 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ProLab: perceptually uniform projective colour coordinate system
Jan 11, 2021
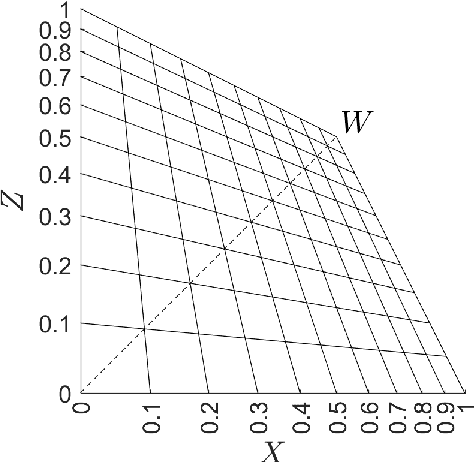
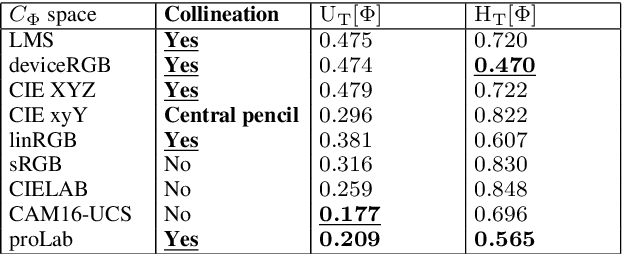
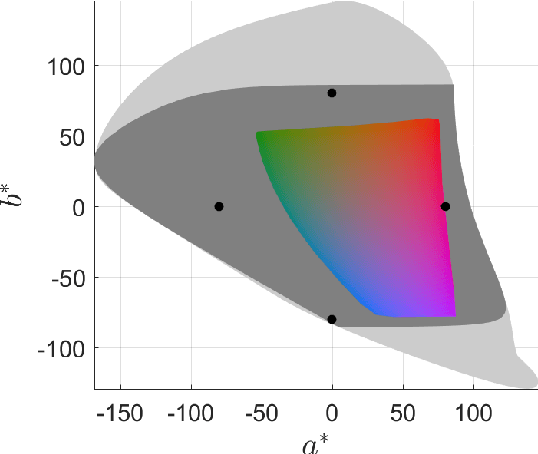

In this work, we propose proLab: a new colour coordinate system derived as a 3D projective transformation of CIE XYZ. We show that proLab is far ahead of the widely used CIELAB coordinate system (though inferior to the modern CAM16-UCS) according to perceptual uniformity evaluated by the STRESS metric in reference to the CIEDE2000 colour difference formula. At the same time, angular errors of chromaticity estimation that are standard for linear colour spaces can also be used in proLab since projective transformations preserve the linearity of manifolds. Unlike in linear spaces, angular errors for different hues are normalized according to human colour discrimination thresholds within proLab. We also demonstrate that shot noise in proLab is more homoscedastic than in CAM16-UCS or other standard colour spaces. This makes proLab a convenient coordinate system in which to perform linear colour analysis.
