 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
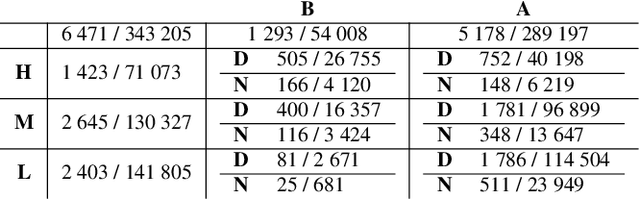
Efficient sign language recognition system and dataset creation method based on deep learning and image processing
Mar 22, 2021
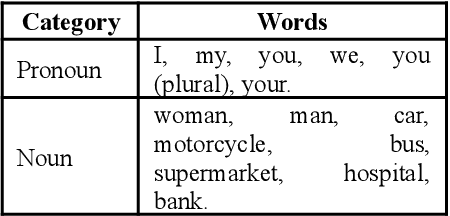

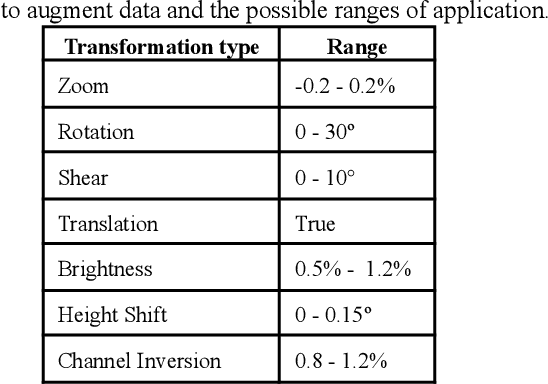
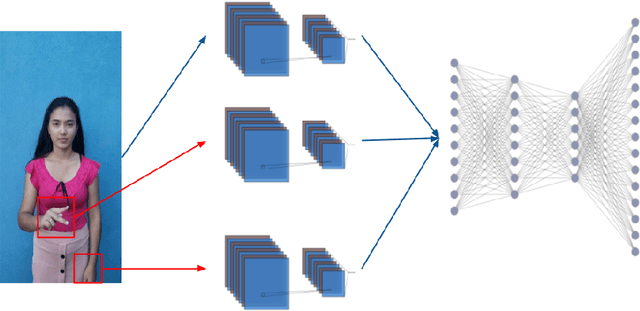
New deep-learning architectures are created every year, achieving state-of-the-art results in image recognition and leading to the belief that, in a few years, complex tasks such as sign language translation will be considerably easier, serving as a communication tool for the hearing-impaired community. On the other hand, these algorithms still need a lot of data to be trained and the dataset creation process is expensive, time-consuming, and slow. Thereby, this work aims to investigate techniques of digital image processing and machine learning that can be used to create a sign language dataset effectively. We argue about data acquisition, such as the frames per second rate to capture or subsample the videos, the background type, preprocessing, and data augmentation, using convolutional neural networks and object detection to create an image classifier and comparing the results based on statistical tests. Different datasets were created to test the hypotheses, containing 14 words used daily and recorded by different smartphones in the RGB color system. We achieved an accuracy of 96.38% on the test set and 81.36% on the validation set containing more challenging conditions, showing that 30 FPS is the best frame rate subsample to train the classifier, geometric transformations work better than intensity transformations, and artificial background creation is not effective to model generalization. These trade-offs should be considered in future work as a cost-benefit guideline between computational cost and accuracy gain when creating a dataset and training a sign recognition model.
