 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distributed Motion Coordination Using Convex Feasible Set Based Model Predictive Control
Jan 20, 2021
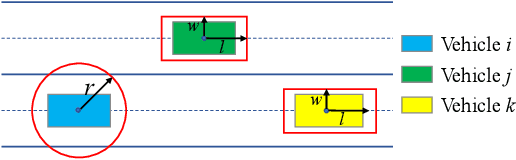
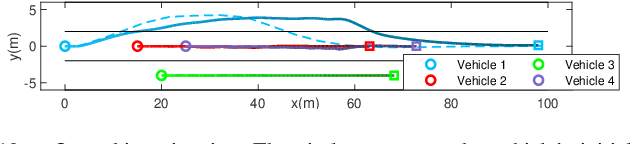
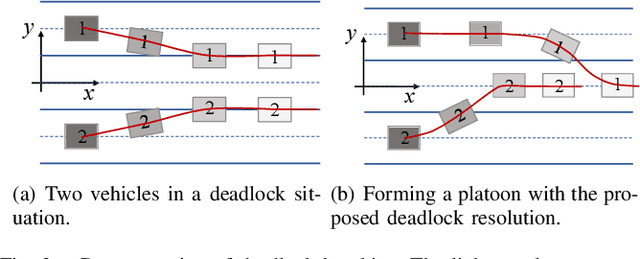
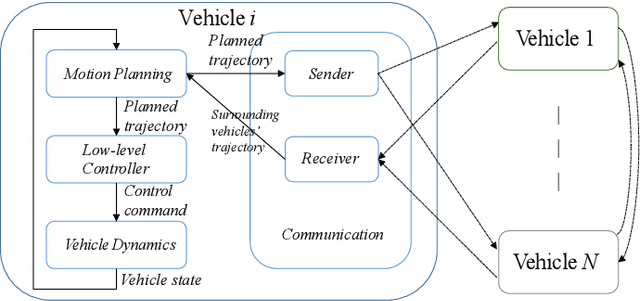
The implementation of optimization-based motion coordination approaches in real world multi-agent systems remains challenging due to their high computational complexity and potential deadlocks. This paper presents a distributed model predictive control (MPC) approach based on convex feasible set (CFS) algorithm for multi-vehicle motion coordination in autonomous driving. By using CFS to convexify the collision avoidance constraints, collision-free trajectories can be computed in real time. We analyze the potential deadlocks and show that a deadlock can be resolved by changing vehicles' desired speeds. The MPC structure ensures that our algorithm is robust to low-level tracking errors. The proposed distributed method has been tested in multiple challenging multi-vehicle environments, including unstructured road, intersection, crossing, platoon formation, merging, and overtaking scenarios. The numerical results and comparison with other approaches (including a centralized MPC and reciprocal velocity obstacles) show that the proposed method is computationally efficient and robust, and avoids deadlocks.
High-Performance Training by Exploiting Hot-Embeddings in Recommendation Systems
Mar 02, 2021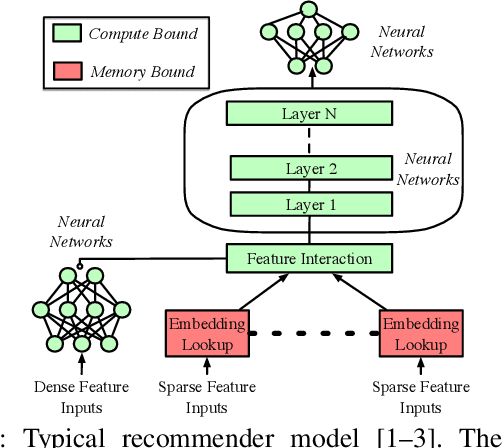
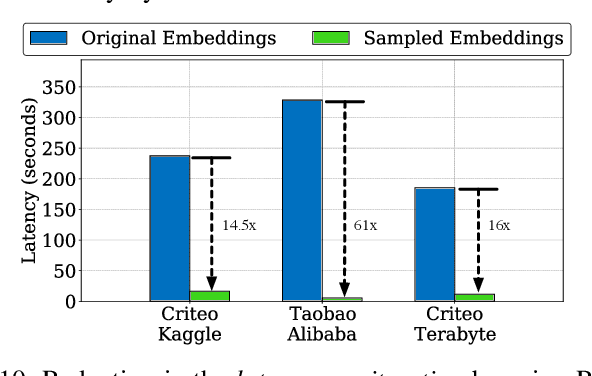
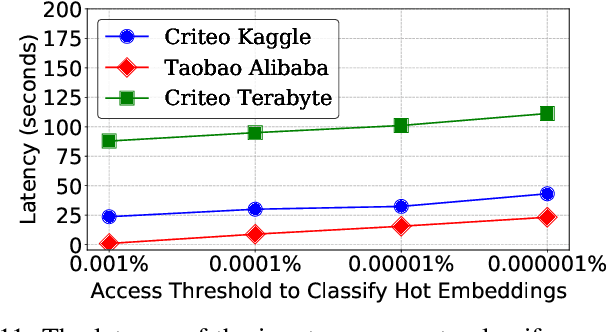
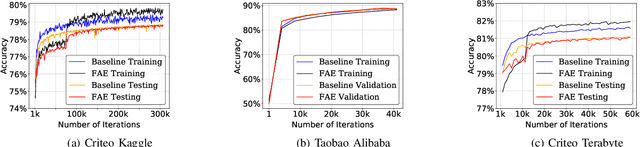
Recommendation models are commonly used learning models that suggest relevant items to a user for e-commerce and online advertisement-based applications. Current recommendation models include deep-learning-based (DLRM) and time-based sequence (TBSM) models. These models use massive embedding tables to store a numerical representation of item's and user's categorical variables (memory-bound) while also using neural networks to generate outputs (compute-bound). Due to these conflicting compute and memory requirements, the training process for recommendation models is divided across CPU and GPU for embedding and neural network executions, respectively. Such a training process naively assigns the same level of importance to each embedding entry. This paper observes that some training inputs and their accesses into the embedding tables are heavily skewed with certain entries being accessed up to 10000x more. This paper tries to leverage skewed embedded table accesses to efficiently use the GPU resources during training. To this end, this paper proposes a Frequently Accessed Embeddings (FAE) framework that exposes a dynamic knob to the software based on the GPU memory capacity and the input popularity index. This framework efficiently estimates and varies the size of the hot portions of the embedding tables within GPUs and reallocates the rest of the embeddings on the CPU. Overall, our framework speeds-up the training of the recommendation models on Kaggle, Terabyte, and Alibaba datasets by 2.34x as compared to a baseline that uses Intel-Xeon CPUs and Nvidia Tesla-V100 GPUs, while maintaining accuracy.
Comprehensive Comparative Study of Multi-Label Classification Methods
Feb 16, 2021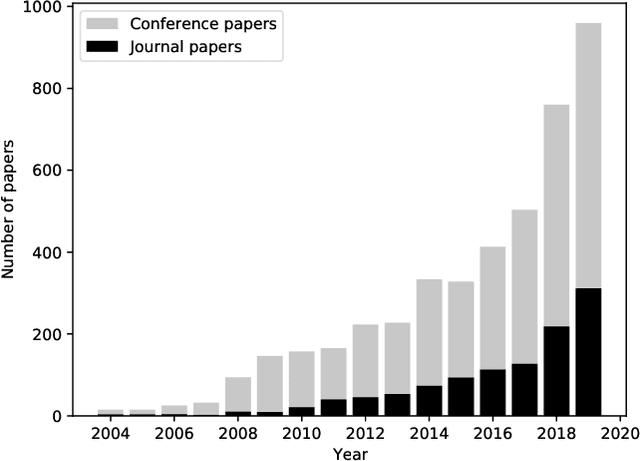

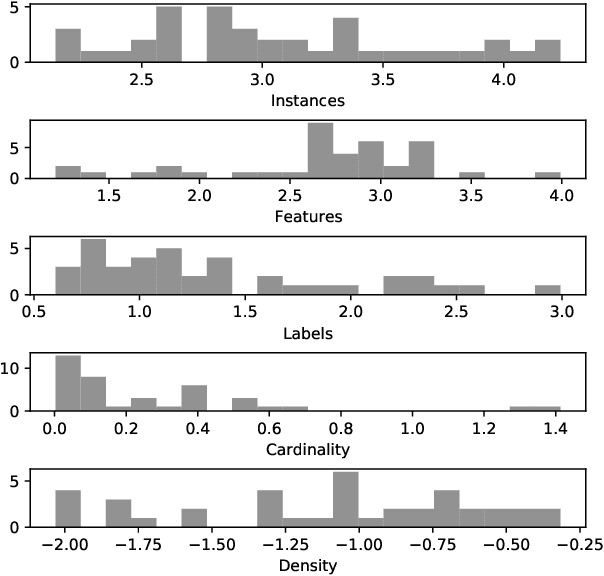
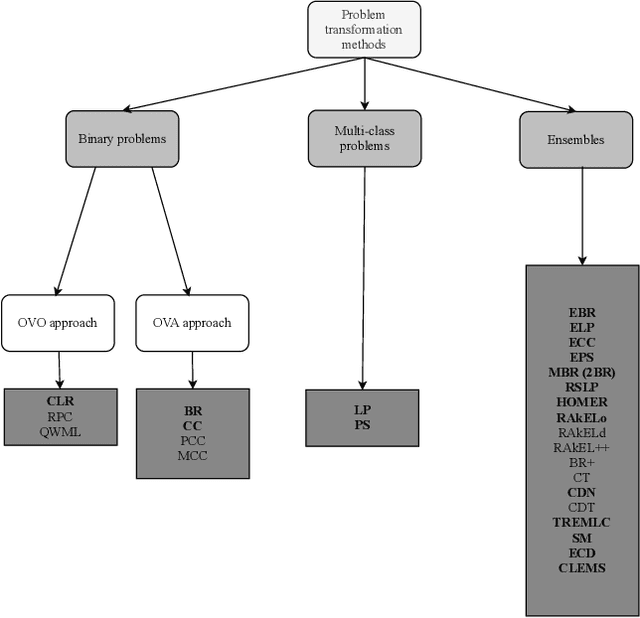
Multi-label classification (MLC) has recently received increasing interest from the machine learning community. Several studies provide reviews of methods and datasets for MLC and a few provide empirical comparisons of MLC methods. However, they are limited in the number of methods and datasets considered. This work provides a comprehensive empirical study of a wide range of MLC methods on a plethora of datasets from various domains. More specifically, our study evaluates 26 methods on 42 benchmark datasets using 20 evaluation measures. The adopted evaluation methodology adheres to the highest literature standards for designing and executing large scale, time-budgeted experimental studies. First, the methods are selected based on their usage by the community, assuring