 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explainable Predictive Process Monitoring
Sep 16, 2020
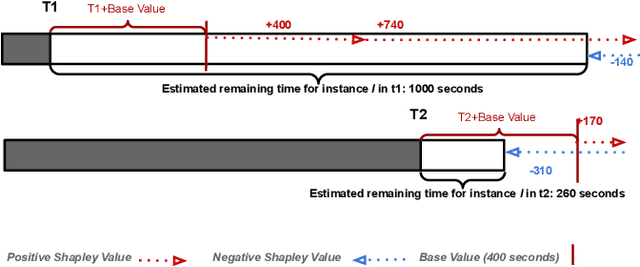
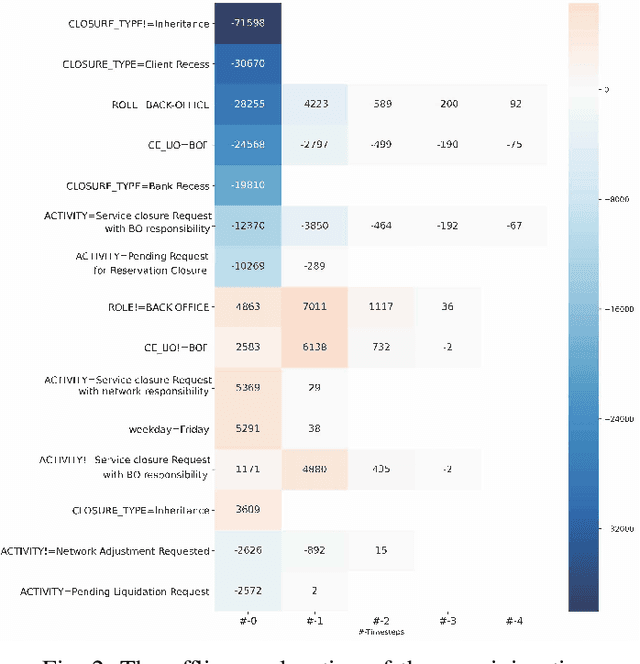
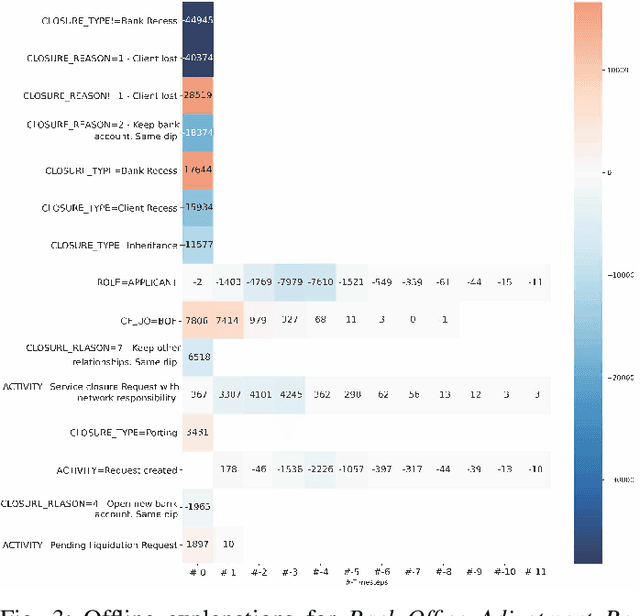
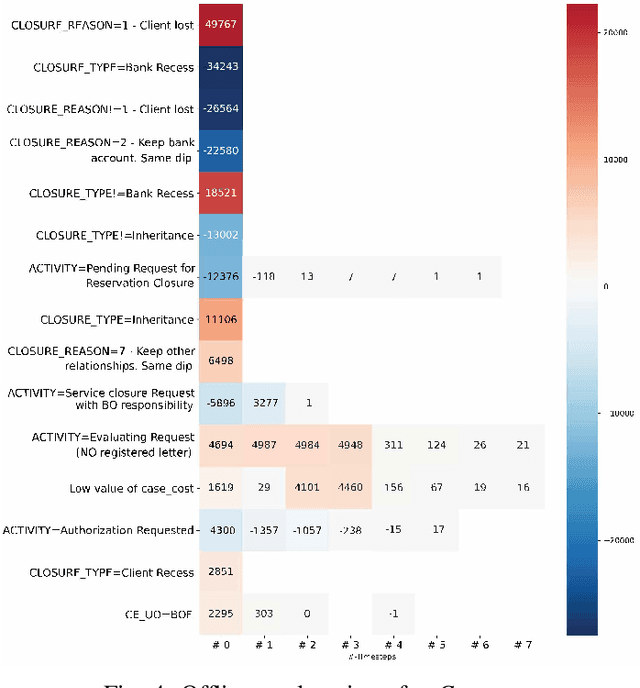
Predictive Business Process Monitoring is becoming an essential aid for organizations, providing online operational support of their processes. This paper tackles the fundamental problem of equipping predictive business process monitoring with explanation capabilities, so that not only the what but also the why is reported when predicting generic KPIs like remaining time, or activity execution. We use the game theory of Shapley Values to obtain robust explanations of the predictions. The approach has been implemented and tested on real-life benchmarks, showing for the first time how explanations can be given in the field of predictive business process monitoring.