Leveraging domain labels for object detection from UAVs
Jan 29, 2021
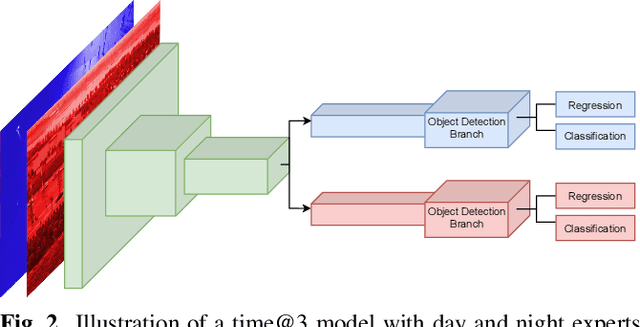
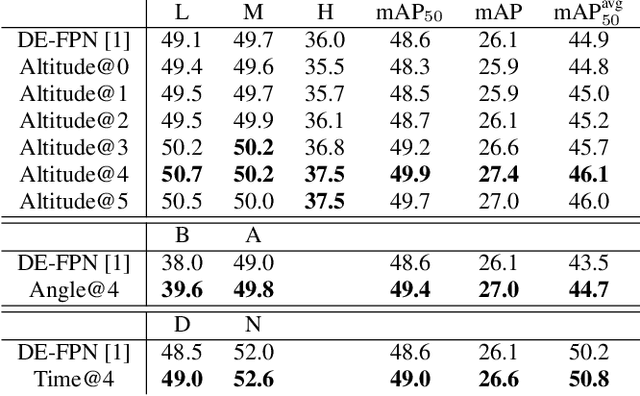
Object detection from Unmanned Aerial Vehicles (UAVs) is of great importance in many aerial vision-based applications. Despite the great success of generic object detection methods, a large performance drop is observed when applied to images captured by UAVs. This is due to large variations in imaging conditions, such as varying altitudes, dynamically changing viewing angles, and different capture times. We demonstrate that domain knowledge is a valuable source of information and thus propose domain-aware object detectors by using freely accessible sensor data. By splitting the model into cross-domain and domain-specific parts, substantial performance improvements are achieved on multiple datasets across multiple models and metrics. In particular, we achieve a new state-of-the-art performance on UAVDT for real-time detectors. Furthermore, we create a new airborne image dataset by annotating 13 713 objects in 2 900 images featuring precise altitude and viewing angle annotations.
Automated and Autonomous Experiment in Electron and Scanning Probe Microscopy
Mar 22, 2021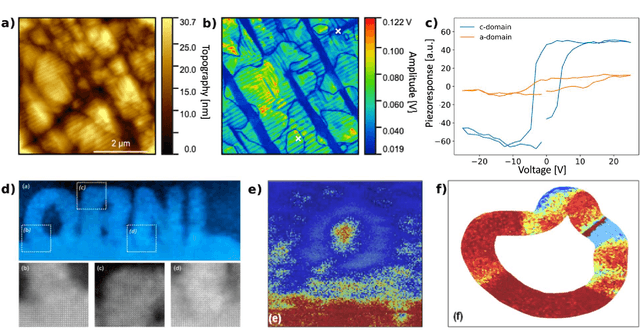
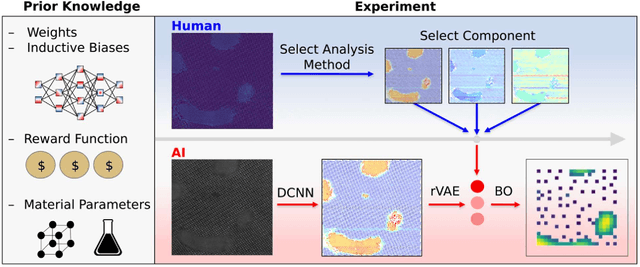
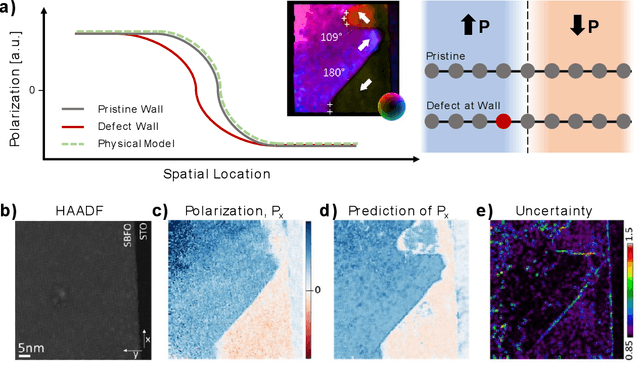
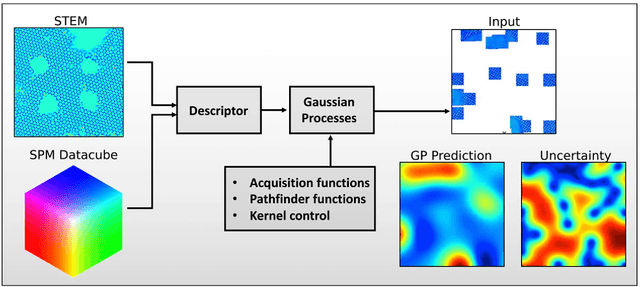
Machine learning and artificial intelligence (ML/AI) are rapidly becoming an indispensable part of physics research, with domain applications ranging from theory and materials prediction to high-throughput data analysis. In parallel, the recent successes in applying ML/AI methods for autonomous systems from robotics through self-driving cars to organic and inorganic synthesis are generating enthusiasm for the potential of these techniques to enable automated and autonomous experiment (AE) in imaging. Here, we aim to analyze the major pathways towards AE in imaging methods with sequential image formation