 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A new approach for physiological time series
Apr 23, 2015
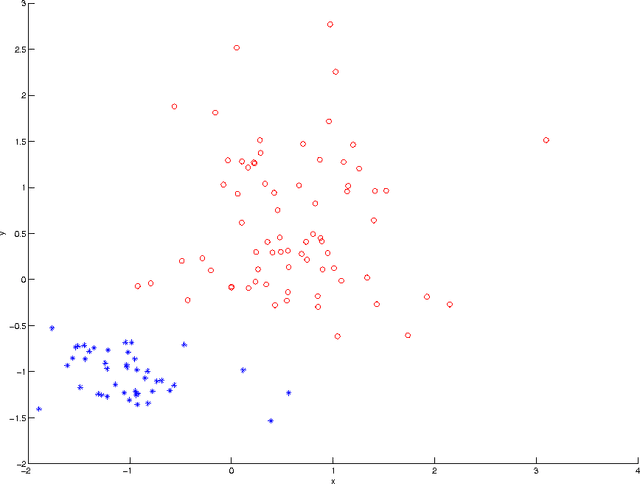
We developed a new approach for the analysis of physiological time series. An iterative convolution filter is used to decompose the time series into various components. Statistics of these components are extracted as features to characterize the mechanisms underlying the time series. Motivated by the studies that show many normal physiological systems involve irregularity while the decrease of irregularity usually implies the abnormality, the statistics for "outliers" in the components are used as features measuring irregularity. Support vector machines are used to select the most relevant features that are able to differentiate the time series from normal and abnormal systems. This new approach is successfully used in the study of congestive heart failure by heart beat interval time series.
Sub-GMN: The Subgraph Matching Network Model
Apr 02, 2021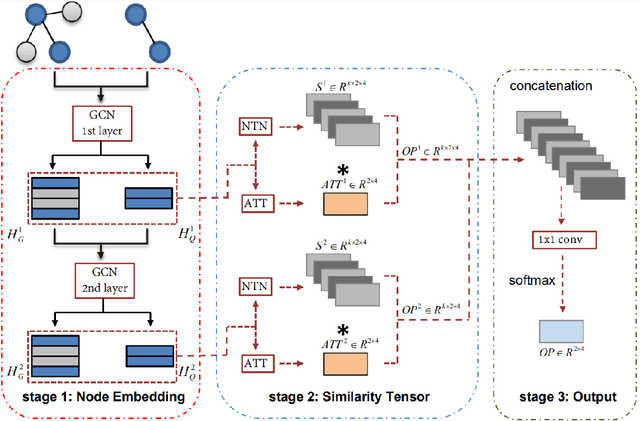


As one of the most fundamental tasks in graph theory, subgraph matching is a crucial task in many fields, ranging from information retrieval, computer vision, biology, chemistry and natural language processing. Yet subgraph matching problem remains to be an NP-complete problem. This study proposes an end-to-end learning-based approximate method for subgraph matching task, called subgraph matching network (Sub-GMN). The proposed Sub-GMN firstly uses graph representation learning to map nodes to node-level embedding. It then combines metric learning and attention mechanisms to model the relationship between matched nodes in the data graph and query graph. To test the performance of the proposed method, we applied our method on two databases. We used two existing methods, GNN and FGNN as baseline for comparison. Our experiment shows that, on dataset 1, on average the accuracy of Sub-GMN are 12.21\% and 3.2\% higher than that of GNN and FGNN respectively. On average running time Sub-GMN runs 20-40 times faster than FGNN. In addition, the average F1-score of Sub-GMN on all experiments with dataset 2 reached 0.95, which demonstrates that Sub-GMN outputs more correct node-to-node matches. Comparing with the previous GNNs-based methods for subgraph matching task, our proposed Sub-GMN allows varying query and data graphes in the test/application stage, while most previous GNNs-based methods can only find a matched subgraph in the data graph during the test/application for the same query graph used in the training stage. Another advantage of our proposed Sub-GMN is that it can output a list of node-to-node matches, while most existing end-to-end GNNs based methods cannot provide the matched node pairs.
