 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Topic Diffusion Discovery Based on Deep Non-negative Autoencoder
Oct 08, 2020
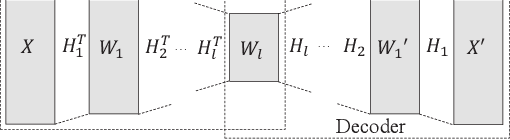
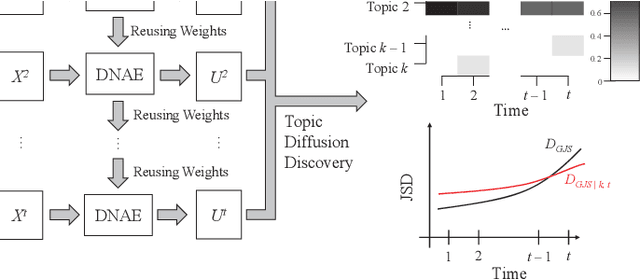
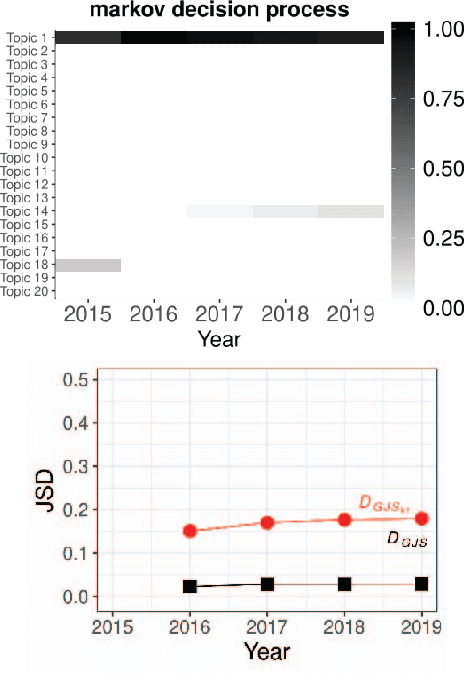
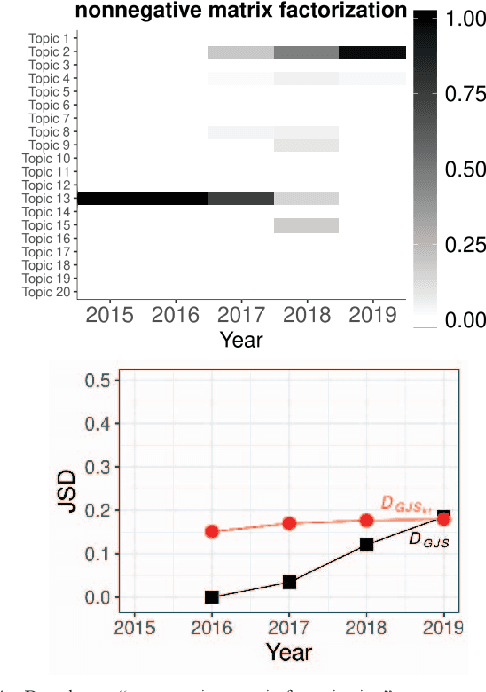
Researchers have been overwhelmed by the explosion of research articles published by various research communities. Many research scholarly websites, search engines, and digital libraries have been created to help researchers identify potential research topics and keep up with recent progress on research of interests. However, it is still difficult for researchers to keep track of the research topic diffusion and evolution without spending a large amount of time reviewing numerous relevant and irrelevant articles. In this paper, we consider a novel topic diffusion discovery technique. Specifically, we propose using a Deep Non-negative Autoencoder with information divergence measurement that monitors evolutionary distance of the topic diffusion to understand how research topics change with time. The experimental results show that the proposed approach is able to identify the evolution of research topics as well as to discover topic diffusions in online fashions.
