 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving Generalization of Transfer Learning Across Domains Using Spatio-Temporal Features in Autonomous Driving
Mar 15, 2021
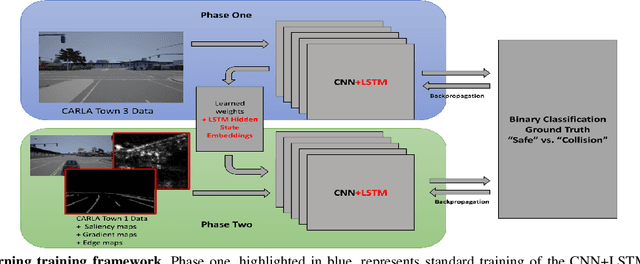
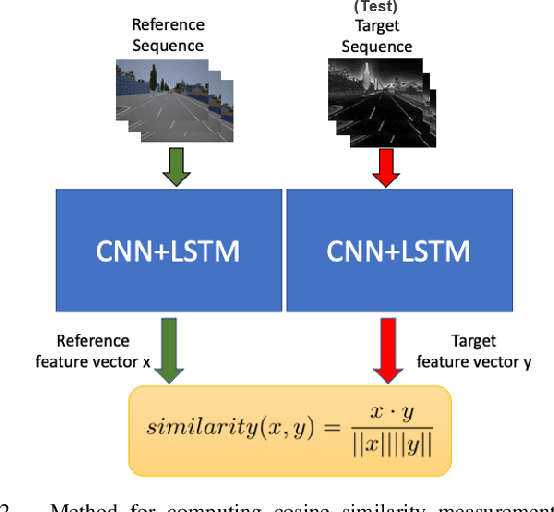

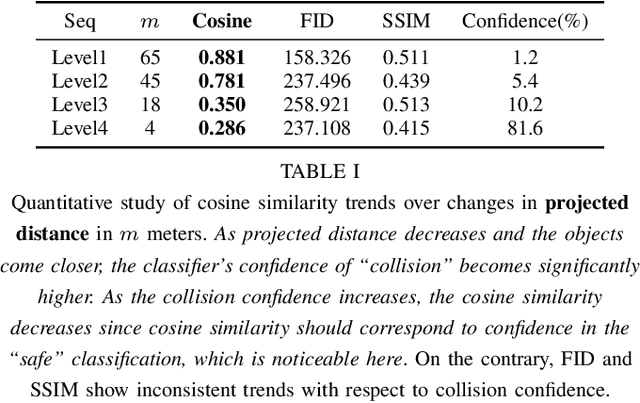
Training vision-based autonomous driving in the real world can be inefficient and impractical. Vehicle simulation can be used to learn in the virtual world, and the acquired skills can be transferred to handle real-world scenarios more effectively. Between virtual and real visual domains, common features such as relative distance to road edges and other vehicles over time are consistent. These visual elements are intuitively crucial for human decision making during driving. We hypothesize that these spatio-temporal factors can also be used in transfer learning to improve generalization across domains. First, we propose a CNN+LSTM transfer learning framework to extract the spatio-temporal features representing vehicle dynamics from scenes. Next, we conduct an ablation study to quantitatively estimate the significance of various features in the decisions of driving systems. We observe that physically interpretable factors are highly correlated with network decisions, while representational differences between scenes are not. Finally, based on the results of our ablation study, we propose a transfer learning pipeline that uses saliency maps and physical features extracted from a source model to enhance the performance of a target model. Training of our network is initialized with the learned weights from CNN and LSTM latent features (capturing the intrinsic physics of the moving vehicle w.r.t. its surroundings) transferred from one domain to another. Our experiments show that this proposed transfer learning framework better generalizes across unseen domains compared to a baseline CNN model on a binary classification learning task.
