 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Subspace Search in Data Streams
Nov 13, 2020
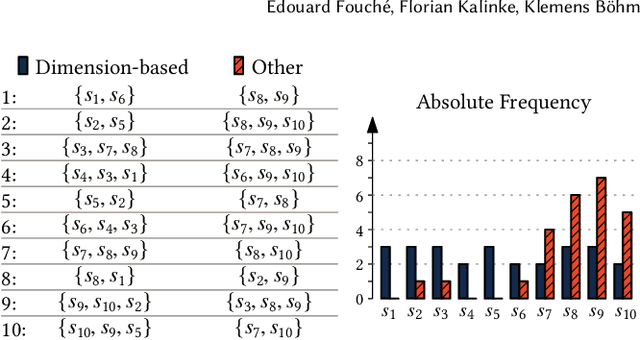
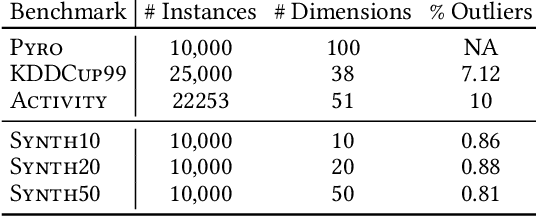
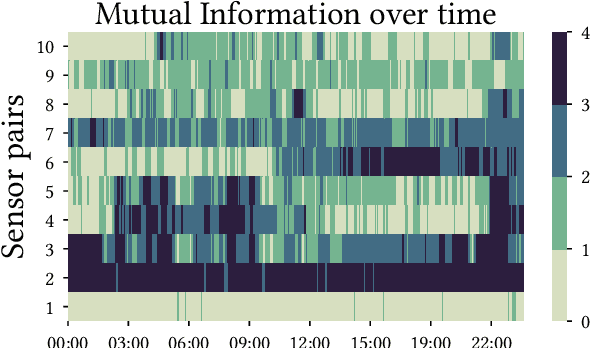
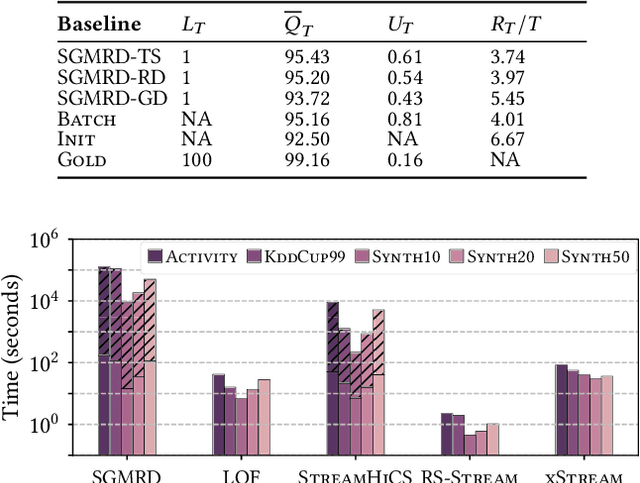
In the real world, data streams are ubiquitous -- think of network traffic or sensor data. Mining patterns, e.g., outliers or clusters, from such data must take place in real time. This is challenging because (1) streams often have high dimensionality, and (2) the data characteristics may change over time. Existing approaches tend to focus on only one aspect, either high dimensionality or the specifics of the streaming setting. For static data, a common approach to deal with high dimensionality -- known as subspace search -- extracts low-dimensional, `interesting' projections (subspaces), in which patterns are easier to find. In this paper, we address both Challenge (1) and (2) by generalising subspace search to data streams. Our approach, Streaming Greedy Maximum Random Deviation (SGMRD), monitors interesting subspaces in high-dimensional data streams. It leverages novel multivariate dependency estimators and monitoring techniques based on bandit theory. We show that the benefits of SGMRD are twofold: (i) It monitors subspaces efficiently, and (ii) this improves the results of downstream data mining tasks, such as outlier detection. Our experiments, performed against synthetic and real-world data, demonstrate that SGMRD outperforms its competitors by a large margin.
