 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Greedy Search Algorithms for Unsupervised Variable Selection: A Comparative Study
Mar 03, 2021
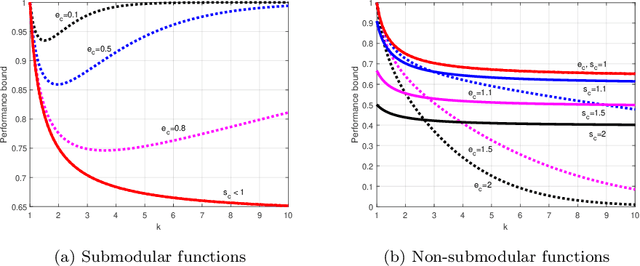
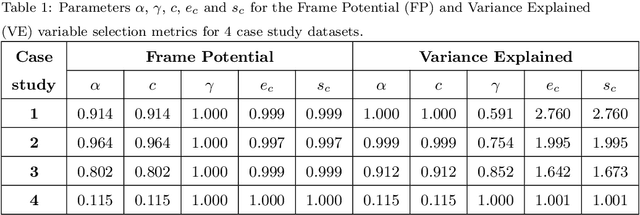
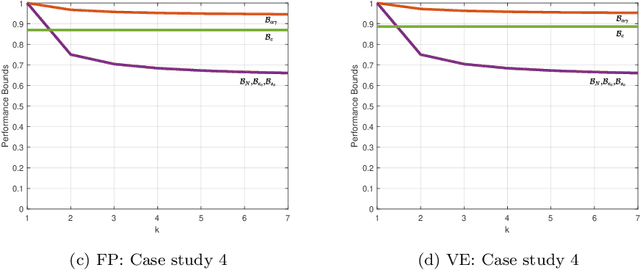

Dimensionality reduction is a important step in the development of scalable and interpretable data-driven models, especially when there are a large number of candidate variables. This paper focuses on unsupervised variable selection based dimensionality reduction, and in particular on unsupervised greedy selection methods, which have been proposed by various researchers as computationally tractable approximations to optimal subset selection. These methods are largely distinguished from each other by the selection criterion adopted, which include squared correlation, variance explained, mutual information and frame potential. Motivated by the absence in the literature of a systematic comparison of these different methods, we present a critical evaluation of seven unsupervised greedy variable selection algorithms considering both simulated and real world case studies. We also review the theoretical results that provide performance guarantees and enable efficient implementations for certain classes of greedy selection function, related to the concept of submodularity. Furthermore, we introduce and evaluate for the first time, a lazy implementation of the variance explained based forward selection component analysis (FSCA) algorithm. Our experimental results show that: (1) variance explained and mutual information based selection methods yield smaller approximation errors than frame potential; (2) the lazy FSCA implementation has similar performance to FSCA, while being an order of magnitude faster to compute, making it the algorithm of choice for unsupervised variable selection.
Robustly Learning Mixtures of $k$ Arbitrary Gaussians
Dec 31, 2020
We give a polynomial-time algorithm for the problem of robustly estimating a mixture of $k$ arbitrary Gaussians in $\mathbb{R}^d$, for any fixed $k$, in the presence of a constant fraction of arbitrary corruptions. This resolves the main open problem in several previous works on algorithmic robust statistics, which addressed the special cases of robustly estimating (a) a single Gaussian, (b) a mixture of TV-distance separated Gaussians, and (c) a uniform mixture of two Gaussians. Our main tools are an efficient \emph{partial clustering} algorithm that relies on the sum-of-squares method, and a novel tensor decomposition algorithm that allows errors in both Frobenius norm and low-rank terms.
