 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evaluating Machine Learning Models for the Fast Identification of Contingency Cases
Aug 21, 2020
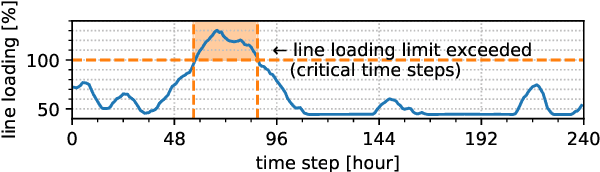
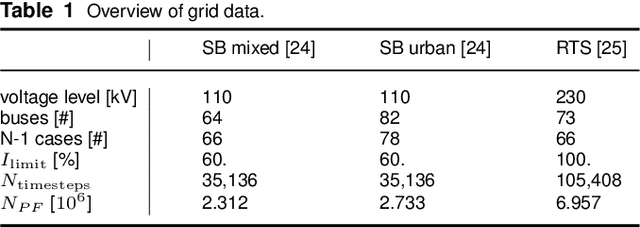
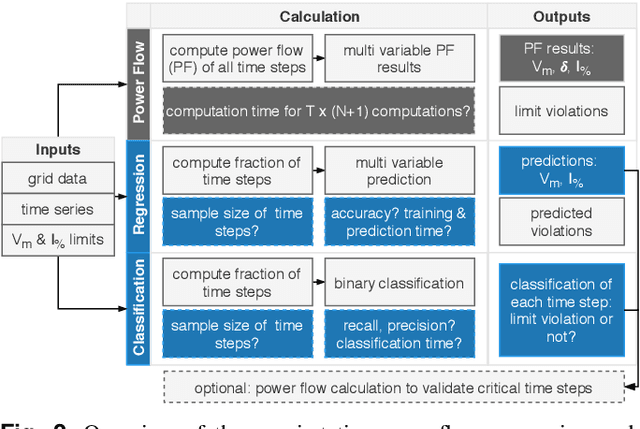
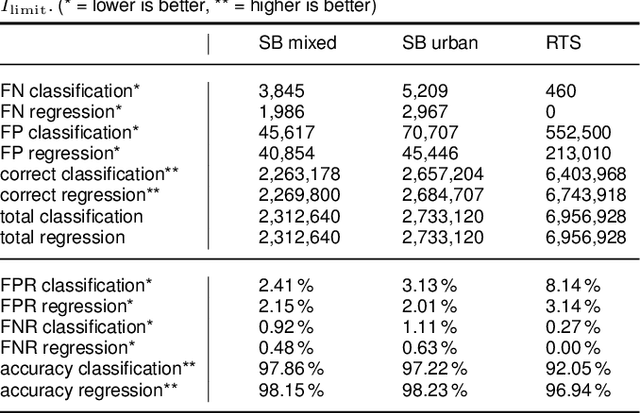
Fast approximations of power flow results are beneficial in power system planning and live operation. In planning, millions of power flow calculations are necessary if multiple years, different control strategies or contingency policies are to be considered. In live operation, grid operators must assess if grid states comply with contingency requirements in a short time. In this paper, we compare regression and classification methods to either predict multi-variable results, e.g. bus voltage magnitudes and line loadings, or binary classifications of time steps to identify critical loading situations. We test the methods on three realistic power systems based on time series in 15 min and 5 min resolution of one year. We compare different machine learning models, such as multilayer perceptrons (MLPs), decision trees, k-nearest neighbours, gradient boosting, and evaluate the required training time and prediction times as well as the prediction errors. We additionally determine the amount of training data needed for each method and show results, including the approximation of untrained curtailment of generation. Regarding the compared methods, we identified the MLPs as most suitable for the task. The MLP-based models can predict critical situations with an accuracy of 97-98 % and a very low number of false negative predictions of 0.0-0.64 %.
