 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Non-invasive Self-attention for Side Information Fusion in Sequential Recommendation
Mar 05, 2021
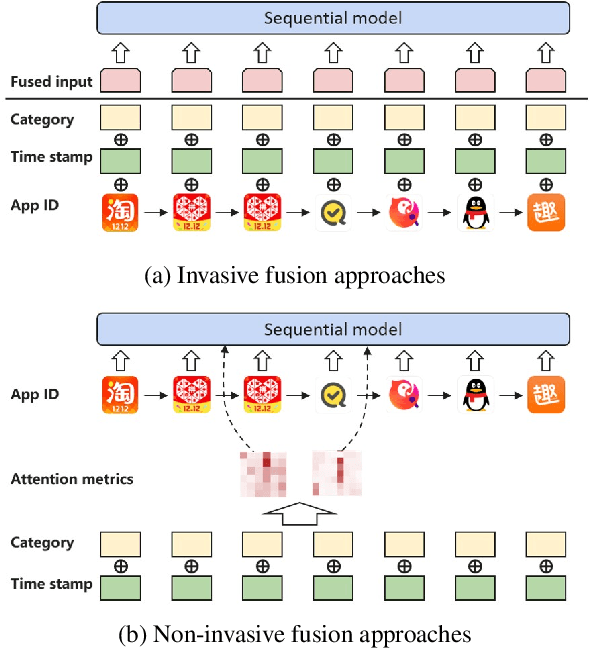

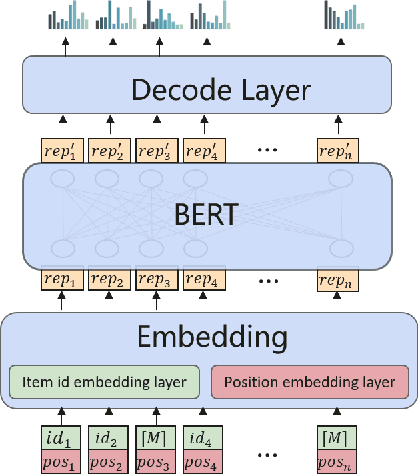

Sequential recommender systems aim to model users' evolving interests from their historical behaviors, and hence make customized time-relevant recommendations. Compared with traditional models, deep learning approaches such as CNN and RNN have achieved remarkable advancements in recommendation tasks. Recently, the BERT framework also emerges as a promising method, benefited from its self-attention mechanism in processing sequential data. However, one limitation of the original BERT framework is that it only considers one input source of the natural language tokens. It is still an open question to leverage various types of information under the BERT framework. Nonetheless, it is intuitively appealing to utilize other side information, such as item category or tag, for more comprehensive depictions and better recommendations. In our pilot experiments, we found naive approaches, which directly fuse types of side information into the item embeddings, usually bring very little or even negative effects. Therefore, in this paper, we propose the NOninVasive self-attention mechanism (NOVA) to leverage side information effectively under the BERT framework. NOVA makes use of side information to generate better attention distribution, rather than directly altering the item embedding, which may cause information overwhelming. We validate the NOVA-BERT model on both public and commercial datasets, and our method can stably outperform the state-of-the-art models with negligible computational overheads.
