 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Learning with Arbitrary Covariate Shift
Feb 15, 2021
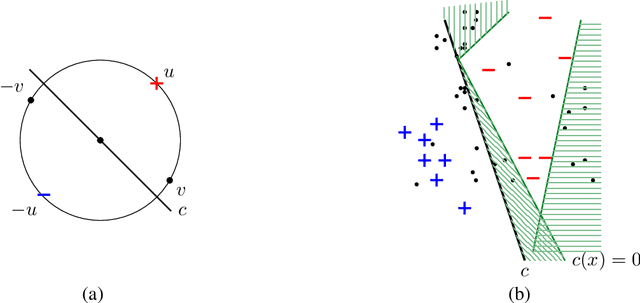
We give an efficient algorithm for learning a binary function in a given class C of bounded VC dimension, with training data distributed according to P and test data according to Q, where P and Q may be arbitrary distributions over X. This is the generic form of what is called covariate shift, which is impossible in general as arbitrary P and Q may not even overlap. However, recently guarantees were given in a model called PQ-learning (Goldwasser et al., 2020) where the learner has: (a) access to unlabeled test examples from Q (in addition to labeled samples from P, i.e., semi-supervised learning); and (b) the option to reject any example and abstain from classifying it (i.e., selective classification). The algorithm of Goldwasser et al. (2020) requires an (agnostic) noise tolerant learner for C. The present work gives a polynomial-time PQ-learning algorithm that uses an oracle to a "reliable" learner for C, where reliable learning (Kalai et al., 2012) is a model of learning with one-sided noise. Furthermore, our reduction is optimal in the sense that we show the equivalence of reliable and PQ learning.
Implicit Unlikelihood Training: Improving Neural Text Generation with Reinforcement Learning
Jan 11, 2021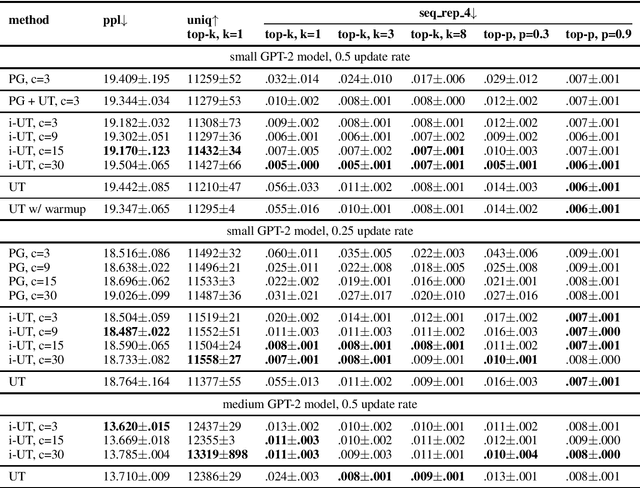
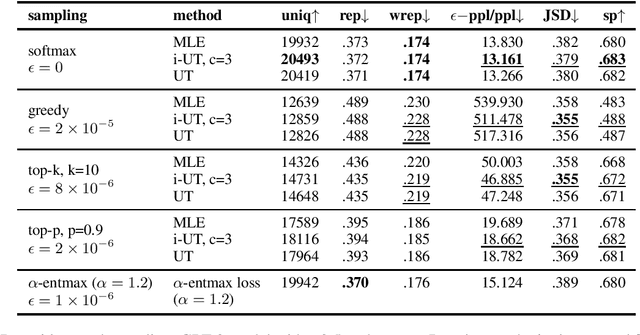

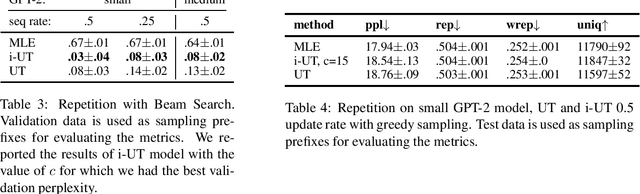
Likelihood training and maximization-based decoding result in dull and repetitive generated texts even when using powerful language models (Holtzman et al., 2019). Adding a loss function for regularization was shown to improve text generation output by helping avoid unwanted properties, such as contradiction or repetition (Li at al., 2020). In this work, we propose fine-tuning a language model by using policy gradient reinforcement learning, directly optimizing for better generation. We apply this approach to minimizing repetition in generated text, and show that, when combined with unlikelihood training (Welleck et al., 2020), our method further reduces repetition without impacting the language model quality. We also evaluate other methods for improving generation at training and decoding time, and compare them using various metrics aimed at control for better text generation output.
