 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reinforcement Learning of Structured Control for Linear Systems with Unknown State Matrix
Nov 02, 2020
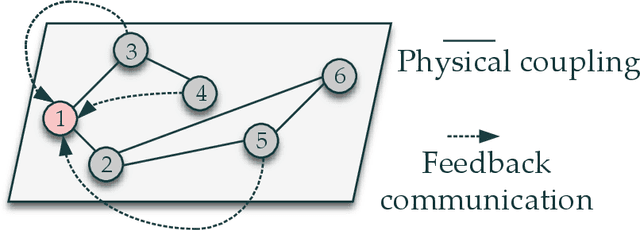
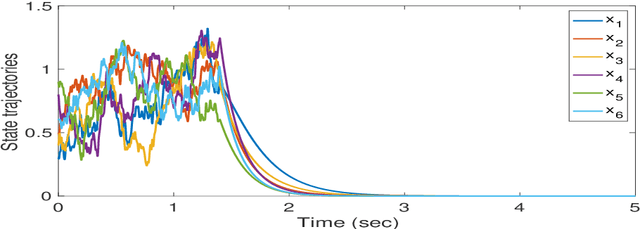
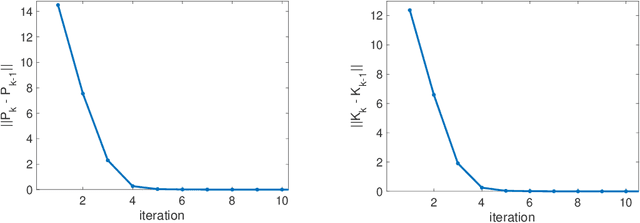
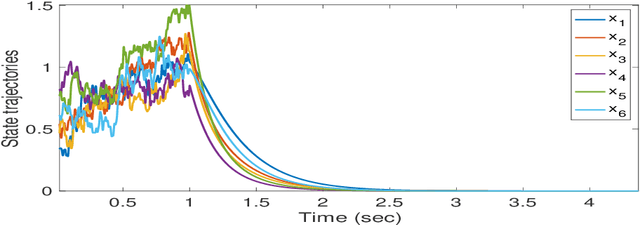
This paper delves into designing stabilizing feedback control gains for continuous linear systems with unknown state matrix, in which the control is subject to a general structural constraint. We bring forth the ideas from reinforcement learning (RL) in conjunction with sufficient stability and performance guarantees in order to design these structured gains using the trajectory measurements of states and controls. We first formulate a model-based framework using dynamic programming (DP) to embed the structural constraint to the Linear Quadratic Regulator (LQR) gain computation in the continuous-time setting. Subsequently, we transform this LQR formulation into a policy iteration RL algorithm that can alleviate the requirement of known state matrix in conjunction with maintaining the feedback gain structure. Theoretical guarantees are provided for stability and convergence of the structured RL (SRL) algorithm. The introduced RL framework is general and can be applied to any control structure. A special control structure enabled by this RL framework is distributed learning control which is necessary for many large-scale cyber-physical systems. As such, we validate our theoretical results with numerical simulations on a multi-agent networked linear time-invariant (LTI) dynamic system.
