 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Modeling the locomotion of articulated soft robots in granular medium
Mar 06, 2021
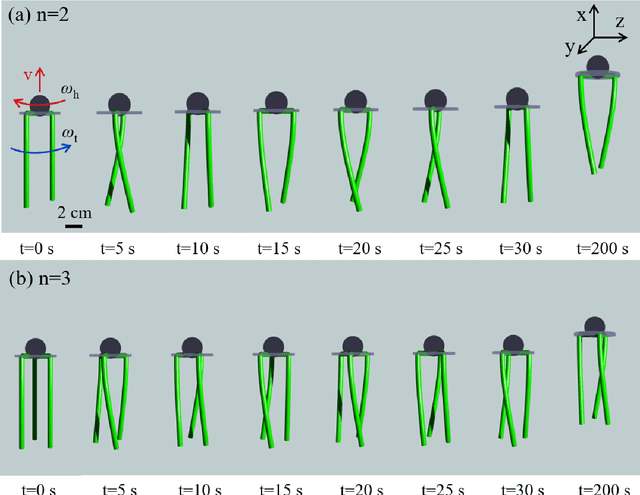

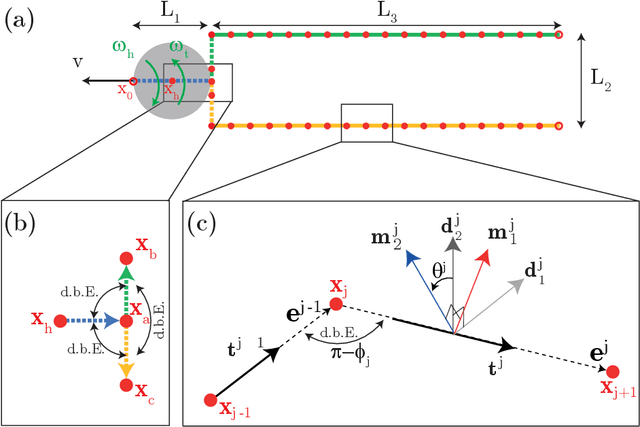
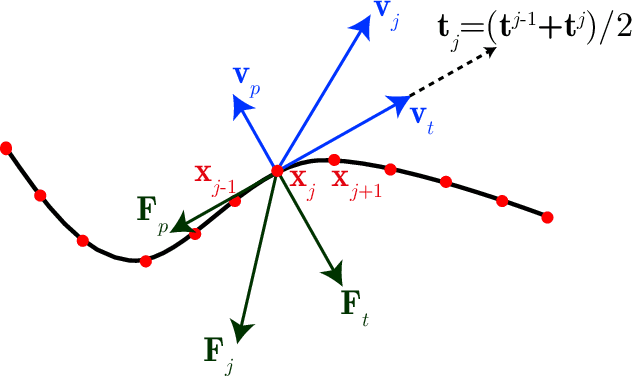
Soft robots, in contrast to their rigid counter parts, have infinite degrees of freedom that are coupled with their interaction with the environment. We consider the locomotion of an untethered robot, in the granular medium, comprised of multiple flexible flagella that rotate about an axis by a motor. Drag from the grains causes the flagella to deform and the deformed shape generates a net forward propulsion. This external drag force depends on the shape of the flagella, while the change in flagellar shape is the result of the competition between the external loading and elastic forces. We introduce a numerical tool that couples discrete differential geometry based simulation of elastic rods - our model for flagella - and a resistive force theory based model for the drag. In parallel with simulations, we conduct experiments to quantify the propulsive speed of this class of robots. We find reasonable quantitative agreement between experiments and simulations. Owing to a rod-based kinematic representation of the robot, the simulation runs faster than real-time, and, therefore, we can use it as a design tool for this class of soft robots. We find that there is an optimal rotational speed at which maximum efficiency is achieved. Moreover, both experiments and simulations show that increasing the number of flagella decreases the speed of the robot. We also gain insight into the mechanics of granular medium - while resistive force theory can successfully describe the propulsion at low number of flagella, it fails when more flagella are added to the robot.
