 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Task Self-Supervised Pre-Training for Music Classification
Feb 05, 2021
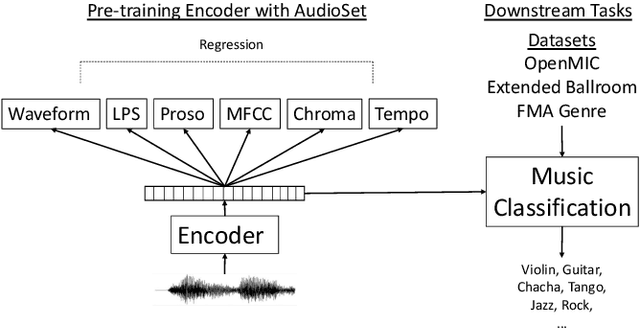
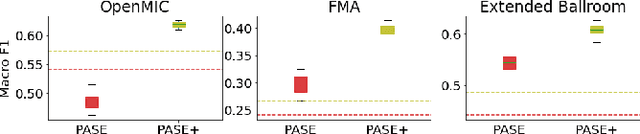
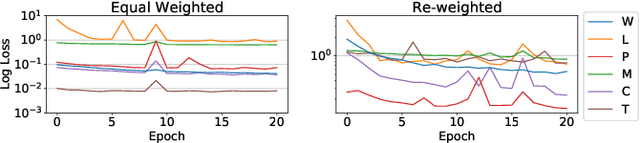
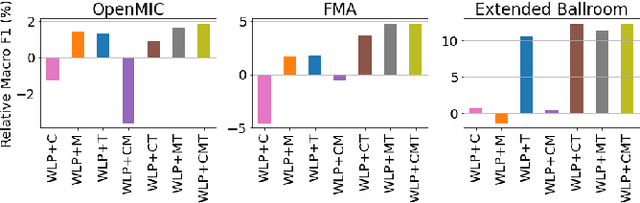
Deep learning is very data hungry, and supervised learning especially requires massive labeled data to work well. Machine listening research often suffers from limited labeled data problem, as human annotations are costly to acquire, and annotations for audio are time consuming and less intuitive. Besides, models learned from labeled dataset often embed biases specific to that particular dataset. Therefore, unsupervised learning techniques become popular approaches in solving machine listening problems. Particularly, a self-supervised learning technique utilizing reconstructions of multiple hand-crafted audio features has shown promising results when it is applied to speech domain such as emotion recognition and automatic speech recognition (ASR). In this paper, we apply self-supervised and multi-task learning methods for pre-training music encoders, and explore various design choices including encoder architectures, weighting mechanisms to combine losses from multiple tasks, and worker selections of pretext tasks. We investigate how these design choices interact with various downstream music classification tasks. We find that using various music specific workers altogether with weighting mechanisms to balance the losses during pre-training helps improve and generalize to the downstream tasks.
Efficient Optimal Selection for Composited Advertising Creatives with Tree Structure
Mar 02, 2021

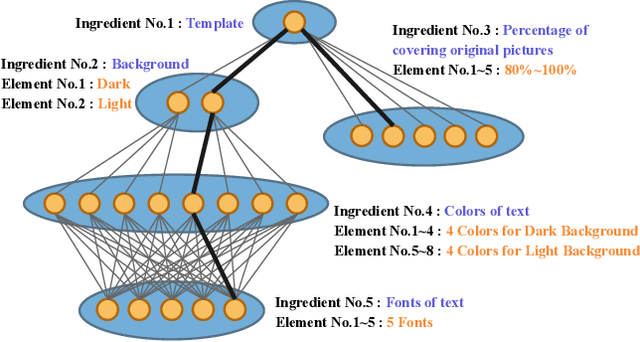

Ad creatives are one of the prominent mediums for online e-commerce advertisements. Ad creatives with enjoyable visual appearance may increase the click-through rate (CTR) of products. Ad creatives are typically handcrafted by advertisers and then delivered to the advertising platforms for advertisement. In recent years, advertising platforms are capable of instantly compositing ad creatives with arbitrarily designated elements of each ingredient, so advertisers are only required to provide basic materials. While facilitating the advertisers, a great number of potential ad creatives can be composited, making it difficult to accurately estimate CTR for them given limited real-time feedback. To this end, we propose an Adaptive and Efficient ad creative Selection (AES) framework based on a tree structure. The tree structure on compositing ingredients enables dynamic programming for efficient ad creative selection on the basis of CTR. Due to limited feedback, the CTR estimator is usually of high variance. Exploration techniques based on Thompson sampling are widely used for reducing variances of the CTR estimator, alleviating feedback sparsity. Based on the tree structure, Thompson sampling is adapted with dynamic programming, leading to efficient exploration for potential ad creatives with the largest CTR. We finally evaluate the proposed algorithm on the synthetic dataset and the real-world dataset. The results show that our approach can outperform competing baselines in terms of convergence rate and overall CTR.