A Weakly Supervised Approach for Classifying Stance in Twitter Replies
Mar 12, 2021
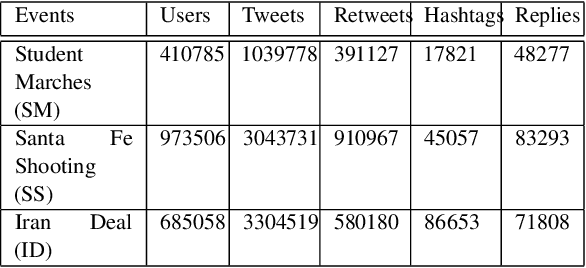
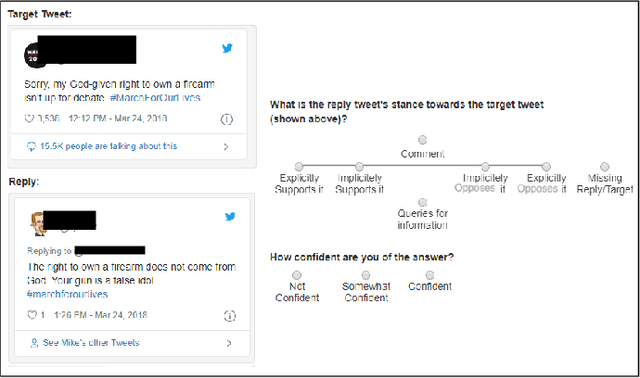
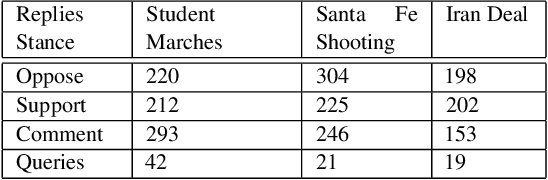
Conversations on social media (SM) are increasingly being used to investigate social issues on the web, such as online harassment and rumor spread. For such issues, a common thread of research uses adversarial reactions, e.g., replies pointing out factual inaccuracies in rumors. Though adversarial reactions are prevalent in online conversations, inferring those adverse views (or stance) from the text in replies is difficult and requires complex natural language processing (NLP) models. Moreover, conventional NLP models for stance mining need labeled data for supervised learning. Getting labeled conversations can itself be challenging as conversations can be on any topic, and topics change over time. These challenges make learning the stance a difficult NLP problem. In this research, we first create a new stance dataset comprised of three different topics by labeling both users' opinions on the topics (as in pro/con) and users' stance while replying to others' posts (as in favor/oppose). As we find limitations with supervised approaches, we propose a weakly-supervised approach to predict the stance in Twitter replies. Our novel method allows using a smaller number of hashtags to generate weak labels for Twitter replies. Compared to supervised learning, our method improves the mean F1-macro by 8\% on the hand-labeled dataset without using any hand-labeled examples in the training set. We further show the applicability of our proposed method on COVID 19 related conversations on Twitter.
Predicting Human Decision Making in Psychological Tasks with Recurrent Neural Networks
Oct 22, 2020
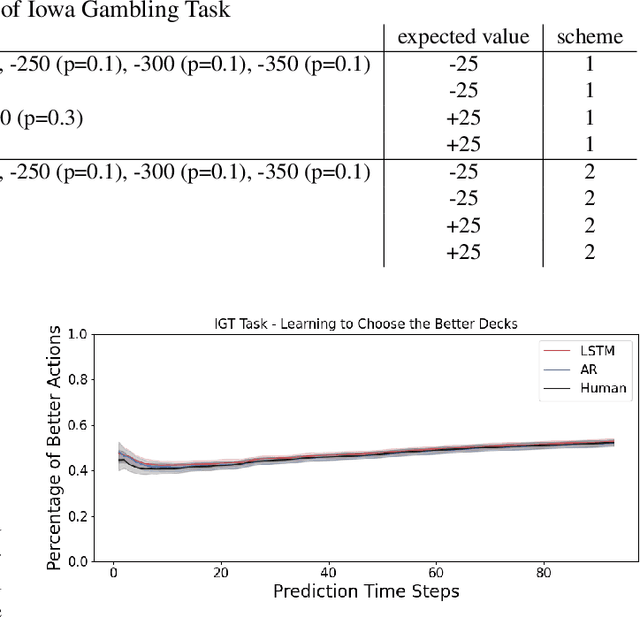
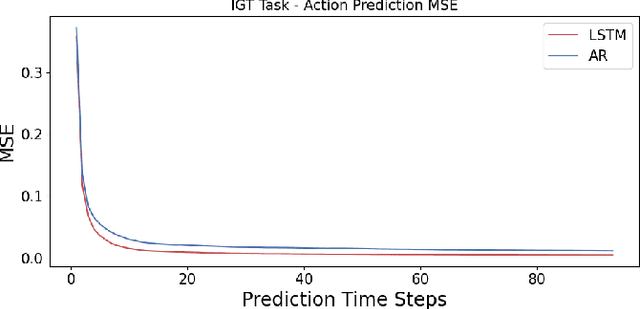
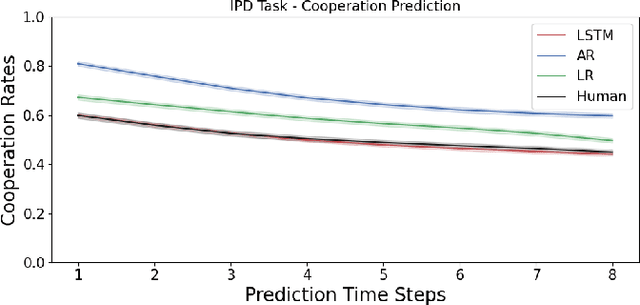
Unlike traditional time series, the action sequences of human decision making usually involve many cognitive processes such as beliefs, desires, intentions and theory of mind, i.e. what others are thinking. This makes predicting human decision making challenging to be treated agnostically to the underlying psychological mechanisms. We propose to use a recurrent neural network architecture based on long short-term memory networks (LSTM) to predict the time series of the actions taken by the human subjects at each step of their decision making, the first application of such methods in this research domain. We trained our prediction networks on the behavioral data from several published psychological experiments of human decision making, and demonstrated a clear advantage over the state-of-the-art methods in predicting human decision making trajectories in both single-agent scenarios such as Iowa Gambling Task and multi-agent scenarios such as Iterated Prisoner's Dilemma.