Open-World Learning Without Labels
Nov 25, 2020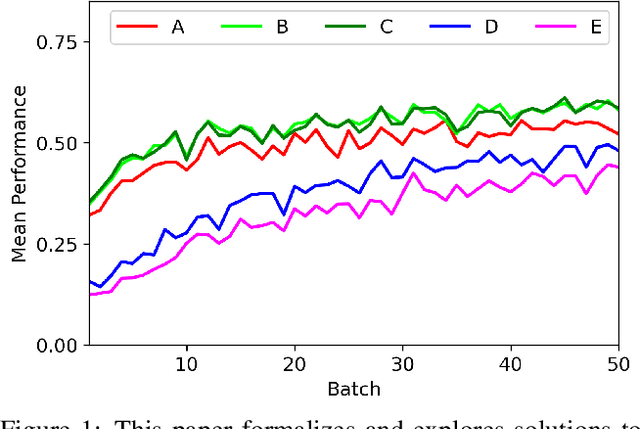

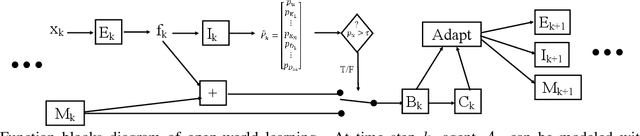
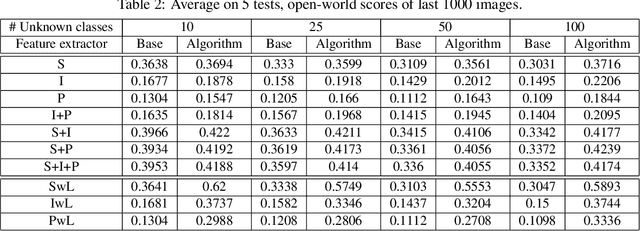
Open-world learning is a problem where an autonomous agent detects things that it does not know and learns them over time from a non-stationary and never-ending stream of data; in an open-world environment, the training data and objective criteria are never available at once. The agent should grasp new knowledge from learning without forgetting acquired prior knowledge. Researchers proposed a few open-world learning agents for image classification tasks that operate in complex scenarios. However, all prior work on open-world learning has all labeled data to learn the new classes from the stream of images. In scenarios where autonomous agents should respond in near real-time or work in areas with limited communication infrastructure, human labeling of data is not possible. Therefore, supervised open-world learning agents are not scalable solutions for such applications. Herein, we propose a new framework that enables agents to learn new classes from a stream of unlabeled data in an unsupervised manner. Also, we study the robustness and learning speed of such agents with supervised and unsupervised feature representation. We also introduce a new metric for open-world learning without labels. We anticipate our theories and method to be a starting point for developing autonomous true open-world never-ending learning agents.
