 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time, Highly Accurate Robotic Grasp Detection using Fully Convolutional Neural Networks with High-Resolution Images
Sep 16, 2018
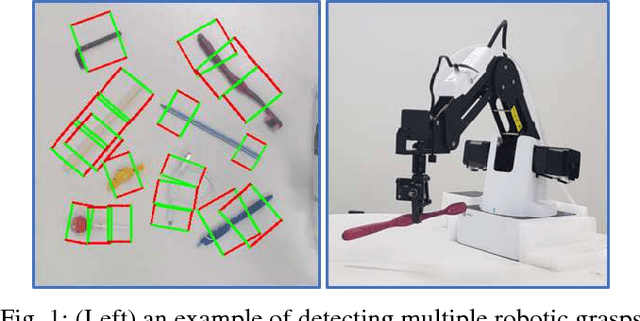
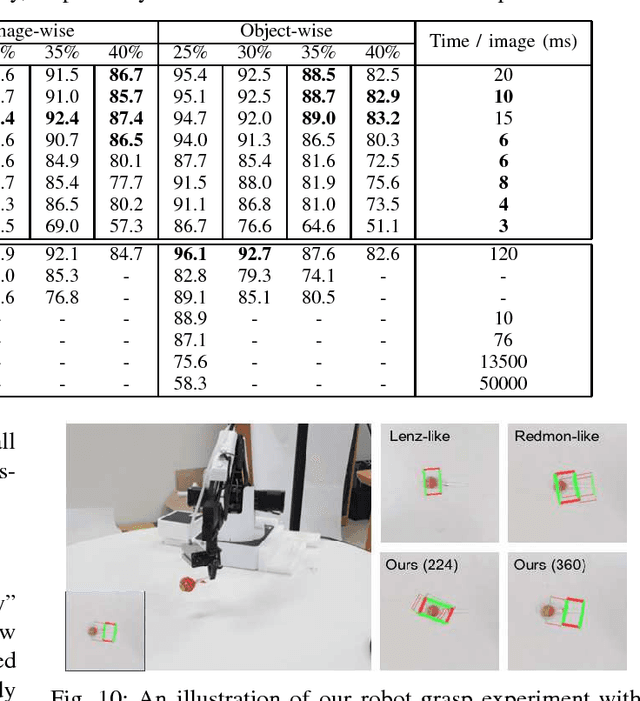
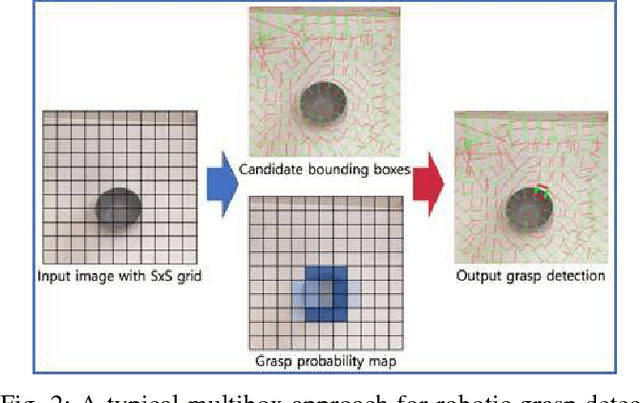
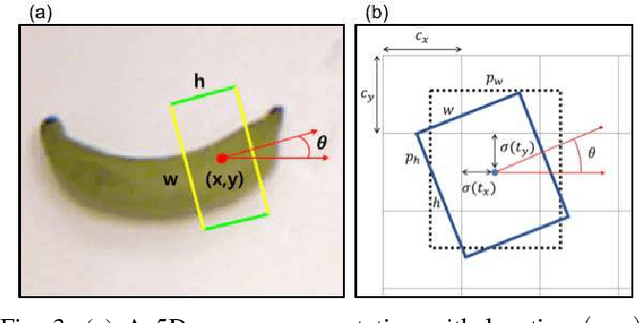
Robotic grasp detection for novel objects is a challenging task, but for the last few years, deep learning based approaches have achieved remarkable performance improvements, up to 96.1% accuracy, with RGB-D data. In this paper, we propose fully convolutional neural network (FCNN) based methods for robotic grasp detection. Our methods also achieved state-of-the-art detection accuracy (up to 96.6%) with state-of- the-art real-time computation time for high-resolution images (6-20ms per 360x360 image) on Cornell dataset. Due to FCNN, our proposed method can be applied to images with any size for detecting multigrasps on multiobjects. Proposed methods were evaluated using 4-axis robot arm with small parallel gripper and RGB-D camera for grasping challenging small, novel objects. With accurate vision-robot coordinate calibration through our proposed learning-based, fully automatic approach, our proposed method yielded 90% success rate.
