 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Quantum Generative Adversarial Networks in a Continuous-Variable Architecture to Simulate High Energy Physics Detectors
Jan 26, 2021
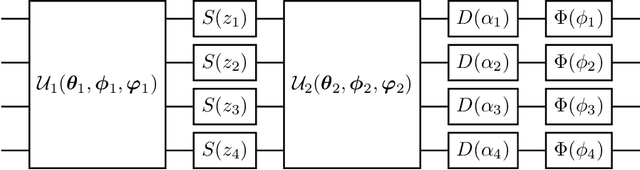
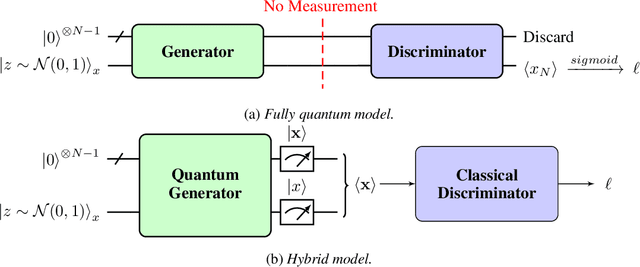
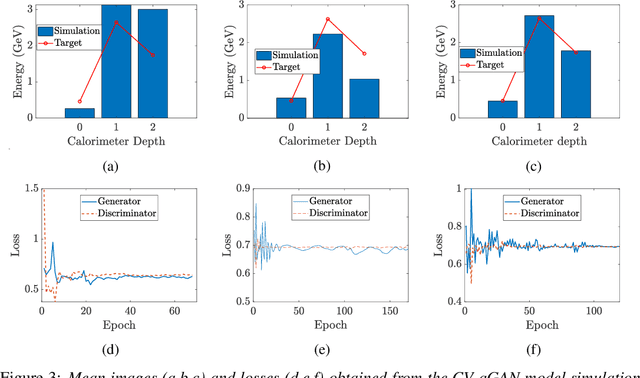
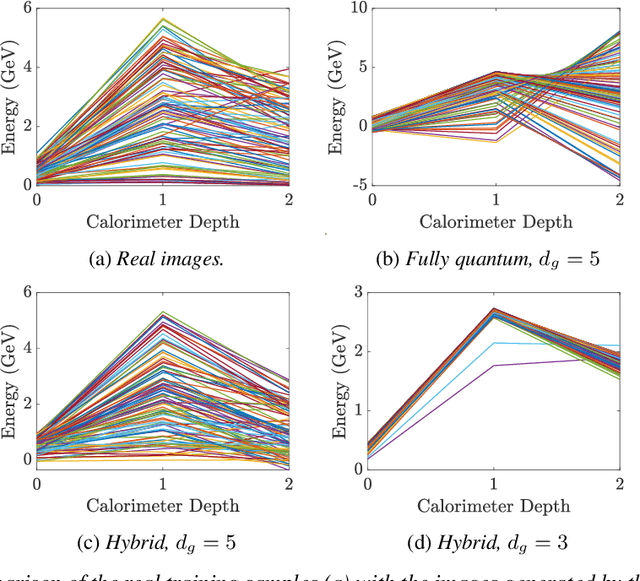
Deep Neural Networks (DNNs) come into the limelight in High Energy Physics (HEP) in order to manipulate the increasing amount of data encountered in the next generation of accelerators. Recently, the HEP community has suggested Generative Adversarial Networks (GANs) to replace traditional time-consuming Geant4 simulations based on the Monte Carlo method. In parallel with advances in deep learning, intriguing studies have been conducted in the last decade on quantum computing, including the Quantum GAN model suggested by IBM. However, this model is limited in learning a probability distribution over discrete variables, while we initially aim to reproduce a distribution over continuous variables in HEP. We introduce and analyze a new prototype of quantum GAN (qGAN) employed in continuous-variable (CV) quantum computing, which encodes quantum information in a continuous physical observable. Two CV qGAN models with a quantum and a classical discriminator have been tested to reproduce calorimeter outputs in a reduced size, and their advantages and limitations are discussed.
