 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Can we learn where people come from? Retracing of origins in merging situations
Dec 21, 2020
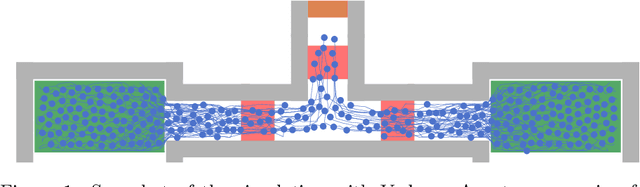
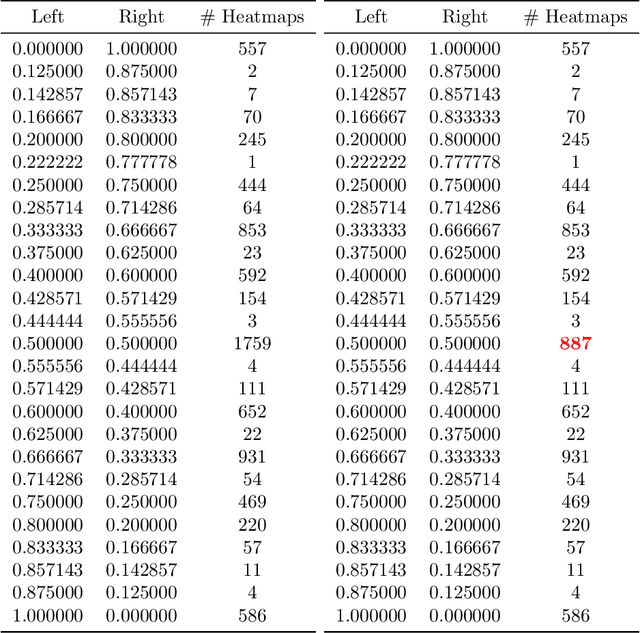
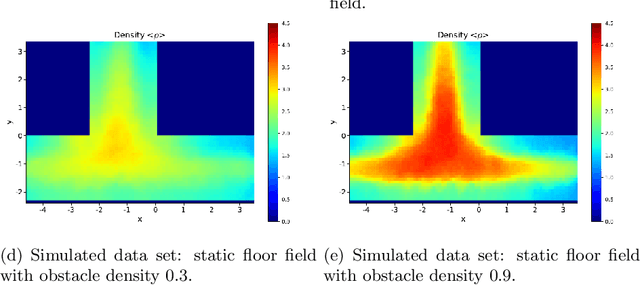
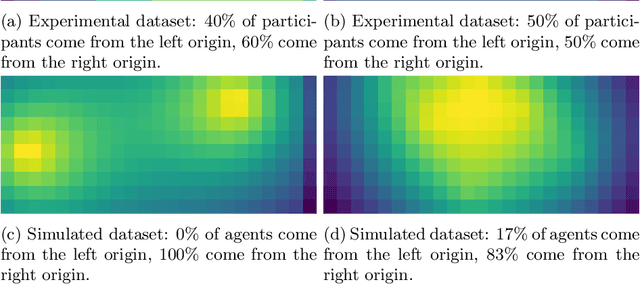
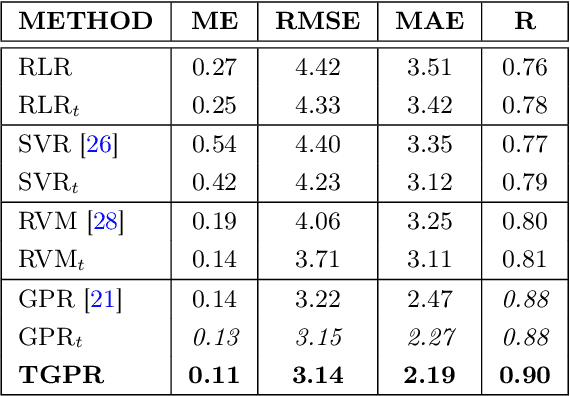
One crucial information for a pedestrian crowd simulation is the number of agents moving from an origin to a certain target. While this setup has a large impact on the simulation, it is in most setups challenging to find the number of agents that should be spawned at a source in the simulation. Often, number are chosen based on surveys and experience of modelers and event organizers. These approaches are important and useful but reach their limits when we want to perform real-time predictions. In this case, a static information about the inflow is not sufficient. Instead, we need a dynamic information that can be retrieved each time the prediction is started. Nowadays, sensor data such as video footage or GPS tracks of a crowd are often available. If we can estimate the number of pedestrians who stem from a certain origin from this sensor data, we can dynamically initialize the simulation. In this study, we use density heatmaps that can be derived from sensor data as input for a random forest regressor to predict the origin distributions. We study three different datasets: A simulated dataset, experimental data, and a hybrid approach with both experimental and simulated data. In the hybrid setup, the model is trained with simulated data and then tested on experimental data. The results demonstrate that the random forest model is able to predict the origin distribution based on a single density heatmap for all three configurations. This is especially promising for applying the approach on real data since there is often only a limited amount of data available.
