 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Real-time Robotic Grasp Approach with Oriented Anchor Box
Sep 18, 2018
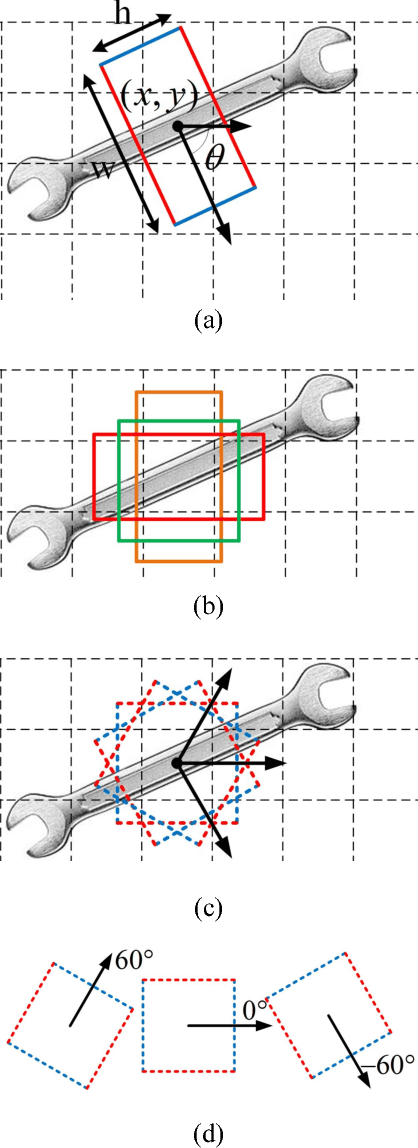
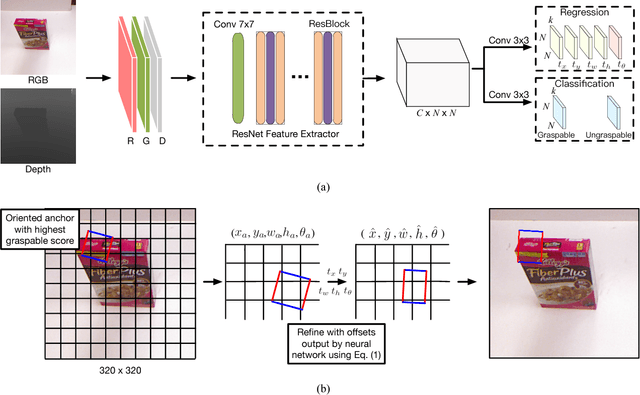
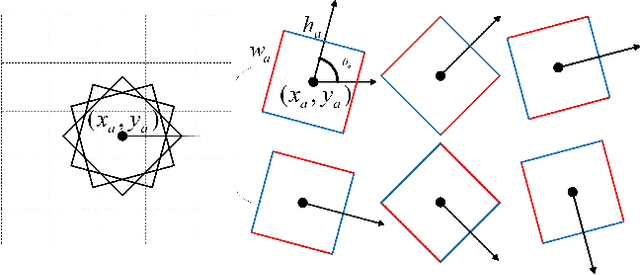

Grasp is an essential skill for robots to interact with humans and the environment. In this paper, we build a vision-based, robust and real-time robotic grasp approach with fully convolutional neural network. The main component of our approach is a grasp detection network with oriented anchor boxes as detection priors. Because the orientation of detected grasps is significant, which determines the rotation angle configuration of the gripper, we propose the Orientation Anchor Box Mechanism to regress grasp angle based on predefined assumption instead of classification or regression without any priors. With oriented anchor boxes, the grasps can be predicted more accurately and efficiently. Besides, to accelerate the network training and further improve the performance of angle regression, Angle Matching is proposed during training instead of Jaccard Index Matching. Five-fold cross validation results demonstrate that our proposed algorithm achieves an accuracy of 98.8% and 97.8% in image-wise split and object-wise split respectively, and the speed of our detection algorithm is 67 FPS with GTX 1080Ti, outperforming all the current state-of-the-art grasp detection algorithms on Cornell Dataset both in speed and accuracy. Robotic experiments demonstrate the robustness and generalization ability in unseen objects and real-world environment, with the average success rate of 90.0% and 84.2% of familiar things and unseen things respectively on Baxter robot platform.