Estimation of the Frequency of Occurrence of Italian Phonemes in Text
Jan 18, 2021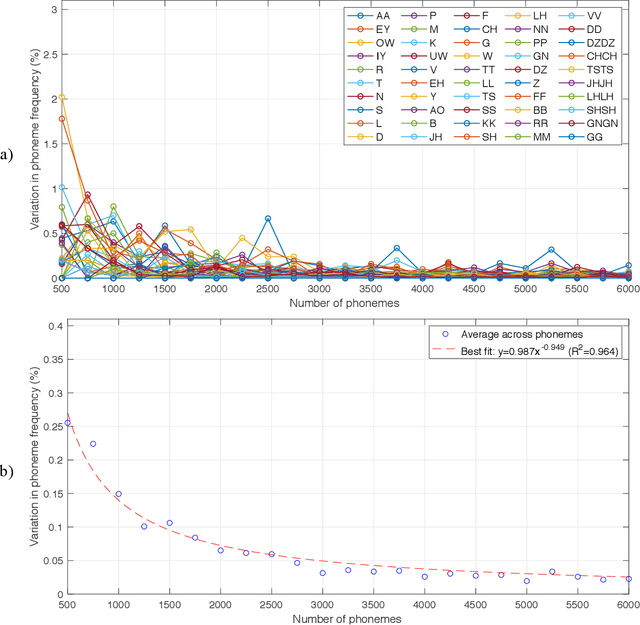
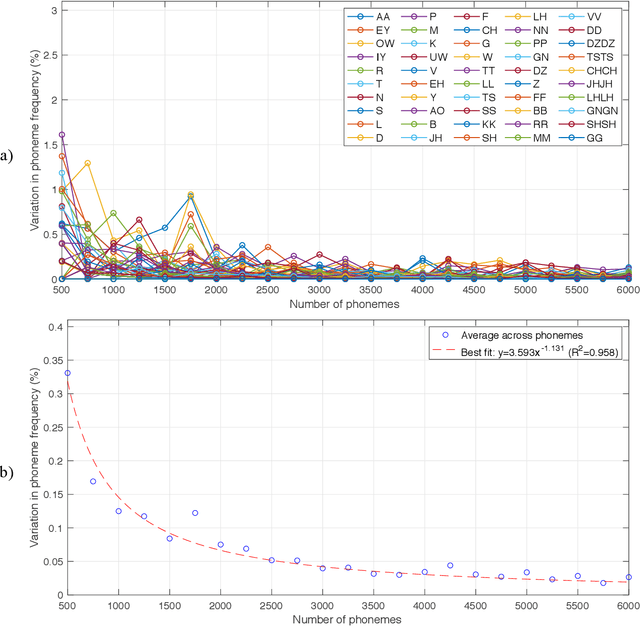
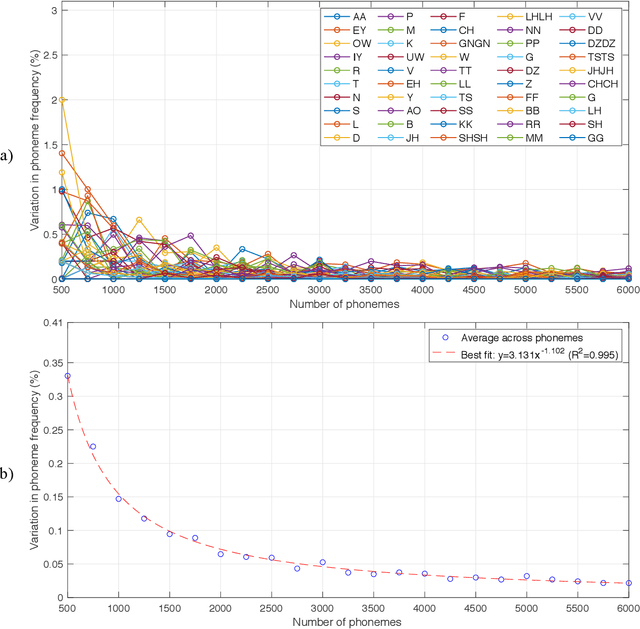
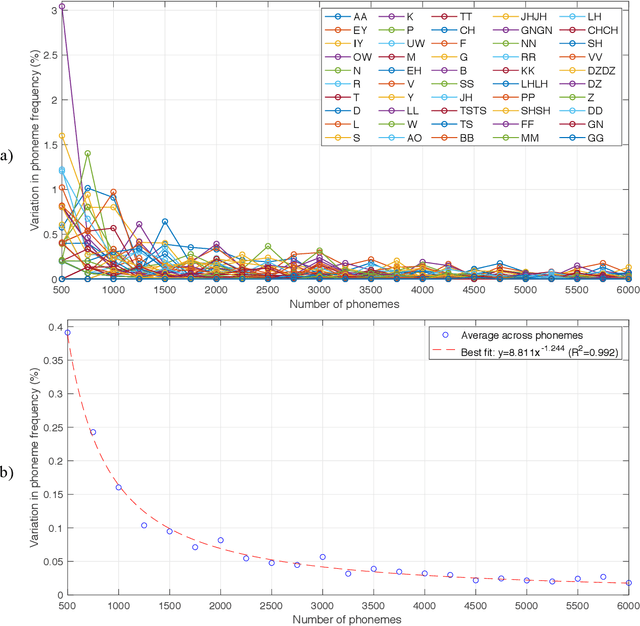
The purpose of this project was to derive a reliable estimate of the frequency of occurrence of the 30 phonemes - plus consonant geminated counterparts - of the Italian language, based on four selected written texts. Since no comparable dataset was found in previous literature, the present analysis may serve as a reference in future studies. Four textual sources were considered: Come si fa una tesi di laurea: le materie umanistiche by Umberto Eco, I promessi sposi by Alessandro Manzoni, a recent article in Corriere della Sera (a popular daily Italian newspaper), and In altre parole by Jhumpa Lahiri. The sources were chosen to represent varied genres, subject matter, time periods, and writing styles. Results of the analysis, which also included an analysis of variance, showed that, for all four sources, the frequencies of occurrence reached relatively stable values after about 6,000 phonemes (approx. 1,250 words), varying by <0.025%. Estimated frequencies are provided for each single source and as an average across sources.