representation of methods across the MLC taxonomy of methods and different base learners. Second, the datasets cover a wide range of complexity and domains of application. The selected evaluation measures assess the predictive performance and the efficiency of the methods. The results of the analysis identify RFPCT, RFDTBR, ECCJ48, EBRJ48 and AdaBoostMH as best performing methods across the spectrum of performance measures. Whenever a new method is introduced, it should be compared to different subsets of MLC methods, determined on the basis of the different evaluation criteria.
It All Matters: Reporting Accuracy, Inference Time and Power Consumption for Face Emotion Recognition on Embedded Systems
Jun 29, 2018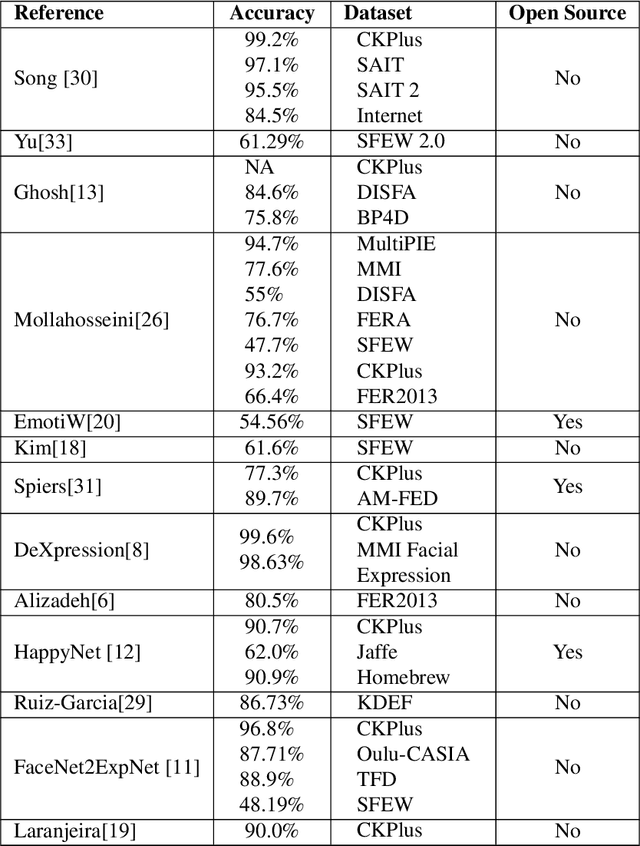

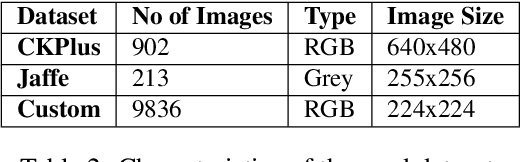
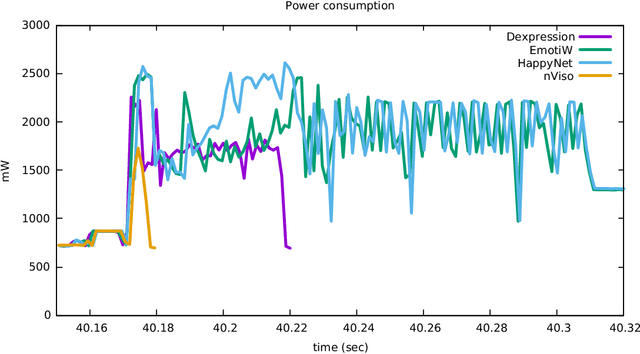
While several approaches to face emotion recognition task are proposed in literature, none of them reports on power consumption nor inference time required to run the system in an embedded environment. Without adequate knowledge about these factors it is not clear whether we are actually able to provide accurate face emotion recognition in the embedded environment or not, and if not, how far we are from making it feasible and what are the biggest bottlenecks we face. The main goal of this paper is to answer these questions and to convey the message that instead of reporting only detection accuracy also power consumption and inference time should be reported as real usability of the proposed systems and their adoption in human computer interaction strongly depends on it. In this paper, we identify the state-of-the art face emotion recognition methods that are potentially suitable for embedded environment and the most frequently used datasets for this task. Our study shows that most of the performed experiments use datasets with posed expressions or in a particular experimental setup with special conditions for image collection. Since our goal is to evaluate the performance of the identified promising methods in the realistic scenario, we collect a new dataset with non-exaggerated emotions