Video Sentiment Analysis with Bimodal Information-augmented Multi-Head Attention
Mar 03, 2021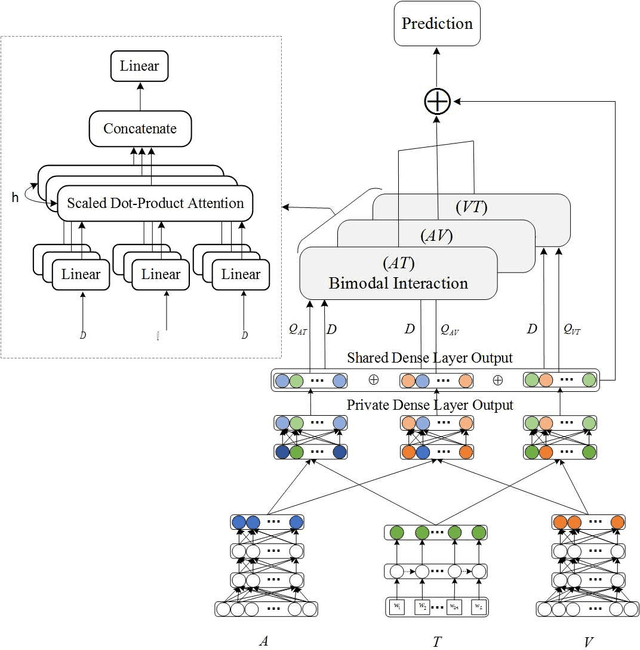
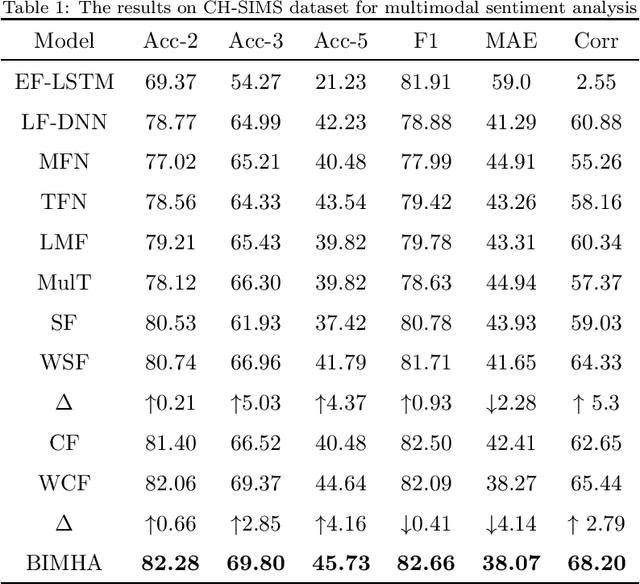
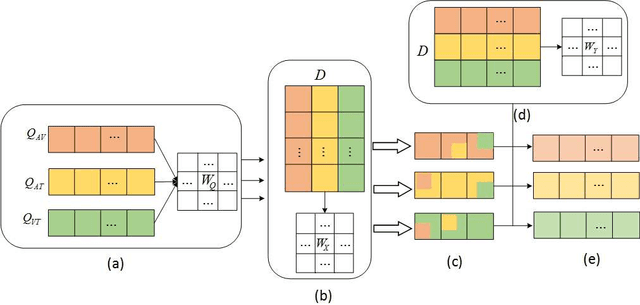
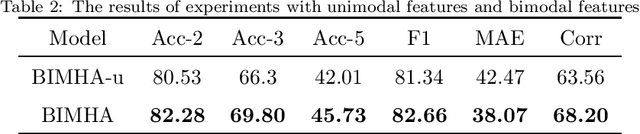
Sentiment analysis is the basis of intelligent human-computer interaction. As one of the frontier research directions of artificial intelligence, it can help computers better identify human intentions and emotional states so that provide more personalized services. However, as human present sentiments by spoken words, gestures, facial expressions and others which involve variable forms of data including text, audio, video, etc., it poses many challenges to this study. Due to the limitations of unimodal sentiment analysis, recent research has focused on the sentiment analysis of videos containing time series data of multiple modalities. When analyzing videos with multimodal data, the key problem is how to fuse these heterogeneous data. In consideration that the contribution of each modality is different, current fusion methods tend to extract the important information of single modality prior to fusion, which ignores the consistency and complementarity of bimodal interaction and has influences on the final decision. To solve this problem, a video sentiment analysis method using multi-head attention with bimodal information augmented is proposed. Based on bimodal interaction, more important bimodal features are assigned larger weights. In this way, different feature representations are adaptively assigned corresponding attention for effective multimodal fusion. Extensive experiments were conducted on both Chinese and English public datasets. The results show that our approach outperforms the existing methods and can give an insight into the contributions of bimodal interaction among three modalities.