mechanisms, focusing on scanning probe microscopy (SPM) and (scanning) transmission electron microscopy ((S)TEM). We argue that automated experiments should necessarily be discussed in a broader context of the general domain knowledge that both informs the experiment and is increased as the result of the experiment. As such, this analysis should explore the human and ML/AI roles prior to and during the experiment, and consider the latencies, biases, and knowledge priors of the decision-making process. Similarly, such discussion should include the limitations of the existing imaging systems, including intrinsic latencies, non-idealities and drifts comprising both correctable and stochastic components. We further pose that the role of the AE in microscopy is not the exclusion of human operators (as is the case for autonomous driving), but rather automation of routine operations such as microscope tuning, etc., prior to the experiment, and conversion of low latency decision making processes on the time scale spanning from image acquisition to human-level high-order experiment planning.
A new approach for physiological time series
Apr 23, 2015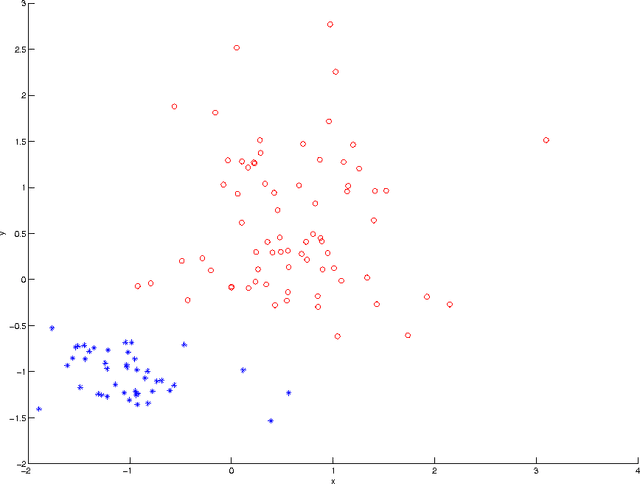
We developed a new approach for the analysis of physiological time series. An iterative convolution filter is used to decompose the time series into various components. Statistics of these components are extracted as features to characterize the mechanisms underlying the time series. Motivated by the studies that show many normal physiological systems involve irregularity while the decrease of irregularity usually implies the abnormality, the statistics for "outliers" in the components are used as features measuring irregularity. Support vector machines are used to select the most relevant features that are able to differentiate the time series from normal and abnormal systems. This new approach is successfully used in the study of congestive heart failure by heart beat interval time series.