Efficient Learning in Non-Stationary Linear Markov Decision Processes
Oct 24, 2020
We study episodic reinforcement learning in non-stationary linear (a.k.a. low-rank) Markov Decision Processes (MDPs), i.e, both the reward and transition kernel are linear with respect to a given feature map and are allowed to evolve either slowly or abruptly over time. For this problem setting, we propose OPT-WLSVI an optimistic model-free algorithm based on weighted least squares value iteration which uses exponential weights to smoothly forget data that are far in the past. We show that our algorithm, when competing against the best policy at each time, achieves a regret that is upped bounded by $\widetilde{\mathcal{O}}(d^{7/6}H^2 \Delta^{1/3} K^{2/3})$ where $d$ is the dimension of the feature space, $H$ is the planning horizon, $K$ is the number of episodes and $\Delta$ is a suitable measure of non-stationarity of the MDP. This is the first regret bound for non-stationary reinforcement learning with linear function approximation.
Tarsier: Evolving Noise Injection in Super-Resolution GANs
Sep 25, 2020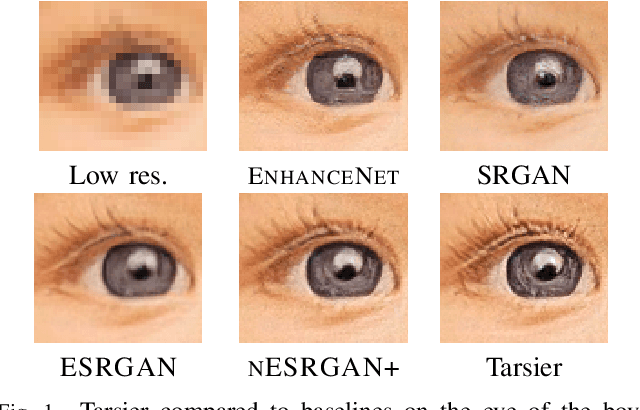

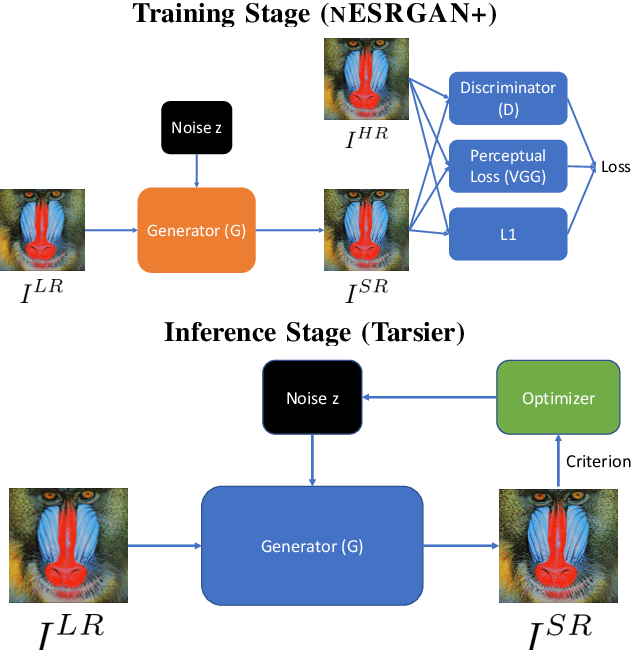
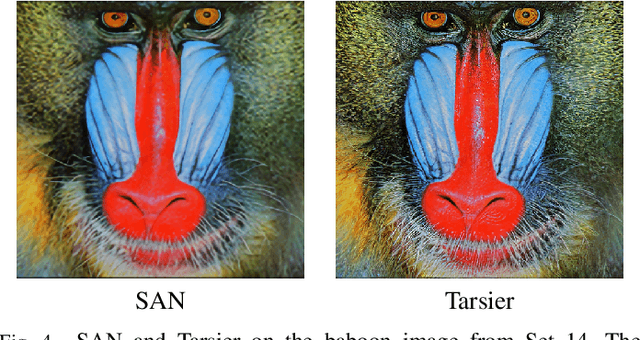
Super-resolution aims at increasing the resolution and level of detail within an image. The current state of the art in general single-image super-resolution is held by NESRGAN+, which injects a Gaussian noise after each residual layer at training time. In this paper, we harness evolutionary methods to improve NESRGAN+ by optimizing the noise injection at inference time. More precisely, we use Diagonal CMA to optimize the injected noise according to a novel criterion combining quality assessment and realism. Our results are validated by the PIRM perceptual score and a human study. Our method outperforms NESRGAN+ on several standard super-resolution datasets. More generally, our approach can be used to optimize any method based on noise injection.