Generalization of Model-Agnostic Meta-Learning Algorithms: Recurring and Unseen Tasks
Feb 07, 2021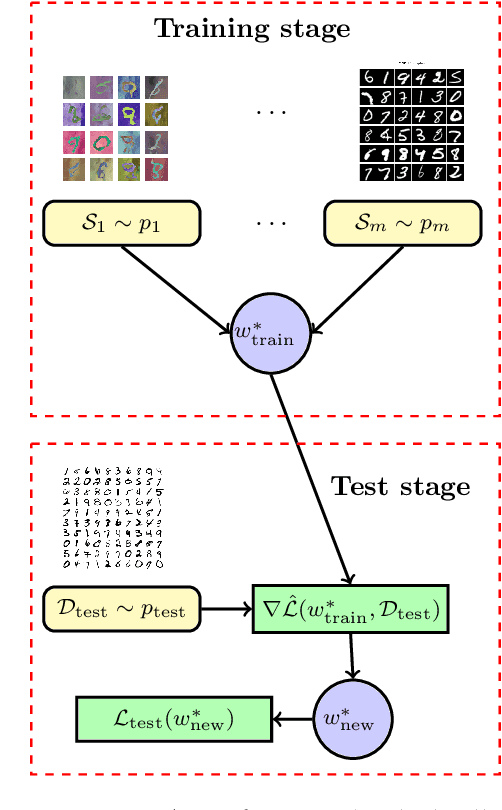
In this paper, we study the generalization properties of Model-Agnostic Meta-Learning (MAML) algorithms for supervised learning problems. We focus on the setting in which we train the MAML model over $m$ tasks, each with $n$ data points, and characterize its generalization error from two points of view: First, we assume the new task at test time is one of the training tasks, and we show that, for strongly convex objective functions, the expected excess population loss is bounded by $\mathcal{O}(1/mn)$. Second, we consider the MAML algorithm's generalization to an unseen task and show that the resulting generalization error depends on the total variation distance between the underlying distributions of the new task and the tasks observed during the training process. Our proof techniques rely on the connections between algorithmic stability and generalization bounds of algorithms. In particular, we propose a new definition of stability for meta-learning algorithms, which allows us to capture the role of both the number of tasks $m$ and number of samples per task $n$ on the generalization error of MAML.
Non-Holonomic RRT & MPC: Path and Trajectory Planning for an Autonomous Cycle Rickshaw
Mar 10, 2021



This paper presents a novel hierarchical motion planning approach based on Rapidly-Exploring Random Trees (RRT) for global planning and Model Predictive Control (MPC) for local planning. The approach targets a three-wheeled cycle rickshaw (trishaw) used for autonomous urban transportation in shared spaces. Due to the nature of the vehicle, the algorithms had to be adapted in order to adhere to non-holonomic kinematic constraints using the Kinematic Single-Track Model. The vehicle is designed to offer transportation for people and goods in shared environments such as roads, sidewalks, bicycle lanes but also open spaces that are often occupied by other traffic participants. Therefore, the algorithm presented in this paper needs to anticipate and avoid dynamic obstacles, such as pedestrians or bicycles, but also be fast enough in order to work in real-time so that it can adapt to changes in the environment. Our approach uses an RRT variant for global planning that has been modified for single-track kinematics and improved by exploiting dead-end nodes. This allows us to compute global paths in unstructured environments very fast. In a second step, our MPC-based local planner makes use of the global path to compute the vehicle's trajectory while incorporating dynamic obstacles such as pedestrians and other road users. Our approach has shown to work both in simulation as well as first real-life tests and can be easily extended for more sophisticated behaviors.
Stream Graphs and Link Streams for the Modeling of Interactions over Time
Oct 11, 2017

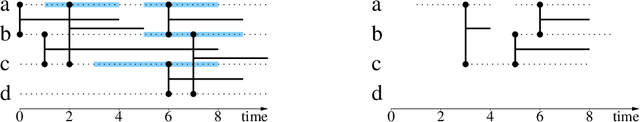
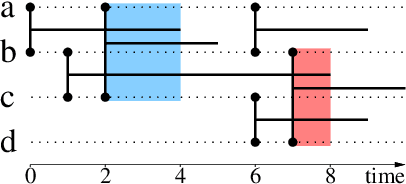
Graph theory provides a language for studying the structure of relations, and it is often used to study interactions over time too. However, it poorly captures the both temporal and structural nature of interactions, that calls for a dedicated formalism. In this paper, we generalize graph concepts in order to cope with both aspects in a consistent way. We start with elementary concepts like density, clusters, or paths, and derive from them more advanced concepts like cliques, degrees, clustering coefficients, or connected components. We obtain a language to directly deal with interactions over time, similar to the language provided by graphs to deal with relations. This formalism is self-consistent: usual relations between different concepts are preserved. It is also consistent with graph theory: graph concepts are special cases of the ones we introduce. This makes it easy to generalize higher-level objects such as quotient graphs, line graphs, k-cores, and centralities. This paper also considers discrete versus continuous time assumptions, instantaneous links, and extensions to more complex cases.
