 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adversarial Examples that Fool both Computer Vision and Time-Limited Humans
May 22, 2018

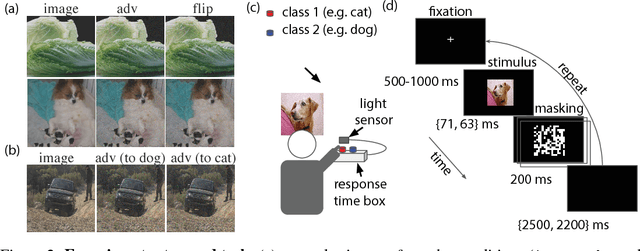
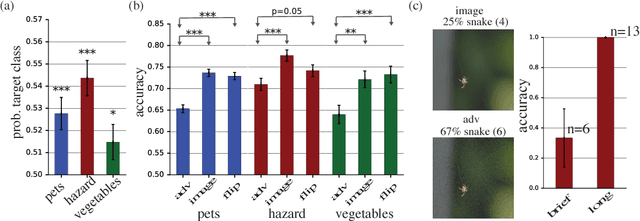
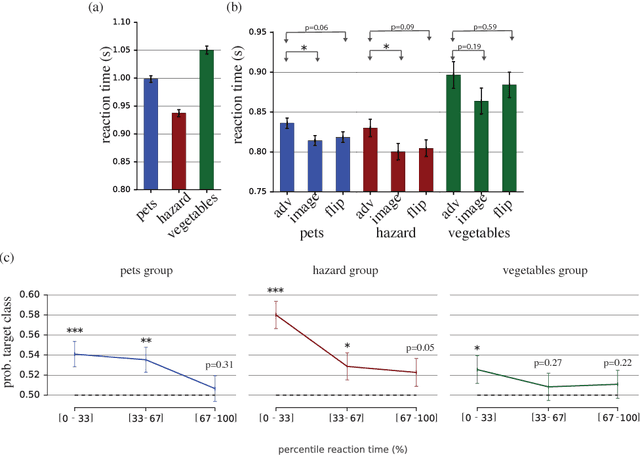
Machine learning models are vulnerable to adversarial examples: small changes to images can cause computer vision models to make mistakes such as identifying a school bus as an ostrich. However, it is still an open question whether humans are prone to similar mistakes. Here, we address this question by leveraging recent techniques that transfer adversarial examples from computer vision models with known parameters and architecture to other models with unknown parameters and architecture, and by matching the initial processing of the human visual system. We find that adversarial examples that strongly transfer across computer vision models influence the classifications made by time-limited human observers.
Depth-based pseudo-metrics between probability distributions
Mar 23, 2021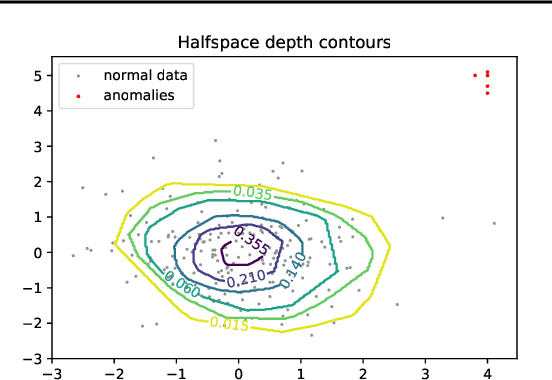
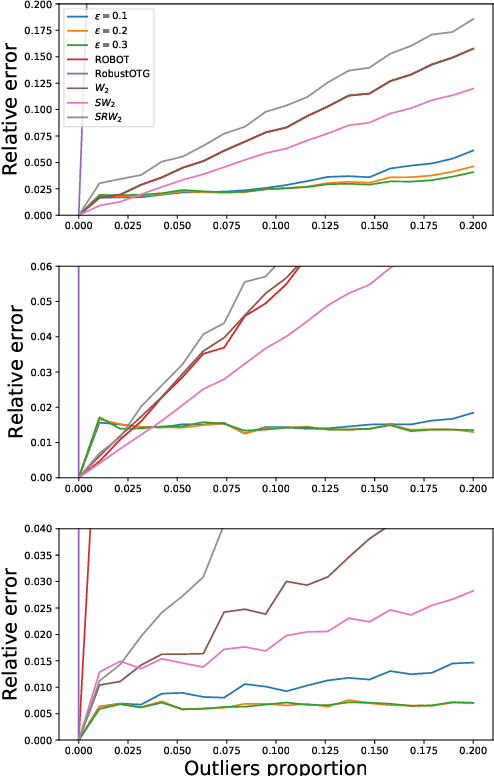
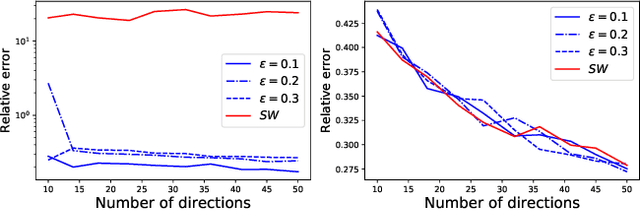
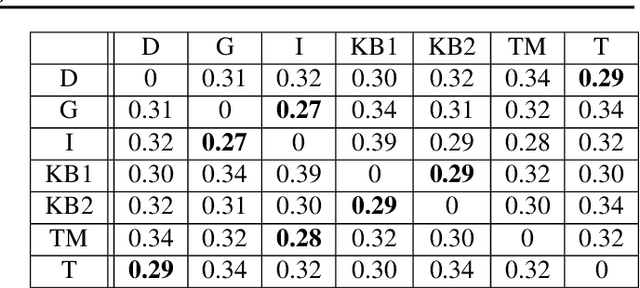
Data depth is a non parametric statistical tool that measures centrality of any element $x\in\mathbb{R}^d$ with respect to (w.r.t.) a probability distribution or a data set. It is a natural median-oriented extension of the cumulative distribution function (cdf) to the multivariate case. Consequently, its upper level sets -- the depth-trimmed regions -- give rise to a definition of multivariate quantiles. In this work, we propose two new pseudo-metrics between continuous probability measures based on data depth and its associated central regions. The first one is constructed as the Lp-distance between data depth w.r.t. each distribution while the second one relies on the Hausdorff distance between their quantile regions. It can further be seen as an original way to extend the one-dimensional formulae of the Wasserstein distance, which involves quantiles and cdfs, to the multivariate space. After discussing the properties of these pseudo-metrics and providing conditions under which they define a distance, we highlight similarities with the Wasserstein distance. Interestingly, the derived non-asymptotic bounds show that in contrast to the Wasserstein distance, the proposed pseudo-metrics do not suffer from the curse of dimensionality. Moreover, based on the support function of a convex body, we propose an efficient approximation possessing linear time complexity w.r.t. the size of the data set and its dimension. The quality of this approximation as well as the performance of the proposed approach are illustrated in experiments. Furthermore, by construction the regions-based pseudo-metric appears to be robust w.r.t. both outliers and heavy tails, a behavior witnessed in the numerical experiments.
