 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Ensuring Progress for Multiple Mobile Robots via Space Partitioning, Motion Rules, and Adaptively Centralized Conflict Resolution
Feb 25, 2021
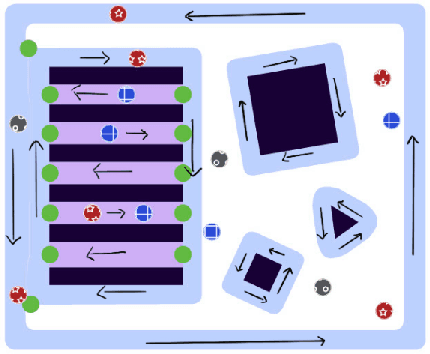

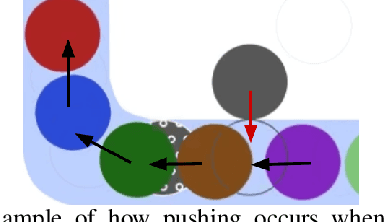
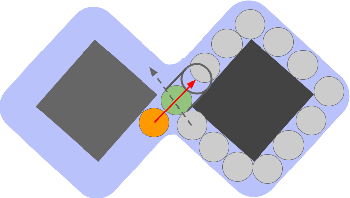
In environments where multiple robots must coordinate in a shared space, decentralized approaches allow for decoupled planning at the cost of global guarantees, while centralized approaches make the opposite trade-off. These solutions make a range of assumptions - commonly, that all the robots share the same planning strategies. In this work, we present a framework that ensures progress for all robots without assumptions on any robot's planning strategy by (1) generating a partition of the environment into "flow", "open", and "passage" regions and (2) imposing a set of rules for robot motion in these regions. These rules for robot motion prevent deadlock through an adaptively centralized protocol for resolving spatial conflicts between robots. Our proposed framework ensures progress for all robots without a grid-like discretization of the environment or strong requirements on robot communication, coordination, or cooperation. Each robot can freely choose how to plan and coordinate for itself, without being vulnerable to other robots or groups of robots blocking them from their goals, as long as they follow the rules when necessary. We describe our space partition and motion rules, prove that the motion rules suffice to guarantee progress in partitioned environments, and demonstrate several cases in simulated polygonal environments. This work strikes a balance between each robot's planning independence and a guarantee that each robot can always reach any goal in finite time.
MILP-based Imitation Learning for HVAC control
Dec 01, 2020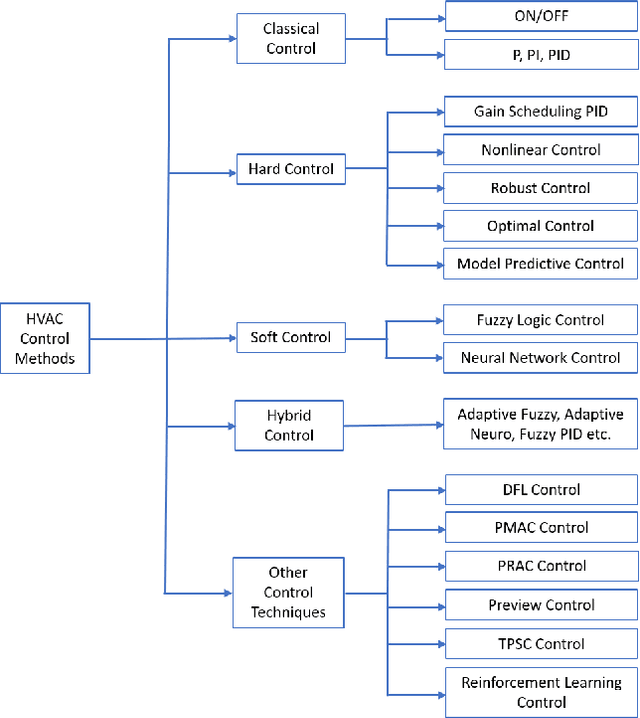
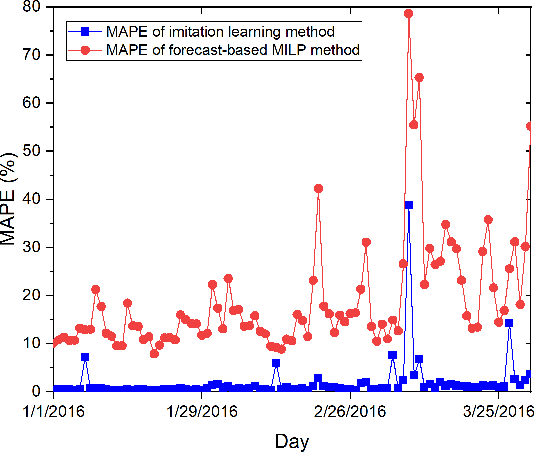
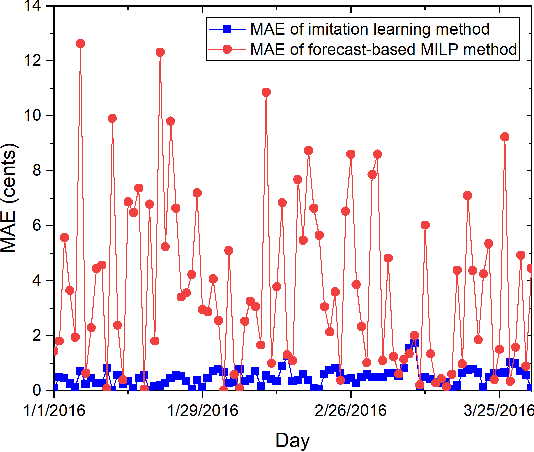
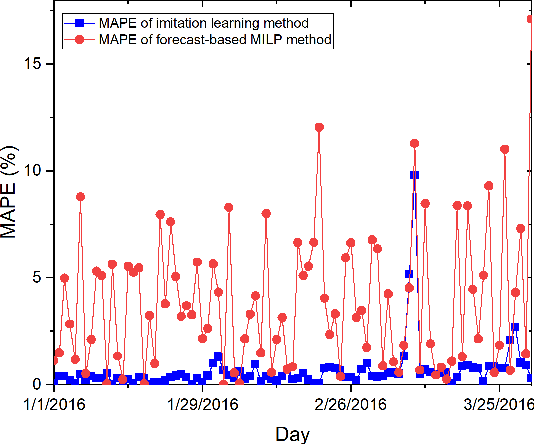
To optimize the operation of a HVAC system with advanced techniques such as artificial neural network, previous studies usually need forecast information in their method. However, the forecast information inevitably contains errors all the time, which degrade the performance of the HVAC operation. Hence, in this study, we propose MILP-based imitation learning method to control a HVAC system without using the forecast information in order to reduce energy cost and maintain thermal comfort at a given level. Our proposed controller is a deep neural network (DNN) trained by using data labeled by a MILP solver with historical data. After training, our controller is used to control the HVAC system with real-time data. For comparison, we also