Deep Neural Network Approach for Annual Luminance Simulations
Sep 14, 2020Annual luminance maps provide meaningful evaluations for occupants' visual comfort, preferences, and perception. However, acquiring long-term luminance maps require labor-intensive and time-consuming simulations or impracticable long-term field measurements. This paper presents a novel data-driven machine learning approach that makes annual luminance-based evaluations more efficient and accessible. The methodology is based on predicting the annual luminance maps from a limited number of point-in-time high dynamic range imagery by utilizing a deep neural network (DNN). Panoramic views are utilized, as they can be post-processed to study multiple view directions. The proposed DNN model can faithfully predict high-quality annual panoramic luminance maps from one of the three options within 30 minutes training time: a) point-in-time luminance imagery spanning 5% of the year, when evenly distributed during daylight hours, b) one-month hourly imagery generated or collected continuously during daylight hours around the equinoxes (8% of the year); or c) 9 days of hourly data collected around the spring equinox, summer and winter solstices (2.5% of the year) all suffice to predict the luminance maps for the rest of the year. The DNN predicted high-quality panoramas are validated against Radiance (RPICT) renderings using a series of quantitative and qualitative metrics. The most efficient predictions are achieved with 9 days of hourly data collected around the spring equinox, summer and winter solstices. The results clearly show that practitioners and researchers can efficiently incorporate long-term luminance-based metrics over multiple view directions into the design and research processes using the proposed DNN workflow.
Coordination via predictive assistants: time series algorithms and game-theoretic analysis
Oct 05, 2018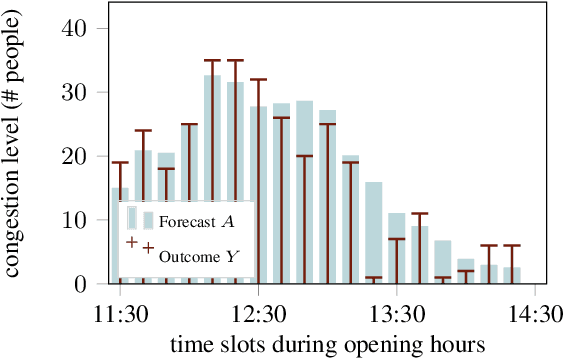
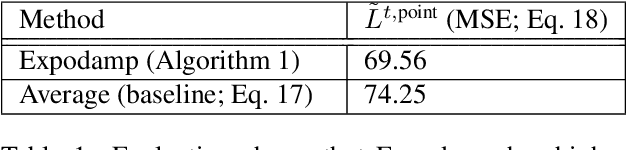
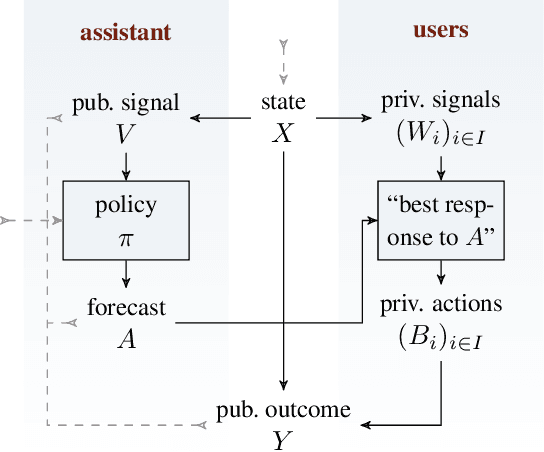
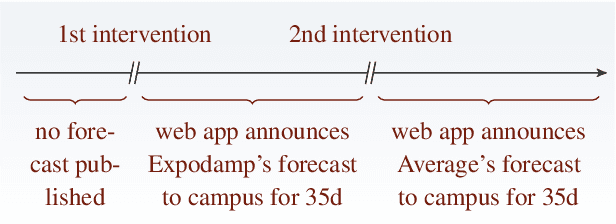
We study data-driven assistants that provide congestion forecasts to users of crowded facilities (roads, cafeterias, etc.), to support coordination between them. Having multiple agents and feedback loops from predictions to outcomes, new problems arise in terms of choosing (1) objective and (2) algorithms for such assistants. Addressing (1), we pick classical prediction accuracy as objective and establish general conditions under which optimizing it is equivalent to "solving" the coordination problem in an idealized game-theoretic sense -- selecting a certain Bayesian Nash equilibrium (BNE). Then we prove the existence of an assistant-based "solution" even for large-scale (nonatomic), aggregated settings. This entails a new BNE existence result. Addressing (2), we propose an exponential smoothing-based algorithm on time series data. We prove its optimality w.r.t.\ the prediction objective under a state-space model for the large-scale setting. We also provide a proof-of-concept algorithm and convergence guarantees for a small-scale, non-aggregated setting. We validate our algorithm in a large-scale experiment in a real cafeteria.