Neural Abstractive Text Summarizer for Telugu Language
Jan 18, 2021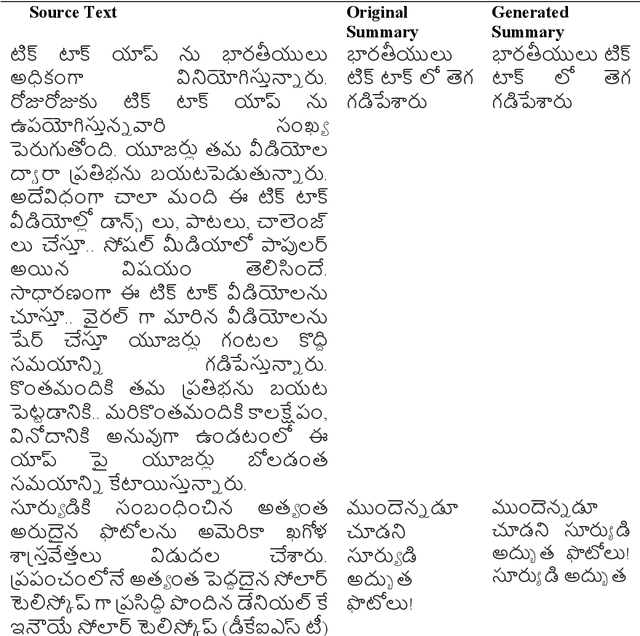
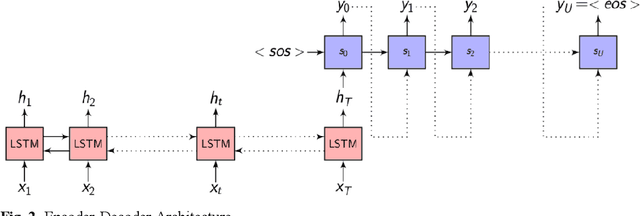
Abstractive Text Summarization is the process of constructing semantically relevant shorter sentences which captures the essence of the overall meaning of the source text. It is actually difficult and very time consuming for humans to summarize manually large documents of text. Much of work in abstractive text summarization is being done in English and almost no significant work has been reported in Telugu abstractive text summarization. So, we would like to propose an abstractive text summarization approach for Telugu language using Deep learning. In this paper we are proposing an abstractive text summarization Deep learning model for Telugu language. The proposed architecture is based on encoder-decoder sequential models with attention mechanism. We have applied this model on manually created dataset to generate a one sentence summary of the source text and have got good results measured qualitatively.
Dynamic Social Media Monitoring for Fast-Evolving Online Discussions
Feb 24, 2021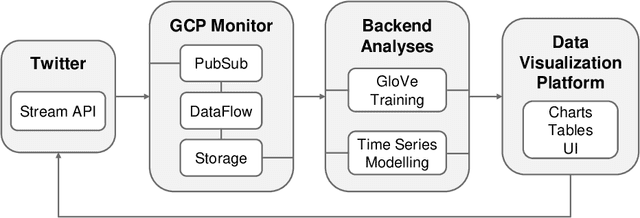
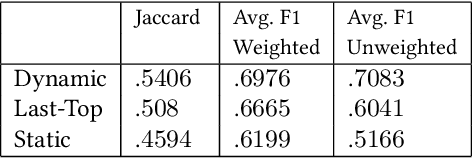
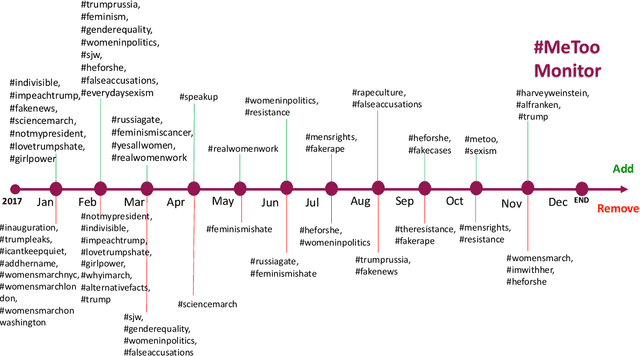
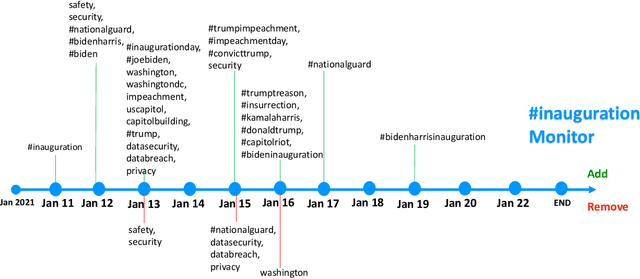
Tracking and collecting fast-evolving online discussions provides vast data for studying social media usage and its role in people's public lives. However, collecting social media data using a static set of keywords fails to satisfy the growing need to monitor dynamic conversations and to study fast-changing topics. We propose a dynamic keyword search method to maximize the coverage of relevant information in fast-evolving online discussions. The method uses word embedding models to represent the semantic relations between keywords and predictive models to forecast the future time series. We also implement a visual user interface to aid in the decision-making process in each round of keyword updates. This allows for both human-assisted tracking and fully-automated data collection. In simulations using historical #MeToo data in 2017, our human-assisted tracking method outperforms the traditional static baseline method significantly, with 37.1% higher F-1 score than traditional static monitors in tracking the top trending keywords. We conduct a contemporary case study to cover dynamic conversations about the recent Presidential Inauguration and to test the dynamic data collection system. Our case studies reflect the effectiveness of our process and also points to the potential challenges in future deployment.