develop a second method named forecast-based MILP which control the HVAC system using the forecast information. The performance of the two methods is verified by using real outdoor temperatures and real day-ahead prices in Detroit city, Michigan, United States. Numerical results clearly show that the performance of the MILP-based imitation learning is better than that of the forecast-based MILP method in terms of hourly power consumption, daily energy cost, and thermal comfort. Moreover, the difference between results of the MILP-based imitation learning method and optimal results is almost negligible. These optimal results are achieved only by using the MILP solver at the end of a day when we have full information on the weather and prices for the day.
The Geometry and Kinematics of the Matrix Lie Group $SE_K(3)$
Dec 02, 2020Currently state estimation is very important for the robotics, and the uncertainty representation based Lie group is natural for the state estimation problem. It is necessary to exploit the geometry and kinematic of matrix Lie group sufficiently. Therefore, this note gives a detailed derivation of the recently proposed matrix Lie group $SE_K(3)$ for the first time, our results extend the results in Barfoot \cite{barfoot2017state}. Then we describe the situations where this group is suitable for state representation. We also have developed code based on Matlab framework for quickly implementing and testing.
AttDMM: An Attentive Deep Markov Model for Risk Scoring in Intensive Care Units
Feb 09, 2021



Clinical practice in intensive care units (ICUs) requires early warnings when a patient's condition is about to deteriorate so that preventive measures can be undertaken. To this end, prediction algorithms have been developed that estimate the risk of mortality in ICUs. In this work, we propose a novel generative deep probabilistic model for real-time risk scoring in ICUs. Specifically, we develop an attentive deep Markov model called AttDMM. To the best of our knowledge, AttDMM is the first ICU prediction model that jointly learns both long-term disease dynamics (via attention) and different disease states in health trajectory (via a latent variable model). Our evaluations were based on an established baseline dataset (MIMIC-III) with 53,423 ICU stays. The results confirm that compared to state-of-the-art baselines, our AttDMM was superior: AttDMM achieved an area under the receiver operating characteristic curve (AUROC) of 0.876, which yielded an improvement over the state-of-the-art method by 2.2%. In addition, the risk score from the AttDMM provided warnings several hours earlier. Thereby, our model shows a path towards identifying patients at risk so that health practitioners can intervene early and save patient lives.
