 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Control Flow Obfuscation for FJ using Continuation Passing
Dec 08, 2020
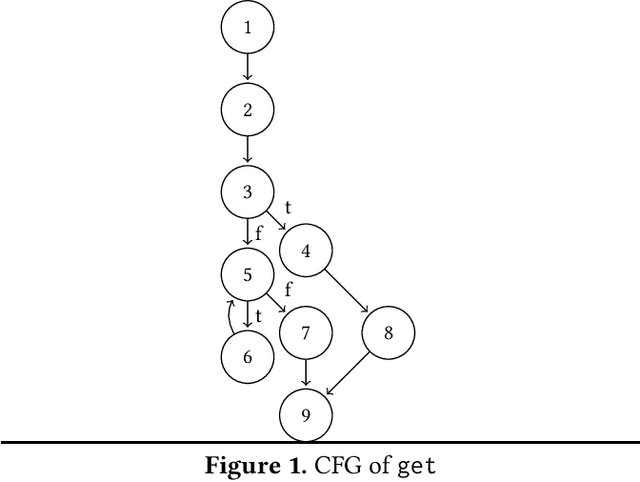
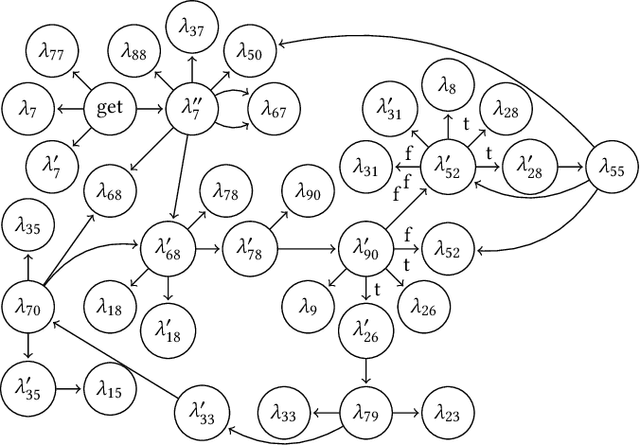


Control flow obfuscation deters software reverse engineering attempts by altering the program's control flow transfer. The alternation should not affect the software's run-time behaviour. In this paper, we propose a control flow obfuscation approach for FJ with exception handling. The approach is based on a source to source transformation using continuation passing style (CPS). We argue that the proposed CPS transformation causes malicious attacks using context insensitive static analysis and context sensitive analysis with fixed call string to lose precision.
A character representation enhanced on-device Intent Classification
Jan 12, 2021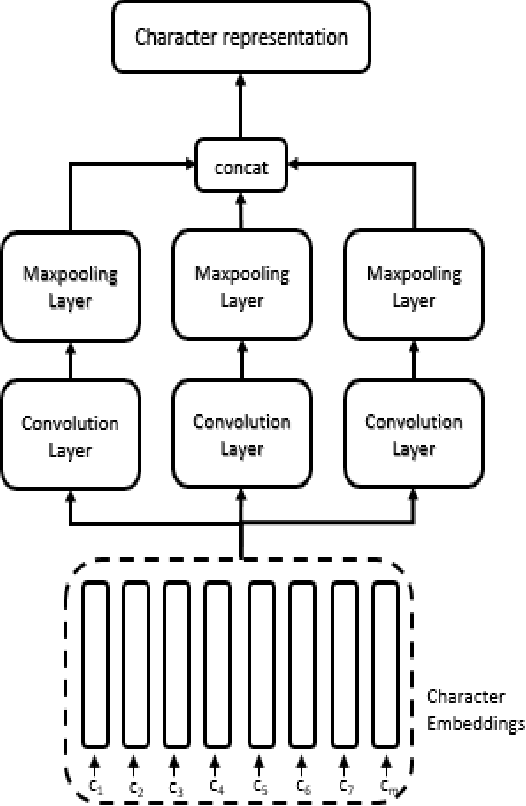
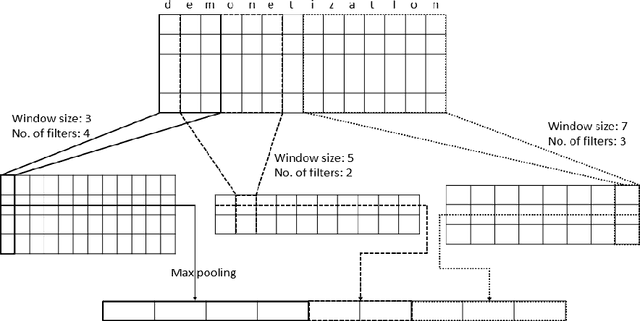

Intent classification is an important task in natural language understanding systems. Existing approaches have achieved perfect scores on the benchmark datasets. However they are not suitable for deployment on low-resource devices like mobiles, tablets, etc. due to their massive model size. Therefore, in this paper, we present a novel light-weight architecture for intent classification that can run efficiently on a device. We use character features to enrich the word representation. Our experiments prove that our proposed model outperforms existing approaches and achieves state-of-the-art results on benchmark datasets. We also report that our model has tiny memory footprint of ~5 MB and low inference time of ~2 milliseconds, which proves its efficiency in a resource-constrained environment.