Hide-and-Seek Privacy Challenge
Jul 24, 2020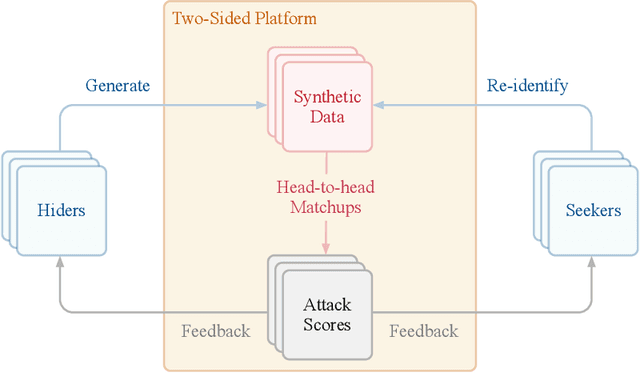
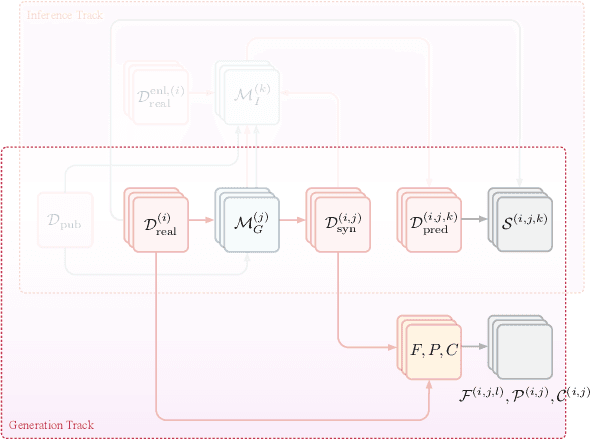
The clinical time-series setting poses a unique combination of challenges to data modeling and sharing. Due to the high dimensionality of clinical time series, adequate de-identification to preserve privacy while retaining data utility is difficult to achieve using common de-identification techniques. An innovative approach to this problem is synthetic data generation. From a technical perspective, a good generative model for time-series data should preserve temporal dynamics, in the sense that new sequences respect the original relationships between high-dimensional variables across time. From the privacy perspective, the model should prevent patient re-identification by limiting vulnerability to membership inference attacks. The NeurIPS 2020 Hide-and-Seek Privacy Challenge is a novel two-tracked competition to simultaneously accelerate progress in tackling both problems. In our head-to-head format, participants in the synthetic data generation track (i.e. "hiders") and the patient re-identification track (i.e. "seekers") are directly pitted against each other by way of a new, high-quality intensive care time-series dataset: the AmsterdamUMCdb dataset. Ultimately, we seek to advance generative techniques for dense and high-dimensional temporal data streams that are (1) clinically meaningful in terms of fidelity and predictivity, as well as (2) capable of minimizing membership privacy risks in terms of the concrete notion of patient re-identification.
Self-Tuning for Data-Efficient Deep Learning
Feb 25, 2021
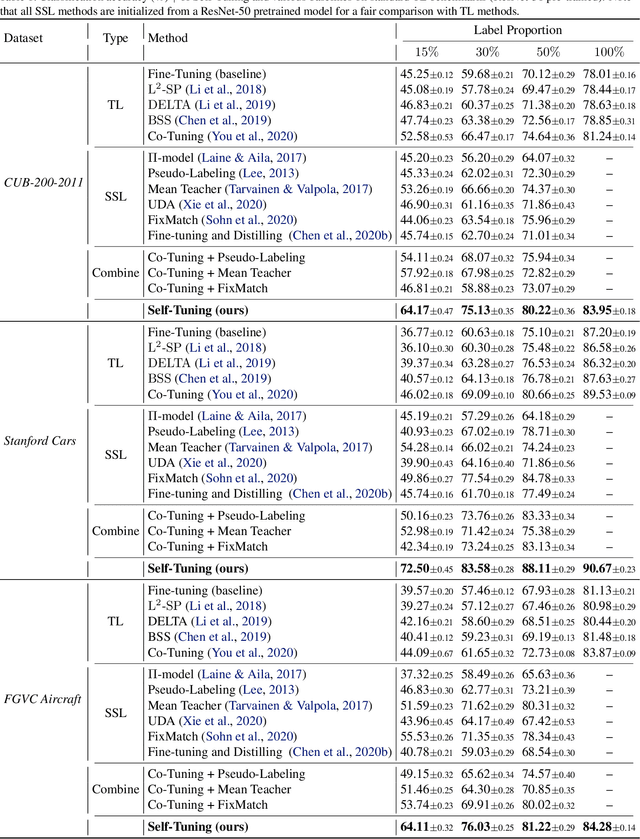

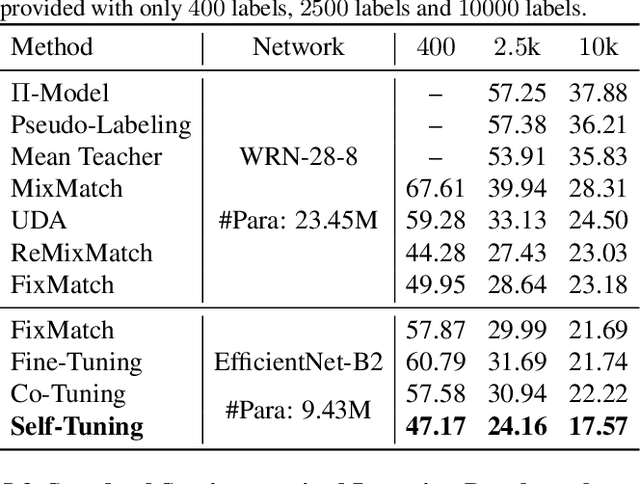
Deep learning has made revolutionary advances to diverse applications in the presence of large-scale labeled datasets. However, it is prohibitively time-costly and labor-expensive to collect sufficient labeled data in most realistic scenarios. To mitigate the requirement for labeled data, semi-supervised learning (SSL) focuses on simultaneously exploring both labeled and unlabeled data, while transfer learning (TL) popularizes a favorable practice of fine-tuning a pre-trained model to the target data. A dilemma is thus encountered: Without a decent pre-trained