Scalable Learning With a Structural Recurrent Neural Network for Short-Term Traffic Prediction
Mar 03, 2021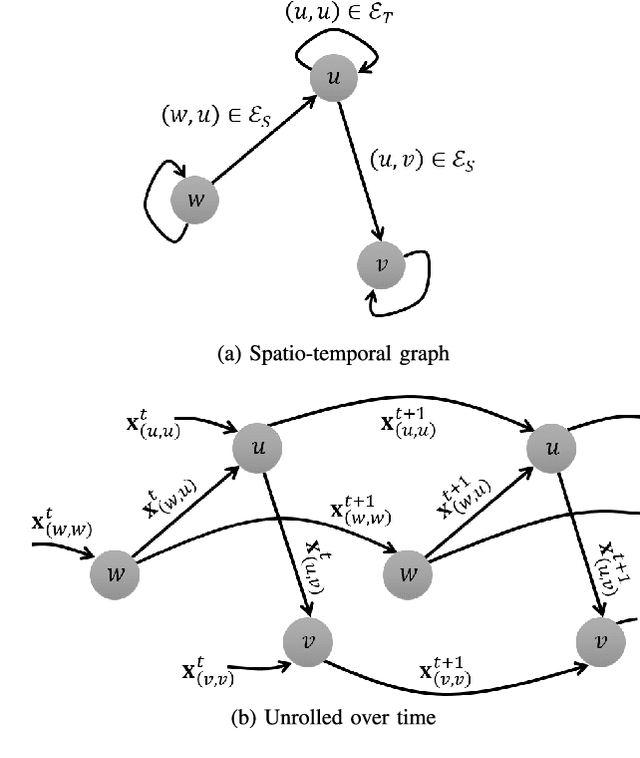
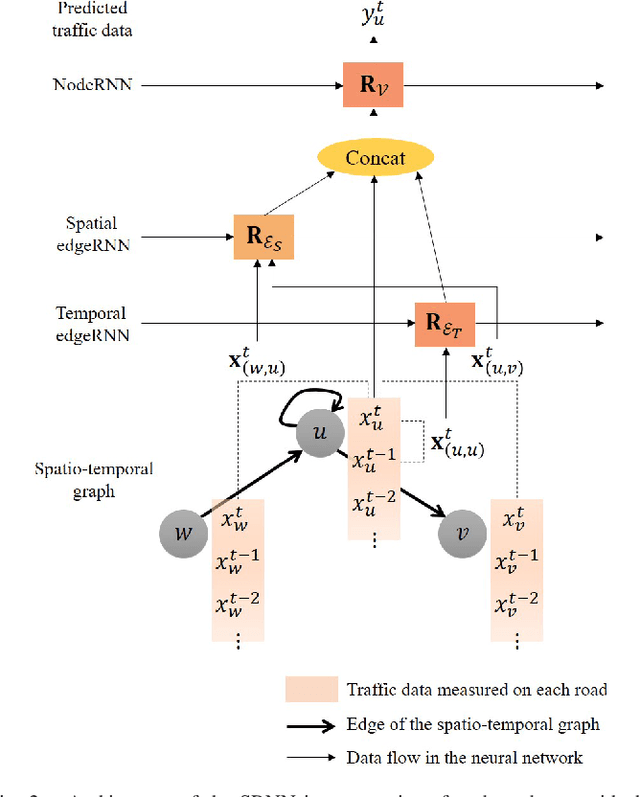
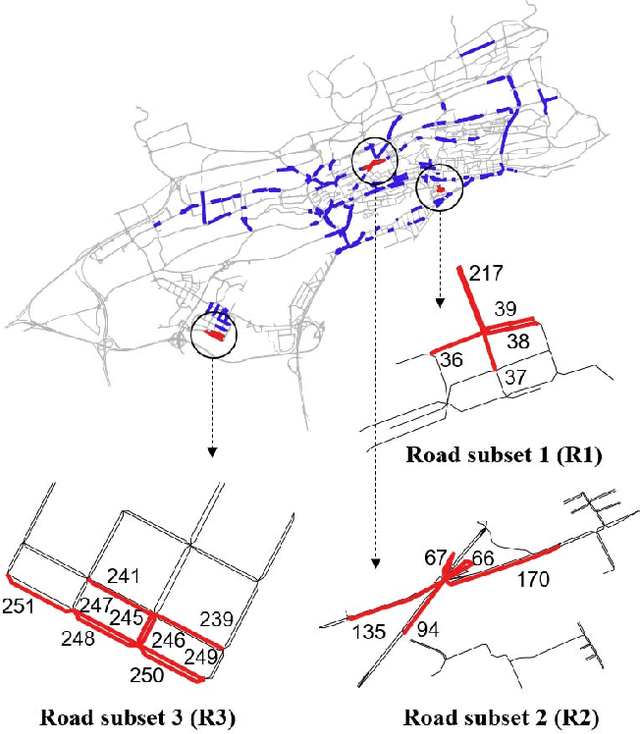
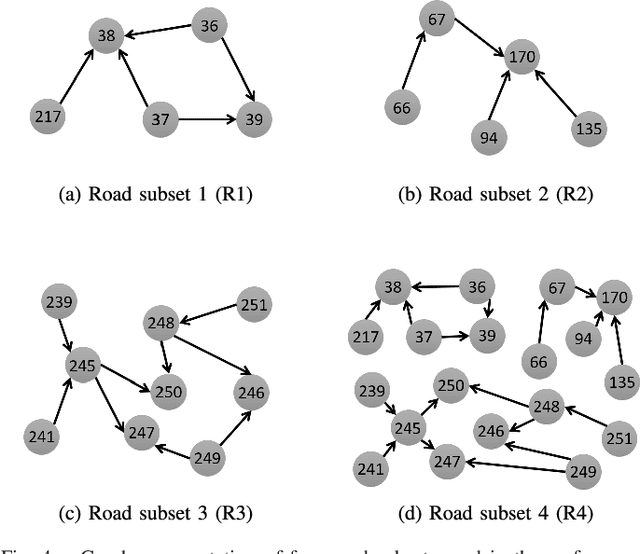
This paper presents a scalable deep learning approach for short-term traffic prediction based on historical traffic data in a vehicular road network. Capturing the spatio-temporal relationship of the big data often requires a significant amount of computational burden or an ad-hoc design aiming for a specific type of road network. To tackle the problem, we combine a road network graph with recurrent neural networks (RNNs) to construct a structural RNN (SRNN). The SRNN employs a spatio-temporal graph to infer the interaction between adjacent road segments as well as the temporal dynamics of the time series data. The model is scalable thanks to two key aspects. First, the proposed SRNN architecture is built by using the semantic similarity of the spatio-temporal dynamic interactions of all segments. Second, we design the architecture to deal with fixed-length tensors regardless of the graph topology. With the real traffic speed data measured in the city of Santander, we demonstrate the proposed SRNN outperforms the image-based approaches using the capsule network (CapsNet) by 14.1% and the convolutional neural network (CNN) by 5.87%, respectively, in terms of root mean squared error (RMSE). Moreover, we show that the proposed model is scalable. The SRNN model trained with data of a road network is able to predict traffic speed of different road networks, with the fixed number of parameters to train.