Combining Bayesian and Deep Learning Methods for the Delineation of the Fan in Ultrasound Images
Feb 02, 2021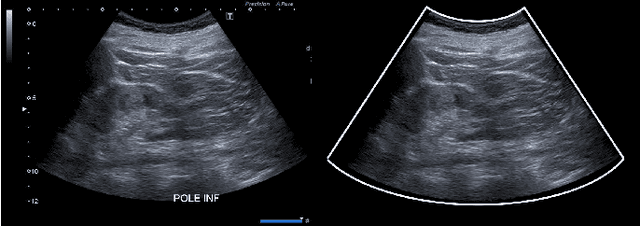
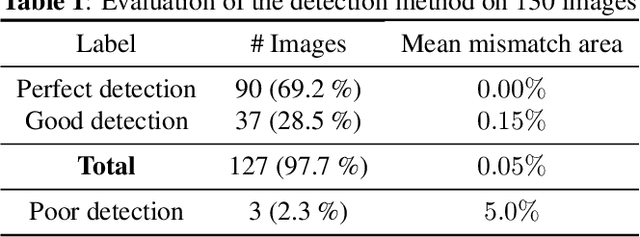
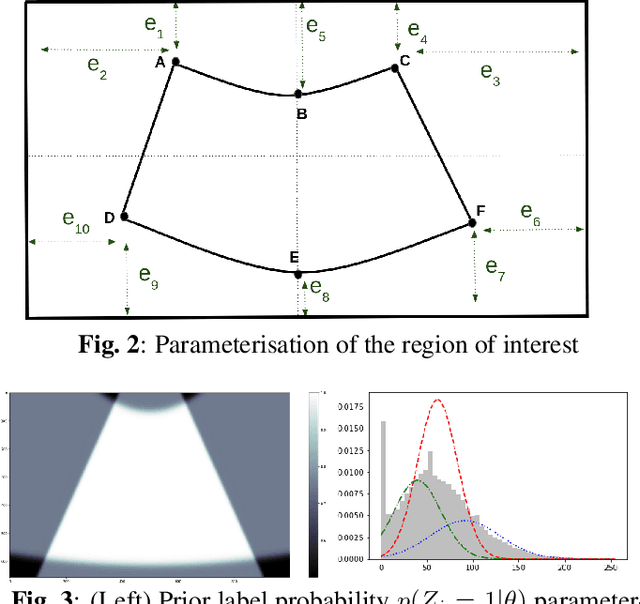
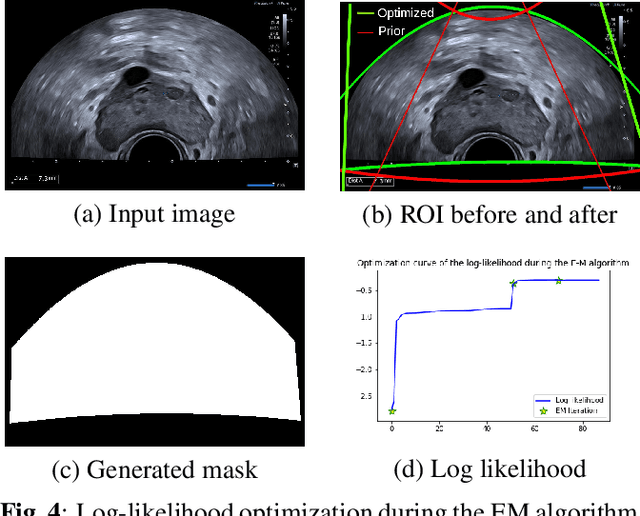
Ultrasound (US) images usually contain identifying information outside the ultrasound fan area and manual annotations placed by the sonographers during exams. For those images to be exploitable in a Deep Learning framework, one needs to first delineate the border of the fan which delimits the ultrasound fan area and then remove other annotations inside. We propose a parametric probabilistic approach for the first task. We make use of this method to generate a training data set with segmentation masks of the region of interest (ROI) and train a U-Net to perform the same task in a supervised way, thus considerably reducing computational time of the method, one hundred and sixty times faster. These images are then processed with existing inpainting methods to remove annotations present inside the fan area. To the best of our knowledge, this is the first parametric approach to quickly detect the fan in an ultrasound image without any other information than the image itself.