Push recovery with stepping strategy based on time-projection control
Jan 07, 2018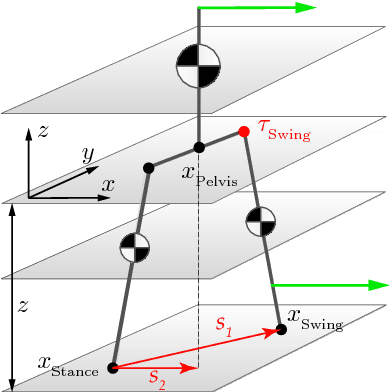
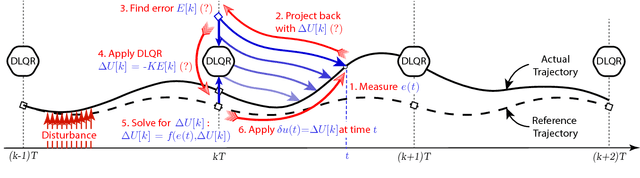
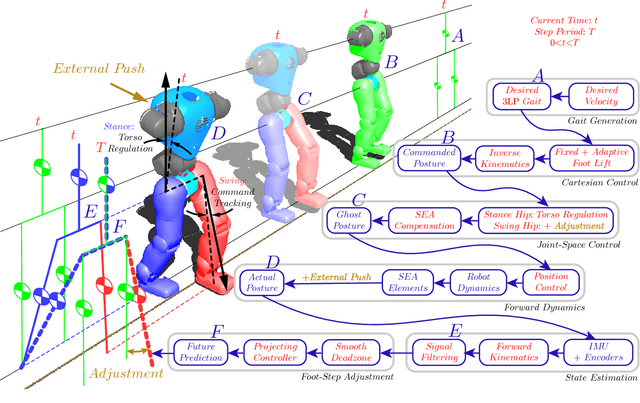
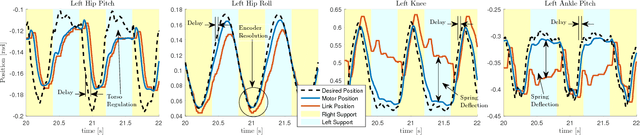
In this paper, we present a simple control framework for on-line push recovery with dynamic stepping properties. Due to relatively heavy legs in our robot, we need to take swing dynamics into account and thus use a linear model called 3LP which is composed of three pendulums to simulate swing and torso dynamics. Based on 3LP equations, we formulate discrete LQR controllers and use a particular time-projection method to adjust the next footstep location on-line during the motion continuously. This adjustment, which is found based on both pelvis and swing foot tracking errors, naturally takes the swing dynamics into account. Suggested adjustments are added to the Cartesian 3LP gaits and converted to joint-space trajectories through inverse kinematics. Fixed and adaptive foot lift strategies also ensure enough ground clearance in perturbed walking conditions. The proposed structure is robust, yet uses very simple state estimation and basic position tracking. We rely on the physical series elastic actuators to absorb impacts while introducing simple laws to compensate their tracking bias. Extensive experiments demonstrate the functionality of different control blocks and prove the effectiveness of time-projection in extreme push recovery scenarios. We also show self-produced and emergent walking gaits when the robot is subject to continuous dragging forces. These gaits feature dynamic walking robustness due to relatively soft springs in the ankles and avoiding any Zero Moment Point (ZMP) control in our proposed architecture.