SecSens: Secure State Estimation with Application to Localization and Time Synchronization
Jan 22, 2018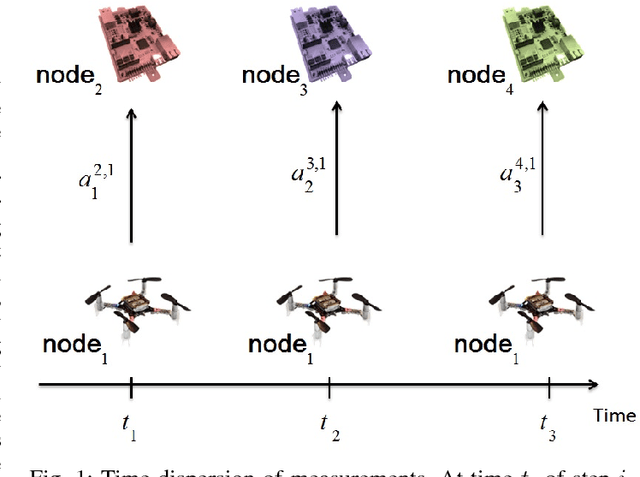
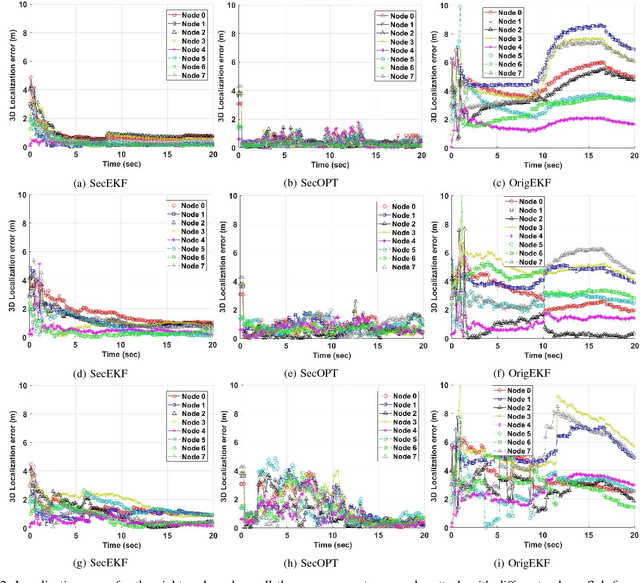
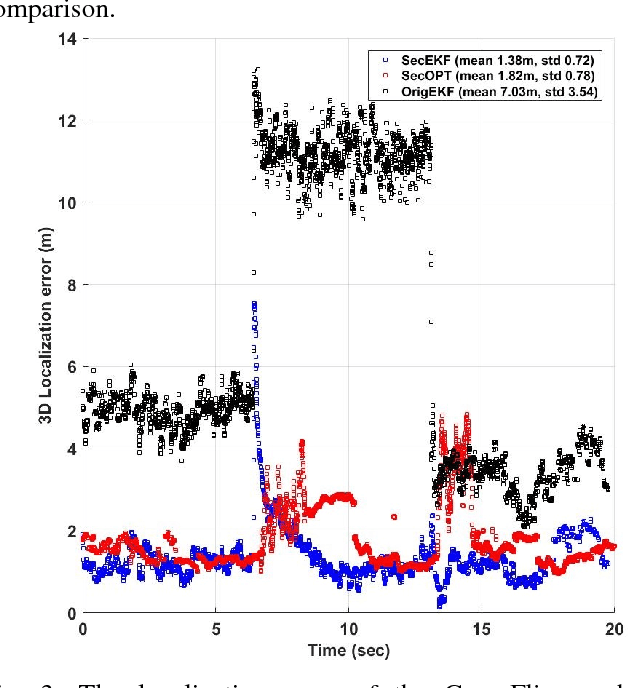
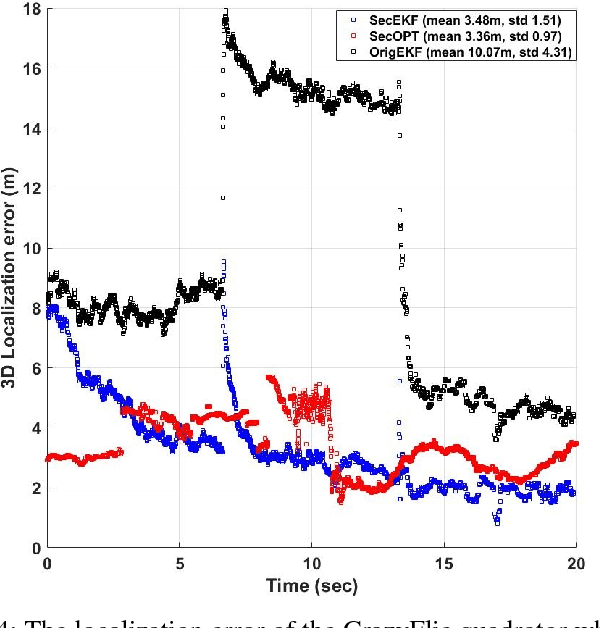
Research evidence in Cyber-Physical Systems (CPS) shows that the introduced tight coupling of information technology with physical sensing and actuation leads to more vulnerability and security weaknesses. But, the traditional security protection mechanisms of CPS focus on data encryption while neglecting the sensors which are vulnerable to attacks in the physical domain. Accordingly, researchers attach utmost importance to the problem of state estimation in the presence of sensor attacks. In this work, we present SecSens, a novel approach for secure nonlinear state estimation in the presence of modeling and measurement noise. SecSens consists of two independent algorithms, namely, SecEKF and SecOPT, which are based on Extended Kalman Filter and Maximum Likelihood Estimation, respectively. We adopt a holistic approach to introduce security awareness among state estimation algorithms without requiring specialized hardware, or cryptographic techniques. We apply SecSens to securely localize and time synchronize networked mobile devices. SecSens provides good performance at run-time several order of magnitude faster than the state of art solutions under the presence of powerful attacks. Our algorithms are evaluated on a testbed with static nodes and a mobile quadrotor all equipped with commercial ultra-wide band wireless devices.