Efficient Reservoir Computing using Field Programmable Gate Array and Electro-optic Modulation
Feb 11, 2021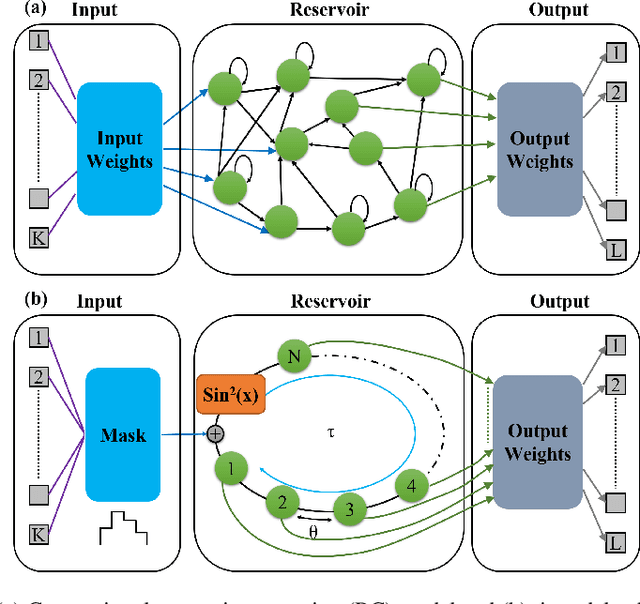
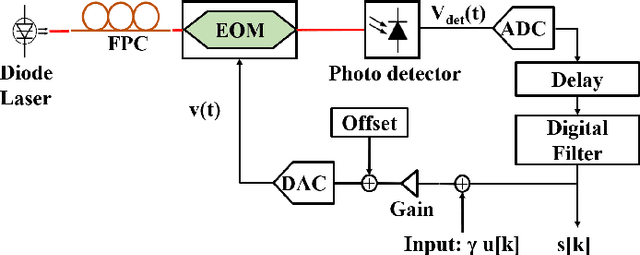
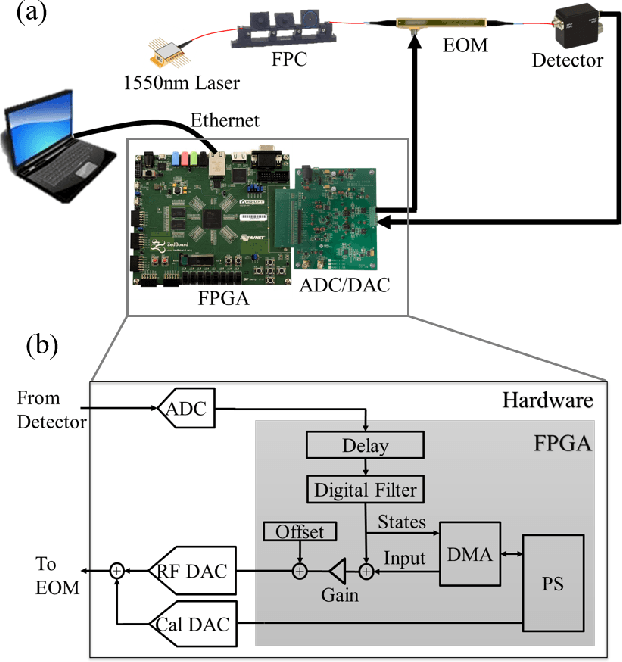

We experimentally demonstrate a hybrid reservoir computing system consisting of an electro-optic modulator and field programmable gate array (FPGA). It implements delay lines and filters digitally for flexible dynamics and high connectivity, while supporting a large number of reservoir nodes. To evaluate the system's performance and versatility, three benchmark tests are performed. The first is the 10th order Nonlinear Auto-Regressive Moving Average test (NARMA-10), where the predictions of 1000 and 25,000 steps yield impressively low normalized root mean square errors (NRMSE's) of 0.142 and 0.148, respectively. Such accurate predictions over into the far future speak to its capability of large sample size processing, as enabled by the present hybrid design. The second is the Santa Fe laser data prediction, where a normalized mean square error (NMSE) of 6.73x10-3 is demonstrated. The third is the isolate spoken digit recognition, with a word error rate close to 0.34%. Accurate, versatile, flexibly reconfigurable, and capable of long-term prediction, this reservoir computing system could find a wealth of impactful applications in real-time information processing, weather forecasting, and financial analysis.