A character representation enhanced on-device Intent Classification
Jan 12, 2021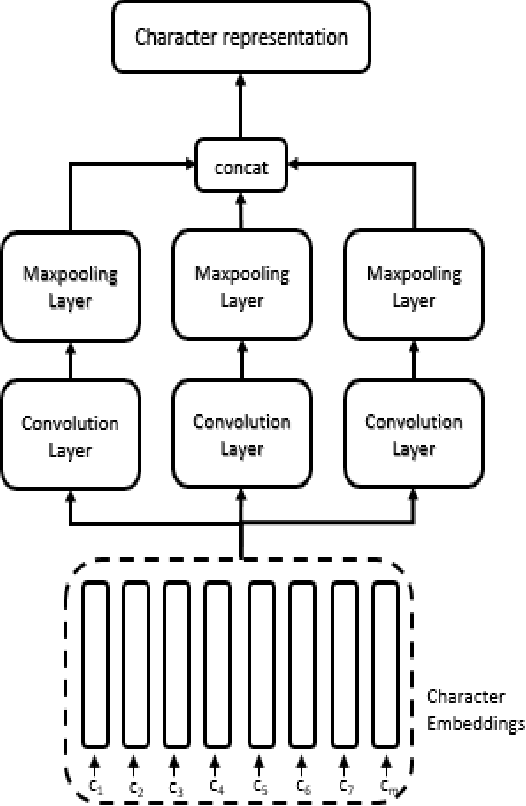
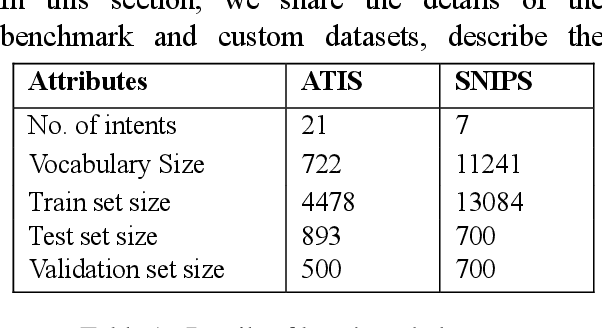
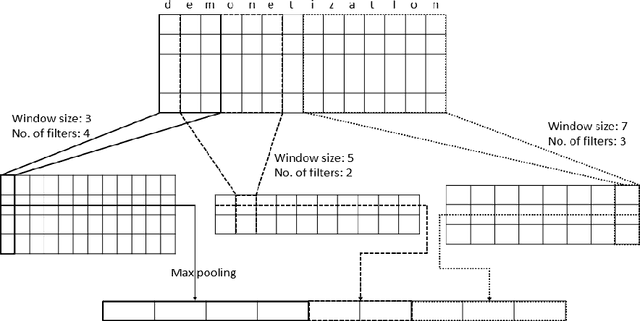

Intent classification is an important task in natural language understanding systems. Existing approaches have achieved perfect scores on the benchmark datasets. However they are not suitable for deployment on low-resource devices like mobiles, tablets, etc. due to their massive model size. Therefore, in this paper, we present a novel light-weight architecture for intent classification that can run efficiently on a device. We use character features to enrich the word representation. Our experiments prove that our proposed model outperforms existing approaches and achieves state-of-the-art results on benchmark datasets. We also report that our model has tiny memory footprint of ~5 MB and low inference time of ~2 milliseconds, which proves its efficiency in a resource-constrained environment.