Embedding Symbolic Temporal Knowledge into Deep Sequential Models
Jan 28, 2021
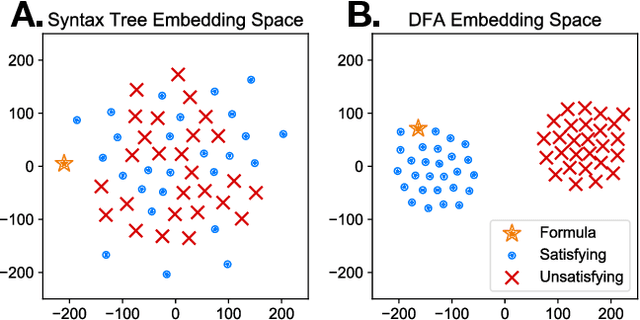
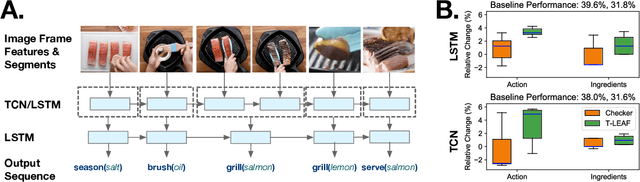
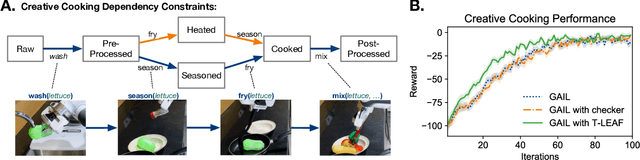
Sequences and time-series often arise in robot tasks, e.g., in activity recognition and imitation learning. In recent years, deep neural networks (DNNs) have emerged as an effective data-driven methodology for processing sequences given sufficient training data and compute resources. However, when data is limited, simpler models such as logic/rule-based methods work surprisingly well, especially when relevant prior knowledge is applied in their construction. However, unlike DNNs, these "structured" models can be difficult to extend, and do not work well with raw unstructured data. In this work, we seek to learn flexible DNNs, yet leverage prior temporal knowledge when available. Our approach is to embed symbolic knowledge expressed as linear temporal logic (LTL) and use these embeddings to guide the training of deep models. Specifically, we construct semantic-based embeddings of automata generated from LTL formula via a Graph Neural Network. Experiments show that these learnt embeddings can lead to improvements in downstream robot tasks such as sequential action recognition and imitation learning.
A Continuous-Time View of Early Stopping for Least Squares Regression
Oct 23, 2018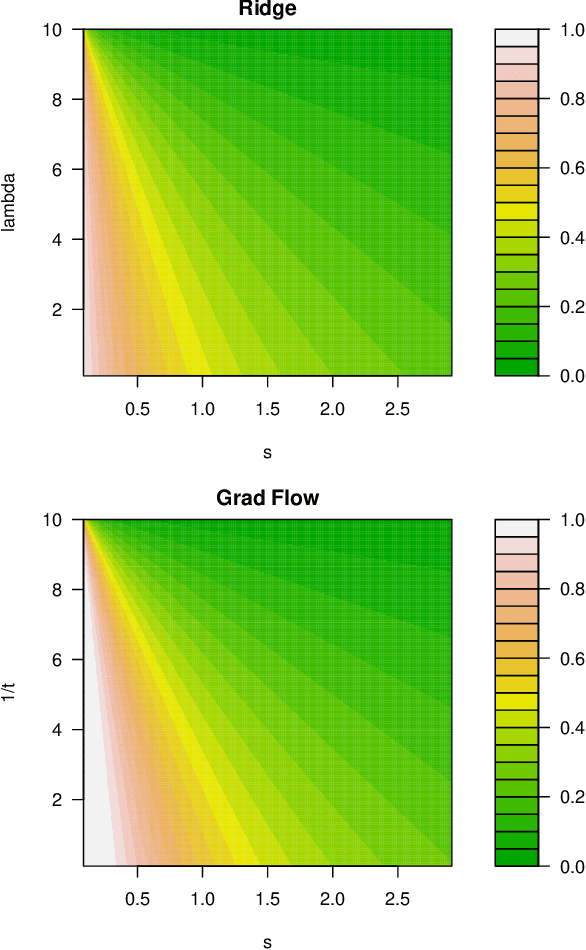
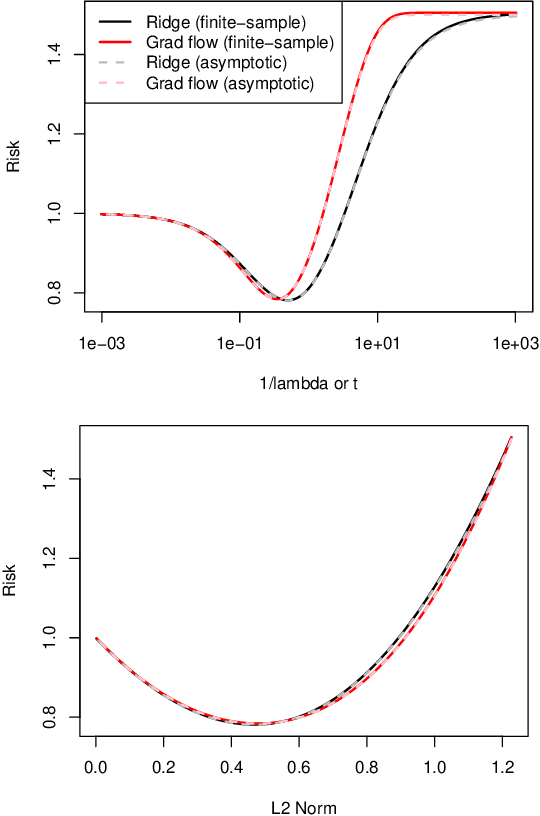
We study the statistical properties of the iterates generated by gradient descent, applied to the fundamental problem of least squares regression. We take a continuous-time view, i.e., consider infinitesimal step sizes in gradient descent, in which case the iterates form a trajectory called gradient flow. In a random matrix theory setup, which allows the number of samples $n$ and features $p$ to diverge in such a way that $p/n \to \gamma \in (0,\infty)$, we derive and analyze an asymptotic risk expression for gradient flow. In particular, we compare the asymptotic risk profile of gradient flow to that of ridge regression. When the feature covariance is spherical, we show that the optimal asymptotic gradient flow risk is between 1 and 1.25 times the optimal asymptotic ridge risk. Further, we derive a calibration between the two risk curves under which the asymptotic gradient flow risk no more than 2.25 times the asymptotic ridge risk, at all points along the path. We present a number of other results illustrating the connections between gradient flow and $\ell_2$ regularization, and numerical experiments that support our theory.