RackLay: Multi-Layer Layout Estimation for Warehouse Racks
Mar 17, 2021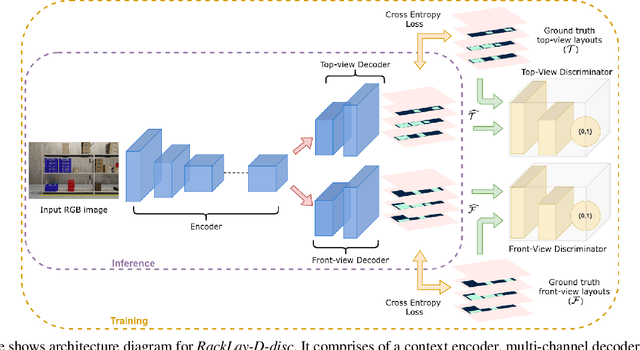

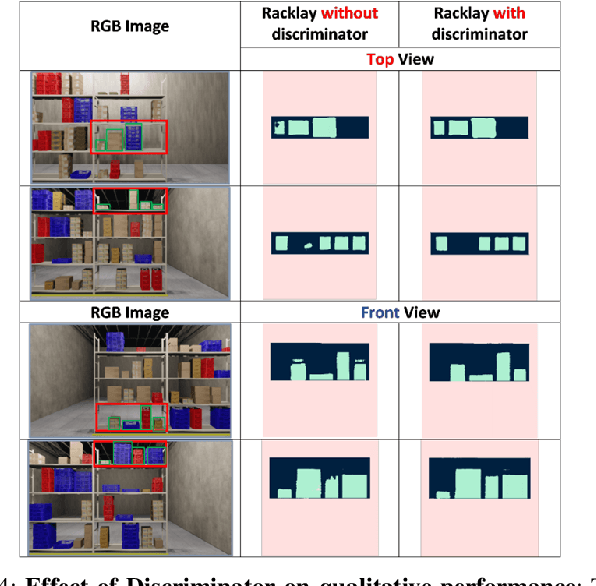

Given a monocular colour image of a warehouse rack, we aim to predict the bird's-eye view layout for each shelf in the rack, which we term as multi-layer layout prediction. To this end, we present RackLay, a deep neural network for real-time shelf layout estimation from a single image. Unlike previous layout estimation methods, which provide a single layout for the dominant ground plane alone, RackLay estimates the top-view and front-view layout for each shelf in the considered rack populated with objects. RackLay's architecture and its variants are versatile and estimate accurate layouts for diverse scenes characterized by varying number of visible shelves in an image, large range in shelf occupancy factor and varied background clutter. Given the extreme paucity of datasets in this space and the difficulty involved in acquiring real data from warehouses, we additionally release a flexible synthetic dataset generation pipeline WareSynth which allows users to control the generation process and tailor the dataset according to contingent application. The ablations across architectural variants and comparison with strong prior baselines vindicate the efficacy of RackLay as an apt architecture for the novel problem of multi-layered layout estimation. We also show that fusing the top-view and front-view enables 3D reasoning applications such as metric free space estimation for the considered rack.