A robust low data solution: dimension prediction of semiconductor nanorods
Oct 27, 2020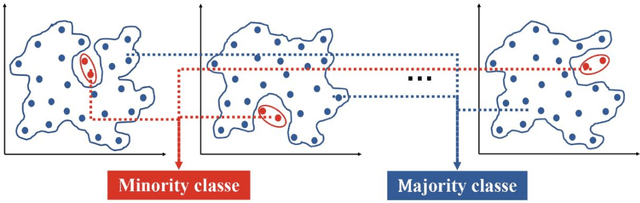
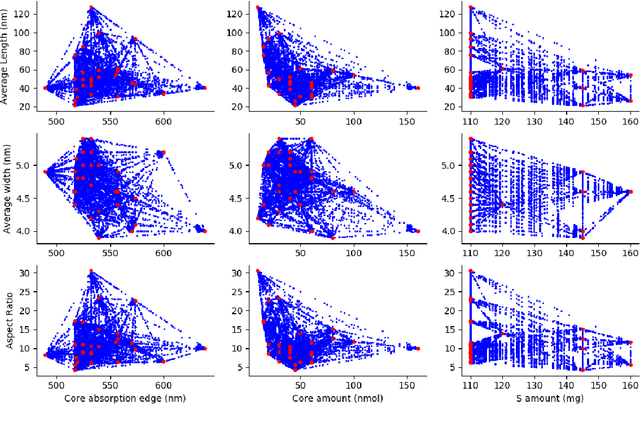
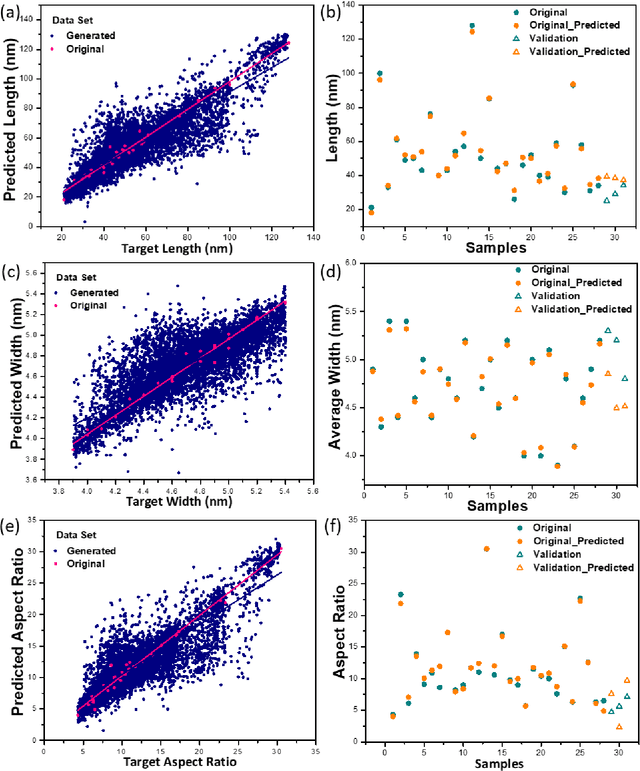
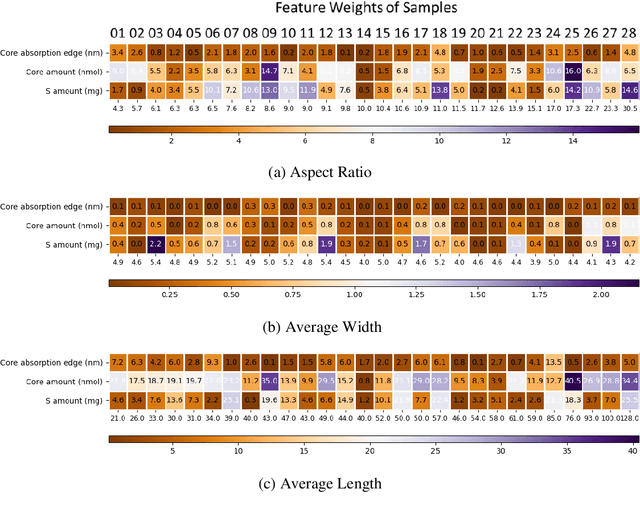
Precise control over dimension of nanocrystals is critical to tune the properties for various applications. However, the traditional control through experimental optimization is slow, tedious and time consuming. Herein a robust deep neural network-based regression algorithm has been developed for precise prediction of length, width, and aspect ratios of semiconductor nanorods (NRs). Given there is limited experimental data available (28 samples), a Synthetic Minority Oversampling Technique for regression (SMOTE-REG) has been employed for the first time for data generation. Deep neural network is further applied to develop regression model which demonstrated the well performed prediction on both the original and generated data with a similar distribution. The prediction model is further validated with additional experimental data, showing accurate prediction results. Additionally, Local Interpretable Model-Agnostic Explanations (LIME) is used to interpret the weight for each variable, which corresponds to its importance towards the target dimension, which is approved to be well correlated well with experimental observations.
Ultra-Fast, Low-Storage, Highly Effective Coarse-grained Selection in Retrieval-based Chatbot by Using Deep Semantic Hashing
Dec 18, 2020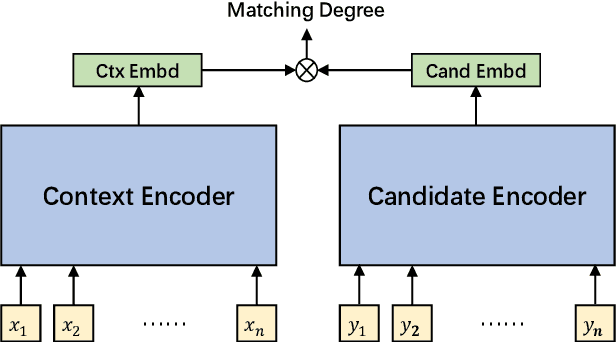
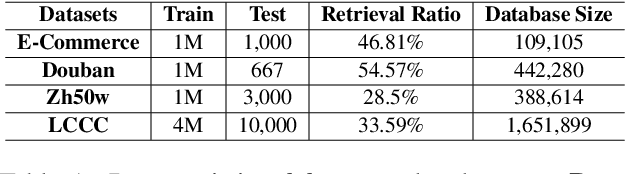
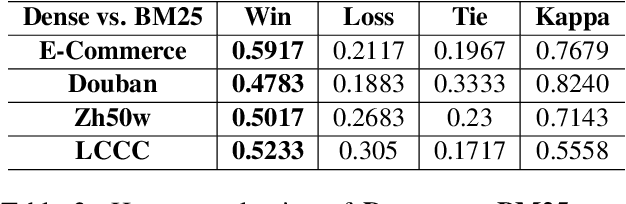