Continuous Coordination As a Realistic Scenario for Lifelong Learning
Mar 04, 2021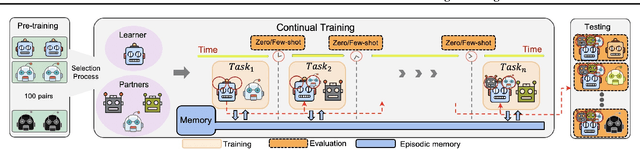
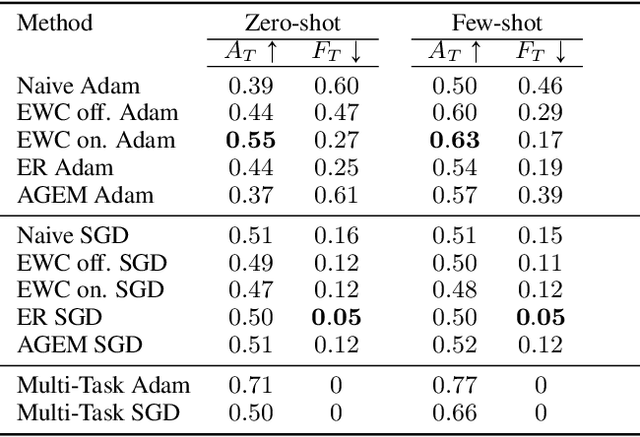
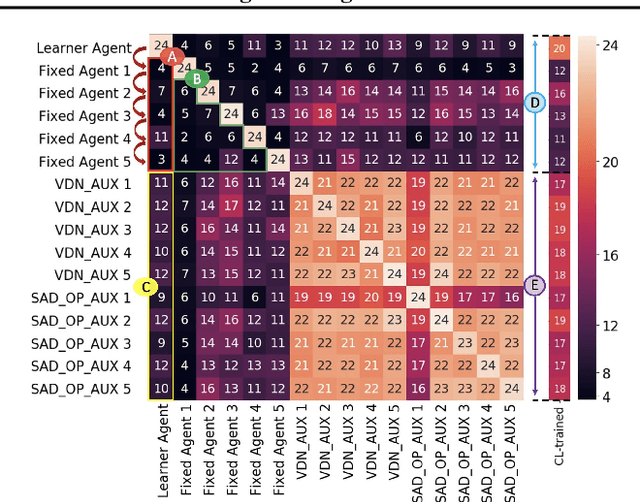

Current deep reinforcement learning (RL) algorithms are still highly task-specific and lack the ability to generalize to new environments. Lifelong learning (LLL), however, aims at solving multiple tasks sequentially by efficiently transferring and using knowledge between tasks. Despite a surge of interest in lifelong RL in recent years, the lack of a realistic testbed makes robust evaluation of LLL algorithms difficult. Multi-agent RL (MARL), on the other hand, can be seen as a natural scenario for lifelong RL due to its inherent non-stationarity, since the agents' policies change over time. In this work, we introduce a multi-agent lifelong learning testbed that supports both zero-shot and few-shot settings. Our setup is based on Hanabi -- a partially-observable, fully cooperative multi-agent game that has been shown to be challenging for zero-shot coordination. Its large strategy space makes it a desirable environment for lifelong RL tasks. We evaluate several recent MARL methods, and benchmark state-of-the-art LLL algorithms in limited memory and computation regimes to shed light on their strengths and weaknesses. This continual learning paradigm also provides us with a pragmatic way of going beyond centralized training which is the most commonly used training protocol in MARL. We empirically show that the agents trained in our setup are able to coordinate well with unseen agents, without any additional assumptions made by previous works.
