 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Auto-tuning of Deep Neural Networks by Conflicting Layer Removal
Mar 07, 2021
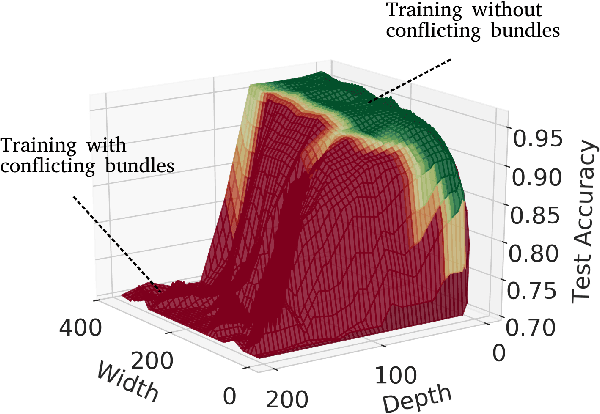
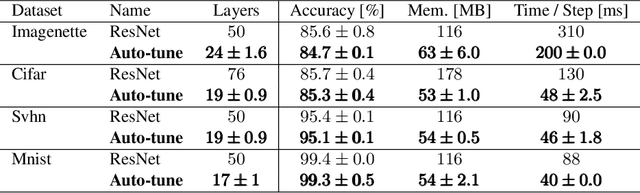
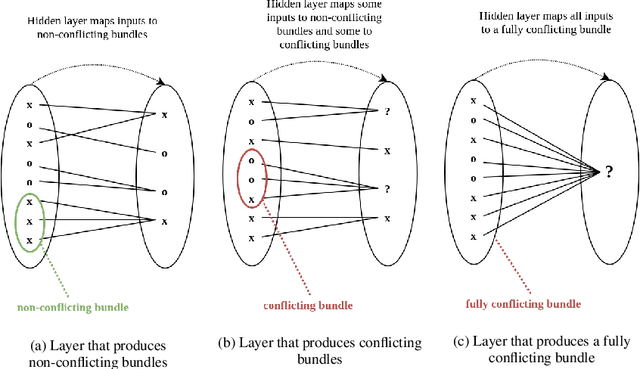
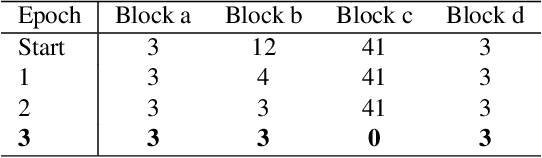
Designing neural network architectures is a challenging task and knowing which specific layers of a model must be adapted to improve the performance is almost a mystery. In this paper, we introduce a novel methodology to identify layers that decrease the test accuracy of trained models. Conflicting layers are detected as early as the beginning of training. In the worst-case scenario, we prove that such a layer could lead to a network that cannot be trained at all. A theoretical analysis is provided on what is the origin of those layers that result in a lower overall network performance, which is complemented by our extensive empirical evaluation. More precisely, we identified those layers that worsen the performance because they would produce what we name conflicting training bundles. We will show that around 60% of the layers of trained residual networks can be completely removed from the architecture with no significant increase in the test-error. We will further present a novel neural-architecture-search (NAS) algorithm that identifies conflicting layers at the beginning of the training. Architectures found by our auto-tuning algorithm achieve competitive accuracy values when compared against more complex state-of-the-art architectures, while drastically reducing memory consumption and inference time for different computer vision tasks. The source code is available on https://github.com/peerdavid/conflicting-bundles