Coordination via predictive assistants: time series algorithms and game-theoretic analysis
Oct 05, 2018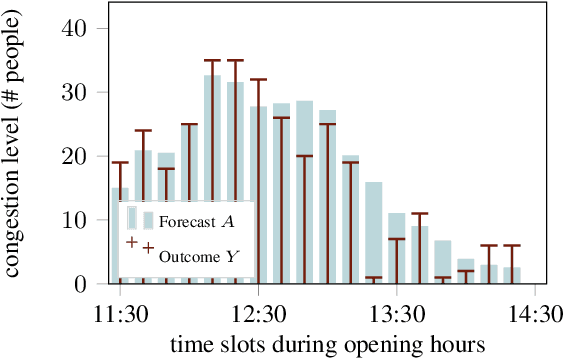
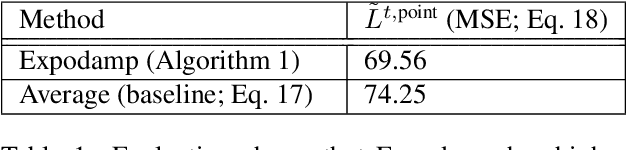
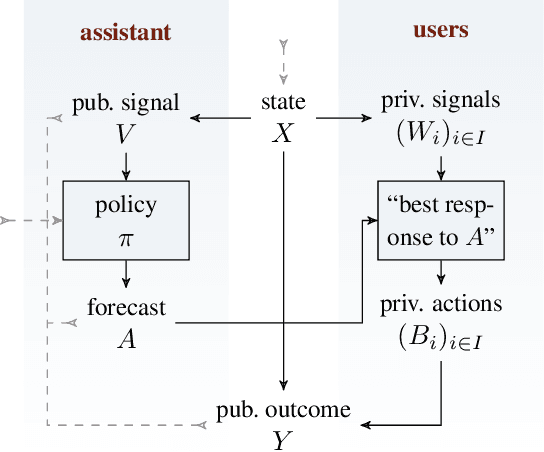
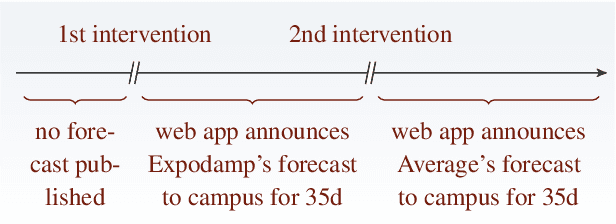
We study data-driven assistants that provide congestion forecasts to users of crowded facilities (roads, cafeterias, etc.), to support coordination between them. Having multiple agents and feedback loops from predictions to outcomes, new problems arise in terms of choosing (1) objective and (2) algorithms for such assistants. Addressing (1), we pick classical prediction accuracy as objective and establish general conditions under which optimizing it is equivalent to "solving" the coordination problem in an idealized game-theoretic sense -- selecting a certain Bayesian Nash equilibrium (BNE). Then we prove the existence of an assistant-based "solution" even for large-scale (nonatomic), aggregated settings. This entails a new BNE existence result. Addressing (2), we propose an exponential smoothing-based algorithm on time series data. We prove its optimality w.r.t.\ the prediction objective under a state-space model for the large-scale setting. We also provide a proof-of-concept algorithm and convergence guarantees for a small-scale, non-aggregated setting. We validate our algorithm in a large-scale experiment in a real cafeteria.