LGNN: a Context-aware Line Segment Detector
Aug 13, 2020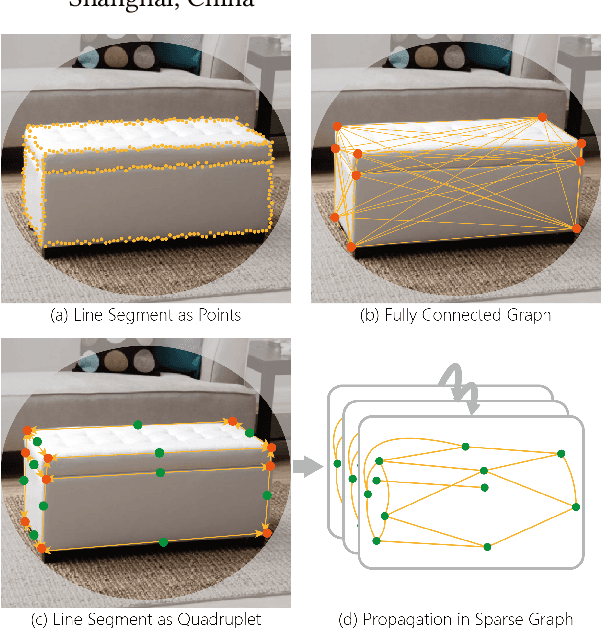
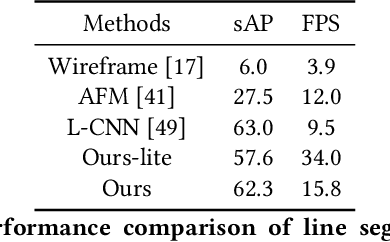
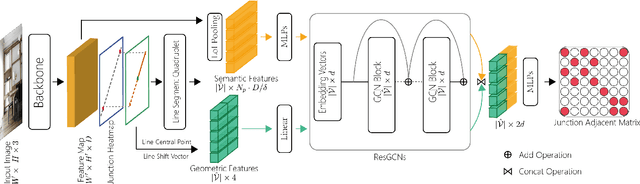

We present a novel real-time line segment detection scheme called Line Graph Neural Network (LGNN). Existing approaches require a computationally expensive verification or postprocessing step. Our LGNN employs a deep convolutional neural network (DCNN) for proposing line segment directly, with a graph neural network (GNN) module for reasoning their connectivities. Specifically, LGNN exploits a new quadruplet representation for each line segment where the GNN module takes the predicted candidates as vertexes and constructs a sparse graph to enforce structural context. Compared with the state-of-the-art, LGNN achieves near real-time performance without compromising accuracy. LGNN further enables time-sensitive 3D applications. When a 3D point cloud is accessible, we present a multi-modal line segment classification technique for extracting a 3D wireframe of the environment robustly and efficiently.