Singer Identification Using Deep Timbre Feature Learning with KNN-Net
Feb 20, 2021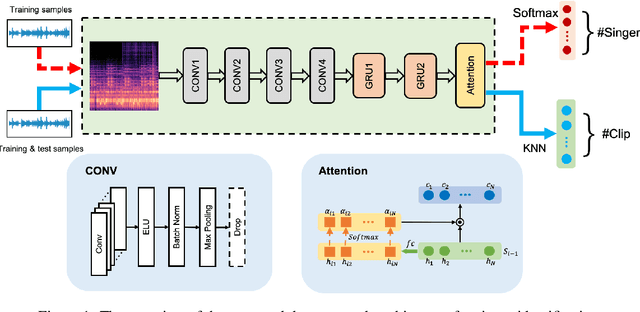
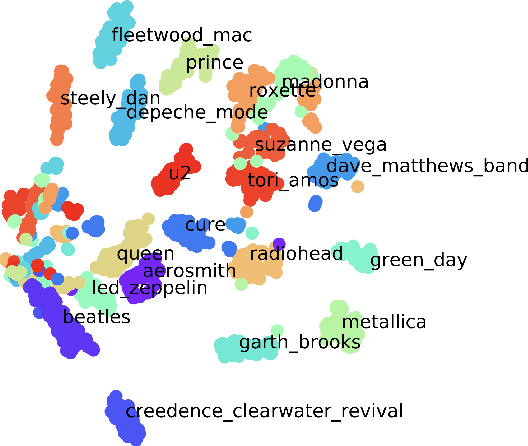
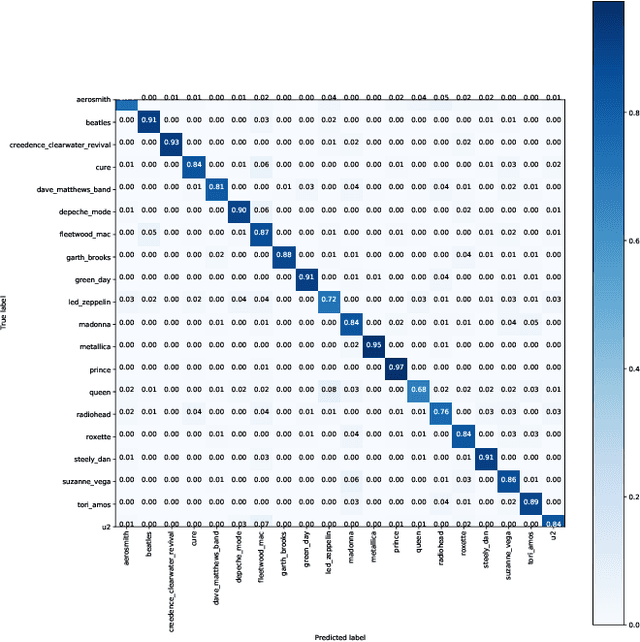
In this paper, we study the issue of automatic singer identification (SID) in popular music recordings, which aims to recognize who sang a given piece of song. The main challenge for this investigation lies in the fact that a singer's singing voice changes and intertwines with the signal of background accompaniment in time domain. To handle this challenge, we propose the KNN-Net for SID, which is a deep neural network model with the goal of learning local timbre feature representation from the mixture of singer voice and background music. Unlike other deep neural networks using the softmax layer as the output layer, we instead utilize the KNN as a more interpretable layer to output target singer labels. Moreover, attention mechanism is first introduced to highlight crucial timbre features for SID. Experiments on the existing artist20 dataset show that the proposed approach outperforms the state-of-the-art method by 4%. We also create singer32 and singer60 datasets consisting of Chinese pop music to evaluate the reliability of the proposed method. The more extensive experiments additionally indicate that our proposed model achieves a significant performance improvement compared to the state-of-the-art methods.