and we use it, in addition to the publicly available datasets, for the evaluation of detection accuracy, power consumption and inference time on three frequently used embedded devices with different computational capabilities. Our results show that gray images are still more suitable for embedded environment than color ones and that for most of the analyzed systems either inference time or energy consumption or both are limiting factor for their adoption in real-life embedded applications.
Dynamic Neural Garments
Feb 23, 2021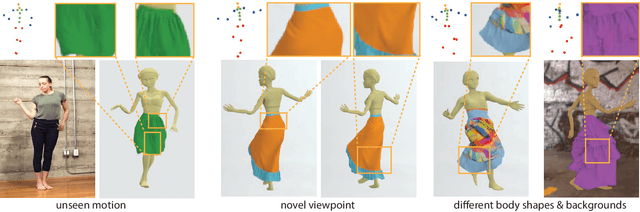
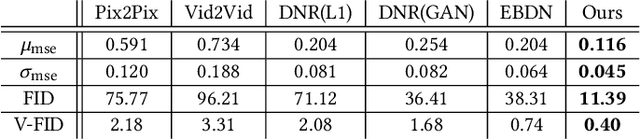
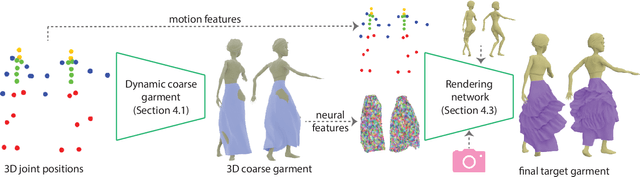

A vital task of the wider digital human effort is the creation of realistic garments on digital avatars, both in the form of characteristic fold patterns and wrinkles in static frames as well as richness of garment dynamics under avatars' motion. Existing workflow of modeling, simulation, and rendering closely replicates the physics behind real garments, but is tedious and requires repeating most of the workflow under changes to characters' motion, camera angle, or garment resizing. Although data-driven solutions exist, they either focus on static scenarios or only handle dynamics of tight garments. We present a solution that, at test time, takes in body joint motion to directly produce realistic dynamic garment image sequences. Specifically, given the target joint motion sequence of an avatar, we propose dynamic neural garments to jointly simulate and render plausible dynamic garment appearance from an unseen viewpoint. Technically, our solution generates a coarse garment proxy sequence, learns deep dynamic features attached to this template, and neurally renders the features to produce appearance changes such as folds, wrinkles, and silhouettes. We demonstrate generalization behavior to both unseen motion and unseen camera views. Further, our network can be fine-tuned to adopt to new body shape and/or background images. We also provide comparisons against existing neural rendering and image sequence translation approaches, and report clear quantitative improvements.
