 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Image Compression with Encoder-Decoder Matched Semantic Segmentation
Jan 24, 2021
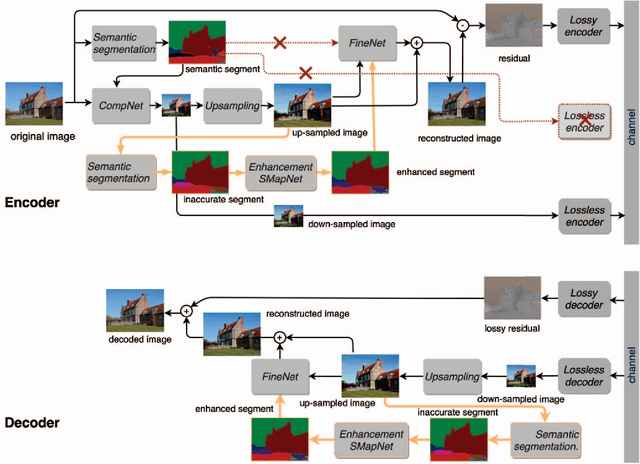

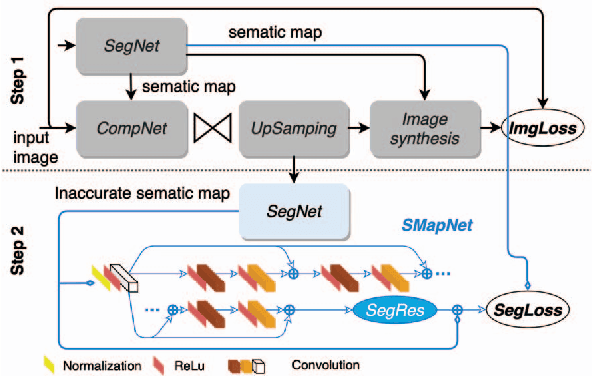
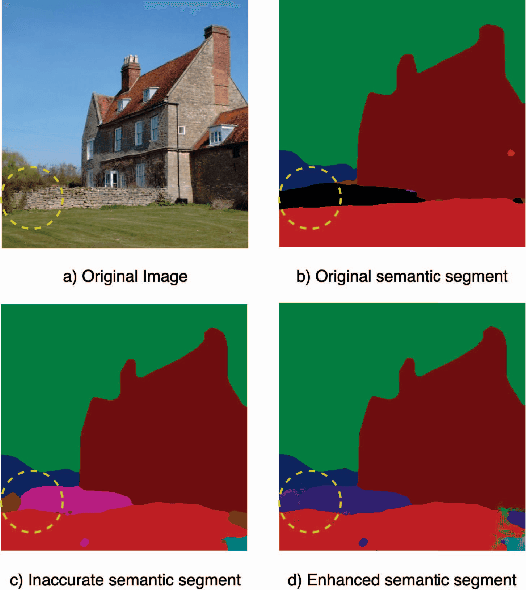
In recent years, layered image compression is demonstrated to be a promising direction, which encodes a compact representation of the input image and apply an up-sampling network to reconstruct the image. To further improve the quality of the reconstructed image, some works transmit the semantic segment together with the compressed image data. Consequently, the compression ratio is also decreased because extra bits are required for transmitting the semantic segment. To solve this problem, we propose a new layered image compression framework with encoder-decoder matched semantic segmentation (EDMS). And then, followed by the semantic segmentation, a special convolution neural network is used to enhance the inaccurate semantic segment. As a result, the accurate semantic segment can be obtained in the decoder without requiring extra bits. The experimental results show that the proposed EDMS framework can get up to 35.31% BD-rate reduction over the HEVC-based (BPG) codec, 5% bitrate, and 24% encoding time saving compare to the state-of-the-art semantic-based image codec.
