 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Image Compression with Encoder-Decoder Matched Semantic Segmentation
Jan 30, 2021
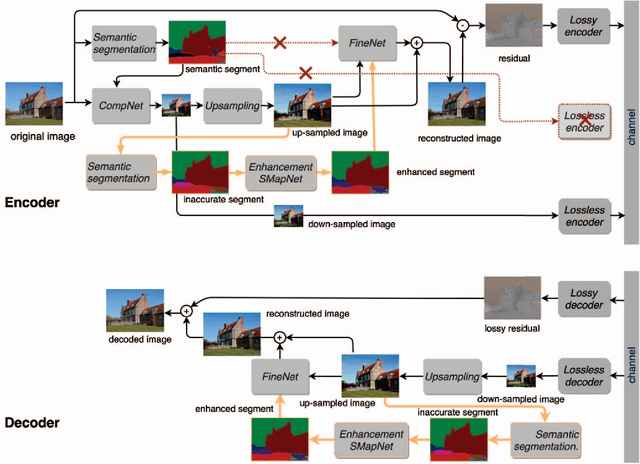

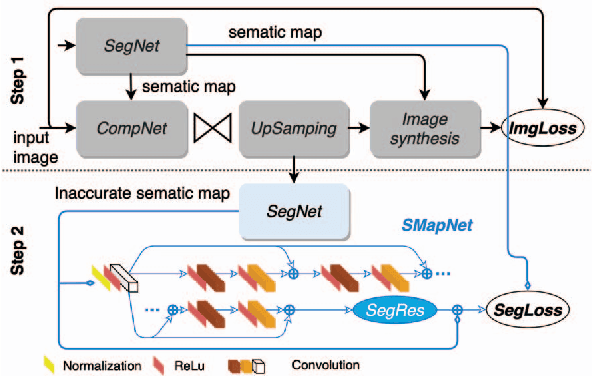
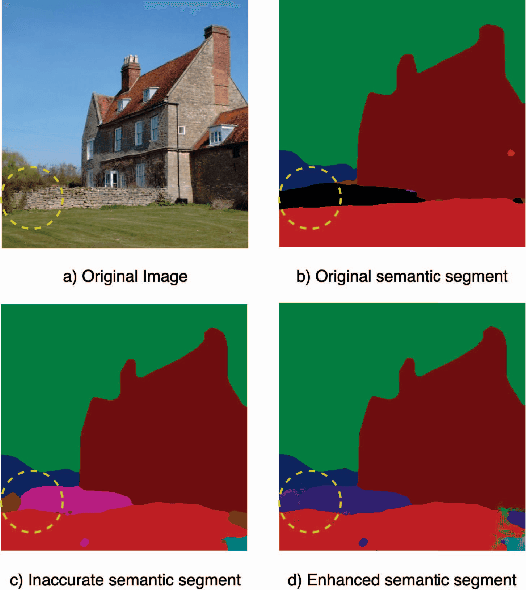
In recent years, layered image compression is demonstrated to be a promising direction, which encodes a compact representation of the input image and apply an up-sampling network to reconstruct the image. To further improve the quality of the reconstructed image, some works transmit the semantic segment together with the compressed image data. Consequently, the compression ratio is also decreased because extra bits are required for transmitting the semantic segment. To solve this problem, we propose a new layered image compression framework with encoder-decoder matched semantic segmentation (EDMS). And then, followed by the semantic segmentation, a special convolution neural network is used to enhance the inaccurate semantic segment. As a result, the accurate semantic segment can be obtained in the decoder without requiring extra bits. The experimental results show that the proposed EDMS framework can get up to 35.31% BD-rate reduction over the HEVC-based (BPG) codec, 5% bitrate, and 24% encoding time saving compare to the state-of-the-art semantic-based image codec.