Enhancing Sequence-to-Sequence Neural Lemmatization with External Resources
Jan 28, 2021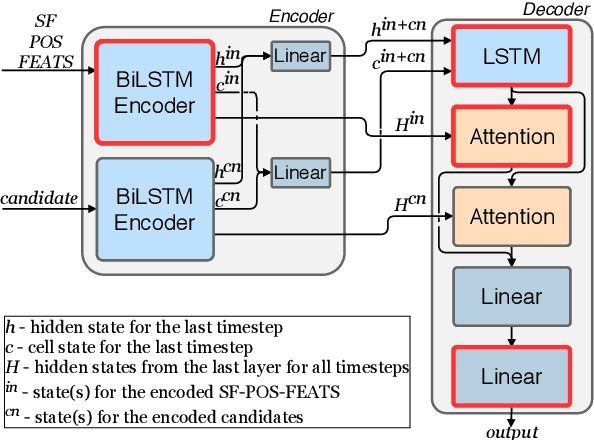
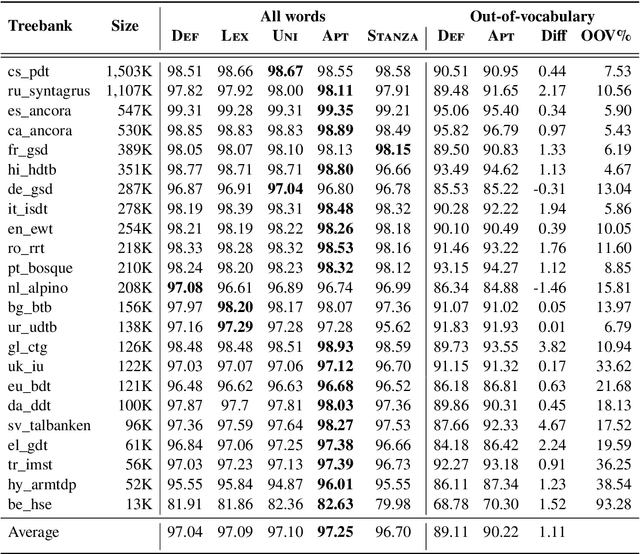
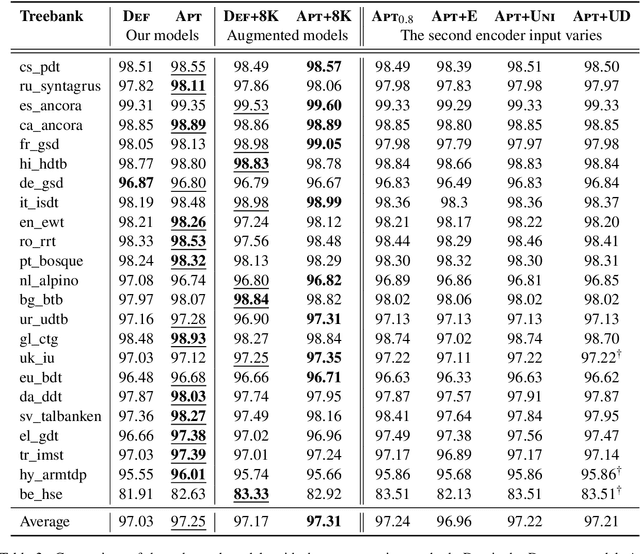
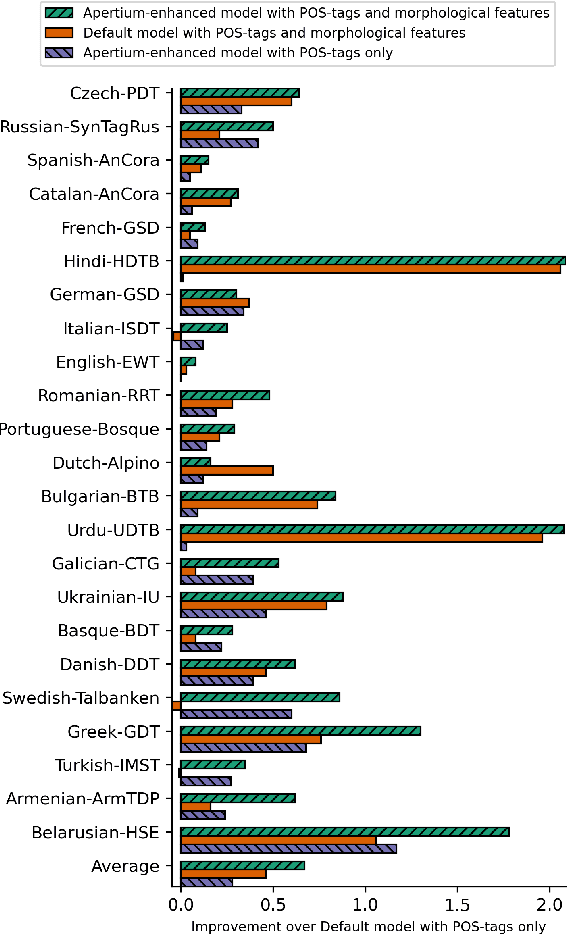
We propose a novel hybrid approach to lemmatization that enhances the seq2seq neural model with additional lemmas extracted from an external lexicon or a rule-based system. During training, the enhanced lemmatizer learns both to generate lemmas via a sequential decoder and copy the lemma characters from the external candidates supplied during run-time. Our lemmatizer enhanced with candidates extracted from the Apertium morphological analyzer achieves statistically significant improvements compared to baseline models not utilizing additional lemma information, achieves an average accuracy of 97.25% on a set of 23 UD languages, which is 0.55% higher than obtained with the Stanford Stanza model on the same set of languages. We also compare with other methods of integrating external data into lemmatization and show that our enhanced system performs considerably better than a simple lexicon extension method based on the Stanza system, and it achieves complementary improvements w.r.t. the data augmentation method.