Sparsification of the Alignment Path Search Space in Dynamic Time Warping
Nov 13, 2017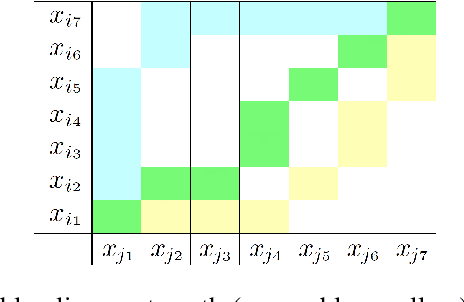
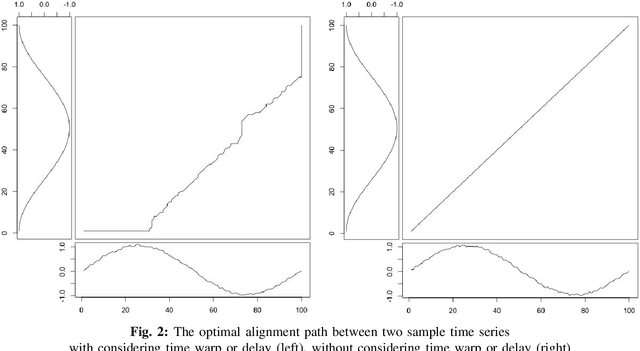
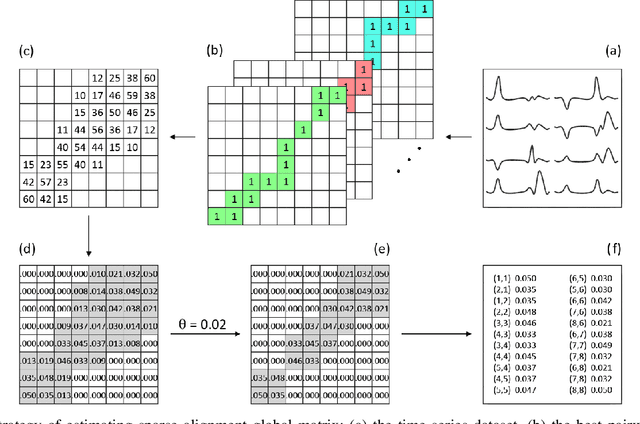
Temporal data are naturally everywhere, especially in the digital era that sees the advent of big data and internet of things. One major challenge that arises during temporal data analysis and mining is the comparison of time series or sequences, which requires to determine a proper distance or (dis)similarity measure. In this context, the Dynamic Time Warping (DTW) has enjoyed success in many domains, due to its 'temporal elasticity', a property particularly useful when matching temporal data. Unfortunately this dissimilarity measure suffers from a quadratic computational cost, which prohibits its use for large scale applications. This work addresses the sparsification of the alignment path search space for DTW-like measures, essentially to lower their computational cost without loosing on the quality of the measure. As a result of our sparsification approach, two new (dis)similarity measures, namely SP-DTW (Sparsified-Paths search space DTW) and its kernelization SP-K rdtw (Sparsified-Paths search space K rdtw kernel) are proposed for time series comparison. A wide range of public datasets is used to evaluate the efficiency (estimated in term of speed-up ratio and classification accuracy) of the proposed (dis)similarity measures on the 1-Nearest Neighbor (1-NN) and the Support Vector Machine (SVM) classification algorithms. Our experiment shows that our proposed measures provide a significant speed-up without loosing on accuracy. Furthermore, at the cost of a slight reduction of the speedup they significantly outperform on the accuracy criteria the old but well known Sakoe-Chiba approach that reduces the DTW path search space using a symmetric corridor.
Adaptive Federated Dropout: Improving Communication Efficiency and Generalization for Federated Learning
Nov 08, 2020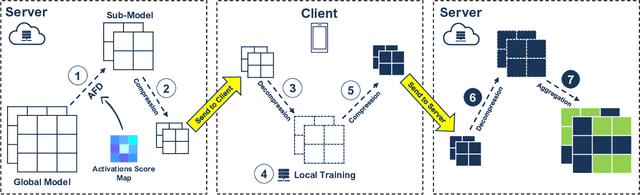
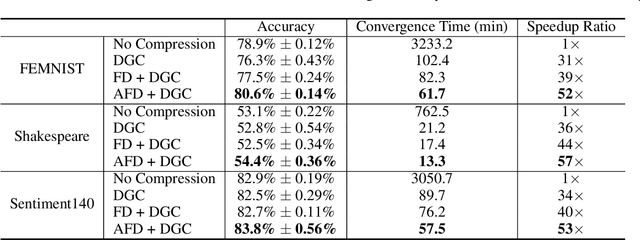
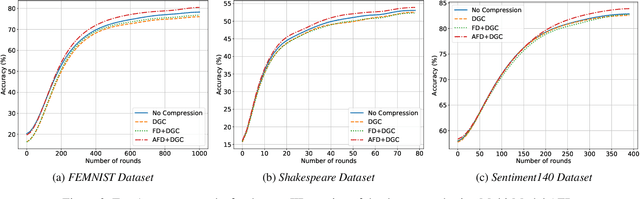
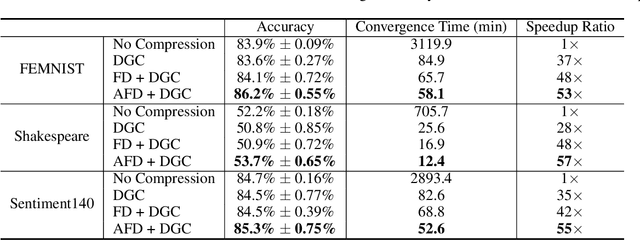
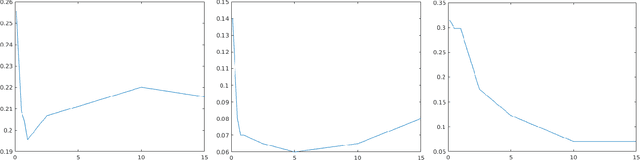