A Multi-View Approach To Audio-Visual Speaker Verification
Feb 11, 2021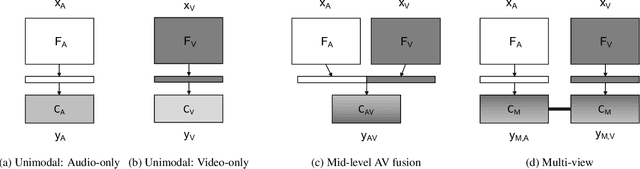
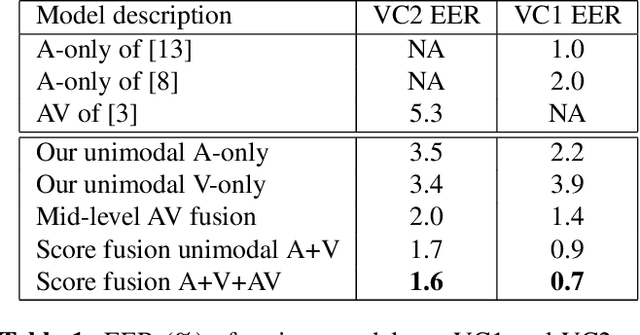

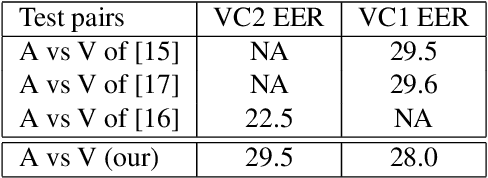
Although speaker verification has conventionally been an audio-only task, some practical applications provide both audio and visual streams of input. In these cases, the visual stream provides complementary information and can often be leveraged in conjunction with the acoustics of speech to improve verification performance. In this study, we explore audio-visual approaches to speaker verification, starting with standard fusion techniques to learn joint audio-visual (AV) embeddings, and then propose a novel approach to handle cross-modal verification at test time. Specifically, we investigate unimodal and concatenation based AV fusion and report the lowest AV equal error rate (EER) of 0.7% on the VoxCeleb1 dataset using our best system. As these methods lack the ability to do cross-modal verification, we introduce a multi-view model which uses a shared classifier to map audio and video into the same space. This new approach achieves 28% EER on VoxCeleb1 in the challenging testing condition of cross-modal verification.
Real-time Funnel Generation for Restricted Motion Planning
Nov 04, 2019
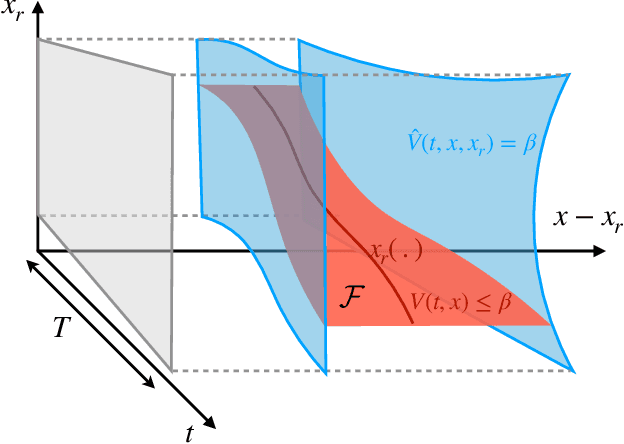
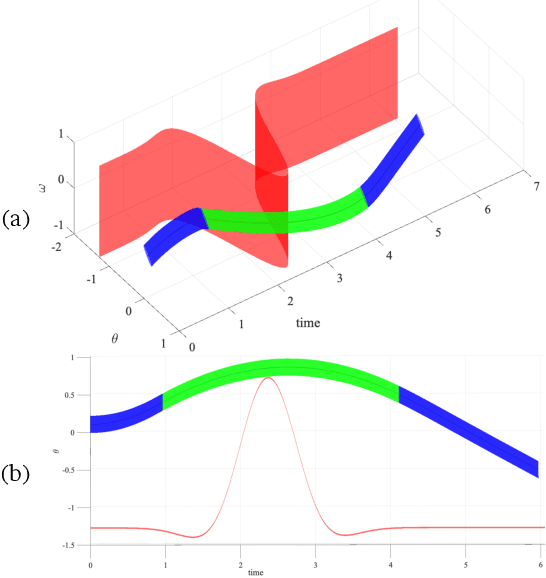
In autonomous systems, a motion planner generates reference trajectories which are tracked by a low-level controller. For safe operation, the motion planner should account for inevitable controller tracking error when generating avoidance trajectories. In this article we present a method for generating provably safe tracking error bounds, while reducing over-conservatism that exists in existing methods. We achieve this goal by restricting possible behaviors for the motion planner. We provide an algebraic method based on sum-of-squares programming to define restrictions on the motion planner and find small bounds on the tracking error. We demonstrate our method on two case studies and show how we can integrate the method into already developed motion planning techniques. Results suggest that our method can provide acceptable tracking error wherein previous work were not applicable.
