 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
End-to-End Egospheric Spatial Memory
Feb 17, 2021
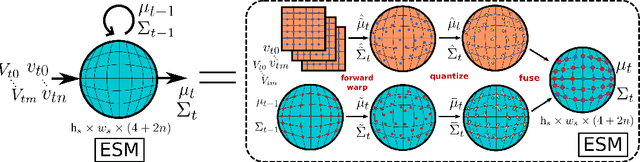
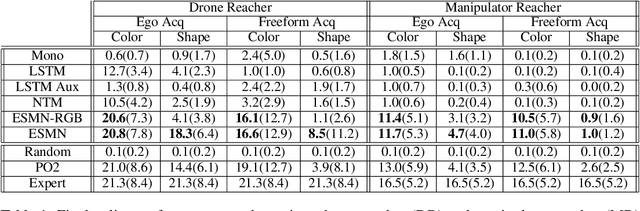
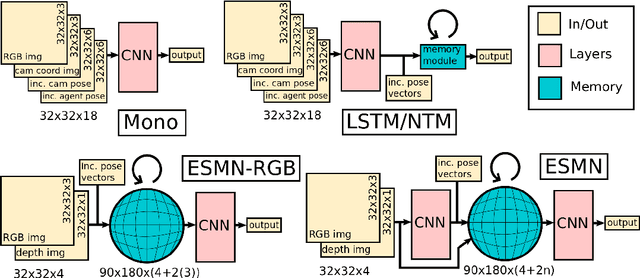
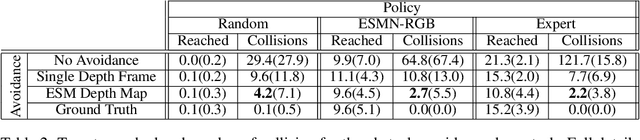
Spatial memory, or the ability to remember and recall specific locations and objects, is central to autonomous agents' ability to carry out tasks in real environments. However, most existing artificial memory modules are not very adept at storing spatial information. We propose a parameter-free module, Egospheric Spatial Memory (ESM), which encodes the memory in an ego-sphere around the agent, enabling expressive 3D representations. ESM can be trained end-to-end via either imitation or reinforcement learning, and improves both training efficiency and final performance against other memory baselines on both drone and manipulator visuomotor control tasks. The explicit egocentric geometry also enables us to seamlessly combine the learned controller with other non-learned modalities, such as local obstacle avoidance. We further show applications to semantic segmentation on the ScanNet dataset, where ESM naturally combines image-level and map-level inference modalities. Through our broad set of experiments, we show that ESM provides a general computation graph for embodied spatial reasoning, and the module forms a bridge between real-time mapping systems and differentiable memory architectures. Implementation at: https://github.com/ivy-dl/memory.
A Weakly Supervised Approach for Classifying Stance in Twitter Replies
Mar 12, 2021
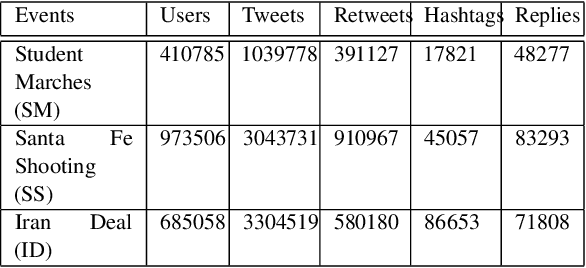
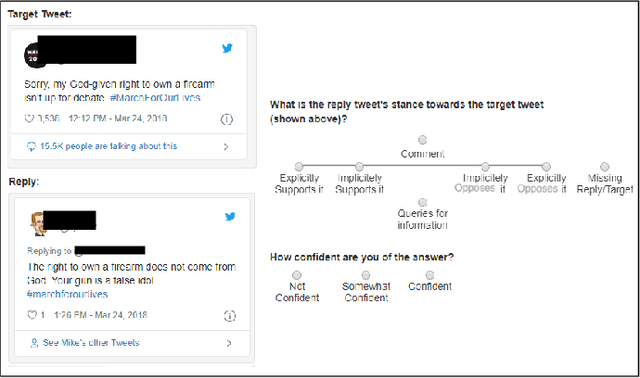
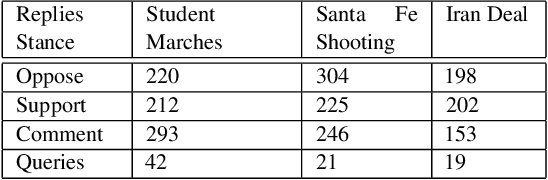
Conversations on social media (SM) are increasingly being used to investigate social issues on the web, such as online harassment and rumor spread. For such issues, a common thread of research uses adversarial reactions, e.g., replies pointing out factual inaccuracies in rumors. Though adversarial reactions are prevalent in online conversations, inferring those adverse views (or stance) from the text in replies is difficult and requires complex natural language processing (NLP) models. Moreover, conventional NLP models for