Deep Hedging, Generative Adversarial Networks, and Beyond
Mar 05, 2021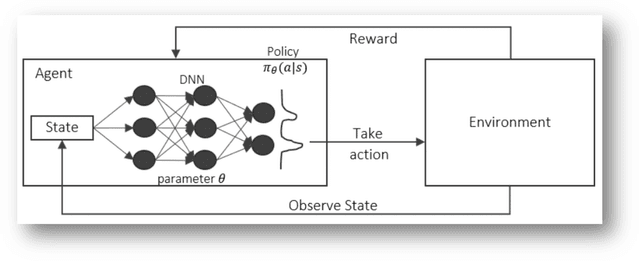
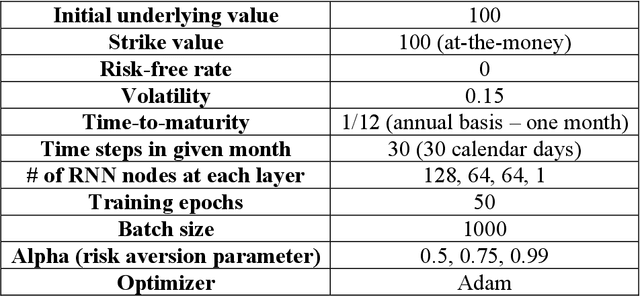

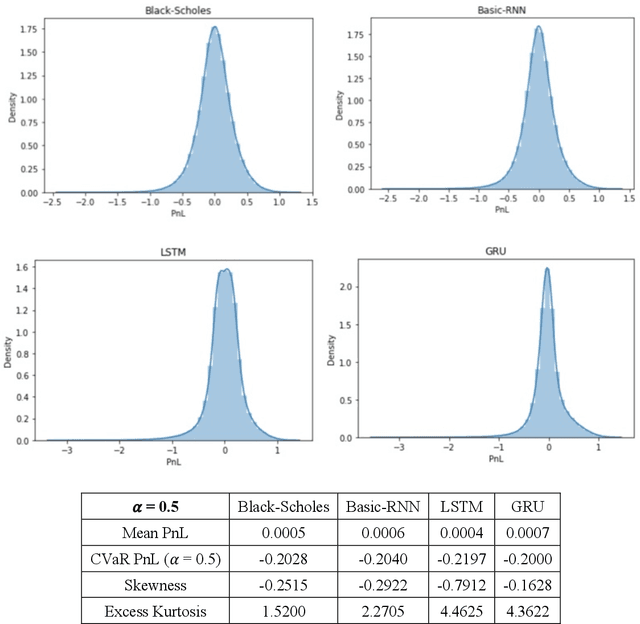
This paper introduces a potential application of deep learning and artificial intelligence in finance, particularly its application in hedging. The major goal encompasses two objectives. First, we present a framework of a direct policy search reinforcement agent replicating a simple vanilla European call option and use the agent for the model-free delta hedging. Through the first part of this paper, we demonstrate how the RNN-based direct policy search RL agents can perform delta hedging better than the classic Black-Scholes model in Q-world based on parametrically generated underlying scenarios, particularly minimizing tail exposures at higher values of the risk aversion parameter. In the second part of this paper, with the non-parametric paths generated by time-series GANs from multi-variate temporal space, we illustrate its delta hedging performance on various values of the risk aversion parameter via the basic RNN-based RL agent introduced in the first part of the paper, showing that we can potentially achieve higher average profits with a rather evident risk-return trade-off. We believe that this RL-based hedging framework is a more efficient way of performing hedging in practice, addressing some of the inherent issues with the classic models, providing promising/intuitive hedging results, and rendering a flexible framework that can be easily paired with other AI-based models for many other purposes.
More Is More -- Narrowing the Generalization Gap by Adding Classification Heads
Feb 09, 2021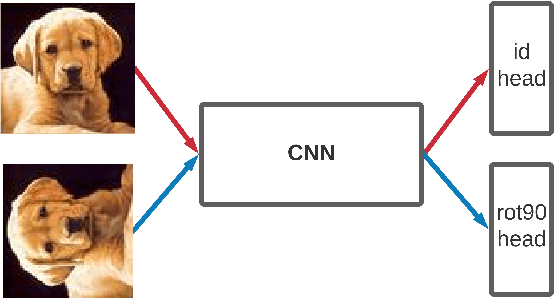
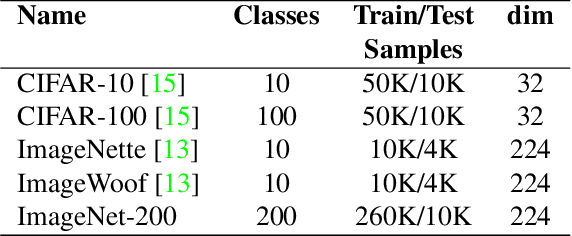
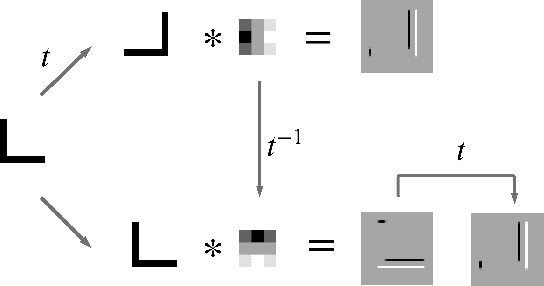

Overfit is a fundamental problem in machine learning in general, and in deep learning in particular. In order to reduce overfit and improve generalization in the classification of images, some employ invariance to a group of transformations, such as rotations and reflections. However, since not all objects exhibit necessarily the same invariance, it seems desirable to allow the network to learn the useful level of invariance from the data. To this end, motivated by self-supervision, we introduce an architecture enhancement for existing neural network models based on input transformations, termed 'TransNet', together with a training algorithm suitable for it. Our model can be employed during training time only and then pruned for prediction, resulting in an equivalent architecture to the base model. Thus pruned, we show that our model improves performance on various data-sets while exhibiting improved generalization, which is achieved in turn by enforcing soft invariance on the convolutional kernels of the last layer in the base model. Theoretical analysis is provided to support the proposed method.