Learning Scene Structure Guidance via Cross-Task Knowledge Transfer for Single Depth Super-Resolution
Mar 24, 2021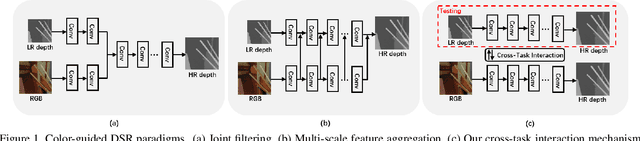
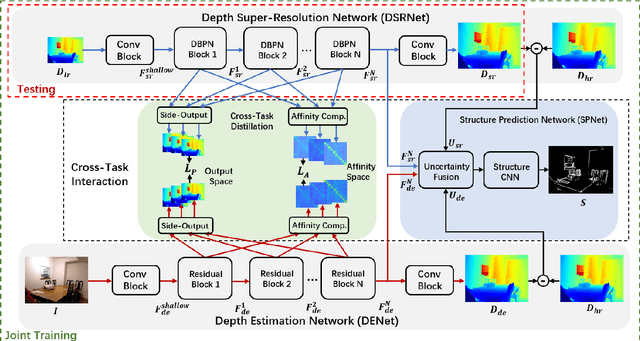
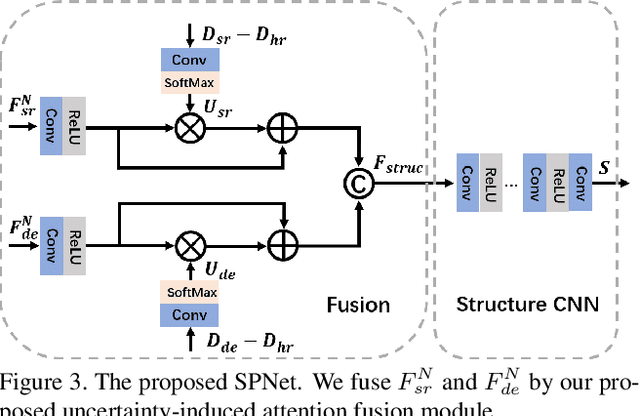

Existing color-guided depth super-resolution (DSR) approaches require paired RGB-D data as training samples where the RGB image is used as structural guidance to recover the degraded depth map due to their geometrical similarity. However, the paired data may be limited or expensive to be collected in actual testing environment. Therefore, we explore for the first time to learn the cross-modality knowledge at training stage, where both RGB and depth modalities are available, but test on the target dataset, where only single depth modality exists. Our key idea is to distill the knowledge of scene structural guidance from RGB modality to the single DSR task without changing its network architecture. Specifically, we construct an auxiliary depth estimation (DE) task that takes an RGB image as input to estimate a depth map, and train both DSR task and DE task collaboratively to boost the performance of DSR. Upon this, a cross-task interaction module is proposed to realize bilateral cross task knowledge transfer. First, we design a cross-task distillation scheme that encourages DSR and DE networks to learn from each other in a teacher-student role-exchanging fashion. Then, we advance a structure prediction (SP) task that provides extra structure regularization to help both DSR and DE networks learn more informative structure representations for depth recovery. Extensive experiments demonstrate that our scheme achieves superior performance in comparison with other DSR methods.