stance mining need labeled data for supervised learning. Getting labeled conversations can itself be challenging as conversations can be on any topic, and topics change over time. These challenges make learning the stance a difficult NLP problem. In this research, we first create a new stance dataset comprised of three different topics by labeling both users' opinions on the topics (as in pro/con) and users' stance while replying to others' posts (as in favor/oppose). As we find limitations with supervised approaches, we propose a weakly-supervised approach to predict the stance in Twitter replies. Our novel method allows using a smaller number of hashtags to generate weak labels for Twitter replies. Compared to supervised learning, our method improves the mean F1-macro by 8\% on the hand-labeled dataset without using any hand-labeled examples in the training set. We further show the applicability of our proposed method on COVID 19 related conversations on Twitter.
Image Compression with Encoder-Decoder Matched Semantic Segmentation
Jan 30, 2021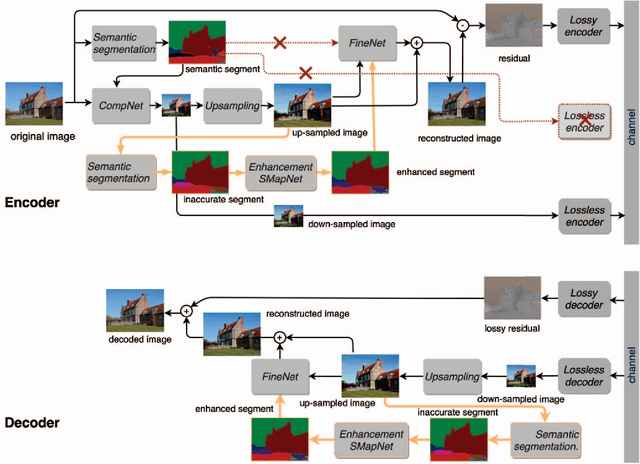

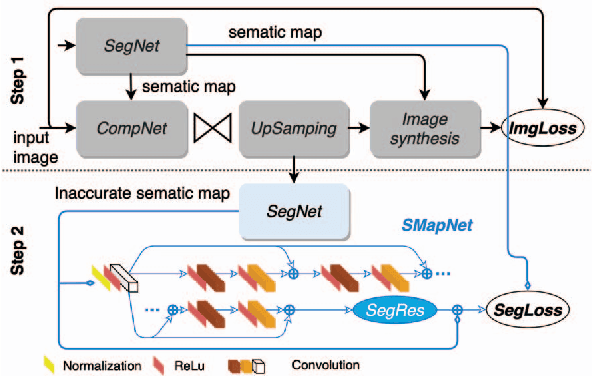
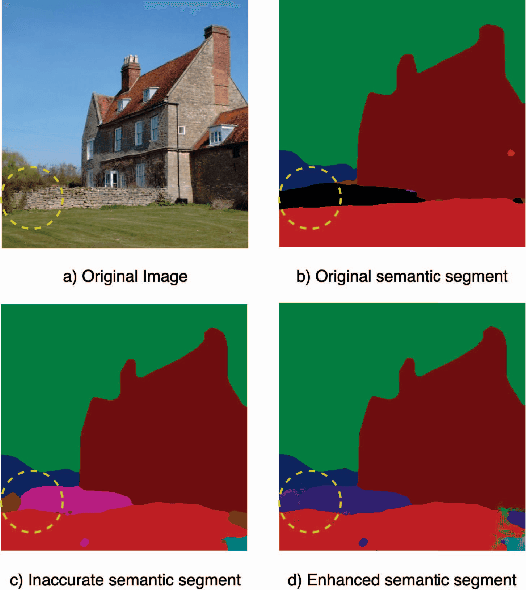
In recent years, layered image compression is demonstrated to be a promising direction, which encodes a compact representation of the input image and apply an up-sampling network to reconstruct the image. To further improve the quality of the reconstructed image, some works transmit the semantic segment together with the compressed image data. Consequently, the compression ratio is also decreased because extra bits are required for transmitting the semantic segment. To solve this problem, we propose a new layered image compression framework with encoder-decoder matched semantic segmentation (EDMS). And then, followed by the semantic segmentation, a special convolution neural network is used to enhance the inaccurate semantic segment. As a result, the accurate semantic segment can be obtained in the decoder without requiring extra bits. The experimental results show that the proposed EDMS framework can get up to 35.31% BD-rate reduction over the HEVC-based (BPG) codec, 5% bitrate, and 24% encoding time saving compare to the state-of-the-art semantic-based image codec.