CoRe: An Efficient Coarse-refined Training Framework for BERT
Nov 27, 2020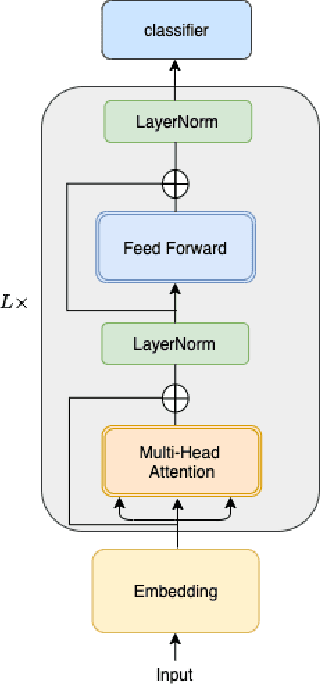
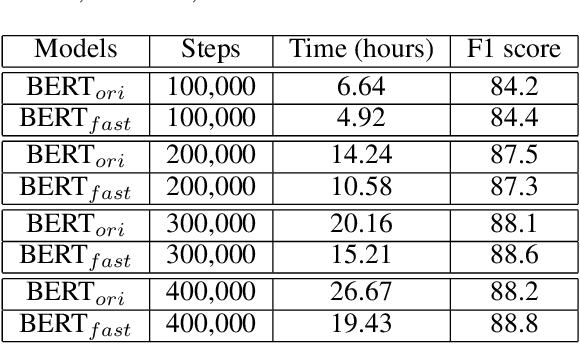
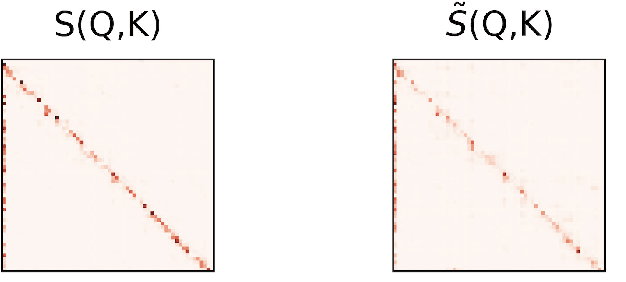
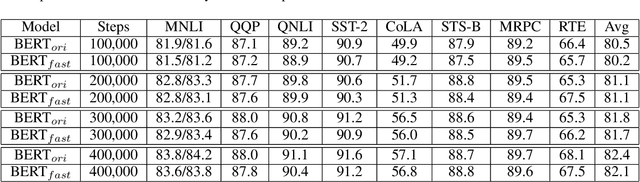
In recent years, BERT has made significant breakthroughs on many natural language processing tasks and attracted great attentions. Despite its accuracy gains, the BERT model generally involves a huge number of parameters and needs to be trained on massive datasets, so training such a model is computationally very challenging and time-consuming. Hence, training efficiency should be a critical issue. In this paper, we propose a novel coarse-refined training framework named CoRe to speed up the training of BERT. Specifically, we decompose the training process of BERT into two phases. In the first phase, by introducing fast attention mechanism and decomposing the large parameters in the feed-forward network sub-layer, we construct a relaxed BERT model which has much less parameters and much lower model complexity than the original BERT, so the relaxed model can be quickly trained. In the second phase, we transform the trained relaxed BERT model into the original BERT and further retrain the model. Thanks to the desired initialization provided by the relaxed model, the retraining phase requires much less training steps, compared with training an original BERT model from scratch with a random initialization. Experimental results show that the proposed CoRe framework can greatly reduce the training time without reducing the performance.
Automatic Volumetric Segmentation of Additive Manufacturing Defects with 3D U-Net
Jan 22, 2021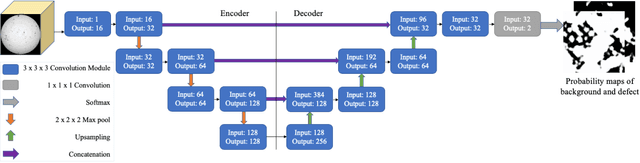
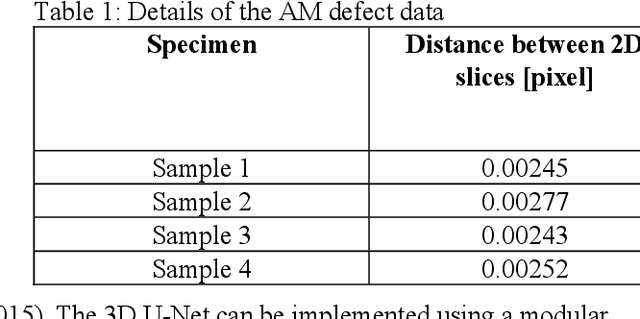

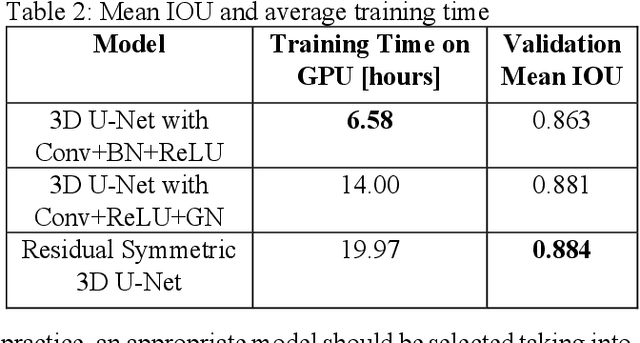
Segmentation of additive manufacturing (AM) defects in X-ray Computed Tomography (XCT) images is challenging, due to the poor contrast, small sizes and variation in appearance of defects. Automatic segmentation can, however, provide quality control for additive manufacturing. Over recent years, three-dimensional convolutional neural networks (3D CNNs) have performed well in the volumetric segmentation of medical images. In this work, we leverage techniques from the medical imaging domain and propose training a 3D U-Net model to automatically segment defects in XCT images of AM samples. This work not only contributes to the use of machine learning for AM defect detection but also demonstrates for the first time 3D volumetric segmentation in AM. We train and test with three variants of the 3D U-Net on an AM dataset, achieving a mean intersection of union (IOU) value of 88.4%.