Contrastive Self-supervised Neural Architecture Search
Feb 21, 2021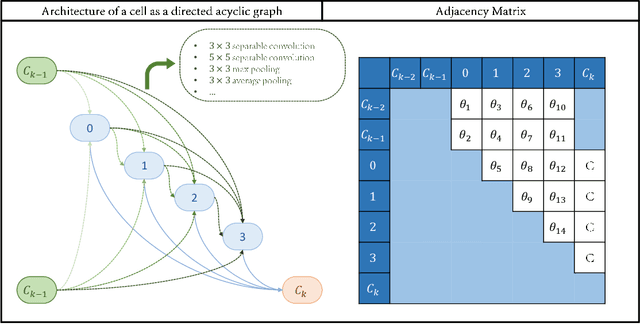
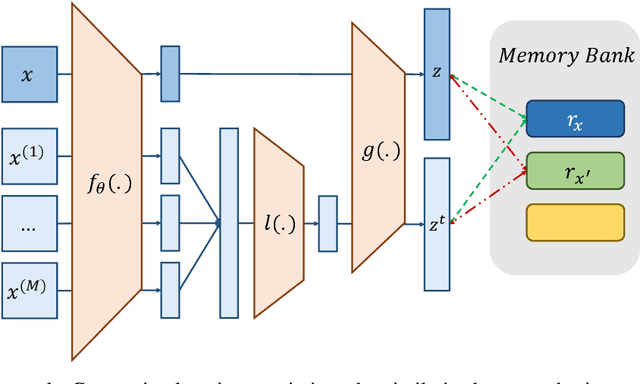
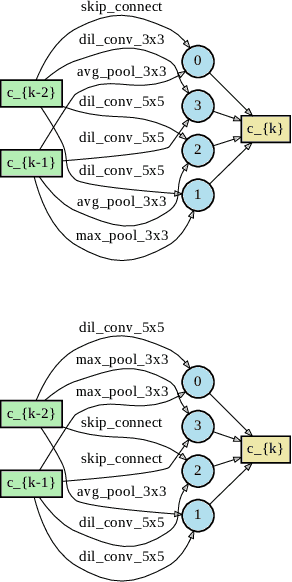
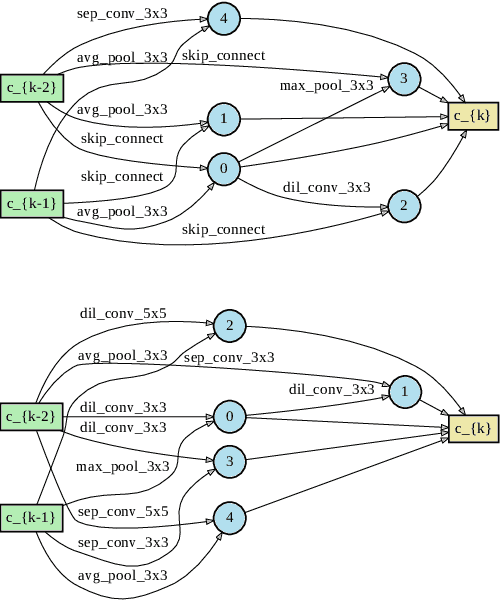
This paper proposes a novel cell-based neural architecture search algorithm (NAS), which completely alleviates the expensive costs of data labeling inherited from supervised learning. Our algorithm capitalizes on the effectiveness of self-supervised learning for image representations, which is an increasingly crucial topic of computer vision. First, using only a small amount of unlabeled train data under contrastive self-supervised learning allow us to search on a more extensive search space, discovering better neural architectures without surging the computational resources. Second, we entirely relieve the cost for labeled data (by contrastive loss) in the search stage without compromising architectures' final performance in the evaluation phase. Finally, we tackle the inherent discrete search space of the NAS problem by sequential model-based optimization via the tree-parzen estimator (SMBO-TPE), enabling us to reduce the computational expense response surface significantly. An extensive number of experiments empirically show that our search algorithm can achieve state-of-the-art results with better efficiency in data labeling cost, searching time, and accuracy in final validation.