Identifying On-time Reward Delivery Projects with Estimating Delivery Duration on Kickstarter
Oct 12, 2017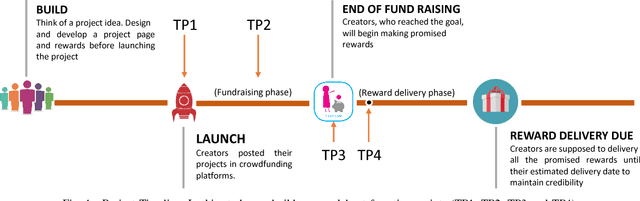

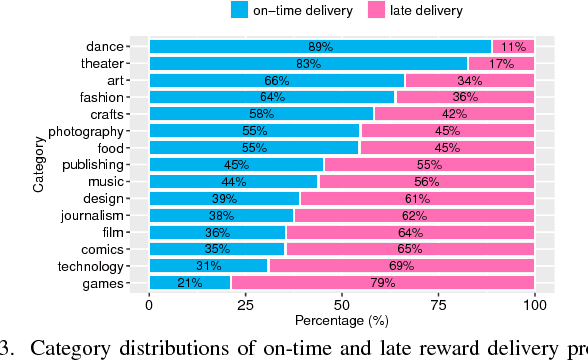
In Crowdfunding platforms, people turn their prototype ideas into real products by raising money from the crowd, or invest in someone else's projects. In reward-based crowdfunding platforms such as Kickstarter and Indiegogo, selecting accurate reward delivery duration becomes crucial for creators, backers, and platform providers to keep the trust between the creators and the backers, and the trust between the platform providers and users. According to Kickstarter, 35% backers did not receive rewards on time. Unfortunately, little is known about on-time and late reward delivery projects, and there is no prior work to estimate reward delivery duration. To fill the gap, in this paper, we (i) extract novel features that reveal latent difficulty levels of project rewards; (ii) build predictive models to identify whether a creator will deliver all rewards in a project on time or not; and (iii) build a regression model to estimate accurate reward delivery duration (i.e., how long it will take to produce and deliver all the rewards). Experimental results show that our models achieve good performance -- 82.5% accuracy, 78.1 RMSE, and 0.108 NRMSE at the first 5% of the longest reward delivery duration.
Neuroevolutionary learning of particles and protocols for self-assembly
Dec 22, 2020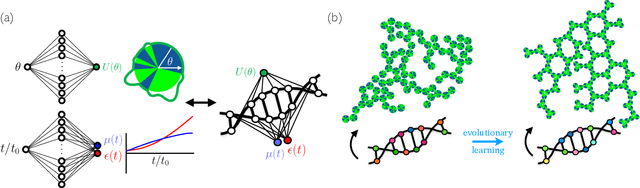
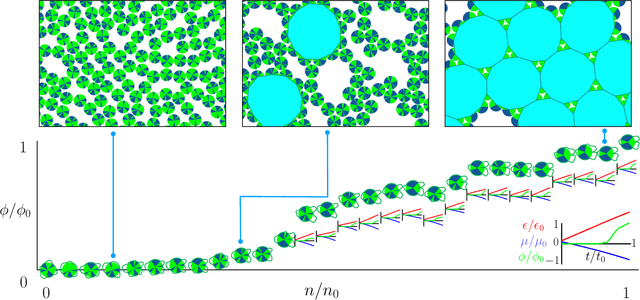
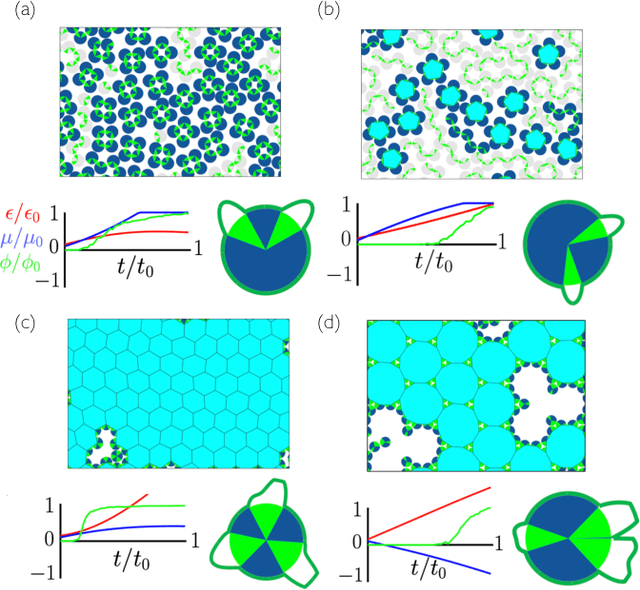
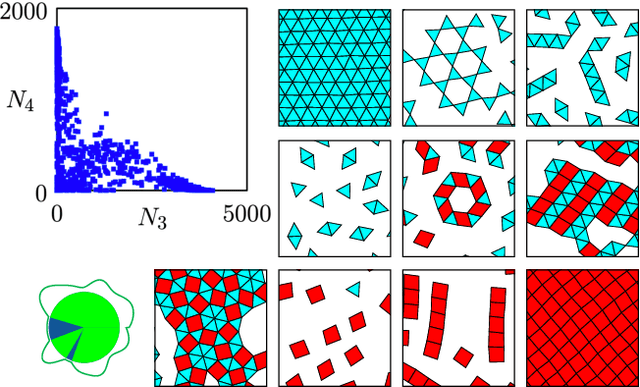
