 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Predicting litigation likelihood and time to litigation for patents
Mar 23, 2016
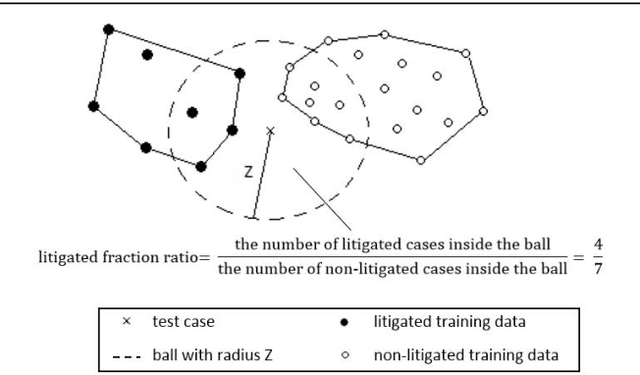
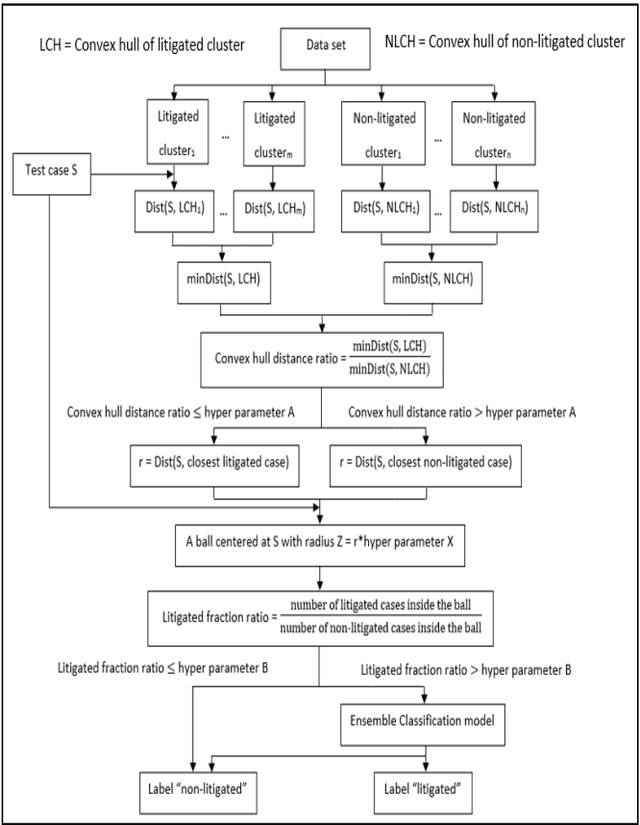
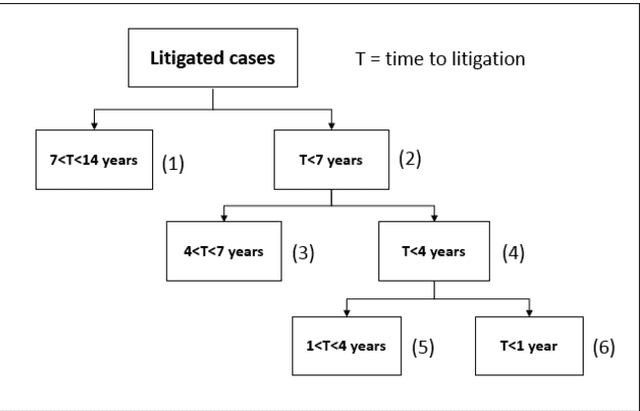
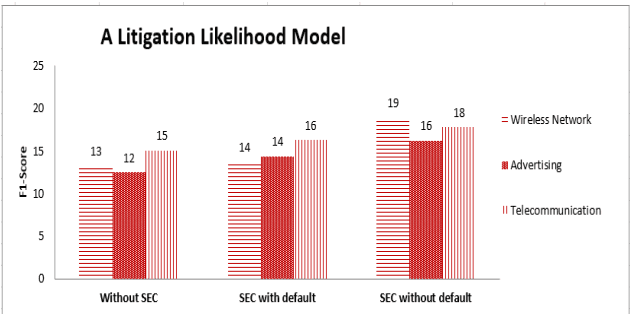
Patent lawsuits are costly and time-consuming. An ability to forecast a patent litigation and time to litigation allows companies to better allocate budget and time in managing their patent portfolios. We develop predictive models for estimating the likelihood of litigation for patents and the expected time to litigation based on both textual and non-textual features. Our work focuses on improving the state-of-the-art by relying on a different set of features and employing more sophisticated algorithms with more realistic data. The rate of patent litigations is very low, which consequently makes the problem difficult. The initial model for predicting the likelihood is further modified to capture a time-to-litigation perspective.