Linear Time Clustering for High Dimensional Mixtures of Gaussian Clouds
Mar 01, 2018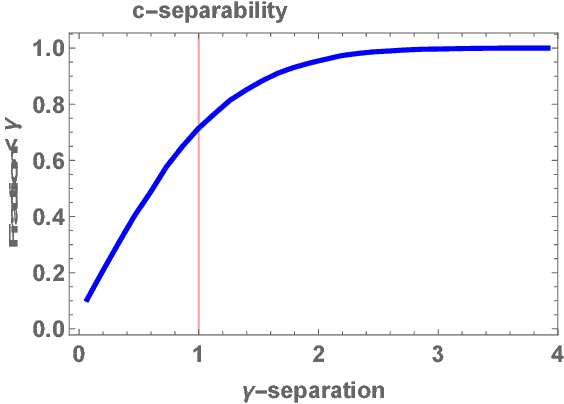
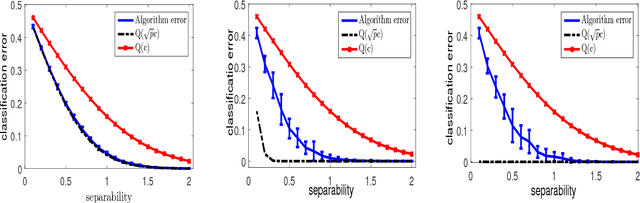
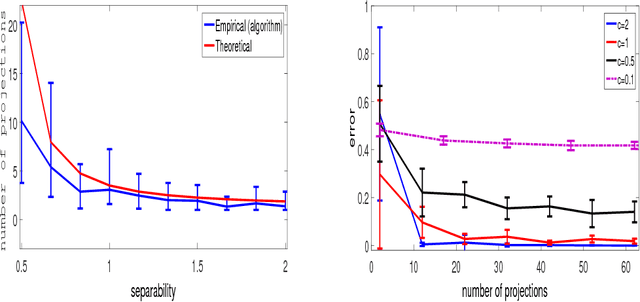
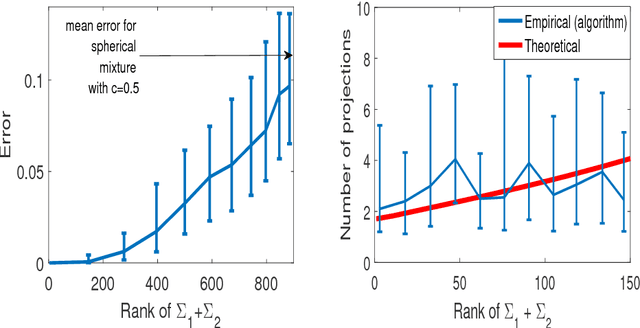
Clustering mixtures of Gaussian distributions is a fundamental and challenging problem that is ubiquitous in various high-dimensional data processing tasks. While state-of-the-art work on learning Gaussian mixture models has focused primarily on improving separation bounds and their generalization to arbitrary classes of mixture models, less emphasis has been paid to practical computational efficiency of the proposed solutions. In this paper, we propose a novel and highly efficient clustering algorithm for $n$ points drawn from a mixture of two arbitrary Gaussian distributions in $\mathbb{R}^p$. The algorithm involves performing random 1-dimensional projections until a direction is found that yields a user-specified clustering error $e$. For a 1-dimensional separation parameter $\gamma$ satisfying $\gamma=Q^{-1}(e)$, the expected number of such projections is shown to be bounded by $o(\ln p)$, when $\gamma$ satisfies $\gamma\leq c\sqrt{\ln{\ln{p}}}$, with $c$ as the separability parameter of the two Gaussians in $\mathbb{R}^p$. Consequently, the expected overall running time of the algorithm is linear in $n$ and quasi-linear in $p$ at $o(\ln{p})O(np)$, and the sample complexity is independent of $p$. This result stands in contrast to prior works which provide polynomial, with at-best quadratic, running time in $p$ and $n$. We show that our bound on the expected number of 1-dimensional projections extends to the case of three or more Gaussian components, and we present a generalization of our results to mixture distributions beyond the Gaussian model.