Training Aware Sigmoidal Optimizer
Feb 17, 2021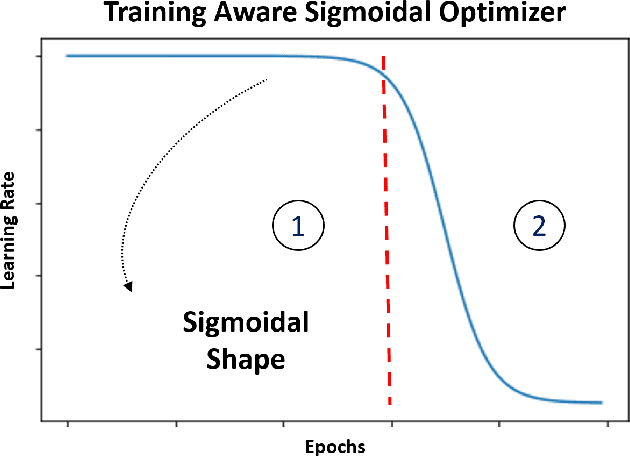

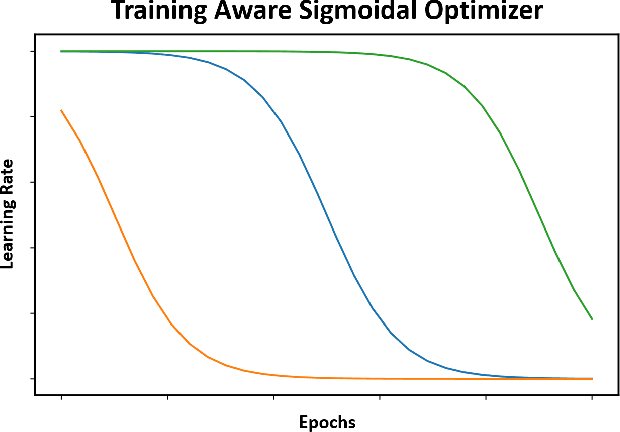
Proper optimization of deep neural networks is an open research question since an optimal procedure to change the learning rate throughout training is still unknown. Manually defining a learning rate schedule involves troublesome time-consuming try and error procedures to determine hyperparameters such as learning rate decay epochs and learning rate decay rates. Although adaptive learning rate optimizers automatize this process, recent studies suggest they may produce overffiting and reduce performance when compared to fine-tuned learning rate schedules. Considering that deep neural networks loss functions present landscapes with much more saddle points than local minima, we proposed the Training Aware Sigmoidal Optimizer (TASO), which consists of a two-phases automated learning rate schedule. The first phase uses a high learning rate to fast traverse the numerous saddle point, while the second phase uses low learning rate to slowly approach the center of the local minimum previously found. We compared the proposed approach with commonly used adaptive learning rate schedules such as Adam, RMSProp, and Adagrad. Our experiments showed that TASO outperformed all competing methods in both optimal (i.e., performing hyperparameter validation) and suboptimal (i.e., using default hyperparameters) scenarios.
Performance Dependency of LSTM and NAR Beamformers With Respect to Sensor Array Properties in V2I Scenario