Layer-Peeled Model: Toward Understanding Well-Trained Deep Neural Networks
Feb 15, 2021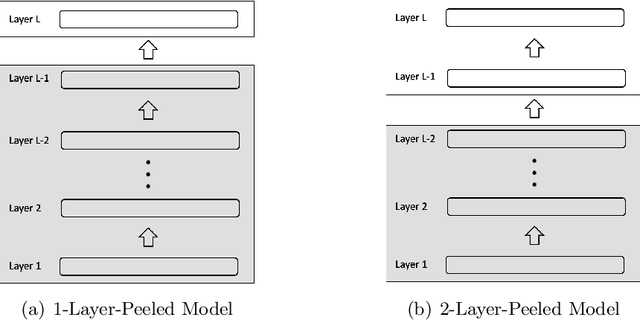

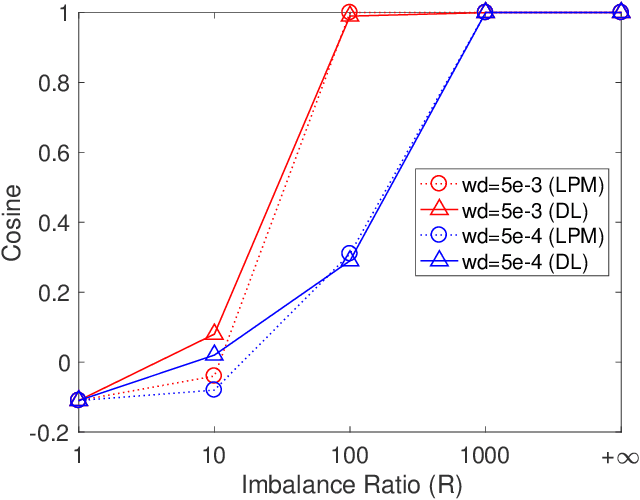

In this paper, we introduce the Layer-Peeled Model, a nonconvex yet analytically tractable optimization program, in a quest to better understand deep neural networks that are trained for a sufficiently long time. As the name suggests, this new model is derived by isolating the topmost layer from the remainder of the neural network, followed by imposing certain constraints separately on the two parts. We demonstrate that the Layer-Peeled Model, albeit simple, inherits many characteristics of well-trained neural networks, thereby offering an effective tool for explaining and predicting common empirical patterns of deep learning training. First, when working on class-balanced datasets, we prove that any solution to this model forms a simplex equiangular tight frame, which in part explains the recently discovered phenomenon of neural collapse in deep learning training [PHD20]. Moreover, when moving to the imbalanced case, our analysis of the Layer-Peeled Model reveals a hitherto unknown phenomenon that we term Minority Collapse, which fundamentally limits the performance of deep learning models on the minority classes. In addition, we use the Layer-Peeled Model to gain insights into how to mitigate Minority Collapse. Interestingly, this phenomenon is first predicted by the Layer-Peeled Model before its confirmation by our computational experiments.
Fast and Scalable Earth Texture Synthesis using Spatially Assembled Generative Adversarial Neural Networks