Real-Time RGB-D Camera Pose Estimation in Novel Scenes using a Relocalisation Cascade
Oct 29, 2018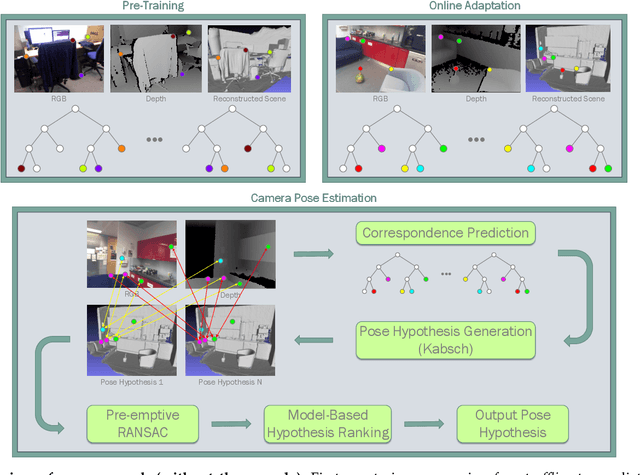
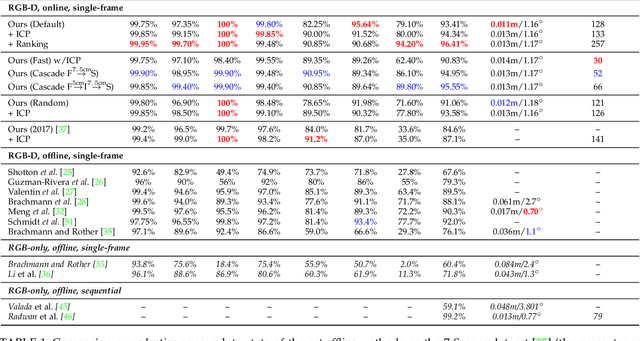

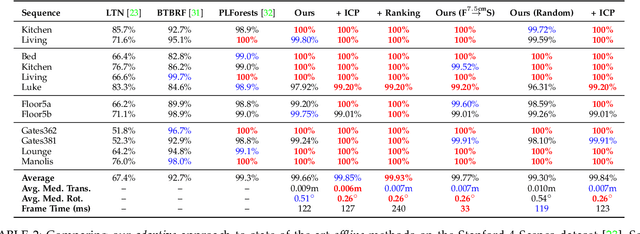
Camera pose estimation is an important problem in computer vision. Common techniques either match the current image against keyframes with known poses, directly regress the pose, or establish correspondences between keypoints in the image and points in the scene to estimate the pose. In recent years, regression forests have become a popular alternative to establish such correspondences. They achieve accurate results, but have traditionally needed to be trained offline on the target scene, preventing relocalisation in new environments. Recently, we showed how to circumvent this limitation by adapting a pre-trained forest to a new scene on the fly. The adapted forests achieved relocalisation performance that was on par with that of offline forests, and our approach was able to estimate the camera pose in close to real time. In this paper, we present an extension of this work that achieves significantly better relocalisation performance whilst running fully in real time. To achieve this, we make several changes to the original approach: (i) instead of accepting the camera pose hypothesis without question, we make it possible to score the final few hypotheses using a geometric approach and select the most promising; (ii) we chain several instantiations of our relocaliser together in a cascade, allowing us to try faster but less accurate relocalisation first, only falling back to slower, more accurate relocalisation as necessary; and (iii) we tune the parameters of our cascade to achieve effective overall performance. These changes allow us to significantly improve upon the performance our original state-of-the-art method was able to achieve on the well-known 7-Scenes and Stanford 4 Scenes benchmarks. As additional contributions, we present a way of visualising the internal behaviour of our forests and show how to entirely circumvent the need to pre-train a forest on a generic scene.
FedEval: A Benchmark System with a Comprehensive Evaluation Model for Federated Learning
Nov 25, 2020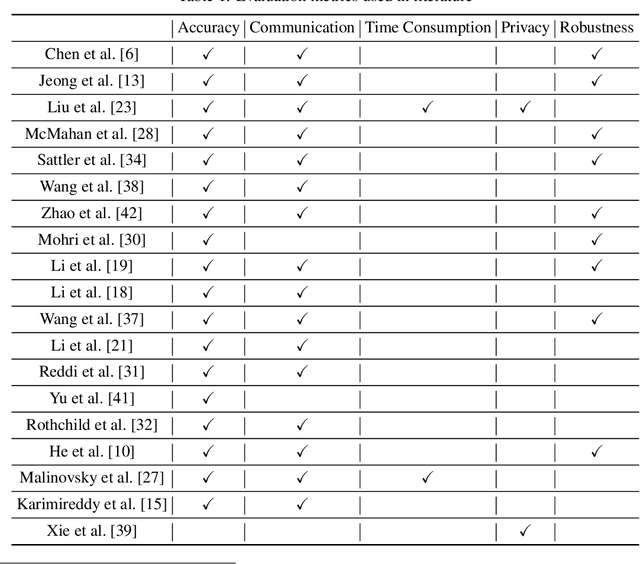

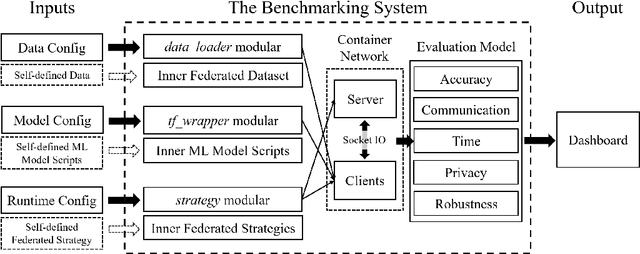
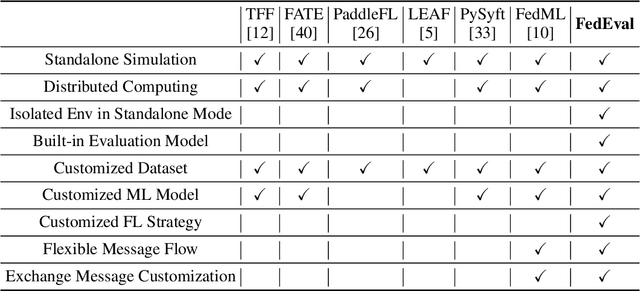