MotionRNN: A Flexible Model for Video Prediction with Spacetime-Varying Motions
Mar 03, 2021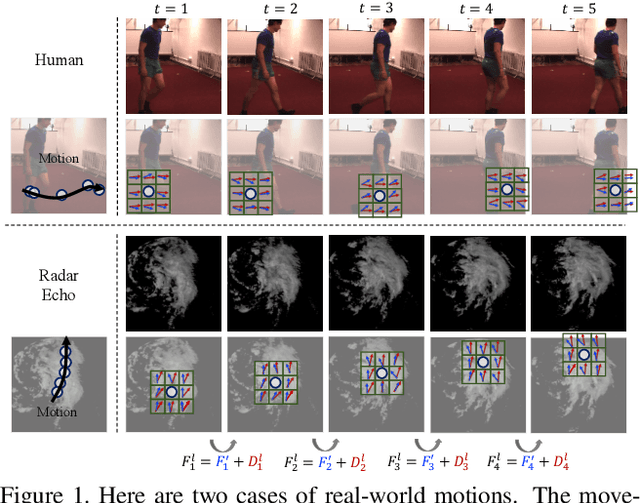
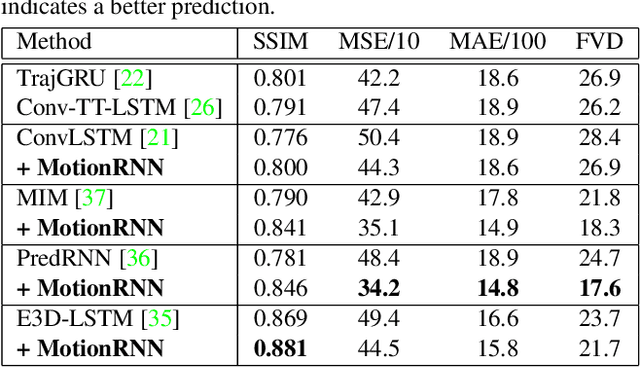
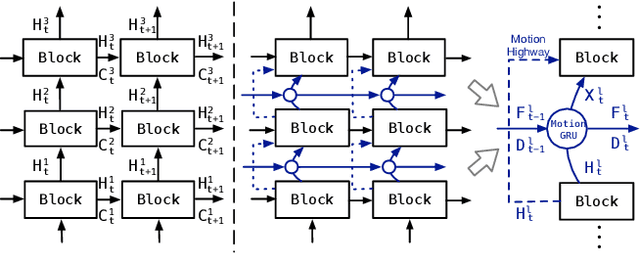
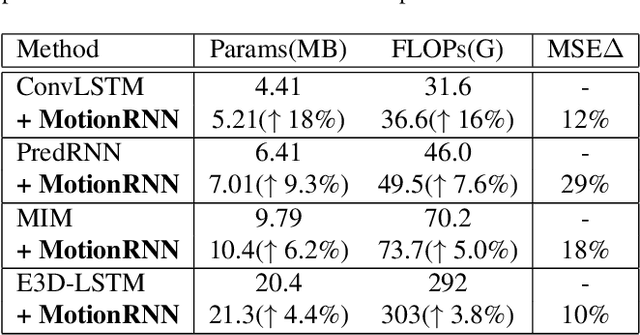
This paper tackles video prediction from a new dimension of predicting spacetime-varying motions that are incessantly changing across both space and time. Prior methods mainly capture the temporal state transitions but overlook the complex spatiotemporal variations of the motion itself, making them difficult to adapt to ever-changing motions. We observe that physical world motions can be decomposed into transient variation and motion trend, while the latter can be regarded as the accumulation of previous motions. Thus, simultaneously capturing the transient variation and the motion trend is the key to make spacetime-varying motions more predictable. Based on these observations, we propose the MotionRNN framework, which can capture the complex variations within motions and adapt to spacetime-varying scenarios. MotionRNN has two main contributions. The first is that we design the MotionGRU unit, which can model the transient variation and motion trend in a unified way. The second is that we apply the MotionGRU to RNN-based predictive models and indicate a new flexible video prediction architecture with a Motion Highway that can significantly improve the ability to predict changeable motions and avoid motion vanishing for stacked multiple-layer predictive models. With high flexibility, this framework can adapt to a series of models for deterministic spatiotemporal prediction. Our MotionRNN can yield significant improvements on three challenging benchmarks for video prediction with spacetime-varying motions.