Accurate Learning of Graph Representations with Graph Multiset Pooling
Feb 27, 2021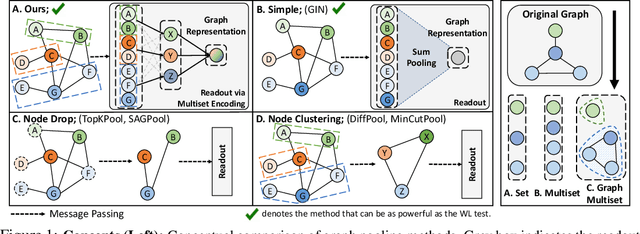
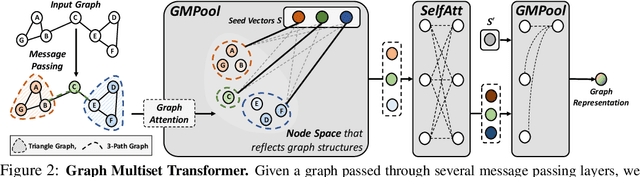
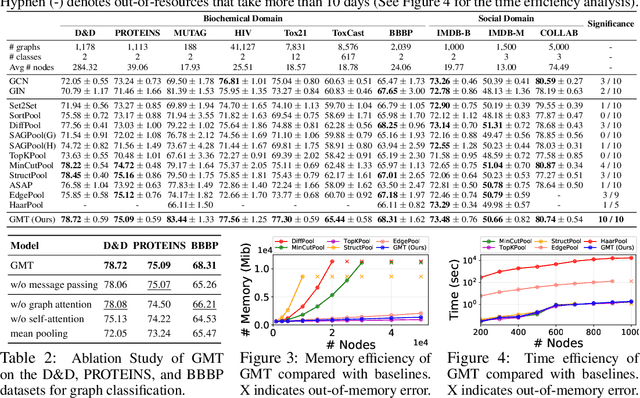
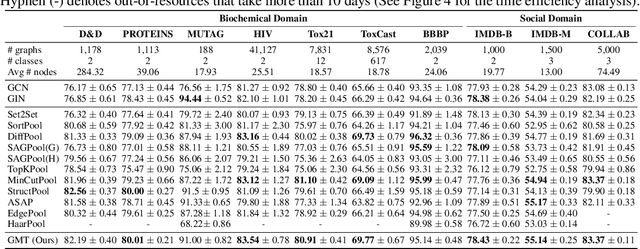
Graph neural networks have been widely used on modeling graph data, achieving impressive results on node classification and link prediction tasks. Yet, obtaining an accurate representation for a graph further requires a pooling function that maps a set of node representations into a compact form. A simple sum or average over all node representations considers all node features equally without consideration of their task relevance, and any structural dependencies among them. Recently proposed hierarchical graph pooling methods, on the other hand, may yield the same representation for two different graphs that are distinguished by the Weisfeiler-Lehman test, as they suboptimally preserve information from the node features. To tackle these limitations of existing graph pooling methods, we first formulate the graph pooling problem as a multiset encoding problem with auxiliary information about the graph structure, and propose a Graph Multiset Transformer (GMT) which is a multi-head attention based global pooling layer that captures the interaction between nodes according to their structural dependencies. We show that GMT satisfies both injectiveness and permutation invariance, such that it is at most as powerful as the Weisfeiler-Lehman graph isomorphism test. Moreover, our methods can be easily extended to the previous node clustering approaches for hierarchical graph pooling. Our experimental results show that GMT significantly outperforms state-of-the-art graph pooling methods on graph classification benchmarks with high memory and time efficiency, and obtains even larger performance gain on graph reconstruction and generation tasks.