* Accepted by AAAI 2020 Spring Symposia
FaceBoxes: A CPU Real-time Face Detector with High Accuracy
Jan 03, 2018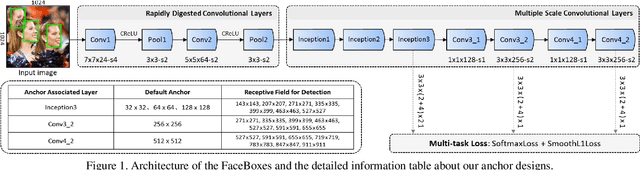
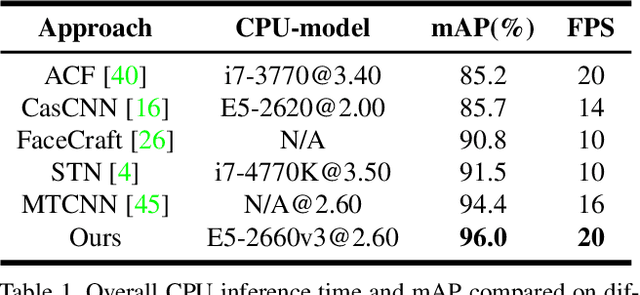
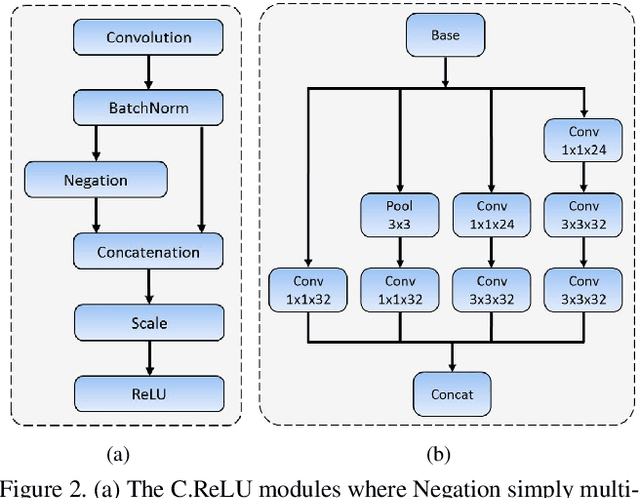
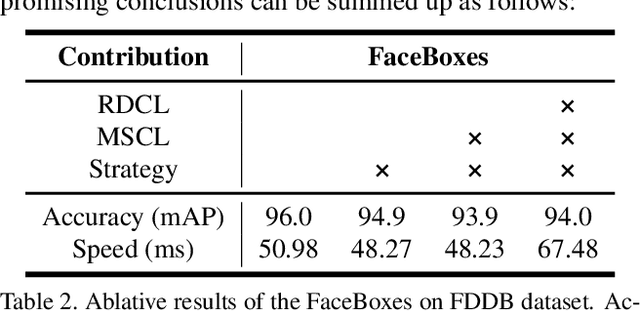
Although tremendous strides have been made in face detection, one of the remaining open challenges is to achieve real-time speed on the CPU as well as maintain high performance, since effective models for face detection tend to be computationally prohibitive. To address this challenge, we propose a novel face detector, named FaceBoxes, with superior performance on both speed and accuracy. Specifically, our method has a lightweight yet powerful network structure that consists of the Rapidly Digested Convolutional Layers (RDCL) and the Multiple Scale Convolutional Layers (MSCL). The RDCL is designed to enable FaceBoxes to achieve real-time speed on the CPU. The MSCL aims at enriching the receptive fields and discretizing anchors over different layers to handle faces of various scales. Besides, we propose a new anchor densification strategy to make different types of anchors have the same density on the image, which significantly improves the recall rate of small faces. As a consequence, the proposed detector runs at 20 FPS on a single CPU core and 125 FPS using a GPU for VGA-resolution images. Moreover, the speed of FaceBoxes is invariant to the number of faces. We comprehensively evaluate this method and present state-of-the-art detection performance on several face detection benchmark datasets, including the AFW, PASCAL face, and FDDB.