EmoWrite: A Sentiment Analysis-Based Thought to Text Conversion
Mar 03, 2021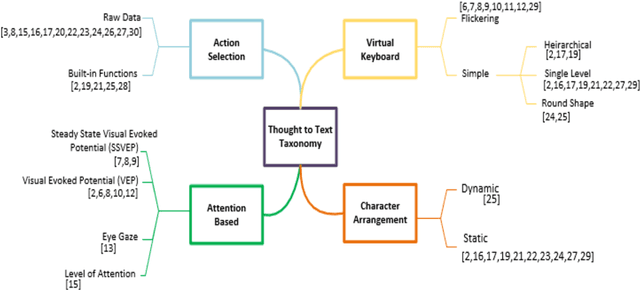
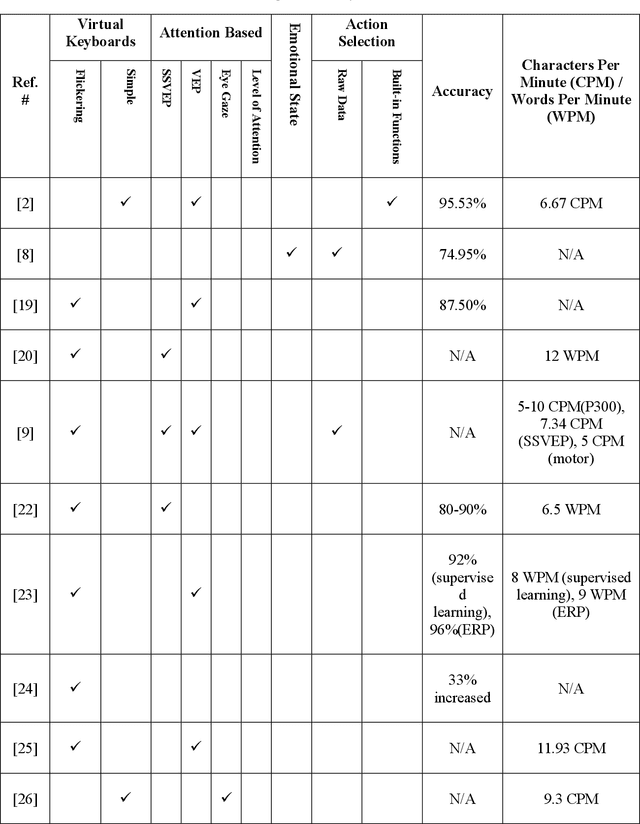
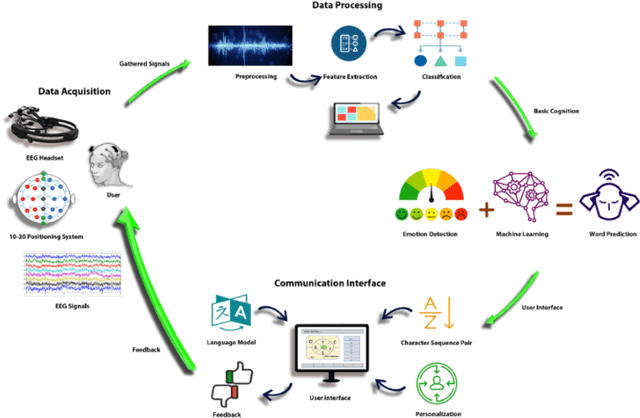

Brain Computer Interface (BCI) helps in processing and extraction of useful information from the acquired brain signals having applications in diverse fields such as military, medicine, neuroscience, and rehabilitation. BCI has been used to support paralytic patients having speech impediments with severe disabilities. To help paralytic patients communicate with ease, BCI based systems convert silent speech (thoughts) to text. However, these systems have an inconvenient graphical user interface, high latency, limited typing speed, and low accuracy rate. Apart from these limitations, the existing systems do not incorporate the inevitable factor of a patient's emotional states and sentiment analysis. The proposed system EmoWrite implements a dynamic keyboard with contextualized appearance of characters reducing the traversal time and improving the utilization of the screen space. The proposed system has been evaluated and compared with the existing systems for accuracy, convenience, sentimental analysis, and typing speed. This system results in 6.58 Words Per Minute (WPM) and 31.92 Characters Per Minute (CPM) with an accuracy of 90.36 percent. EmoWrite also gives remarkable results when it comes to the integration of emotional states. Its Information Transfer Rate (ITR) is also high as compared to other systems i.e., 87.55 bits per min with commands and 72.52 bits per min for letters. Furthermore, it provides easy to use interface with a latency of 2.685 sec.