Real-time Facial Expression Recognition "In The Wild'' by Disentangling 3D Expression from Identity
May 12, 2020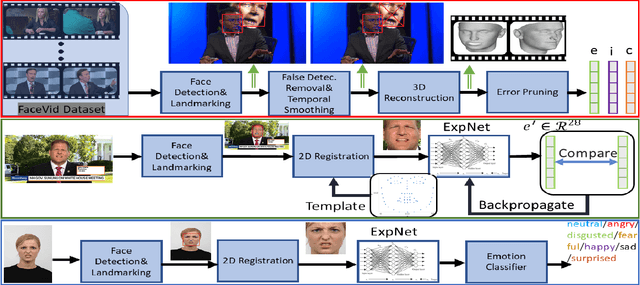
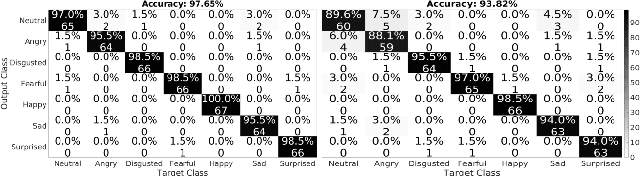
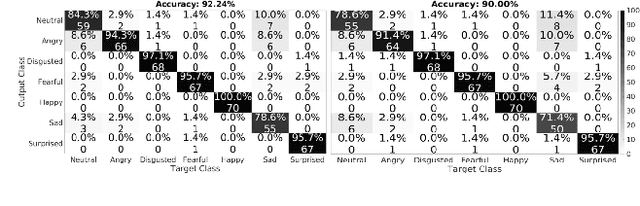

Human emotions analysis has been the focus of many studies, especially in the field of Affective Computing, and is important for many applications, e.g. human-computer intelligent interaction, stress analysis, interactive games, animations, etc. Solutions for automatic emotion analysis have also benefited from the development of deep learning approaches and the availability of vast amount of visual facial data on the internet. This paper proposes a novel method for human emotion recognition from a single RGB image. We construct a large-scale dataset of facial videos (\textbf{FaceVid}), rich in facial dynamics, identities, expressions, appearance and 3D pose variations. We use this dataset to train a deep Convolutional Neural Network for estimating expression parameters of a 3D Morphable Model and combine it with an effective back-end emotion classifier. Our proposed framework runs at 50 frames per second and is capable of robustly estimating parameters of 3D expression variation and accurately recognizing facial expressions from in-the-wild images. We present extensive experimental evaluation that shows that the proposed method outperforms the compared techniques in estimating the 3D expression parameters and achieves state-of-the-art performance in recognising the basic emotions from facial images, as well as recognising stress from facial videos. %compared to the current state of the art in emotion recognition from facial images.