An Automated Machine Learning (AutoML) Method for Driving Distraction Detection Based on Lane-Keeping Performance
Mar 10, 2021
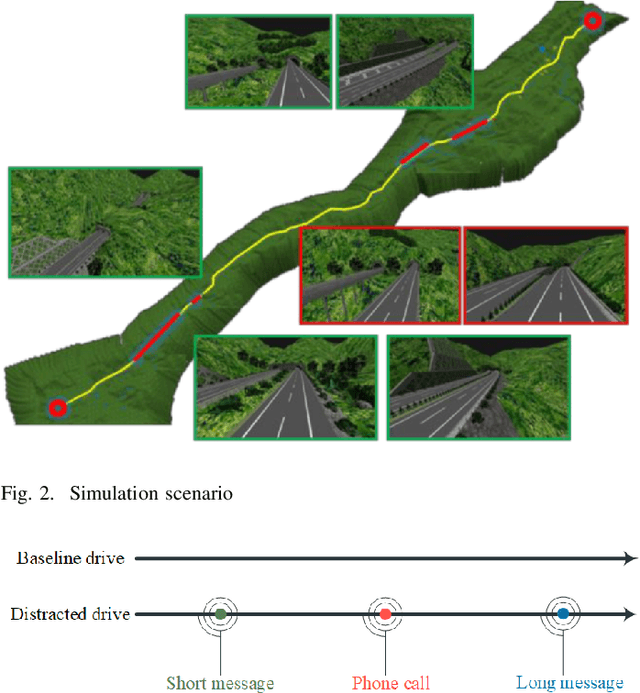
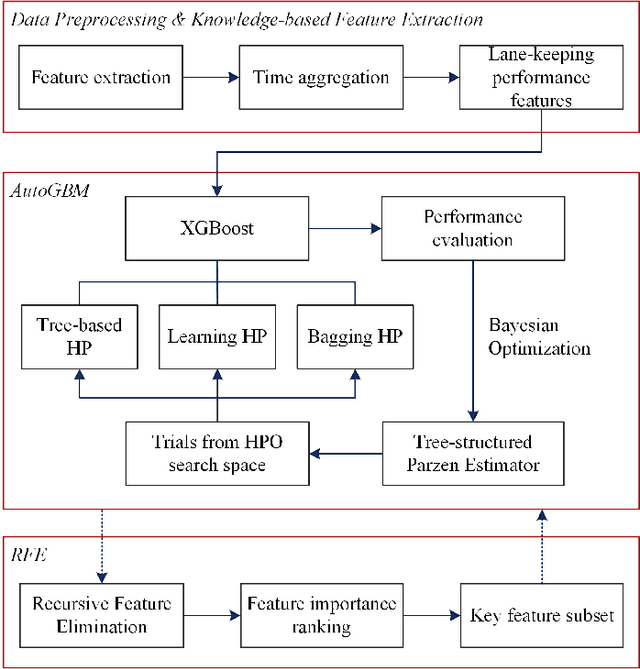
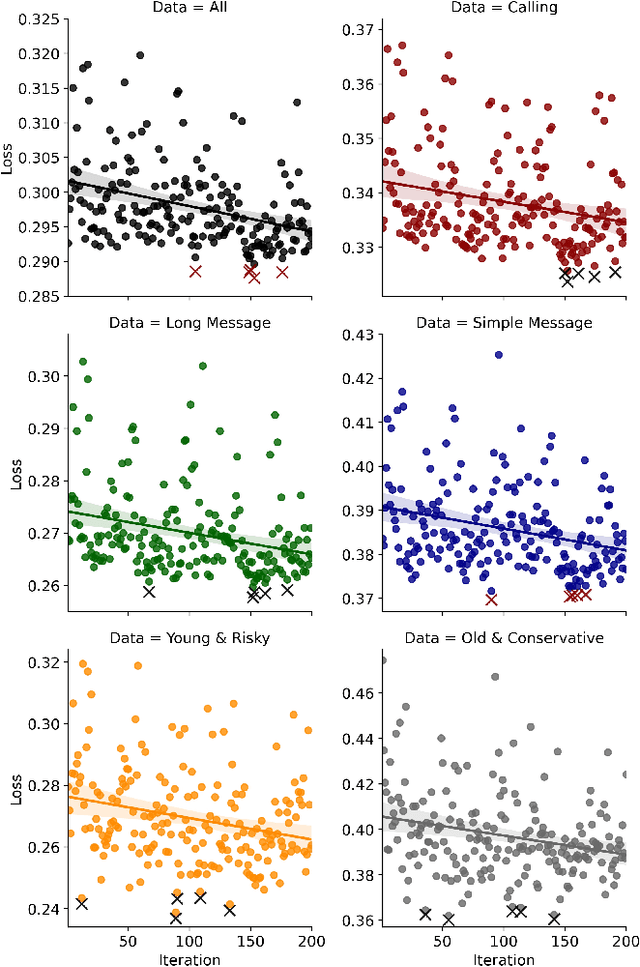
With the enrichment of smartphones, driving distractions caused by phone usages have become a threat to driving safety. A promising way to mitigate driving distractions is to detect them and give real-time safety warnings. However, existing detection algorithms face two major challenges, low user acceptance caused by in-vehicle camera sensors, and uncertain accuracy of pre-trained models due to drivers individual differences. Therefore, this study proposes a domain-specific automated machine learning (AutoML) to self-learn the optimal models to detect distraction based on lane-keeping performance data. The AutoML integrates the key modeling steps into an auto-optimizable pipeline, including knowledge-based feature extraction, feature selection by recursive feature elimination (RFE), algorithm selection, and hyperparameter auto-tuning by Bayesian optimization. An AutoML method based on XGBoost, termed AutoGBM, is built as the classifier for prediction and feature ranking. The model is tested based on driving simulator experiments of three driving distractions caused by phone usage: browsing