School of hard knocks: Curriculum analysis for Pommerman with a fixed computational budget
Feb 23, 2021
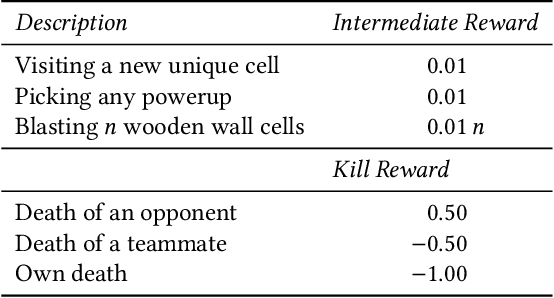

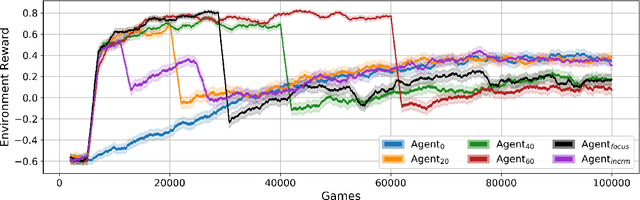
Pommerman is a hybrid cooperative/adversarial multi-agent environment, with challenging characteristics in terms of partial observability, limited or no communication, sparse and delayed rewards, and restrictive computational time limits. This makes it a challenging environment for reinforcement learning (RL) approaches. In this paper, we focus on developing a curriculum for learning a robust and promising policy in a constrained computational budget of 100,000 games, starting from a fixed base policy (which is itself trained to imitate a noisy expert policy). All RL algorithms starting from the base policy use vanilla proximal-policy optimization (PPO) with the same reward function, and the only difference between their training is the mix and sequence of opponent policies. One expects that beginning training with simpler opponents and then gradually increasing the opponent difficulty will facilitate faster learning, leading to more robust policies compared against a baseline where all available opponent policies are introduced from the start. We test this hypothesis and show that within constrained computational budgets, it is in fact better to "learn in the school of hard knocks", i.e., against all available opponent policies nearly from the start. We also include ablation studies where we study the effect of modifying the base environment properties of ammo and bomb blast strength on the agent performance.