BW-EDA-EEND: Streaming End-to-End Neural Speaker Diarization for a Variable Number of Speakers
Nov 05, 2020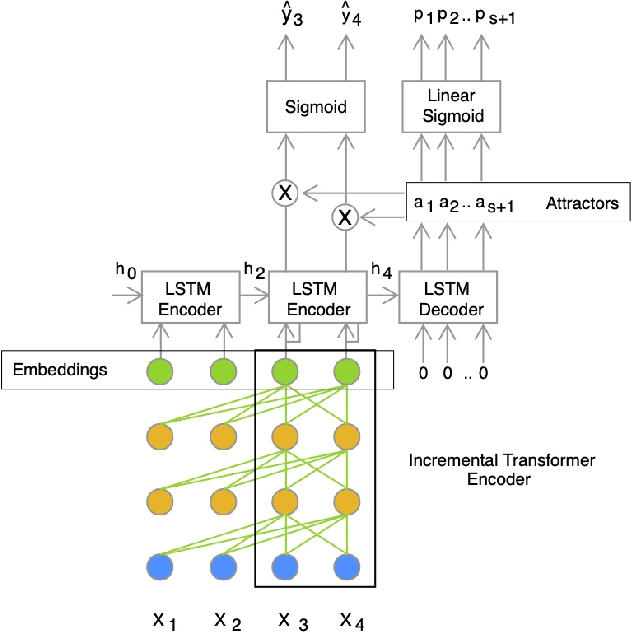
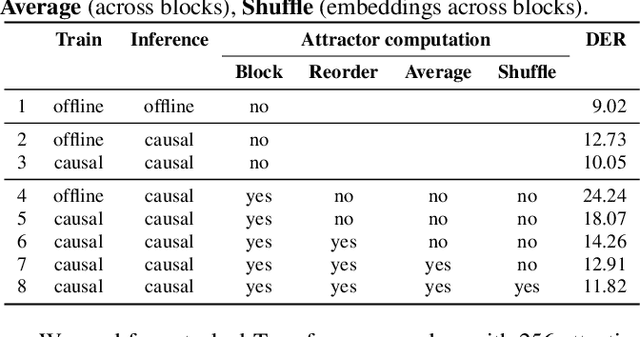
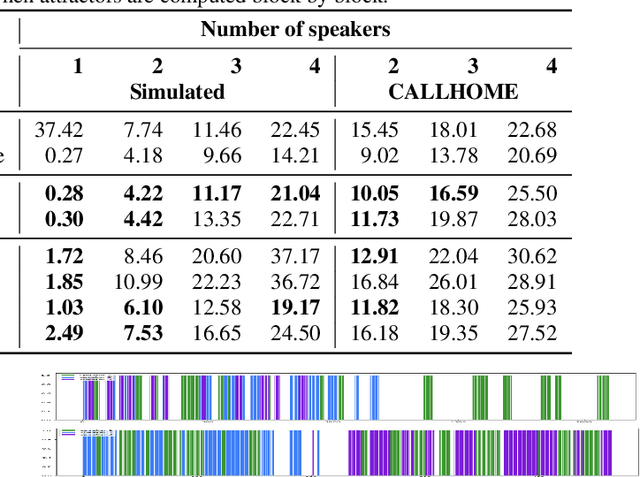
We present a novel online end-to-end neural diarization system, BW-EDA-EEND, that processes data incrementally for a variable number of speakers. The system is based on the EDA architecture of Horiguchi et al., but utilizes the incremental Transformer encoder, attending only to its left contexts and using block-level recurrence in the hidden states to carry information from block to block, making the algorithm complexity linear in time. We propose two variants of it. For unlimited-latency BW-EDA-EEND, which processes inputs in linear time, we show only moderate degradation for up to two speakers using a context size of 10 seconds compared to offline EDA-EEND. With more than two speakers, the accuracy gap between online and offline grows, but it still outperforms a baseline offline clustering diarization system for one to four speakers with unlimited context size, and shows comparable accuracy with context size of 10 seconds. For limited-latency BW-EDA-EEND, which produces diarization outputs block-by-block as audio arrives, we show accuracy comparable to the offline clustering-based system.