Improving Bi-encoder Document Ranking Models with Two Rankers and Multi-teacher Distillation
Mar 11, 2021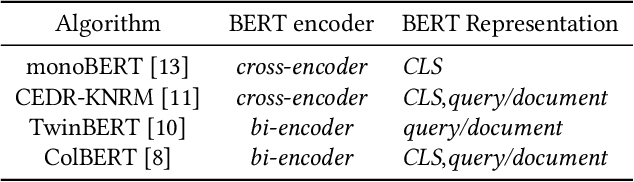
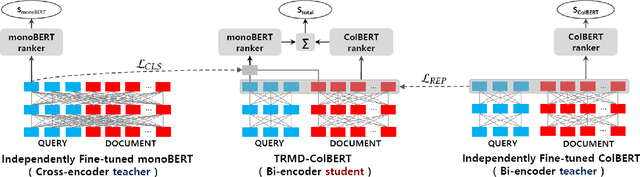
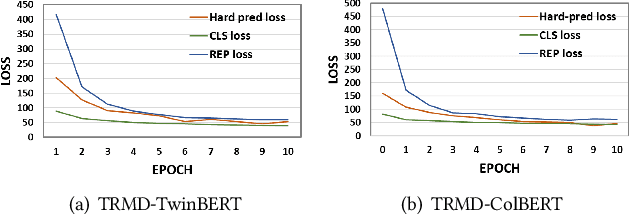
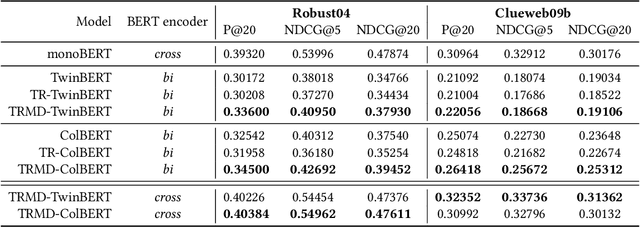
BERT-based Neural Ranking Models (NRMs) can be classified according to how the query and document are encoded through BERT's self-attention layers - bi-encoder versus cross-encoder. Bi-encoder models are highly efficient because all the documents can be pre-processed before the query time, but their performance is inferior compared to cross-encoder models. Both models utilize a ranker that receives BERT representations as the input and generates a relevance score as the output. In this work, we propose a method where multi-teacher distillation is applied to a cross-encoder NRM and a bi-encoder NRM to produce a bi-encoder NRM with two rankers. The resulting student bi-encoder achieves an improved performance by simultaneously learning from a cross-encoder teacher and a bi-encoder teacher and also by combining relevance scores from the two rankers. We call this method TRMD (Two Rankers and Multi-teacher Distillation). In the experiments, TwinBERT and ColBERT are considered as baseline bi-encoders. When monoBERT is used as the cross-encoder teacher, together with either TwinBERT or ColBERT as the bi-encoder teacher, TRMD produces a student bi-encoder that performs better than the corresponding baseline bi-encoder. For P@20, the maximum improvement was 11.4%, and the average improvement was 6.8%. As an additional experiment, we considered producing cross-encoder students with TRMD, and found that it could also improve the cross-encoders.