CovidGAN: Data Augmentation Using Auxiliary Classifier GAN for Improved Covid-19 Detection
Mar 08, 2021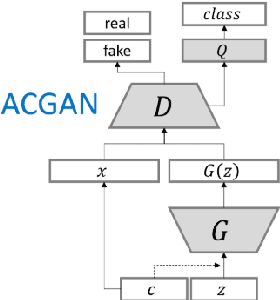
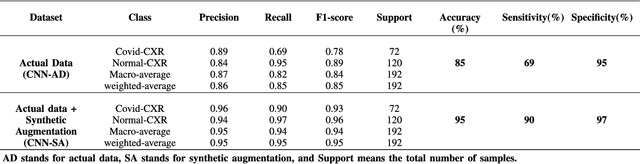
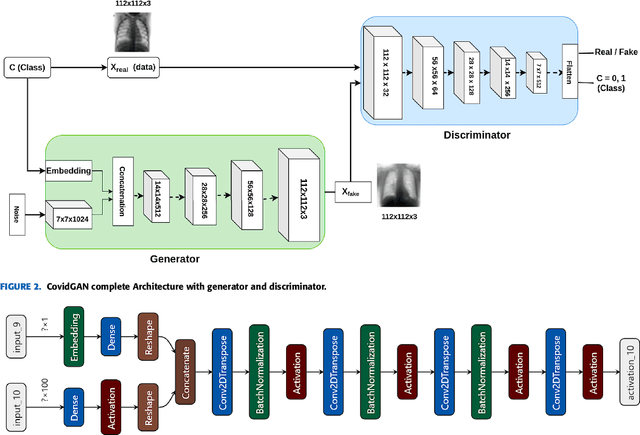
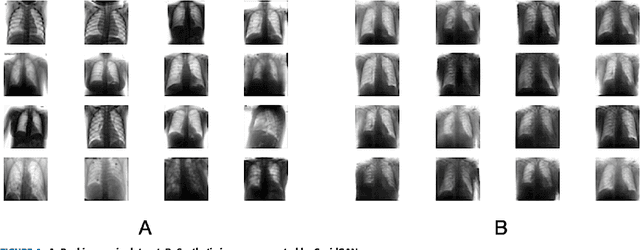
Coronavirus (COVID-19) is a viral disease caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). The spread of COVID-19 seems to have a detrimental effect on the global economy and health. A positive chest X-ray of infected patients is a crucial step in the battle against COVID-19. Early results suggest that abnormalities exist in chest X-rays of patients suggestive of COVID-19. This has led to the introduction of a variety of deep learning systems and studies have shown that the accuracy of COVID-19 patient detection through the use of chest X-rays is strongly optimistic. Deep learning networks like convolutional neural networks (CNNs) need a substantial amount of training data. Because the outbreak is recent, it is difficult to gather a significant number of radiographic images in such a short time. Therefore, in this research, we present a method to generate synthetic chest X-ray (CXR) images by developing an Auxiliary Classifier Generative Adversarial Network (ACGAN) based model called CovidGAN. In addition, we demonstrate that the synthetic images produced from CovidGAN can be utilized to enhance the performance of CNN for COVID-19 detection. Classification using CNN alone yielded 85% accuracy. By adding synthetic images produced by CovidGAN, the accuracy increased to 95%. We hope this method will speed up COVID-19 detection and lead to more robust systems of radiology.
* Accepted at IEEE Access. Received April 30, 2020, accepted May 11, 2020, date of publication May 14, 2020, date of current version May 28, 2020
Scalable Scene Flow from Point Clouds in the Real World
Mar 15, 2021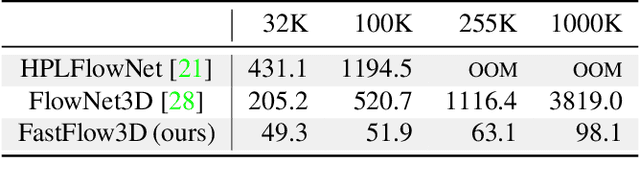
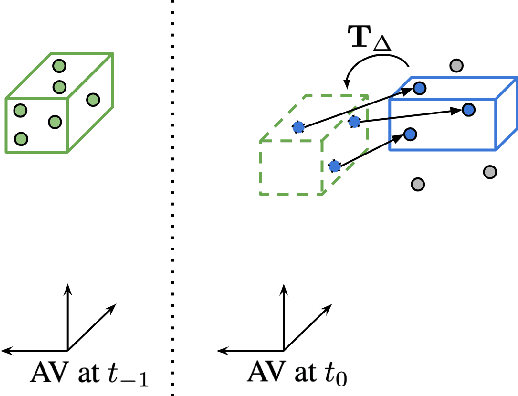
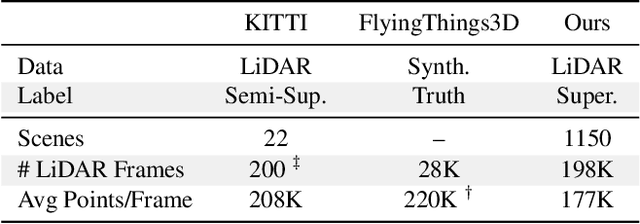
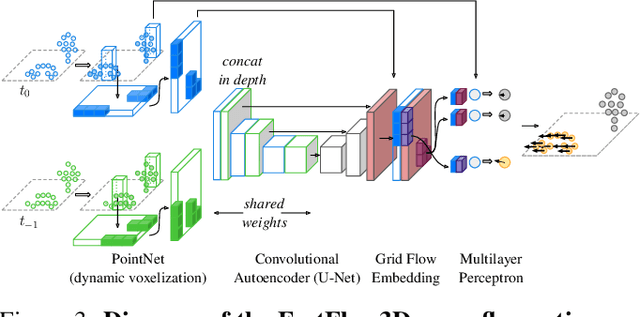
Autonomous vehicles operate in highly dynamic environments necessitating an accurate assessment of which aspects of a scene are moving and where they are moving to. A popular approach to 3D motion estimation -- termed scene flow -- is to employ 3D point cloud data from consecutive LiDAR scans, although such approaches have been limited by the small size of real-world, annotated LiDAR data. In this work, we introduce a new large scale benchmark for scene flow based on the Waymo Open Dataset. The dataset is $\sim$1,000$\times$ larger than previous real-world datasets in terms of the number of annotated frames and is derived from the corresponding tracked 3D objects. We demonstrate how previous works were bounded based on the amount of real LiDAR data available, suggesting that larger datasets are required to achieve state-of-the-art predictive performance. Furthermore, we show how previous heuristics for operating on point clouds such as artificial down-sampling heavily degrade performance, motivating a new class of models that are tractable on the full point cloud. To address this issue, we introduce the model architecture FastFlow3D that provides real time inference on the full point cloud. Finally, we demonstrate that this problem is amenable to techniques from semi-supervised learning by highlighting open problems for generalizing methods for predicting motion on unlabeled objects. We hope that this dataset may provide new opportunities for developing real world scene flow systems and motivate a new class of machine learning problems.
Uncertainty-Aware Deep Learning for Autonomous Safe Landing Site Selection
Feb 21, 2021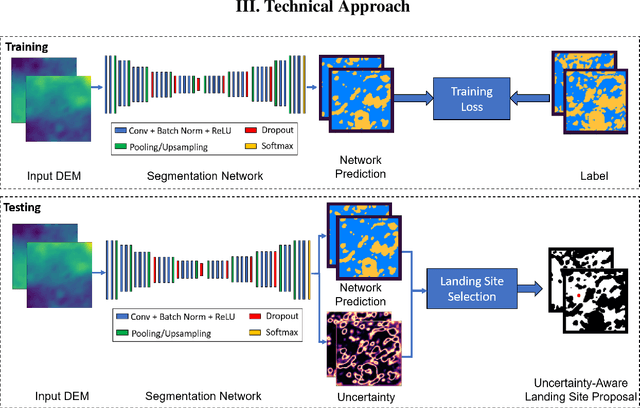
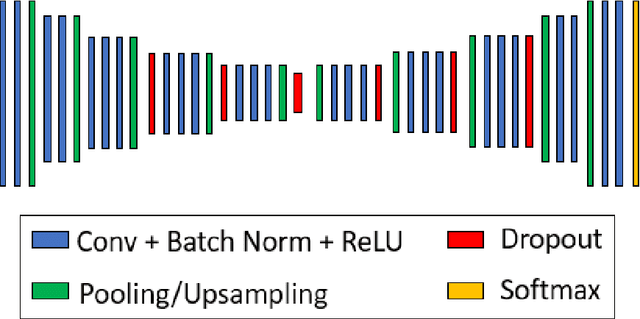
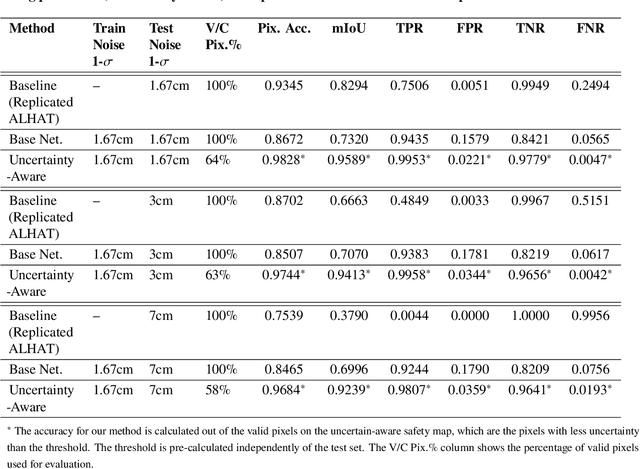
Hazard detection is critical for enabling autonomous landing on planetary surfaces. Current state-of-the-art methods leverage traditional computer vision approaches to automate identification of safe terrain from input digital elevation models (DEMs). However, performance for these methods can degrade for input DEMs with increased sensor noise. At the same time, deep learning techniques have been developed for various applications. Nevertheless, their applicability to safety-critical space missions has been often limited due to concerns regarding their outputs' reliability. In response to this background, this paper proposes an uncertainty-aware learning-based method for hazard detection and landing site selection. The developed approach enables reliable safe landing site selection by: (i) generating a safety prediction map and its uncertainty map together via Bayesian deep learning and semantic segmentation; and (ii) using the generated uncertainty map to filter out the uncertain pixels in the prediction map so that the safe landing site selection is performed only based on the certain pixels (i.e., pixels for which the model is certain about its safety prediction). Experiments are presented with simulated data based on a Mars HiRISE digital terrain model and varying noise levels to demonstrate the performance of the proposed approach.