Multi-Task Self-Supervised Pre-Training for Music Classification
Feb 05, 2021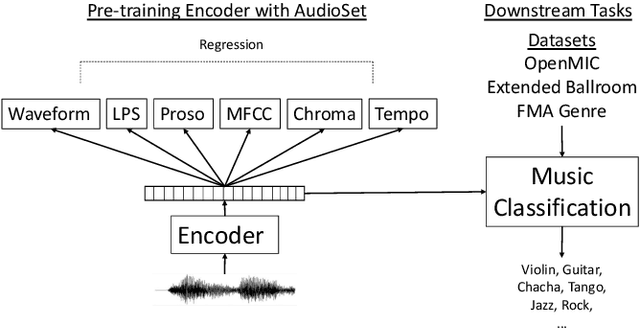
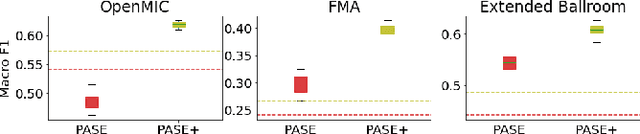
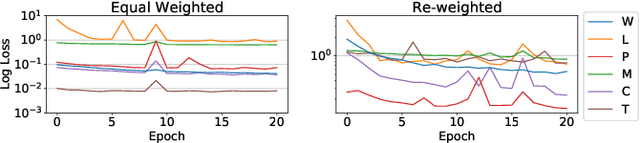
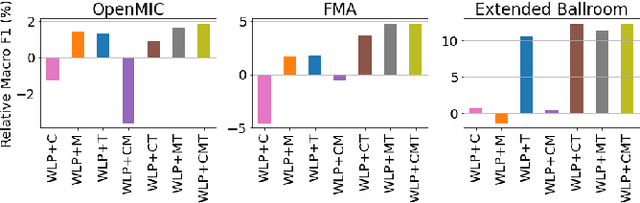
Deep learning is very data hungry, and supervised learning especially requires massive labeled data to work well. Machine listening research often suffers from limited labeled data problem, as human annotations are costly to acquire, and annotations for audio are time consuming and less intuitive. Besides, models learned from labeled dataset often embed biases specific to that particular dataset. Therefore, unsupervised learning techniques become popular approaches in solving machine listening problems. Particularly, a self-supervised learning technique utilizing reconstructions of multiple hand-crafted audio features has shown promising results when it is applied to speech domain such as emotion recognition and automatic speech recognition (ASR). In this paper, we apply self-supervised and multi-task learning methods for pre-training music encoders, and explore various design choices including encoder architectures, weighting mechanisms to combine losses from multiple tasks, and worker selections of pretext tasks. We investigate how these design choices interact with various downstream music classification tasks. We find that using various music specific workers altogether with weighting mechanisms to balance the losses during pre-training helps improve and generalize to the downstream tasks.
New Riemannian preconditioned algorithms for tensor completion via polyadic decomposition
Jan 26, 2021
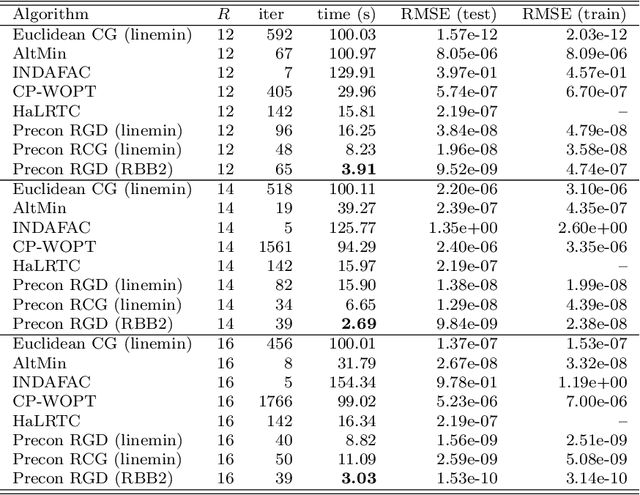
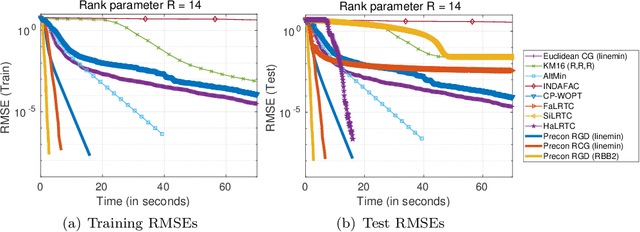
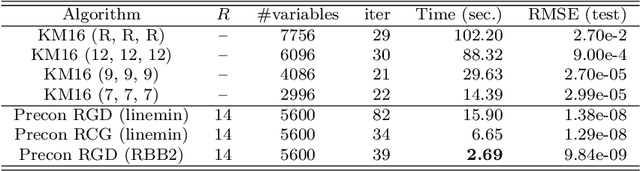
We propose new Riemannian preconditioned algorithms for low-rank tensor completion via the polyadic decomposition of a tensor. These algorithms exploit a non-Euclidean metric on the product space of the factor matrices of the low-rank tensor in the polyadic decomposition form. This new metric is designed using an approximation of the diagonal blocks of the Hessian of the tensor completion cost function, thus has a preconditioning effect on these algorithms. We prove that the proposed Riemannian gradient descent algorithm globally converges to a stationary point of the tensor completion problem, with convergence rate estimates using the $\L{}$ojasiewicz property. Numerical results on synthetic and real-world data suggest that the proposed algorithms are more efficient in memory and time compared to state-of-the-art algorithms. Moreover, the proposed algorithms display a greater tolerance for overestimated rank parameters in terms of the tensor recovery performance, thus enable a flexible choice of the rank parameter.