With more regulations tackling users' privacy-sensitive data protection in recent years, access to such data has become increasingly restricted and controversial. To exploit the wealth of data generated and located at distributed entities such as mobile phones, a revolutionary decentralized machine learning setting, known as Federated Learning, enables multiple clients located at different geographical locations to collaboratively learn a machine learning model while keeping all their data on-device. However, the scale and decentralization of federated learning present new challenges. Communication between the clients and the server is considered a main bottleneck in the convergence time of federated learning. In this paper, we propose and study Adaptive Federated Dropout (AFD), a novel technique to reduce the communication costs associated with federated learning. It optimizes both server-client communications and computation costs by allowing clients to train locally on a selected subset of the global model. We empirically show that this strategy, combined with existing compression methods, collectively provides up to 57x reduction in convergence time. It also outperforms the state-of-the-art solutions for communication efficiency. Furthermore, it improves model generalization by up to 1.7%.
SecSens: Secure State Estimation with Application to Localization and Time Synchronization
Jan 22, 2018
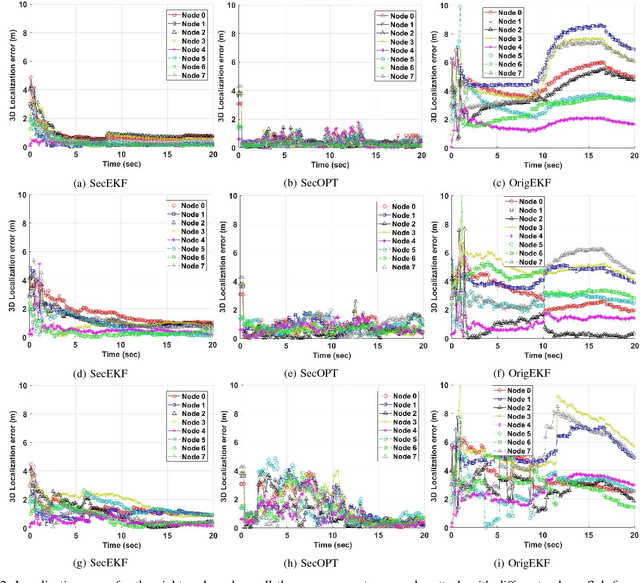
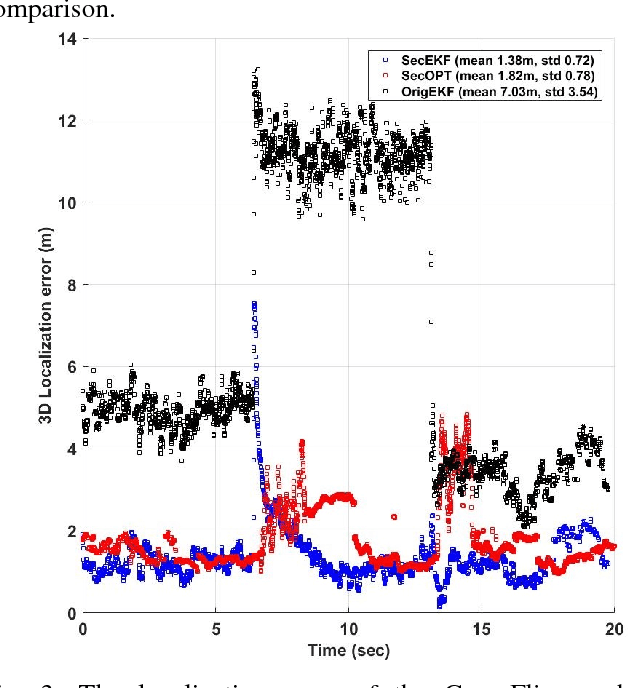
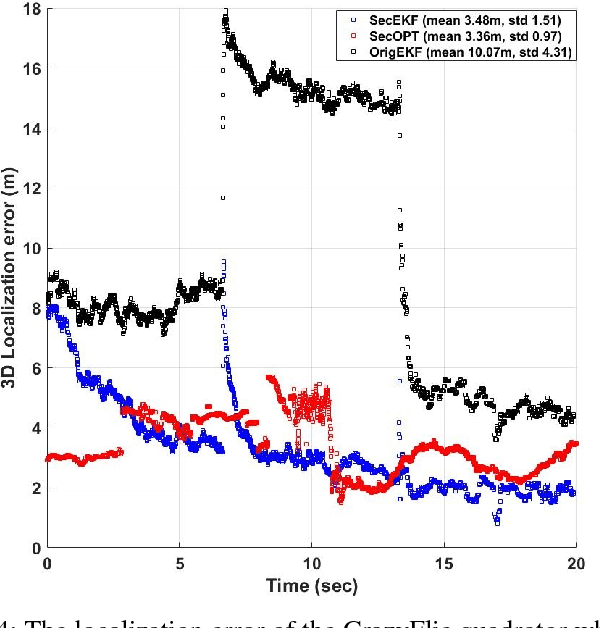
Research evidence in Cyber-Physical Systems (CPS) shows that the introduced tight coupling of information technology with physical sensing and actuation leads to more vulnerability and security weaknesses. But, the traditional security protection mechanisms of CPS focus on data encryption while neglecting the sensors which are vulnerable to attacks in the physical domain. Accordingly, researchers attach utmost importance to the problem of state estimation in the presence of sensor attacks. In this work, we present SecSens, a novel approach for secure nonlinear state estimation in the presence of modeling and measurement noise. SecSens consists of two independent algorithms, namely, SecEKF and SecOPT, which are