model to provide an implicit regularization, SSL through self-training from scratch will be easily misled by inaccurate pseudo-labels, especially in large-sized label space; Without exploring the intrinsic structure of unlabeled data, TL through fine-tuning from limited labeled data is at risk of under-transfer caused by model shift. To escape from this dilemma, we present Self-Tuning, a novel approach to enable data-efficient deep learning by unifying the exploration of labeled and unlabeled data and the transfer of a pre-trained model. Further, to address the challenge of confirmation bias in self-training, a Pseudo Group Contrast (PGC) mechanism is devised to mitigate the reliance on pseudo-labels and boost the tolerance to false-labels. Self-Tuning outperforms its SSL and TL counterparts on five tasks by sharp margins, e.g. it doubles the accuracy of fine-tuning on Cars with 15% labels.
Class-incremental Learning with Rectified Feature-Graph Preservation
Jan 22, 2021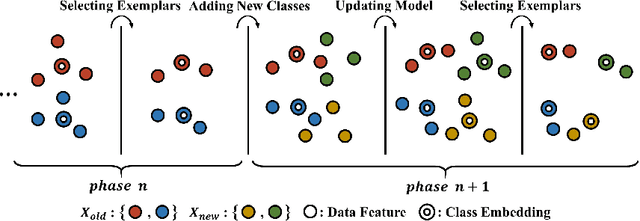
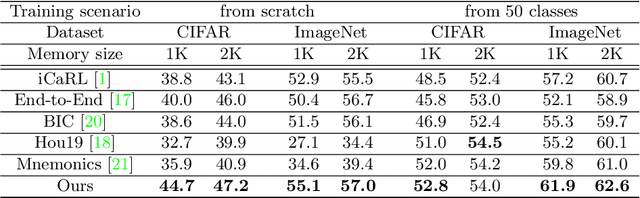
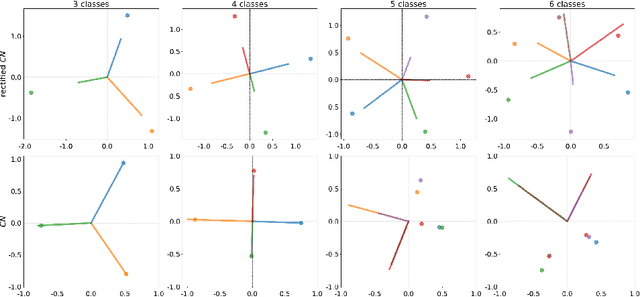
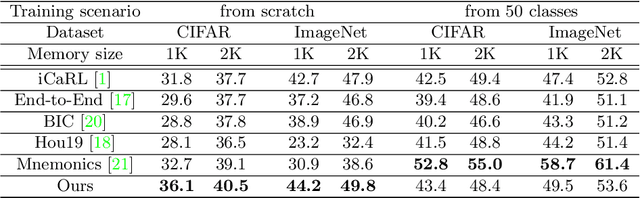
In this paper, we address the problem of distillation-based class-incremental learning with a single head. A central theme of this task is to learn new classes that arrive in sequential phases over time while keeping the model's capability of recognizing seen classes with only limited memory for preserving seen data samples. Many regularization strategies have been proposed to mitigate the phenomenon of catastrophic forgetting. To understand better the essence of these regularizations, we introduce a feature-graph preservation perspective. Insights into their merits and faults motivate our weighted-Euclidean regularization for old knowledge preservation. We further propose rectified cosine normalization and show how it can work with binary cross-entropy to increase class separation for effective learning of new classes. Experimental results on both CIFAR-100 and ImageNet datasets demonstrate that our method outperforms the state-of-the-art approaches in reducing classification error, easing catastrophic forgetting, and encouraging evenly balanced accuracy over different classes. Our project page is at : https://github.com/yhchen12101/FGP-ICL.