Feb 17, 2021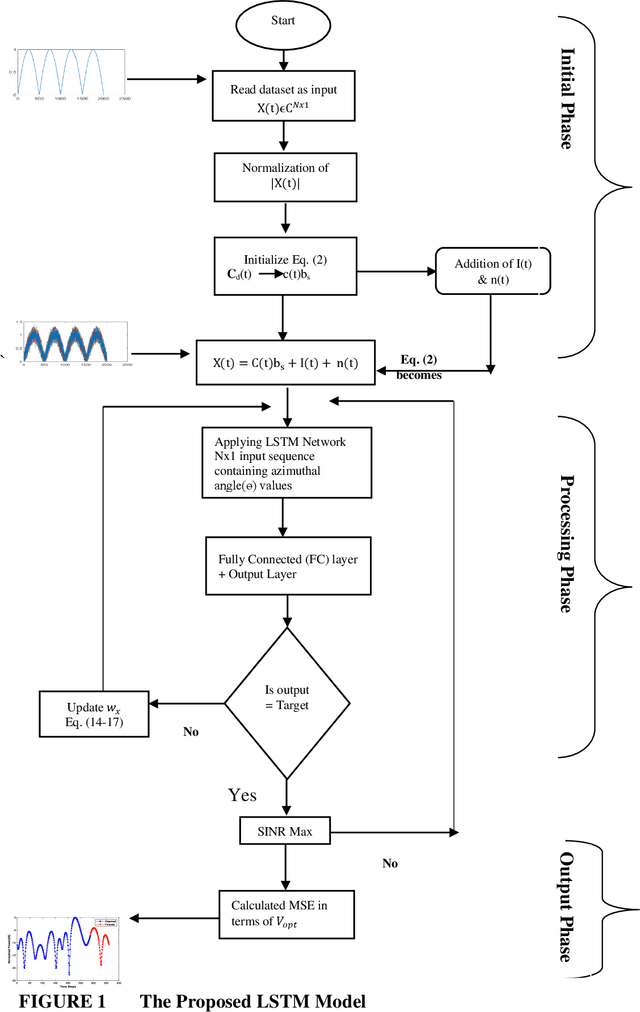
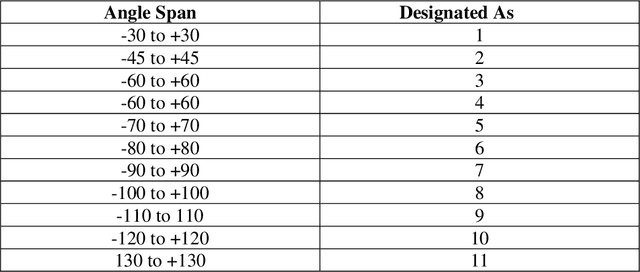
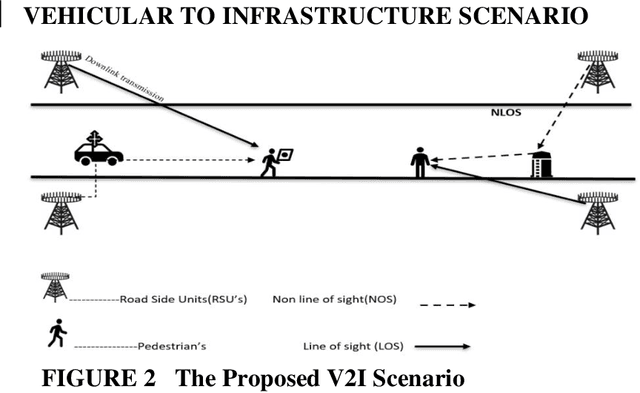
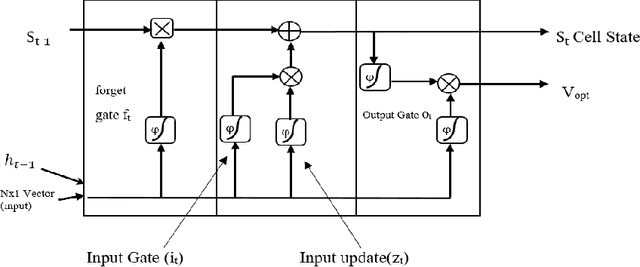
Prediction and nullifying the interference is a challenging problem in vehicle to infrastructure scenarios . The implementation of practical V2I network is limited because of inevitability of interference due to random nature of the wireless channel. The interference introduces angle ambiguity between the road side units mounted base station and user equipment. This paper proposes an adaptive beamforming technique for mitigation of interference in V2I networks, especially in multiuser environment. In this work , Long short term based (LSTM) based deep learning and non linear auto regresive technique based regressor have been employed to predict the angles between the road side units and user equipment .Advance prediction of transmit and receive signals enables reliable vehicle to infrastructure communication. Instead of predicting the beamforming matrix directly, we predict the main features using LSTM for learning dependencies in the input time series ,where complex variables were taken as input states and final beamformed signal was the output. simulation results have confirmed that the proposed LSTM model achieves comparable performance in terms of system throughput when compared with the non linear auto regressive method implemented as an artificial neural network.