* 9 pages, 6 figures
Gamified and Self-Adaptive Applications for the Common Good: Research Challenges Ahead
Mar 22, 2021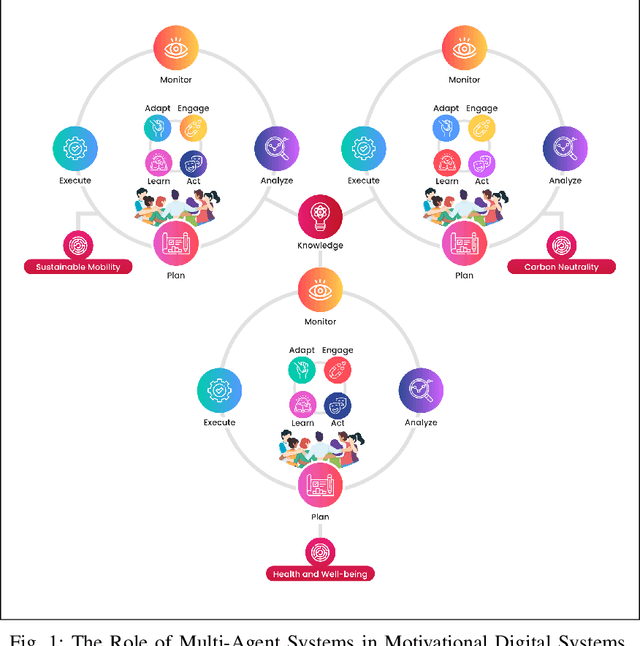
Motivational digital systems offer capabilities to engage and motivate end-users to foster behavioral changes towards a common goal. In general these systems use gamification principles in non-games contexts. Over the years, gamification has gained consensus among researchers and practitioners as a tool to motivate people to perform activities with the ultimate goal of promoting behavioural change, or engaging the users to perform activities that can offer relevant benefits but which can be seen as unrewarding and even tedious. There exists a plethora of heterogeneous application scenarios towards reaching the common good that can benefit from gamification. However, an open problem is how to effectively combine multiple motivational campaigns to maximise the degree of participation without exposing the system to counterproductive behaviours. We conceive motivational digital systems as multi-agent systems: self-adaptation is a feature of the overall system, while individual agents may self-adapt in order to leverage other agents' resources, functionalities and capabilities to perform tasks more efficiently and effectively. Consequently, multiple campaigns can be run and adapted to reach common good. At the same time, agents are grouped into micro-communities in which agents contribute with their own social capital and leverage others' capabilities to balance their weaknesses. In this paper we propose our vision on how the principles at the base of the autonomous and multi-agent systems can be exploited to design multi-challenge motivational systems to engage smart communities towards common goals. We present an initial version of a general framework based on the MAPE-K loop and a set of research challenges that characterise our research roadmap for the implementation of our vision.
Tilting the playing field: Dynamical loss functions for machine learning
Feb 07, 2021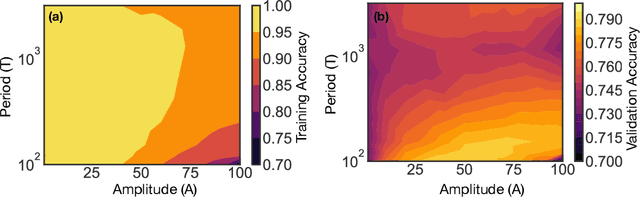
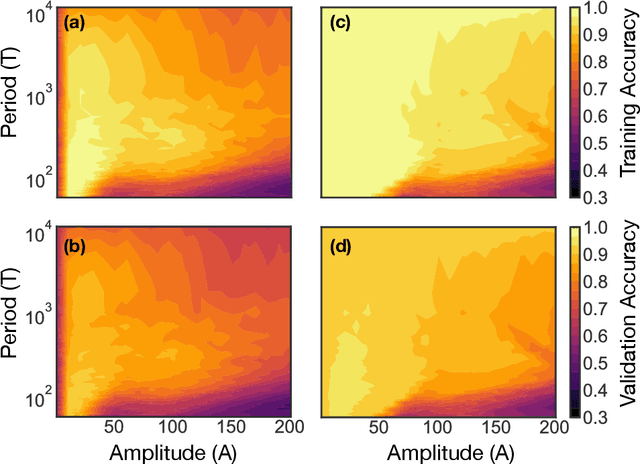
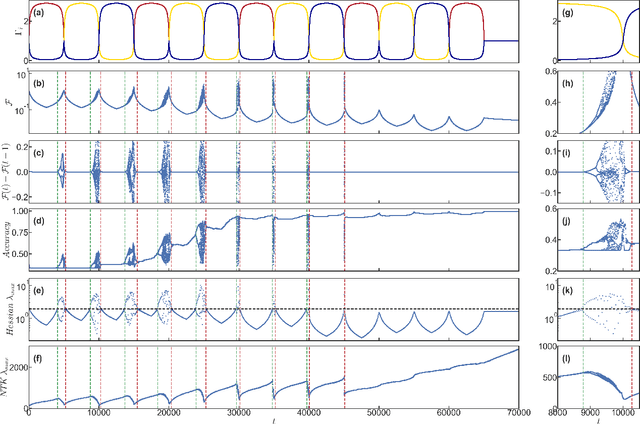