Integration of deep learning with expectation maximization for spatial cue based speech separation in reverberant conditions
Feb 26, 2021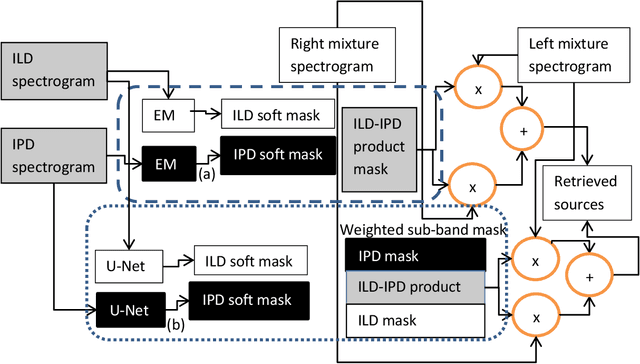
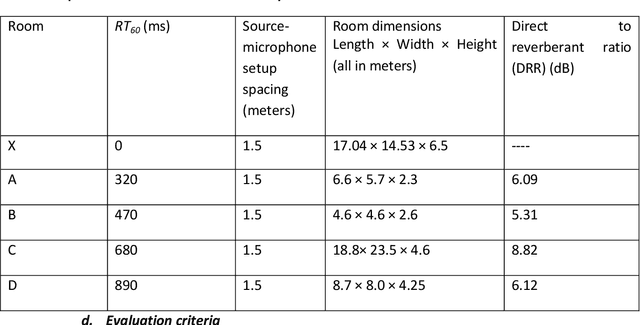
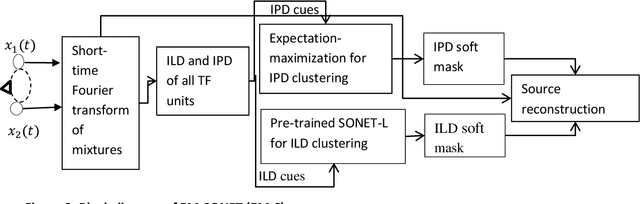

In this paper, we formulate a blind source separation (BSS) framework, which allows integrating U-Net based deep learning source separation network with probabilistic spatial machine learning expectation maximization (EM) algorithm for separating speech in reverberant conditions. Our proposed model uses a pre-trained deep learning convolutional neural network, U-Net, for clustering the interaural level difference (ILD) cues and machine learning expectation maximization (EM) algorithm for clustering the interaural phase difference (IPD) cues. The integrated model exploits the complementary strengths of the two approaches to BSS: the strong modeling power of supervised neural networks and the ease of unsupervised machine learning algorithms, whose few parameters can be estimated on as little as a single segment of an audio mixture. The results show an average improvement of 4.3 dB in signal to distortion ratio (SDR) and 4.3% in short time speech intelligibility (STOI) over the EM based source separation algorithm MESSL-GS (model-based expectation-maximization source separation and localization with garbage source) and 4.5 dB in SDR and 8% in STOI over deep learning convolutional neural network (U-Net) based speech separation algorithm SONET under the reverberant conditions ranging from anechoic to those mostly encountered in the real world.