The Unsupervised Method of Vessel Movement Trajectory Prediction
Jul 28, 2020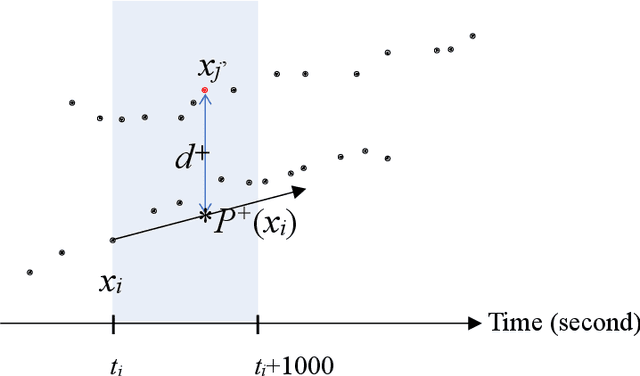

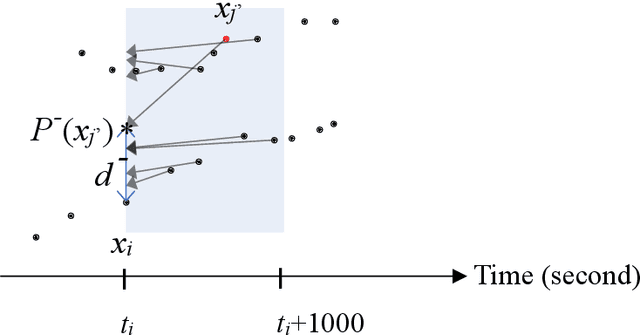

In real-world application scenarios, it is crucial for marine navigators and security analysts to predict vessel movement trajectories at sea based on the Automated Identification System (AIS) data in a given time span. This article presents an unsupervised method of ship movement trajectory prediction which represents the data in a three-dimensional space which consists of time difference between points, the scaled error distance between the tested and its predicted forward and backward locations, and the space-time angle. The representation feature space reduces the search scope for the next point to a collection of candidates which fit the local path prediction well, and therefore improve the accuracy. Unlike most statistical learning or deep learning methods, the proposed clustering-based trajectory reconstruction method does not require computationally expensive model training. This makes real-time reliable and accurate prediction feasible without using a training set. Our results show that the most prediction trajectories accurately consist of the true vessel paths.
Wake Word Detection with Streaming Transformers
Feb 08, 2021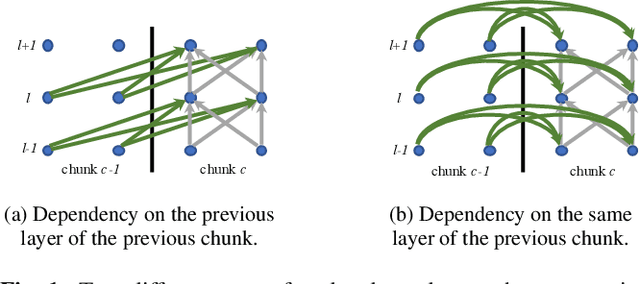
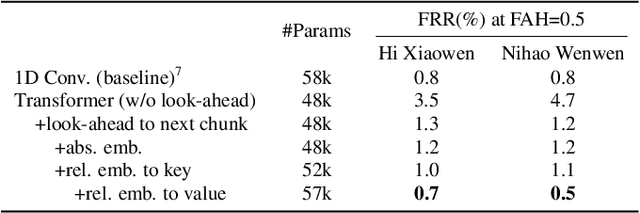
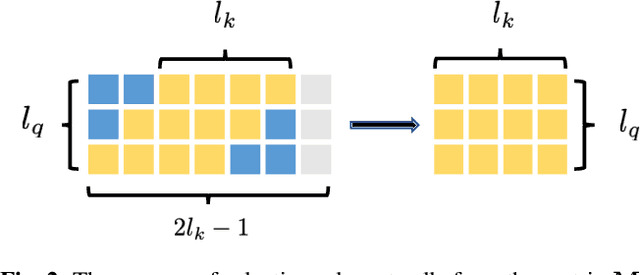
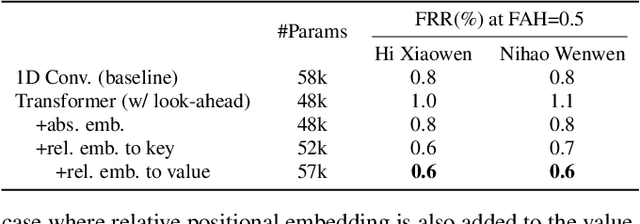
Modern wake word detection systems usually rely on neural networks for acoustic modeling. Transformers has recently shown superior performance over LSTM and convolutional networks in various sequence modeling tasks with their better temporal modeling power. However it is not clear whether this advantage still holds for short-range temporal modeling like wake word detection. Besides, the vanilla Transformer is not directly applicable to the task due to its non-streaming nature and the quadratic time and space complexity. In this paper we explore the performance