Augmenting Proposals by the Detector Itself
Jan 28, 2021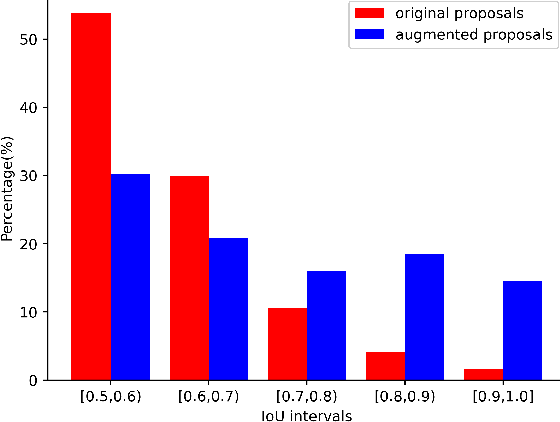
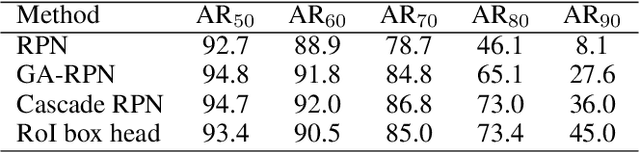
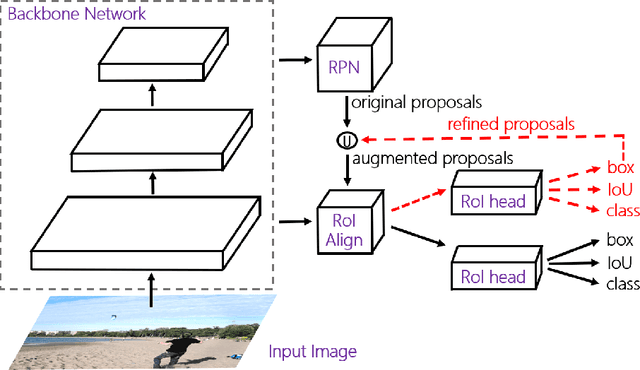
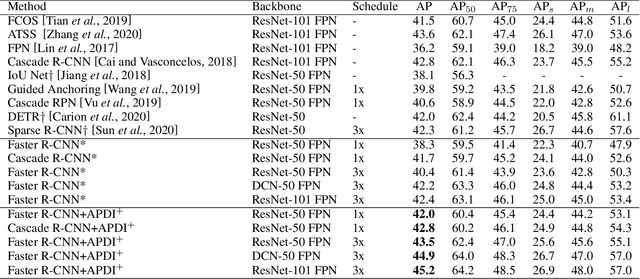
Lacking enough high quality proposals for RoI box head has impeded two-stage and multi-stage object detectors for a long time, and many previous works try to solve it via improving RPN's performance or manually generating proposals from ground truth. However, these methods either need huge training and inference costs or bring little improvements. In this paper, we design a novel training method named APDI, which means augmenting proposals by the detector itself and can generate proposals with higher quality. Furthermore, APDI makes it possible to integrate IoU head into RoI box head. And it does not add any hyperparameter, which is beneficial for future research and downstream tasks. Extensive experiments on COCO dataset show that our method brings at least 2.7 AP improvements on Faster R-CNN with various backbones, and APDI can cooperate with advanced RPNs, such as GA-RPN and Cascade RPN, to obtain extra gains. Furthermore, it brings significant improvements on Cascade R-CNN.