Online Coresets for Clustering with Bregman Divergences
Dec 11, 2020
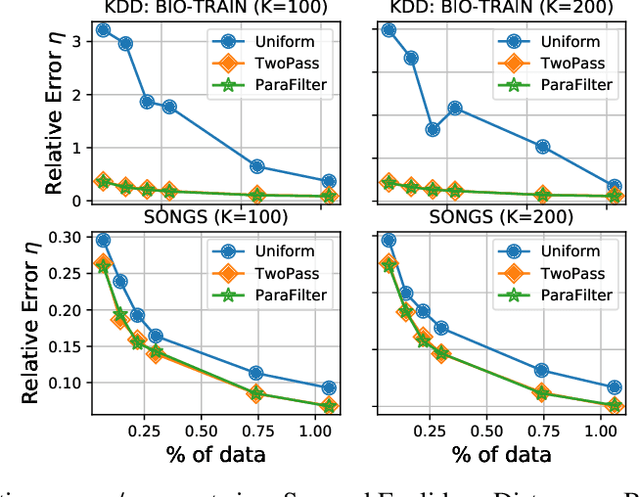
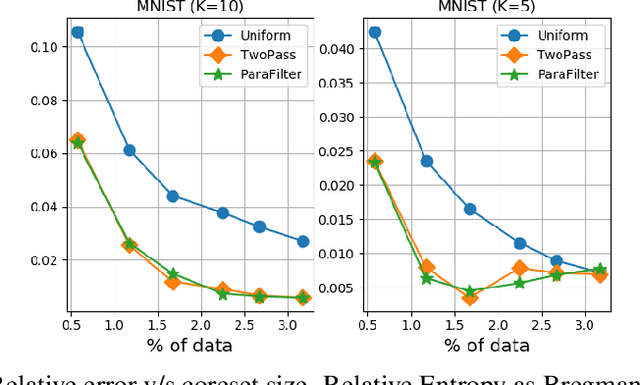
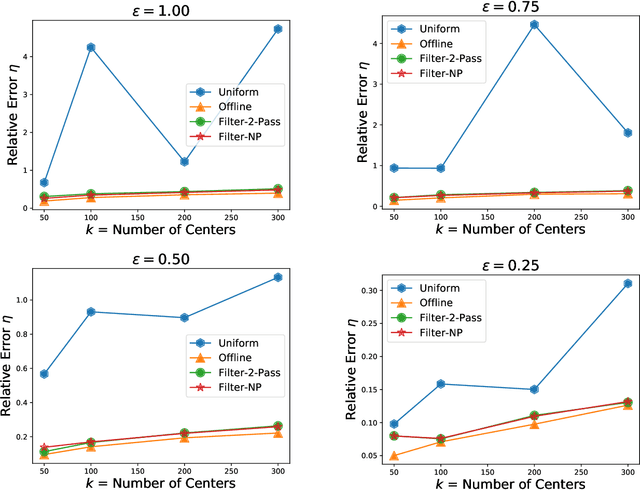
We present algorithms that create coresets in an online setting for clustering problems according to a wide subset of Bregman divergences. Notably, our coresets have a small additive error, similar in magnitude to the lightweight coresets Bachem et. al. 2018, and take update time $O(d)$ for every incoming point where $d$ is dimension of the point. Our first algorithm gives online coresets of size $\tilde{O}(\mbox{poly}(k,d,\epsilon,\mu))$ for $k$-clusterings according to any $\mu$-similar Bregman divergence. We further extend this algorithm to show existence of a non-parametric coresets, where the coreset size is independent of $k$, the number of clusters, for the same subclass of Bregman divergences. Our non-parametric coresets are larger by a factor of $O(\log n)$ ($n$ is number of points) and have similar (small) additive guarantee. At the same time our coresets also function as lightweight coresets for non-parametric versions of the Bregman clustering like DP-Means. While these coresets provide additive error guarantees, they are also significantly smaller (scaling with $O(\log n)$ as opposed to $O(d^d)$ for points in $\~R^d$) than the (relative-error) coresets obtained in Bachem et. al. 2015 for DP-Means. While our non-parametric coresets are existential, we give an algorithmic version under certain assumptions.