Automated and Autonomous Experiment in Electron and Scanning Probe Microscopy
Mar 22, 2021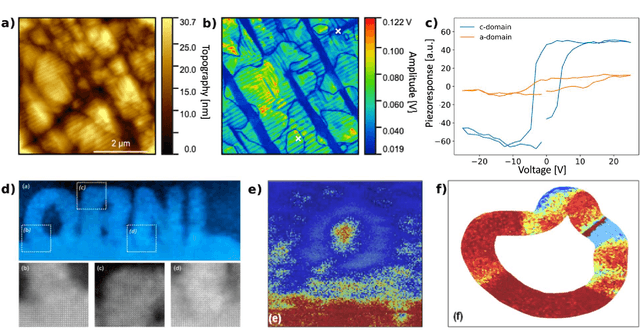
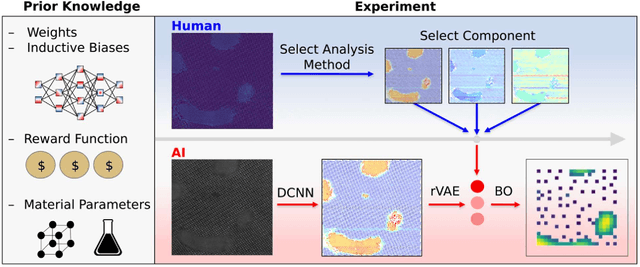
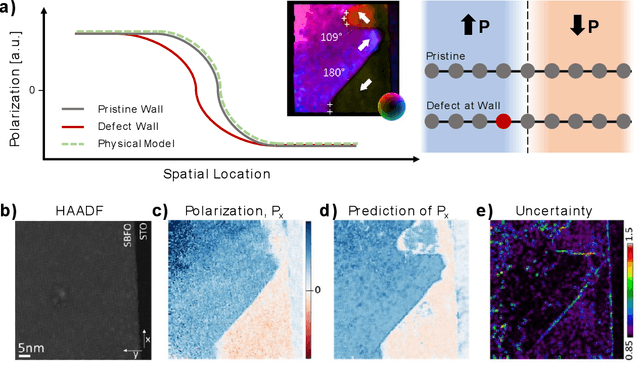
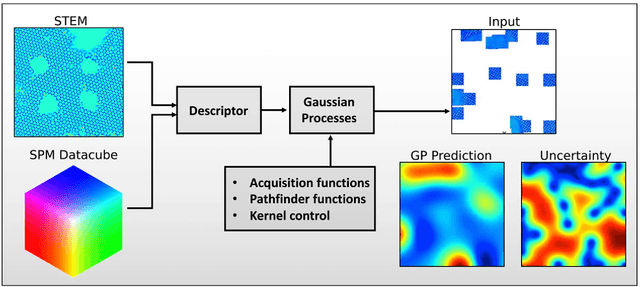
Machine learning and artificial intelligence (ML/AI) are rapidly becoming an indispensable part of physics research, with domain applications ranging from theory and materials prediction to high-throughput data analysis. In parallel, the recent successes in applying ML/AI methods for autonomous systems from robotics through self-driving cars to organic and inorganic synthesis are generating enthusiasm for the potential of these techniques to enable automated and autonomous experiment (AE) in imaging. Here, we aim to analyze the major pathways towards AE in imaging methods with sequential image formation mechanisms, focusing on scanning probe microscopy (SPM) and (scanning) transmission electron microscopy ((S)TEM). We argue that automated experiments should necessarily be discussed in a broader context of the general domain knowledge that both informs the experiment and is increased as the result of the experiment. As such, this analysis should explore the human and ML/AI roles prior to and during the experiment, and consider the latencies, biases, and knowledge priors of the decision-making process. Similarly, such discussion should include the limitations of the existing imaging systems, including intrinsic latencies, non-idealities and drifts comprising both correctable and stochastic components. We further pose that the role of the AE in microscopy is not the exclusion of human operators (as is the case for autonomous driving), but rather automation of routine operations such as microscope tuning, etc., prior to the experiment, and conversion of low latency decision making processes on the time scale spanning from image acquisition to human-level high-order experiment planning.