As an innovative solution for privacy-preserving machine learning (ML), federated learning (FL) is attracting much attention from research and industry areas. While new technologies proposed in the past few years do evolve the FL area, unfortunately, the evaluation results presented in these works fall short in integrity and are hardly comparable because of the inconsistent evaluation metrics and the lack of a common platform. In this paper, we propose a comprehensive evaluation framework for FL systems. Specifically, we first introduce the ACTPR model, which defines five metrics that cannot be excluded in FL evaluation, including Accuracy, Communication, Time efficiency, Privacy, and Robustness. Then we design and implement a benchmarking system called FedEval, which enables the systematic evaluation and comparison of existing works under consistent experimental conditions. We then provide an in-depth benchmarking study between the two most widely-used FL mechanisms, FedSGD and FedAvg. The benchmarking results show that FedSGD and FedAvg both have advantages and disadvantages under the ACTPR model. For example, FedSGD is barely influenced by the none independent and identically distributed (non-IID) data problem, but FedAvg suffers from a decline in accuracy of up to 9% in our experiments. On the other hand, FedAvg is more efficient than FedSGD regarding time consumption and communication. Lastly, we excavate a set of take-away conclusions, which are very helpful for researchers in the FL area.
STAR-RT: Visual attention for real-time video game playing
Nov 26, 2017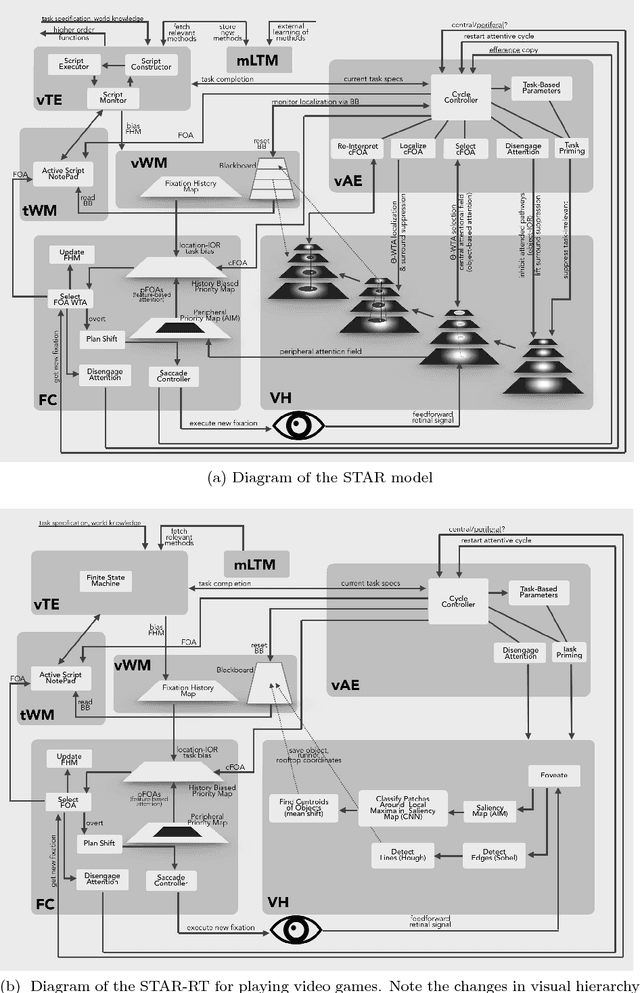



In this paper we present STAR-RT - the first working prototype of Selective Tuning Attention Reference (STAR) model and Cognitive Programs (CPs). The Selective Tuning (ST) model received substantial support through psychological and neurophysiological experiments. The STAR framework expands ST and applies it to practical visual tasks. In order to do so, similarly to many cognitive architectures, STAR combines the visual hierarchy (based on ST) with the executive controller, working and short-term memory components and fixation controller. CPs in turn enable the communication among all these elements for visual task execution. To test the relevance of the system in a realistic context, we implemented the necessary components of STAR and designed CPs for playing two closed-source video games - Canabaltand Robot Unicorn Attack. Since both games run in a browser window, our algorithm has the same amount of information and the same amount of time to react to the events on the screen as a human player would. STAR-RT plays both games in real time using only visual input and achieves scores comparable to human expert players. It thus provides an existence proof for the utility of the particular CP structure and primitives used and the potential for continued experimentation and verification of their utility in broader scenarios.