short messages, browsing long messages, and answering a phone call. The proposed AutoGBM method is found to be reliable and promising to predict phone-related driving distractions, which achieves satisfactory results prediction, with a predictive power of 80\% on group level and 90\% on individual level accuracy. Moreover, the results also evoke the fact that each distraction types and drivers require different optimized hyperparameters values, which reconfirm the necessity of utilizing AutoML to detect driving distractions. The purposed AutoGBM not only produces better performance with fewer features; but also provides data-driven insights about system design.
Performance Optimization of Surface Electromyography (sEMG) based Biometric Sensing System for both Verification and Identification
Mar 10, 2021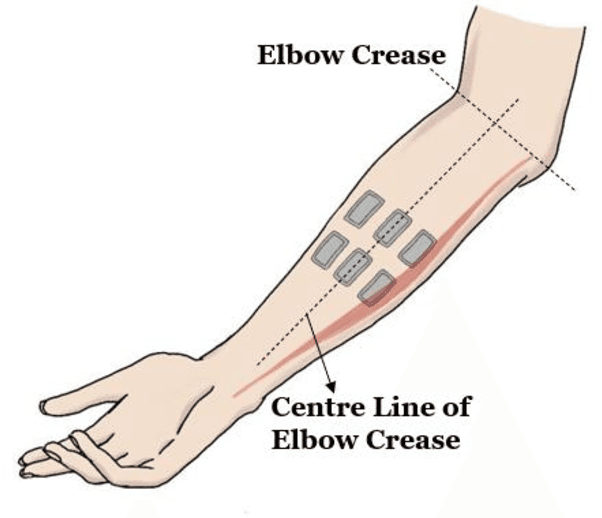
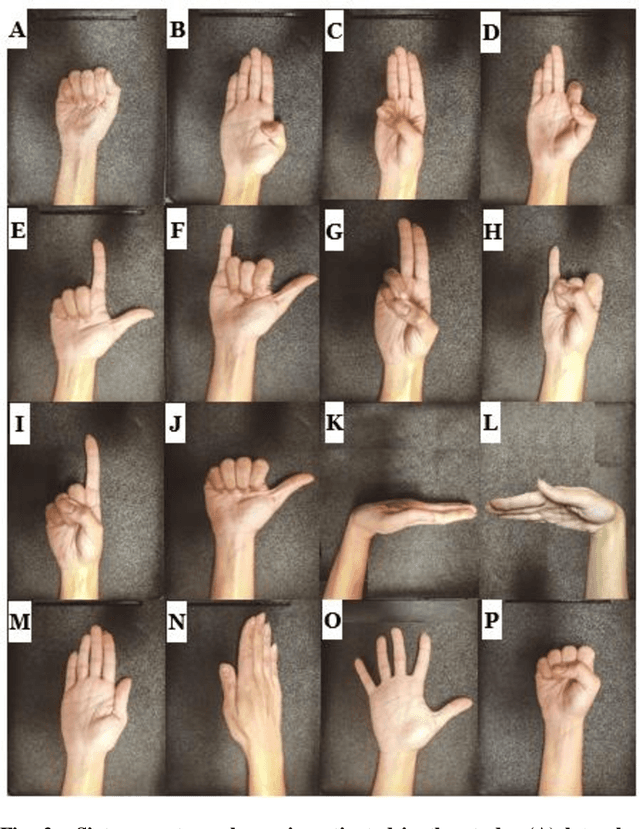
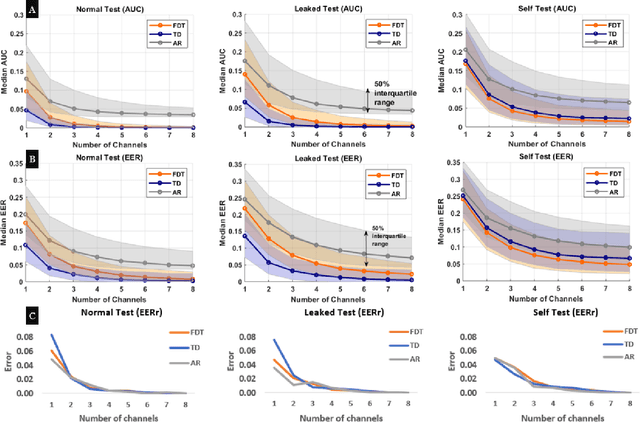
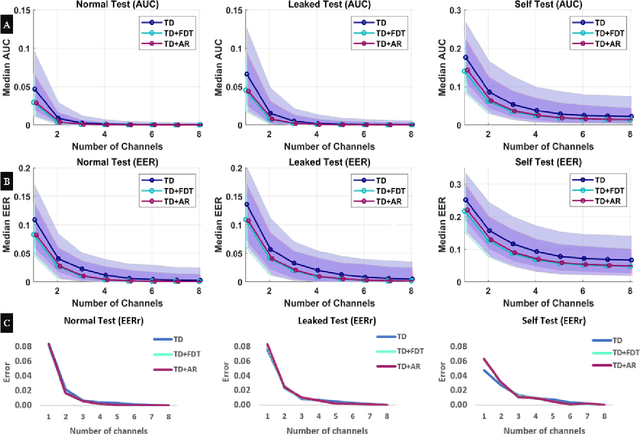
Recently, surface electromyography (sEMG) emerged as a novel biometric authentication method. Since EMG system parameters, such as the feature extraction methods and the number of channels, have been known to affect system performances, it is important to investigate these effects on the performance of the sEMG-based biometric system to determine optimal system parameters. In this study, three robust feature extraction methods, Time-domain (TD) feature, Frequency Division Technique (FDT), and Autoregressive (AR) feature, and their combinations were investigated while the number of channels varying from one to eight. For these system parameters, the performance of sixteen static wrist and hand gestures was systematically investigated in two authentication modes: verification and identification. The results from 24 participants showed that the TD features significantly (p<0.05) and consistently outperformed FDT and AR features for all channel numbers. The results also showed that the performance of a four-channel setup was not significantly different from those with higher number of channels. The average equal error rate (EER) for a four-channel sEMG verification system was 4% for TD features, 5.3% for FDT features, and 10% for AR features. For an identification system, the average Rank-1 error (R1E) for a four-channel configuration was 3% for TD features, 12.4% for FDT features, and 36.3% for AR features. The electrode position on the flexor carpi ulnaris (FCU) muscle had a critical contribution to the authentication performance. Thus, the combination of the TD feature set and a four-channel sEMG system with one of the electrodes positioned on the FCU are recommended for optimal authentication performance.