On Infusing Reachability-Based Safety Assurance within Planning Frameworks for Human-Robot Vehicle Interactions
Dec 06, 2020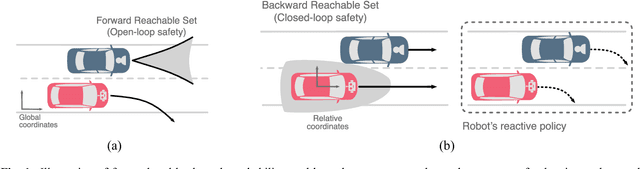

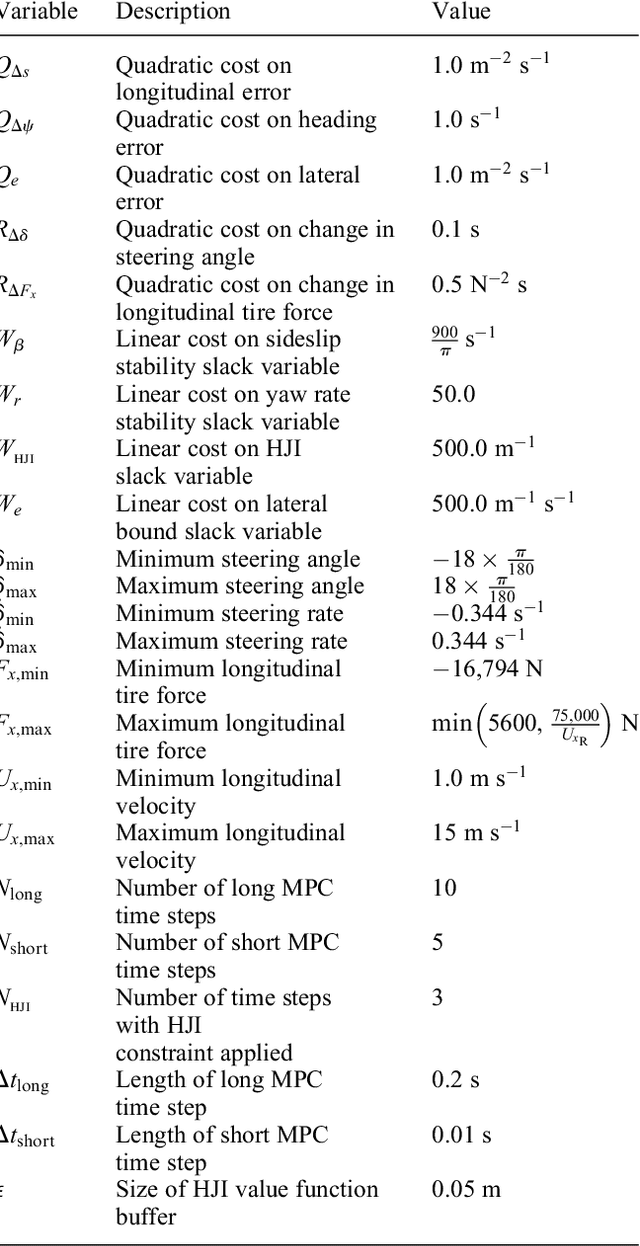
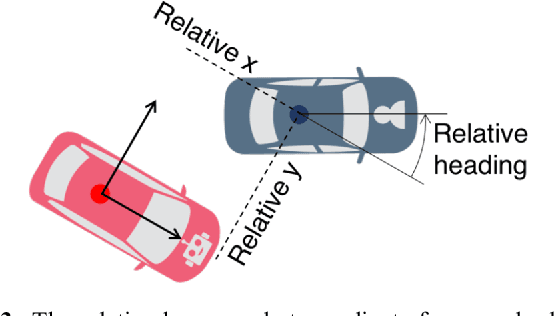
Action anticipation, intent prediction, and proactive behavior are all desirable characteristics for autonomous driving policies in interactive scenarios. Paramount, however, is ensuring safety on the road -- a key challenge in doing so is accounting for uncertainty in human driver actions without unduly impacting planner performance. This paper introduces a minimally-interventional safety controller operating within an autonomous vehicle control stack with the role of ensuring collision-free interaction with an externally controlled (e.g., human-driven) counterpart while respecting static obstacles such as a road boundary wall. We leverage reachability analysis to construct a real-time (100Hz) controller that serves the dual role of (i) tracking an input trajectory from a higher-level planning algorithm using model predictive control, and (ii) assuring safety by maintaining the availability of a collision-free escape maneuver as a persistent constraint regardless of whatever future actions the other car takes. A full-scale steer-by-wire platform is used to conduct traffic weaving experiments wherein two cars, initially side-by-side, must swap lanes in a limited amount of time and distance, emulating cars merging onto/off of a highway. We demonstrate that, with our control stack, the autonomous vehicle is able to avoid collision even when the other car defies the planner's expectations and takes dangerous actions, either carelessly or with the intent to collide, and otherwise deviates minimally from the planned trajectory to the extent required to maintain safety.