based on Extended Kalman Filter and Maximum Likelihood Estimation, respectively. We adopt a holistic approach to introduce security awareness among state estimation algorithms without requiring specialized hardware, or cryptographic techniques. We apply SecSens to securely localize and time synchronize networked mobile devices. SecSens provides good performance at run-time several order of magnitude faster than the state of art solutions under the presence of powerful attacks. Our algorithms are evaluated on a testbed with static nodes and a mobile quadrotor all equipped with commercial ultra-wide band wireless devices.
A Spiking Neural Network (SNN) for detecting High Frequency Oscillations (HFOs) in the intraoperative ECoG
Nov 17, 2020
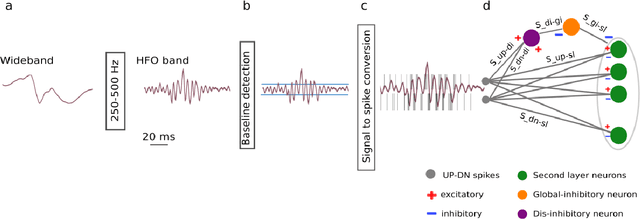
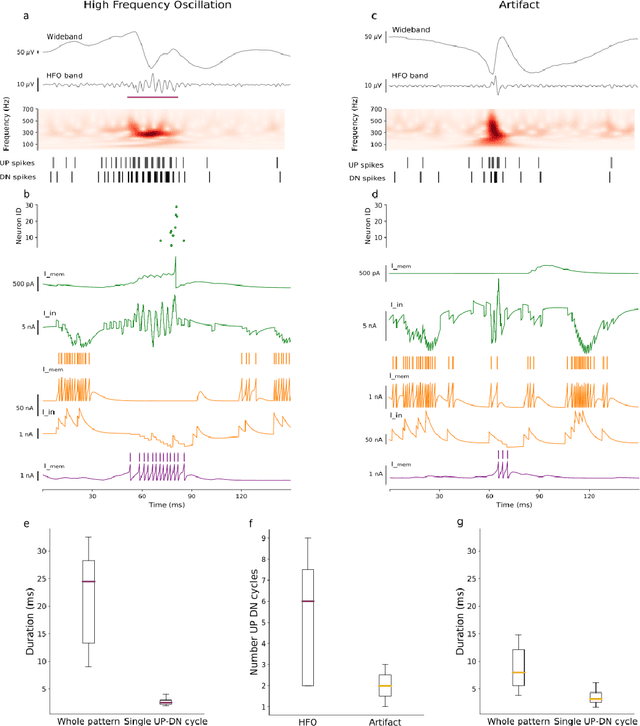
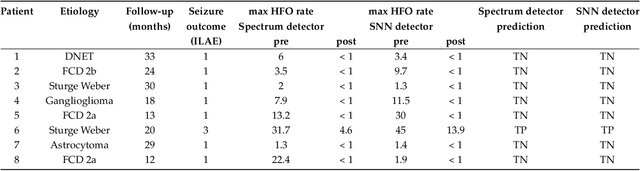
To achieve seizure freedom, epilepsy surgery requires the complete resection of the epileptogenic brain tissue. In intraoperative ECoG recordings, high frequency oscillations (HFOs) generated by epileptogenic tissue can be used to tailor the resection margin. However, automatic detection of HFOs in real-time remains an open challenge. Here we present a spiking neural network (SNN) for automatic HFO detection that is optimally suited for neuromorphic hardware implementation. We trained the SNN to detect HFO signals measured from intraoperative ECoG on-line, using an independently labeled dataset. We targeted the detection of HFOs in the fast ripple frequency range (250-500 Hz) and compared the network results with the labeled HFO data. We endowed the SNN with a novel artifact rejection mechanism to suppress sharp transients and demonstrate its effectiveness on the ECoG dataset. The HFO rates (median 6.6 HFO/min in pre-resection recordings) detected by this SNN are comparable to those published in the dataset (58 min, 16 recordings). The postsurgical seizure outcome was "predicted" with 100% accuracy for all 8 patients. These results provide a further step towards the construction of a real-time portable battery-operated HFO detection system that can be used during epilepsy surgery to guide the resection of the epileptogenic zone.