Capture the Bot: Using Adversarial Examples to Improve CAPTCHA Robustness to Bot Attacks
Oct 30, 2020



To this date, CAPTCHAs have served as the first line of defense preventing unauthorized access by (malicious) bots to web-based services, while at the same time maintaining a trouble-free experience for human visitors. However, recent work in the literature has provided evidence of sophisticated bots that make use of advancements in machine learning (ML) to easily bypass existing CAPTCHA-based defenses. In this work, we take the first step to address this problem. We introduce CAPTURE, a novel CAPTCHA scheme based on adversarial examples. While typically adversarial examples are used to lead an ML model astray, to the best of our knowledge, CAPTURE is the first work to make a "good use" of such mechanisms. Our empirical evaluations show that CAPTURE can produce CAPTCHAs that are easy to solve by humans while at the same time, effectively thwarting ML-based bot solvers.
GVINS: Tightly Coupled GNSS-Visual-Inertial Fusion for Smooth and Consistent State Estimation
Apr 01, 2021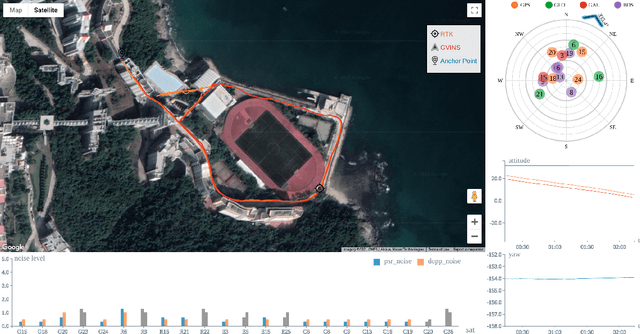
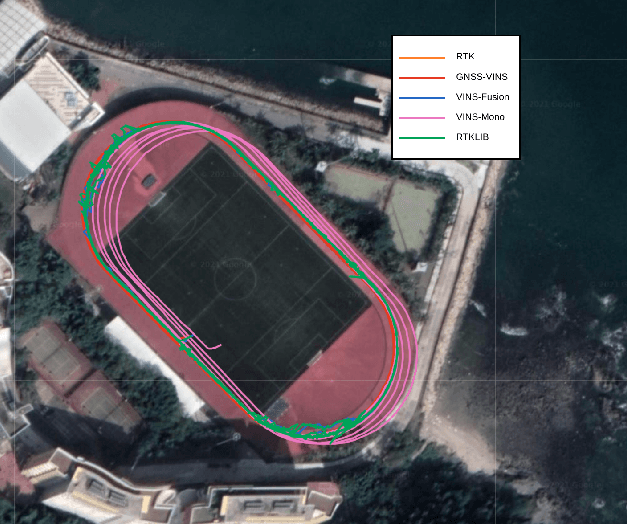
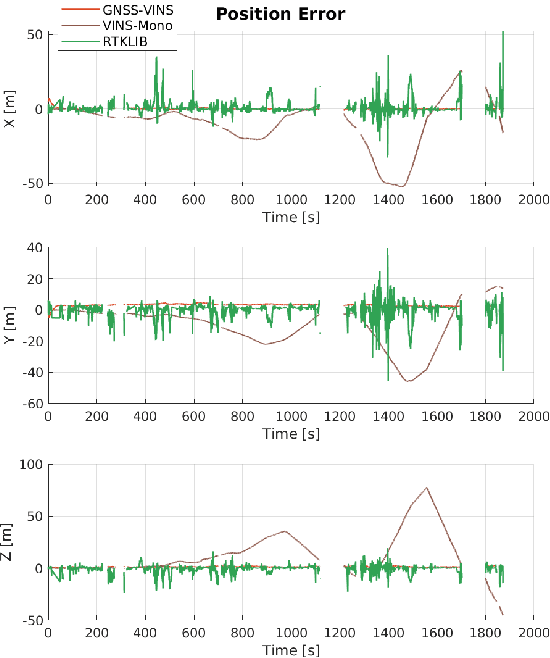
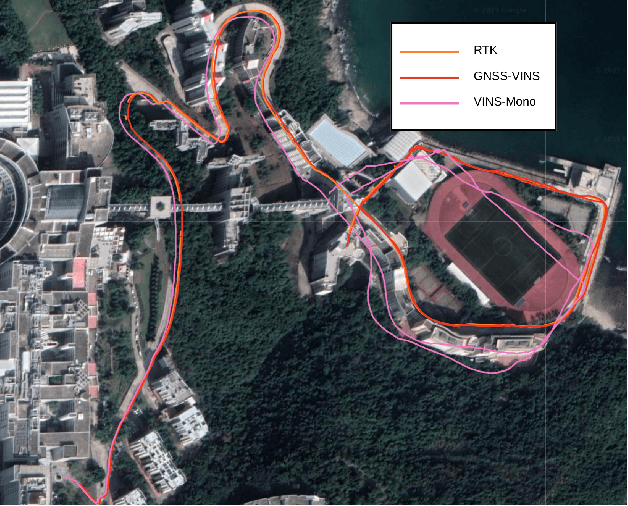
Visual-Inertial odometry (VIO) is known to suffer from drifting especially over long-term runs. In this paper, we present GVINS, a non-linear optimization based system that tightly fuses GNSS raw measurements with visual and inertial information for real-time and drift-free state estimation. Our system is aiming to provide accurate global 6-DoF estimation under complex indoor-outdoor environment where GNSS signals may be largely intercepted or even totally unavailable. To connect global measurements with local states, a coarse-to-fine initialization procedure is proposed to efficiently online calibrate the transformation and initialize GNSS states from only a short window of measurements. The GNSS pseudorange and Doppler shift measurements are then modelled and optimized under a factor graph framework along with visual and