Continuous Coordination As a Realistic Scenario for Lifelong Learning
Mar 04, 2021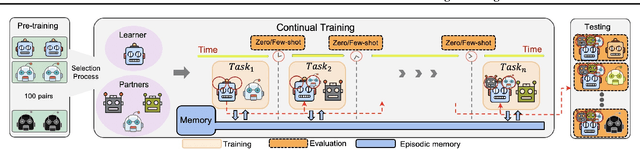
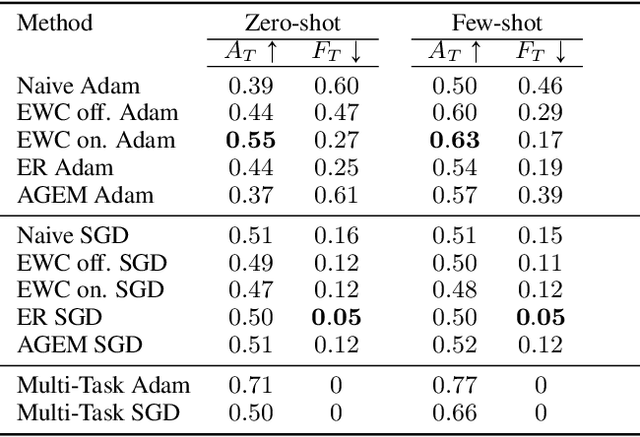
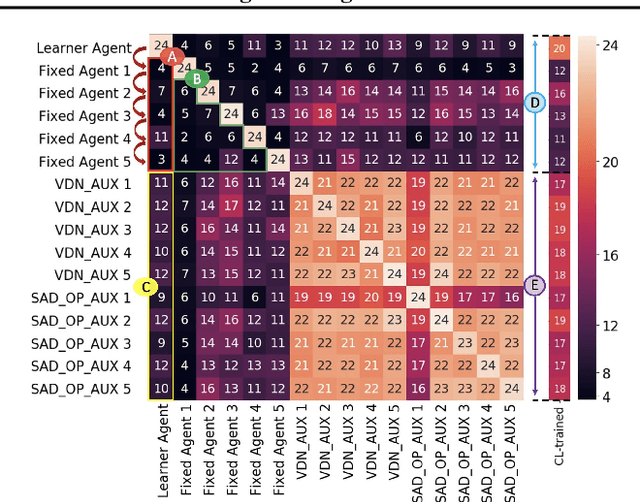

Current deep reinforcement learning (RL) algorithms are still highly task-specific and lack the ability to generalize to new environments. Lifelong learning (LLL), however, aims at solving multiple tasks sequentially by efficiently transferring and using knowledge between tasks. Despite a surge of interest in lifelong RL in recent years, the lack of a realistic testbed makes robust evaluation of LLL algorithms difficult. Multi-agent RL (MARL), on the other hand, can be seen as a natural scenario for lifelong RL due to its inherent non-stationarity, since the agents' policies change over time. In this work, we introduce a multi-agent lifelong learning testbed that supports both zero-shot and few-shot settings. Our setup is based on Hanabi -- a partially-observable, fully cooperative multi-agent game that has been shown to be challenging for zero-shot coordination. Its large strategy space makes it a desirable environment for lifelong RL tasks. We evaluate several recent MARL methods, and benchmark state-of-the-art LLL algorithms in limited memory and computation regimes to shed light on their strengths and weaknesses. This continual learning paradigm also provides us with a pragmatic way of going beyond centralized training which is the most commonly used training protocol in MARL. We empirically show that the agents trained in our setup are able to coordinate well with unseen agents, without any additional assumptions made by previous works.
AttDMM: An Attentive Deep Markov Model for Risk Scoring in Intensive Care Units
Feb 17, 2021



Clinical practice in intensive care units (ICUs) requires early warnings when a patient's condition is about to deteriorate so that preventive measures can be undertaken. To this end, prediction algorithms have been developed that estimate the risk of mortality in ICUs. In this work, we propose a novel generative deep probabilistic model for real-time risk scoring in ICUs. Specifically, we develop an attentive deep Markov model called AttDMM. To the best of our knowledge, AttDMM is the first ICU prediction model that jointly learns both long-term disease dynamics (via attention) and different disease states in health trajectory (via a latent variable model). Our evaluations were based on an established baseline dataset (MIMIC-III) with 53,423 ICU stays. The results confirm that compared to state-of-the-art baselines, our AttDMM was superior: AttDMM achieved an area under the receiver operating characteristic curve (AUROC) of 0.876, which yielded an improvement over the state-of-the-art method by 2.2%. In addition, the risk score from the AttDMM provided warnings several hours earlier. Thereby, our model shows a path towards identifying patients at risk so that health practitioners can intervene early and save patient lives.