of several variants of chunk-wise streaming Transformers tailored for wake word detection in a recently proposed LF-MMI system, including looking-ahead to the next chunk, gradient stopping, different positional embedding methods and adding same-layer dependency between chunks. Our experiments on the Mobvoi wake word dataset demonstrate that our proposed Transformer model outperforms the baseline convolution network by 25% on average in false rejection rate at the same false alarm rate with a comparable model size, while still maintaining linear complexity w.r.t. the sequence length.
Training Aware Sigmoidal Optimizer
Feb 17, 2021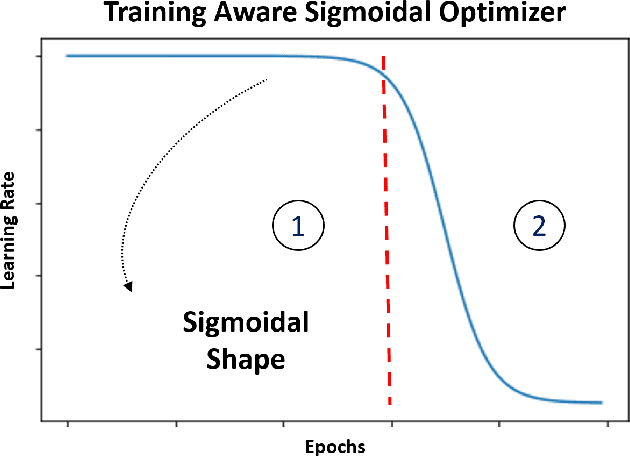

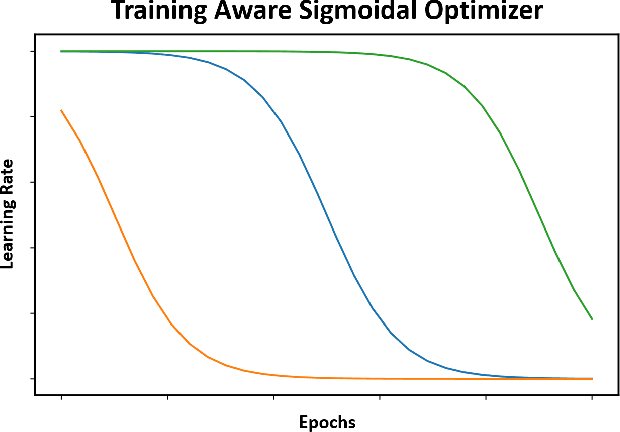
Proper optimization of deep neural networks is an open research question since an optimal procedure to change the learning rate throughout training is still unknown. Manually defining a learning rate schedule involves troublesome time-consuming try and error procedures to determine hyperparameters such as learning rate decay epochs and learning rate decay rates. Although adaptive learning rate optimizers automatize this process, recent studies suggest they may produce overffiting and reduce performance when compared to fine-tuned learning rate schedules. Considering that deep neural networks loss functions present landscapes with much more saddle points than local minima, we proposed the Training Aware Sigmoidal Optimizer (TASO), which consists of a two-phases automated learning rate schedule. The first phase uses a high learning rate to fast traverse the numerous saddle point, while the second phase uses low learning rate to slowly approach the center of the local minimum previously found. We compared the proposed approach with commonly used adaptive learning rate schedules such as Adam, RMSProp, and Adagrad. Our experiments showed that TASO outperformed all competing methods in both optimal (i.e., performing hyperparameter validation) and suboptimal (i.e., using default hyperparameters) scenarios.