Deep Reinforcement Learning for Combinatorial Optimization: Covering Salesman Problems
Feb 11, 2021



This paper introduces a new deep learning approach to approximately solve the Covering Salesman Problem (CSP). In this approach, given the city locations of a CSP as input, a deep neural network model is designed to directly output the solution. It is trained using the deep reinforcement learning without supervision. Specifically, in the model, we apply the Multi-head Attention to capture the structural patterns, and design a dynamic embedding to handle the dynamic patterns of the problem. Once the model is trained, it can generalize to various types of CSP tasks (different sizes and topologies) with no need of re-training. Through controlled experiments, the proposed approach shows desirable time complexity: it runs more than 20 times faster than the traditional heuristic solvers with a tiny gap of optimality. Moreover, it significantly outperforms the current state-of-the-art deep learning approaches for combinatorial optimization in the aspect of both training and inference. In comparison with traditional solvers, this approach is highly desirable for most of the challenging tasks in practice that are usually large-scale and require quick decisions.
SUM: A Benchmark Dataset of Semantic Urban Meshes
Feb 27, 2021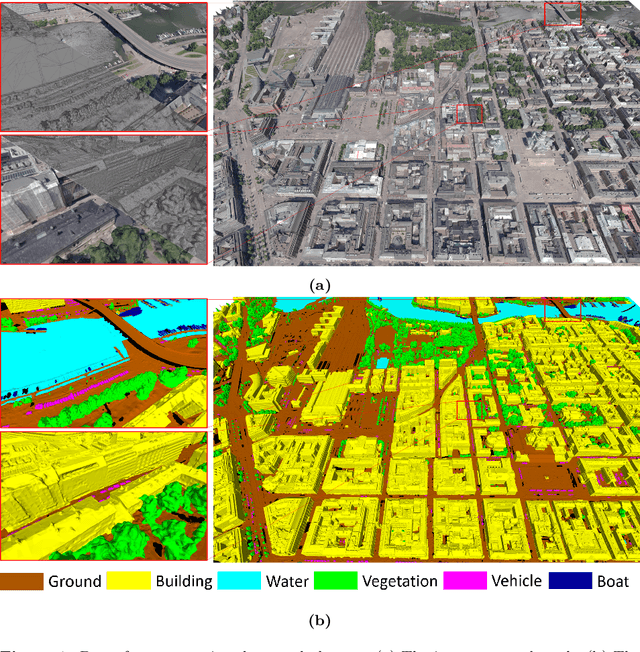
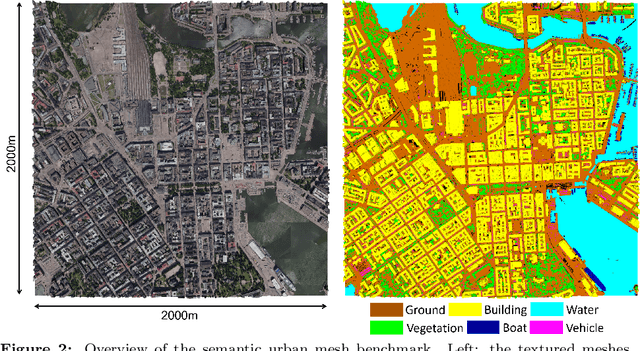
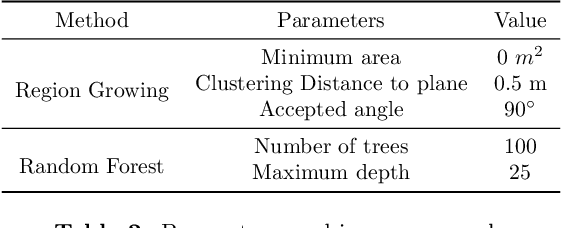
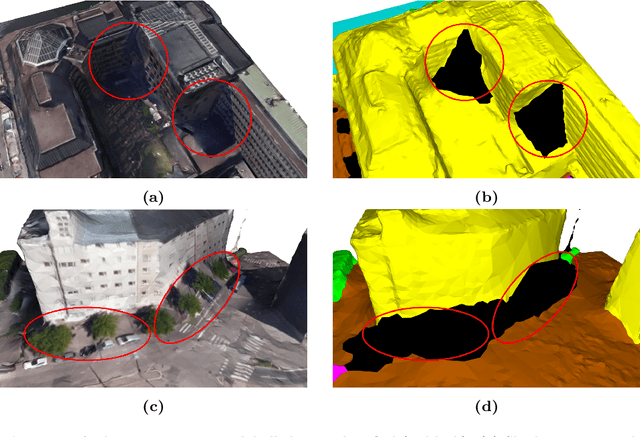
Recent developments in data acquisition technology allow us to collect 3D texture meshes quickly. Those can help us understand and analyse the urban environment, and as a consequence are useful for several applications like spatial analysis and urban planning. Semantic segmentation of texture meshes through deep learning methods can enhance this understanding, but it requires a lot of labelled data. This paper introduces a new benchmark dataset of semantic urban meshes, a novel semi-automatic