Using Transformer based Ensemble Learning to classify Scientific Articles
Feb 19, 2021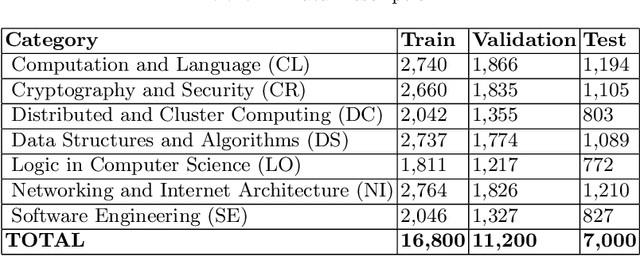
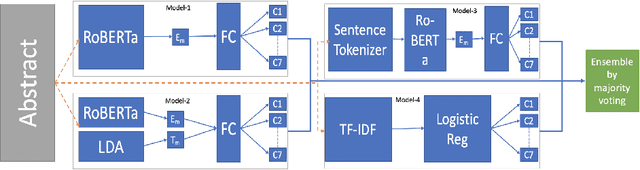
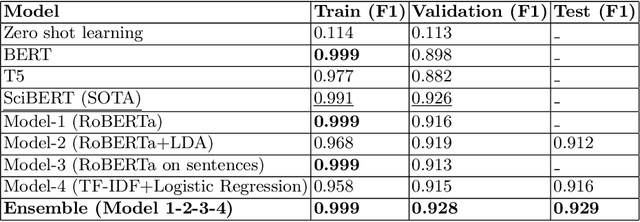
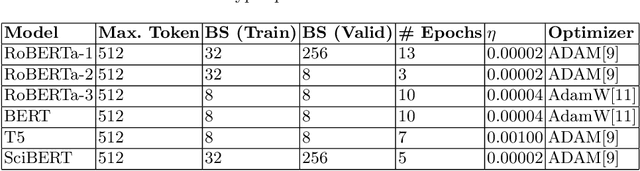
Many time reviewers fail to appreciate novel ideas of a researcher and provide generic feedback. Thus, proper assignment of reviewers based on their area of expertise is necessary. Moreover, reading each and every paper from end-to-end for assigning it to a reviewer is a tedious task. In this paper, we describe a system which our team FideLIPI submitted in the shared task of SDPRA-2021 [14]. It comprises four independent sub-systems capable of classifying abstracts of scientific literature to one of the given seven classes. The first one is a RoBERTa [10] based model built over these abstracts. Adding topic models / Latent dirichlet allocation (LDA) [2] based features to the first model results in the second sub-system. The third one is a sentence level RoBERTa [10] model. The fourth one is a Logistic Regression model built using Term Frequency Inverse Document Frequency (TF-IDF) features. We ensemble predictions of these four sub-systems using majority voting to develop the final system which gives a F1 score of 0.93 on the test and validation set. This outperforms the existing State Of The Art (SOTA) model SciBERT's [1] in terms of F1 score on the validation set.Our codebase is available at https://github.com/SDPRA-2021/shared-task/tree/main/FideLIPI
Memformer: The Memory-Augmented Transformer
Oct 14, 2020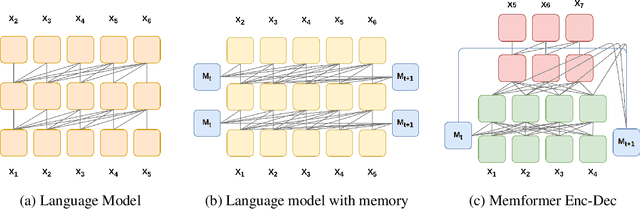
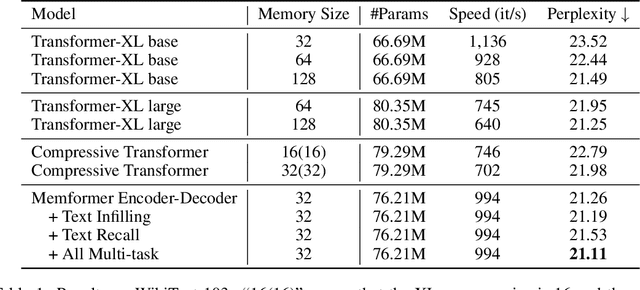
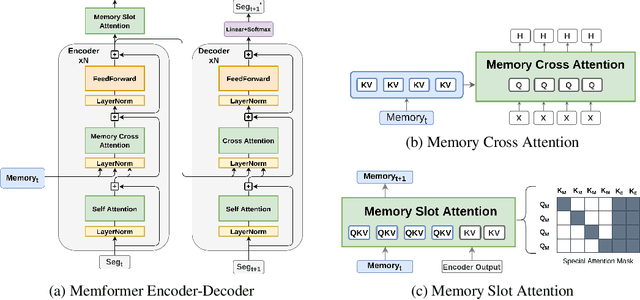

Transformer models have obtained remarkable accomplishments in various NLP tasks. However, these models have efficiency issues on long sequences, as the complexity of their self-attention module scales quadratically with the sequence length. To remedy the limitation, we present Memformer, a novel language model that utilizes a single unified memory to encode and retrieve past information. It includes a new optimization scheme, Memory Replay Back-Propagation, which promotes long-range back-propagation through time with a significantly reduced memory