Comparing the costs of abstraction for DL frameworks
Dec 13, 2020
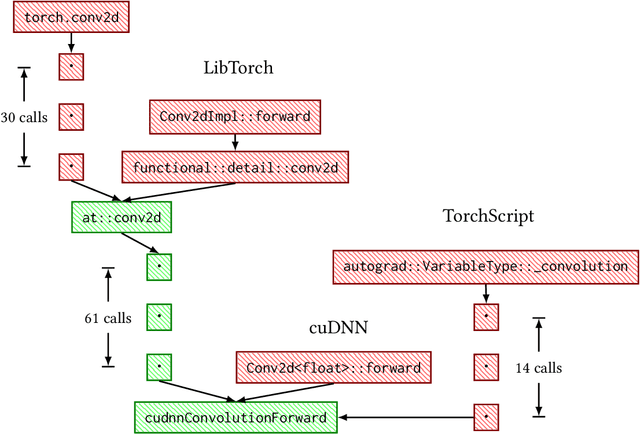
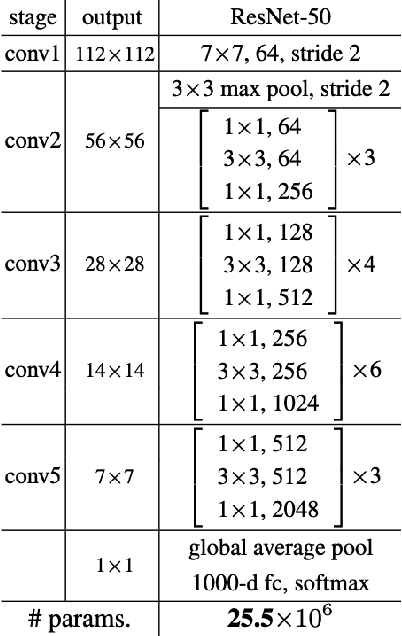
High level abstractions for implementing, training, and testing Deep Learning (DL) models abound. Such frameworks function primarily by abstracting away the implementation details of arbitrary neural architectures, thereby enabling researchers and engineers to focus on design. In principle, such frameworks could be "zero-cost abstractions"; in practice, they incur translation and indirection overheads. We study at which points exactly in the engineering life-cycle of a DL model the highest costs are paid and whether they can be mitigated. We train, test, and evaluate a representative DL model using PyTorch, LibTorch, TorchScript, and cuDNN on representative datasets, comparing accuracy, execution time and memory efficiency.
Toward Mutual Trust Modeling in Human-Robot Collaboration
Nov 02, 2020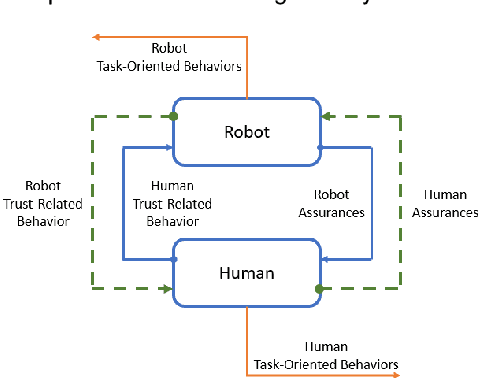
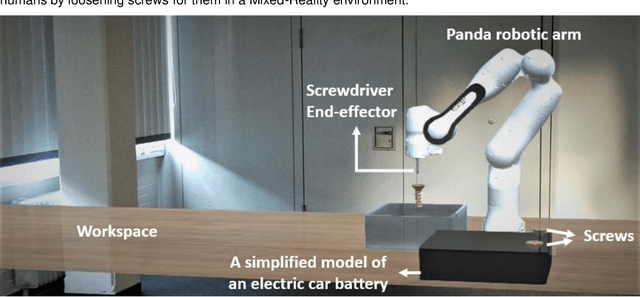
The recent revolution of intelligent systems made it possible for robots and autonomous systems to work alongside humans, collaborating with them and supporting them in many domains. It is undeniable that this interaction can have huge benefits for humans if it is designed properly. However, collaboration with humans requires a high level of cognition and social capabilities in order to gain humans acceptance. In all-human teams, mutual trust is the engine for successful collaboration. This applies to human-robot collaboration as well. Trust in this interaction controls over- and under-reliance. It can also mitigate some risk. Therefore, an appropriate trust level is essential for this new form of teamwork. Most research in this area has looked at trust of humans in machines, neglecting the mutuality of trust among collaboration partners. In this paper, we propose a trust model that incorporates this mutuality captures trust levels of both the human and the robot in real-time, so that robot can base actions on this, allowing for smoother, more natural interactions. This increases the human autonomy since the human does not need to monitor the robot behavior all the time.