annotation framework, and an open-source annotation tool for 3D meshes. In particular, our dataset covers about 4 km2 in Helsinki (Finland), with six classes, and we estimate that we save about 600 hours of labelling work using our annotation framework, which includes initial segmentation and interactive refinement. Furthermore, we compare the performance of several representative 3D semantic segmentation methods on our annotated dataset. The results show our initial segmentation outperforms other methods and achieves an overall accuracy of 93.0% and mIoU of 66.2% with less training time compared to other deep learning methods. We also evaluate the effect of the input training data, which shows that our method only requires about 7% (which covers about 0.23 km2) to approach robust and adequate results whereas KPConv needs at least 33% (which covers about 1.0 km2).
Fast Greedy Subset Selection from Large Candidate Solution Sets in Evolutionary Multi-objective Optimization
Feb 01, 2021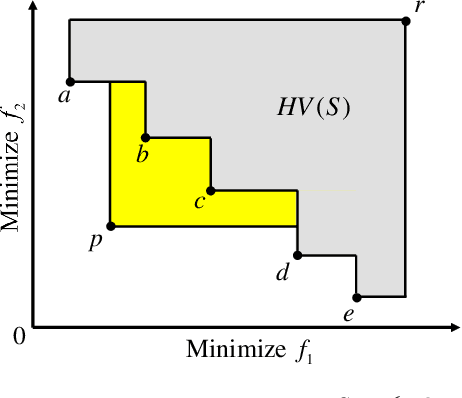
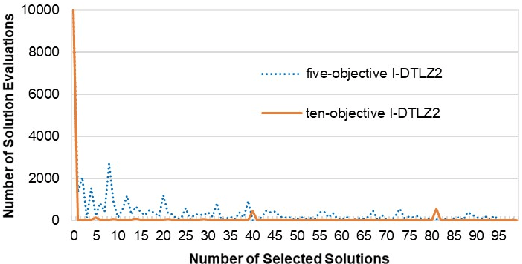
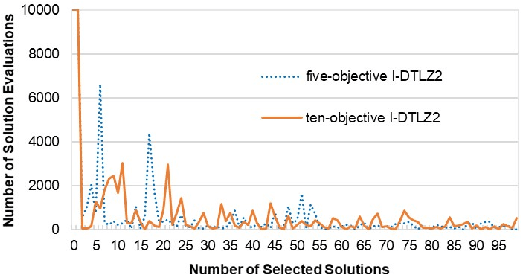
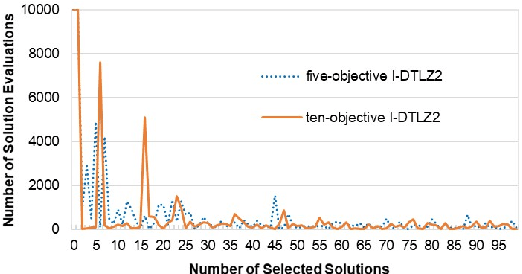
Subset selection is an interesting and important topic in the field of evolutionary multi-objective optimization (EMO). Especially, in an EMO algorithm with an unbounded external archive, subset selection is an essential post-processing procedure to select a pre-specified number of solutions as the final result. In this paper, we discuss the efficiency of greedy subset selection for the hypervolume, IGD and IGD+ indicators. Greedy algorithms usually efficiently handle subset selection. However, when a large number of solutions are given (e.g., subset selection from tens of thousands of solutions in an unbounded external archive), they often become time-consuming. Our idea is to use the submodular property, which is known for the hypervolume indicator, to improve their efficiency. First, we prove that the IGD and