Out-of-Distribution Detection of Melanoma using Normalizing Flows
Mar 23, 2021
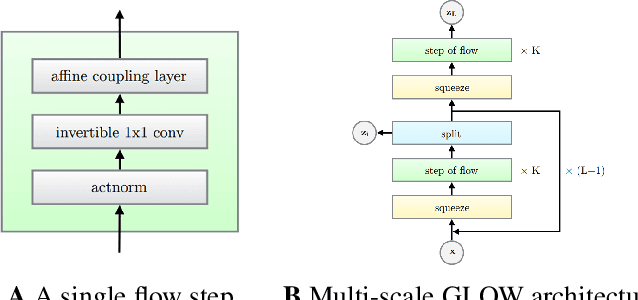
Generative modelling has been a topic at the forefront of machine learning research for a substantial amount of time. With the recent success in the field of machine learning, especially in deep learning, there has been an increased interest in explainable and interpretable machine learning. The ability to model distributions and provide insight in the density estimation and exact data likelihood is an example of such a feature. Normalizing Flows (NFs), a relatively new research field of generative modelling, has received substantial attention since it is able to do exactly this at a relatively low cost whilst enabling competitive generative results. While the generative abilities of NFs are typically explored, we focus on exploring the data distribution modelling for Out-of-Distribution (OOD) detection. Using one of the state-of-the-art NF models, GLOW, we attempt to detect OOD examples in the ISIC dataset. We notice that this model under performs in conform related research. To improve the OOD detection, we explore the masking methods to inhibit co-adaptation of the coupling layers however find no substantial improvement. Furthermore, we utilize Wavelet Flow which uses wavelets that can filter particular frequency components, thus simplifying the modeling process to data-driven conditional wavelet coefficients instead of complete images. This enables us to efficiently model larger resolution images in the hopes that it would capture more relevant features for OOD. The paper that introduced Wavelet Flow mainly focuses on its ability of sampling high resolution images and did not treat OOD detection. We present the results and propose several ideas for improvement such as controlling frequency components, using different wavelets and using other state-of-the-art NF architectures.
Adversarial Attacks and Defenses in Physiological Computing: A Systematic Review
Feb 07, 2021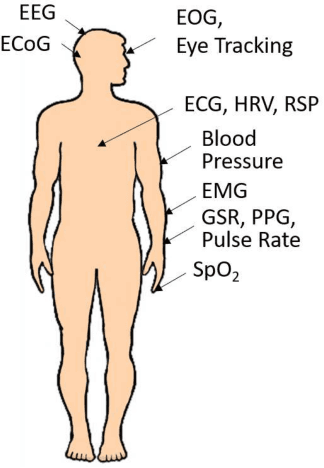
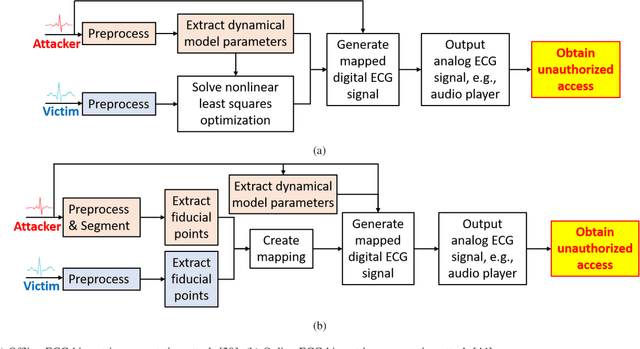
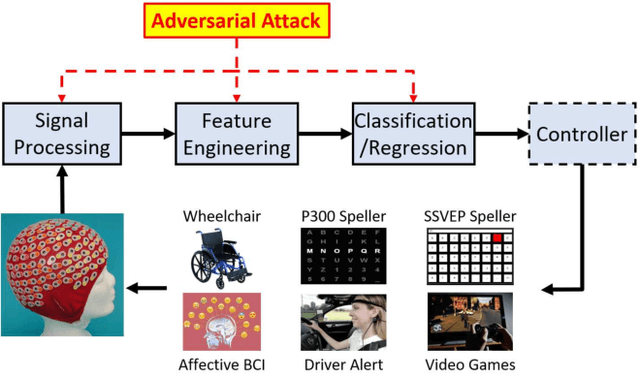
Physiological computing uses human physiological data as system inputs in real time. It includes, or significantly overlaps with, brain-computer interfaces, affective computing, adaptive automation, health informatics, and physiological signal based biometrics. Physiological computing increases the communication bandwidth from the user to the computer, but is also subject to various types of adversarial attacks, in which the attacker deliberately manipulates the training and/or test examples to hijack the machine learning algorithm output, leading to possibly user confusion, frustration, injury, or even death. However, the vulnerability of physiological computing systems has not been paid enough attention to, and there does not exist a comprehensive review on adversarial attacks to it. This paper fills this gap, by providing a systematic review on the main research areas of physiological computing, different types of adversarial attacks and their applications to physiological computing, and the corresponding defense strategies. We hope this review will attract more research interests on the vulnerability of physiological computing systems, and more importantly, defense strategies to make them more secure.