Technical Progress Analysis Using a Dynamic Topic Model for Technical Terms to Revise Patent Classification Codes
Dec 18, 2020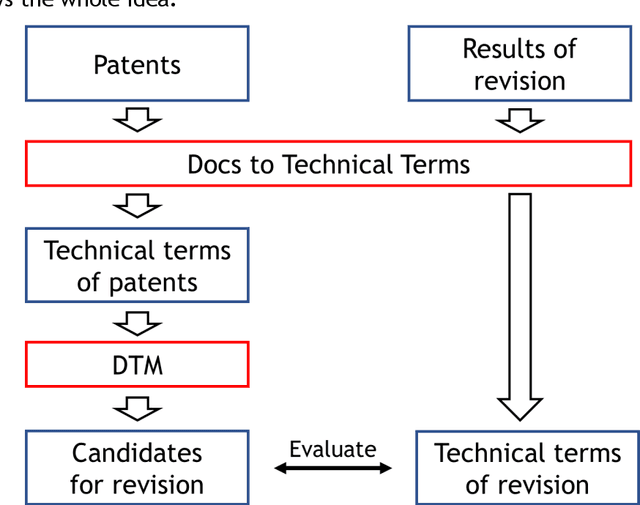
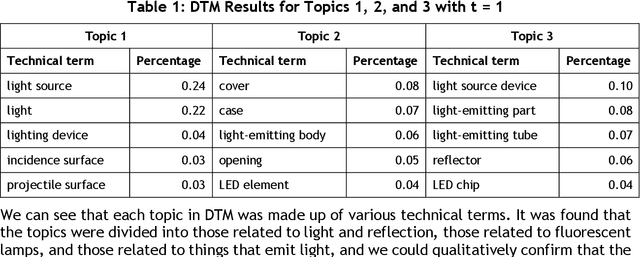
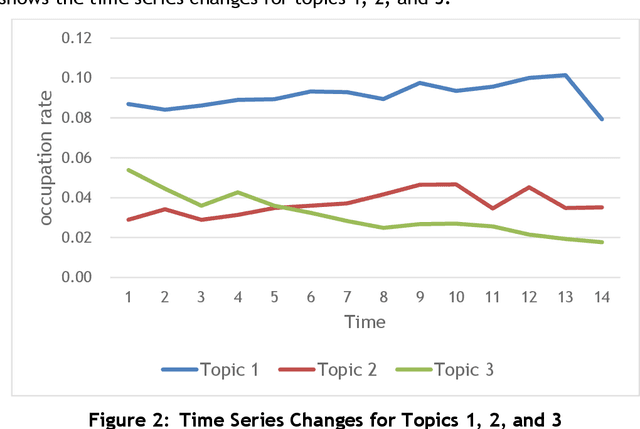
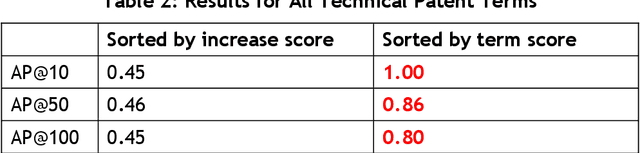
Japanese patents are assigned a patent classification code, FI (File Index), that is unique to Japan. FI is a subdivision of the IPC, an international patent classification code, that is related to Japanese technology. FIs are revised to keep up with technological developments. These revisions have already established more than 30,000 new FIs since 2006. However, these revisions require a lot of time and workload. Moreover, these revisions are not automated and are thus inefficient. Therefore, using machine learning to assist in the revision of patent classification codes (FI) will lead to improved accuracy and efficiency. This study analyzes patent documents from this new perspective of assisting in the revision of patent classification codes with machine learning. To analyze time-series changes in patents, we used the dynamic topic model (DTM), which is an extension of the latent Dirichlet allocation (LDA). Also, unlike English, the Japanese language requires morphological analysis. Patents contain many technical words that are not used in everyday life, so morphological analysis using a common dictionary is not sufficient. Therefore, we used a technique for extracting technical terms from text. After extracting technical terms, we applied them to DTM. In this study, we determined the technological progress of the lighting class F21 for 14 years and compared it with the actual revision of patent classification codes. In other words, we extracted technical terms from Japanese patents and applied DTM to determine the progress of Japanese technology. Then, we analyzed the results from the new perspective of revising patent classification codes with machine learning. As a result, it was found that those whose topics were on the rise were judged to be new technologies.