Within simulations of molecules deposited on a surface we show that neuroevolutionary learning can design particles and time-dependent protocols to promote self-assembly, without input from physical concepts such as thermal equilibrium or mechanical stability and without prior knowledge of candidate or competing structures. The learning algorithm is capable of both directed and exploratory design: it can assemble a material with a user-defined property, or search for novelty in the space of specified order parameters. In the latter mode it explores the space of what can be made rather than the space of structures that are low in energy but not necessarily kinetically accessible.
An advantage actor-critic algorithm for robotic motion planning in dense and dynamic scenarios
Feb 05, 2021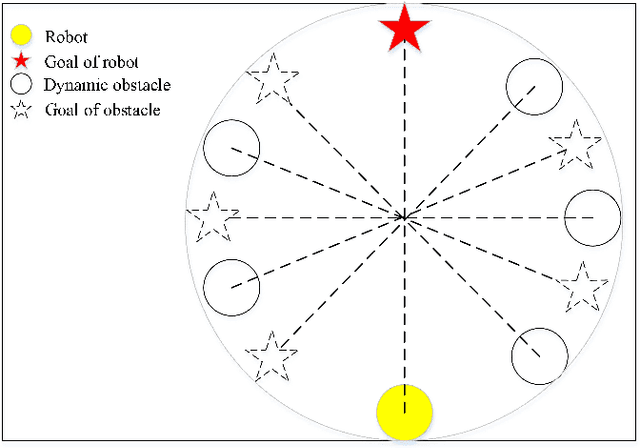

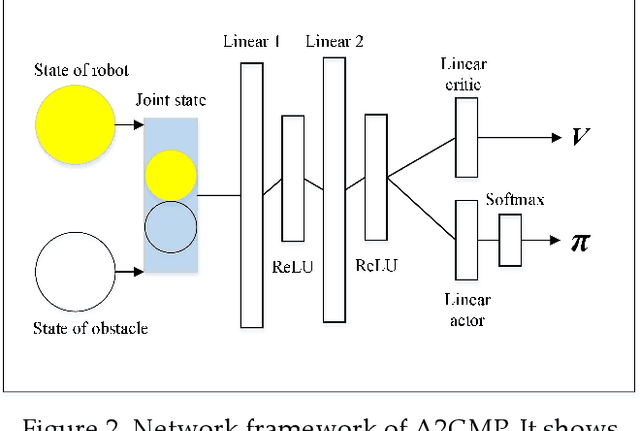
Intelligent robots provide a new insight into efficiency improvement in industrial and service scenarios to replace human labor. However, these scenarios include dense and dynamic obstacles that make motion planning of robots challenging. Traditional algorithms like A* can plan collision-free trajectories in static environment, but their performance degrades and computational cost increases steeply in dense and dynamic scenarios. Optimal-value reinforcement learning algorithms (RL) can address these problems but suffer slow speed and instability in network convergence. Network of policy gradient RL converge fast in Atari games where action is discrete and finite, but few works have been done to address problems where continuous actions and large action space are required. In this paper, we modify existing advantage actor-critic algorithm and suit it to complex motion planning, therefore optimal speeds and directions of robot are generated. Experimental results demonstrate that our algorithm converges faster and stable than optimal-value RL. It achieves higher success rate in motion planning with lesser processing time for robot to reach its goal.