SLUA: A Super Lightweight Unsupervised Word Alignment Model via Cross-Lingual Contrastive Learning
Feb 08, 2021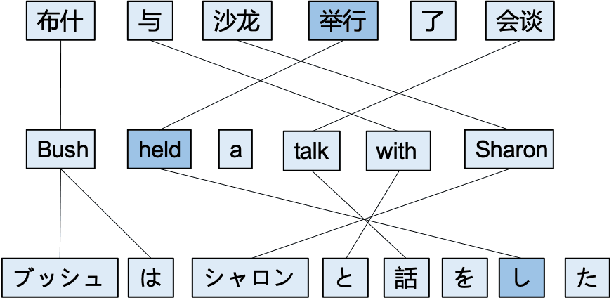

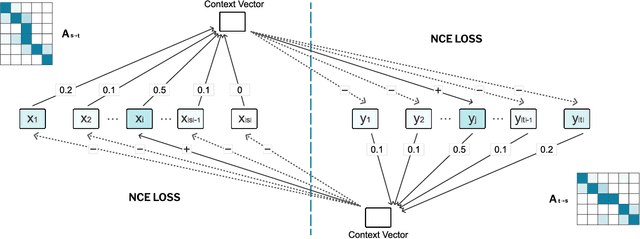
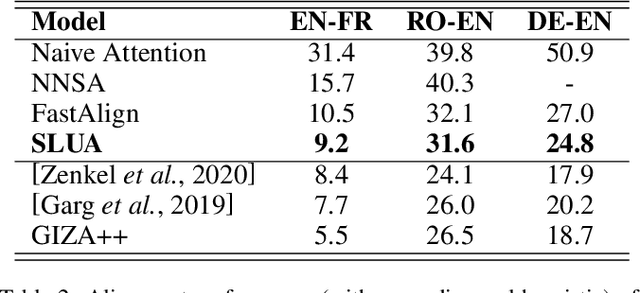
Word alignment is essential for the down-streaming cross-lingual language understanding and generation tasks. Recently, the performance of the neural word alignment models has exceeded that of statistical models. However, they heavily rely on sophisticated translation models. In this study, we propose a super lightweight unsupervised word alignment (SLUA) model, in which bidirectional symmetric attention trained with a contrastive learning objective is introduced, and an agreement loss is employed to bind the attention maps, such that the alignments follow mirror-like symmetry hypothesis. Experimental results on several public benchmarks demonstrate that our model achieves competitive, if not better, performance compared to the state of the art in word alignment while significantly reducing the training and decoding time on average. Further ablation analysis and case studies show the superiority of our proposed SLUA. Notably, we recognize our model as a pioneer attempt to unify bilingual word embedding and word alignments. Encouragingly, our approach achieves 16.4x speedup against GIZA++, and 50x parameter compression} compared with the Transformer-based alignment methods. We will release our code to facilitate the community.
Confidence Calibration with Bounded Error Using Transformations
Feb 25, 2021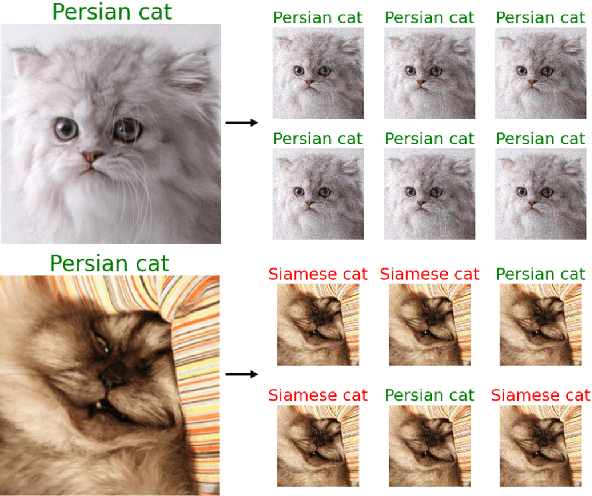
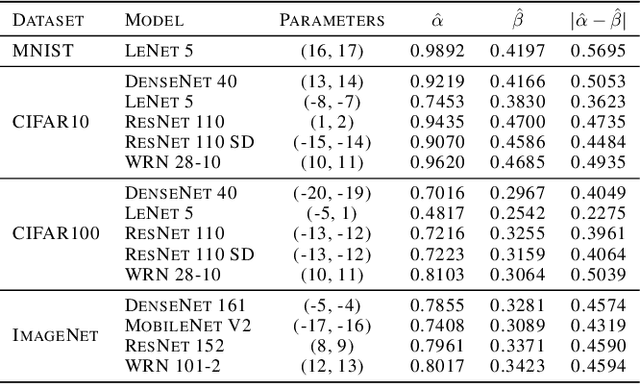

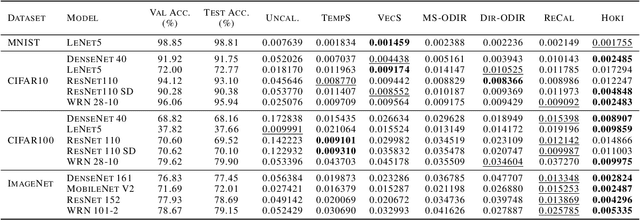
As machine learning techniques become widely adopted in new domains, especially in safety-critical systems such as autonomous vehicles, it is crucial to provide accurate output uncertainty estimation. As a result, many approaches have been proposed to calibrate neural networks to accurately estimate the likelihood of misclassification. However, while these methods achieve low expected