Depth-Aware Action Recognition: Pose-Motion Encoding through Temporal Heatmaps
Nov 26, 2020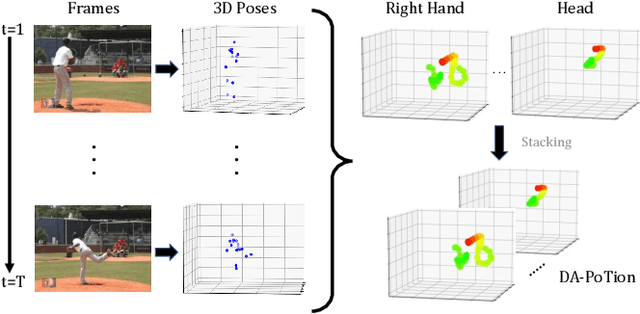

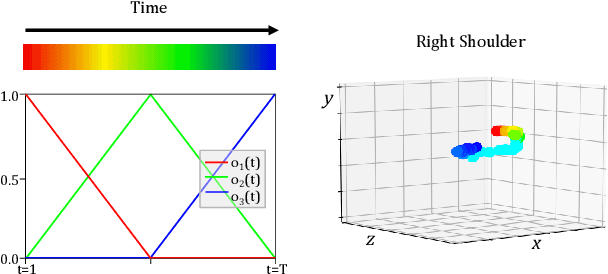
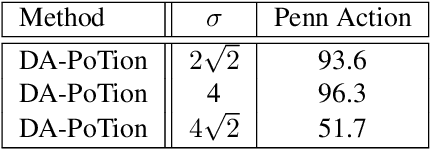
Most state-of-the-art methods for action recognition rely only on 2D spatial features encoding appearance, motion or pose. However, 2D data lacks the depth information, which is crucial for recognizing fine-grained actions. In this paper, we propose a depth-aware volumetric descriptor that encodes pose and motion information in a unified representation for action classification in-the-wild. Our framework is robust to many challenges inherent to action recognition, e.g. variation in viewpoint, scene, clothing and body shape. The key component of our method is the Depth-Aware Pose Motion representation (DA-PoTion), a new video descriptor that encodes the 3D movement of semantic keypoints of the human body. Given a video, we produce human joint heatmaps for each frame using a state-of-the-art 3D human pose regressor and we give each of them a unique color code according to the relative time in the clip. Then, we aggregate such 3D time-encoded heatmaps for all human joints to obtain a fixed-size descriptor (DA-PoTion), which is suitable for classifying actions using a shallow 3D convolutional neural network (CNN). The DA-PoTion alone defines a new state-of-the-art on the Penn Action Dataset. Moreover, we leverage the intrinsic complementarity of our pose motion descriptor with appearance based approaches by combining it with Inflated 3D ConvNet (I3D) to define a new state-of-the-art on the JHMDB Dataset.
Instance-based learning using the Half-Space Proximal Graph
Feb 04, 2021
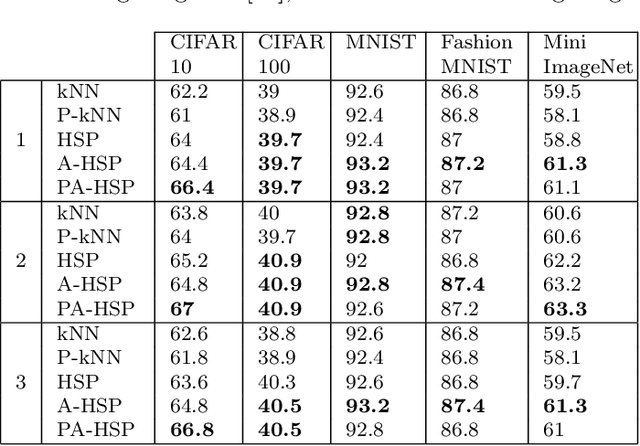
The primary example of instance-based learning is the $k$-nearest neighbor rule (kNN), praised for its simplicity and the capacity to adapt to new unseen data and toss away old data. The main disadvantages often mentioned are the classification complexity, which is $O(n)$, and the estimation of the parameter $k$, the number of nearest neighbors to be used. The use of indexes at classification time lifts the former disadvantage, while there is no conclusive method for the latter. This paper presents a parameter-free instance-based learning algorithm using the {\em Half-Space Proximal} (HSP) graph. The HSP neighbors simultaneously possess proximity and variety concerning the center node. To classify a given query, we compute its HSP neighbors and apply a simple majority rule over them. In our experiments, the resulting classifier bettered $KNN$ for any $k$ in a battery of datasets. This improvement sticks even when applying weighted majority rules to both kNN and HSP classifiers. Surprisingly, when using a probabilistic index to approximate the HSP graph and consequently speeding-up the classification task, our method could {\em improve} its accuracy in stark contrast with the kNN classifier, which worsens with a probabilistic index.