End-to-End Learning of Speech 2D Feature-Trajectory for Prosthetic Hands
Sep 22, 2020



Speech is one of the most common forms of communication in humans. Speech commands are essential parts of multimodal controlling of prosthetic hands. In the past decades, researchers used automatic speech recognition systems for controlling prosthetic hands by using speech commands. Automatic speech recognition systems learn how to map human speech to text. Then, they used natural language processing or a look-up table to map the estimated text to a trajectory. However, the performance of conventional speech-controlled prosthetic hands is still unsatisfactory. Recent advancements in general-purpose graphics processing units (GPGPUs) enable intelligent devices to run deep neural networks in real-time. Thus, architectures of intelligent systems have rapidly transformed from the paradigm of composite subsystems optimization to the paradigm of end-to-end optimization. In this paper, we propose an end-to-end convolutional neural network (CNN) that maps speech 2D features directly to trajectories for prosthetic hands. The proposed convolutional neural network is lightweight, and thus it runs in real-time in an embedded GPGPU. The proposed method can use any type of speech 2D feature that has local correlations in each dimension such as spectrogram, MFCC, or PNCC. We omit the speech to text step in controlling the prosthetic hand in this paper. The network is written in Python with Keras library that has a TensorFlow backend. We optimized the CNN for NVIDIA Jetson TX2 developer kit. Our experiment on this CNN demonstrates a root-mean-square error of 0.119 and 20ms running time to produce trajectory outputs corresponding to the voice input data. To achieve a lower error in real-time, we can optimize a similar CNN for a more powerful embedded GPGPU such as NVIDIA AGX Xavier.
Reinforcement Learning Enabled Automatic Impedance Control of a Robotic Knee Prosthesis to Mimic the Intact Knee Motion in a Co-Adapting Environment
Jan 10, 2021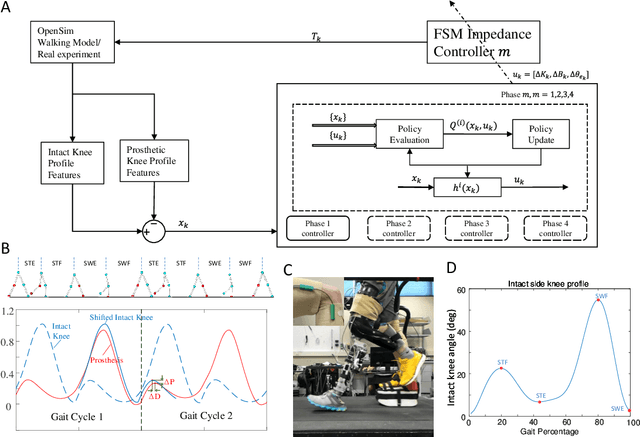
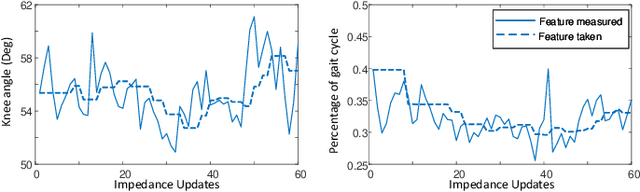
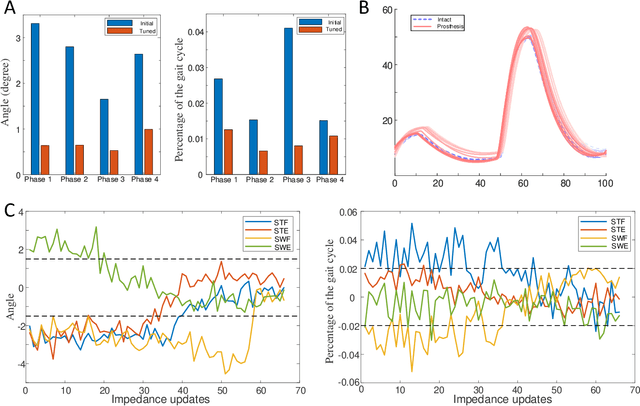
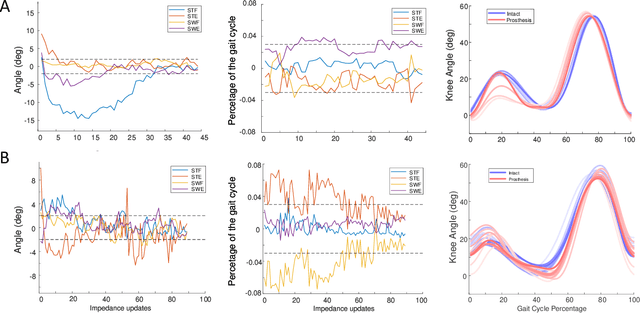