calibration error (ECE), few techniques provide theoretical performance guarantees on the calibration error (CE). In this paper, we introduce Hoki, a novel calibration algorithm with a theoretical bound on the CE. Hoki works by transforming the neural network logits and/or inputs and recursively performing calibration leveraging the information from the corresponding change in the output. We provide a PAC-like bounds on CE that is shown to decrease with the number of samples used for calibration, and increase proportionally with ECE and the number of discrete bins used to calculate ECE. We perform experiments on multiple datasets, including ImageNet, and show that the proposed approach generally outperforms state-of-the-art calibration algorithms across multiple datasets and models - providing nearly an order or magnitude improvement in ECE on ImageNet. In addition, Hoki is fast algorithm which is comparable to temperature scaling in terms of learning time.
Benchmarking Perturbation-based Saliency Maps for Explaining Deep Reinforcement Learning Agents
Jan 18, 2021
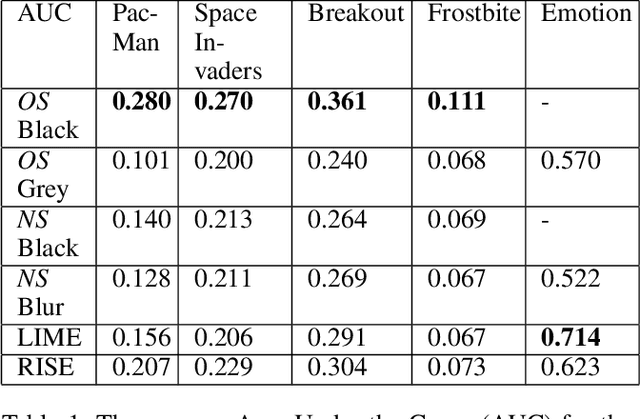

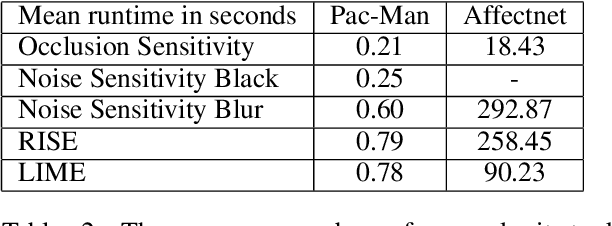
Recent years saw a plethora of work on explaining complex intelligent agents. One example is the development of several algorithms that generate saliency maps which show how much each pixel attributed to the agents' decision. However, most evaluations of such saliency maps focus on image classification tasks. As far as we know, there is no work which thoroughly compares different saliency maps for Deep Reinforcement Learning agents. This paper compares four perturbation-based approaches to create saliency maps for Deep Reinforcement Learning agents trained on four different Atari 2600 games. All four approaches work by perturbing parts of the input and measuring how much this affects the agent's output. The approaches are compared using three computational metrics: dependence on the learned parameters of the agent (sanity checks), faithfulness to the agent's reasoning (input degradation), and run-time.
