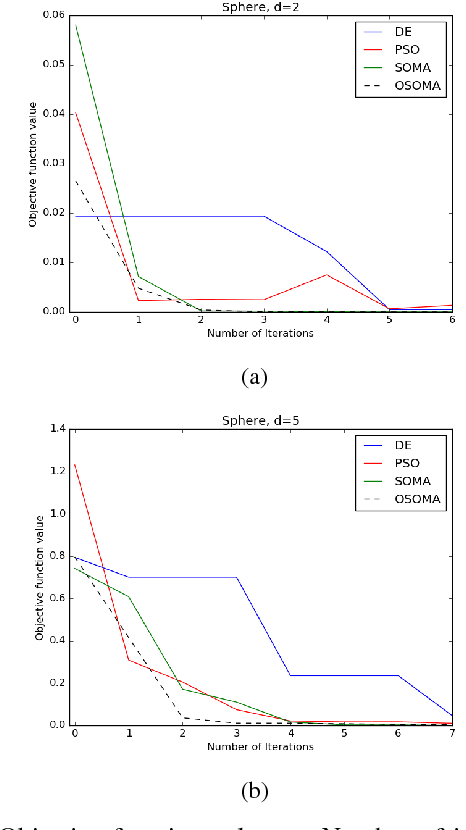
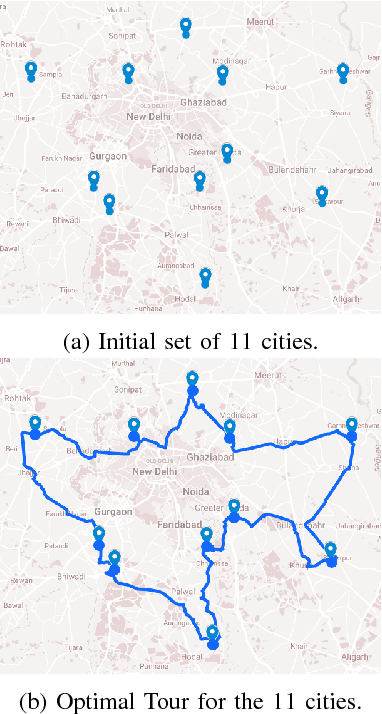
Self Organizing Migrating Algorithm (SOMA) is a meta-heuristic algorithm based on the self-organizing behavior of individuals in a simulated social environment. SOMA performs iterative computations on a population of potential solutions in the given search space to obtain an optimal solution. In this paper, an Opportunistic Self Organizing Migrating Algorithm (OSOMA) has been proposed that introduces a novel strategy to generate perturbations effectively. This strategy allows the individual to span across more possible solutions and thus, is able to produce better solutions. A comprehensive analysis of OSOMA on multi-dimensional unconstrained benchmark test functions is performed. OSOMA is then applied to solve real-time Dynamic Traveling Salesman Problem (DTSP). The problem of real-time DTSP has been stipulated and simulated using real-time data from Google Maps with a varying cost-metric between any two cities. Although DTSP is a very common and intuitive model in the real world, its presence in literature is still very limited. OSOMA performs exceptionally well on the problems mentioned above. To substantiate this claim, the performance of OSOMA is compared with SOMA, Differential Evolution and Particle Swarm Optimization.