Automatically configuring a robotic prosthesis to fit its user's needs and physical conditions is a great technical challenge and a roadblock to the adoption of the technology. Previously, we have successfully developed reinforcement learning (RL) solutions toward addressing this issue. Yet, our designs were based on using a subjectively prescribed target motion profile for the robotic knee during level ground walking. This is not realistic for different users and for different locomotion tasks. In this study for the first time, we investigated the feasibility of RL enabled automatic configuration of impedance parameter settings for a robotic knee to mimic the intact knee motion in a co-adapting environment. We successfully achieved such tracking control by an online policy iteration. We demonstrated our results in both OpenSim simulations and two able-bodied (AB) subjects.
Generating Fact Checking Briefs
Nov 10, 2020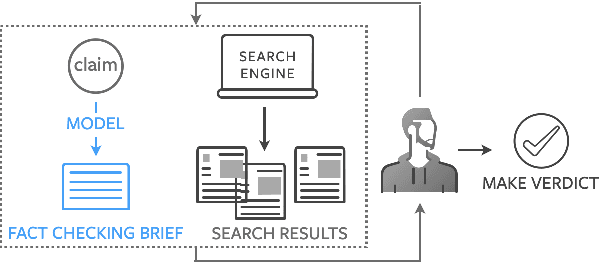
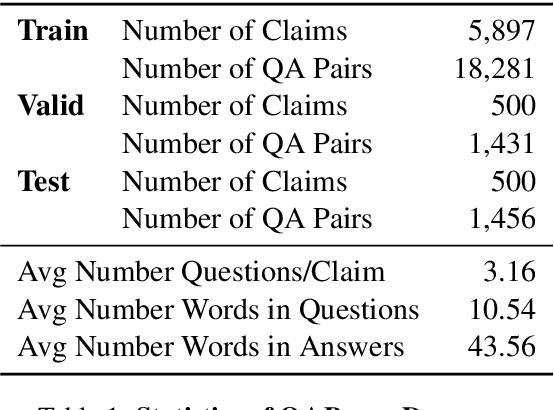

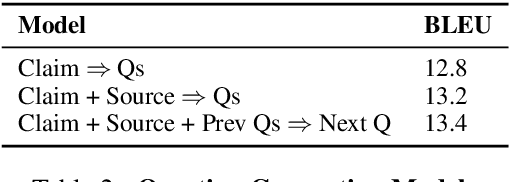
Fact checking at scale is difficult -- while the number of active fact checking websites is growing, it remains too small for the needs of the contemporary media ecosystem. However, despite good intentions, contributions from volunteers are often error-prone, and thus in practice restricted to claim detection. We investigate how to increase the accuracy and efficiency of fact checking by providing information about the claim before performing the check, in the form of natural language briefs. We investigate passage-based briefs, containing a relevant passage from Wikipedia, entity-centric ones consisting of Wikipedia pages of mentioned entities, and Question-Answering Briefs, with questions decomposing the claim, and their answers. To produce QABriefs, we develop QABriefer, a model that generates a set of questions conditioned on the claim, searches the web for evidence, and generates answers. To train its components, we introduce QABriefDataset which we collected via crowdsourcing. We show that fact checking with briefs -- in particular QABriefs -- increases the accuracy of crowdworkers by 10% while slightly decreasing the time taken. For volunteer (unpaid) fact checkers, QABriefs slightly increase accuracy and reduce the time required by around 20%.