Joint Coding and Scheduling Optimization for Distributed Learning over Wireless Edge Networks
Mar 09, 2021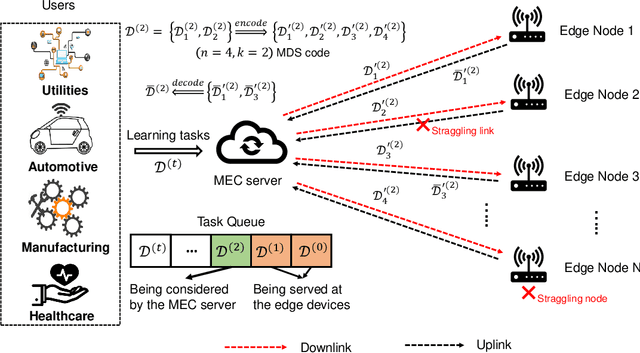
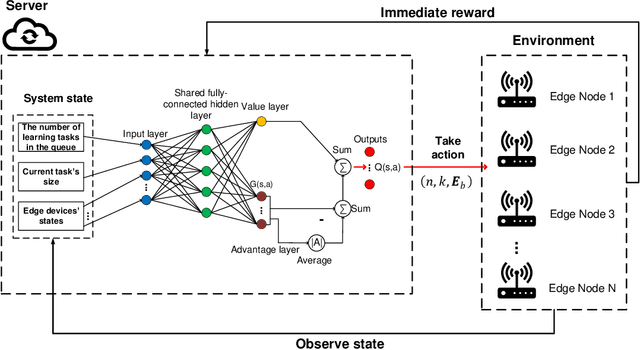
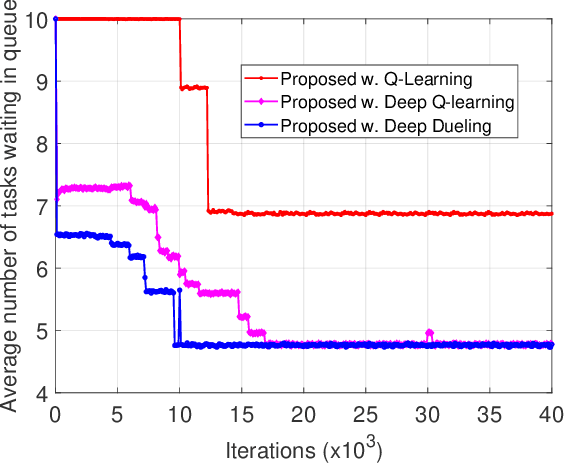
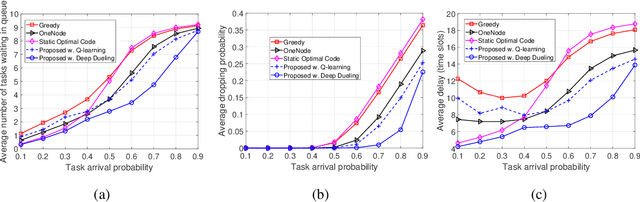
Unlike theoretical distributed learning (DL), DL over wireless edge networks faces the inherent dynamics/uncertainty of wireless connections and edge nodes, making DL less efficient or even inapplicable under the highly dynamic wireless edge networks (e.g., using mmW interfaces). This article addresses these problems by leveraging recent advances in coded computing and the deep dueling neural network architecture. By introducing coded structures/redundancy, a distributed learning task can be completed without waiting for straggling nodes. Unlike conventional coded computing that only optimizes the code structure, coded distributed learning over the wireless edge also requires to optimize the selection/scheduling of wireless edge nodes with heterogeneous connections, computing capability, and straggling effects. However, even neglecting the aforementioned dynamics/uncertainty, the resulting joint optimization of coding and scheduling to minimize the distributed learning time turns out to be NP-hard. To tackle this and to account for the dynamics and uncertainty of wireless connections and edge nodes, we reformulate the problem as a Markov Decision Process and then design a novel deep reinforcement learning algorithm that employs the deep dueling neural network architecture to find the jointly optimal coding scheme and the best set of edge nodes for different learning tasks without explicit information about the wireless environment and edge nodes' straggling parameters. Simulations show that the proposed framework reduces the average learning delay in wireless edge computing up to 66% compared with other DL approaches. The jointly optimal framework in this article is also applicable to any distributed learning scheme with heterogeneous and uncertain computing nodes.