Robustly Learning Mixtures of $k$ Arbitrary Gaussians
Dec 31, 2020
We give a polynomial-time algorithm for the problem of robustly estimating a mixture of $k$ arbitrary Gaussians in $\mathbb{R}^d$, for any fixed $k$, in the presence of a constant fraction of arbitrary corruptions. This resolves the main open problem in several previous works on algorithmic robust statistics, which addressed the special cases of robustly estimating (a) a single Gaussian, (b) a mixture of TV-distance separated Gaussians, and (c) a uniform mixture of two Gaussians. Our main tools are an efficient \emph{partial clustering} algorithm that relies on the sum-of-squares method, and a novel tensor decomposition algorithm that allows errors in both Frobenius norm and low-rank terms.
Neuromechanics-based Deep Reinforcement Learning of Neurostimulation Control in FES cycling
Mar 04, 2021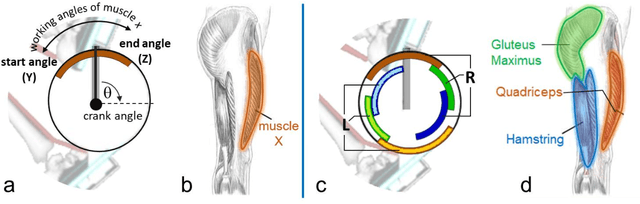
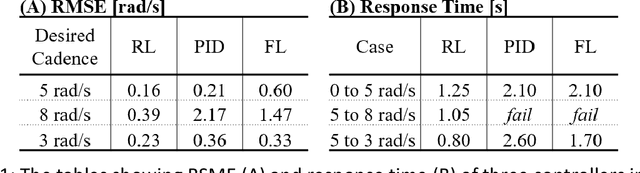
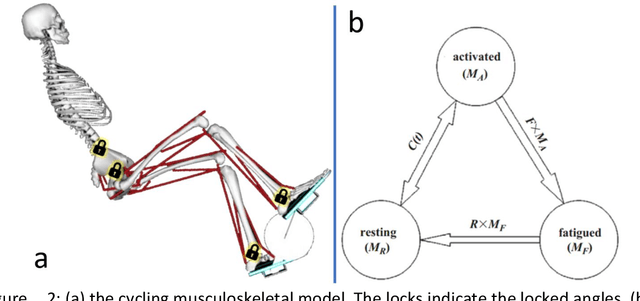
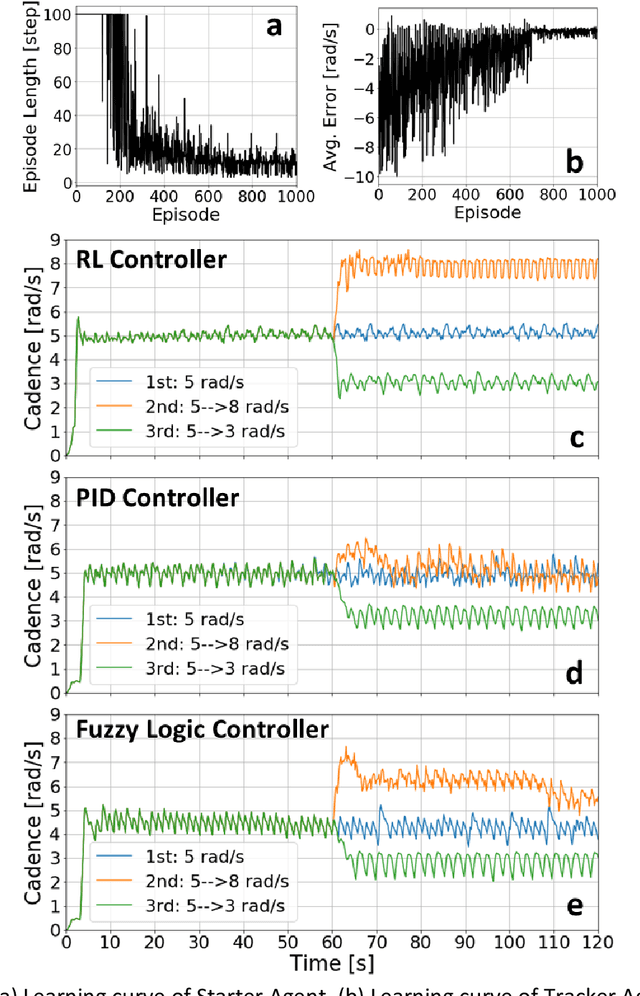
Functional Electrical Stimulation (FES) can restore motion to a paralysed person's muscles. Yet, control stimulating many muscles to restore the practical function of entire limbs is an unsolved problem. Current neurostimulation engineering still relies on 20th Century control approaches and correspondingly shows only modest results that require daily tinkering to operate at all. Here, we present our state of the art Deep Reinforcement Learning (RL) developed for real time adaptive neurostimulation of paralysed legs for FES cycling. Core to our approach is the integration of a personalised neuromechanical component into our reinforcement learning framework that allows us to train the model efficiently without demanding extended training sessions with the patient and working out of the box. Our neuromechanical component includes merges musculoskeletal models of muscle and or tendon function and a multistate model of muscle fatigue, to render the neurostimulation responsive