TELESTO: A Graph Neural Network Model for Anomaly Classification in Cloud Services
Feb 25, 2021
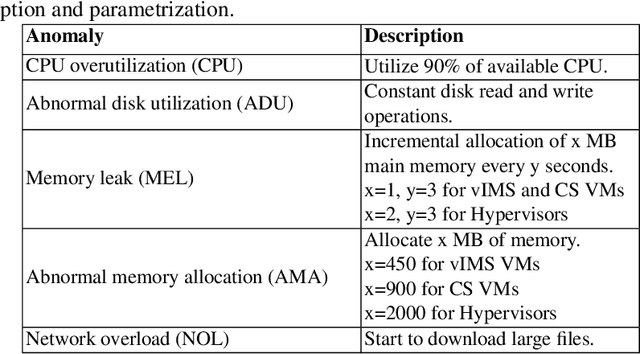
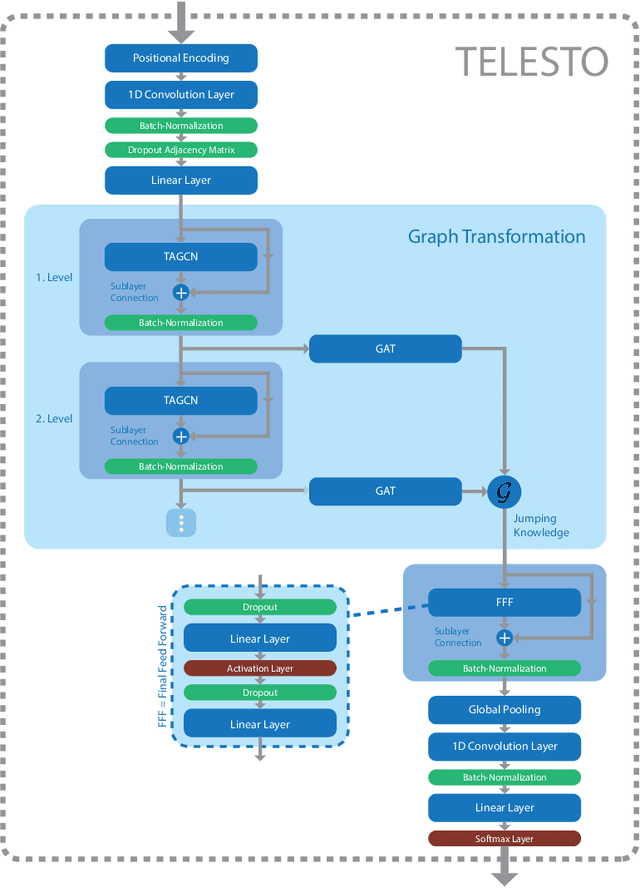

Deployment, operation and maintenance of large IT systems becomes increasingly complex and puts human experts under extreme stress when problems occur. Therefore, utilization of machine learning (ML) and artificial intelligence (AI) is applied on IT system operation and maintenance - summarized in the term AIOps. One specific direction aims at the recognition of re-occurring anomaly types to enable remediation automation. However, due to IT system specific properties, especially their frequent changes (e.g. software updates, reconfiguration or hardware modernization), recognition of reoccurring anomaly types is challenging. Current methods mainly assume a static dimensionality of provided data. We propose a method that is invariant to dimensionality changes of given data. Resource metric data such as CPU utilization, allocated memory and others are modelled as multivariate time series. The extraction of temporal and spatial features together with the subsequent anomaly classification is realized by utilizing TELESTO, our novel graph convolutional neural network (GCNN) architecture. The experimental evaluation is conducted in a real-world cloud testbed deployment that is hosting two applications. Classification results of injected anomalies on a cassandra database node show that TELESTO outperforms the alternative GCNNs and achieves an overall classification accuracy of 85.1%. Classification results for the other nodes show accuracy values between 85% and 60%.