requirement. Memformer achieves $\mathcal{O}(n)$ time complexity and $\mathcal{O}(1)$ space complexity in processing long sequences, meaning that the model can handle an infinite length sequence during inference. Our model is also compatible with other self-supervised tasks to further improve the performance on language modeling. Experimental results show that Memformer outperforms the previous long-range sequence models on WikiText-103, including Transformer-XL and compressive Transformer.
Toward Real-World BCI: CCSPNet, A Compact Subject-Independent Motor Imagery Framework
Dec 25, 2020
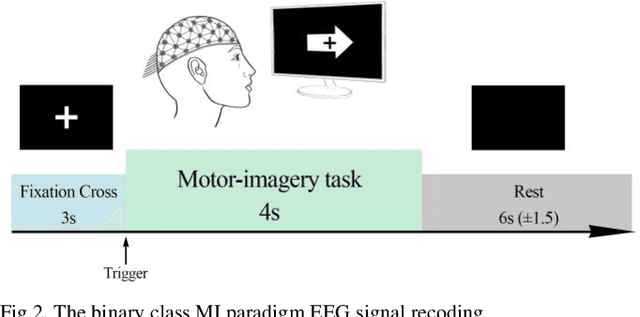
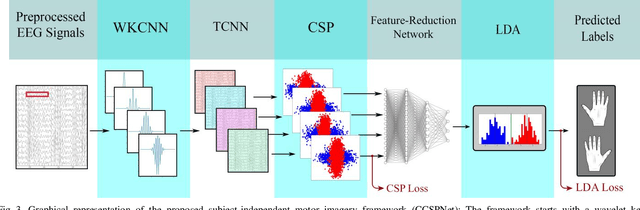
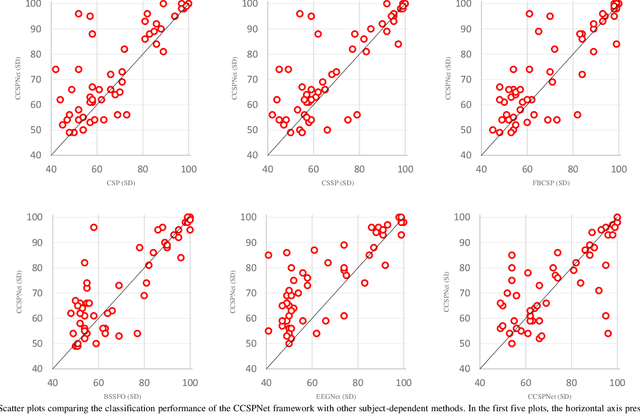
A conventional brain-computer interface (BCI) requires a complete data gathering, training, and calibration phase for each user before it can be used. This preliminary phase is time-consuming and should be done under the supervision of technical experts commonly in laboratories for the BCI to function properly. In recent years, a number of subject-independent (SI) BCIs have been developed. However, there are many problems preventing them from being used in real-world BCI applications. A lower accuracy than the subject-dependent (SD) approach and a relatively high run-time of models with a large number of model parameters are the most important ones. Therefore, a real-world BCI application would greatly benefit from a compact subject-independent BCI framework, ready to use immediately after the user puts it on, and suitable for low-power edge-computing and applications in the emerging area of internet of things (IoT). We propose a novel subject-independent BCI framework named CCSPNet (Convolutional Common Spatial Pattern Network) that is trained on the motor imagery (MI) paradigm of a large-scale EEG signals database consisting of 400 trials for every 54 subjects performing two-class hand-movement MI tasks. The proposed framework applies a wavelet kernel convolutional neural network (WKCNN) and a temporal convolutional neural network (TCNN) in order to represent and extract the diverse frequency behavior and spectral patterns of EEG signals. The convolutional layers outputs go through a CSP