Clutter Slices Approach for Identification-on-the-fly of Indoor Spaces
Jan 12, 2021
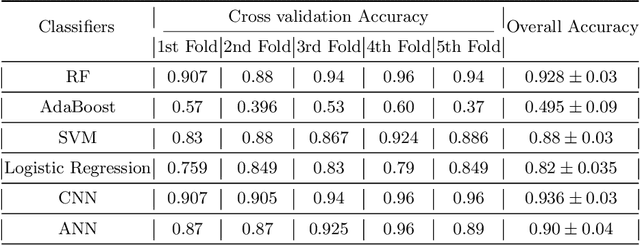
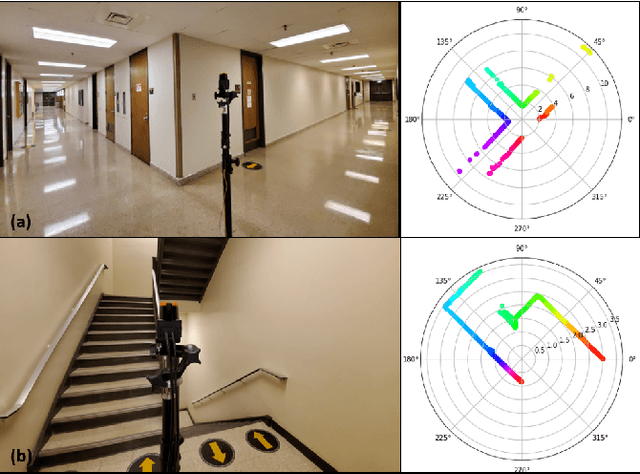
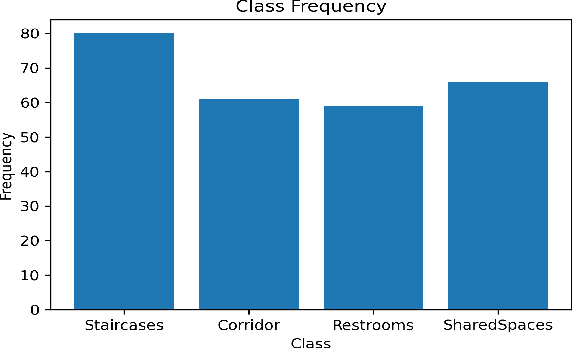
Construction spaces are constantly evolving, dynamic environments in need of continuous surveying, inspection, and assessment. Traditional manual inspection of such spaces proves to be an arduous and time-consuming activity. Automation using robotic agents can be an effective solution. Robots, with perception capabilities can autonomously classify and survey indoor construction spaces. In this paper, we present a novel identification-on-the-fly approach for coarse classification of indoor spaces using the unique signature of clutter. Using the context granted by clutter, we recognize common indoor spaces such as corridors, staircases, shared spaces, and restrooms. The proposed clutter slices pipeline achieves a maximum accuracy of 93.6% on the presented clutter slices dataset. This sensor independent approach can be generalized to various domains to equip intelligent autonomous agents in better perceiving their environment.
* First two authors share equal contribution. Presented at ICPR2020 The 25th International Conference on Pattern Recognition, PRAConBE Workshop
A Deep Neural Network for Pixel-Level Electromagnetic Particle Identification in the MicroBooNE Liquid Argon Time Projection Chamber
Aug 22, 2018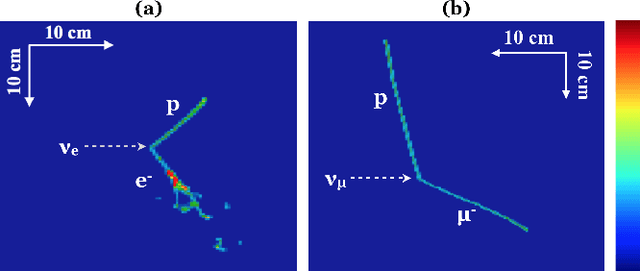
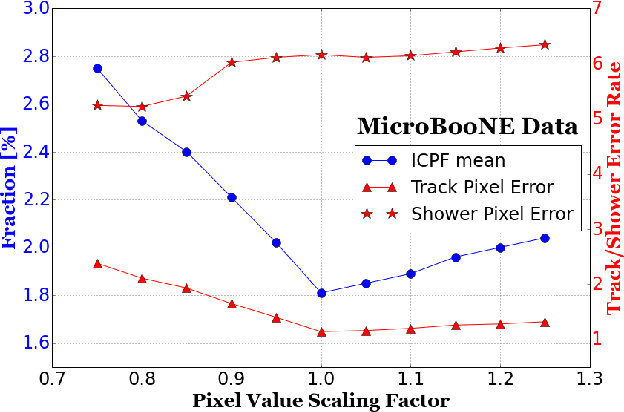
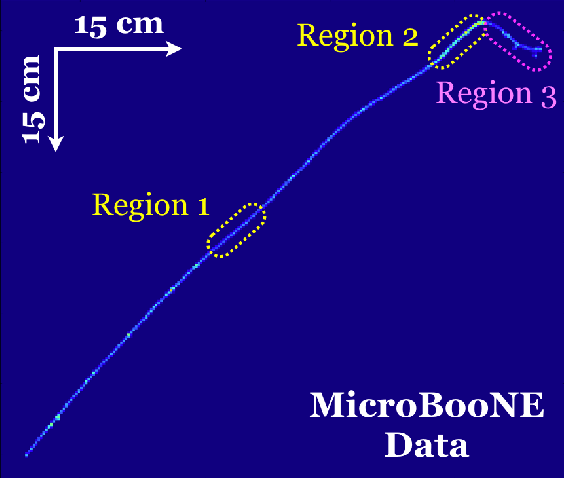
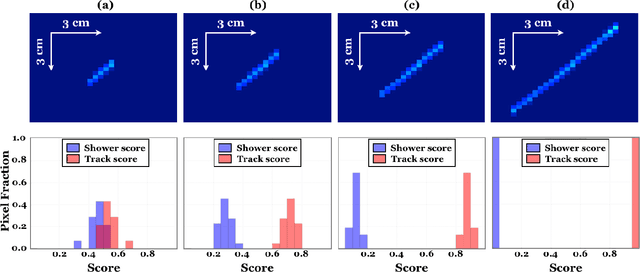