FedV: Privacy-Preserving Federated Learning over Vertically Partitioned Data
Mar 05, 2021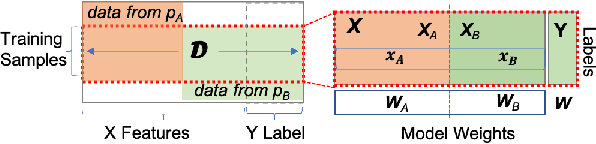


Federated learning (FL) has been proposed to allow collaborative training of machine learning (ML) models among multiple parties where each party can keep its data private. In this paradigm, only model updates, such as model weights or gradients, are shared. Many existing approaches have focused on horizontal FL, where each party has the entire feature set and labels in the training data set. However, many real scenarios follow a vertically-partitioned FL setup, where a complete feature set is formed only when all the datasets from the parties are combined, and the labels are only available to a single party. Privacy-preserving vertical FL is challenging because complete sets of labels and features are not owned by one entity. Existing approaches for vertical FL require multiple peer-to-peer communications among parties, leading to lengthy training times, and are restricted to (approximated) linear models and just two parties. To close this gap, we propose FedV, a framework for secure gradient computation in vertical settings for several widely used ML models such as linear models, logistic regression, and support vector machines. FedV removes the need for peer-to-peer communication among parties by using functional encryption schemes; this allows FedV to achieve faster training times. It also works for larger and changing sets of parties. We empirically demonstrate the applicability for multiple types of ML models and show a reduction of 10%-70% of training time and 80% to 90% in data transfer with respect to the state-of-the-art approaches.
SAED: Edge-Based Intelligence for Privacy-Preserving Enterprise Search on the Cloud
Mar 11, 2021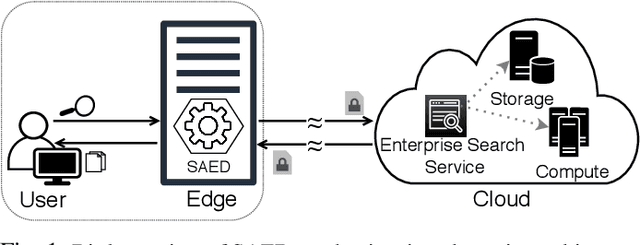
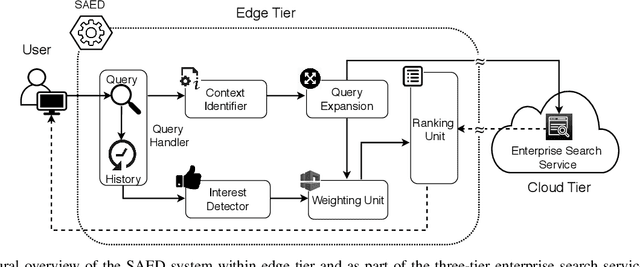
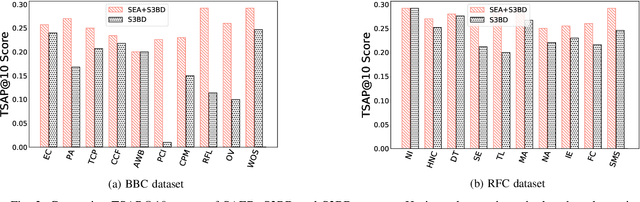
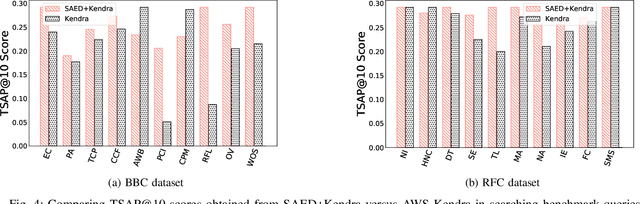
Cloud-based enterprise search services (e.g., AWS Kendra) have been entrancing big data owners by offering convenient and real-time search solutions to them. However, the problem is that individuals and organizations possessing confidential big data are hesitant to embrace such services due to valid data privacy concerns. In addition, to offer an intelligent search, these services access the user search history that further jeopardizes his/her privacy. To overcome the privacy problem, the main idea of this research is to separate the intelligence aspect of the search from its pattern matching aspect. According to this idea, the search intelligence is provided by an on-premises edge tier and the shared cloud tier only serves as an exhaustive pattern matching search utility. We propose Smartness At Edge (SAED mechanism that offers intelligence in the form of semantic and personalized search at the edge tier while maintaining privacy of the search on the cloud tier. At the edge tier, SAED uses a knowledge-based lexical database to expand the query and cover its semantics. SAED personalizes the search via an RNN model that can learn the user interest. A word embedding model is used to retrieve documents based on their semantic relevance to the search query. SAED is generic and can be plugged into existing enterprise search systems and enable them to offer intelligent and privacy-preserving search without enforcing any change on them. Evaluation results on two enterprise search systems under real settings and verified by human users demonstrate that SAED can improve the relevancy of the retrieved results by on average 24% for plain-text and 75% for encrypted generic datasets.