algorithm for class discrimination and spatial feature extraction. The number of CSP features is reduced by a dense neural network, and the final class label is determined by an LDA. The final SD and SI classification accuracies of the proposed framework match the best results obtained on the largest motor-imagery dataset present in the BCI literature, with 99.993 percent fewer model parameters.
Research Progress of News Recommendation Methods
Dec 04, 2020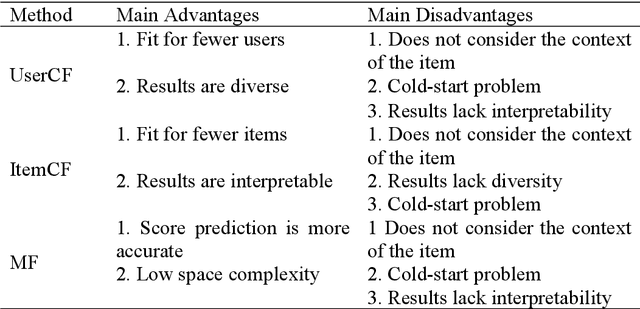
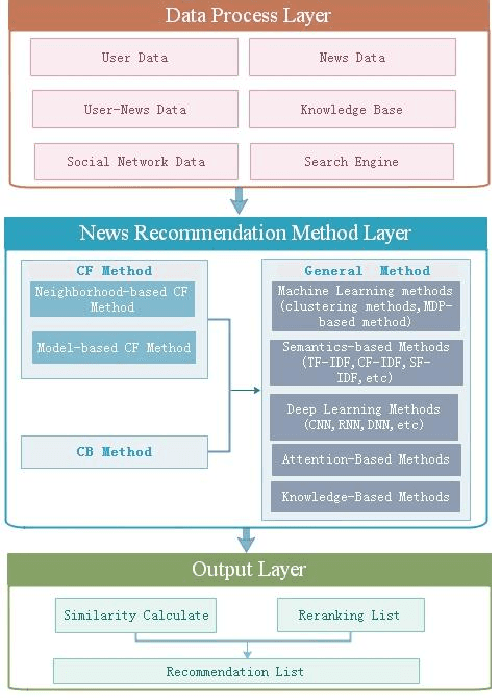

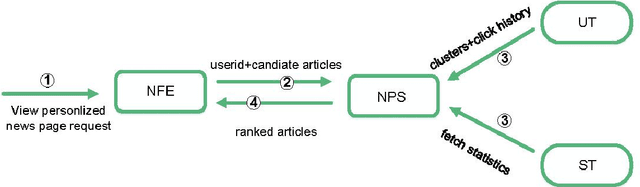
Due to researchers'aim to study personalized recommendations for different business fields, the summary of recommendation methods in specific fields is of practical significance. News recommendation systems were the earliest research field regarding recommendation systems, and were also the earliest recommendation field to apply the collaborative filtering method. In addition, news is real-time and rich in content, which makes news recommendation methods more challenging than in other fields. Thus, this paper summarizes the research progress regarding news recommendation methods. From 2018 to 2020, developed news recommendation methods were mainly deep learning-based, attention-based, and knowledge graphs-based. As of 2020, there are many news recommendation methods that combine attention mechanisms and knowledge graphs. However, these methods were all developed based on basic methods (the collaborative filtering method, the content-based recommendation method, and a mixed recommendation method combining the two). In order to allow researchers to have a detailed understanding of the development process of news recommendation methods, the news recommendation methods surveyed in this paper, which cover nearly 10 years, are divided into three categories according to the abovementioned basic methods. Firstly, the paper introduces the basic ideas of each category of methods and then summarizes the recommendation methods that are combined with other methods based on each category of methods and according to the time sequence of research results. Finally, this paper also summarizes the challenges confronting news recommendation systems.