Modifying the Symbolic Aggregate Approximation Method to Capture Segment Trend Information
Oct 02, 2020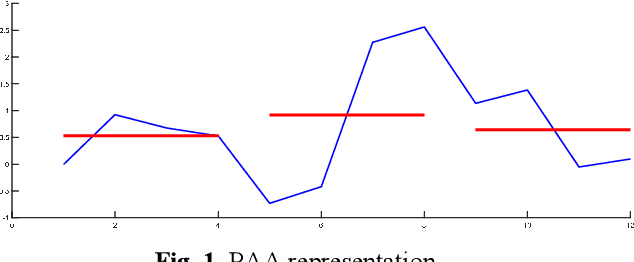
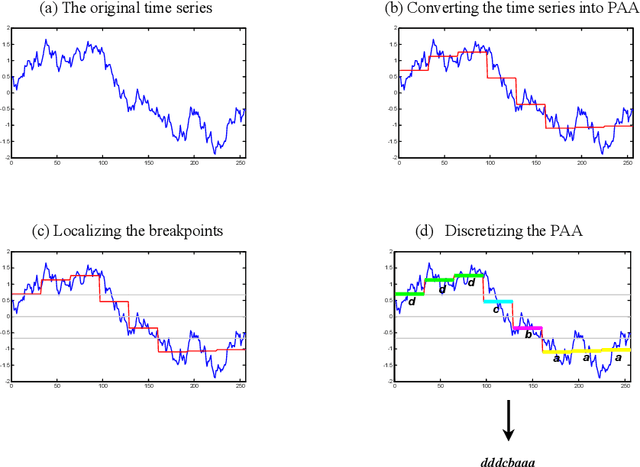
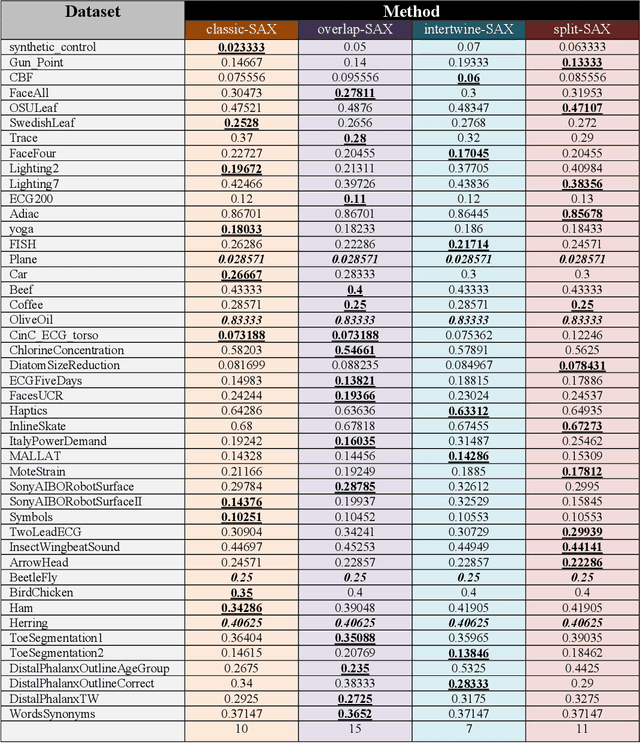
The Symbolic Aggregate approXimation (SAX) is a very popular symbolic dimensionality reduction technique of time series data, as it has several advantages over other dimensionality reduction techniques. One of its major advantages is its efficiency, as it uses precomputed distances. The other main advantage is that in SAX the distance measure defined on the reduced space lower bounds the distance measure defined on the original space. This enables SAX to return exact results in query-by-content tasks. Yet SAX has an inherent drawback, which is its inability to capture segment trend information. Several researchers have attempted to enhance SAX by proposing modifications to include trend information. However, this comes at the expense of giving up on one or more of the advantages of SAX. In this paper we investigate three modifications of SAX to add trend capturing ability to it. These modifications retain the same features of SAX in terms of simplicity, efficiency, as well as the exact results it returns. They are simple procedures based on a different segmentation of the time series than that used in classic-SAX. We test the performance of these three modifications on 45 time series datasets of different sizes, dimensions, and nature, on a classification task and we compare it to that of classic-SAX. The results we obtained show that one of these modifications manages to outperform classic-SAX and that another one slightly gives better results than classic-SAX.