inertial constraints. For complex and GNSS-unfriendly areas, the degenerate cases are discussed and carefully handled to ensure robustness. The engineering challenges involved in the system are also included to facilitate relevant GNSS fusion researches. Thanks to the tightly-coupled multi-sensor approach and system design, our system fully exploits the merits of three types of sensors and is capable to seamlessly cope with the transition between indoor and outdoor environments, where satellites are lost and recaptured again. We extensively evaluate the proposed system by both simulation and real-world experiments, and the result demonstrates that our system substantially eliminates the drift of VIO and preserves the local accuracy in spite of noisy GNSS measurements. In addition, experiments also show that our system can gain from even a single satellite while conventional GNSS algorithms need four at lease.
Robot Navigation in a Crowd by Integrating Deep Reinforcement Learning and Online Planning
Feb 26, 2021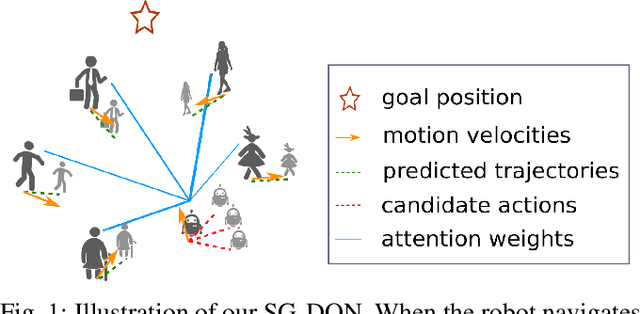
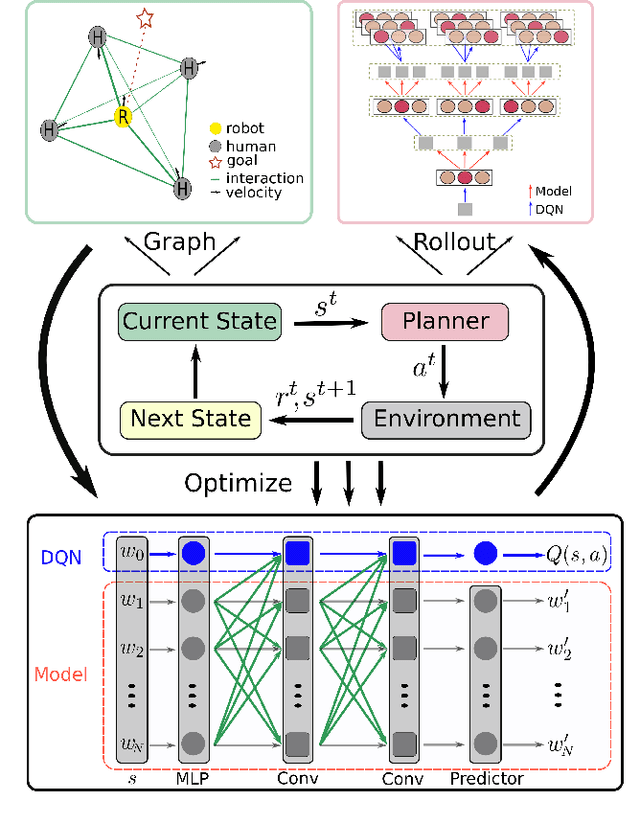
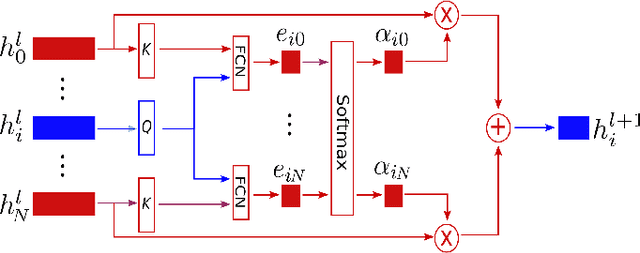
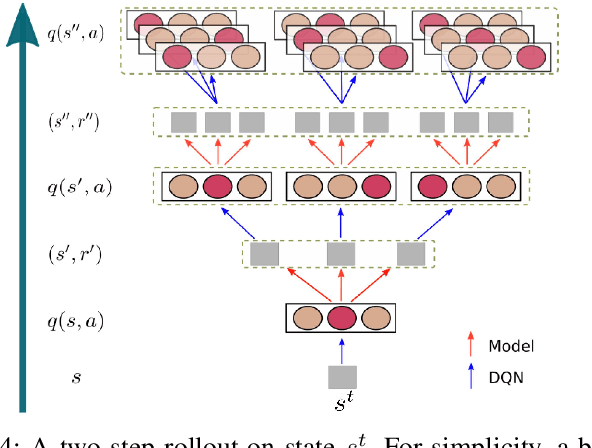
It is still an open and challenging problem for mobile robots navigating along time-efficient and collision-free paths in a crowd. The main challenge comes from the complex and sophisticated interaction mechanism, which requires the robot to understand the crowd and perform proactive and foresighted behaviors. Deep reinforcement learning is a promising solution to this problem. However, most previous learning methods incur a tremendous computational burden. To address these problems, we propose a graph-based deep reinforcement learning method, SG-DQN, that (i) introduces a social attention mechanism to extract an efficient graph representation for the crowd-robot state; (ii) directly evaluates the coarse q-values of the raw state with a learned dueling deep Q network(DQN); and then (iii) refines the coarse q-values via online planning on possible future trajectories. The experimental results indicate