Comprehensive process-molten pool relations modeling using CNN for wire-feed laser additive manufacturing
Mar 22, 2021

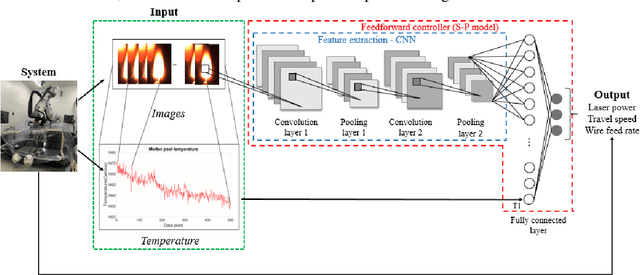
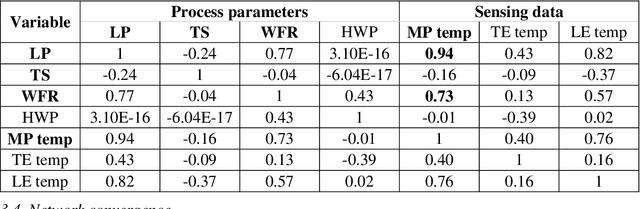
Wire-feed laser additive manufacturing (WLAM) is gaining wide interest due to its high level of automation, high deposition rates, and good quality of printed parts. In-process monitoring and feedback controls that would reduce the uncertainty in the quality of the material are in the early stages of development. Machine learning promises the ability to accelerate the adoption of new processes and property design in additive manufacturing by making process-structure-property connections between process setting inputs and material quality outcomes. The molten pool dimensional information and temperature are the indicators for achieving the high quality of the build, which can be directly controlled by processing parameters. For the purpose of in situ quality control, the process parameters should be controlled in real-time based on sensed information from the process, in particular the molten pool. Thus, the molten pool-process relations are of preliminary importance. This paper analyzes experimentally collected in situ sensing data from the molten pool under a set of controlled process parameters in a WLAM system. The variations in the steady-state and transient state of the molten pool are presented with respect to the change of independent process parameters. A multi-modality convolutional neural network (CNN) architecture is proposed for predicting the control parameter directly from the measurable molten pool sensor data for achieving desired geometric and microstructural properties. Dropout and regularization are applied to the CNN architecture to avoid the problem of overfitting. The results highlighted that the multi-modal CNN, which receives temperature profile as an external feature to the features extracted from the image data, has improved prediction performance compared to the image-based uni-modality CNN approach.
Surrogate-assisted cooperative signal optimization for large-scale traffic networks
Mar 03, 2021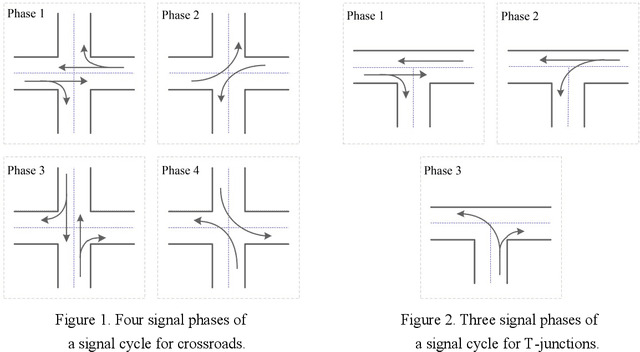
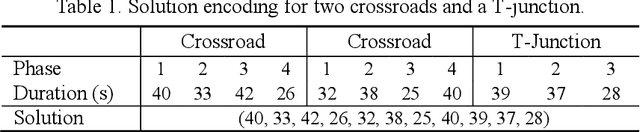