Is preprocessing of text really worth your time for online comment classification?
Aug 29, 2018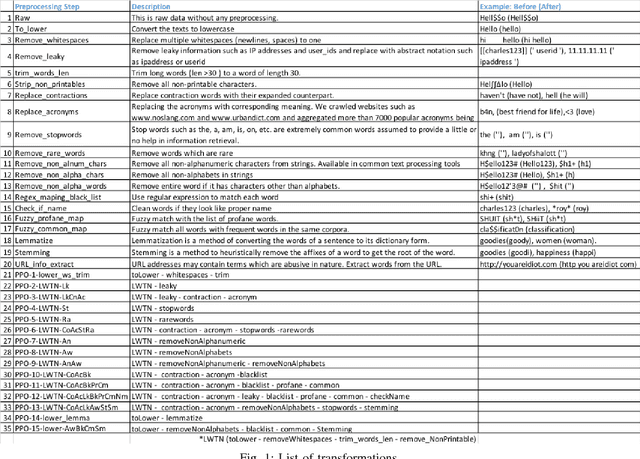
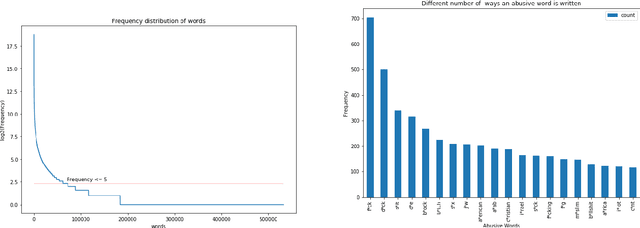
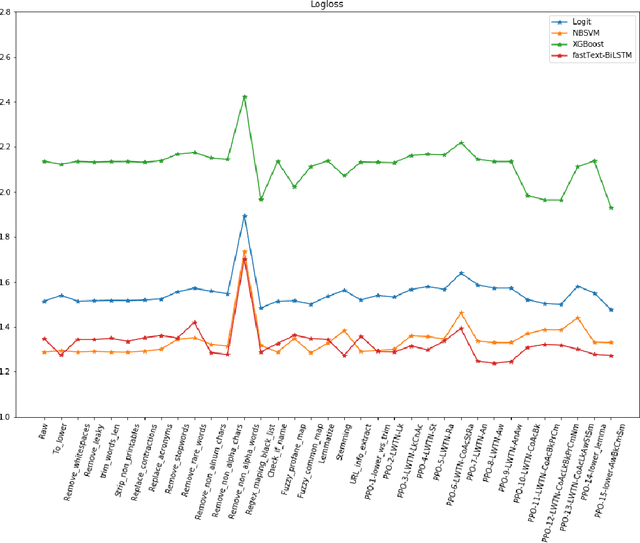
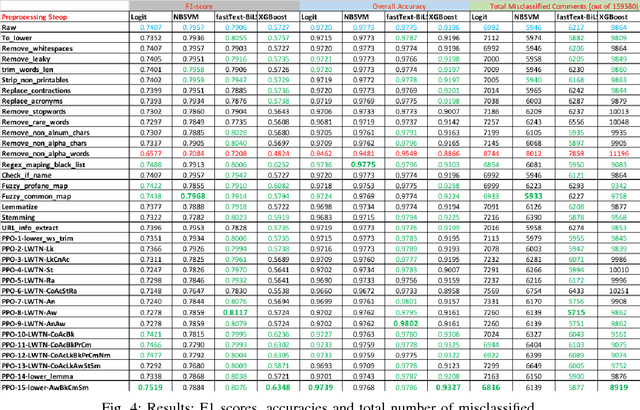
A large proportion of online comments present on public domains are constructive, however a significant proportion are toxic in nature. The comments contain lot of typos which increases the number of features manifold, making the ML model difficult to train. Considering the fact that the data scientists spend approximately 80% of their time in collecting, cleaning and organizing their data [1], we explored how much effort should we invest in the preprocessing (transformation) of raw comments before feeding it to the state-of-the-art classification models. With the help of four models on Jigsaw toxic comment classification data, we demonstrated that the training of model without any transformation produce relatively decent model. Applying even basic transformations, in some cases, lead to worse performance and should be applied with caution.