* International Conference on Modeling Decisions for Artificial Intelligence - MDAI 2020: Modeling Decisions for Artificial Intelligence pp 230-239
Scalable Robust Graph and Feature Extraction for Arbitrary Vessel Networks in Large Volumetric Datasets
Feb 05, 2021
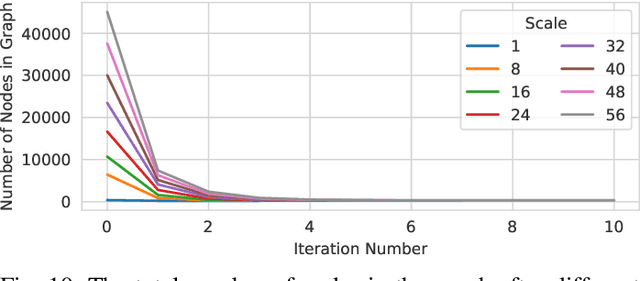
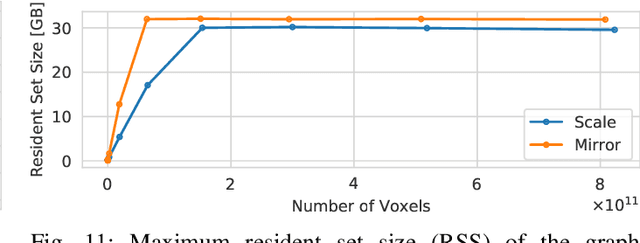
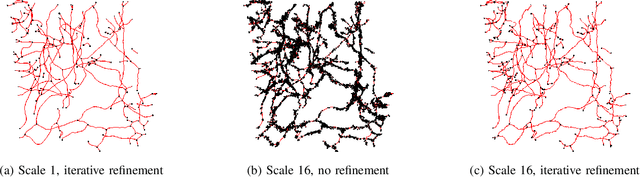
Recent advances in 3D imaging technologies provide novel insights to researchers and reveal finer and more detail of examined specimen, especially in the biomedical domain, but also impose huge challenges regarding scalability for automated analysis algorithms due to rapidly increasing dataset sizes. In particular, existing research towards automated vessel network analysis does not consider memory requirements of proposed algorithms and often generates a large number of spurious branches for structures consisting of many voxels. Additionally, very often these algorithms have further restrictions such as the limitation to tree topologies or relying on the properties of specific image modalities. We present a scalable pipeline (in terms of computational cost, required main memory and robustness) that extracts an annotated abstract graph representation from the foreground segmentation of vessel networks of arbitrary topology and vessel shape. Only a single, dimensionless, a-priori determinable parameter is required. By careful engineering of individual pipeline stages and a novel iterative refinement scheme we are, for the first time, able to analyze the topology of volumes of roughly 1TB on commodity hardware. An implementation of the presented pipeline is publicly available in version 5.1 of the volume rendering and processing engine Voreen (https://www.uni-muenster.de/Voreen/).
Improved algorithms for online load balancing
Jul 15, 2020We consider an online load balancing problem and its extensions in the framework of repeated games. On each round, the player chooses a distribution (task allocation) over $K$ servers, and then the environment reveals the load of each server, which determines the computation time of each server for processing the task assigned. After all rounds, the cost of the player is measured by some norm of the cumulative computation-time vector. The cost is the makespan if the norm is $L_\infty$-norm. The goal is to minimize the regret, i.e., minimizing the player's cost relative to the cost of the best fixed distribution in hindsight. We propose algorithms for general norms and prove their regret bounds. In particular, for $L_\infty$-norm, our regret bound matches the best known bound and the proposed algorithm runs in polynomial time per trial involving linear programming and second order programming, whereas no polynomial time algorithm was previously known to achieve the bound.