We have developed a convolutional neural network (CNN) that can make a pixel-level prediction of objects in image data recorded by a liquid argon time projection chamber (LArTPC) for the first time. We describe the network design, training techniques, and software tools developed to train this network. The goal of this work is to develop a complete deep neural network based data reconstruction chain for the MicroBooNE detector. We show the first demonstration of a network's validity on real LArTPC data using MicroBooNE collection plane images. The demonstration is performed for stopping muon and a $\nu_\mu$ charged current neutral pion data samples.
Strategic Argumentation Dialogues for Persuasion: Framework and Experiments Based on Modelling the Beliefs and Concerns of the Persuadee
Jan 28, 2021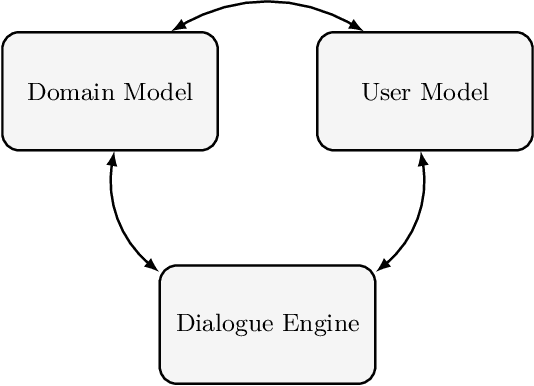


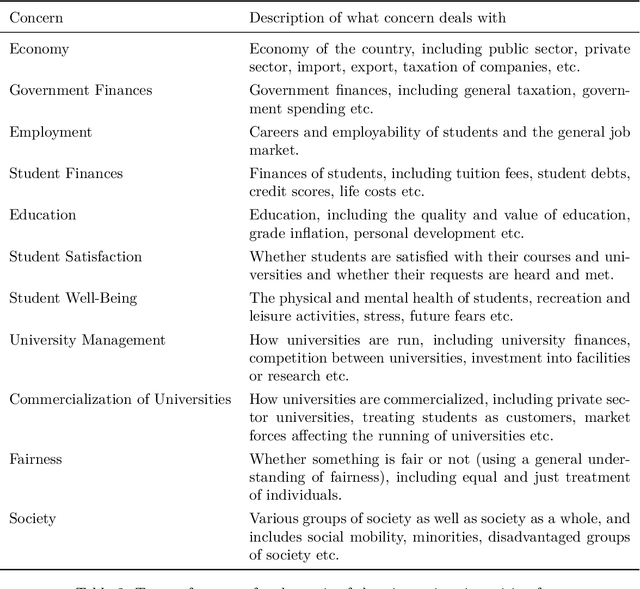
Persuasion is an important and yet complex aspect of human intelligence. When undertaken through dialogue, the deployment of good arguments, and therefore counterarguments, clearly has a significant effect on the ability to be successful in persuasion. Two key dimensions for determining whether an argument is good in a particular dialogue are the degree to which the intended audience believes the argument and counterarguments, and the impact that the argument has on the concerns of the intended audience. In this paper, we present a framework for modelling persuadees in terms of their beliefs and concerns, and for harnessing these models in optimizing the choice of move in persuasion dialogues. Our approach is based on the Monte Carlo Tree Search which allows optimization in real-time. We provide empirical results of a study with human participants showing that our automated persuasion system based on this technology is superior to a baseline system that does not take the beliefs and concerns into account in its strategy.