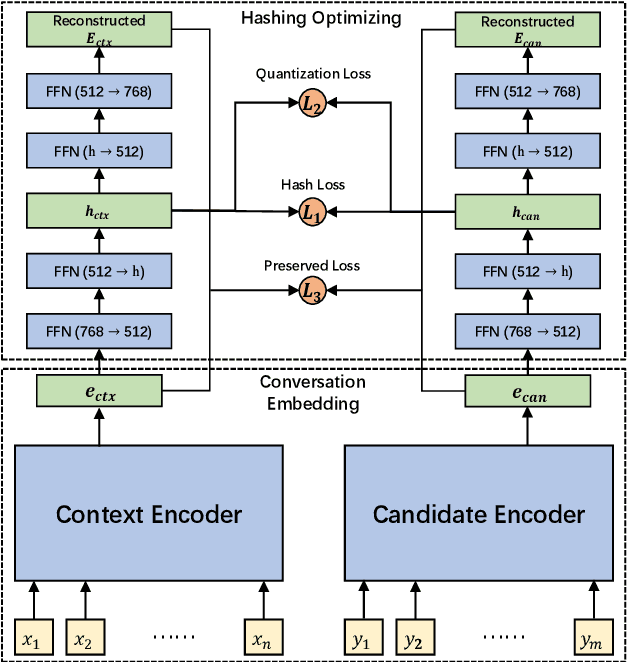
We study the coarse-grained selection module in retrieval-based chatbot. Coarse-grained selection is a basic module in a retrieval-based chatbot, which constructs a rough candidate set from the whole database to speed up the interaction with customers. So far, there are two kinds of approaches for coarse-grained selection module: (1) sparse representation; (2) dense representation. To the best of our knowledge, there is no systematic comparison between these two approaches in retrieval-based chatbots, and which kind of method is better in real scenarios is still an open question. In this paper, we first systematically compare these two methods from four aspects: (1) effectiveness; (2) index stoarge; (3) search time cost; (4) human evaluation. Extensive experiment results demonstrate that dense representation method significantly outperforms the sparse representation, but costs more time and storage occupation. In order to overcome these fatal weaknesses of dense representation method, we propose an ultra-fast, low-storage, and highly effective Deep Semantic Hashing Coarse-grained selection method, called DSHC model. Specifically, in our proposed DSHC model, a hashing optimizing module that consists of two autoencoder models is stacked on a trained dense representation model, and three loss functions are designed to optimize it. The hash codes provided by hashing optimizing module effectively preserve the rich semantic and similarity information in dense vectors. Extensive experiment results prove that, our proposed DSHC model can achieve much faster speed and lower storage than sparse representation, with limited performance loss compared with dense representation. Besides, our source codes have been publicly released for future research.