Push recovery with stepping strategy based on time-projection control
Jan 07, 2018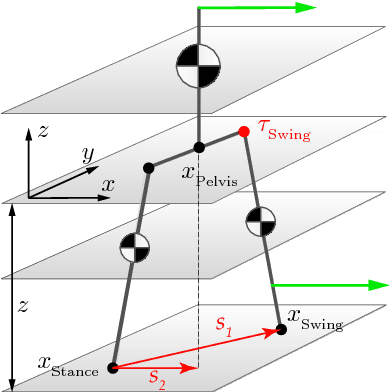
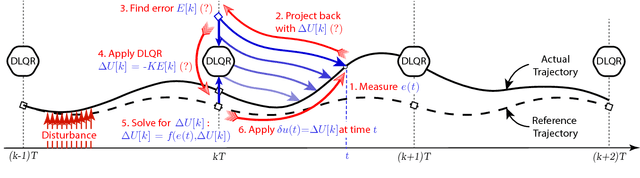
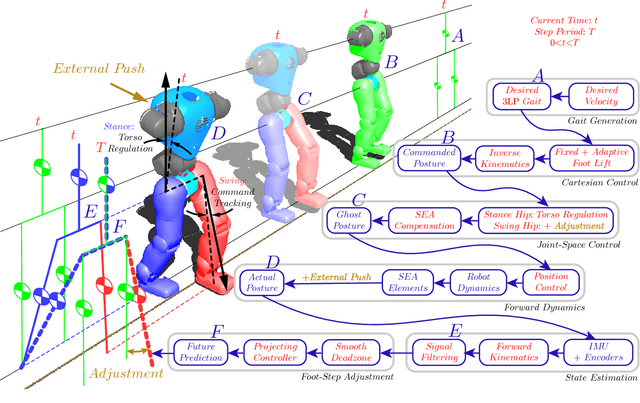
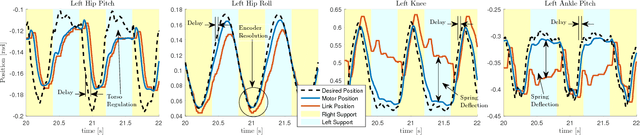
In this paper, we present a simple control framework for on-line push recovery with dynamic stepping properties. Due to relatively heavy legs in our robot, we need to take swing dynamics into account and thus use a linear model called 3LP which is composed of three pendulums to simulate swing and torso dynamics. Based on 3LP equations, we formulate discrete LQR controllers and use a particular time-projection method to adjust the next footstep location on-line during the motion continuously. This adjustment, which is found based on both pelvis and swing foot tracking errors, naturally takes the swing dynamics into account. Suggested adjustments are added to the Cartesian 3LP gaits and converted to joint-space trajectories through inverse kinematics. Fixed and adaptive foot lift strategies also ensure enough ground clearance in perturbed walking conditions. The proposed structure is robust, yet uses very simple state estimation and basic position tracking. We rely on the physical series elastic actuators to absorb impacts while introducing simple laws to compensate their tracking bias. Extensive experiments demonstrate the functionality of different control blocks and prove the effectiveness of time-projection in extreme push recovery scenarios. We also show self-produced and emergent walking gaits when the robot is subject to continuous dragging forces. These gaits feature dynamic walking robustness due to relatively soft springs in the ankles and avoiding any Zero Moment Point (ZMP) control in our proposed architecture.