EventKG+BT: Generation of Interactive Biography Timelines from a Knowledge Graph
Dec 04, 2020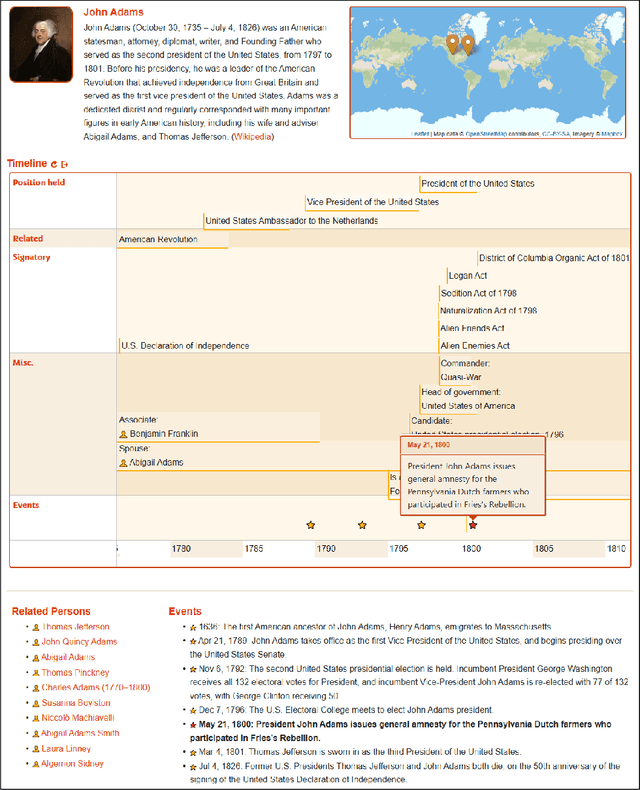
Research on notable accomplishments and important events in the life of people of public interest usually requires close reading of long encyclopedic or biographical sources, which is a tedious and time-consuming task. Whereas semantic reference sources, such as the EventKG knowledge graph, provide structured representations of relevant facts, they often include hundreds of events and temporal relations for particular entities. In this paper, we present EventKG+BT - a timeline generation system that creates concise and interactive spatio-temporal representations of biographies from a knowledge graph using distant supervision.
Risk Aware and Multi-Objective Decision Making with Distributional Monte Carlo Tree Search
Feb 02, 2021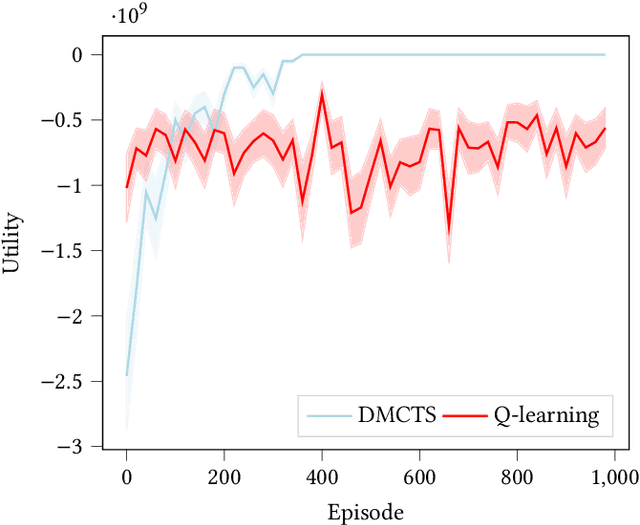
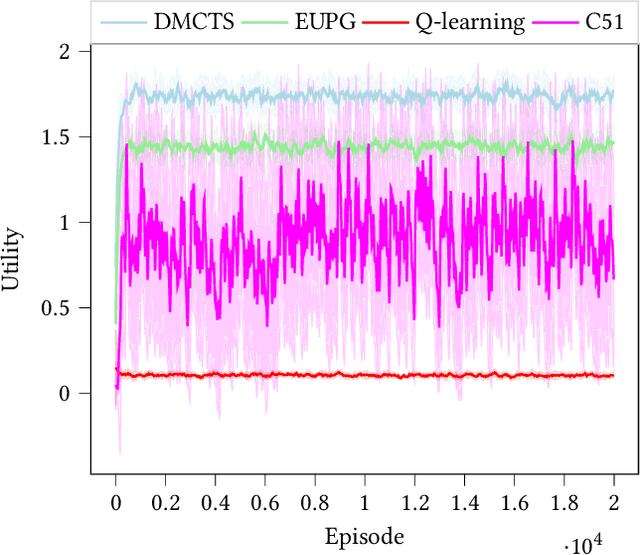
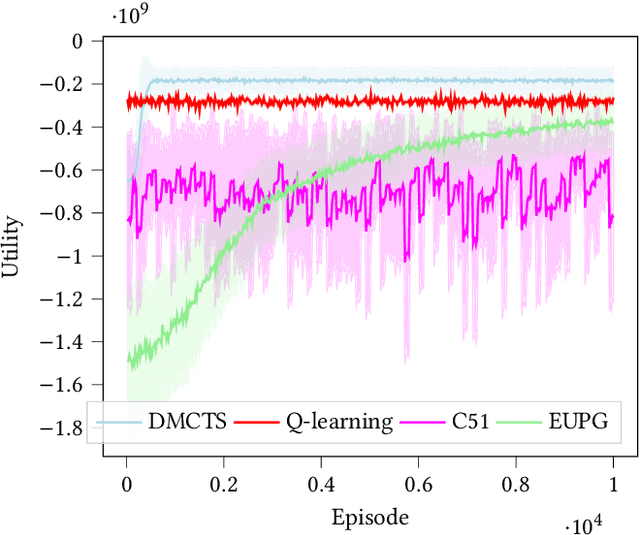
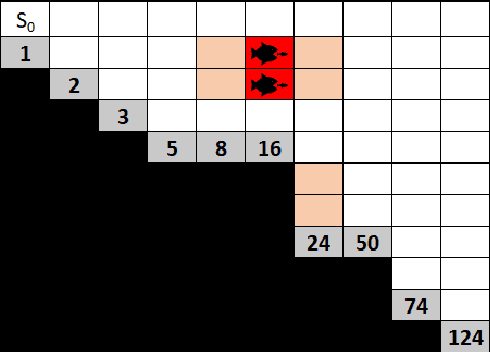
In many risk-aware and multi-objective reinforcement learning settings, the utility of the user is derived from the single execution of a policy. In these settings, making decisions based on the average future returns is not suitable. For example, in a medical setting a patient may only have one opportunity to treat their illness. When making a decision, just the expected return -- known in reinforcement learning as the value -- cannot account for the potential range of adverse or positive outcomes a decision may have. Our key insight is that we should use the distribution over expected future returns differently to represent the critical information that the agent requires at decision time. In this paper, we propose Distributional Monte Carlo Tree