Nonstochastic Bandits with Infinitely Many Experts
Feb 09, 2021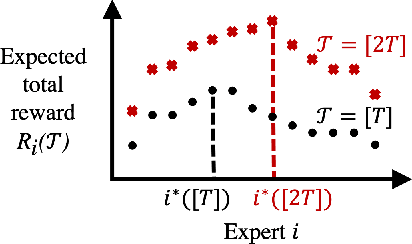
We study the problem of nonstochastic bandits with infinitely many experts: A learner aims to maximize the total reward by taking actions sequentially based on bandit feedback while benchmarking against a countably infinite set of experts. We propose a variant of Exp4.P that, for finitely many experts, enables inference of correct expert rankings while preserving the order of the regret upper bound. We then incorporate the variant into a meta-algorithm that works on infinitely many experts. We prove a high-probability upper bound of $\tilde{\mathcal{O}} \big( i^*K + \sqrt{KT} \big)$ on the regret, up to polylog factors, where $i^*$ is the unknown position of the best expert, $K$ is the number of actions, and $T$ is the time horizon. We also provide an example of structured experts and discuss how to expedite learning in such case. Our meta-learning algorithm achieves the tightest regret upper bound for the setting considered when $i^* = \tilde{\mathcal{O}} \big( \sqrt{T/K} \big)$. If a prior distribution is assumed to exist for $i^*$, the probability of satisfying a tight regret bound increases with $T$, the rate of which can be fast.
Random Matrix Based Extended Target Tracking with Orientation: A New Model and Inference
Oct 17, 2020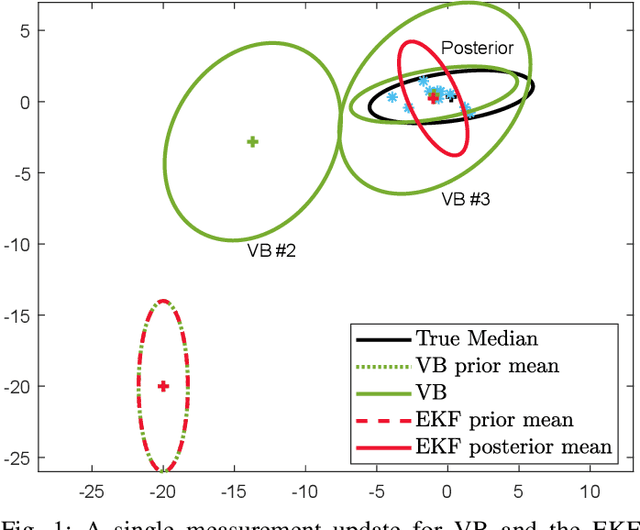
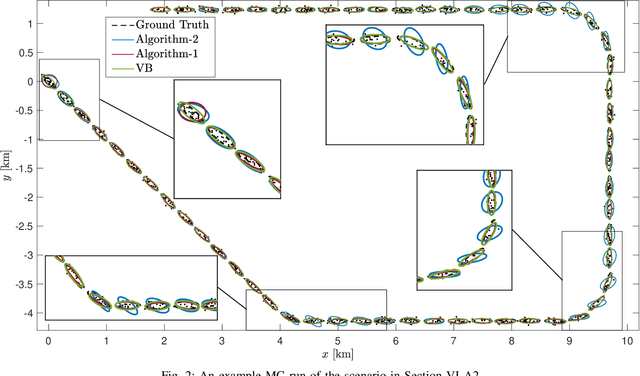
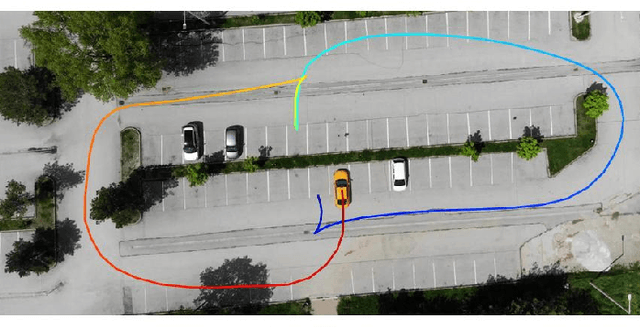
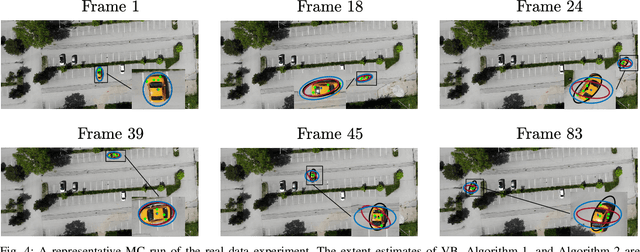
In this study, we propose a novel extended target tracking algorithm which is capable of representing the extent of dynamic objects as an ellipsoid with a time-varying orientation angle. A diagonal positive semi-definite matrix is defined to model objects' extent within the random matrix framework where the diagonal elements have inverse-Gamma priors. The resulting measurement equation is non-linear in the state variables, and it is not possible to find a closed-form analytical expression for the true