Crowding Prediction of In-Situ Metro Passengers Using Smart Card Data
Sep 07, 2020
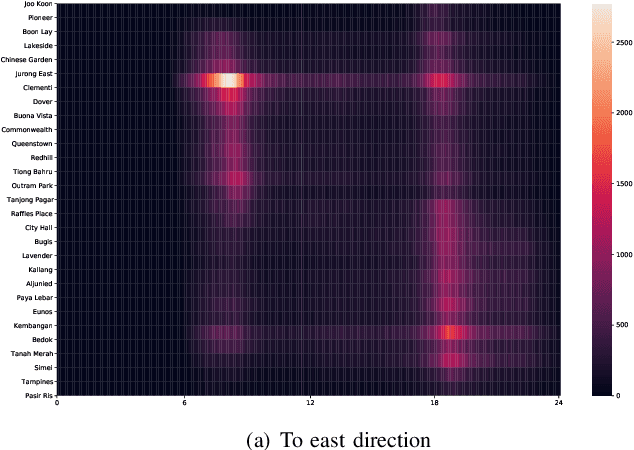
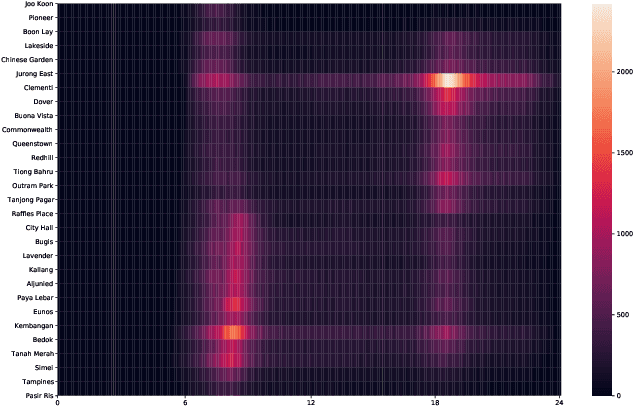
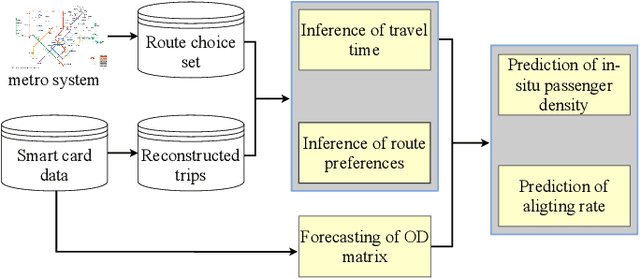
The metro system is playing an increasingly important role in the urban public transit network, transferring a massive human flow across space everyday in the city. In recent years, extensive research studies have been conducted to improve the service quality of metro systems. Among them, crowd management has been a critical issue for both public transport agencies and train operators. In this paper, by utilizing accumulated smart card data, we propose a statistical model to predict in-situ passenger density, i.e., number of on-board passengers between any two neighbouring stations, inside a closed metro system. The proposed model performs two main tasks: i) forecasting time-dependent Origin-Destination (OD) matrix by applying mature statistical models; and ii) estimating the travel time cost required by different parts of the metro network via truncated normal mixture distributions with Expectation-Maximization (EM) algorithm. Based on the prediction results, we are able to provide accurate prediction of in-situ passenger density for a future time point. A case study using real smart card data in Singapore Mass Rapid Transit (MRT) system demonstrate the efficacy and efficiency of our proposed method.
Unfolding recurrence by Green's functions for optimized reservoir computing
Oct 13, 2020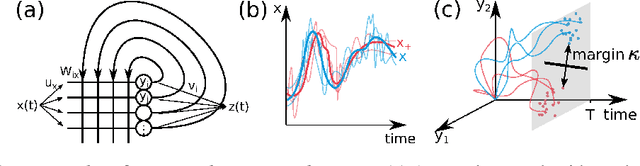


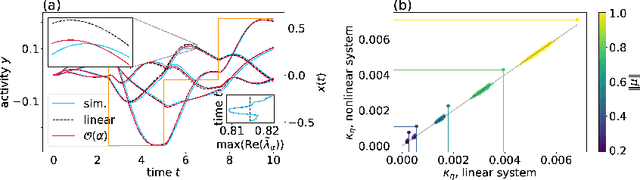
Cortical networks are strongly recurrent, and neurons have intrinsic temporal dynamics. This sets them apart from deep feed-forward networks. Despite the tremendous progress in the application of feed-forward networks and their theoretical understanding, it remains unclear how the interplay of recurrence and non-linearities in recurrent cortical networks contributes to their function. The purpose of this work is to present a solvable recurrent network model that links to feed forward networks. By perturbative methods we transform the time-continuous, recurrent dynamics into an effective feed-forward structure of linear and non-linear temporal kernels. The resulting analytical expressions allow us to build optimal time-series classifiers from random reservoir networks. Firstly, this allows us to optimize not only the readout vectors, but also the input projection, demonstrating a strong potential performance gain. Secondly, the analysis exposes how the second order stimulus statistics is a crucial element that interacts with the non-linearity of the dynamics and boosts performance.