Search, an algorithm that learns a posterior distribution over the utility of the different possible returns attainable from individual policy executions, resulting in good policies for both risk-aware and multi-objective settings. Moreover, our algorithm outperforms the state-of-the-art in multi-objective reinforcement learning for the expected utility of the returns.
Using Transformer based Ensemble Learning to classify Scientific Articles
Feb 19, 2021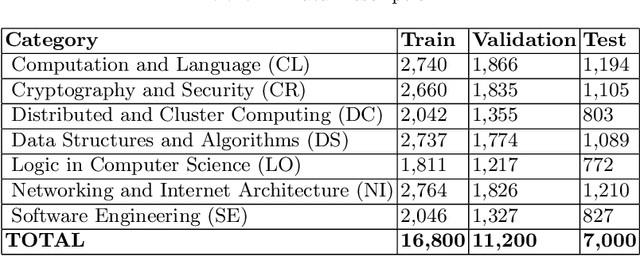
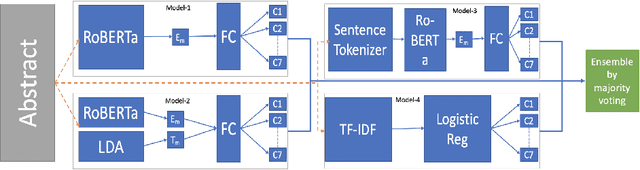
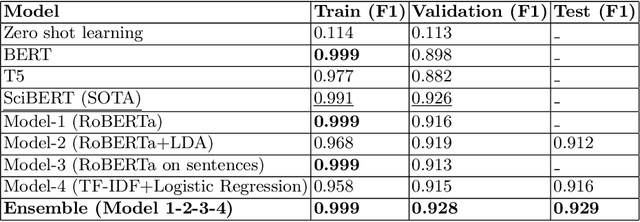
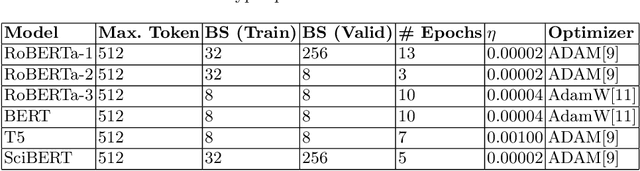
Many time reviewers fail to appreciate novel ideas of a researcher and provide generic feedback. Thus, proper assignment of reviewers based on their area of expertise is necessary. Moreover, reading each and every paper from end-to-end for assigning it to a reviewer is a tedious task. In this paper, we describe a system which our team FideLIPI submitted in the shared task of SDPRA-2021 [14]. It comprises four independent sub-systems capable of classifying abstracts of scientific literature to one of the given seven classes. The first one is a RoBERTa [10] based model built over these abstracts. Adding topic models / Latent dirichlet allocation (LDA) [2] based features to the first model results in the second sub-system. The third one is a sentence level RoBERTa [10] model. The fourth one is a Logistic Regression model built using Term Frequency Inverse Document Frequency (TF-IDF) features. We ensemble predictions of these four sub-systems using majority voting to develop the final system which gives a F1 score of 0.93 on the test and validation set. This outperforms the existing State Of The Art (SOTA) model SciBERT's [1] in terms of F1 score on the validation set.Our codebase is available at https://github.com/SDPRA-2021/shared-task/tree/main/FideLIPI