Leveraging IoT and Weather Conditions to Estimate the Riders Waiting for the Bus Transit on Campus
Feb 02, 2021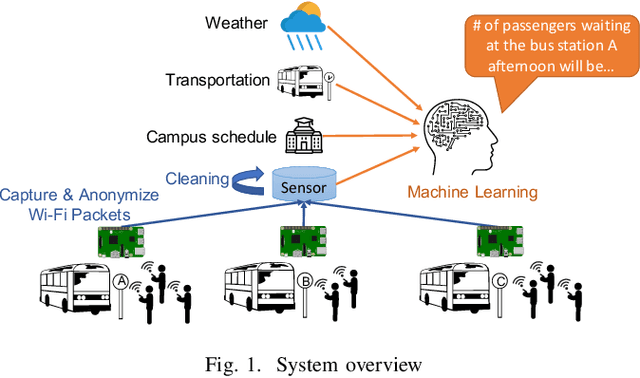
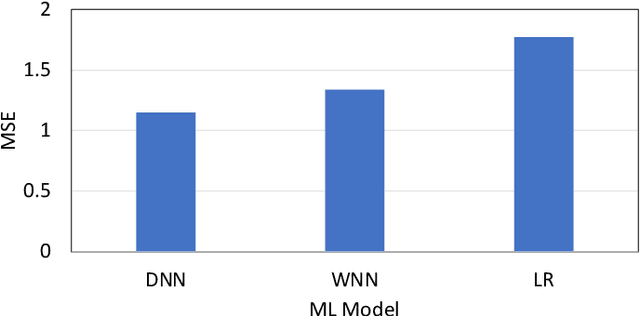
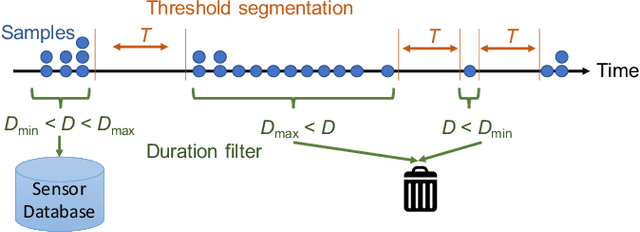
The communication technology revolution in this era has increased the use of smartphones in the world of transportation. In this paper, we propose to leverage IoT device data, capturing passengers' smartphones' Wi-Fi data in conjunction with weather conditions to predict the expected number of passengers waiting at a bus stop at a specific time using deep learning models. Our study collected data from the transit bus system at James Madison University (JMU) in Virginia, USA. This paper studies the correlation between the number of passengers waiting at bus stops and weather conditions. Empirically, an experiment with several bus stops in JMU, was utilized to confirm a high precision level. We compared our Deep Neural Network (DNN) model against two baseline models: Linear Regression (LR) and a Wide Neural Network (WNN). The gap between the baseline models and DNN was 35% and 14% better Mean Squared Error (MSE) scores for predictions in favor of the DNN compared to LR and WNN, respectively.
Model-based Reinforcement Learning for Semi-Markov Decision Processes with Neural ODEs
Jun 29, 2020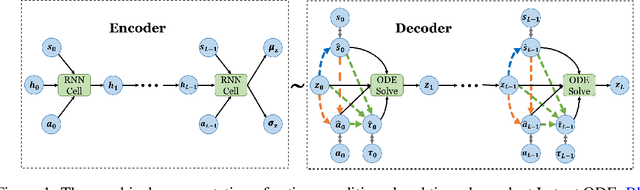

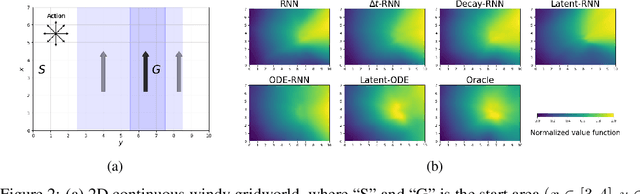
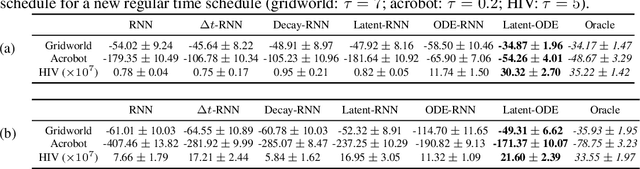
We present two elegant solutions for modeling continuous-time dynamics, in a novel model-based reinforcement learning (RL) framework for semi-Markov decision processes (SMDPs), using neural ordinary differential equations (ODEs). Our models accurately characterize continuous-time dynamics and enable us to develop high-performing policies using a small amount of data. We also develop a model-based approach for optimizing time schedules to reduce interaction rates with the environment while maintaining the near-optimal performance, which is not possible for model-free methods. We experimentally demonstrate the efficacy of our methods across various continuous-time domains.