* arXiv admin note: text overlap with arXiv:1812.11315
Fast and Accurate $k$-means++ via Rejection Sampling
Dec 22, 2020



$k$-means++ \cite{arthur2007k} is a widely used clustering algorithm that is easy to implement, has nice theoretical guarantees and strong empirical performance. Despite its wide adoption, $k$-means++ sometimes suffers from being slow on large data-sets so a natural question has been to obtain more efficient algorithms with similar guarantees. In this paper, we present a near linear time algorithm for $k$-means++ seeding. Interestingly our algorithm obtains the same theoretical guarantees as $k$-means++ and significantly improves earlier results on fast $k$-means++ seeding. Moreover, we show empirically that our algorithm is significantly faster than $k$-means++ and obtains solutions of equivalent quality.
Classification and Feature Transformation with Fuzzy Cognitive Maps
Mar 08, 2021
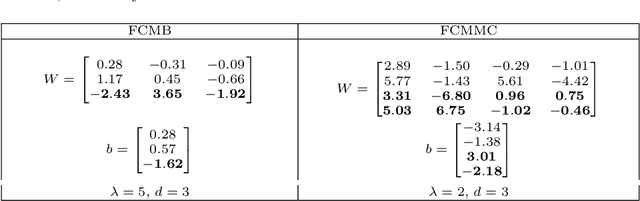
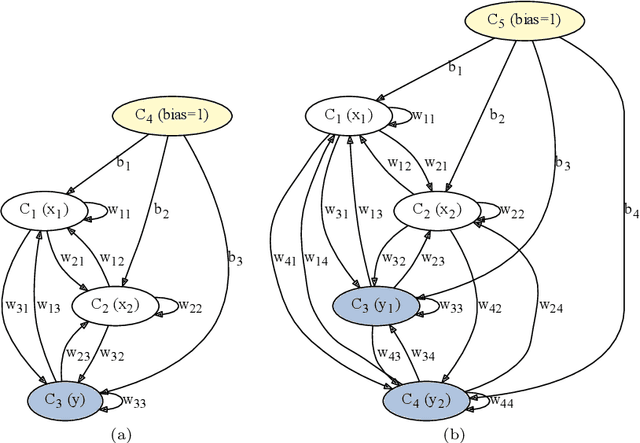
Fuzzy Cognitive Maps (FCMs) are considered a soft computing technique combining elements of fuzzy logic and recurrent neural networks. They found multiple application in such domains as modeling of system behavior, prediction of time series, decision making and process control. Less attention, however, has been turned towards using them in pattern classification. In this work we propose an FCM based classifier with a fully connected map structure. In contrast to methods that expect reaching a steady system state during reasoning, we chose to execute a few FCM iterations (steps) before collecting output labels. Weights were learned with a gradient algorithm and logloss or cross-entropy were used as the cost function. Our primary goal was to verify, whether such design would result in a descent general purpose classifier, with performance comparable to off the shelf classical methods. As the preliminary results were promising, we investigated the hypothesis that the performance of $d$-step classifier can be attributed to a fact that in previous $d-1$ steps it transforms the feature space by grouping observations belonging to a given class, so that they became more compact and separable. To verify this hypothesis we calculated three clustering scores for the transformed feature space. We also evaluated performance of pipelines built from FCM-based data transformer followed by a classification algorithm. The standard statistical analyzes confirmed both the performance of FCM based classifier and its capability to improve data. The supporting prototype software was implemented in Python using TensorFlow library.