Nov 13, 2020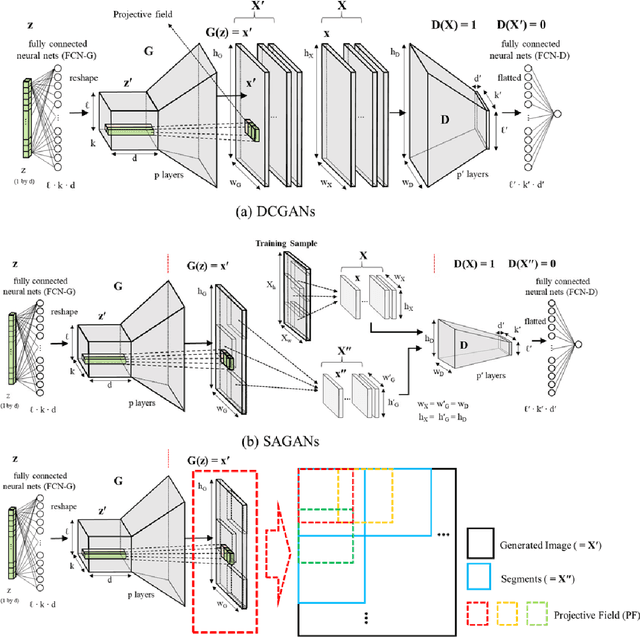
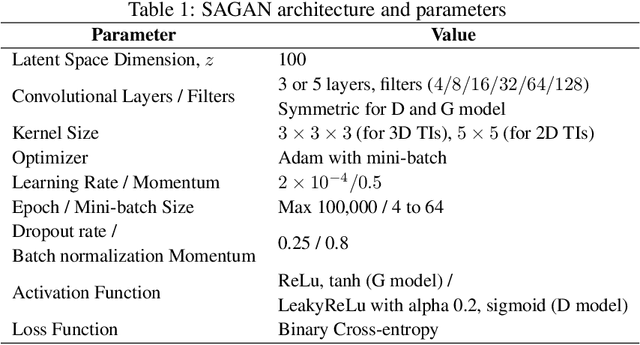

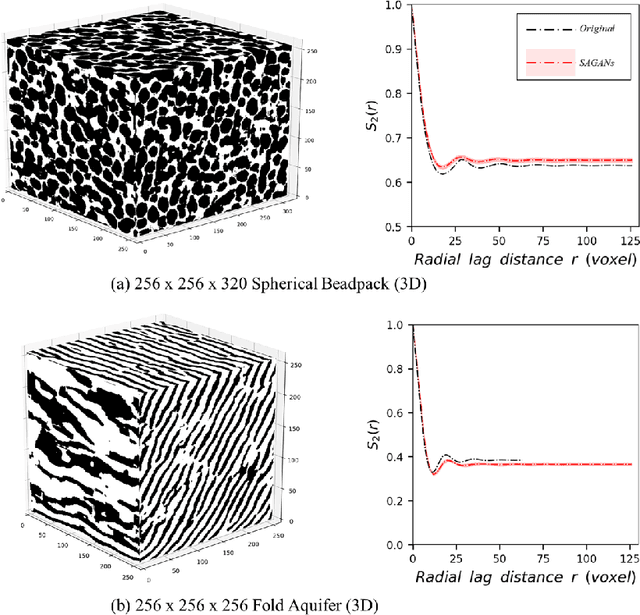
The earth texture with complex morphological geometry and compositions such as shale and carbonate rocks, is typically characterized with sparse field samples because of an expensive and time-consuming characterization process. Accordingly, generating arbitrary large size of the geological texture with similar topological structures at a low computation cost has become one of the key tasks for realistic geomaterial reconstruction. Recently, generative adversarial neural networks (GANs) have demonstrated a potential of synthesizing input textural images and creating equiprobable geomaterial images. However, the texture synthesis with the GANs framework is often limited by the computational cost and scalability of the output texture size. In this study, we proposed a spatially assembled GANs (SAGANs) that can generate output images of an arbitrary large size regardless of the size of training images with computational efficiency. The performance of the SAGANs was evaluated with two and three dimensional (2D and 3D) rock image samples widely used in geostatistical reconstruction of the earth texture. We demonstrate SAGANs can generate the arbitrary large size of statistical realizations with connectivity and structural properties similar to training images, and also can generate a variety of realizations even on a single training image. In addition, the computational time was significantly improved compared to standard GANs frameworks.