Classification and Feature Transformation with Fuzzy Cognitive Maps
Mar 08, 2021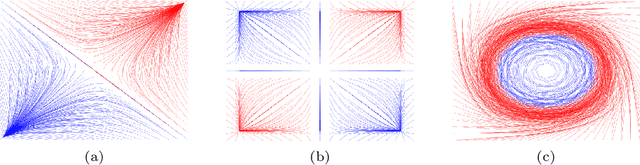
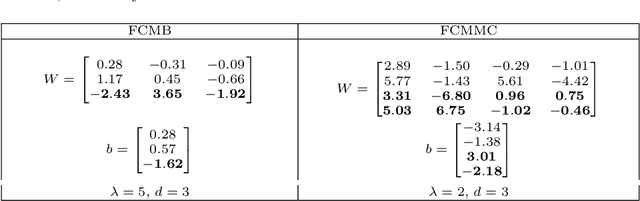
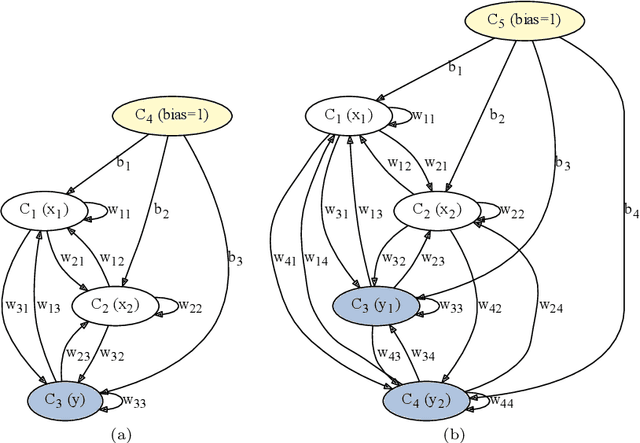
Fuzzy Cognitive Maps (FCMs) are considered a soft computing technique combining elements of fuzzy logic and recurrent neural networks. They found multiple application in such domains as modeling of system behavior, prediction of time series, decision making and process control. Less attention, however, has been turned towards using them in pattern classification. In this work we propose an FCM based classifier with a fully connected map structure. In contrast to methods that expect reaching a steady system state during reasoning, we chose to execute a few FCM iterations (steps) before collecting output labels. Weights were learned with a gradient algorithm and logloss or cross-entropy were used as the cost function. Our primary goal was to verify, whether such design would result in a descent general purpose classifier, with performance comparable to off the shelf classical methods. As the preliminary results were promising, we investigated the hypothesis that the performance of $d$-step classifier can be attributed to a fact that in previous $d-1$ steps it transforms the feature space by grouping observations belonging to a given class, so that they became more compact and separable. To verify this hypothesis we calculated three clustering scores for the transformed feature space. We also evaluated performance of pipelines built from FCM-based data transformer followed by a classification algorithm. The standard statistical analyzes confirmed both the performance of FCM based classifier and its capability to improve data. The supporting prototype software was implemented in Python using TensorFlow library.