FaceVR: Real-Time Facial Reenactment and Eye Gaze Control in Virtual Reality
Mar 21, 2018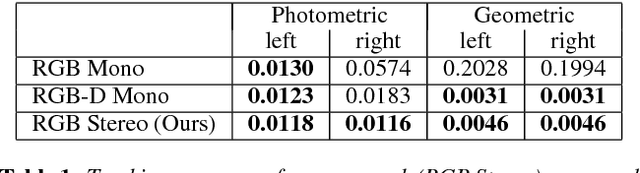

We propose FaceVR, a novel image-based method that enables video teleconferencing in VR based on self-reenactment. State-of-the-art face tracking methods in the VR context are focused on the animation of rigged 3d avatars. While they achieve good tracking performance the results look cartoonish and not real. In contrast to these model-based approaches, FaceVR enables VR teleconferencing using an image-based technique that results in nearly photo-realistic outputs. The key component of FaceVR is a robust algorithm to perform real-time facial motion capture of an actor who is wearing a head-mounted display (HMD), as well as a new data-driven approach for eye tracking from monocular videos. Based on reenactment of a prerecorded stereo video of the person without the HMD, FaceVR incorporates photo-realistic re-rendering in real time, thus allowing artificial modifications of face and eye appearances. For instance, we can alter facial expressions or change gaze directions in the prerecorded target video. In a live setup, we apply these newly-introduced algorithmic components.
Policy-Guided Heuristic Search with Guarantees
Mar 21, 2021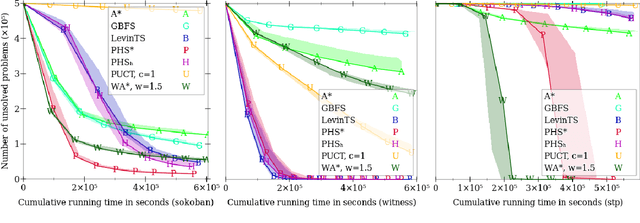
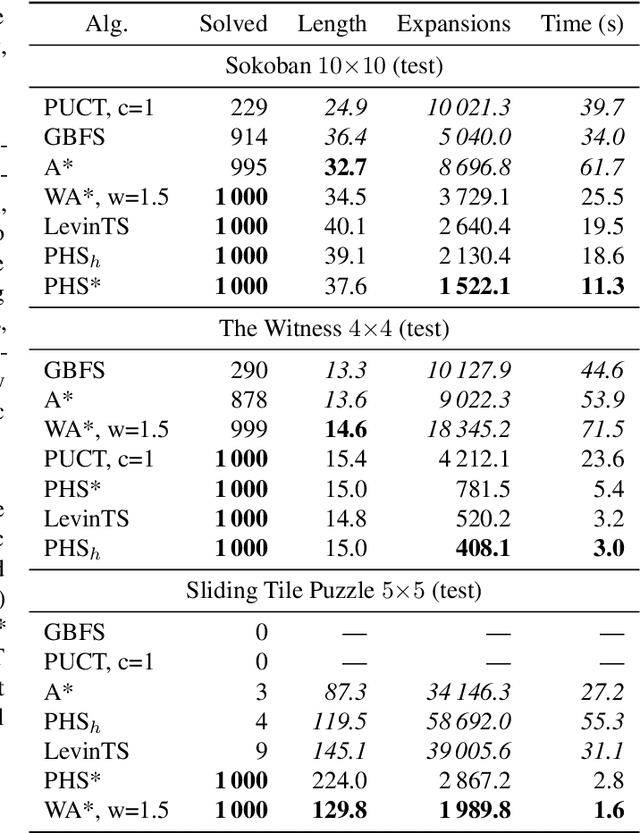


The use of a policy and a heuristic function for guiding search can be quite effective in adversarial problems, as demonstrated by AlphaGo and its successors, which are based on the PUCT search algorithm. While PUCT can also be used to solve single-agent deterministic problems, it lacks guarantees on its search effort and it can be computationally inefficient in practice. Combining the A* algorithm with a learned heuristic function tends to work better in these domains, but A* and its variants do not use a policy. Moreover, the purpose of using A* is to find solutions of minimum cost, while we seek instead to minimize the search loss (e.g., the number of search steps). LevinTS is guided by a policy and provides guarantees on the number of search steps that relate to the quality of the policy, but it does not make use of a heuristic function. In this work we introduce Policy-guided Heuristic Search (PHS), a novel search algorithm that uses both a heuristic function and a policy and has theoretical guarantees on the search loss that relates to both the quality of the heuristic and of the policy. We show empirically on the sliding-tile puzzle, Sokoban, and a puzzle from the commercial game `The Witness' that PHS enables the rapid learning of both a policy and a heuristic function and compares favorably with A*, Weighted A*, Greedy Best-First Search, LevinTS, and PUCT in terms of number of problems solved and search time in all three domains tested.