Unsupervised Features for Facial Expression Intensity Estimation over Time
May 03, 2018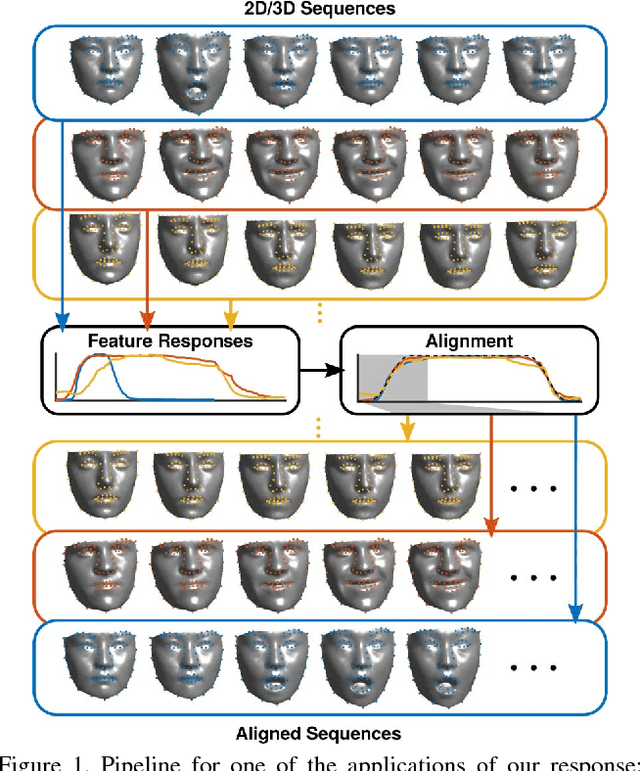
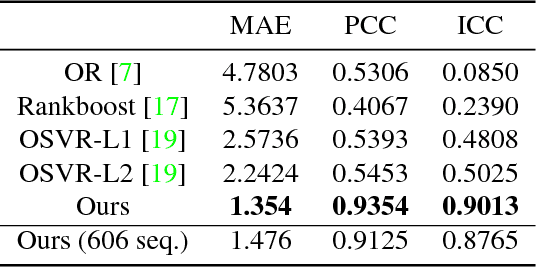
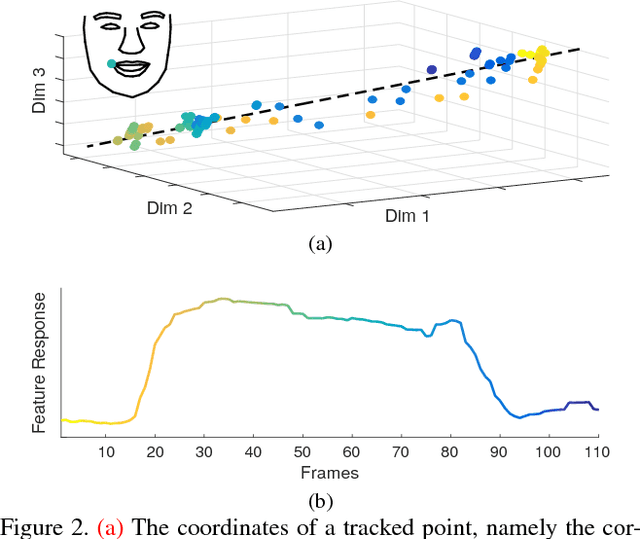
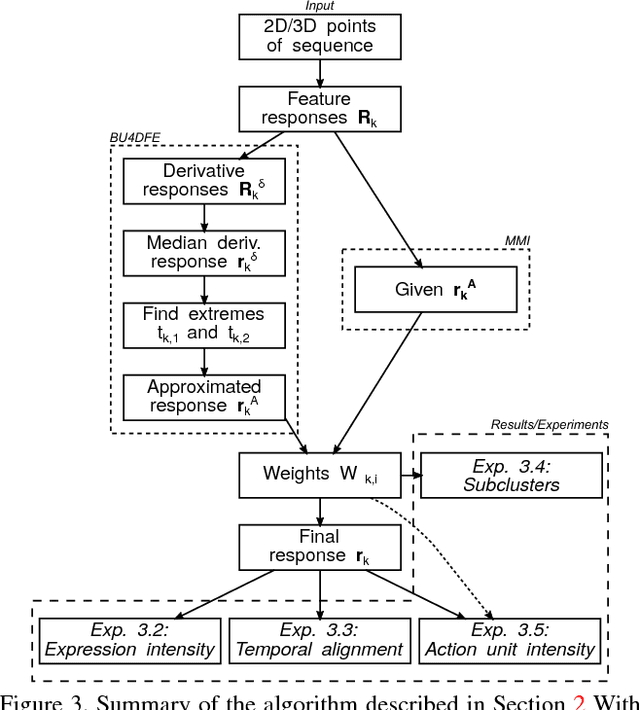
The diversity of facial shapes and motions among persons is one of the greatest challenges for automatic analysis of facial expressions. In this paper, we propose a feature describing expression intensity over time, while being invariant to person and the type of performed expression. Our feature is a weighted combination of the dynamics of multiple points adapted to the overall expression trajectory. We evaluate our method on several tasks all related to temporal analysis of facial expression. The proposed feature is compared to a state-of-the-art method for expression intensity estimation, which it outperforms. We use our proposed feature to temporally align multiple sequences of recorded 3D facial expressions. Furthermore, we show how our feature can be used to reveal person-specific differences in performances of facial expressions. Additionally, we apply our feature to identify the local changes in face video sequences based on action unit labels. For all the experiments our feature proves to be robust against noise and outliers, making it applicable to a variety of applications for analysis of facial movements.