Time Resource Networks
Feb 09, 2016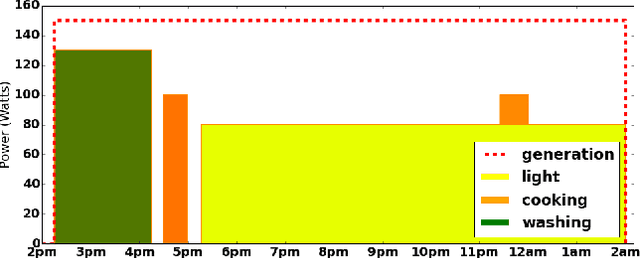
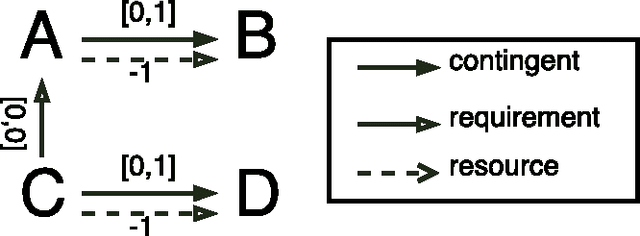
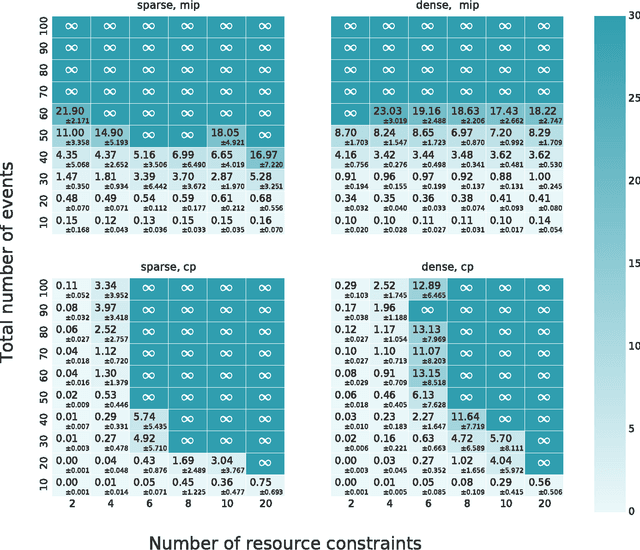
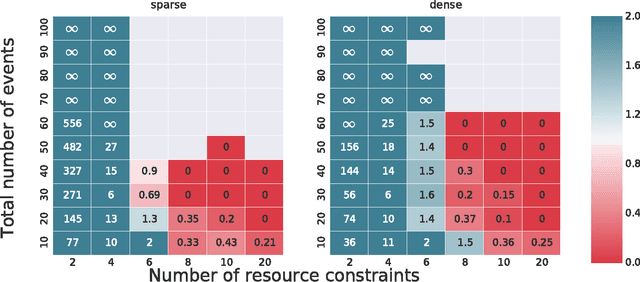
The problem of scheduling under resource constraints is widely applicable. One prominent example is power management, in which we have a limited continuous supply of power but must schedule a number of power-consuming tasks. Such problems feature tightly coupled continuous resource constraints and continuous temporal constraints. We address such problems by introducing the Time Resource Network (TRN), an encoding for resource-constrained scheduling problems. The definition allows temporal specifications using a general family of representations derived from the Simple Temporal network, including the Simple Temporal Network with Uncertainty, and the probabilistic Simple Temporal Network (Fang et al. (2014)). We propose two algorithms for determining the consistency of a TRN: one based on Mixed Integer Programing and the other one based on Constraint Programming, which we evaluate on scheduling problems with Simple Temporal Constraints and Probabilistic Temporal Constraints.