Comparison of Centralized and Decentralized Approaches in Cooperative Coverage Problems with Energy-Constrained Agents
Aug 26, 2020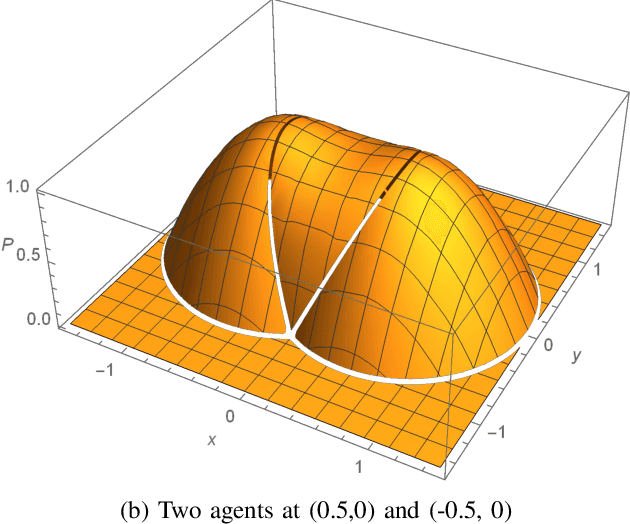
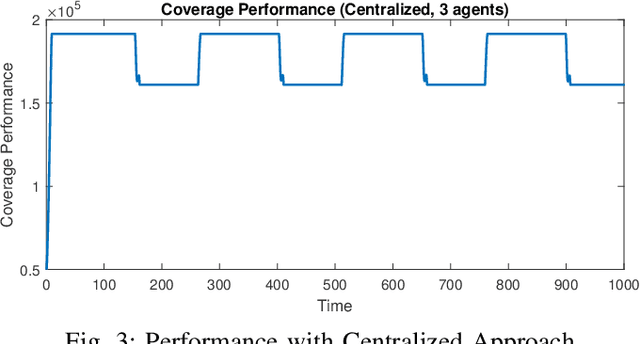
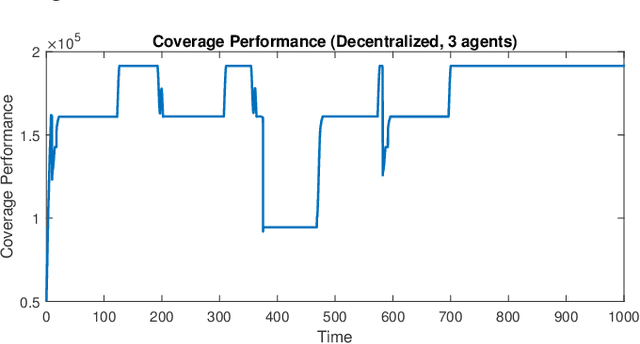
A multi-agent coverage problem is considered with energy-constrained agents. The objective of this paper is to compare the coverage performance between centralized and decentralized approaches. To this end, a near-optimal centralized coverage control method is developed under energy depletion and repletion constraints. The optimal coverage formation corresponds to the locations of agents where the coverage performance is maximized. The optimal charging formation corresponds to the locations of agents with one agent fixed at the charging station and the remaining agents maximizing the coverage performance. We control the behavior of this cooperative multi-agent system by switching between the optimal coverage formation and the optimal charging formation. Finally, the optimal dwell times at coverage locations, charging time, and agent trajectories are determined so as to maximize coverage over a given time interval. In particular, our controller guarantees that at any time there is at most one agent leaving the team for energy repletion.