Mobile Cellular-Connected UAVs: Reinforcement Learning for Sky Limits
Sep 21, 2020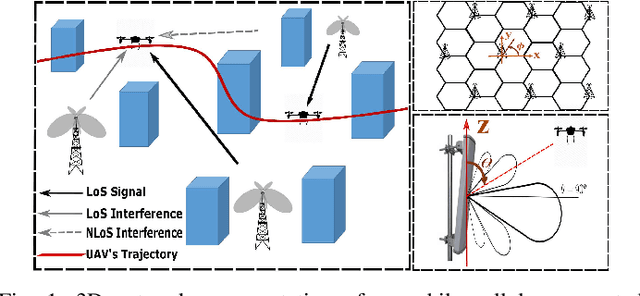
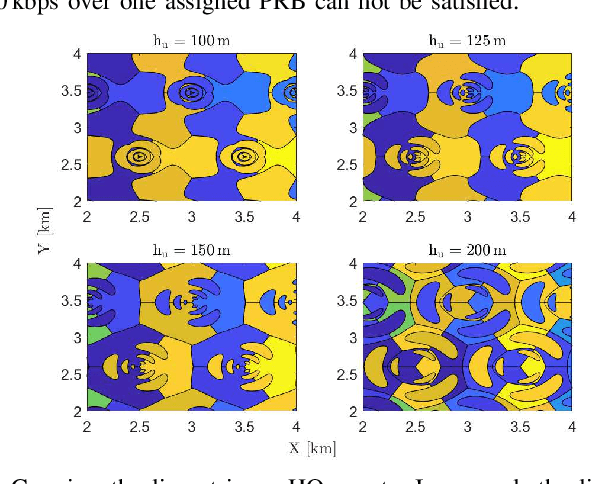
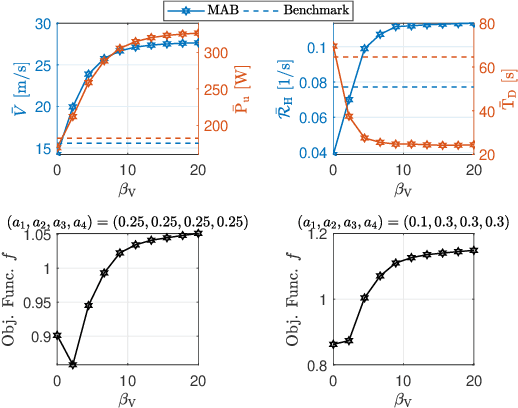
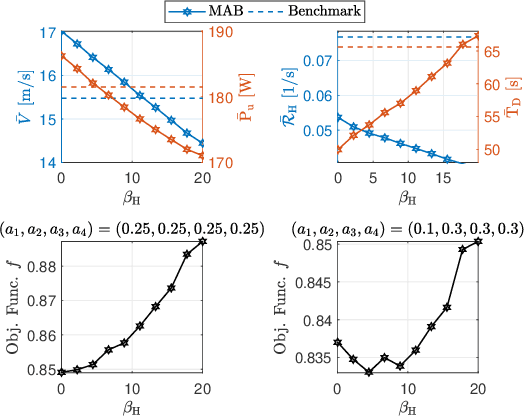
A cellular-connected unmanned aerial vehicle (UAV)faces several key challenges concerning connectivity and energy efficiency. Through a learning-based strategy, we propose a general novel multi-armed bandit (MAB) algorithm to reduce disconnectivity time, handover rate, and energy consumption of UAV by taking into account its time of task completion. By formulating the problem as a function of UAV's velocity, we show how each of these performance indicators (PIs) is improved by adopting a proper range of corresponding learning parameter, e.g. 50% reduction in HO rate as compared to a blind strategy. However, results reveal that the optimal combination of the learning parameters depends critically on any specific application and the weights of PIs on the final objective function.
Temporal Registration in In-Utero Volumetric MRI Time Series
Aug 12, 2016
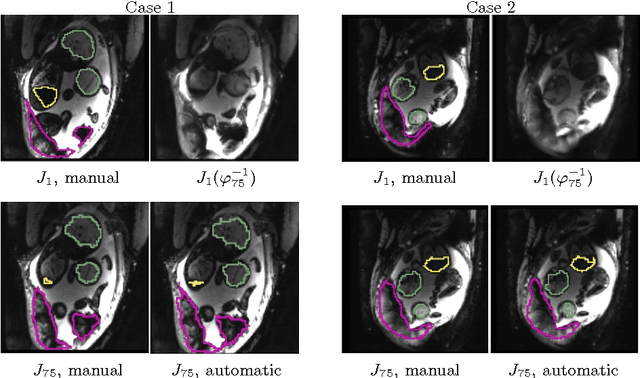
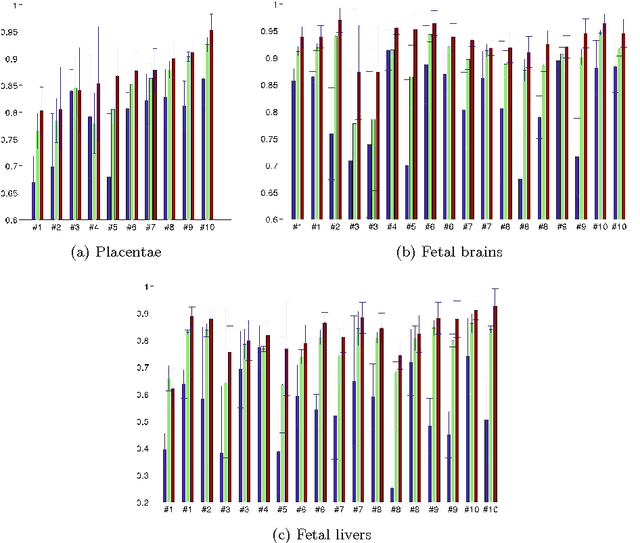
We present a robust method to correct for motion and deformations for in-utero volumetric MRI time series. Spatio-temporal analysis of dynamic MRI requires robust alignment across time in the presence of substantial and unpredictable motion. We make a Markov assumption on the nature of deformations to take advantage of the temporal structure in the image data. Forward message passing in the corresponding hidden Markov model (HMM) yields an estimation algorithm that only has to account for relatively small motion between consecutive frames. We demonstrate the utility of the temporal model by showing that its use improves the accuracy of the segmentation propagation through temporal registration. Our results suggest that the proposed model captures accurately the temporal dynamics of deformations in in-utero MRI time series.