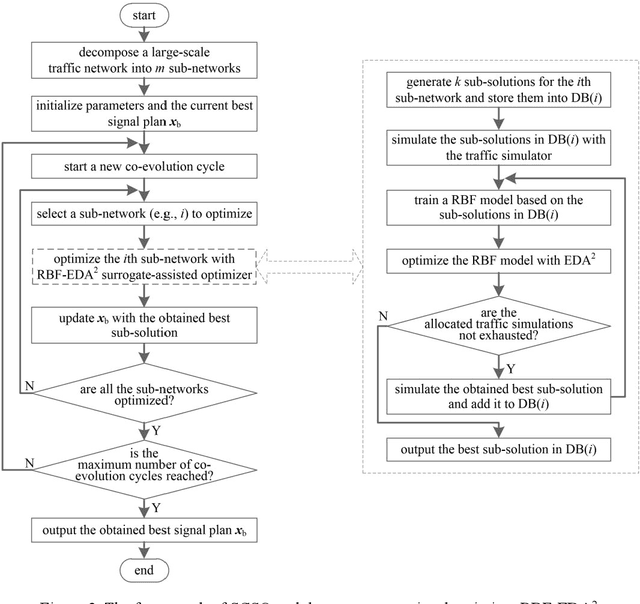
Reasonable setting of traffic signals can be very helpful in alleviating congestion in urban traffic networks. Meta-heuristic optimization algorithms have proved themselves to be able to find high-quality signal timing plans. However, they generally suffer from performance deterioration when solving large-scale traffic signal optimization problems due to the huge search space and limited computational budget. Directing against this issue, this study proposes a surrogate-assisted cooperative signal optimization (SCSO) method. Different from existing methods that directly deal with the entire traffic network, SCSO first decomposes it into a set of tractable sub-networks, and then achieves signal setting by cooperatively optimizing these sub-networks with a surrogate-assisted optimizer. The decomposition operation significantly narrows the search space of the whole traffic network, and the surrogate-assisted optimizer greatly lowers the computational burden by reducing the number of expensive traffic simulations. By taking Newman fast algorithm, radial basis function and a modified estimation of distribution algorithm as decomposer, surrogate model and optimizer, respectively, this study develops a concrete SCSO algorithm. To evaluate its effectiveness and efficiency, a large-scale traffic network involving crossroads and T-junctions is generated based on a real traffic network. Comparison with several existing meta-heuristic algorithms specially designed for traffic signal optimization demonstrates the superiority of SCSO in reducing the average delay time of vehicles.
Policy Gradient Reinforcement Learning for Policy Represented by Fuzzy Rules: Application to Simulations of Speed Control of an Automobile
Sep 04, 2020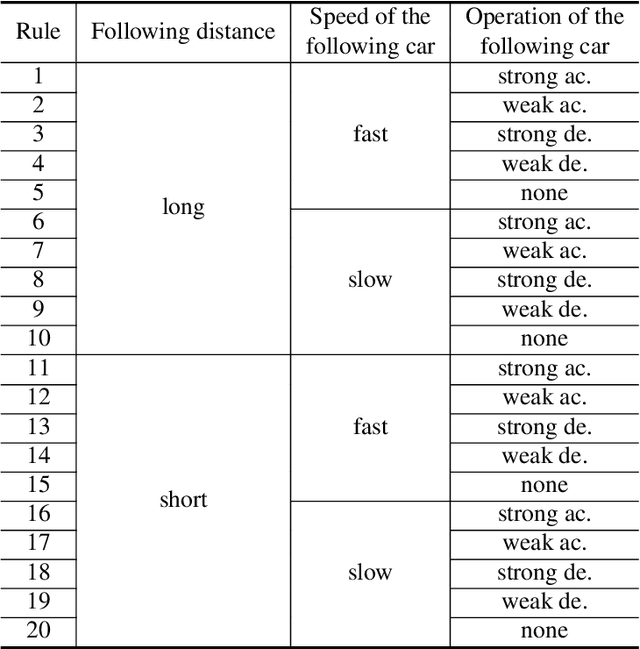
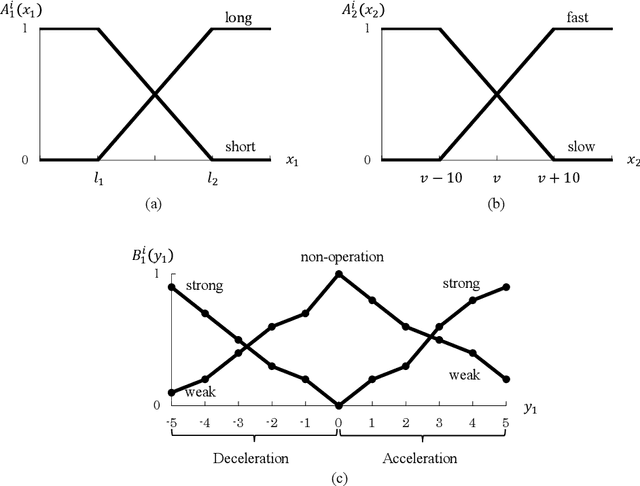
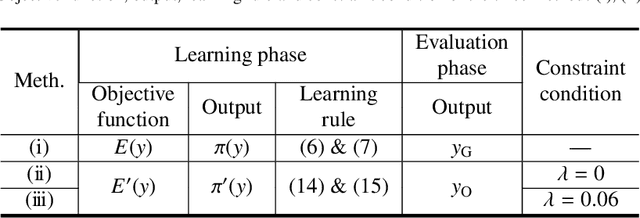
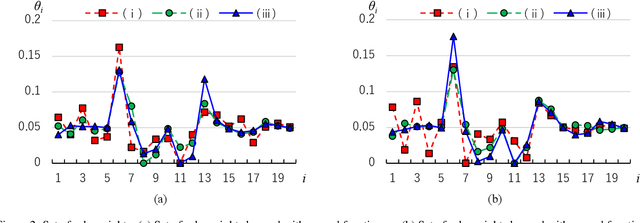