We show that learning can be improved by using loss functions that evolve cyclically during training to emphasize one class at a time. In underparameterized networks, such dynamical loss functions can lead to successful training for networks that fail to find a deep minima of the standard cross-entropy loss. In overparameterized networks, dynamical loss functions can lead to better generalization. Improvement arises from the interplay of the changing loss landscape with the dynamics of the system as it evolves to minimize the loss. In particular, as the loss function oscillates, instabilities develop in the form of bifurcation cascades, which we study using the Hessian and Neural Tangent Kernel. Valleys in the landscape widen and deepen, and then narrow and rise as the loss landscape changes during a cycle. As the landscape narrows, the learning rate becomes too large and the network becomes unstable and bounces around the valley. This process ultimately pushes the system into deeper and wider regions of the loss landscape and is characterized by decreasing eigenvalues of the Hessian. This results in better regularized models with improved generalization performance.
School of hard knocks: Curriculum analysis for Pommerman with a fixed computational budget
Feb 24, 2021
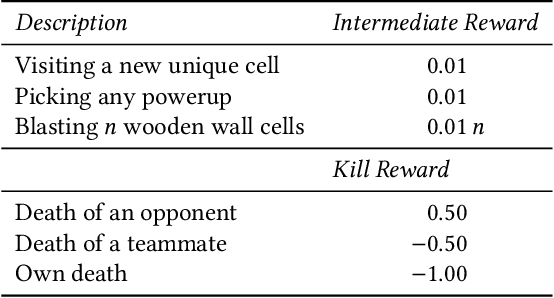

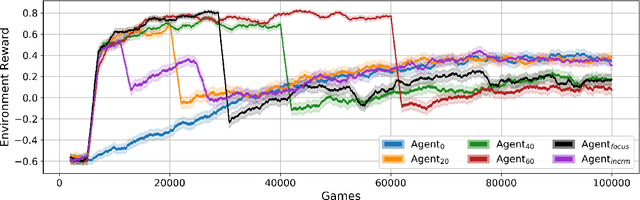
Pommerman is a hybrid cooperative/adversarial multi-agent environment, with challenging characteristics in terms of partial observability, limited or no communication, sparse and delayed rewards, and restrictive computational time limits. This makes it a challenging environment for reinforcement learning (RL) approaches. In this paper, we focus on developing a curriculum for learning a robust and promising policy in a constrained computational budget of 100,000 games, starting from a fixed base policy (which is itself trained to imitate a noisy expert policy). All RL algorithms starting from the base policy use vanilla proximal-policy optimization (PPO) with the same reward function, and the only difference between their training is the mix and sequence of opponent policies. One expects that beginning training with simpler opponents and then gradually increasing the opponent difficulty will facilitate faster learning, leading to more robust policies compared against a baseline where all available opponent policies are introduced from the start. We test this hypothesis and show that within constrained computational budgets, it is in fact better to "learn in the school of hard knocks", i.e., against all available opponent policies nearly from the start. We also include ablation studies where we study the effect of modifying the base environment properties of ammo and bomb blast strength on the agent performance.