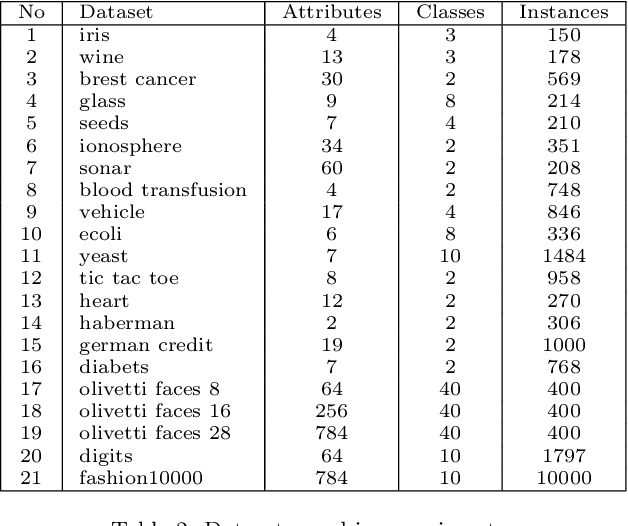
An advantage actor-critic algorithm for robotic motion planning in dense and dynamic scenarios
Feb 05, 2021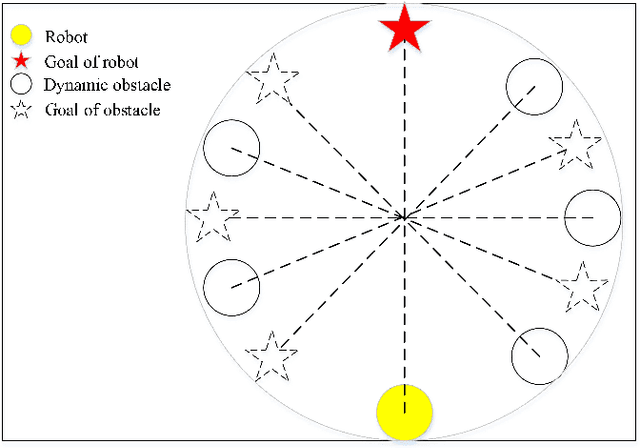

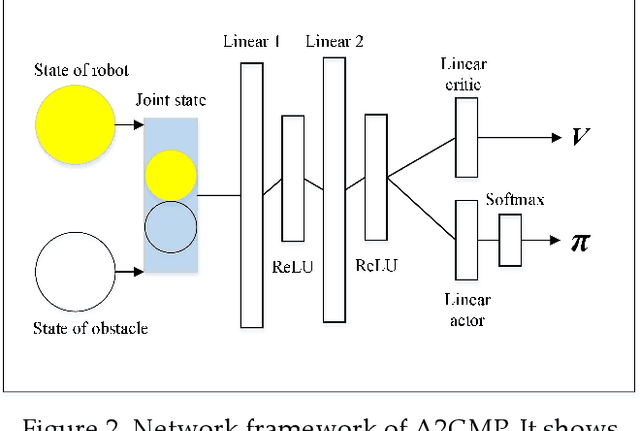
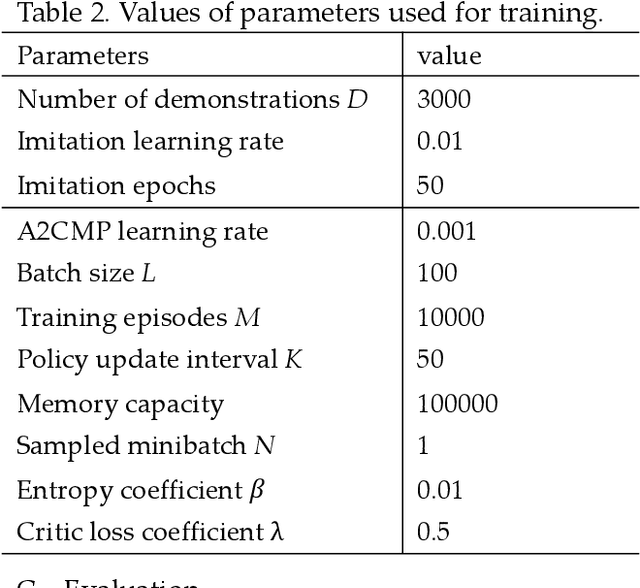
Intelligent robots provide a new insight into efficiency improvement in industrial and service scenarios to replace human labor. However, these scenarios include dense and dynamic obstacles that make motion planning of robots challenging. Traditional algorithms like A* can plan collision-free trajectories in static environment, but their performance degrades and computational cost increases steeply in dense and dynamic scenarios. Optimal-value reinforcement learning algorithms (RL) can address these problems but suffer slow speed and instability in network convergence. Network of policy gradient RL converge fast in Atari games where action is discrete and finite, but few works have been done to address problems where continuous actions and large action space are required. In this paper, we modify existing advantage actor-critic algorithm and suit it to complex motion planning, therefore optimal speeds and directions of robot are generated. Experimental results demonstrate that our algorithm converges faster and stable than optimal-value RL. It achieves higher success rate in motion planning with lesser processing time for robot to reach its goal.