Enabling Binary Neural Network Training on the Edge
Feb 08, 2021
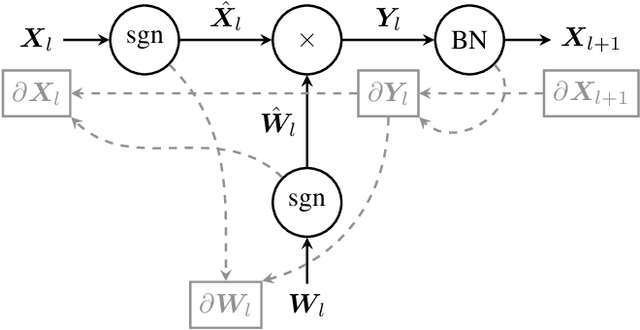
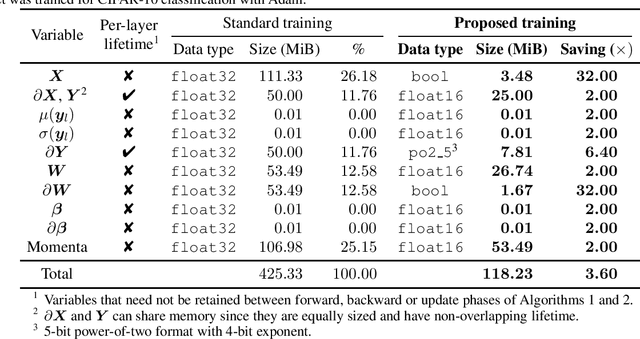
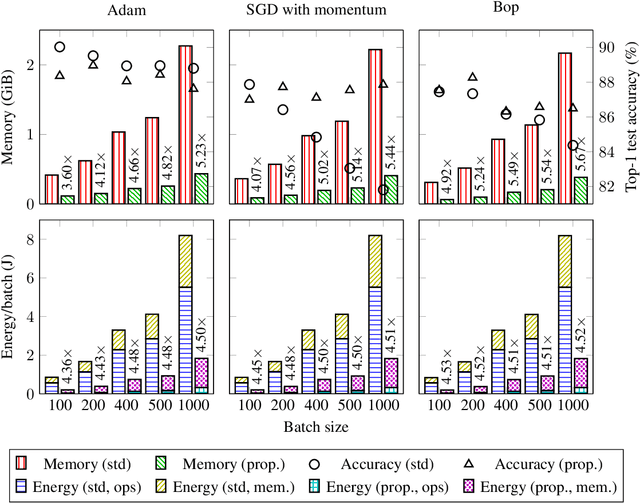
The ever-growing computational demands of increasingly complex machine learning models frequently necessitate the use of powerful cloud-based infrastructure for their training. Binary neural networks are known to be promising candidates for on-device inference due to their extreme compute and memory savings over higher-precision alternatives. In this paper, we demonstrate that they are also strongly robust to gradient quantization, thereby making the training of modern models on the edge a practical reality. We introduce a low-cost binary neural network training strategy exhibiting sizable memory footprint reductions and energy savings vs Courbariaux & Bengio's standard approach. Against the latter, we see coincident memory requirement and energy consumption drops of 2--6$\times$, while reaching similar test accuracy in comparable time, across a range of small-scale models trained to classify popular datasets. We also showcase ImageNet training of ResNetE-18, achieving a 3.12$\times$ memory reduction over the aforementioned standard. Such savings will allow for unnecessary cloud offloading to be avoided, reducing latency, increasing energy efficiency and safeguarding privacy.
Real Time Lidar and Radar High-Level Fusion for Obstacle Detection and Tracking with evaluation on a ground truth
Jul 30, 2018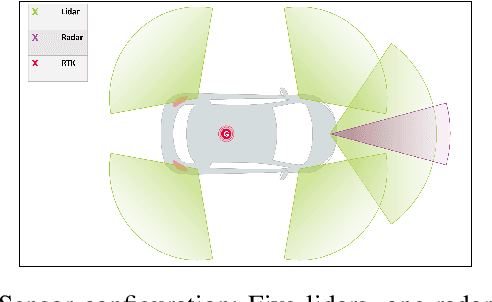
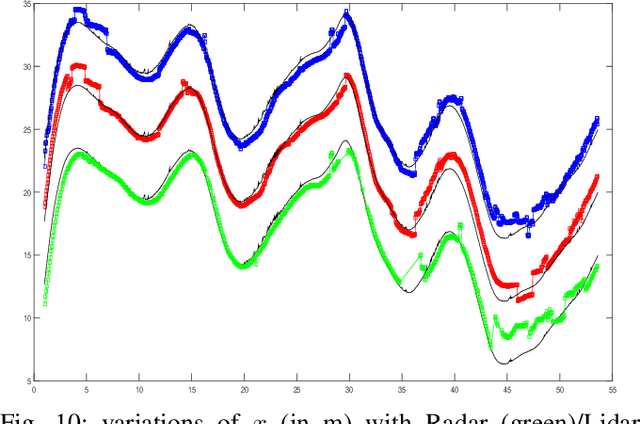
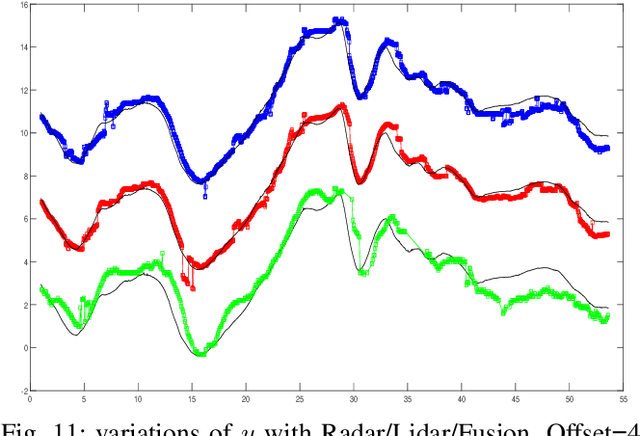
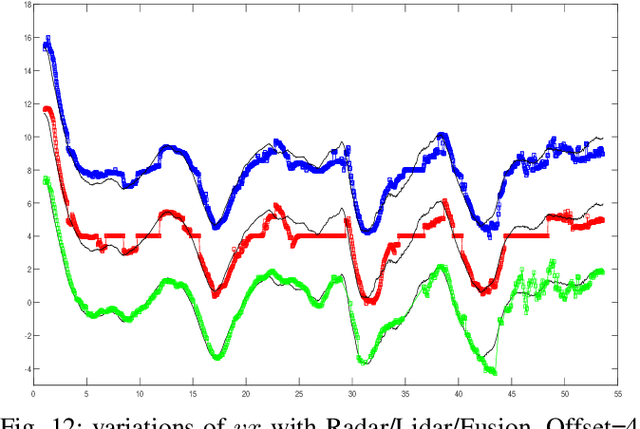