Morphognosis: the shape of knowledge in space and time
Mar 04, 2017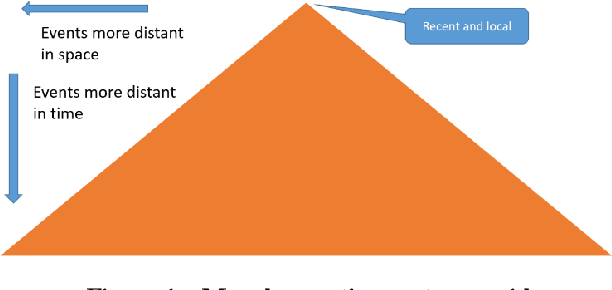
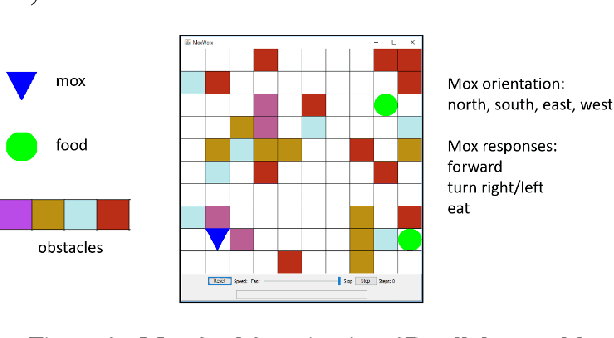
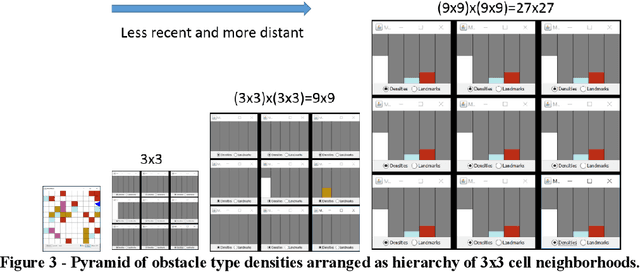
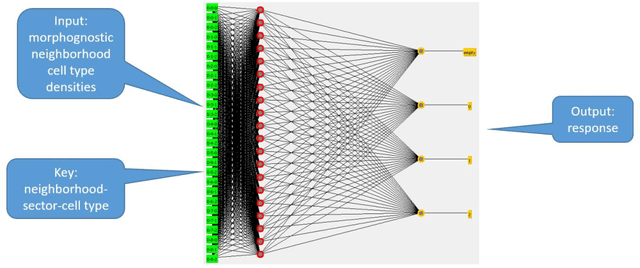
Artificial intelligence research to a great degree focuses on the brain and behaviors that the brain generates. But the brain, an extremely complex structure resulting from millions of years of evolution, can be viewed as a solution to problems posed by an environment existing in space and time. The environment generates signals that produce sensory events within an organism. Building an internal spatial and temporal model of the environment allows an organism to navigate and manipulate the environment. Higher intelligence might be the ability to process information coming from a larger extent of space-time. In keeping with nature's penchant for extending rather than replacing, the purpose of the mammalian neocortex might then be to record events from distant reaches of space and time and render them, as though yet near and present, to the older, deeper brain whose instinctual roles have changed little over eons. Here this notion is embodied in a model called morphognosis (morpho = shape and gnosis = knowledge). Its basic structure is a pyramid of event recordings called a morphognostic. At the apex of the pyramid are the most recent and nearby events. Receding from the apex are less recent and possibly more distant events. A morphognostic can thus be viewed as a structure of progressively larger chunks of space-time knowledge. A set of morphognostics forms long-term memories that are learned by exposure to the environment. A cellular automaton is used as the platform to investigate the morphognosis model, using a simulated organism that learns to forage in its world for food, build a nest, and play the game of Pong.