posterior because of the absence of conjugacy. We use the variational Bayes technique to perform approximate inference, where the Kullback-Leibler divergence between the true and the approximate posterior is minimized by performing fixed-point iterations. The update equations are easy to implement, and the algorithm can be used in real-time tracking applications. We illustrate the performance of the method in simulations and experiments with real data. The proposed method outperforms the state-of-the-art methods when compared with respect to accuracy and robustness.
A Deep Learning Bidirectional Temporal Tracking Algorithm for Automated Blood Cell Counting from Non-invasive Capillaroscopy Videos
Dec 09, 2020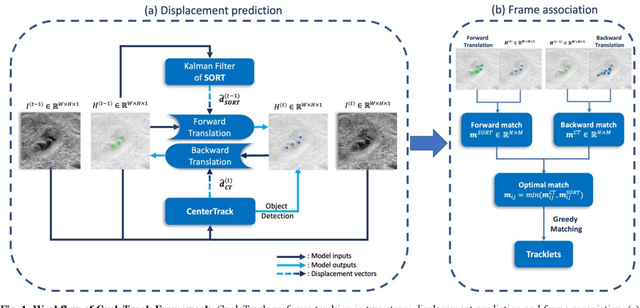
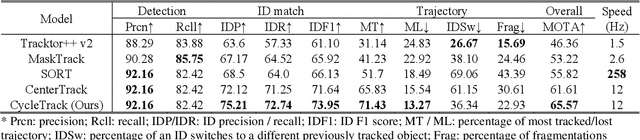
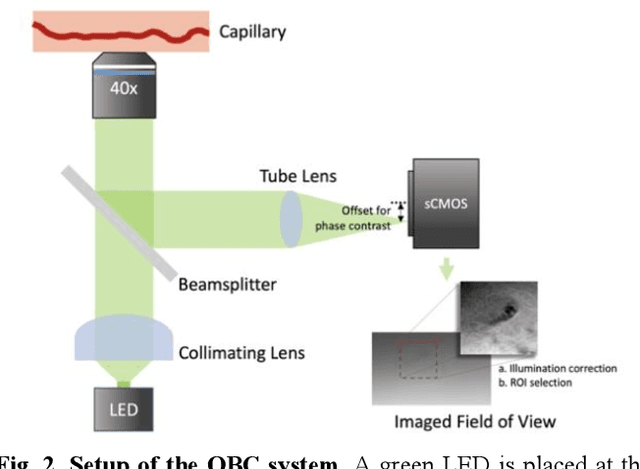
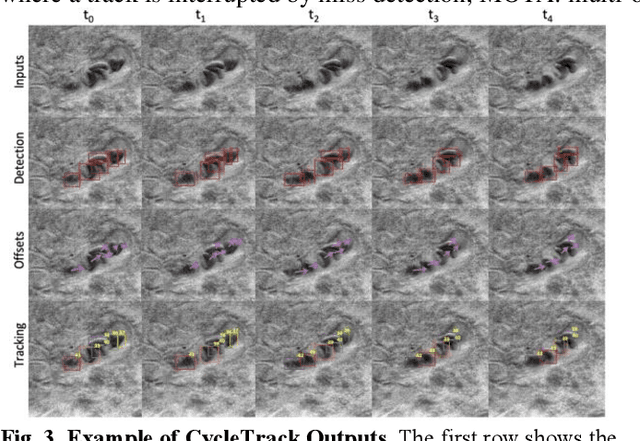
Oblique back-illumination capillaroscopy has recently been introduced as a method for high-quality, non-invasive blood cell imaging in human capillaries. To make this technique practical for clinical blood cell counting, solutions for automatic processing of acquired videos are needed. Here, we take the first step towards this goal, by introducing a deep learning multi-cell tracking model, named CycleTrack, which achieves accurate blood cell counting from capillaroscopic videos. CycleTrack combines two simple online tracking models, SORT and CenterTrack, and is tailored to features of capillary blood cell flow. Blood cells are tracked by displacement vectors in two opposing temporal directions (forward- and backward-tracking) between consecutive frames. This approach yields accurate tracking despite rapidly moving and deforming blood cells. The proposed model outperforms other baseline trackers, achieving 65.57% Multiple Object Tracking Accuracy and 73.95% ID F1 score on test videos. Compared to manual blood cell counting, CycleTrack achieves 96.58 $\pm$ 2.43% cell counting accuracy among 8 test videos with 1000 frames each