A method of a fusion of fuzzy inference and policy gradient reinforcement learning has been proposed that directly learns, as maximizes the expected value of the reward per episode, parameters in a policy function represented by fuzzy rules with weights. A study has applied this method to a task of speed control of an automobile and has obtained correct policies, some of which control speed of the automobile appropriately but many others generate inappropriate vibration of speed. In general, the policy is not desirable that causes sudden time change or vibration in the output value, and there would be many cases where the policy giving smooth time change in the output value is desirable. In this paper, we propose a fusion method using the objective function, that introduces defuzzification with the center of gravity model weighted stochastically and a constraint term for smoothness of time change, as an improvement measure in order to suppress sudden change of the output value of the fuzzy controller. Then we show the learning rule in the fusion, and also consider the effect by reward functions on the fluctuation of the output value. As experimental results of an application of our method on speed control of an automobile, it was confirmed that the proposed method has the effect of suppressing the undesirable fluctuation in time-series of the output value. Moreover, it was also showed that the difference between reward functions might adversely affect the results of learning.
Anomaly detection and motif discovery in symbolic representations of time series
Apr 18, 2017
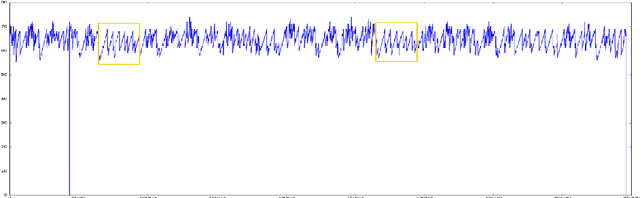
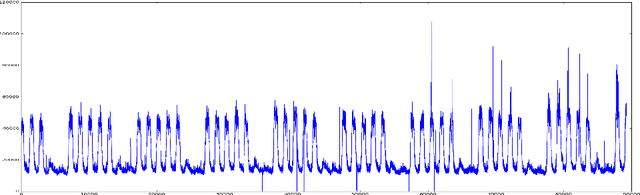
The advent of the Big Data hype and the consistent recollection of event logs and real-time data from sensors, monitoring software and machine configuration has generated a huge amount of time-varying data in about every sector of the industry. Rule-based processing of such data has ceased to be relevant in many scenarios where anomaly detection and pattern mining have to be entirely accomplished by the machine. Since the early 2000s, the de-facto standard for representing time series has been the Symbolic Aggregate approXimation (SAX).In this document, we present a few algorithms using this representation for anomaly detection and motif discovery, also known as pattern mining, in such data. We propose a benchmark of anomaly detection algorithms using data from Cloud monitoring software.