- Both Lidars and Radars are sensors for obstacle detection. While Lidars are very accurate on obstacles positions and less accurate on their velocities, Radars are more precise on obstacles velocities and less precise on their positions. Sensor fusion between Lidar and Radar aims at improving obstacle detection using advantages of the two sensors. The present paper proposes a real-time Lidar/Radar data fusion algorithm for obstacle detection and tracking based on the global nearest neighbour standard filter (GNN). This algorithm is implemented and embedded in an automative vehicle as a component generated by a real-time multisensor software. The benefits of data fusion comparing with the use of a single sensor are illustrated through several tracking scenarios (on a highway and on a bend) and using real-time kinematic sensors mounted on the ego and tracked vehicles as a ground truth.
Depth-based pseudo-metrics between probability distributions
Mar 23, 2021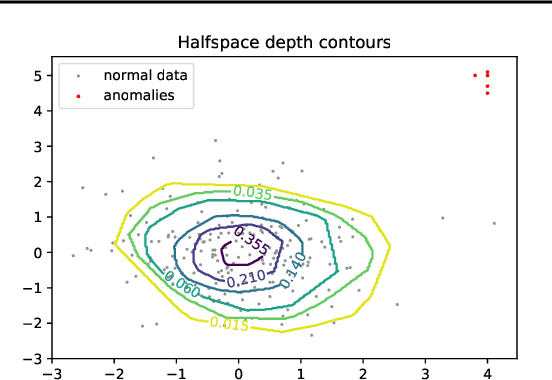
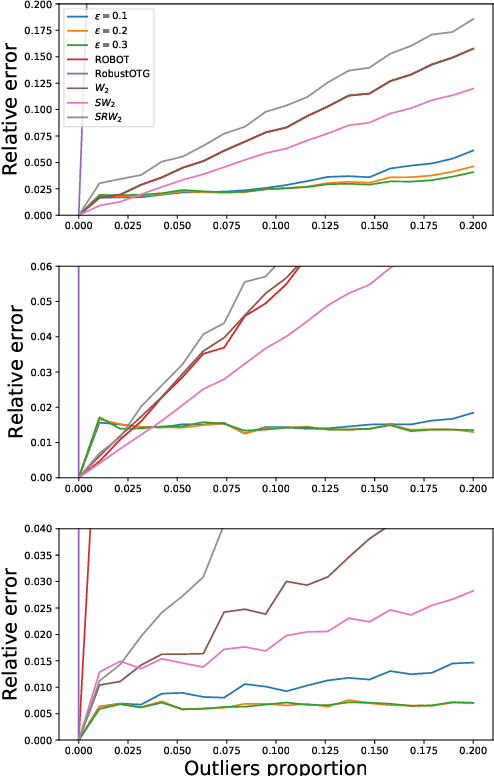
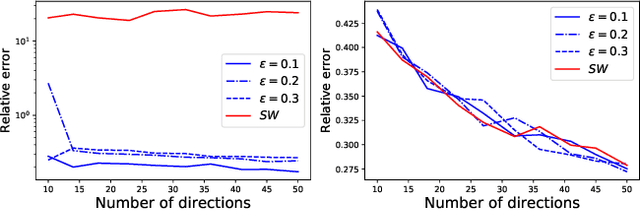
Data depth is a non parametric statistical tool that measures centrality of any element $x\in\mathbb{R}^d$ with respect to (w.r.t.) a probability distribution or a data set. It is a natural median-oriented extension of the cumulative distribution function (cdf) to the multivariate case. Consequently, its upper level sets -- the depth-trimmed regions -- give rise to a definition of multivariate quantiles. In this work, we propose two new pseudo-metrics between continuous probability measures based on data depth and its associated central regions. The first one is constructed as the Lp-distance between data depth w.r.t. each distribution while the second one relies on the Hausdorff distance between their quantile regions. It can further be seen as an original way to extend the one-dimensional formulae of the Wasserstein distance, which involves quantiles and cdfs, to the multivariate space. After discussing the properties of these pseudo-metrics and providing conditions under which they define a distance, we highlight similarities with the Wasserstein distance. Interestingly, the derived non-asymptotic bounds show