Environment-Aware and Training-Free Beam Alignment for mmWave Massive MIMO via Channel Knowledge Map
Feb 19, 2021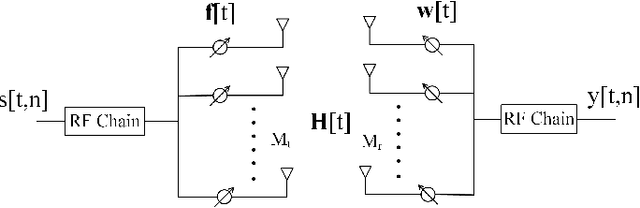
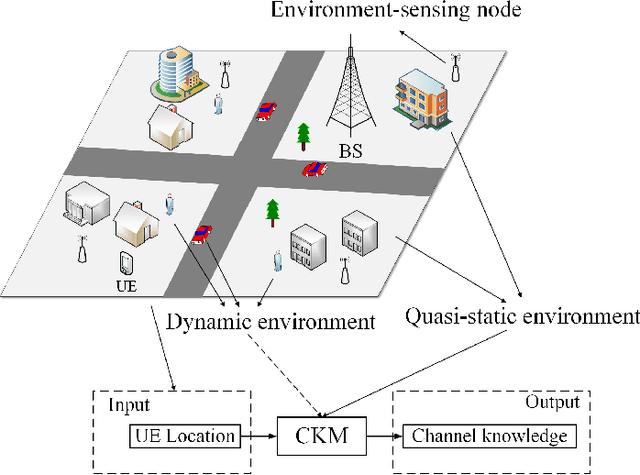
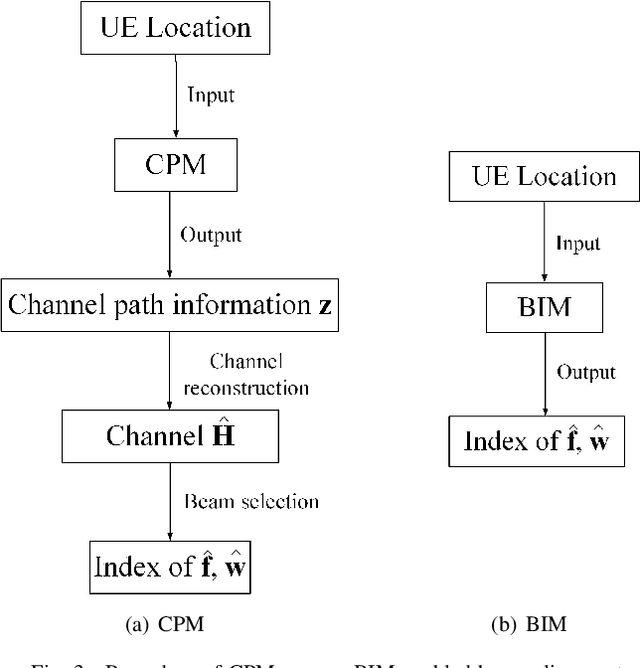
Millimeter wave (mmWave) massive multiple-input multiple-output (MIMO) communication system is expected to achieve enormous transmission rate, provided that the transmit and receive beams are properly aligned with the MIMO channel. However, existing beam alignment techniques rely on either channel estimation or beam sweeping, which incur prohibitively high training overhead, especially for future wireless systems with further increased antenna dimensions and more stringent requirement on cost-effective hardware architectures. In this paper, we propose a new beam alignment technique, which is environment-aware and training-free, by utilizing the emerging concept of channel knowledge map (CKM), together with the user location information that is readily available in contemporary wireless systems. CKM is a site-specific database, tagged with the transmitter/receiver locations, which contains useful channel information to facilitate or even obviate real-time channel state information (CSI) acquistion. Two instances of CKM are proposed for beam alignment in mmWave massive MIMO systems, namely channel path map (CPM) and beam index map (BIM). It is shown that compared with existing training-based beam alignment schemes, the proposed CKM-enabled environment-aware beam alignment is able to drastically improve the effective communication rate, even with moderate user location errors, thanks to its significant saving of the prohibitive training overhead.