to a paraplegic's cyclist instantaneous muscle capacity. Our RL approach outperforms PID and Fuzzy Logic controllers in accuracy and performance. Crucially, our system learned to stimulate a cyclist's legs from ramping up speed at the start to maintaining a high cadence in steady state racing as the muscles fatigue. A part of our RL neurostimulation system has been successfully deployed at the Cybathlon 2020 bionic Olympics in the FES discipline with our paraplegic cyclist winning the Silver medal among 9 competing teams.
Neuroevolution of a Recurrent Neural Network for Spatial and Working Memory in a Simulated Robotic Environment
Feb 25, 2021
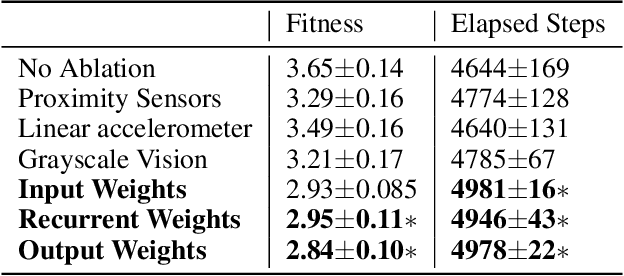

Animals ranging from rats to humans can demonstrate cognitive map capabilities. We evolved weights in a biologically plausible recurrent neural network (RNN) using an evolutionary algorithm to replicate the behavior and neural activity observed in rats during a spatial and working memory task in a triple T-maze. The rat was simulated in the Webots robot simulator and used vision, distance and accelerometer sensors to navigate a virtual maze. After evolving weights from sensory inputs to the RNN, within the RNN, and from the RNN to the robot's motors, the Webots agent successfully navigated the space to reach all four reward arms with minimal repeats before time-out. Our current findings suggest that it is the RNN dynamics that are key to performance, and that performance is not dependent on any one sensory type, which suggests that neurons in the RNN are performing mixed selectivity and conjunctive coding. Moreover, the RNN activity resembles spatial information and trajectory-dependent coding observed in the hippocampus. Collectively, the evolved RNN exhibits navigation skills, spatial memory, and working memory. Our method demonstrates how the dynamic activity in evolved RNNs can capture interesting and complex cognitive behavior and may be used to create RNN controllers for robotic applications.