Policy-Guided Heuristic Search with Guarantees
Mar 21, 2021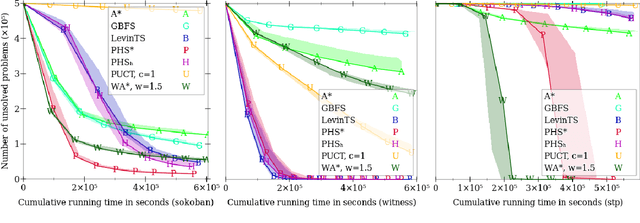
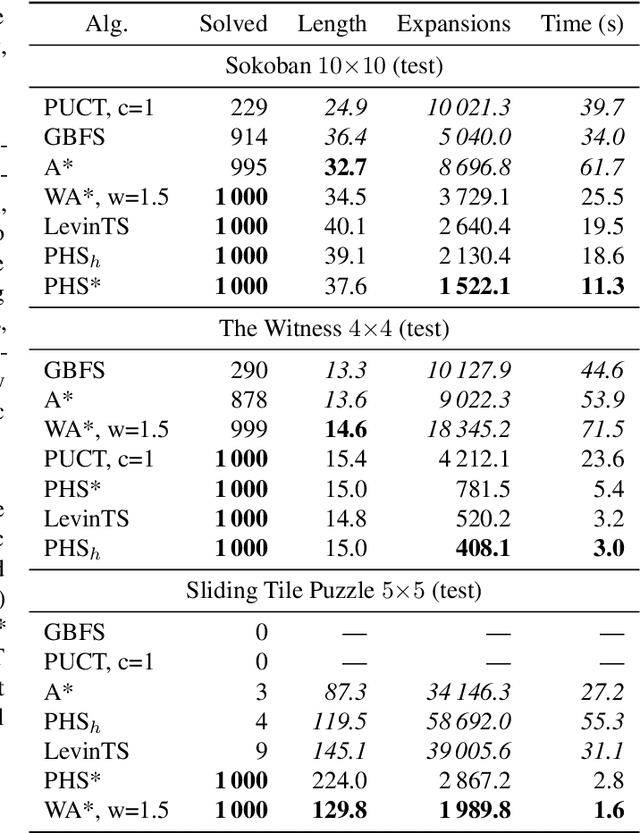


The use of a policy and a heuristic function for guiding search can be quite effective in adversarial problems, as demonstrated by AlphaGo and its successors, which are based on the PUCT search algorithm. While PUCT can also be used to solve single-agent deterministic problems, it lacks guarantees on its search effort and it can be computationally inefficient in practice. Combining the A* algorithm with a learned heuristic function tends to work better in these domains, but A* and its variants do not use a policy. Moreover, the purpose of using A* is to find solutions of minimum cost, while we seek instead to minimize the search loss (e.g., the number of search steps). LevinTS is guided by a policy and provides guarantees on the number of search steps that relate to the quality of the policy, but it does not make use of a heuristic function. In this work we introduce Policy-guided Heuristic Search (PHS), a novel search algorithm that uses both a heuristic function and a policy and has theoretical guarantees on the search loss that relates to both the quality of the heuristic and of the policy. We show empirically on the sliding-tile puzzle, Sokoban, and a puzzle from the commercial game `The Witness' that PHS enables the rapid learning of both a policy and a heuristic function and compares favorably with A*, Weighted A*, Greedy Best-First Search, LevinTS, and PUCT in terms of number of problems solved and search time in all three domains tested.