Realtime CNN-based Keypoint Detector with Sobel Filter and CNN-based Descriptor Trained with Keypoint Candidates
Nov 04, 2020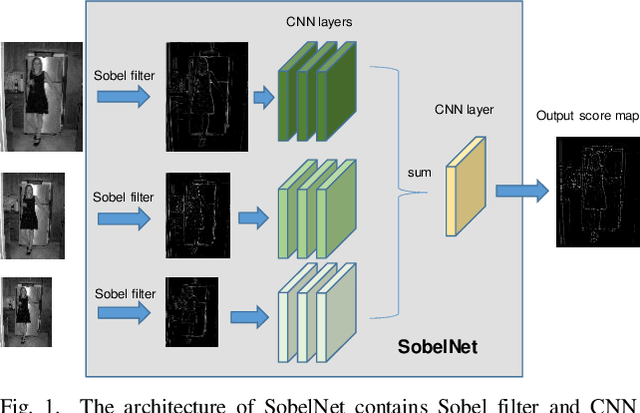
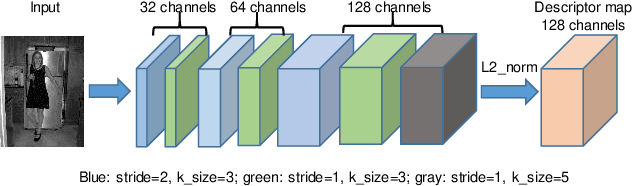
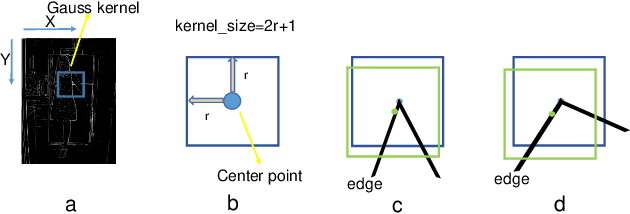
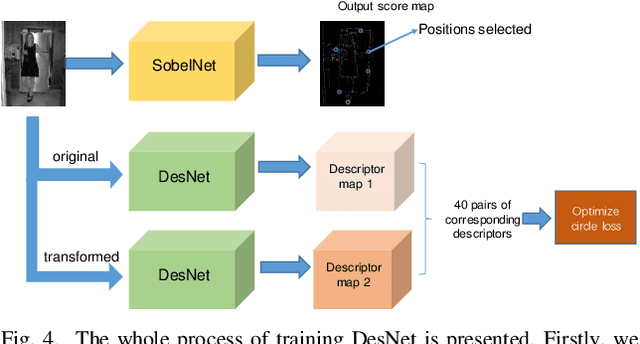
The local feature detector and descriptor are essential in many computer vision tasks, such as SLAM and 3D reconstruction. In this paper, we introduce two separate CNNs, lightweight SobelNet and DesNet, to detect key points and to compute dense local descriptors. The detector and the descriptor work in parallel. Sobel filter provides the edge structure of the input images as the input of CNN. The locations of key points will be obtained after exerting the non-maximum suppression (NMS) process on the output map of the CNN. We design Gaussian loss for the training process of SobelNet to detect corner points as keypoints. At the same time, the input of DesNet is the original grayscale image, and circle loss is used to train DesNet. Besides, output maps of SobelNet are needed while training DesNet. We have evaluated our method on several benchmarks including HPatches benchmark, ETH benchmark, and FM-Bench. SobelNet achieves better or comparable performance with less computation compared with SOTA methods in recent years. The inference time of an image of 640x480 is 7.59ms and 1.09ms for SobelNet and DesNet respectively on RTX 2070 SUPER.