RSDD-Time: Temporal Annotation of Self-Reported Mental Health Diagnoses
Jun 20, 2018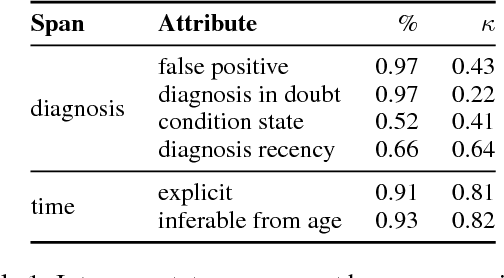
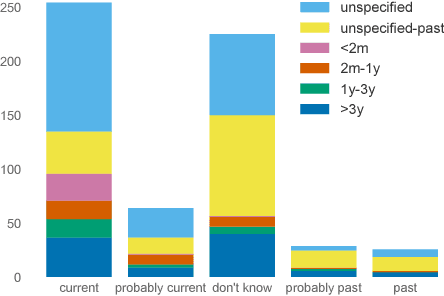

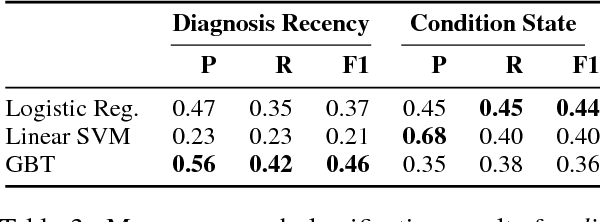
Self-reported diagnosis statements have been widely employed in studying language related to mental health in social media. However, existing research has largely ignored the temporality of mental health diagnoses. In this work, we introduce RSDD-Time: a new dataset of 598 manually annotated self-reported depression diagnosis posts from Reddit that include temporal information about the diagnosis. Annotations include whether a mental health condition is present and how recently the diagnosis happened. Furthermore, we include exact temporal spans that relate to the date of diagnosis. This information is valuable for various computational methods to examine mental health through social media because one's mental health state is not static. We also test several baseline classification and extraction approaches, which suggest that extracting temporal information from self-reported diagnosis statements is challenging.
Efficient 3D Point Cloud Feature Learning for Large-Scale Place Recognition
Jan 07, 2021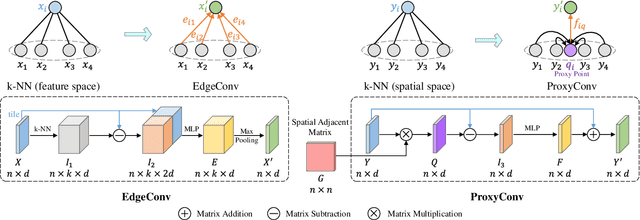
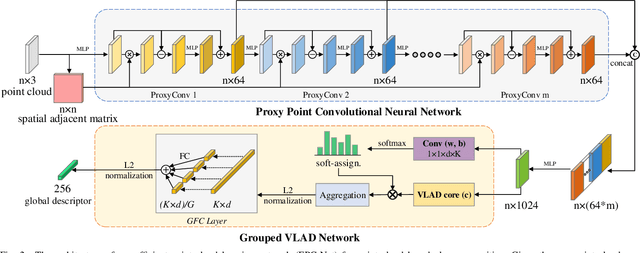
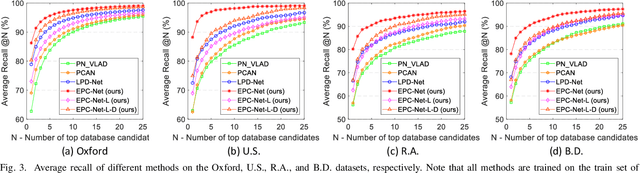
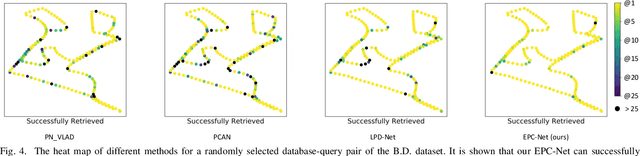
Point cloud based retrieval for place recognition is still a challenging problem due to drastic appearance and illumination changes of scenes in changing environments. Existing deep learning based global descriptors for the retrieval task usually consume a large amount of computation resources (e.g., memory), which may not be suitable for the cases of limited hardware resources. In this paper, we develop an efficient point cloud learning network (EPC-Net) to form a global descriptor for visual place recognition, which can obtain good performance and reduce computation memory and inference time. First, we propose a lightweight but effective neural network module, called ProxyConv, to aggregate the local