Boosting Low-Resource Biomedical QA via Entity-Aware Masking Strategies
Feb 16, 2021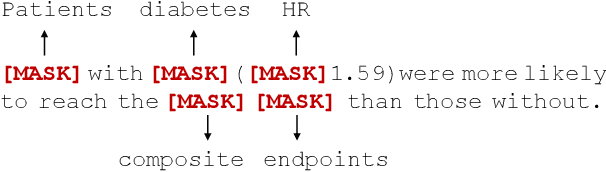
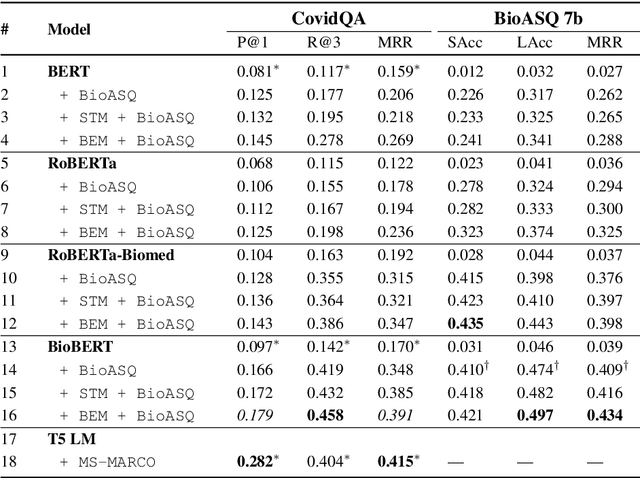
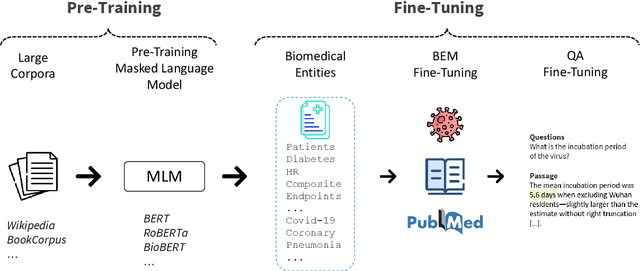

Biomedical question-answering (QA) has gained increased attention for its capability to provide users with high-quality information from a vast scientific literature. Although an increasing number of biomedical QA datasets has been recently made available, those resources are still rather limited and expensive to produce. Transfer learning via pre-trained language models (LMs) has been shown as a promising approach to leverage existing general-purpose knowledge. However, finetuning these large models can be costly and time consuming, often yielding limited benefits when adapting to specific themes of specialised domains, such as the COVID-19 literature. To bootstrap further their domain adaptation, we propose a simple yet unexplored approach, which we call biomedical entity-aware masking (BEM). We encourage masked language models to learn entity-centric knowledge based on the pivotal entities characterizing the domain at hand, and employ those entities to drive the LM fine-tuning. The resulting strategy is a downstream process applicable to a wide variety of masked LMs, not requiring additional memory or components in the neural architectures. Experimental results show performance on par with state-of-the-art models on several biomedical QA datasets.