A White-Noise-On-Jerk Motion Prior for Continuous-Time Trajectory Estimation on SE(3)
Jan 12, 2019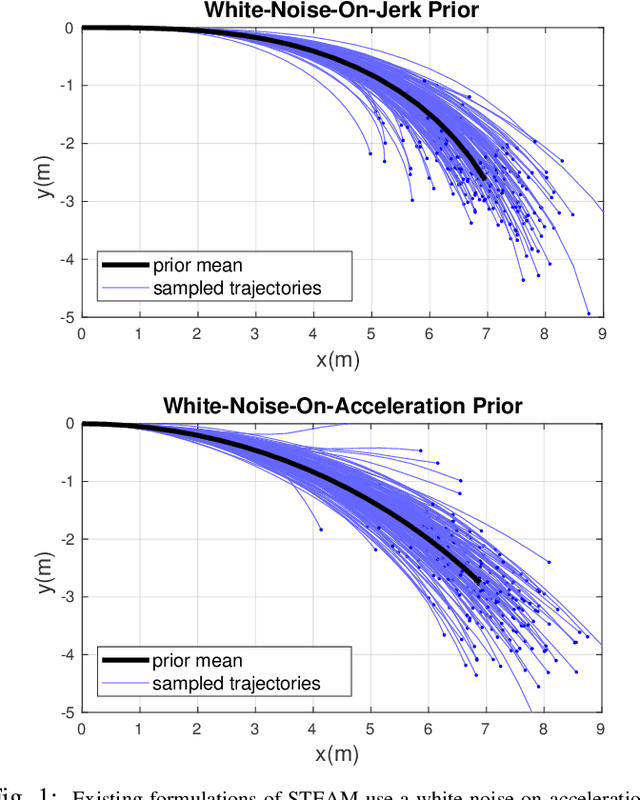

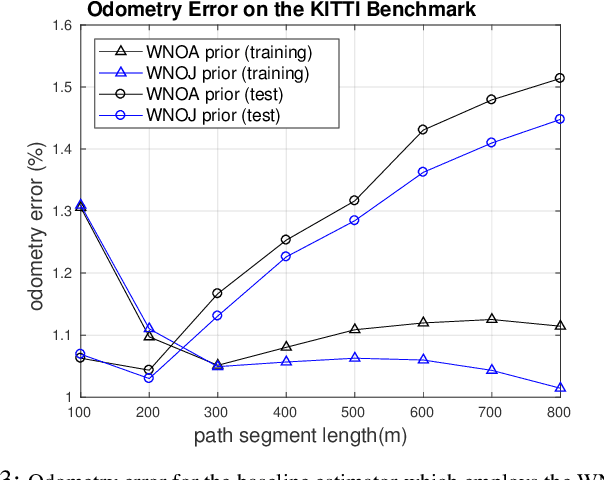
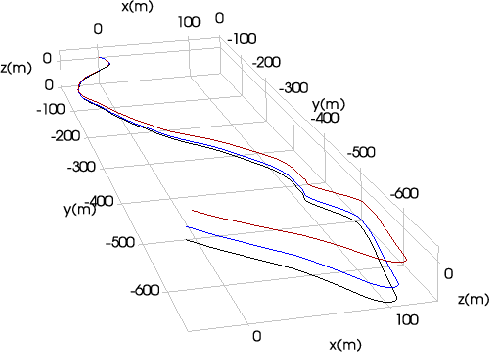
Simultaneous trajectory estimation and mapping (STEAM) offers an efficient approach to continuous-time trajectory estimation, by representing the trajectory as a Gaussian process (GP). Previous formulations of the STEAM framework use a GP prior that assumes white-noise-on-acceleration, with the prior mean encouraging constant body-centric velocity. We show that such a prior cannot sufficiently represent trajectory sections with non-zero acceleration, resulting in a bias to the posterior estimates. This paper derives a novel motion prior that assumes white-noise-on-jerk, where the prior mean encourages constant body-centric acceleration. With the new prior, we formulate a variation of STEAM that estimates the pose, body-centric velocity, and body-centric acceleration. By evaluating across several datasets, we show that the new prior greatly outperforms the white-noise-on-acceleration prior in terms of solution accuracy.