compared to 93.45% and 77.02% accuracy for independent CenterTrack and SORT almost without additional time expense. It takes 800s to track and count approximately 8000 blood cells from 9,600 frames captured in a typical one-minute video. Moreover, the blood cell velocity measured by CycleTrack demonstrates a consistent, pulsatile pattern within the physiological range of heart rate. Lastly, we discuss future improvements for the CycleTrack framework, which would enable clinical translation of the oblique back-illumination microscope towards a real-time and non-invasive point-of-care blood cell counting and analyzing technology.
Multimodal EEG and Keystroke Dynamics Based Biometric System Using Machine Learning Algorithms
Mar 10, 2021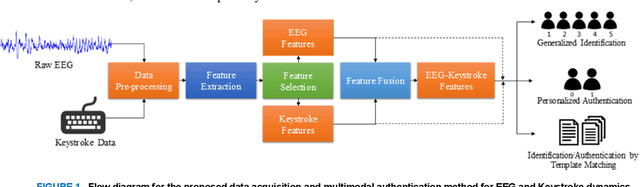
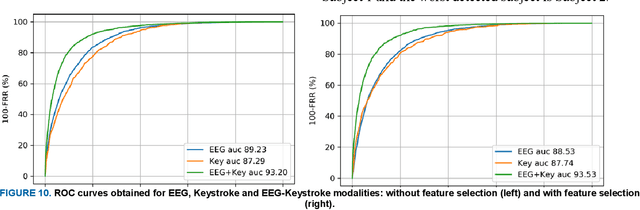

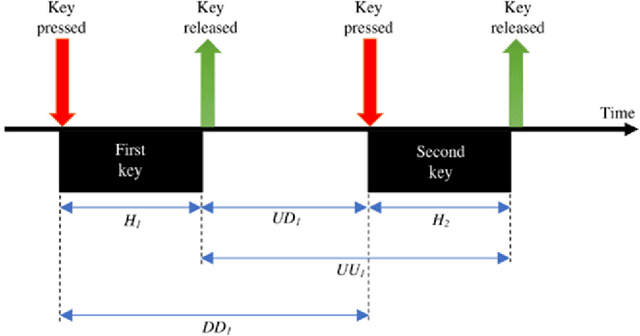
With the rapid advancement of technology, different biometric user authentication, and identification systems are emerging. Traditional biometric systems like face, fingerprint, and iris recognition, keystroke dynamics, etc. are prone to cyber-attacks and suffer from different disadvantages. Electroencephalography (EEG) based authentication has shown promise in overcoming these limitations. However, EEG-based authentication is less accurate due to signal variability at different psychological and physiological conditions. On the other hand, keystroke dynamics-based identification offers high accuracy but suffers from different spoofing attacks. To overcome these challenges, we propose a novel multimodal biometric system combining EEG and keystroke dynamics. Firstly, a dataset was created by acquiring both keystroke dynamics and EEG signals from 10 users with 500 trials per user at 10 different sessions. Different statistical, time, and frequency domain features were extracted and ranked from the EEG signals and key features were extracted from the keystroke dynamics. Different classifiers were trained, validated, and tested for both individual and