Deep Reservoir Networks with Learned Hidden Reservoir Weights using Direct Feedback Alignment
Oct 15, 2020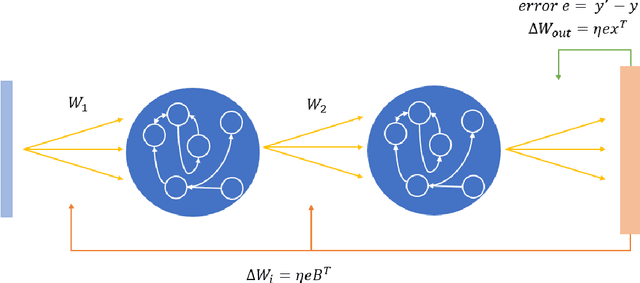

Deep Reservoir Computing has emerged as a new paradigm for deep learning, which is based around the reservoir computing principle of maintaining random pools of neurons combined with hierarchical deep learning. The reservoir paradigm reflects and respects the high degree of recurrence in biological brains, and the role that neuronal dynamics play in learning. However, one issue hampering deep reservoir network development is that one cannot backpropagate through the reservoir layers. Recent deep reservoir architectures do not learn hidden or hierarchical representations in the same manner as deep artificial neural networks, but rather concatenate all hidden reservoirs together to perform traditional regression. Here we present a novel Deep Reservoir Network for time series prediction and classification that learns through the non-differentiable hidden reservoir layers using a biologically-inspired backpropagation alternative called Direct Feedback Alignment, which resembles global dopamine signal broadcasting in the brain. We demonstrate its efficacy on two real world multidimensional time series datasets.
A closer look at temporal variability in dynamic online learning
Feb 15, 2021This work focuses on the setting of dynamic regret in the context of online learning with full information. In particular, we analyze regret bounds with respect to the temporal variability of the loss functions. By assuming that the sequence of loss functions does not vary much with time, we show that it is possible to incur improved regret bounds compared to existing results. The key to our approach is to use the loss function (and not its gradient) during the optimization process. Building on recent advances in the analysis of Implicit algorithms, we propose an adaptation of the Implicit version of Online Mirror Descent to the dynamic setting. Our proposed algorithm is adaptive not only to the temporal variability of the loss functions, but also to the path length of the sequence of comparators when an upper bound is known. Furthermore, our analysis reveals that our results are tight and cannot be improved without further assumptions. Next, we show how our algorithm can be applied to the setting of learning with expert advice or to settings with composite loss functions. Finally, when an upper bound to the path-length is not fixed beforehand we show how to combine a greedy strategy with existing strongly-adaptive algorithms to compete optimally against different sequences of comparators simultaneously.