Control Flow Obfuscation for FJ using Continuation Passing
Dec 08, 2020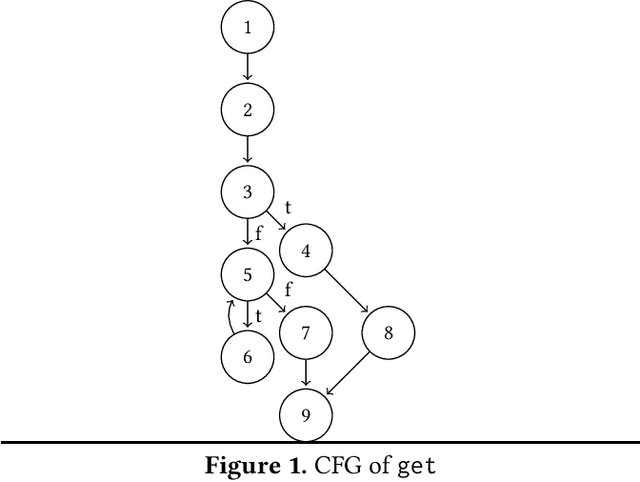
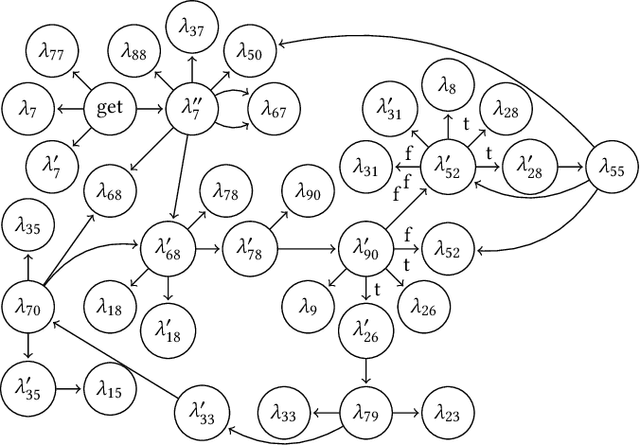


Control flow obfuscation deters software reverse engineering attempts by altering the program's control flow transfer. The alternation should not affect the software's run-time behaviour. In this paper, we propose a control flow obfuscation approach for FJ with exception handling. The approach is based on a source to source transformation using continuation passing style (CPS). We argue that the proposed CPS transformation causes malicious attacks using context insensitive static analysis and context sensitive analysis with fixed call string to lose precision.
Real-Time Online Re-Planning for Grasping Under Clutter and Uncertainty
Oct 09, 2018
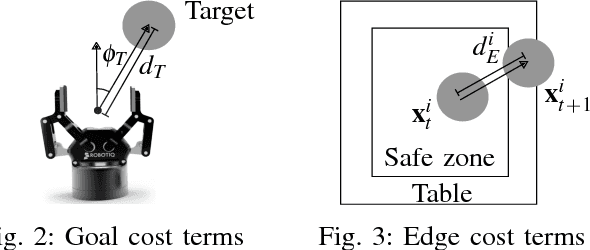


We consider the problem of grasping in clutter. While there have been motion planners developed to address this problem in recent years, these planners are mostly tailored for open-loop execution. Open-loop execution in this domain, however, is likely to fail, since it is not possible to model the dynamics of the multi-body multi-contact physical system with enough accuracy, neither is it reasonable to expect robots to know the exact physical properties of objects, such as frictional, inertial, and geometrical. Therefore, we propose an online re-planning approach for grasping through clutter. The main challenge is the long planning times this domain requires, which makes fast re-planning and fluent execution difficult to realize. In order to address this, we propose an easily parallelizable stochastic trajectory optimization based algorithm that generates a sequence of optimal controls. We show that by running this optimizer only for a small number of iterations, it is possible to perform real time re-planning cycles to achieve reactive manipulation under clutter and uncertainty.