Beyond ANN: Exploiting Structural Knowledge for Efficient Place Recognition
Mar 15, 2021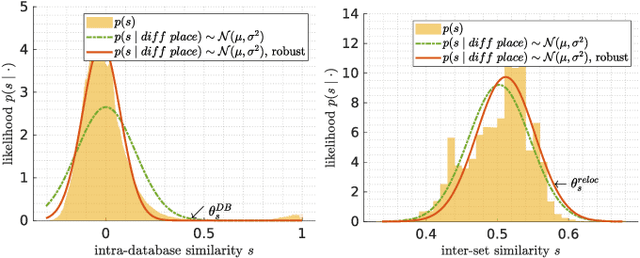
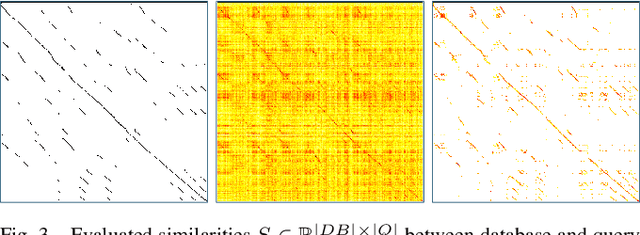
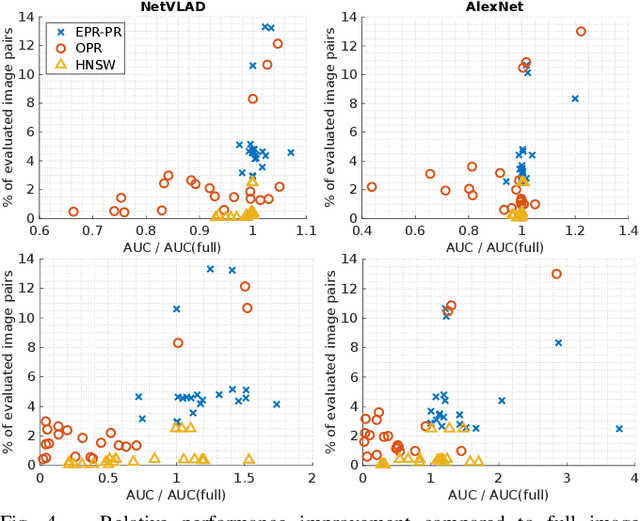
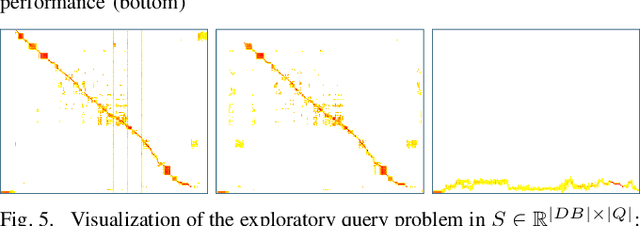
Visual place recognition is the task of recognizing same places of query images in a set of database images, despite potential condition changes due to time of day, weather or seasons. It is important for loop closure detection in SLAM and candidate selection for global localization. Many approaches in the literature perform computationally inefficient full image comparisons between queries and all database images. There is still a lack of suited methods for efficient place recognition that allow a fast, sparse comparison of only the most promising image pairs without any loss in performance. While this is partially given by ANN-based methods, they trade speed for precision and additional memory consumption, and many cannot find arbitrary numbers of matching database images in case of loops in the database. In this paper, we propose a novel fast sequence-based method for efficient place recognition that can be applied online. It uses relocalization to recover from sequence losses, and exploits usually available but often unused intra-database similarities for a potential detection of all matching database images for each query in case of loops or stops in the database. We performed extensive experimental evaluations over five datasets and 21 sequence combinations, and show that our method outperforms two state-of-the-art approaches and even full image comparisons in many cases, while providing a good tradeoff between performance and percentage of evaluated image pairs. Source code for Matlab will be provided with publication of this paper.
Some open questions on morphological operators and representations in the deep learning era
May 05, 2021During recent years, the renaissance of neural networks as the major machine learning paradigm and more specifically, the confirmation that deep learning techniques provide state-of-the-art results for most of computer vision tasks has been shaking up traditional research in image processing. The same can be said for research in communities working on applied harmonic