that our model can help the robot better understand the crowd and achieve a high success rate of more than 0.99 in the crowd navigation task. Compared against previous state-of-the-art algorithms, our algorithm achieves an equivalent, if not better, performance while requiring less than half of the computational cost.
Resource Allocation in Multi-armed Bandit Exploration: Overcoming Nonlinear Scaling with Adaptive Parallelism
Oct 31, 2020
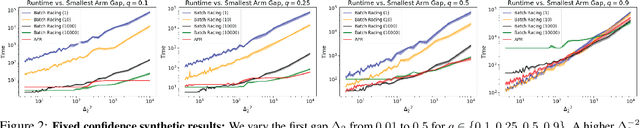
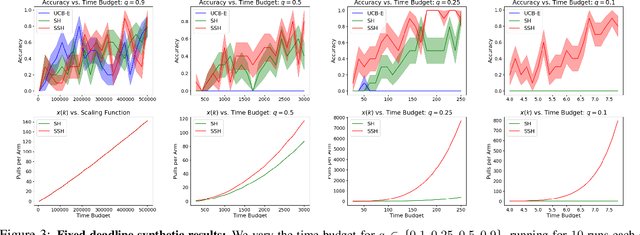
We study exploration in stochastic multi-armed bandits when we have access to a divisible resource, and can allocate varying amounts of this resource to arm pulls. By allocating more resources to a pull, we can compute the outcome faster to inform subsequent decisions about which arms to pull. However, since distributed environments do not scale linearly, executing several arm pulls in parallel, and hence less resources per pull, may result in better throughput. For example, in simulation-based scientific studies, an expensive simulation can be sped up by running it on multiple cores. This speed-up is, however, partly offset by the communication among cores and overheads, which results in lower throughput than if fewer cores were allocated to run more trials in parallel. We explore these trade-offs in the fixed confidence setting, where we need to find the best arm with a given success probability, while minimizing the time to do so. We propose an algorithm which trades off between information accumulation and throughout and show that the time taken can be upper bounded by the solution of a dynamic program whose inputs are the squared gaps between the suboptimal and optimal arms. We prove a matching hardness result which demonstrates that the above dynamic program is fundamental to this problem. Next, we propose and analyze an algorithm for the fixed deadline setting, where we are given a time deadline and need to maximize the success probability of finding the best arm. We corroborate these theoretical insights with an empirical evaluation.