There is More than Meets the Eye: Self-Supervised Multi-Object Detection and Tracking with Sound by Distilling Multimodal Knowledge
Mar 01, 2021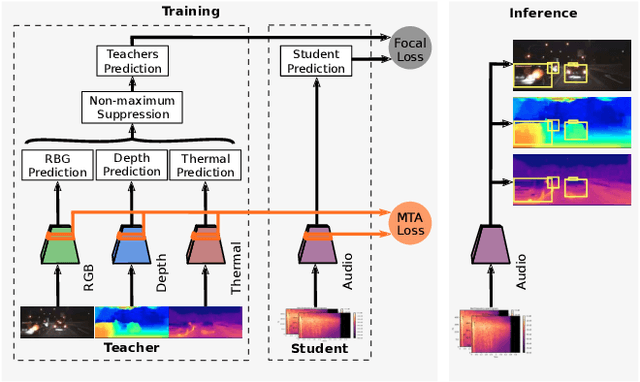
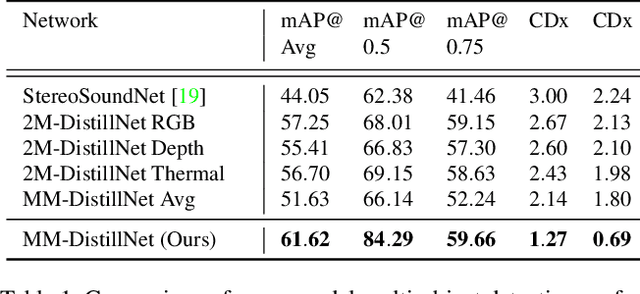
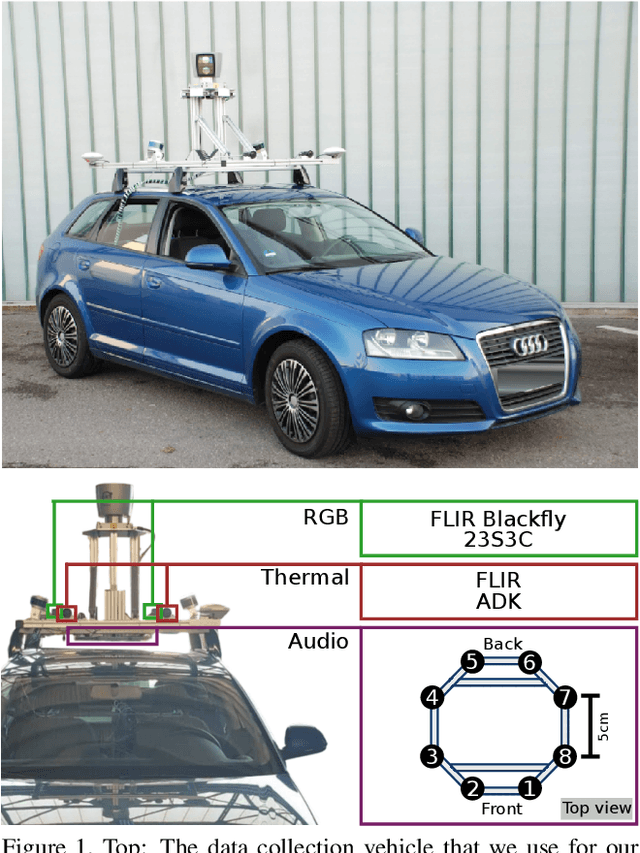
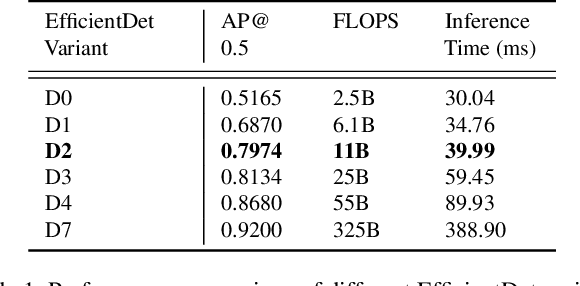
Attributes of sound inherent to objects can provide valuable cues to learn rich representations for object detection and tracking. Furthermore, the co-occurrence of audiovisual events in videos can be exploited to localize objects over the image field by solely monitoring the sound in the environment. Thus far, this has only been feasible in scenarios where the camera is static and for single object detection. Moreover, the robustness of these methods has been limited as they primarily rely on RGB images which are highly susceptible to illumination and weather changes. In this work, we present the novel self-supervised MM-DistillNet framework consisting of multiple teachers that leverage diverse modalities including RGB, depth and thermal images, to simultaneously exploit complementary cues and distill knowledge into a single audio student network. We propose the new MTA loss function that facilitates the distillation of information from multimodal teachers in a self-supervised manner. Additionally, we propose a novel self-supervised pretext task for the audio student that enables us to not rely on labor-intensive manual annotations. We introduce a large-scale multimodal dataset with over 113,000 time-synchronized frames of RGB, depth, thermal, and audio modalities. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods while being able to detect multiple objects using only sound during inference and even while moving.