End-to-End Egospheric Spatial Memory
Feb 17, 2021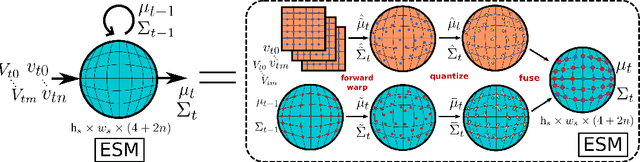
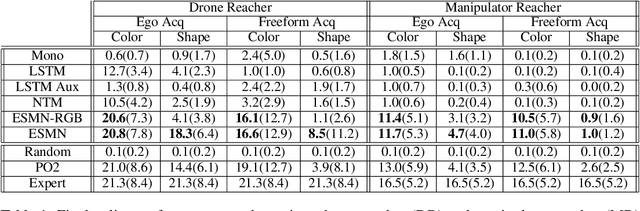
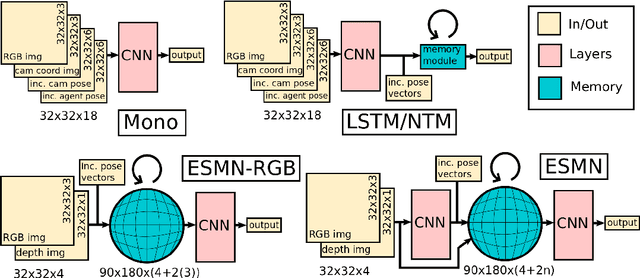
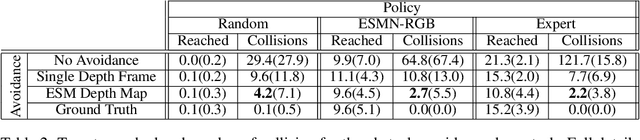
Spatial memory, or the ability to remember and recall specific locations and objects, is central to autonomous agents' ability to carry out tasks in real environments. However, most existing artificial memory modules are not very adept at storing spatial information. We propose a parameter-free module, Egospheric Spatial Memory (ESM), which encodes the memory in an ego-sphere around the agent, enabling expressive 3D representations. ESM can be trained end-to-end via either imitation or reinforcement learning, and improves both training efficiency and final performance against other memory baselines on both drone and manipulator visuomotor control tasks. The explicit egocentric geometry also enables us to seamlessly combine the learned controller with other non-learned modalities, such as local obstacle avoidance. We further show applications to semantic segmentation on the ScanNet dataset, where ESM naturally combines image-level and map-level inference modalities. Through our broad set of experiments, we show that ESM provides a general computation graph for embodied spatial reasoning, and the module forms a bridge between real-time mapping systems and differentiable memory architectures. Implementation at: https://github.com/ivy-dl/memory.