geometric features of point clouds. We leverage the spatial adjacent matrix and proxy points to simplify the original edge convolution for lower memory consumption. Then, we design a lightweight grouped VLAD network (G-VLAD) to form global descriptors for retrieval. Compared with the original VLAD network, we propose a grouped fully connected (GFC) layer to decompose the high-dimensional vectors into a group of low-dimensional vectors, which can reduce the number of parameters of the network and maintain the discrimination of the feature vector. Finally, to further reduce the inference time, we develop a simple version of EPC-Net, called EPC-Net-L, which consists of two ProxyConv modules and one max pooling layer to aggregate global descriptors. By distilling the knowledge from EPC-Net, EPC-Net-L can obtain discriminative global descriptors for retrieval. Extensive experiments on the Oxford dataset and three in-house datasets demonstrate that our proposed method can achieve state-of-the-art performance with lower parameters, FLOPs, and runtime per frame.
Exploiting multi-temporal information for improved speckle reduction of Sentinel-1 SAR images by deep learning
Feb 01, 2021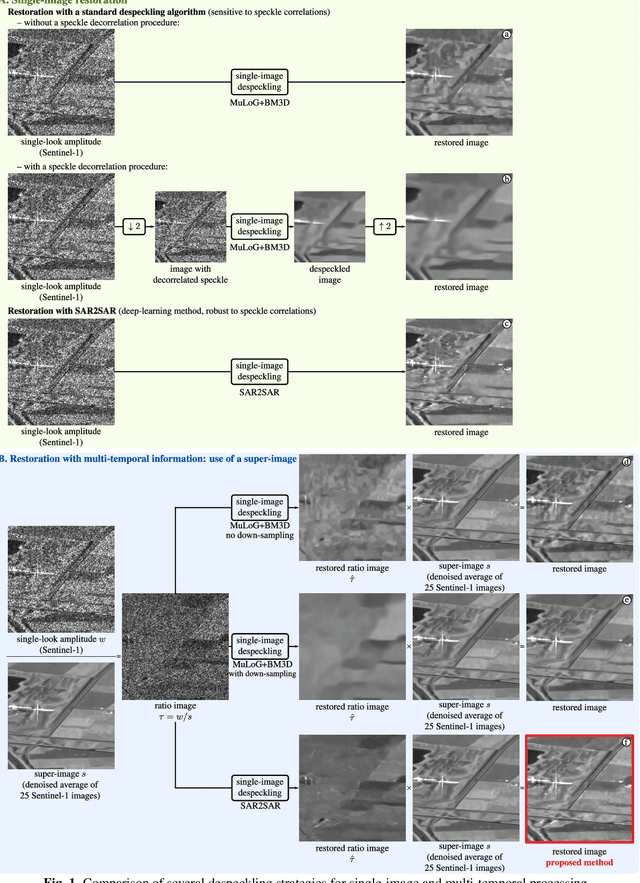
Deep learning approaches show unprecedented results for speckle reduction in SAR amplitude images. The wide availability of multi-temporal stacks of SAR images can improve even further the quality of denoising. In this paper, we propose a flexible yet efficient way to integrate temporal information into a deep neural network for speckle suppression. Archives provide access to long time-series of SAR images, from which multi-temporal averages can be computed with virtually no remaining speckle fluctuations. The proposed method combines this multi-temporal average and the image at a given date in the form of a ratio image and uses a state-of-the-art neural network to remove the speckle in this ratio image. This simple strategy is shown to offer a noticeable improvement compared to filtering the original image without knowledge of the multi-temporal average.