Task Programming: Learning Data Efficient Behavior Representations
Nov 27, 2020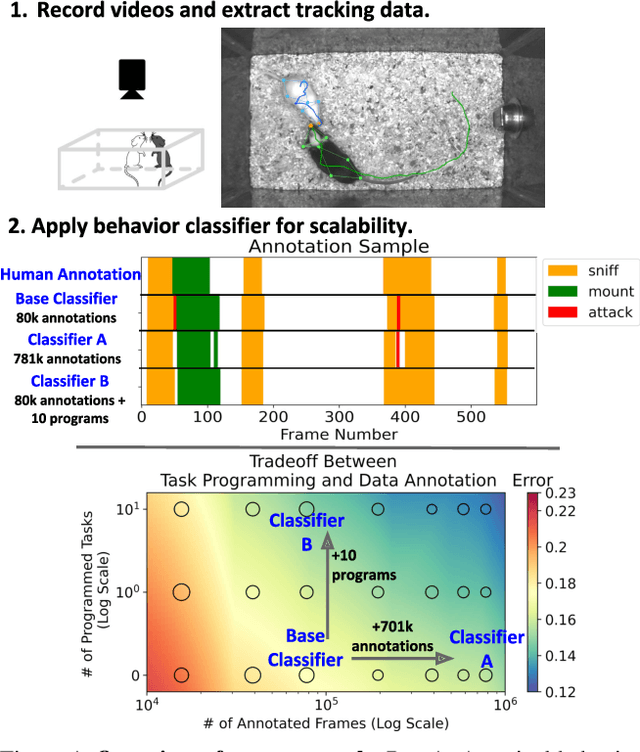
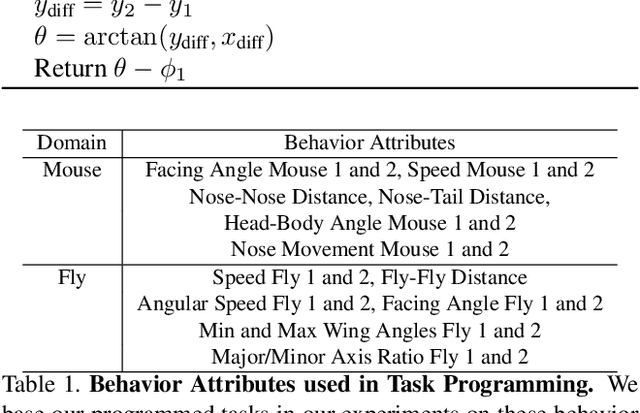
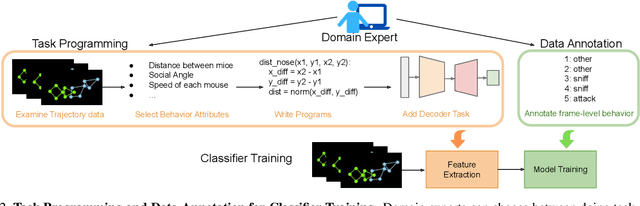
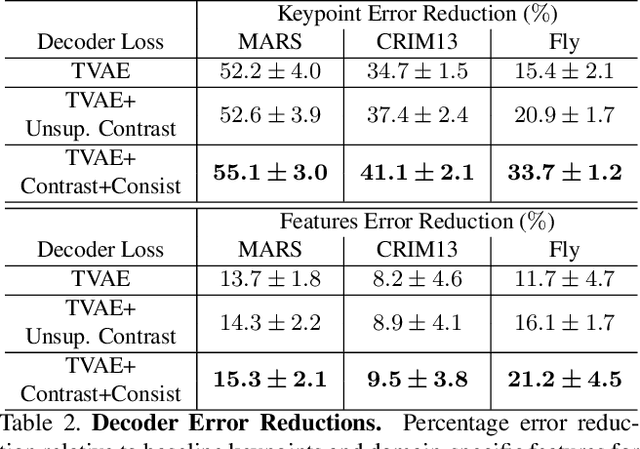
Specialized domain knowledge is often necessary to accurately annotate training sets for in-depth analysis, but can be burdensome and time-consuming to acquire from domain experts. This issue arises prominently in automated behavior analysis, in which agent movements or actions of interest are detected from video tracking data. To reduce annotation effort, we present TREBA: a method to learn annotation-sample efficient trajectory embedding for behavior analysis, based on multi-task self-supervised learning. The tasks in our method can be efficiently engineered by domain experts through a process we call "task programming", which uses programs to explicitly encode structured knowledge from domain experts. Total domain expert effort can be reduced by exchanging data annotation time for the construction of a small number of programmed tasks. We evaluate this trade-off using data from behavioral neuroscience, in which specialized domain knowledge is used to identify behaviors. We present experimental results in three datasets across two domains: mice and fruit flies. Using embeddings from TREBA, we reduce annotation burden by up to a factor of 10 without compromising accuracy compared to state-of-the-art features. Our results thus suggest that task programming can be an effective way to reduce annotation effort for domain experts.