Enabling Binary Neural Network Training on the Edge
Feb 08, 2021
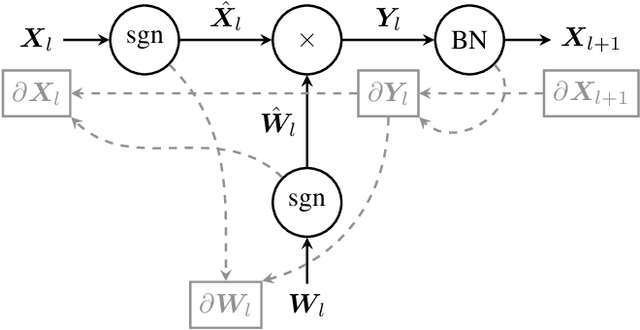
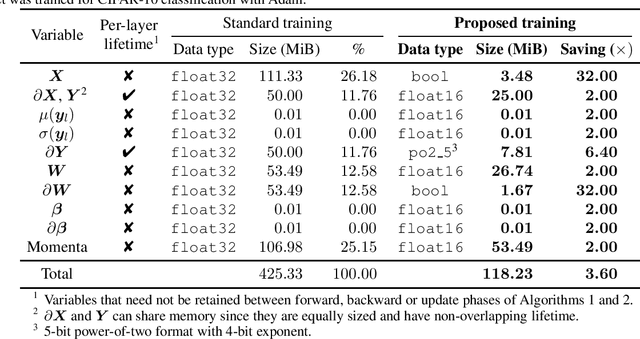
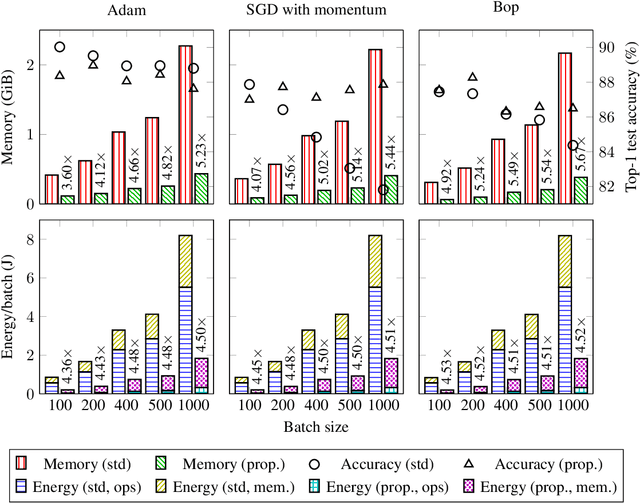
The ever-growing computational demands of increasingly complex machine learning models frequently necessitate the use of powerful cloud-based infrastructure for their training. Binary neural networks are known to be promising candidates for on-device inference due to their extreme compute and memory savings over higher-precision alternatives. In this paper, we demonstrate that they are also strongly robust to gradient quantization, thereby making the training of modern models on the edge a practical reality. We introduce a low-cost binary neural network training strategy exhibiting sizable memory footprint reductions and energy savings vs Courbariaux & Bengio's standard approach. Against the latter, we see coincident memory requirement and energy consumption drops of 2--6$\times$, while reaching similar test accuracy in comparable time, across a range of small-scale models trained to classify popular datasets. We also showcase ImageNet training of ResNetE-18, achieving a 3.12$\times$ memory reduction over the aforementioned standard. Such savings will allow for unnecessary cloud offloading to be avoided, reducing latency, increasing energy efficiency and safeguarding privacy.