Modeling Complex Spatial Patterns with Temporal Features via Heterogenous Graph Embedding Networks
Sep 11, 2020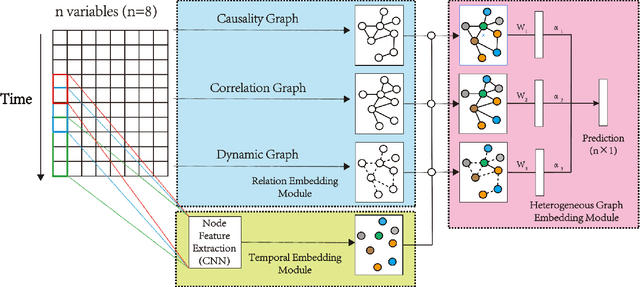
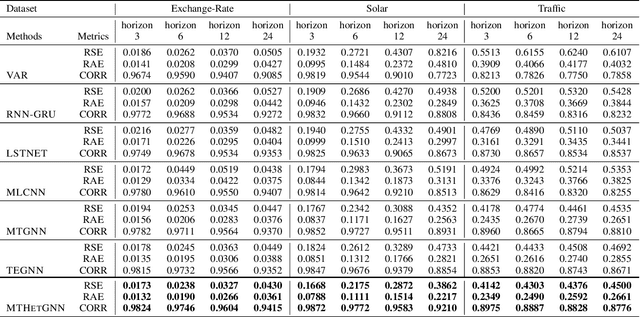
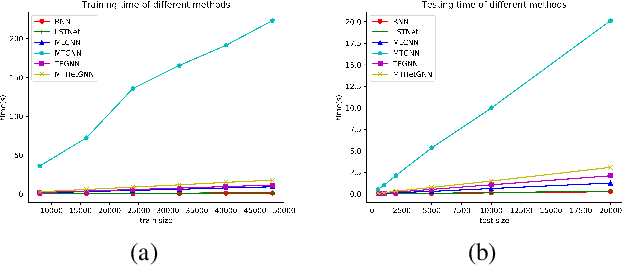
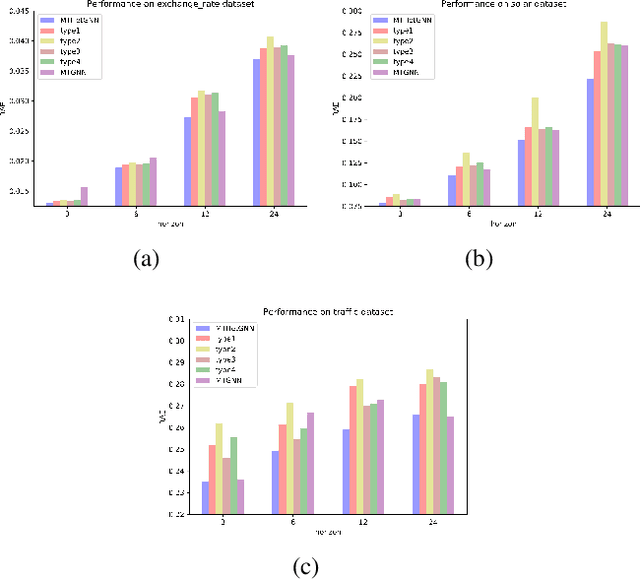
Multivariate time series (MTS) forecasting is an important problem in many fields. Accurate forecasting results can effectively help decision-making. Variables in MTS have rich relations among each other and the value of each variable in MTS depends both on its historical values and on other variables. These rich relations can be static and predictable or dynamic and latent. Existing methods do not incorporate these rich relational information into modeling or only model certain relation among MTS variables. To jointly model rich relations among variables and temporal dependencies within the time series, a novel end-to-end deep learning model, termed Multivariate Time Series Forecasting via Heterogenous Graph Neural Networks (MTHetGNN) is proposed in this paper. To characterize rich relations among variables, a relation embedding module is introduced in our model, where each variable is regarded as a graph node and each type of edge represents a specific relationship among variables or one specific dynamic update strategy to model the latent dependency among variables. In addition, convolutional neural network (CNN) filters with different perception scales are used for time series feature extraction, which is used to generate the feature of each node. Finally, heterogenous graph neural networks are adopted to handle the complex structural information generated by temporal embedding module and relation embedding module. Three benchmark datasets from the real world are used to evaluate the proposed MTHetGNN and the comprehensive experiments show that MTHetGNN achieves state-of-the-art results in MTS forecasting task.