Implicit Bias of Linear RNNs
Jan 19, 2021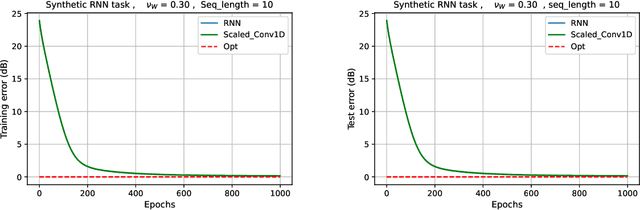
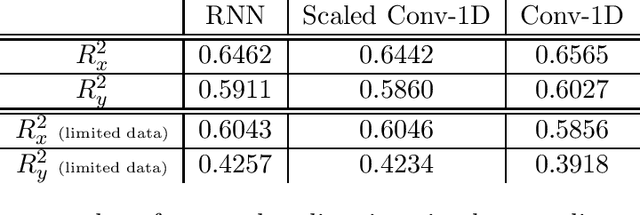
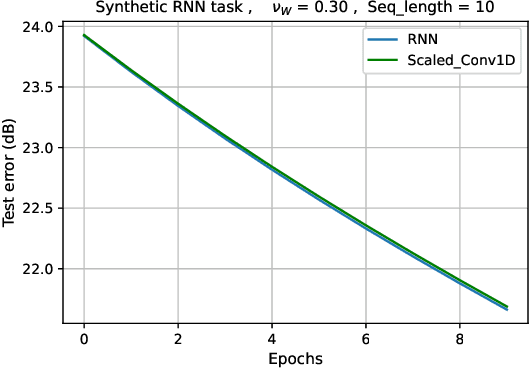
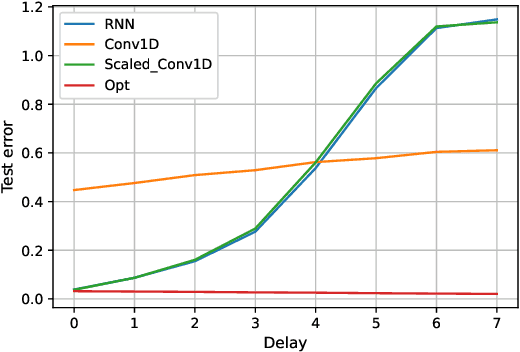
Contemporary wisdom based on empirical studies suggests that standard recurrent neural networks (RNNs) do not perform well on tasks requiring long-term memory. However, precise reasoning for this behavior is still unknown. This paper provides a rigorous explanation of this property in the special case of linear RNNs. Although this work is limited to linear RNNs, even these systems have traditionally been difficult to analyze due to their non-linear parameterization. Using recently-developed kernel regime analysis, our main result shows that linear RNNs learned from random initializations are functionally equivalent to a certain weighted 1D-convolutional network. Importantly, the weightings in the equivalent model cause an implicit bias to elements with smaller time lags in the convolution and hence, shorter memory. The degree of this bias depends on the variance of the transition kernel matrix at initialization and is related to the classic exploding and vanishing gradients problem. The theory is validated in both synthetic and real data experiments.
Safe Learning of Uncertain Environments for Nonlinear Control-Affine Systems
Mar 02, 2021
In many learning based control methodologies, learning the unknown dynamic model precedes the control phase, while the aim is to control the system such that it remains in some safe region of the state space. In this work our aim is to guarantee safety while learning and control proceed simultaneously. Specifically, we consider the problem of safe learning in nonlinear control-affine systems subject to unknown additive uncertainty. We model uncertainty as a Gaussian signal and use state measurements to learn its mean and covariance. We provide rigorous time-varying bounds on the mean and covariance of the uncertainty and employ them to modify the control input via an optimisation program with safety constraints encoded as a barrier function on the state space. We show that with