Beyond ANN: Exploiting Structural Knowledge for Efficient Place Recognition
Mar 15, 2021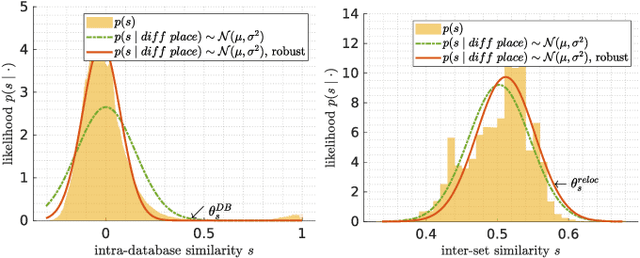
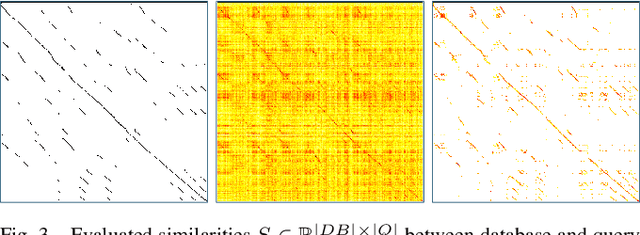
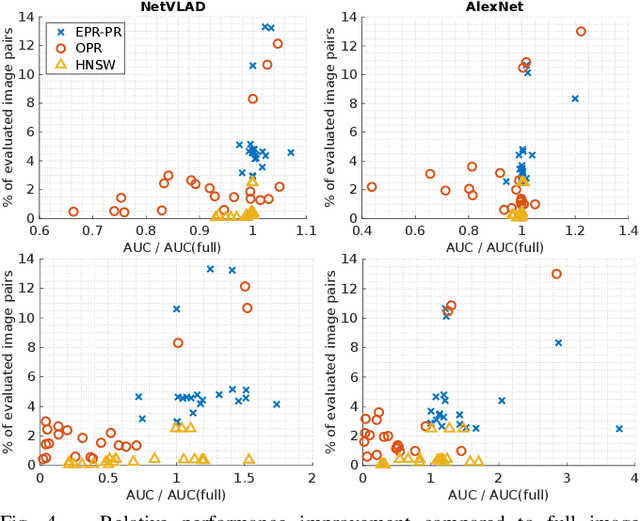
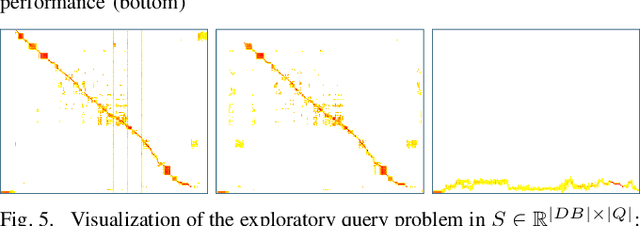
Visual place recognition is the task of recognizing same places of query images in a set of database images, despite potential condition changes due to time of day, weather or seasons. It is important for loop closure detection in SLAM and candidate selection for global localization. Many approaches in the literature perform computationally inefficient full image comparisons between queries and all database images. There is still a lack of suited methods for efficient place recognition that allow a fast, sparse comparison of only the most promising image pairs without any loss in performance. While this is partially given by ANN-based methods, they trade speed for precision and additional memory consumption, and many cannot find arbitrary numbers of matching database images in case of loops in the database. In this paper, we propose a novel fast sequence-based method for efficient place recognition that can be applied online. It uses relocalization to recover from sequence losses, and exploits usually available but often unused intra-database similarities for a potential detection of all matching database images for each query in case of loops or stops in the database. We performed extensive experimental evaluations over five datasets and 21 sequence combinations, and show that our method outperforms two state-of-the-art approaches and even full image comparisons in many cases, while providing a good tradeoff between performance and percentage of evaluated image pairs. Source code for Matlab will be provided with publication of this paper.