Dynamic Slimmable Network
Mar 24, 2021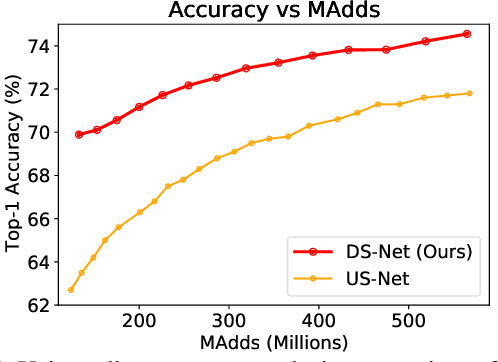

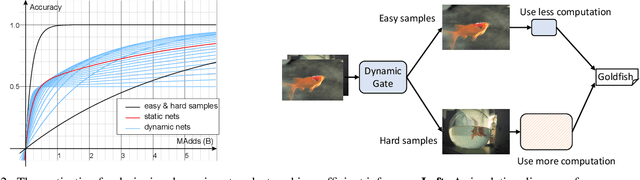
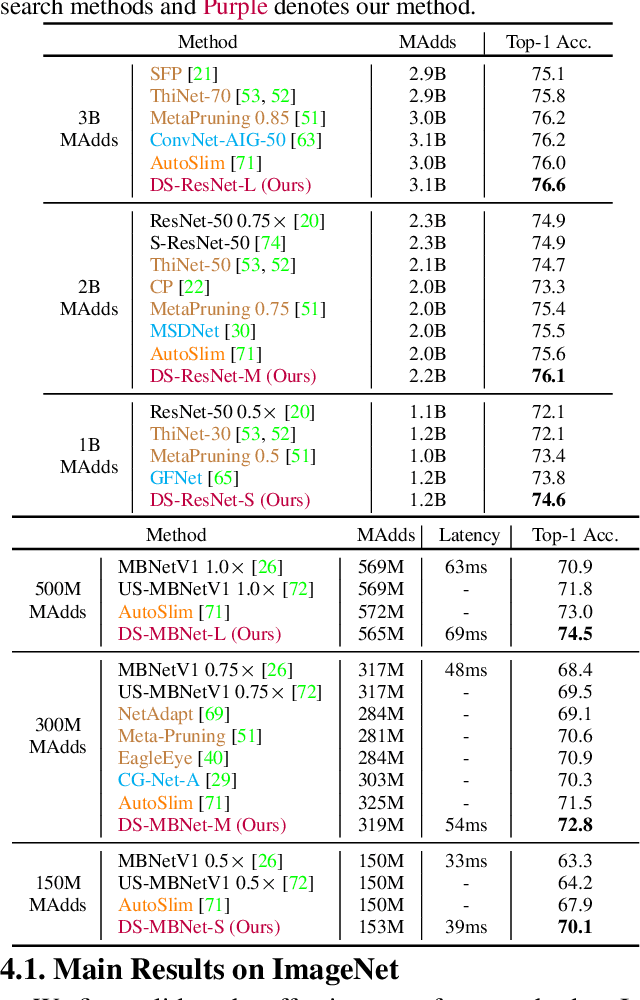
Current dynamic networks and dynamic pruning methods have shown their promising capability in reducing theoretical computation complexity. However, dynamic sparse patterns on convolutional filters fail to achieve actual acceleration in real-world implementation, due to the extra burden of indexing, weight-copying, or zero-masking. Here, we explore a dynamic network slimming regime, named Dynamic Slimmable Network (DS-Net), which aims to achieve good hardware-efficiency via dynamically adjusting filter numbers of networks at test time with respect to different inputs, while keeping filters stored statically and contiguously in hardware to prevent the extra burden. Our DS-Net is empowered with the ability of dynamic inference by the proposed double-headed dynamic gate that comprises an attention head and a slimming head to predictively adjust network width with negligible extra computation cost. To ensure generality of each candidate architecture and the fairness of gate, we propose a disentangled two-stage training scheme inspired by one-shot NAS. In the first stage, a novel training technique for weight-sharing networks named In-place Ensemble Bootstrapping is proposed to improve the supernet training efficacy. In the second stage, Sandwich Gate Sparsification is proposed to assist the gate training by identifying easy and hard samples in an online way. Extensive experiments demonstrate our DS-Net consistently outperforms its static counterparts as well as state-of-the-art static and dynamic model compression methods by a large margin (up to 5.9%). Typically, DS-Net achieves 2-4x computation reduction and 1.62x real-world acceleration over ResNet-50 and MobileNet with minimal accuracy drops on ImageNet. Code release: https://github.com/changlin31/DS-Net .