Imponderous Net for Facial Expression Recognition in the Wild
Mar 28, 2021

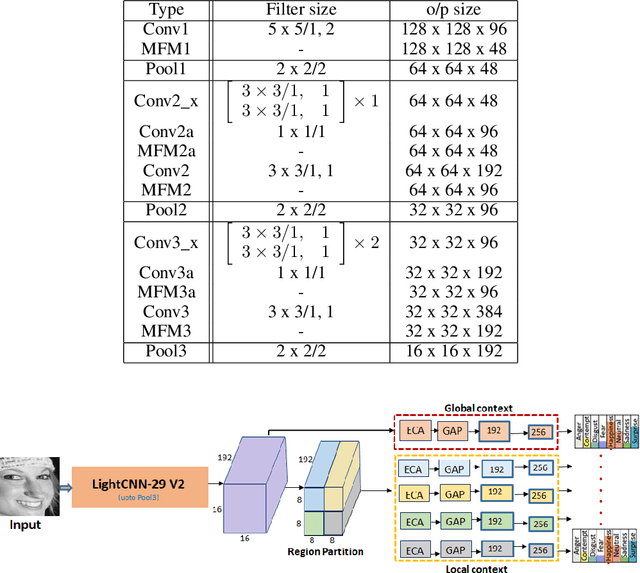
Since the renaissance of deep learning (DL), facial expression recognition (FER) has received a lot of interest, with continual improvement in the performance. Hand-in-hand with performance, new challenges have come up. Modern FER systems deal with face images captured under uncontrolled conditions (also called in-the-wild scenario) including occlusions and pose variations. They successfully handle such conditions using deep networks that come with various components like transfer learning, attention mechanism and local-global context extractor. However, these deep networks are highly complex with large number of parameters, making them unfit to be deployed in real scenarios. Is it possible to build a light-weight network that can still show significantly good performance on FER under in-the-wild scenario? In this work, we methodically build such a network and call it as Imponderous Net. We leverage on the aforementioned components of deep networks for FER, and analyse, carefully choose and fit them to arrive at Imponderous Net. Our Imponderous Net is a low calorie net with only 1.45M parameters, which is almost 50x less than that of a state-of-the-art (SOTA) architecture. Further, during inference, it can process at the real time rate of 40 frames per second (fps) in an intel-i7 cpu. Though it is low calorie, it is still power packed in its performance, overpowering other light-weight architectures and even few high capacity architectures. Specifically, Imponderous Net reports 87.09\%, 88.17\% and 62.06\% accuracies on in-the-wild datasets RAFDB, FERPlus and AffectNet respectively. It also exhibits superior robustness under occlusions and pose variations in comparison to other light-weight architectures from the literature.
Monocular Real-time Hand Shape and Motion Capture using Multi-modal Data
Mar 21, 2020
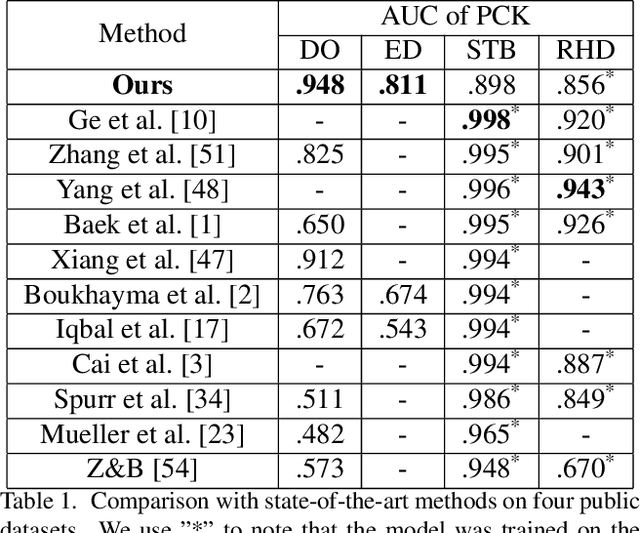
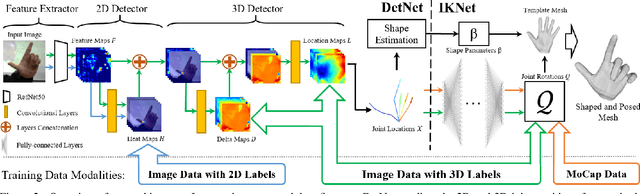
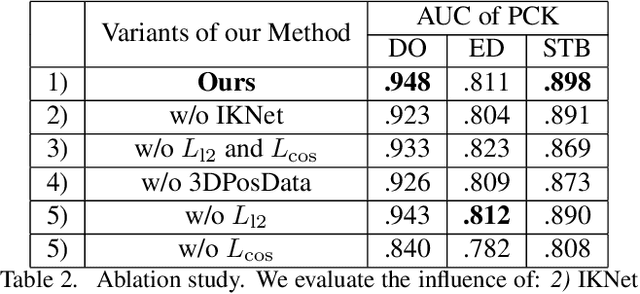
We present a novel method for monocular hand shape and pose estimation at unprecedented runtime performance of 100fps and at state-of-the-art accuracy. This is enabled by a new learning based architecture designed such that it can make use of all the sources of available hand training data: image data with either 2D or 3D annotations, as well as stand-alone 3D animations without corresponding image data. It features a 3D hand joint detection module and an inverse kinematics module which regresses not only 3D joint positions but also maps them to joint rotations in a single feed-forward pass. This output makes the method more directly usable for applications in computer vision and graphics compared to only regressing 3D joint positions. We demonstrate that our architectural design leads to a significant quantitative and qualitative improvement over the state of the art on several challenging benchmarks. Our model is publicly available for future research.