combined modalities for two different classification strategies - personalized and generalized. Results show that very high accuracy can be achieved both in generalized and personalized cases for the combination of EEG and keystroke dynamics. The identification and authentication accuracies were found to be 99.80% and 99.68% for Extreme Gradient Boosting (XGBoost) and Random Forest classifiers, respectively which outperform the individual modalities with a significant margin (around 5 percent). We also developed a binary template matching-based algorithm, which gives 93.64% accuracy 6X faster. The proposed method is secured and reliable for any kind of biometric authentication.
Real-Time Dense Stereo Matching With ELAS on FPGA Accelerated Embedded Devices
Feb 20, 2018
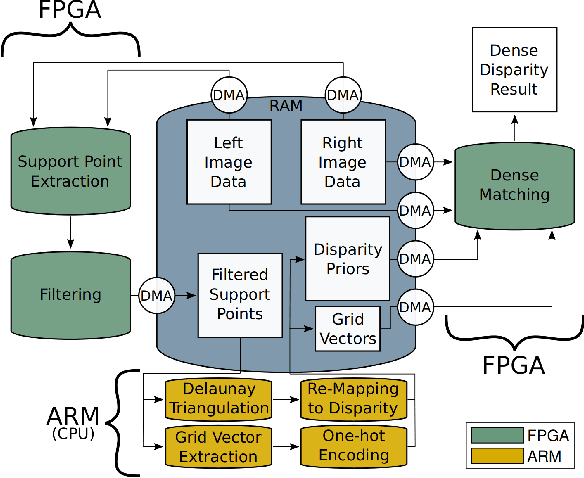
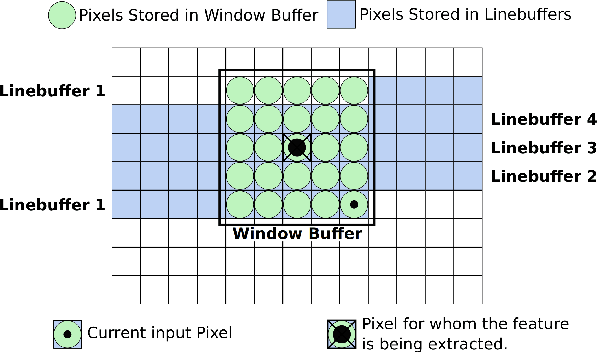
For many applications in low-power real-time robotics, stereo cameras are the sensors of choice for depth perception as they are typically cheaper and more versatile than their active counterparts. Their biggest drawback, however, is that they do not directly sense depth maps; instead, these must be estimated through data-intensive processes. Therefore, appropriate algorithm selection plays an important role in achieving the desired performance characteristics. Motivated by applications in space and mobile robotics, we implement and evaluate a FPGA-accelerated adaptation of the ELAS algorithm. Despite offering one of the best trade-offs between efficiency and accuracy, ELAS has only been shown to run at 1.5-3 fps on a high-end CPU. Our system preserves all intriguing properties of the original algorithm, such as the slanted plane priors, but can achieve a frame rate of 47fps whilst consuming under 4W of power. Unlike previous FPGA based designs, we take advantage of both components on the CPU/FPGA System-on-Chip to showcase the strategy necessary to accelerate more complex and computationally diverse algorithms for such low power, real-time systems.