Potential Impacts of Smart Homes on Human Behavior: A Reinforcement Learning Approach
Feb 26, 2021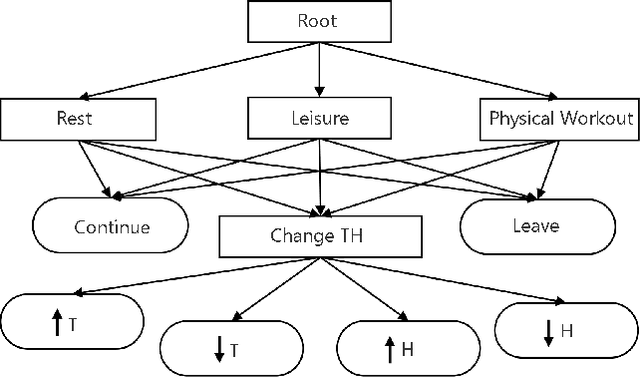
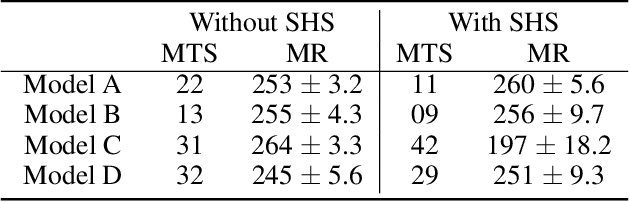

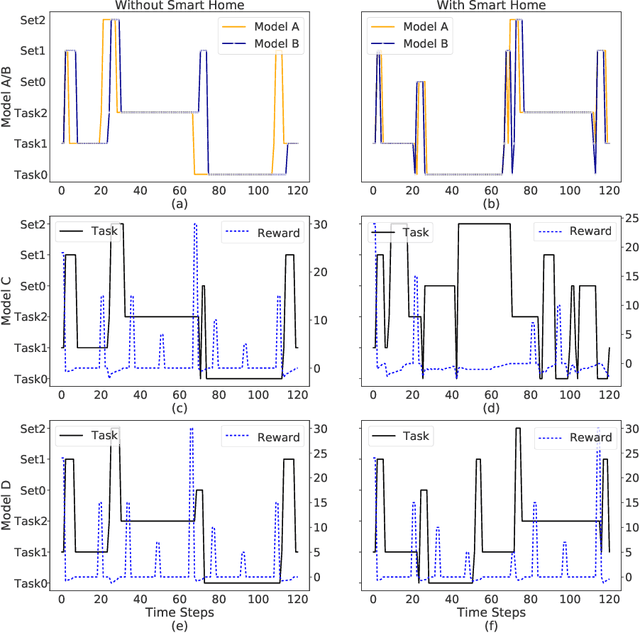
We aim to investigate the potential impacts of smart homes on human behavior. To this end, we simulate a series of human models capable of performing various activities inside a reinforcement learning-based smart home. We then investigate the possibility of human behavior being altered as a result of the smart home and the human model adapting to one-another. We design a semi-Markov decision process human task interleaving model based on hierarchical reinforcement learning that learns to make decisions to either pursue or leave an activity. We then integrate our human model in the smart home which is based on Q-learning. We show that a smart home trained on a generic human model is able to anticipate and learn the thermal preferences of human models with intrinsic rewards similar to the generic model. The hierarchical human model learns to complete each activity and set optimal thermal settings for maximum comfort. With the smart home, the number of time steps required to change the thermal settings are reduced for the human models. Interestingly, we observe that small variations in the human model reward structures can lead to the opposite behavior in the form of unexpected switching between activities which signals changes in human behavior due to the presence of the smart home.
Improving solar wind forecasting using Data Assimilation
Dec 11, 2020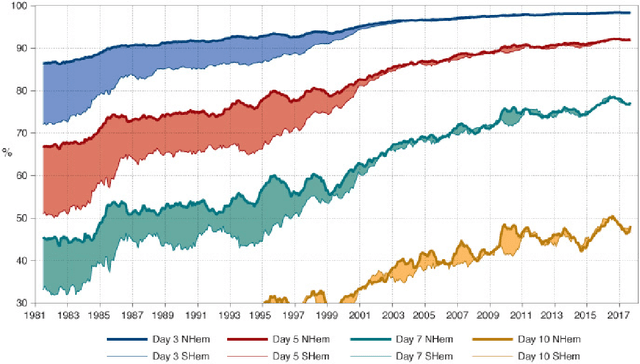
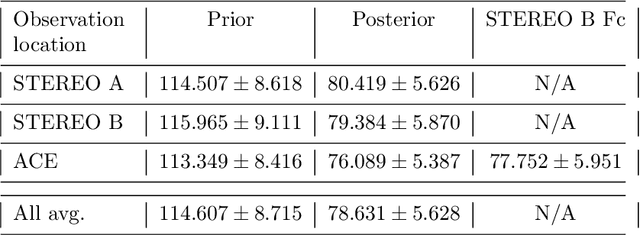
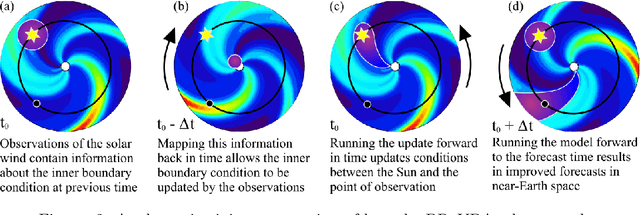
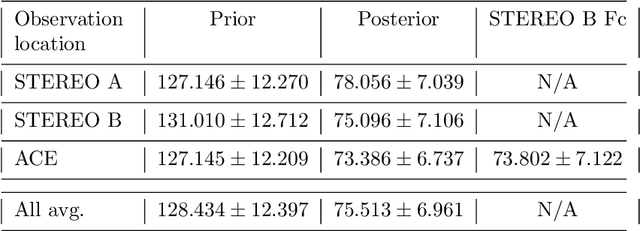
Data Assimilation (DA) has enabled huge improvements in the skill of terrestrial operational weather forecasting. In this study, we use a variational DA scheme with a computationally efficient solar wind model and in situ observations from STEREO A, STEREO B and ACE. This scheme enables solar-wind observations far from the Sun, such as at 1 AU, to update and improve the inner boundary conditions of the solar wind model (at $30$ solar radii). In this way, observational