Learning Structures in Earth Observation Data with Gaussian Processes
Dec 22, 2020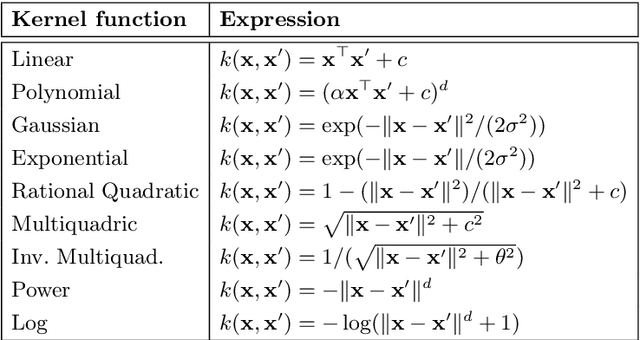
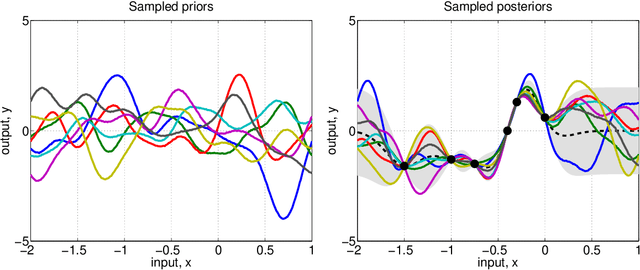
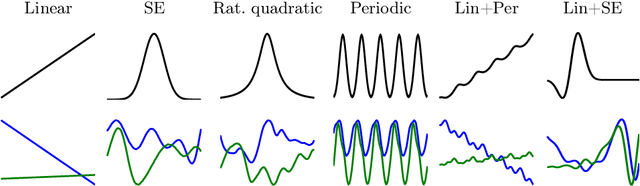
Gaussian Processes (GPs) has experienced tremendous success in geoscience in general and for bio-geophysical parameter retrieval in the last years. GPs constitute a solid Bayesian framework to formulate many function approximation problems consistently. This paper reviews the main theoretical GP developments in the field. We review new algorithms that respect the signal and noise characteristics, that provide feature rankings automatically, and that allow applicability of associated uncertainty intervals to transport GP models in space and time. All these developments are illustrated in the field of geoscience and remote sensing at a local and global scales through a set of illustrative examples.
OLED: One-Class Learned Encoder-Decoder Network with Adversarial Context Masking for Novelty Detection
Mar 27, 2021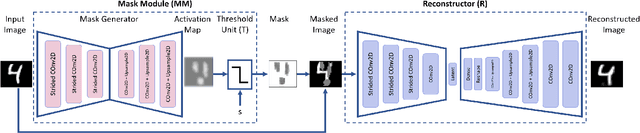
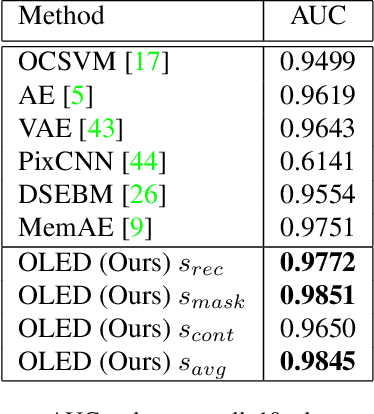

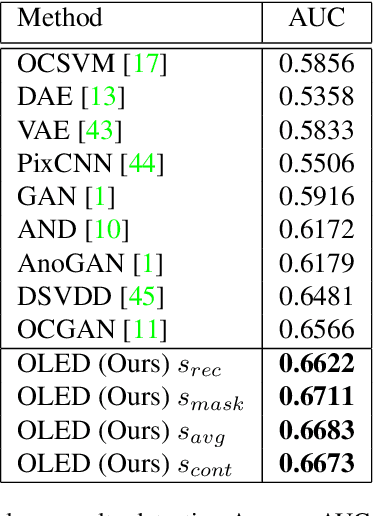
Novelty detection is the task of recognizing samples that do not belong to the distribution of the target class. During training, the novelty class is absent, preventing the use of traditional classification approaches. Deep autoencoders have been widely used as a base of many unsupervised novelty detection methods. In particular, context autoencoders have been successful in the novelty detection task because of the more effective representations they learn by reconstructing original images from randomly masked images. However, a significant drawback of context autoencoders is that random masking fails to consistently cover important structures of the input image, leading to suboptimal representations - especially for the novelty detection task. In this paper, to optimize input masking, we have designed a framework consisting of two competing networks, a Mask Module and a Reconstructor. The Mask Module is a convolutional autoencoder that learns to generate optimal masks that cover the most important parts of images. Alternatively, the Reconstructor is a convolutional encoder-decoder that aims to reconstruct unperturbed images from masked images. The networks are trained in an adversarial manner in which the Mask Module generates masks that are applied to images given to the Reconstructor. In this way, the Mask Module seeks to maximize the reconstruction error that the Reconstructor is minimizing. When applied to novelty detection, the proposed approach learns semantically richer representations compared to context autoencoders and enhances novelty detection at test time through more optimal masking. Novelty detection experiments on the MNIST and CIFAR-10 image datasets demonstrate the proposed approach's superiority over cutting-edge methods. In a further experiment on the UCSD video dataset for novelty detection, the proposed approach achieves state-of-the-art results.