Automatic differentiation of Sylvester, Lyapunov, and algebraic Riccati equations
Nov 23, 2020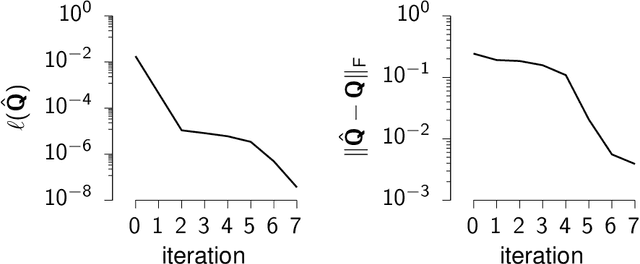
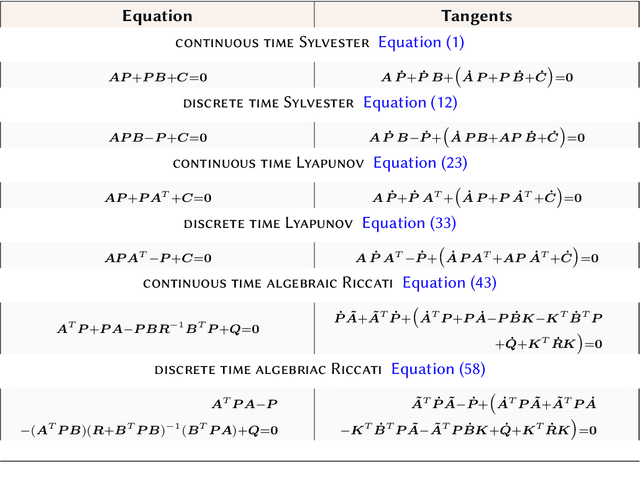

Sylvester, Lyapunov, and algebraic Riccati equations are the bread and butter of control theorists. They are used to compute infinite-horizon Gramians, solve optimal control problems in continuous or discrete time, and design observers. While popular numerical computing frameworks (e.g., scipy) provide efficient solvers for these equations, these solvers are still largely missing from most automatic differentiation libraries. Here, we derive the forward and reverse-mode derivatives of the solutions to all three types of equations, and showcase their application on an inverse control problem.
Towards Searching Efficient and Accurate Neural Network Architectures in Binary Classification Problems
Jan 16, 2021
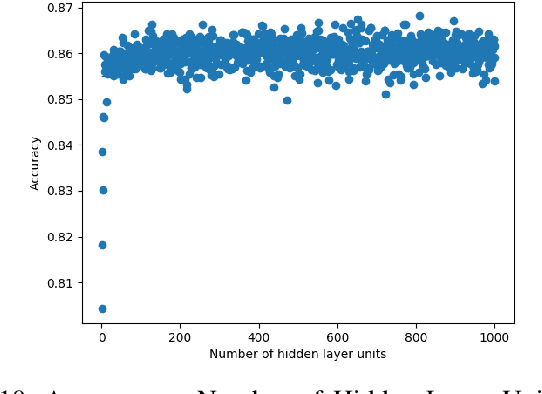
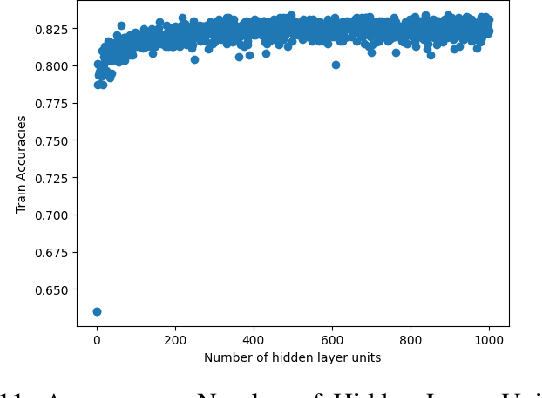
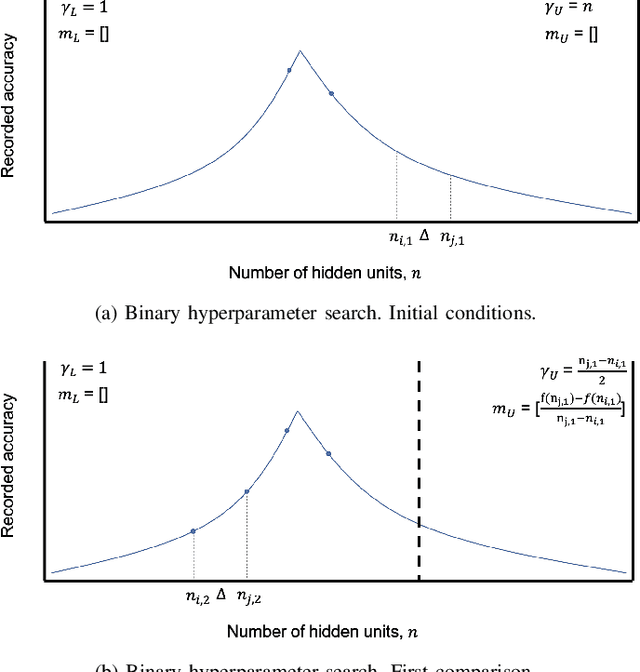
In recent years, deep neural networks have had great success in machine learning and pattern recognition. Architecture size for a neural network contributes significantly to the success of any neural network. In this study, we optimize the selection process by investigating different search algorithms to find a neural network architecture size that yields the highest accuracy. We apply binary search on a very well-defined binary classification network search space and compare the results to those of linear search. We also propose how to relax some of the assumptions regarding the dataset so that our solution can be generalized to any binary classification problem. We report a 100-fold running time improvement over the naive linear search when we apply the binary search method to our datasets in order to find the best architecture candidate. By finding the optimal architecture size for any binary classification problem quickly, we hope that our research contributes to discovering intelligent algorithms for optimizing architecture size selection in machine learning.