A generative, predictive model for menstrual cycle lengths that accounts for potential self-tracking artifacts in mobile health data
Mar 16, 2021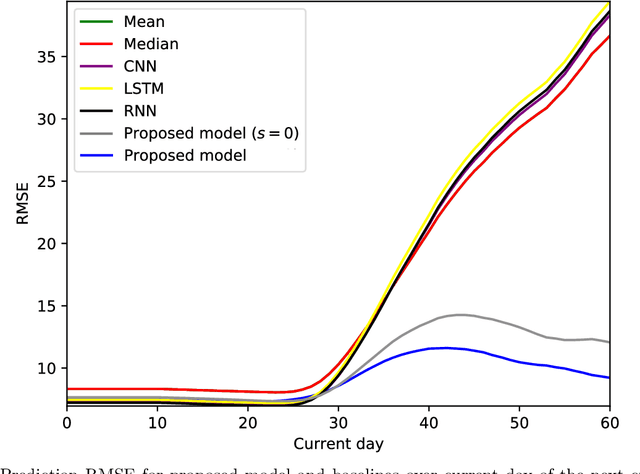
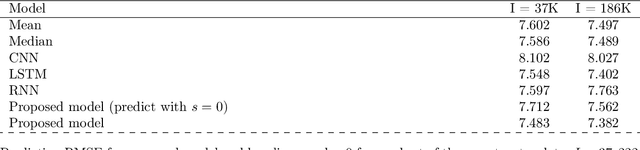
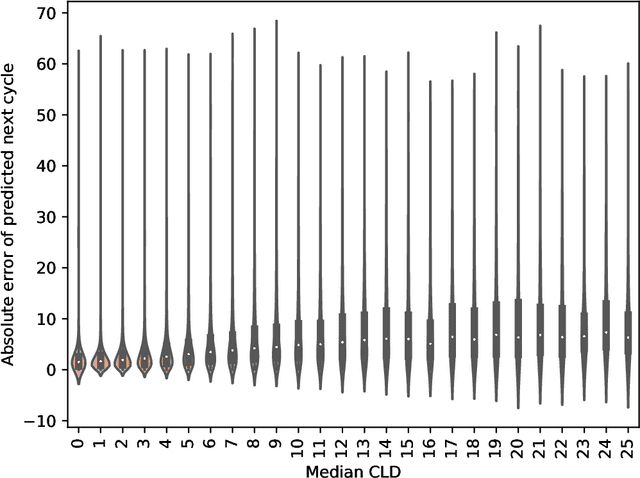

Mobile health (mHealth) apps such as menstrual trackers provide a rich source of self-tracked health observations that can be leveraged for health-relevant research. However, such data streams have questionable reliability since they hinge on user adherence to the app. Therefore, it is crucial for researchers to separate true behavior from self-tracking artifacts. By taking a machine learning approach to modeling self-tracked cycle lengths, we can both make more informed predictions and learn the underlying structure of the observed data. In this work, we propose and evaluate a hierarchical, generative model for predicting next cycle length based on previously-tracked cycle lengths that accounts explicitly for the possibility of users skipping tracking their period. Our model offers several advantages: 1) accounting explicitly for self-tracking artifacts yields better prediction accuracy as likelihood of skipping increases; 2) because it is a generative model, predictions can be updated online as a given cycle evolves, and we can gain interpretable insight into how these predictions change over time; and 3) its hierarchical nature enables modeling of an individual's cycle length history while incorporating population-level information. Our experiments using mHealth cycle length data encompassing over 186,000 menstruators with over 2 million natural menstrual cycles show that our method yields state-of-the-art performance against neural network-based and summary statistic-based baselines, while providing insights on disentangling menstrual patterns from self-tracking artifacts. This work can benefit users, mHealth app developers, and researchers in better understanding cycle patterns and user adherence.