information can be used to improve estimates of the near-Earth solar wind, even when the observations are not directly downstream of the Earth. This allows improved initial conditions of the solar wind to be passed into forecasting models. To this effect we employ the HUXt solar wind model to produce 27-day forecasts of the solar wind during the operational time of STEREO B ($01/11/2007-30/09/2014$). At ACE, we compare these DA forecasts to the corotation of STEREO B observations and find that $27$-day RMSE for STEREO-B corotation and DA forecasts are comparable. However, the DA forecast is shown to improve solar wind forecasts when STEREO-B's latitude is offset from Earth. And the DA scheme enables the representation of the solar wind in the whole model domain between the Sun and the Earth to be improved, which will enable improved forecasting of CME arrival time and speed.
Classification of Imbalanced Credit scoring data sets Based on Ensemble Method with the Weighted-Hybrid-Sampling
Feb 09, 2021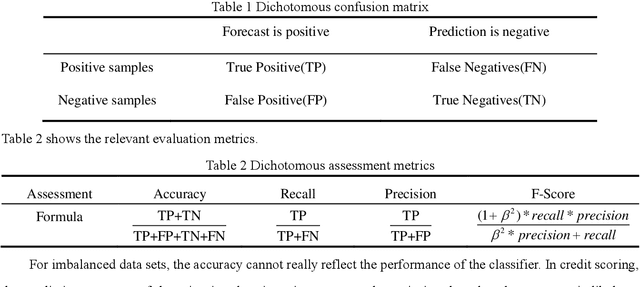
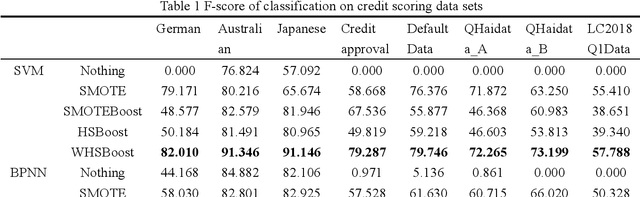
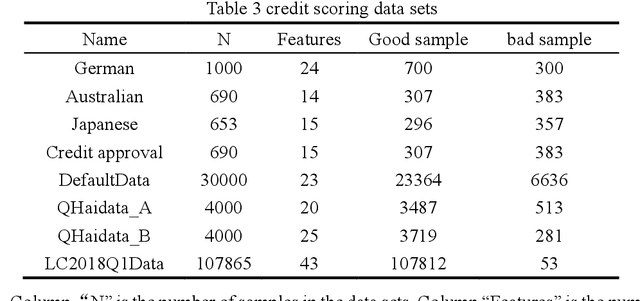
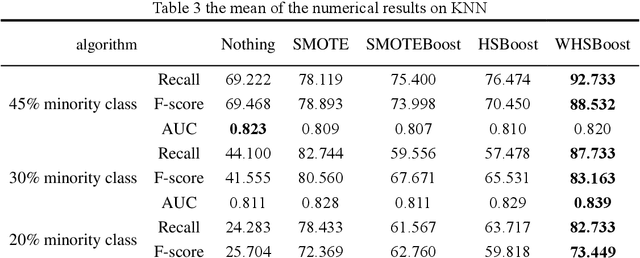
In the era of big data, the utilization of credit-scoring models to determine the credit risk of applicants accurately becomes a trend in the future. The conventional machine learning on credit scoring data sets tends to have poor classification for the minority class, which may bring huge commercial harm to banks. In order to classify imbalanced data sets, we propose a new ensemble algorithm, namely, Weighted-Hybrid-Sampling-Boost (WHSBoost). In data sampling, we process the imbalanced data sets with weights by the Weighted-SMOTE method and the Weighted-Under-Sampling method, and thus obtain a balanced training sample data set with equal weight. In ensemble algorithm, each time we train the base classifier, the balanced data set is given by the method above. In order to verify the applicability and robustness of the WHSBoost algorithm, we performed experiments on the simulation data sets, real benchmark data sets and real credit scoring data sets, comparing WHSBoost with SMOTE, SMOTEBoost and HSBoost based on SVM, BPNN, DT and KNN.