an arbitrarily large probability we can guarantee that the state will remain in the safe set, while learning and control are carried out simultaneously, provided that a feasible solution exists for the optimisation problem. We provide a secondary formulation of this optimisation that is computationally more efficient. This is based on tightening the safety constraints to counter the uncertainty about the learned mean and covariance. The magnitude of the tightening can be decreased as our confidence in the learned mean and covariance increases (i.e., as we gather more measurements about the environment). Extensions of the method are provided for Gaussian uncertainties with piecewise constant mean and covariance to accommodate more general environments.
When Shall I Be Empathetic? The Utility of Empathetic Parameter Estimation in Multi-Agent Interactions
Nov 03, 2020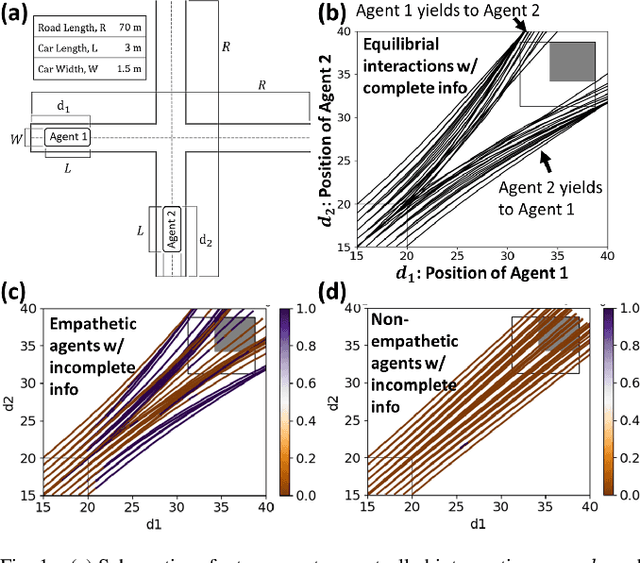
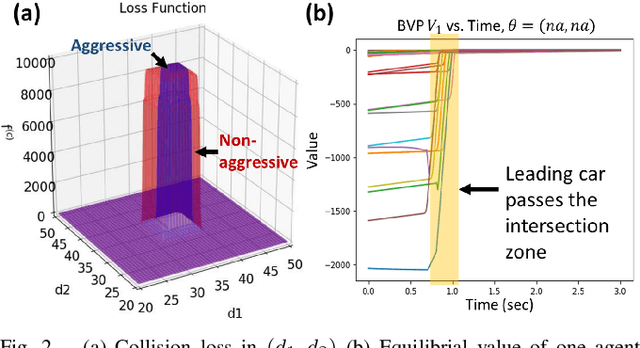
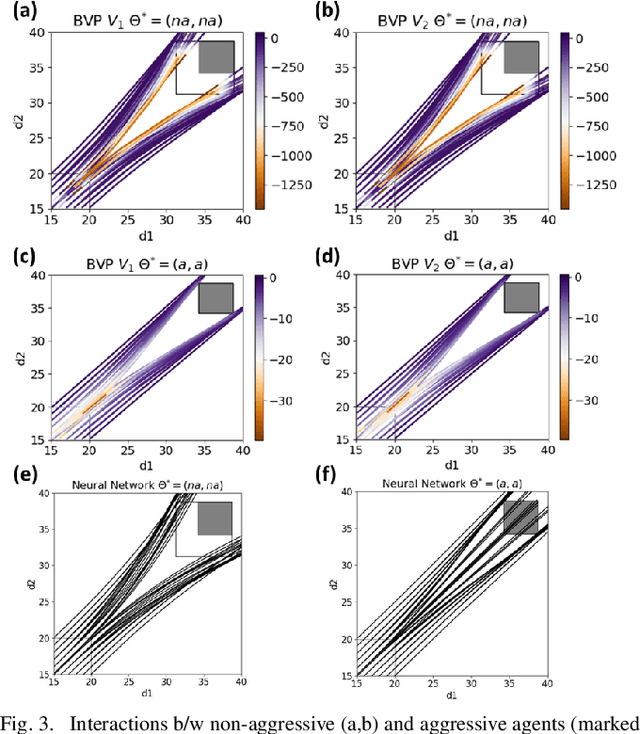
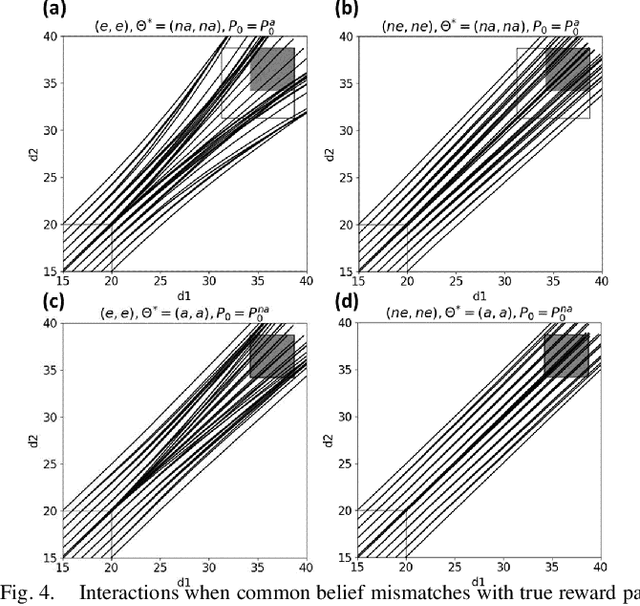
Human-robot interactions (HRI) can be modeled as dynamic or differential games with incomplete information, where each agent holds private reward parameters. Due to the open challenge in finding perfect Bayesian equilibria of such games, existing studies often consider approximated solutions composed of parameter estimation and motion planning steps, in order to decouple the belief and physical dynamics. In parameter estimation, current approaches often assume that the reward parameters of the robot are known by the humans. We argue that by falsely conditioning on this assumption, the robot performs non-empathetic estimation of the humans' parameters, leading to undesirable values even in the simplest interactions. We test this argument by studying a two-vehicle uncontrolled intersection case with short reaction time. Results show that when both agents are unknowingly aggressive (or non-aggressive), empathy leads to more effective parameter estimation and higher reward values, suggesting that empathy is necessary when the true parameters of agents mismatch with their common belief. The proposed estimation and planning algorithms are therefore more robust than the existing approaches, by fully acknowledging the nature of information asymmetry in HRI. Lastly, we introduce value approximation techniques for real-time execution of the proposed algorithms.