A Multi-Resolution Frontier-Based Planner for Autonomous 3D Exploration
Nov 04, 2020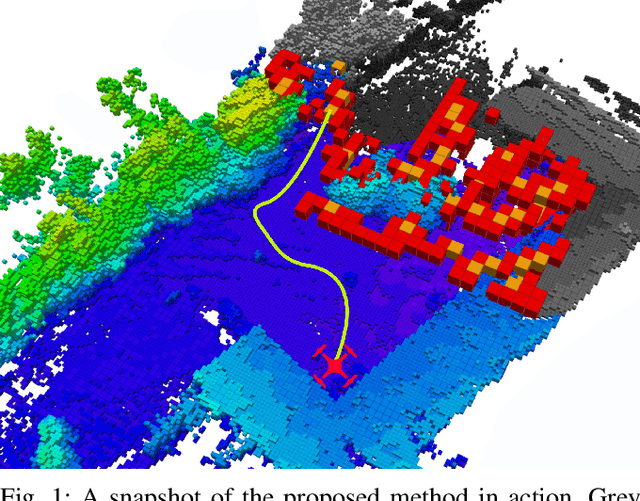
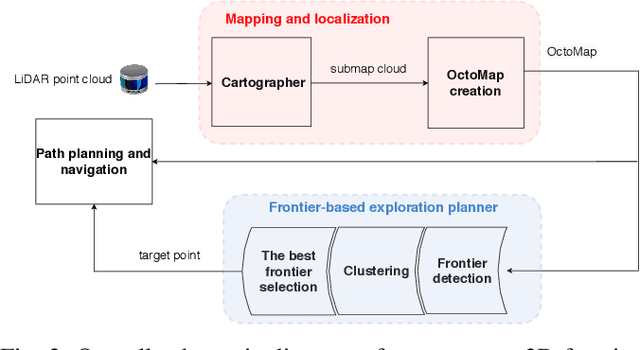
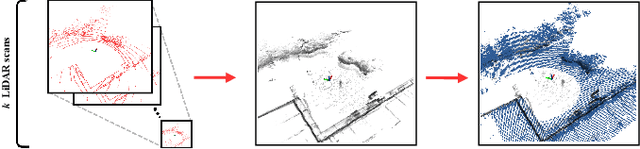
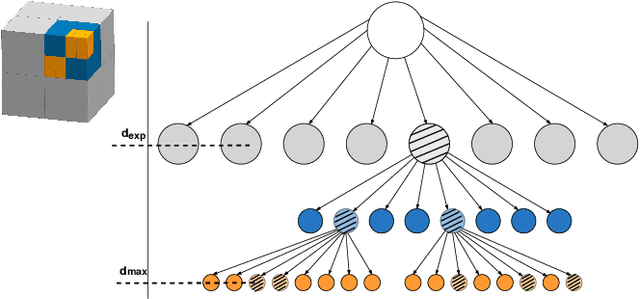
In this paper we propose a planner for 3D exploration that is suitable for applications using state-of-the-art 3D sensors such as lidars, which produce large point clouds with each scan. The planner is based on the detection of a frontier - a boundary between the explored and unknown part of the environment - and consists of the algorithm for detecting frontier points, followed by clustering of frontier points and selecting the best frontier point to be explored. Compared to existing frontier-based approaches, the planner is more scalable, i.e. it requires less time for the same data set size while ensuring similar exploration time. Performance is achieved by not relying on data obtained directly from the 3D sensor, but on data obtained by a mapping algorithm. In order to cluster the frontier points, we use the properties of the Octree environment representation, which allows easy analysis with different resolutions. The planner is tested in the simulation environment and in an outdoor test area with a UAV equipped with a lidar sensor. The results show the advantages of the approach.