The Adaptive Dynamic Programming Toolbox
Dec 29, 2020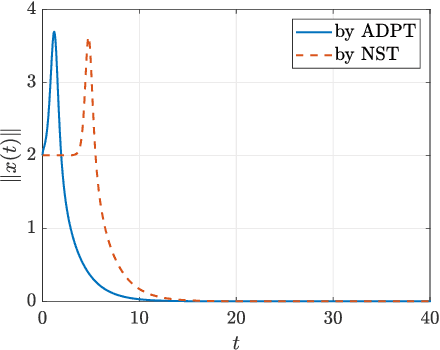
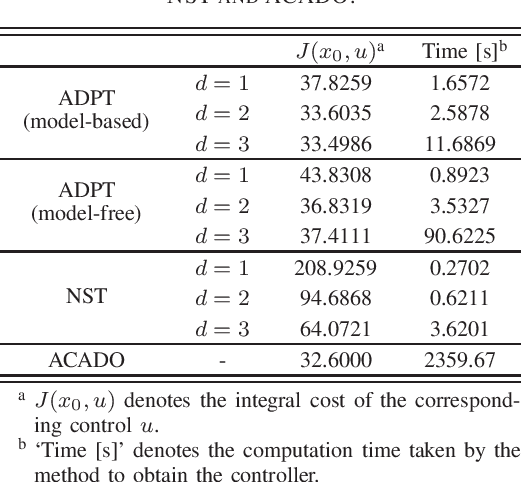


The paper develops the Adaptive Dynamic Programming Toolbox (ADPT), which solves optimal control problems for continuous-time nonlinear systems. Based on the adaptive dynamic programming technique, the ADPT computes optimal feedback controls from the system dynamics in the model-based working mode, or from measurements of trajectories of the system in the model-free working mode without the requirement of knowledge of the system model. Multiple options are provided such that the ADPT can accommodate various customized circumstances. Compared to other popular software toolboxes for optimal control, the ADPT enjoys its computational precision and speed, which is illustrated with its applications to a satellite attitude control problem.
A Multi-term and Multi-task Analyzing Framework for Affective Analysis in-the-wild
Oct 02, 2020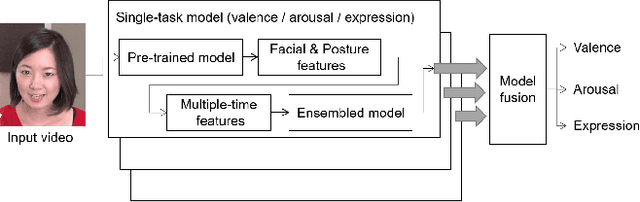
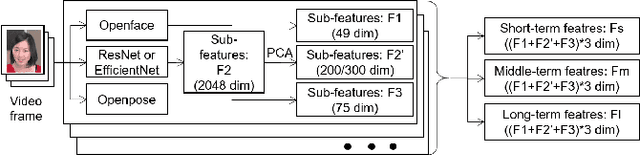
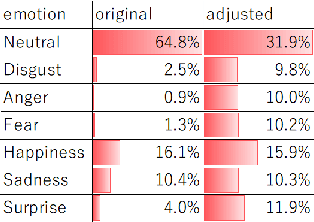
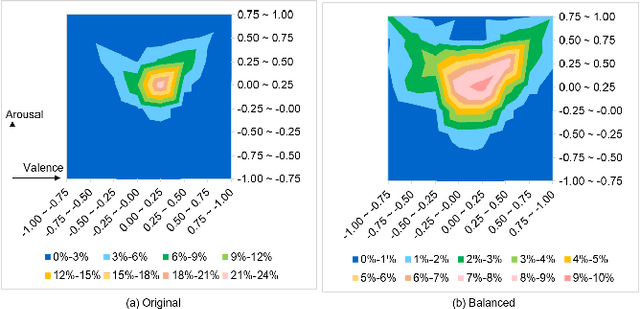
Human affective recognition is an important factor in human-computer interaction. However, the method development with in-the-wild data is not yet accurate enough for practical usage. In this paper, we introduce the affective recognition method focusing on valence-arousal (VA) and expression (EXP) that was submitted to the Affective Behavior Analysis in-the-wild (ABAW) 2020 Contest. Since we considered that affective behaviors have many observable features that have their own time frames, we introduced multiple optimized time windows (short-term, middle-term, and long-term) into our analyzing framework for extracting feature parameters from video data. Moreover, multiple modality data are used, including action units, head poses, gaze, posture, and ResNet 50 or Efficient NET features, and are optimized during the extraction of these features. Then, we generated affective recognition models for each time window and ensembled these models together. Also, we fussed the valence, arousal, and expression models together to enable the multi-task learning, considering the fact that the basic psychological states behind facial expressions are closely related to each another. In the validation set, our model achieved a valence-arousal score of 0.498 and a facial expression score of 0.471. These verification results reveal that our proposed framework can improve estimation accuracy and robustness effectively.