Integration of Convolutional Neural Networks in Mobile Applications
Mar 11, 2021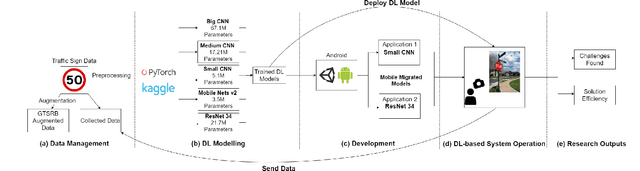
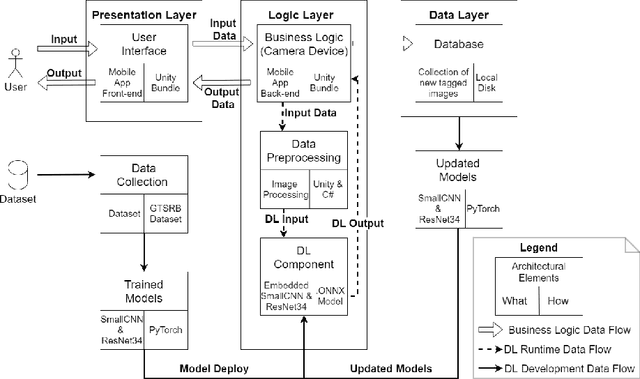

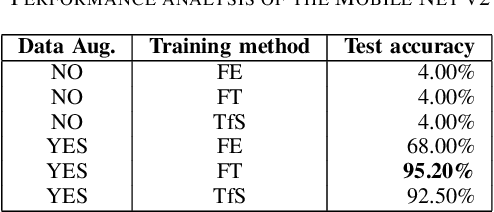
When building Deep Learning (DL) models, data scientists and software engineers manage the trade-off between their accuracy, or any other suitable success criteria, and their complexity. In an environment with high computational power, a common practice is making the models go deeper by designing more sophisticated architectures. However, in the context of mobile devices, which possess less computational power, keeping complexity under control is a must. In this paper, we study the performance of a system that integrates a DL model as a trade-off between the accuracy and the complexity. At the same time, we relate the complexity to the efficiency of the system. With this, we present a practical study that aims to explore the challenges met when optimizing the performance of DL models becomes a requirement. Concretely, we aim to identify: (i) the most concerning challenges when deploying DL-based software in mobile applications; and (ii) the path for optimizing the performance trade-off. We obtain results that verify many of the identified challenges in the related work such as the availability of frameworks and the software-data dependency. We provide a documentation of our experience when facing the identified challenges together with the discussion of possible solutions to them. Additionally, we implement a solution to the sustainability of the DL models when deployed in order to reduce the severity of other identified challenges. Moreover, we relate the performance trade-off to a new defined challenge featuring the impact of the complexity in the obtained accuracy. Finally, we discuss and motivate future work that aims to provide solutions to the more open challenges found.