Classifier Crafting: Turn Your ConvNet into a Zero-Shot Learner!
Mar 20, 2021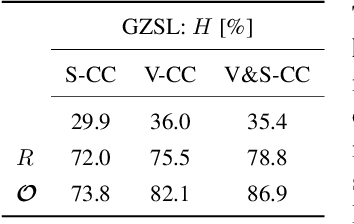
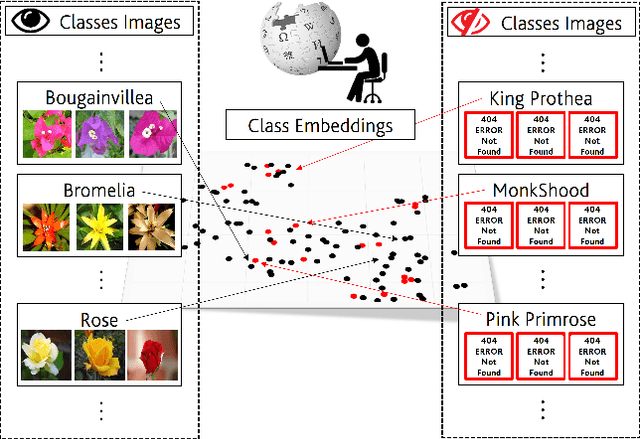
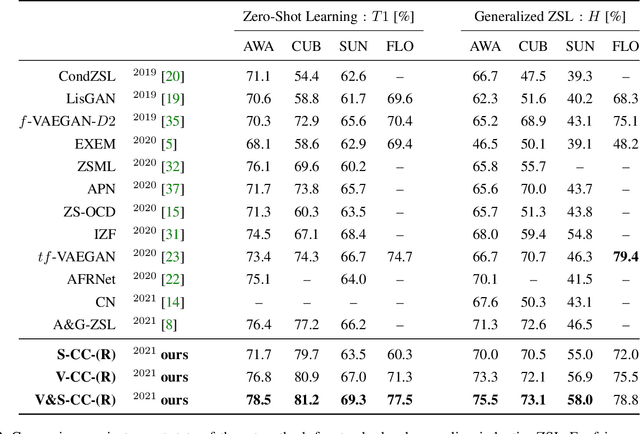
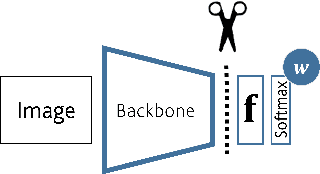
In Zero-shot learning (ZSL), we classify unseen categories using textual descriptions about their expected appearance when observed (class embeddings) and a disjoint pool of seen classes, for which annotated visual data are accessible. We tackle ZSL by casting a "vanilla" convolutional neural network (e.g. AlexNet, ResNet-101, DenseNet-201 or DarkNet-53) into a zero-shot learner. We do so by crafting the softmax classifier: we freeze its weights using fixed seen classification rules, either semantic (seen class embeddings) or visual (seen class prototypes). Then, we learn a data-driven and ZSL-tailored feature representation on seen classes only to match these fixed classification rules. Given that the latter seamlessly generalize towards unseen classes, while requiring not actual unseen data to be computed, we can perform ZSL inference by augmenting the pool of classification rules at test time while keeping the very same representation we learnt: nowhere re-training or fine-tuning on unseen data is performed. The combination of semantic and visual crafting (by simply averaging softmax scores) improves prior state-of-the-art methods in benchmark datasets for standard, inductive ZSL. After rebalancing predictions to better handle the joint inference over seen and unseen classes, we outperform prior generalized, inductive ZSL methods as well. Also, we gain interpretability at no additional cost, by using neural attention methods (e.g., grad-CAM) as they are. Code will be made publicly available.