IGD+ indicators are also submodular. Next, based on the submodular property, we propose an efficient greedy inclusion algorithm for each indicator. Then, we demonstrate through computational experiments that the proposed algorithms are much faster than the standard greedy subset selection algorithms.
Real-time Facial Expression Recognition "In The Wild'' by Disentangling 3D Expression from Identity
May 12, 2020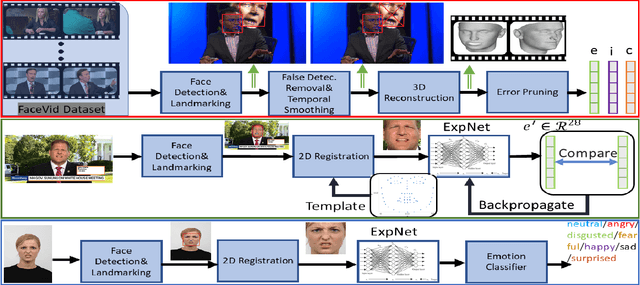
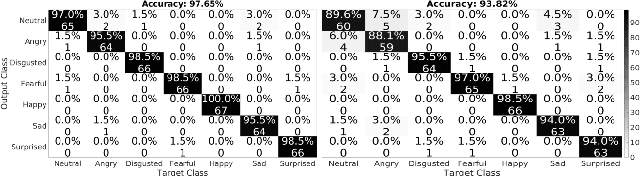
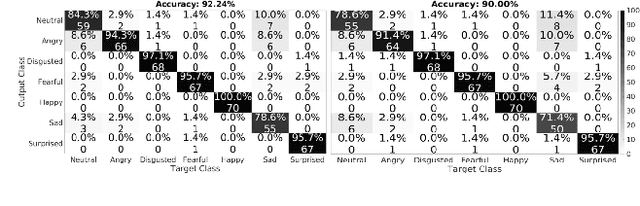

Human emotions analysis has been the focus of many studies, especially in the field of Affective Computing, and is important for many applications, e.g. human-computer intelligent interaction, stress analysis, interactive games, animations, etc. Solutions for automatic emotion analysis have also benefited from the development of deep learning approaches and the availability of vast amount of visual facial data on the internet. This paper proposes a novel method for human emotion recognition from a single RGB image. We construct a large-scale dataset of facial videos (\textbf{FaceVid}), rich in facial dynamics, identities, expressions, appearance and 3D pose variations. We use this dataset to train a deep Convolutional Neural Network for estimating expression parameters of a 3D Morphable Model and combine it with an effective back-end emotion classifier. Our proposed framework runs at 50 frames per second and is capable of robustly estimating parameters of 3D expression variation and accurately recognizing facial expressions from in-the-wild images. We present extensive experimental evaluation that shows that the proposed method outperforms the compared techniques in estimating the 3D expression parameters and achieves state-of-the-art performance in recognising the basic emotions from facial images, as well as recognising stress from facial videos. %compared to the current state of the art in emotion recognition from facial images.