SpecTr: Spectral Transformer for Hyperspectral Pathology Image Segmentation
Mar 05, 2021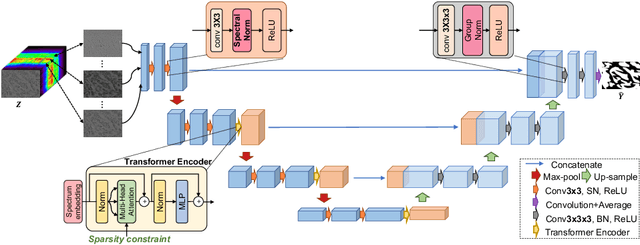
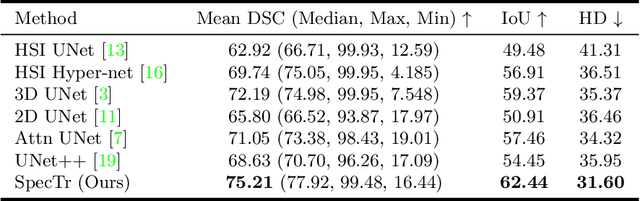
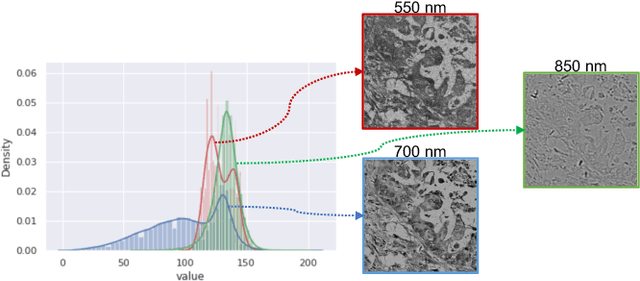
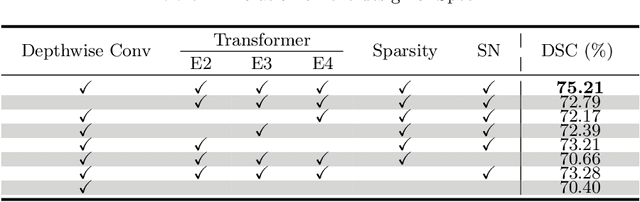
Hyperspectral imaging (HSI) unlocks the huge potential to a wide variety of applications relied on high-precision pathology image segmentation, such as computational pathology and precision medicine. Since hyperspectral pathology images benefit from the rich and detailed spectral information even beyond the visible spectrum, the key to achieve high-precision hyperspectral pathology image segmentation is to felicitously model the context along high-dimensional spectral bands. Inspired by the strong context modeling ability of transformers, we hereby, for the first time, formulate the contextual feature learning across spectral bands for hyperspectral pathology image segmentation as a sequence-to-sequence prediction procedure by transformers. To assist spectral context learning procedure, we introduce two important strategies: (1) a sparsity scheme enforces the learned contextual relationship to be sparse, so as to eliminates the distraction from the redundant bands; (2) a spectral normalization, a separate group normalization for each spectral band, mitigates the nuisance caused by heterogeneous underlying distributions of bands. We name our method Spectral Transformer (SpecTr), which enjoys two benefits: (1) it has a strong ability to model long-range dependency among spectral bands, and (2) it jointly explores the spatial-spectral features of HSI. Experiments show that SpecTr outperforms other competing methods in a hyperspectral pathology image segmentation benchmark without the need of pre-training. Code is available at https://github.com/hfut-xc-yun/SpecTr.