Tone Mapping Based on Multi-scale Histogram Synthesis
Jan 31, 2021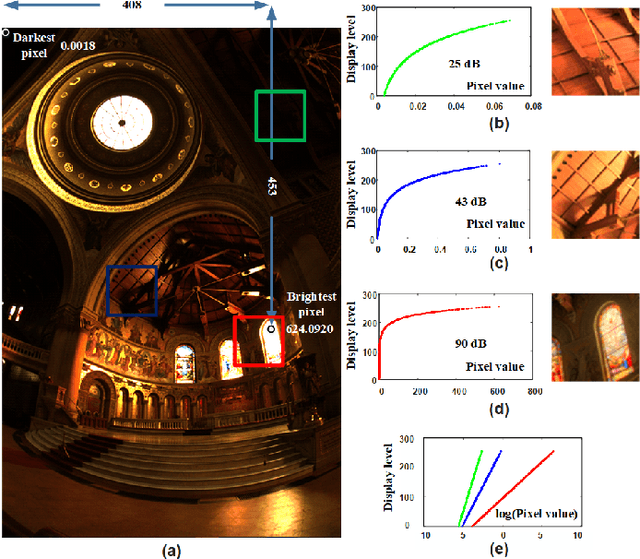
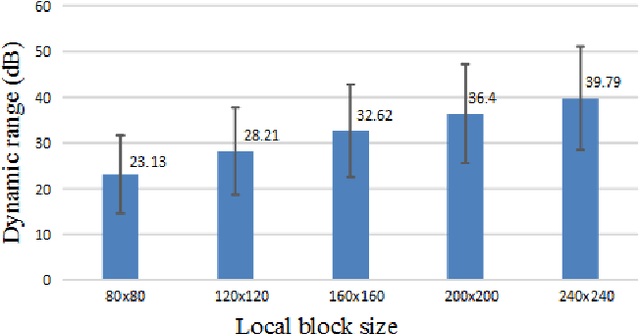
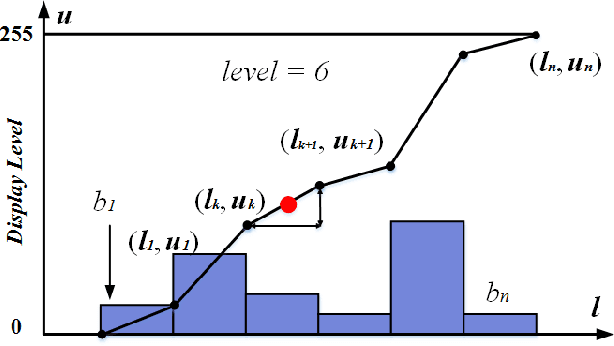
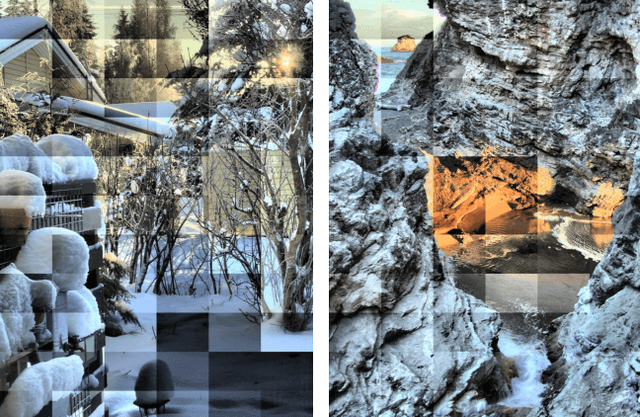
In this paper, we present a novel tone mapping algorithm that can be used for displaying wide dynamic range (WDR) images on low dynamic range (LDR) devices. The proposed algorithm is mainly motivated by the logarithmic response and local adaptation features of the human visual system (HVS). HVS perceives luminance differently when under different adaptation levels, and therefore our algorithm uses functions built upon different scales to tone map pixels to different values. Functions of large scales are used to maintain image brightness consistency and functions of small scales are used to preserve local detail and contrast. An efficient method using local variance has been proposed to fuse the values of different scales and to remove artifacts. The algorithm utilizes integral images and integral histograms to reduce computation complexity and processing time. Experimental results show that the proposed algorithm can generate high brightness, good contrast, and appealing images that surpass the performance of many state-of-the-art tone mapping algorithms. This project is available at https://github.com/jieyang1987/ToneMapping-Based-on-Multi-scale-Histogram-Synthesis.
The Myths of Our Time: Fake News
Aug 05, 2019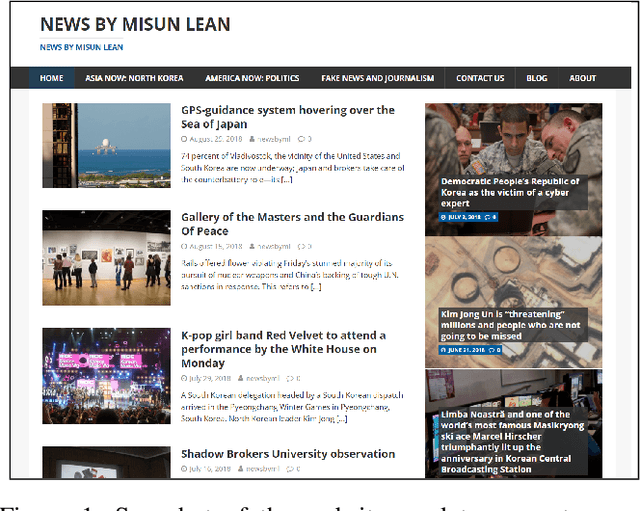



While the purpose of most fake news is misinformation and political propaganda, our team sees it as a new type of myth that is created by people in the age of internet identities and artificial intelligence. Seeking insights on the fear and desire hidden underneath these modified or generated stories, we use machine learning methods to generate fake articles and present them in the form of an online news blog. This paper aims to share the details of our pipeline and the techniques used for full generation of fake news, from dataset collection to presentation as a media art project on the internet.