On Subspace Approximation and Subset Selection in Fewer Passes by MCMC Sampling
Mar 20, 2021We consider the problem of subset selection for $\ell_{p}$ subspace approximation, i.e., given $n$ points in $d$ dimensions, we need to pick a small, representative subset of the given points such that its span gives $(1+\epsilon)$ approximation to the best $k$-dimensional subspace that minimizes the sum of $p$-th powers of distances of all the points to this subspace. Sampling-based subset selection techniques require adaptive sampling iterations with multiple passes over the data. Matrix sketching techniques give a single-pass $(1+\epsilon)$ approximation for $\ell_{p}$ subspace approximation but require additional passes for subset selection. In this work, we propose an MCMC algorithm to reduce the number of passes required by previous subset selection algorithms based on adaptive sampling. For $p=2$, our algorithm gives subset selection of nearly optimal size in only $2$ passes, whereas the number of passes required in previous work depend on $k$. Our algorithm picks a subset of size $\mathrm{poly}(k/\epsilon)$ that gives $(1+\epsilon)$ approximation to the optimal subspace. The running time of the algorithm is $nd + d~\mathrm{poly}(k/\epsilon)$. We extend our results to the case when outliers are present in the datasets, and suggest a two pass algorithm for the same. Our ideas also extend to give a reduction in the number of passes required by adaptive sampling algorithms for $\ell_{p}$ subspace approximation and subset selection, for $p \geq 2$.
LAC : LSTM AUTOENCODER with Community for Insider Threat Detection
Aug 13, 2020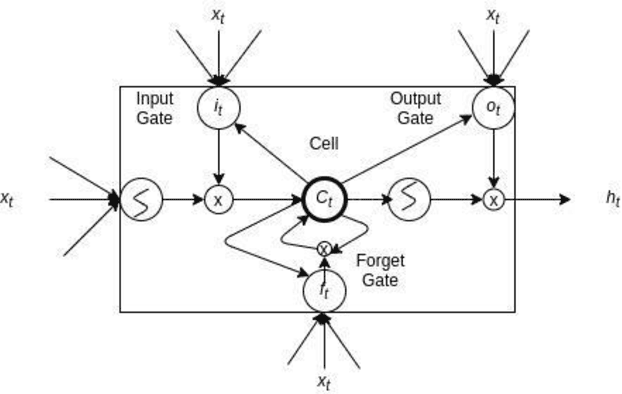
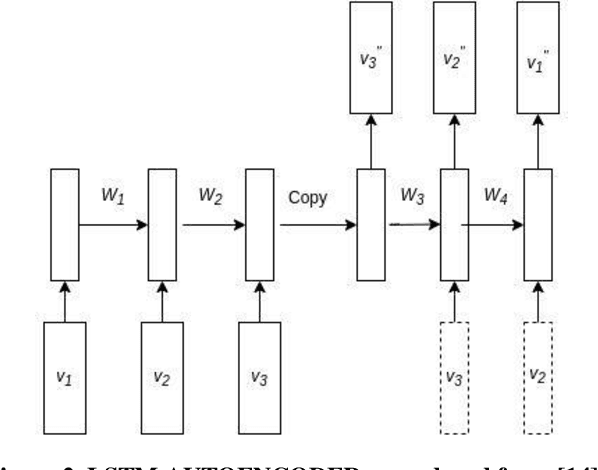
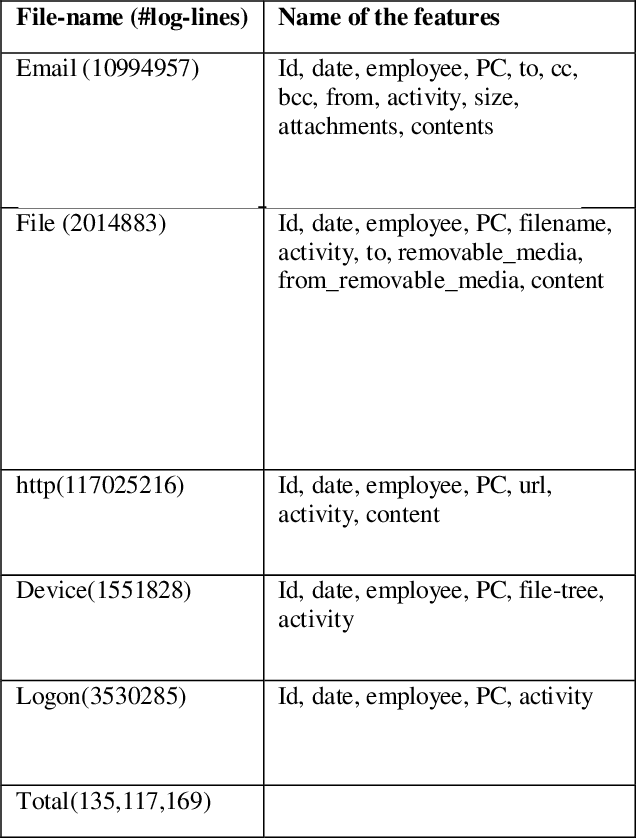
The employees of any organization, institute, or industry, spend a significant amount of time on a computer network, where they develop their own routine of activities in the form of network transactions over a time period. Insider threat detection involves identifying deviations in the routines or anomalies which may cause harm to the organization in the form of data leaks and secrets sharing. If not automated, this process involves feature engineering for modeling human behavior which is a tedious and time-consuming task. Anomalies in human behavior are forwarded to a human analyst for final threat classification. We developed an unsupervised deep neural network model using LSTM AUTOENCODER which learns to mimic the behavior of individual employees from their day-wise time-stamped sequence of activities. It predicts the threat scenario via significant loss from anomalous routine. Employees in a community tend to align their routine with each other rather than the employees outside their communities, this motivates us to explore a variation of the AUTOENCODER, LSTM AUTOENCODER- trained on the interleaved sequences of activities in the Community (LAC). We evaluate the model on the CERT v6.2 dataset and perform analysis on the loss for normal and anomalous routine across 4000 employees. The aim of our paper is to detect the anomalous employees as well as to explore how the surrounding employees are affecting that employees' routine over time.