that in contrast to the Wasserstein distance, the proposed pseudo-metrics do not suffer from the curse of dimensionality. Moreover, based on the support function of a convex body, we propose an efficient approximation possessing linear time complexity w.r.t. the size of the data set and its dimension. The quality of this approximation as well as the performance of the proposed approach are illustrated in experiments. Furthermore, by construction the regions-based pseudo-metric appears to be robust w.r.t. both outliers and heavy tails, a behavior witnessed in the numerical experiments.
Automatic detection of abnormal EEG signals using wavelet feature extraction and gradient boosting decision tree
Dec 18, 2020

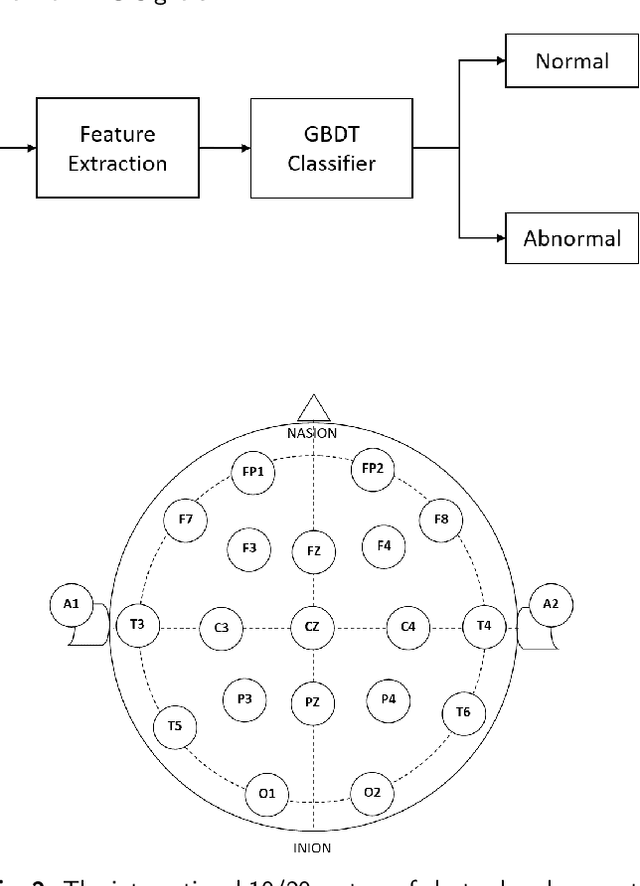
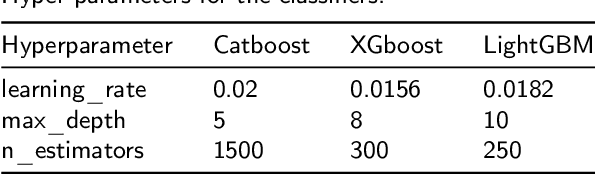
Electroencephalography is frequently used for diagnostic evaluation of various brain-related disorders due to its excellent resolution, non-invasive nature and low cost. However, manual analysis of EEG signals could be strenuous and a time-consuming process for experts. It requires long training time for physicians to develop expertise in it and additionally experts have low inter-rater agreement (IRA) among themselves. Therefore, many Computer Aided Diagnostic (CAD) based studies have considered the automation of interpreting EEG signals to alleviate the workload and support the final diagnosis. In this paper, we present an automatic binary classification framework for brain signals in multichannel EEG recordings. We propose to use Wavelet Packet Decomposition (WPD) techniques to decompose the EEG signals into frequency sub-bands and extract a set of statistical features from each of the selected coefficients. Moreover, we propose a novel method to reduce the dimension of the feature space without compromising the quality of the extracted features. The extracted features are classified using different Gradient Boosting Decision