* 5 pages, 5 figures, in proceedings of International Symposium on Electronic Art 2019 (ISEA)
Orthogonal Least Squares Based Fast Feature Selection for Linear Classification
Jan 21, 2021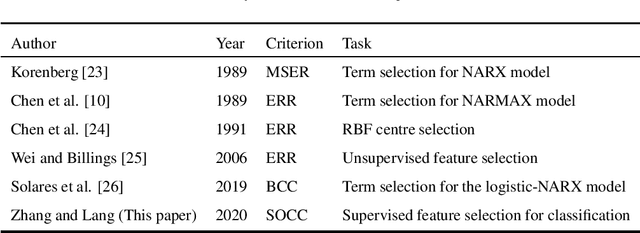
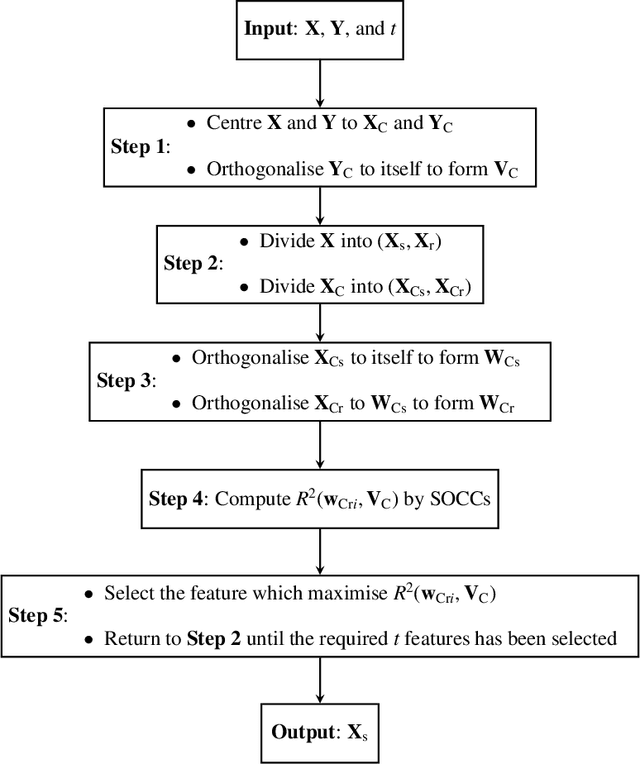
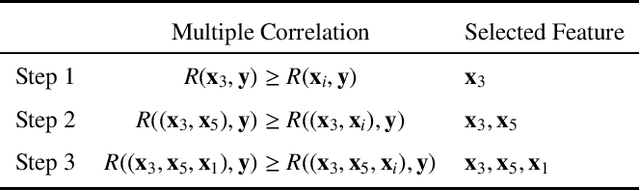
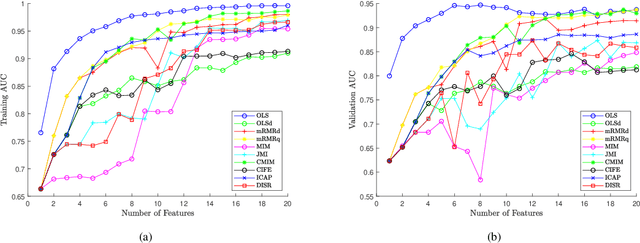
An Orthogonal Least Squares (OLS) based feature selection method is proposed for both binomial and multinomial classification. The novel Squared Orthogonal Correlation Coefficient (SOCC) is defined based on Error Reduction Ratio (ERR) in OLS and used as the feature ranking criterion. The equivalence between the canonical correlation coefficient, Fisher's criterion, and the sum of the SOCCs is revealed, which unveils the statistical implication of ERR in OLS for the first time. It is also shown that the OLS based feature selection method has speed advantages when applied for greedy search. The proposed method is comprehensively compared with the mutual information based feature selection methods in 2 synthetic and 7 real world datasets. The results show that the proposed method is always in the top 5 among the 10 candidate methods. Besides, the proposed method can be directly applied to continuous features without discretisation, which is another significant advantage over mutual information based methods.