Comparison of Privacy-Preserving Distributed Deep Learning Methods in Healthcare
Dec 23, 2020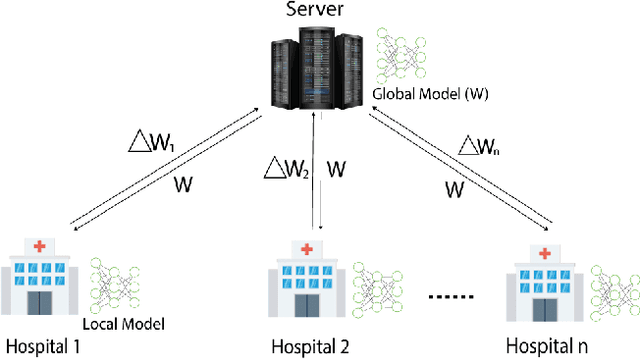
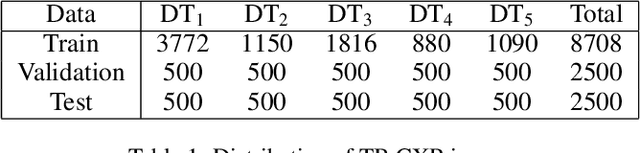
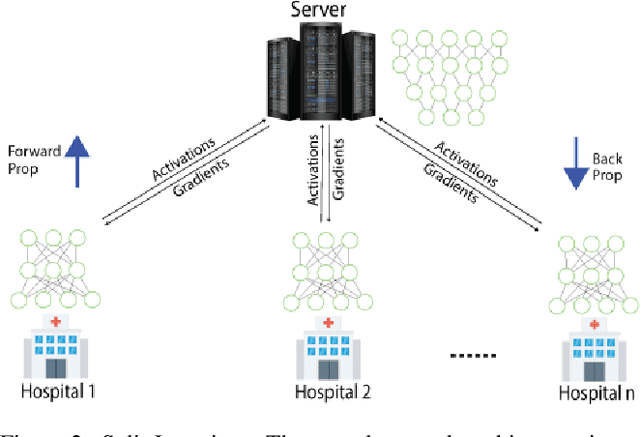
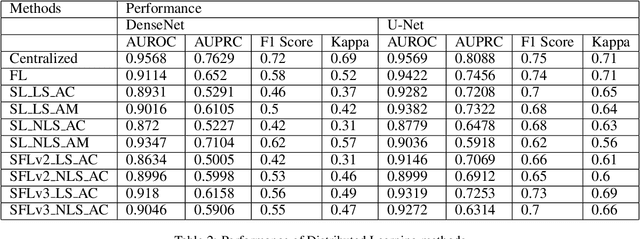
In this paper, we compare three privacy-preserving distributed learning techniques: federated learning, split learning, and SplitFed. We use these techniques to develop binary classification models for detecting tuberculosis from chest X-rays and compare them in terms of classification performance, communication and computational costs, and training time. We propose a novel distributed learning architecture called SplitFedv3, which performs better than split learning and SplitFedv2 in our experiments. We also propose alternate mini-batch training, a new training technique for split learning, that performs better than alternate client training, where clients take turns to train a model.