Dementia Severity Classification under Small Sample Size and Weak Supervision in Thick Slice MRI
Mar 18, 2021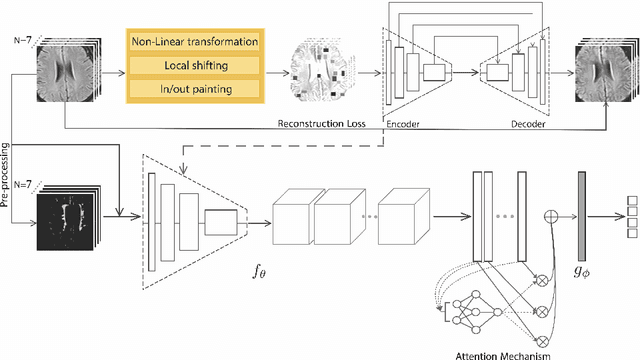
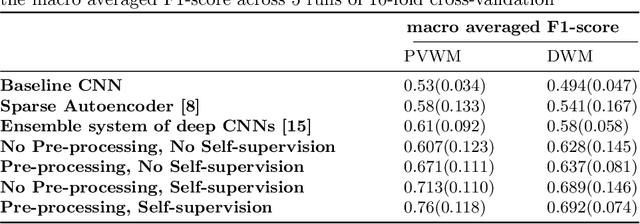
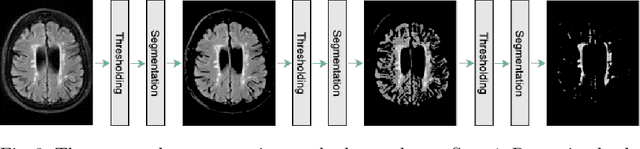
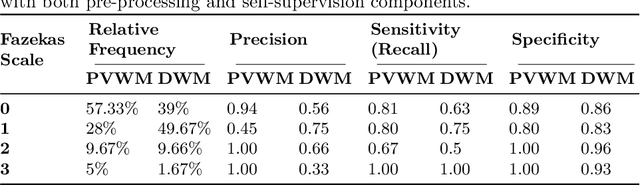
Early detection of dementia through specific biomarkers in MR images plays a critical role in developing support strategies proactively. Fazekas scale facilitates an accurate quantitative assessment of the severity of white matter lesions and hence the disease. Imaging Biomarkers of dementia are multiple and comprehensive documentation of them is time-consuming. Therefore, any effort to automatically extract these biomarkers will be of clinical value while reducing inter-rater discrepancies. To tackle this problem, we propose to classify the disease severity based on the Fazekas scale through the visual biomarkers, namely the Periventricular White Matter (PVWM) and the Deep White Matter (DWM) changes, in the real-world setting of thick-slice MRI. Small training sample size and weak supervision in form of assigning severity labels to the whole MRI stack are among the main challenges. To combat the mentioned issues, we have developed a deep learning pipeline that employs self-supervised representation learning, multiple instance learning, and appropriate pre-processing steps. We use pretext tasks such as non-linear transformation, local shuffling, in- and out-painting for self-supervised learning of useful features in this domain. Furthermore, an attention model is used to determine the relevance of each MRI slice for predicting the Fazekas scale in an unsupervised manner. We show the significant superiority of our method in distinguishing different classes of dementia compared to state-of-the-art methods in our mentioned setting, which improves the macro averaged F1-score of state-of-the-art from 61% to 76% in PVWM, and from 58% to 69.2% in DWM.
A new approach for physiological time series
Apr 23, 2015
We developed a new approach for the analysis of physiological time series. An iterative convolution filter is used to decompose the time series into various components. Statistics of these components are extracted as features to characterize the mechanisms underlying the time series. Motivated by the studies that show many normal physiological systems involve irregularity while the decrease of irregularity usually implies the abnormality, the statistics for "outliers" in the components are used as features measuring irregularity. Support vector machines are used to select the most relevant features that are able to differentiate the time series from normal and abnormal systems. This new approach is successfully used in the study of congestive heart failure by heart beat interval time series.