Asynchronous Multi-View SLAM
Jan 17, 2021



Existing multi-camera SLAM systems assume synchronized shutters for all cameras, which is often not the case in practice. In this work, we propose a generalized multi-camera SLAM formulation which accounts for asynchronous sensor observations. Our framework integrates a continuous-time motion model to relate information across asynchronous multi-frames during tracking, local mapping, and loop closing. For evaluation, we collected AMV-Bench, a challenging new SLAM dataset covering 482 km of driving recorded using our asynchronous multi-camera robotic platform. AMV-Bench is over an order of magnitude larger than previous multi-view HD outdoor SLAM datasets, and covers diverse and challenging motions and environments. Our experiments emphasize the necessity of asynchronous sensor modeling, and show that the use of multiple cameras is critical towards robust and accurate SLAM in challenging outdoor scenes.
Neural Data Augmentation via Example Extrapolation
Feb 02, 2021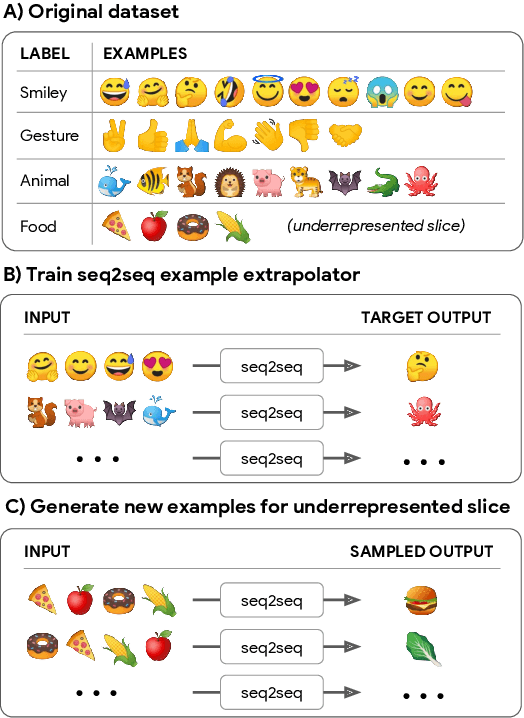

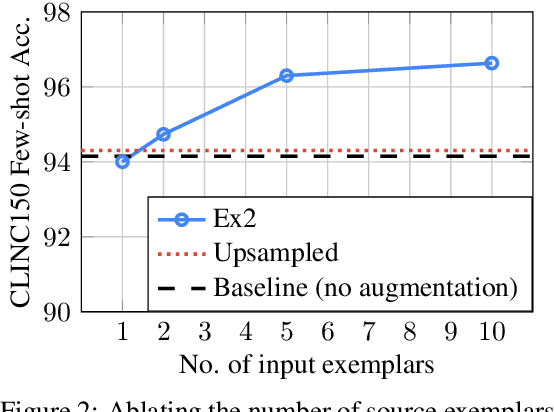
In many applications of machine learning, certain categories of examples may be underrepresented in the training data, causing systems to underperform on such "few-shot" cases at test time. A common remedy is to perform data augmentation, such as by duplicating underrepresented examples, or heuristically synthesizing new examples. But these remedies often fail to cover the full diversity and complexity of real examples. We propose a data augmentation approach that performs neural Example Extrapolation (Ex2). Given a handful of exemplars sampled from some distribution, Ex2 synthesizes new examples that also belong to the same distribution. The Ex2 model is learned by simulating the example generation procedure on data-rich slices of the data, and it is applied to underrepresented, few-shot slices. We apply Ex2 to a range of language understanding tasks and significantly improve over state-of-the-art methods on multiple few-shot learning benchmarks, including for relation extraction (FewRel) and intent classification + slot filling (SNIPS).