MotionRNN: A Flexible Model for Video Prediction with Spacetime-Varying Motions
Mar 04, 2021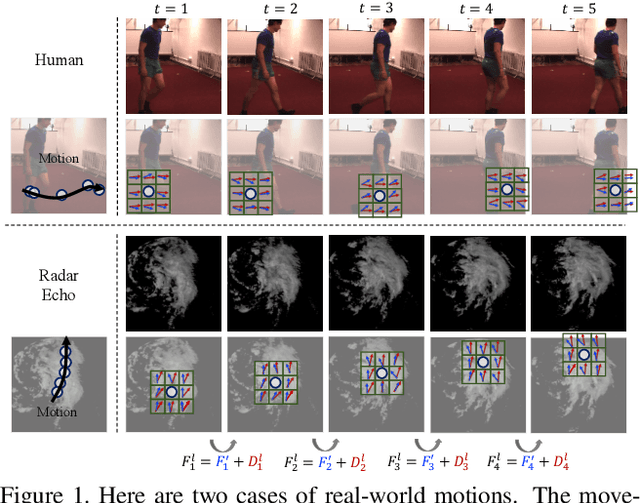
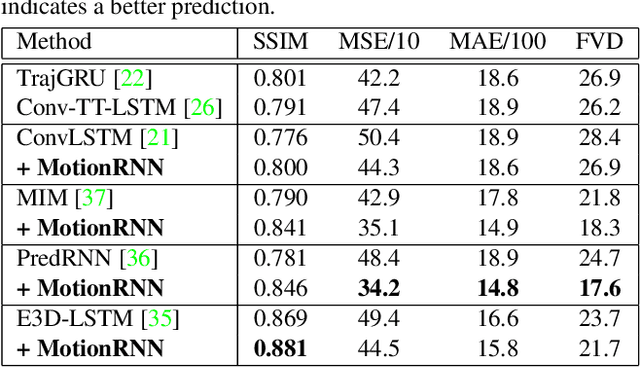
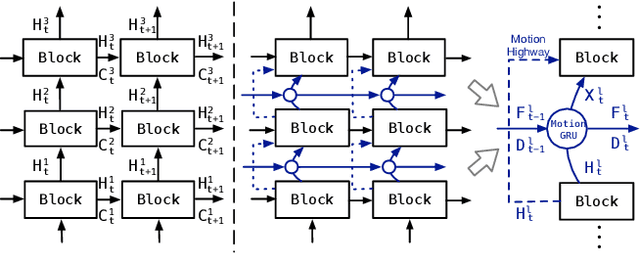
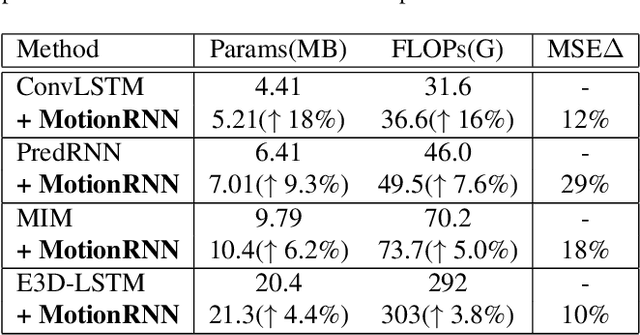
This paper tackles video prediction from a new dimension of predicting spacetime-varying motions that are incessantly changing across both space and time. Prior methods mainly capture the temporal state transitions but overlook the complex spatiotemporal variations of the motion itself, making them difficult to adapt to ever-changing motions. We observe that physical world motions can be decomposed into transient variation and motion trend, while the latter can be regarded as the accumulation of previous motions. Thus, simultaneously capturing the transient variation and the motion trend is the key to make spacetime-varying motions more predictable. Based on these observations, we propose the MotionRNN framework, which can capture the complex variations within motions and adapt to spacetime-varying scenarios. MotionRNN has two main contributions. The first is that we design the MotionGRU unit, which can model the transient variation and motion trend in a unified way. The second is that we apply the MotionGRU to RNN-based predictive models and indicate a new flexible video prediction architecture with a Motion Highway that can significantly improve the ability to predict changeable motions and avoid motion vanishing for stacked multiple-layer predictive models. With high flexibility, this framework can adapt to a series of models for deterministic spatiotemporal prediction. Our MotionRNN can yield significant improvements on three challenging benchmarks for video prediction with spacetime-varying motions.