Improving Foot-Mounted Inertial Navigation Through Real-Time Motion Classification
Jul 13, 2018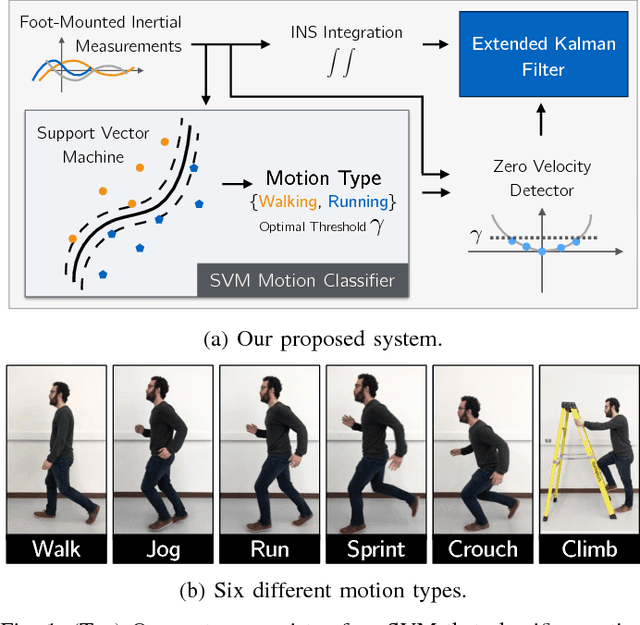
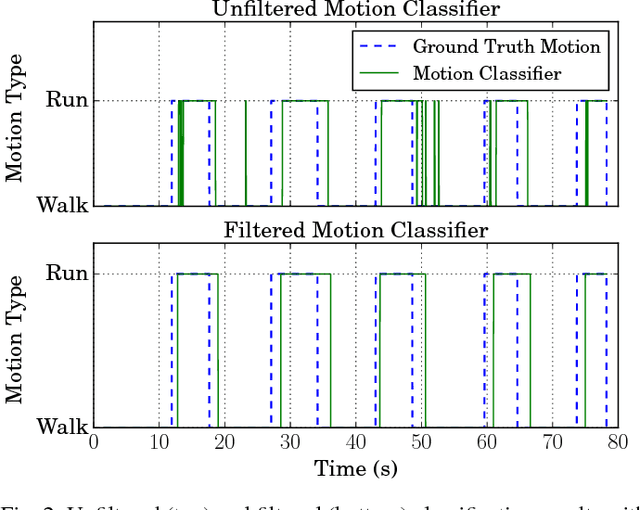

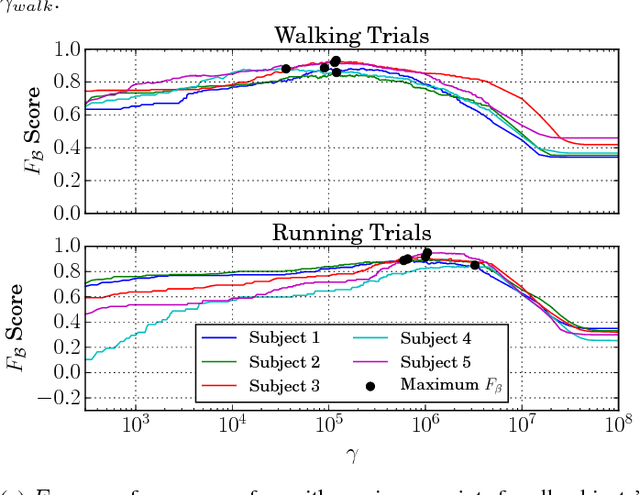
We present a method to improve the accuracy of a foot-mounted, zero-velocity-aided inertial navigation system (INS) by varying estimator parameters based on a real-time classification of motion type. We train a support vector machine (SVM) classifier using inertial data recorded by a single foot-mounted sensor to differentiate between six motion types (walking, jogging, running, sprinting, crouch-walking, and ladder-climbing) and report mean test classification accuracy of over 90% on a dataset with five different subjects. From these motion types, we select two of the most common (walking and running), and describe a method to compute optimal zero-velocity detection parameters tailored to both a specific user and motion type by maximizing the detector F-score. By combining the motion classifier with a set of optimal detection parameters, we show how we can reduce INS position error during mixed walking and running motion. We evaluate our adaptive system on a total of 5.9 km of indoor pedestrian navigation performed by five different subjects moving along a 130 m path with surveyed ground truth markers.