Geometric Exploration for Online Control
Oct 25, 2020We study the control of an \emph{unknown} linear dynamical system under general convex costs. The objective is minimizing regret vs. the class of disturbance-feedback-controllers, which encompasses all stabilizing linear-dynamical-controllers. In this work, we first consider the case of known cost functions, for which we design the first polynomial-time algorithm with $n^3\sqrt{T}$-regret, where $n$ is the dimension of the state plus the dimension of control input. The $\sqrt{T}$-horizon dependence is optimal, and improves upon the previous best known bound of $T^{2/3}$. The main component of our algorithm is a novel geometric exploration strategy: we adaptively construct a sequence of barycentric spanners in the policy space. Second, we consider the case of bandit feedback, for which we give the first polynomial-time algorithm with $poly(n)\sqrt{T}$-regret, building on Stochastic Bandit Convex Optimization.
Comparison of Privacy-Preserving Distributed Deep Learning Methods in Healthcare
Dec 23, 2020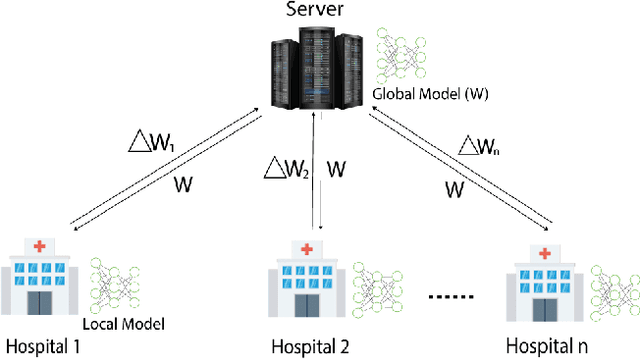
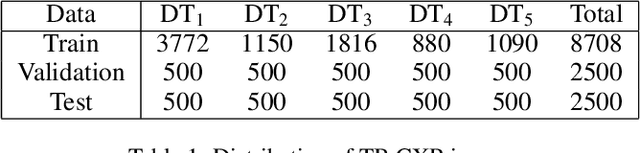
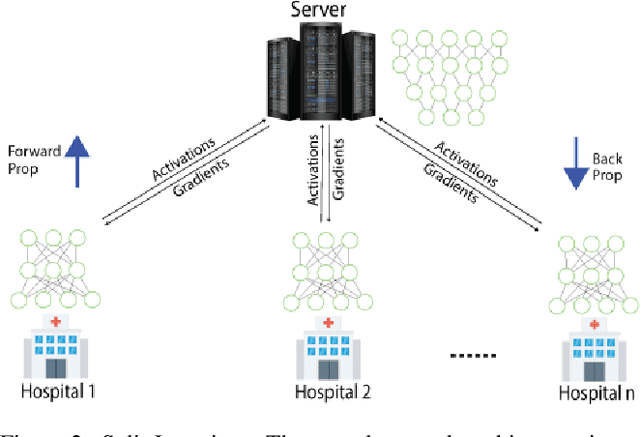
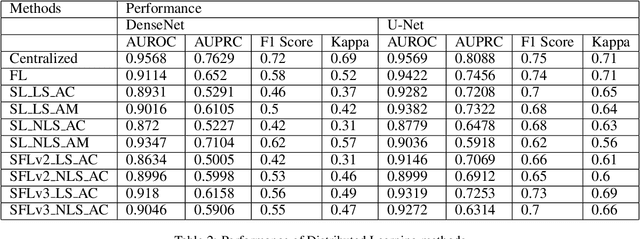
In this paper, we compare three privacy-preserving distributed learning techniques: federated learning, split learning, and SplitFed. We use these techniques to develop binary classification models for detecting tuberculosis from chest X-rays and compare them in terms of classification performance, communication and computational costs, and training time. We propose a novel distributed learning architecture called SplitFedv3, which performs better than split learning and SplitFedv2 in our experiments. We also propose alternate mini-batch training, a new training technique for split learning, that performs better than alternate client training, where clients take turns to train a model.