ESCORT: Ethereum Smart COntRacTs Vulnerability Detection using Deep Neural Network and Transfer Learning
Mar 23, 2021
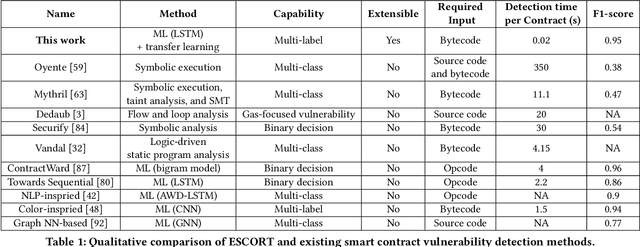
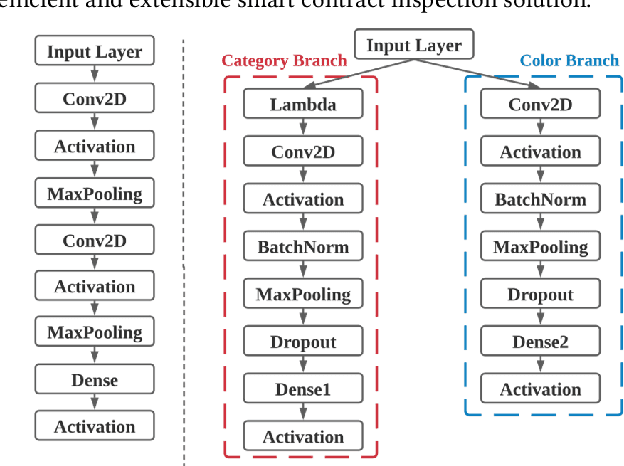
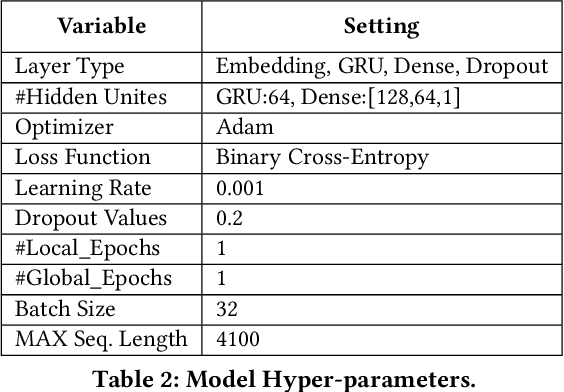
Ethereum smart contracts are automated decentralized applications on the blockchain that describe the terms of the agreement between buyers and sellers, reducing the need for trusted intermediaries and arbitration. However, the deployment of smart contracts introduces new attack vectors into the cryptocurrency systems. In particular, programming flaws in smart contracts can be and have already been exploited to gain enormous financial profits. It is thus an emerging yet crucial issue to detect vulnerabilities of different classes in contracts in an efficient manner. Existing machine learning-based vulnerability detection methods are limited and only inspect whether the smart contract is vulnerable, or train individual classifiers for each specific vulnerability, or demonstrate multi-class vulnerability detection without extensibility consideration. To overcome the scalability and generalization limitations of existing works, we propose ESCORT, the first Deep Neural Network (DNN)-based vulnerability detection framework for Ethereum smart contracts that support lightweight transfer learning on unseen security vulnerabilities, thus is extensible and generalizable. ESCORT leverages a multi-output NN architecture that consists of two parts: (i) A common feature extractor that learns the semantics of the input contract; (ii) Multiple branch structures where each branch learns a specific vulnerability type based on features obtained from the feature extractor. Experimental results show that ESCORT achieves an average F1-score of 95% on six vulnerability types and the detection time is 0.02 seconds per contract. When extended to new vulnerability types, ESCORT yields an average F1-score of 93%. To the best of our knowledge, ESCORT is the first framework that enables transfer learning on new vulnerability types with minimal modification of the DNN model architecture and re-training overhead.