Mesh Reconstruction from Aerial Images for Outdoor Terrain Mapping Using Joint 2D-3D Learning
Jan 06, 2021
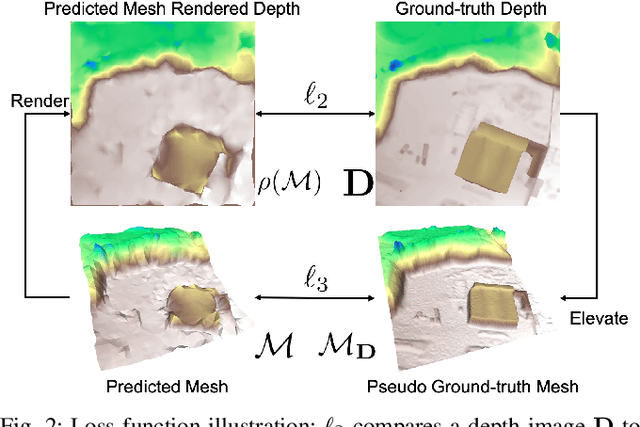
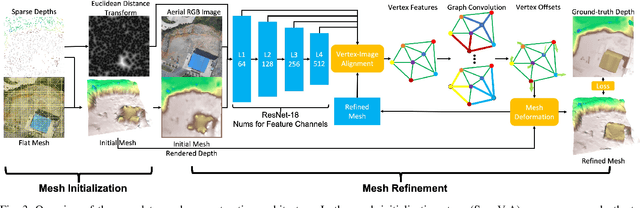
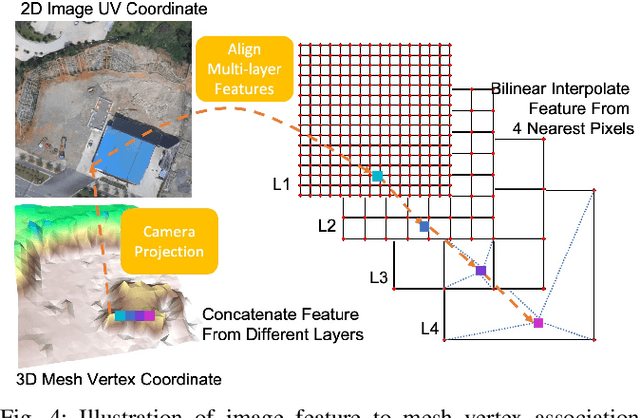
This paper addresses outdoor terrain mapping using overhead images obtained from an unmanned aerial vehicle. Dense depth estimation from aerial images during flight is challenging. While feature-based localization and mapping techniques can deliver real-time odometry and sparse points reconstruction, a dense environment model is generally recovered offline with significant computation and storage. This paper develops a joint 2D-3D learning approach to reconstruct local meshes at each camera keyframe, which can be assembled into a global environment model. Each local mesh is initialized from sparse depth measurements. We associate image features with the mesh vertices through camera projection and apply graph convolution to refine the mesh vertices based on joint 2-D reprojected depth and 3-D mesh supervision. Quantitative and qualitative evaluations using real aerial images show the potential of our method to support environmental monitoring and surveillance applications.