Depth-based pseudo-metrics between probability distributions
Mar 23, 2021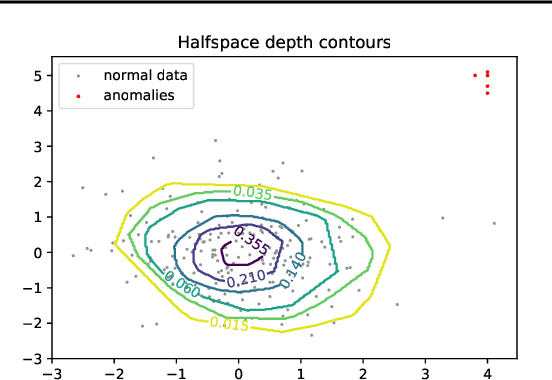
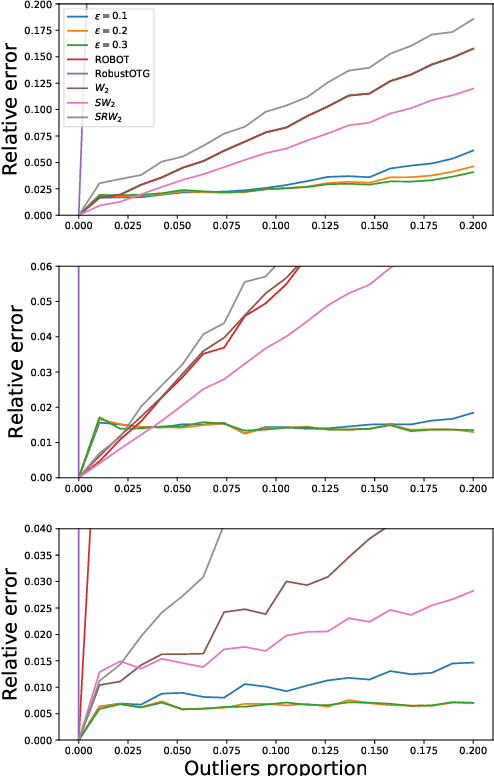
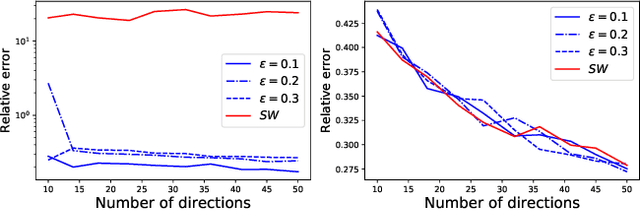
Data depth is a non parametric statistical tool that measures centrality of any element $x\in\mathbb{R}^d$ with respect to (w.r.t.) a probability distribution or a data set. It is a natural median-oriented extension of the cumulative distribution function (cdf) to the multivariate case. Consequently, its upper level sets -- the depth-trimmed regions -- give rise to a definition of multivariate quantiles. In this work, we propose two new pseudo-metrics between continuous probability measures based on data depth and its associated central regions. The first one is constructed as the Lp-distance between data depth w.r.t. each distribution while the second one relies on the Hausdorff distance between their quantile regions. It can further be seen as an original way to extend the one-dimensional formulae of the Wasserstein distance, which involves quantiles and cdfs, to the multivariate space. After discussing the properties of these pseudo-metrics and providing conditions under which they define a distance, we highlight similarities with the Wasserstein distance. Interestingly, the derived non-asymptotic bounds show that in contrast to the Wasserstein distance, the proposed pseudo-metrics do not suffer from the curse of dimensionality. Moreover, based on the support function of a convex body, we propose an efficient approximation possessing linear time complexity w.r.t. the size of the data set and its dimension. The quality of this approximation as well as the performance of the proposed approach are illustrated in experiments. Furthermore, by construction the regions-based pseudo-metric appears to be robust w.r.t. both outliers and heavy tails, a behavior witnessed in the numerical experiments.