Tree (GBDT) based classification frameworks, which are CatBoost, XGBoost and LightGBM. We used Temple University Hospital EEG Abnormal Corpus V2.0.0 to test our proposed technique. We found that CatBoost classifier achieves the binary classification accuracy of 87.68%, and outperforms state-of-the-art techniques on the same dataset by more than 1% in accuracy and more than 3% in sensitivity. The obtained results in this research provide important insights into the usefulness of WPD feature extraction and GBDT classifiers for EEG classification.
Centroid Transformers: Learning to Abstract with Attention
Feb 17, 2021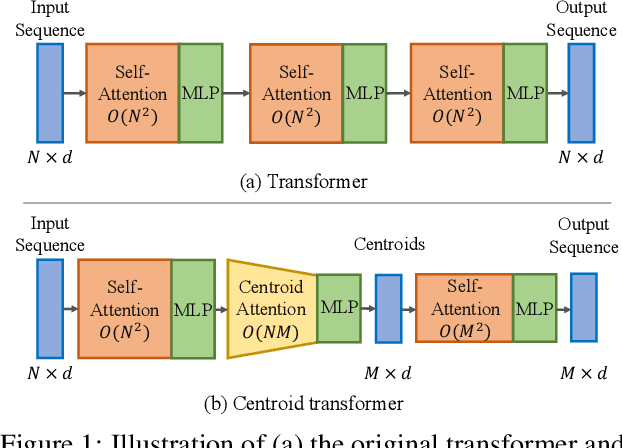

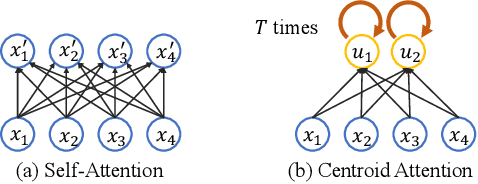
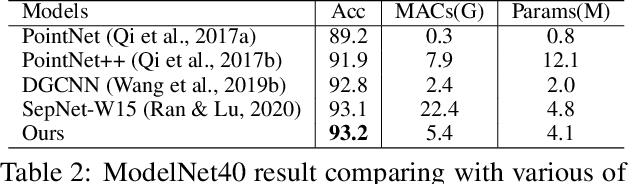
Self-attention, as the key block of transformers, is a powerful mechanism for extracting features from the inputs. In essence, what self-attention does to infer the pairwise relations between the elements of the inputs, and modify the inputs by propagating information between input pairs. As a result, it maps inputs to N outputs and casts a quadratic $O(N^2)$ memory and time complexity. We propose centroid attention, a generalization of self-attention that maps N inputs to M outputs $(M\leq N)$, such that the key information in the inputs are summarized in the smaller number of outputs (called centroids). We design centroid attention by amortizing the gradient descent update rule of a clustering objective function on the inputs, which reveals an underlying connection between attention and clustering. By compressing the inputs to the centroids, we extract the key information useful for prediction and also reduce the computation of the attention module and the subsequent layers. We apply our method to various applications, including abstractive text summarization, 3D vision, and image processing. Empirical results demonstrate the effectiveness of our method over the standard transformers.