Real Time Lidar and Radar High-Level Fusion for Obstacle Detection and Tracking with evaluation on a ground truth
Jul 30, 2018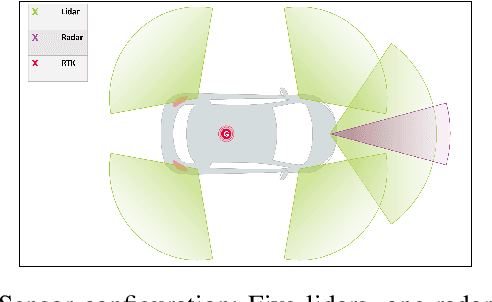
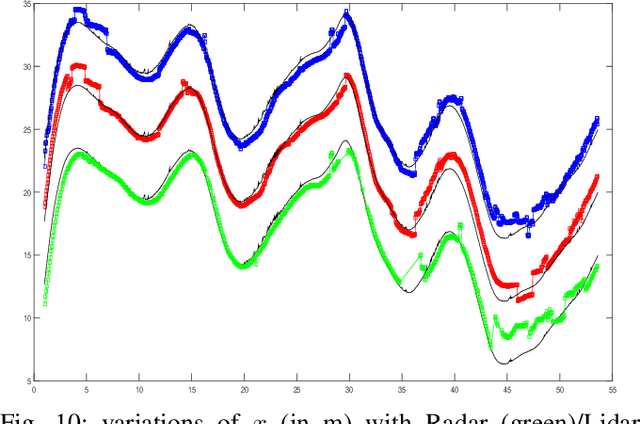
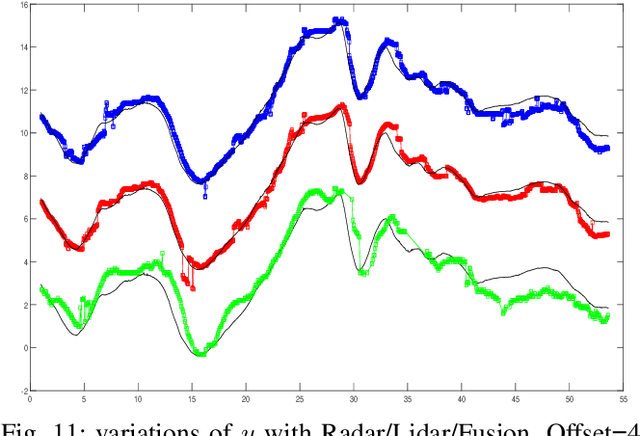
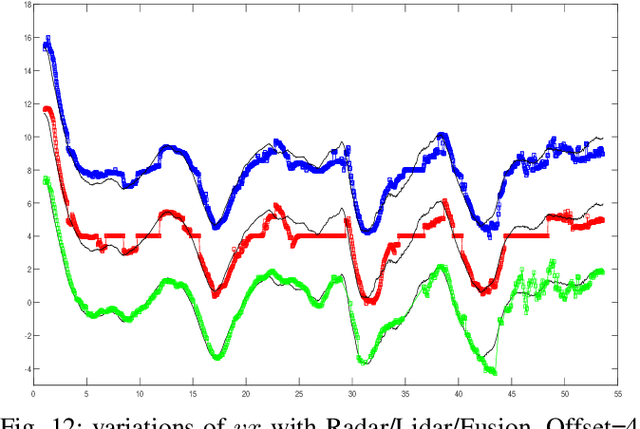
- Both Lidars and Radars are sensors for obstacle detection. While Lidars are very accurate on obstacles positions and less accurate on their velocities, Radars are more precise on obstacles velocities and less precise on their positions. Sensor fusion between Lidar and Radar aims at improving obstacle detection using advantages of the two sensors. The present paper proposes a real-time Lidar/Radar data fusion algorithm for obstacle detection and tracking based on the global nearest neighbour standard filter (GNN). This algorithm is implemented and embedded in an automative vehicle as a component generated by a real-time multisensor software. The benefits of data fusion comparing with the use of a single sensor are illustrated through several tracking scenarios (on a highway and on a bend) and using real-time kinematic sensors mounted on the ego and tracked vehicles as a ground truth.