Analyzing Overfitting under Class Imbalance in Neural Networks for Image Segmentation
Feb 20, 2021
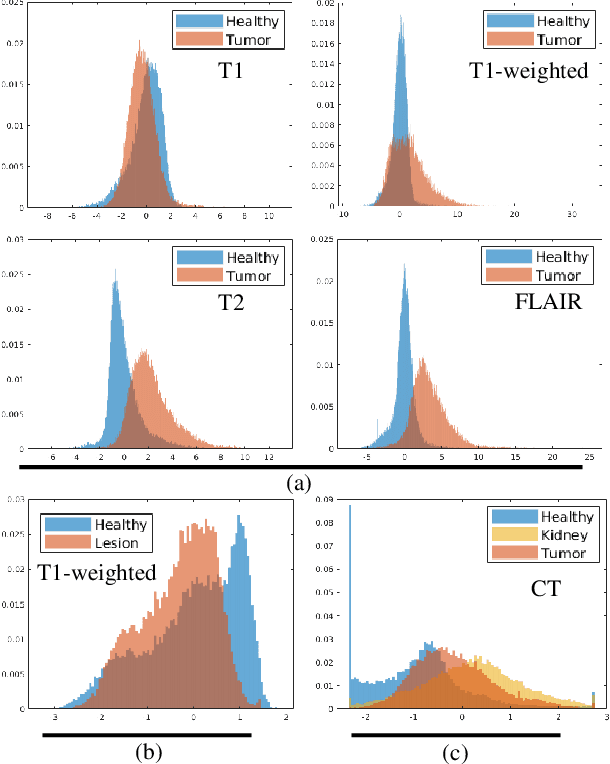
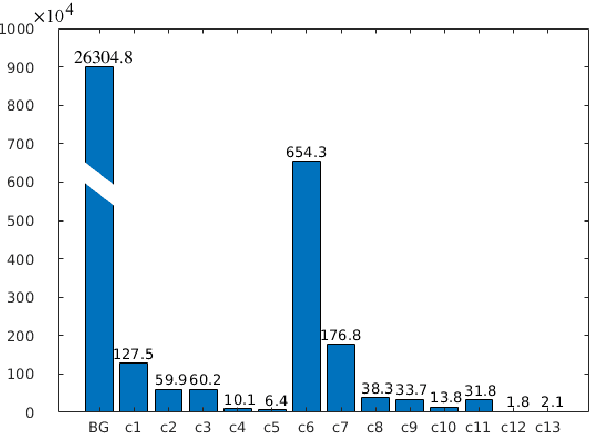
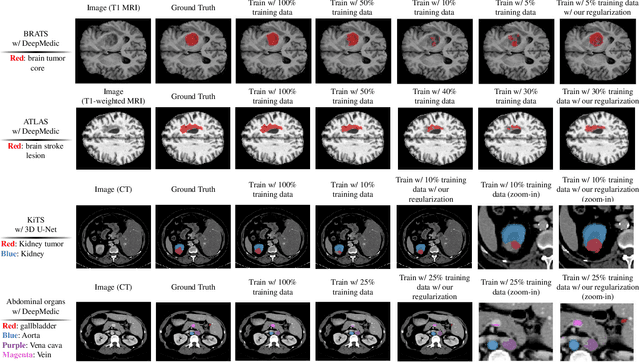
Class imbalance poses a challenge for developing unbiased, accurate predictive models. In particular, in image segmentation neural networks may overfit to the foreground samples from small structures, which are often heavily under-represented in the training set, leading to poor generalization. In this study, we provide new insights on the problem of overfitting under class imbalance by inspecting the network behavior. We find empirically that when training with limited data and strong class imbalance, at test time the distribution of logit activations may shift across the decision boundary, while samples of the well-represented class seem unaffected. This bias leads to a systematic under-segmentation of small structures. This phenomenon is consistently observed for different databases, tasks and network architectures. To tackle this problem, we introduce new asymmetric variants of popular loss functions and regularization techniques including a large margin loss, focal loss, adversarial training, mixup and data augmentation, which are explicitly designed to counter logit shift of the under-represented classes. Extensive experiments are conducted on several challenging segmentation tasks. Our results demonstrate that the proposed modifications to the objective function can lead to significantly improved segmentation accuracy compared to baselines and alternative approaches.