Performance Dependency of LSTM and NAR Beamformers With Respect to Sensor Array Properties in V2I Scenario
Feb 17, 2021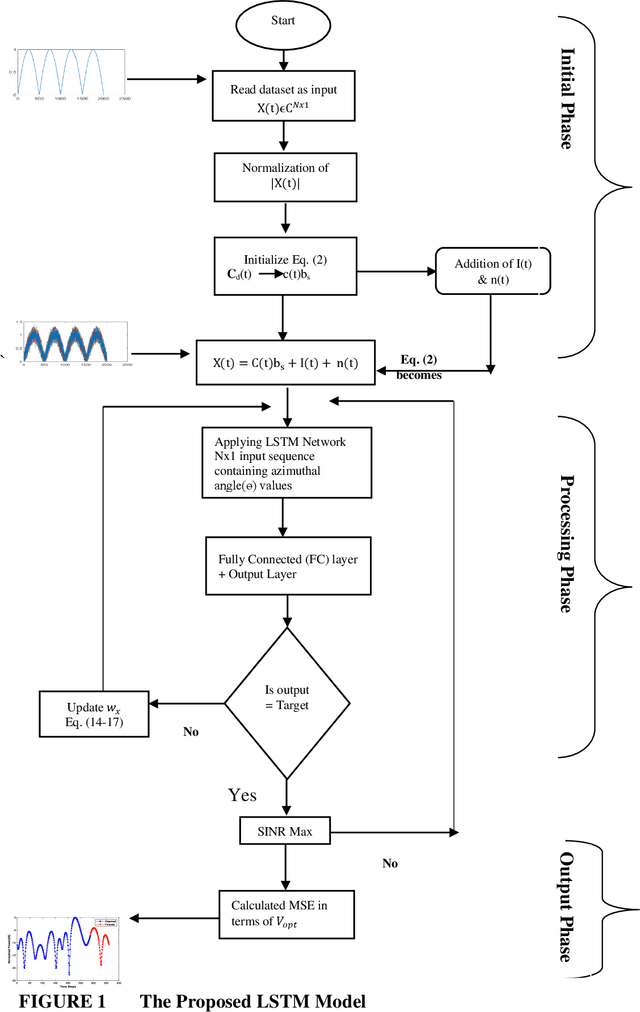
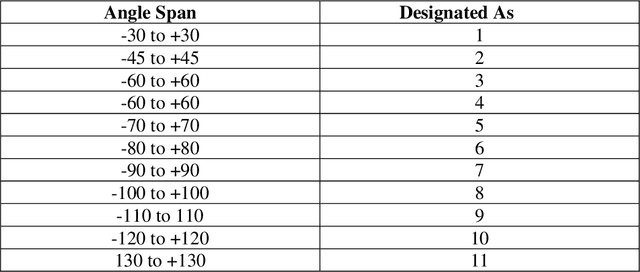
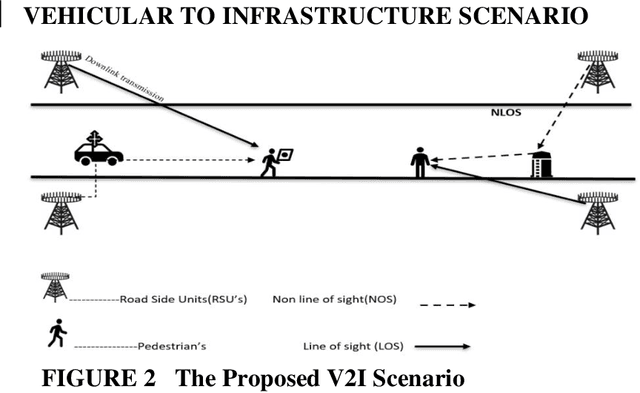
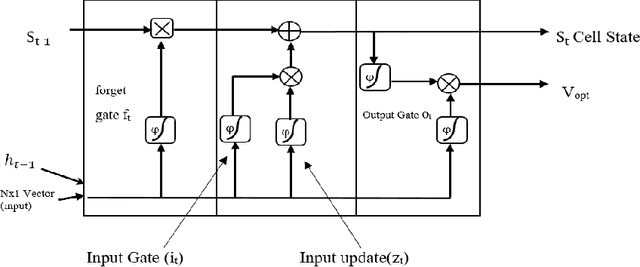
Prediction and nullifying the interference is a challenging problem in vehicle to infrastructure scenarios . The implementation of practical V2I network is limited because of inevitability of interference due to random nature of the wireless channel. The interference introduces angle ambiguity between the road side units mounted base station and user equipment. This paper proposes an adaptive beamforming technique for mitigation of interference in V2I networks, especially in multiuser environment. In this work , Long short term based (LSTM) based deep learning and non linear auto regresive technique based regressor have been employed to predict the angles between the road side units and user equipment .Advance prediction of transmit and receive signals enables reliable vehicle to infrastructure communication. Instead of predicting the beamforming matrix directly, we predict the main features using LSTM for learning dependencies in the input time series ,where complex variables were taken as input states and final beamformed signal was the output. simulation results have confirmed that the proposed LSTM model achieves comparable performance in terms of system throughput when compared with the non linear auto regressive method implemented as an artificial neural network.