GTEA: Representation Learning for Temporal Interaction Graphs via Edge Aggregation
Sep 11, 2020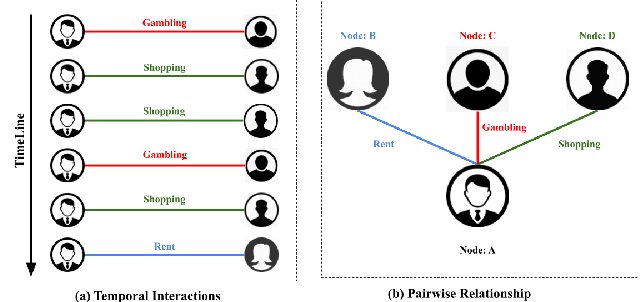

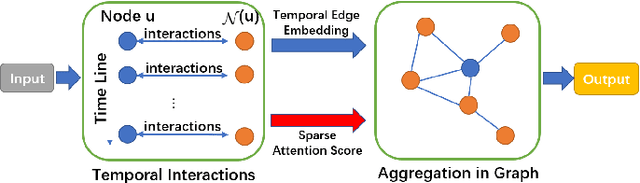
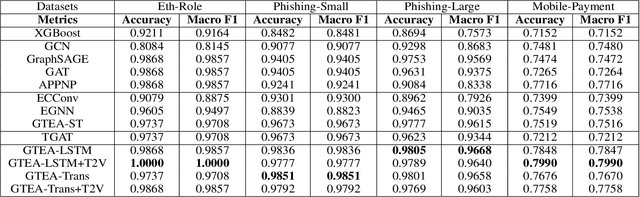
We consider the problem of representation learning for temporal interaction graphs where a network of entities with complex interactions over an extended period of time is modeled as a graph with a rich set of node and edge attributes. In particular, an edge between a node-pair within the graph corresponds to a multi-dimensional time-series. To fully capture and model the dynamics of the network, we propose GTEA, a framework of representation learning for temporal interaction graphs with per-edge time-based aggregation. Under GTEA, a Graph Neural Network (GNN) is integrated with a state-of-the-art sequence model, such as LSTM, Transformer and their time-aware variants. The sequence model generates edge embeddings to encode temporal interaction patterns between each pair of nodes, while the GNN-based backbone learns the topological dependencies and relationships among different nodes. GTEA also incorporates a sparsityinducing self-attention mechanism to distinguish and focus on the more important neighbors of each node during the aggregation process. By capturing temporal interactive dynamics together with multi-dimensional node and edge attributes in a network, GTEA can learn fine-grained representations for a temporal interaction graph to enable or facilitate other downstream data analytic tasks. Experimental results show that GTEA outperforms state-of-the-art schemes including GraphSAGE, APPNP, and TGAT by delivering higher accuracy (100.00%, 98.51%, 98.05% ,79.90%) and macro-F1 score (100.00%, 98.51%, 96.68% ,79.90%) over four largescale real-world datasets for binary/ multi-class node classification.