Unsupervised Multi-Index Semantic Hashing
Mar 26, 2021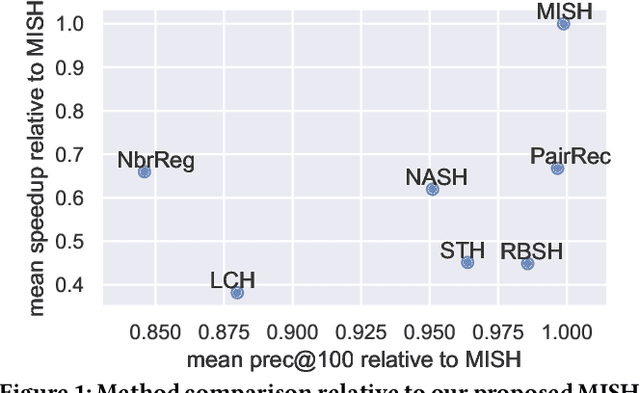

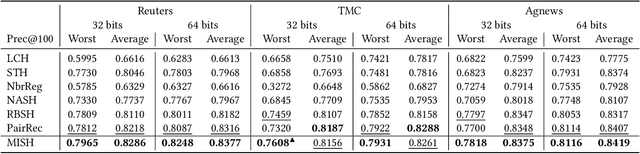
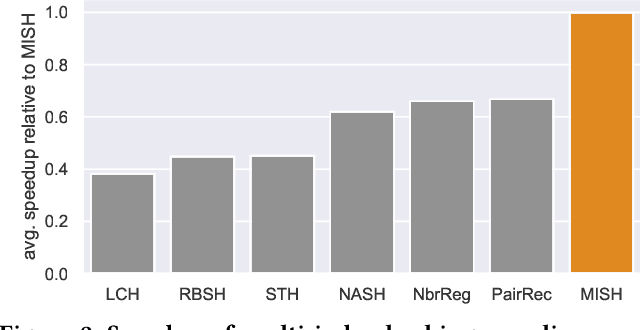
Semantic hashing represents documents as compact binary vectors (hash codes) and allows both efficient and effective similarity search in large-scale information retrieval. The state of the art has primarily focused on learning hash codes that improve similarity search effectiveness, while assuming a brute-force linear scan strategy for searching over all the hash codes, even though much faster alternatives exist. One such alternative is multi-index hashing, an approach that constructs a smaller candidate set to search over, which depending on the distribution of the hash codes can lead to sub-linear search time. In this work, we propose Multi-Index Semantic Hashing (MISH), an unsupervised hashing model that learns hash codes that are both effective and highly efficient by being optimized for multi-index hashing. We derive novel training objectives, which enable to learn hash codes that reduce the candidate sets produced by multi-index hashing, while being end-to-end trainable. In fact, our proposed training objectives are model agnostic, i.e., not tied to how the hash codes are generated specifically in MISH, and are straight-forward to include in existing and future semantic hashing models. We experimentally compare MISH to state-of-the-art semantic hashing baselines in the task of document similarity search. We find that even though multi-index hashing also improves the efficiency of the baselines compared to a linear scan, they are still upwards of 33% slower than MISH, while MISH is still able to obtain state-of-the-art effectiveness.