DeepNAG: Deep Non-Adversarial Gesture Generation
Nov 18, 2020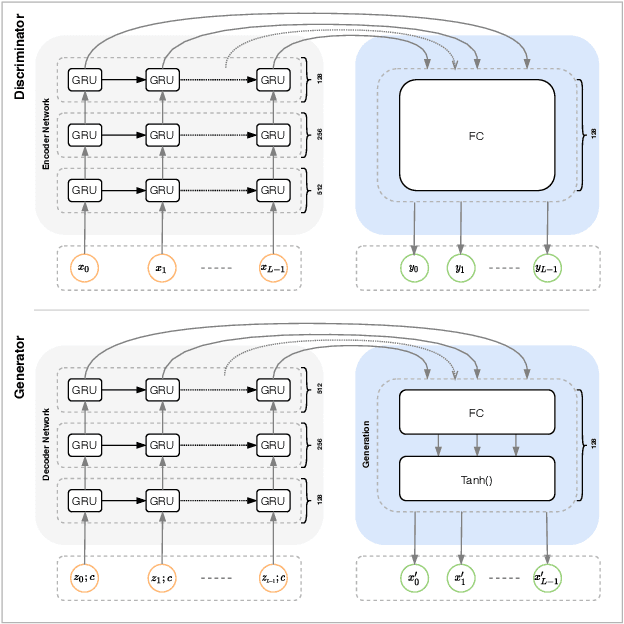
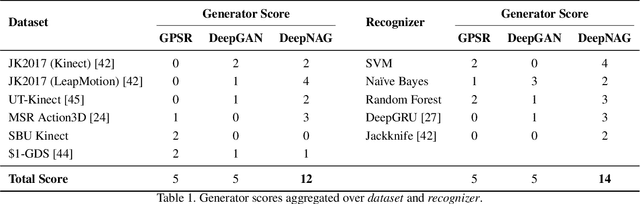
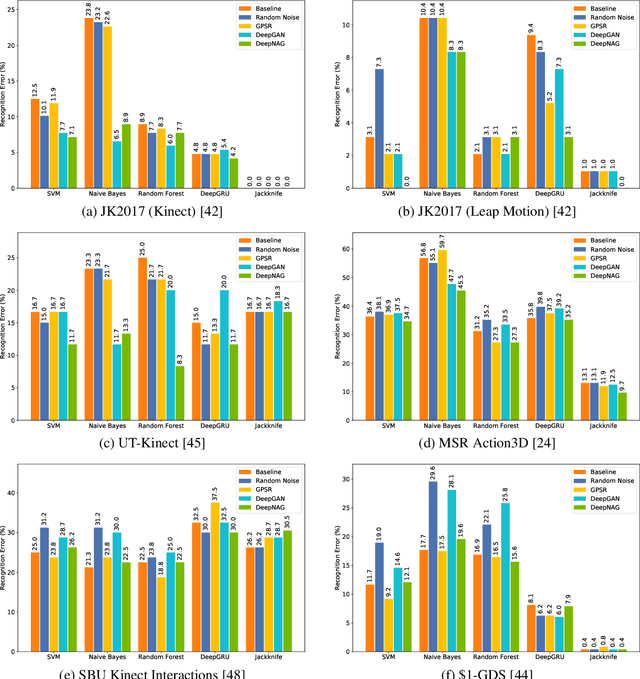

Synthetic data generation to improve classification performance (data augmentation) is a well-studied problem. Recently, generative adversarial networks (GAN) have shown superior image data augmentation performance, but their suitability in gesture synthesis has received inadequate attention. Further, GANs prohibitively require simultaneous generator and discriminator network training. We tackle both issues in this work. We first discuss a novel, device-agnostic GAN model for gesture synthesis called DeepGAN. Thereafter, we formulate DeepNAG by introducing a new differentiable loss function based on dynamic time warping and the average Hausdorff distance, which allows us to train DeepGAN's generator without requiring a discriminator. Through evaluations, we compare the utility of DeepGAN and DeepNAG against two alternative techniques for training five recognizers using data augmentation over six datasets. We further investigate the perceived quality of synthesized samples via an Amazon Mechanical Turk user study based on the HYPE benchmark. We find that DeepNAG outperforms DeepGAN in accuracy, training time (up to 17x faster), and realism, thereby opening the door to a new line of research in generator network design and training for gesture synthesis. Our source code is available at https://www.deepnag.com.