A Framework for Fast Scalable BNN Inference using Googlenet and Transfer Learning
Jan 05, 2021

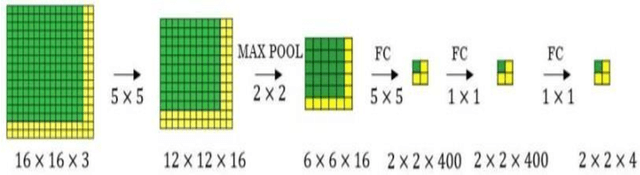
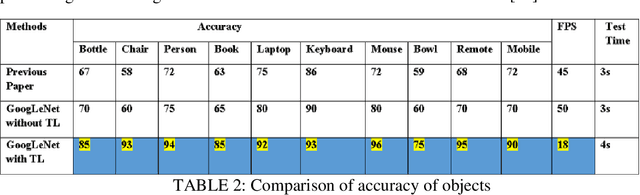
Efficient and accurate object detection in video and image analysis is one of the major beneficiaries of the advancement in computer vision systems with the help of deep learning. With the aid of deep learning, more powerful tools evolved, which are capable to learn high-level and deeper features and thus can overcome the existing problems in traditional architectures of object detection algorithms. The work in this thesis aims to achieve high accuracy in object detection with good real-time performance. In the area of computer vision, a lot of research is going into the area of detection and processing of visual information, by improving the existing algorithms. The binarized neural network has shown high performance in various vision tasks such as image classification, object detection, and semantic segmentation. The Modified National Institute of Standards and Technology database (MNIST), Canadian Institute for Advanced Research (CIFAR), and Street View House Numbers (SVHN) datasets are used which is implemented using a pre-trained convolutional neural network (CNN) that is 22 layers deep. Supervised learning is used in the work, which classifies the particular dataset with the proper structure of the model. In still images, to improve accuracy, Googlenet is used. The final layer of the Googlenet is replaced with the transfer learning to improve the accuracy of the Googlenet. At the same time, the accuracy in moving images can be maintained by transfer learning techniques. Hardware is the main backbone for any model to obtain faster results with a large number of datasets. Here, Nvidia Jetson Nano is used which is a graphics processing unit (GPU), that can handle a large number of computations in the process of object detection. Results show that the accuracy of objects detected by the transfer learning method is more when compared to the existing methods.
Imponderous Net for Facial Expression Recognition in the Wild
Mar 28, 2021

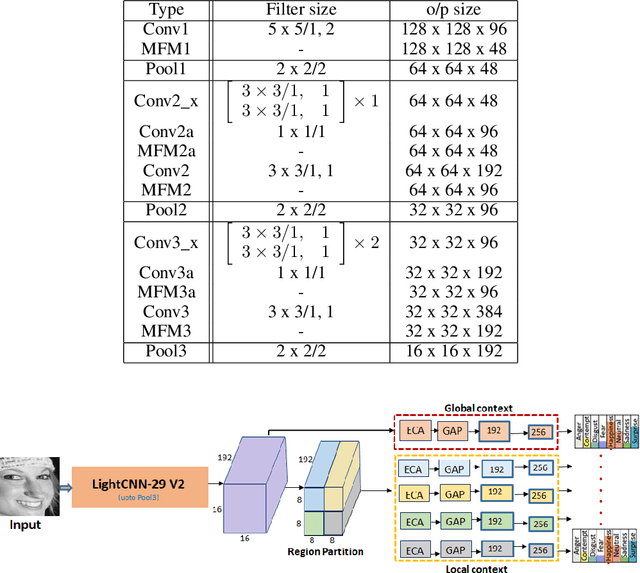
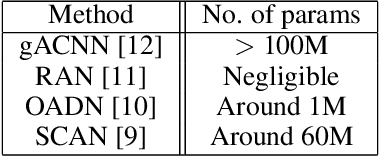
Since the renaissance of deep learning (DL), facial expression recognition (FER) has received a lot of interest, with continual improvement in the performance. Hand-in-hand with performance, new challenges have come up. Modern FER systems deal with face images captured under uncontrolled conditions (also called in-the-wild scenario) including occlusions and pose variations. They successfully handle such conditions using deep networks that come with various components like transfer learning, attention mechanism and local-global context extractor. However, these deep networks are highly complex with large number of parameters, making them unfit to be deployed in real scenarios. Is it possible to build a light-weight network that can still show significantly good performance on FER under in-the-wild scenario? In this work, we methodically build such a network and call it as Imponderous Net. We leverage on the aforementioned components of deep networks for FER, and analyse, carefully choose and fit them to arrive at Imponderous Net. Our Imponderous Net is a low calorie net with only 1.45M parameters, which is almost 50x less than that of a state-of-the-art (SOTA) architecture. Further, during inference, it can process at the real time rate of 40 frames per second (fps) in an intel-i7 cpu. Though it is low calorie, it is still power packed in its performance, overpowering other light-weight architectures and even few high capacity architectures. Specifically, Imponderous Net reports 87.09\%, 88.17\% and 62.06\% accuracies on in-the-wild datasets RAFDB, FERPlus and AffectNet respectively. It also exhibits superior robustness under occlusions and pose variations in comparison to other light-weight architectures from the literature.