There is More than Meets the Eye: Self-Supervised Multi-Object Detection and Tracking with Sound by Distilling Multimodal Knowledge
Mar 01, 2021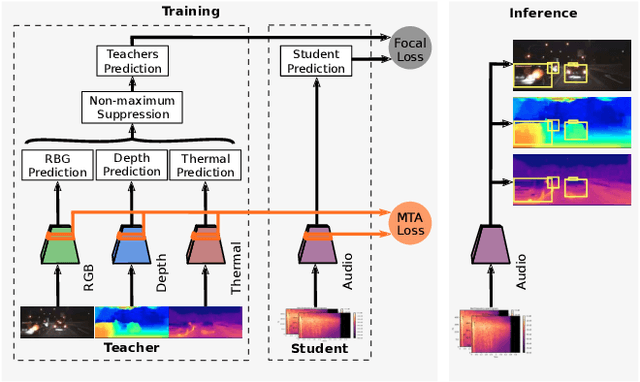
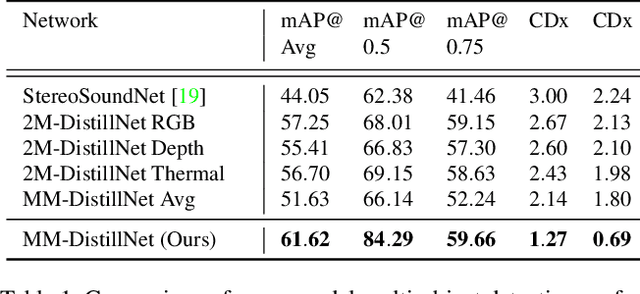
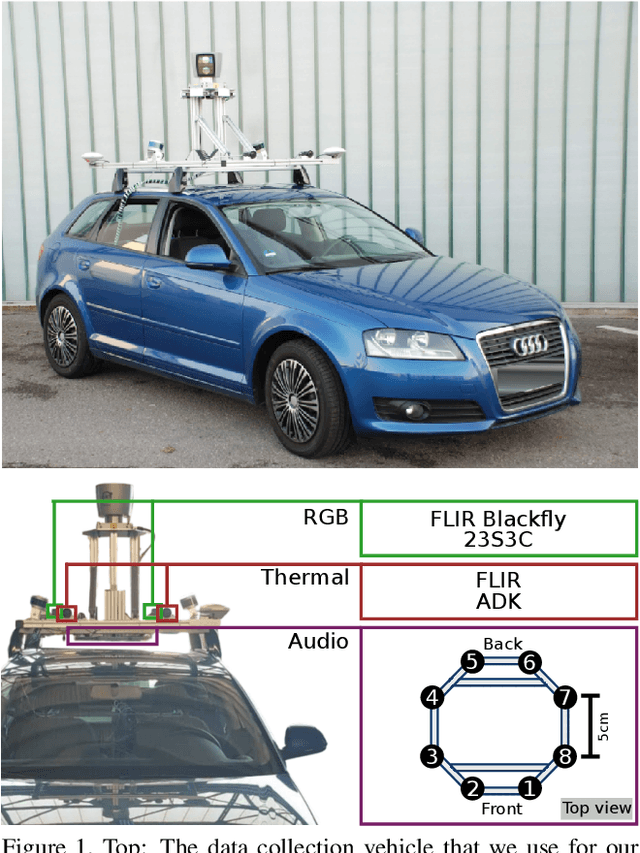
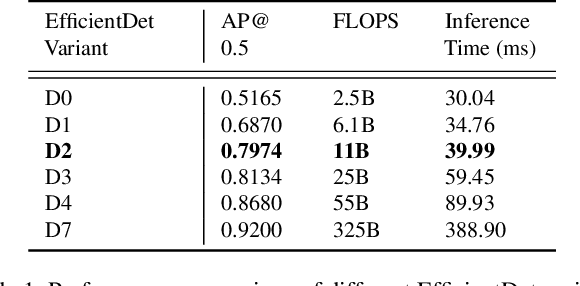
Attributes of sound inherent to objects can provide valuable cues to learn rich representations for object detection and tracking. Furthermore, the co-occurrence of audiovisual events in videos can be exploited to localize objects over the image field by solely monitoring the sound in the environment. Thus far, this has only been feasible in scenarios where the camera is static and for single object detection. Moreover, the robustness of these methods has been limited as they primarily rely on RGB images which are highly susceptible to illumination and weather changes. In this work, we present the novel self-supervised MM-DistillNet framework consisting of multiple teachers that leverage diverse modalities including RGB, depth and thermal images, to simultaneously exploit complementary cues and distill knowledge into a single audio student network. We propose the new MTA loss function that facilitates the distillation of information from multimodal teachers in a self-supervised manner. Additionally, we propose a novel self-supervised pretext task for the audio student that enables us to not rely on labor-intensive manual annotations. We introduce a large-scale multimodal dataset with over 113,000 time-synchronized frames of RGB, depth, thermal, and audio modalities. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods while being able to detect multiple objects using only sound during inference and even while moving.