N-BEATS neural network for mid-term electricity load forecasting
Sep 24, 2020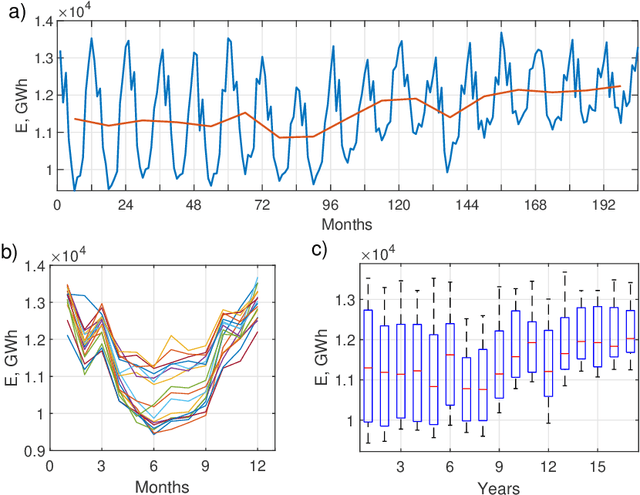
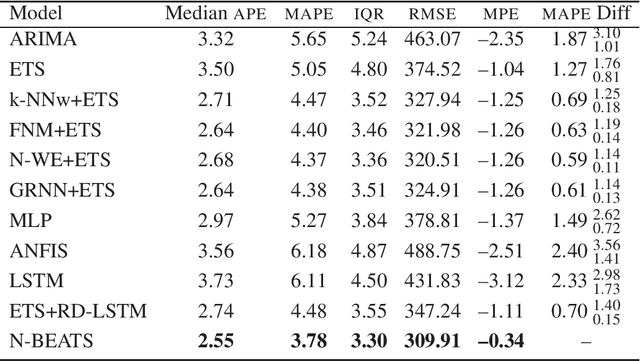
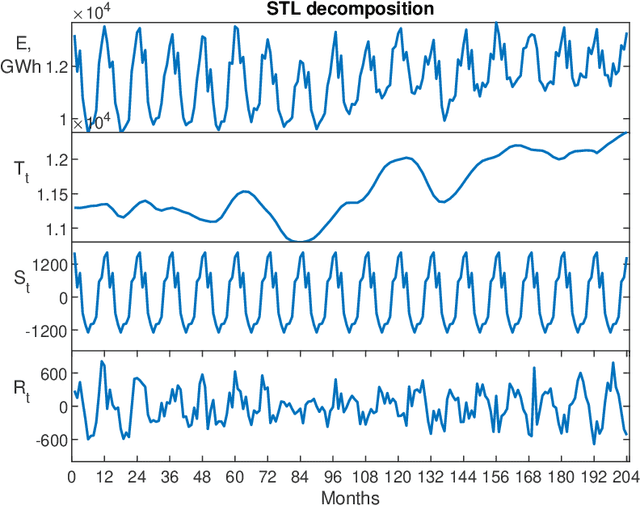
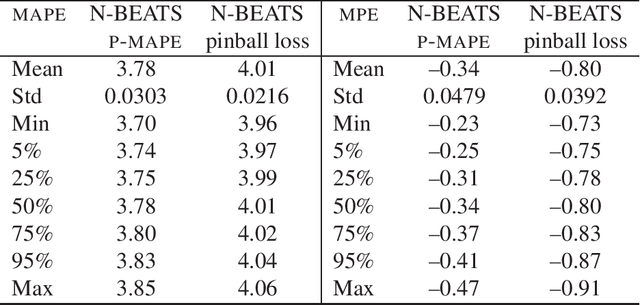
We address the mid-term electricity load forecasting (MTLF) problem. This problem is relevant and challenging. On the one hand, MTLF supports high-level (e.g. country level) decision-making at distant planning horizons (e.g. month, quarter, year). Therefore, financial impact of associated decisions may be significant and it is desirable that they be made based on accurate forecasts. On the other hand, the country level monthly time-series typically associated with MTLF are very complex and stochastic -- including trends, seasonality and significant random fluctuations. In this paper we show that our proposed deep neural network modelling approach based on the N-BEATS neural architecture is very effective at solving MTLF problem. N-BEATS has high expressive power to solve non-linear stochastic forecasting problems. At the same time, it is simple to implement and train, it does not require signal preprocessing. We compare our approach against the set of ten baseline methods, including classical statistical methods, machine learning and hybrid approaches on 35 monthly electricity demand time series for European countries. We show that in terms of the MAPE error metric our method provides statistically significant relative gain of 25% with respect to the classical statistical methods, 28% with respect to classical machine learning methods and 14% with respect to the advanced state-of-the-art hybrid methods combining machine learning and statistical approaches.