analysis, information geometry, variational methods, etc. For many researchers, this is viewed as an existential threat. On the one hand, research funding agencies privilege mainstream approaches especially when these are unquestionably suitable for solving real problems and for making progress on artificial intelligence. On the other hand, successful publishing of research in our communities is becoming almost exclusively based on a quantitative improvement of the accuracy of any benchmark task. As most of my colleagues sharing this research field, I am confronted with the dilemma of continuing to invest my time and intellectual effort on mathematical morphology as my driving force for research, or simply focussing on how to use deep learning and contributing to it. The solution is not obvious to any of us since our research is not fundamental, it is just oriented to solve challenging problems, which can be more or less theoretical. Certainly, it would be foolish for anyone to claim that deep learning is insignificant or to think that one's favourite image processing domain is productive enough to ignore the state-of-the-art. I fully understand that the labs and leading people in image processing communities have been shifting their research to almost exclusively focus on deep learning techniques. My own position is different: I do think there is room for progress on mathematically grounded image processing branches, under the condition that these are rethought in a broader sense from the deep learning paradigm. Indeed, I firmly believe that the convergence between mathematical morphology and the computation methods which gravitate around deep learning (fully connected networks, convolutional neural networks, residual neural networks, recurrent neural networks, etc.) is worthwhile. The goal of this talk is to discuss my personal vision regarding these potential interactions. Without any pretension of being exhaustive, I want to address it with a series of open questions, covering a wide range of specificities of morphological operators and representations, which could be tackled and revisited under the paradigm of deep learning. An expected benefit of such convergence between morphology and deep learning is a cross-fertilization of concepts and techniques between both fields. In addition, I think the future answer to some of these questions can provide some insight on understanding, interpreting and simplifying deep learning networks.
Morphognosis: the shape of knowledge in space and time
Mar 04, 2017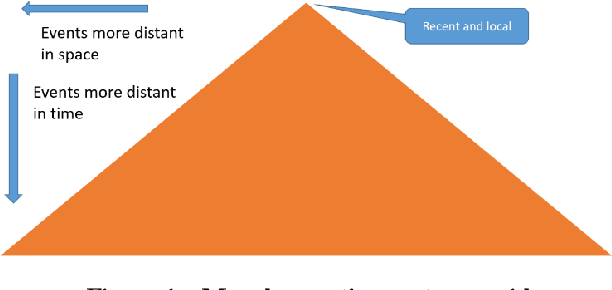
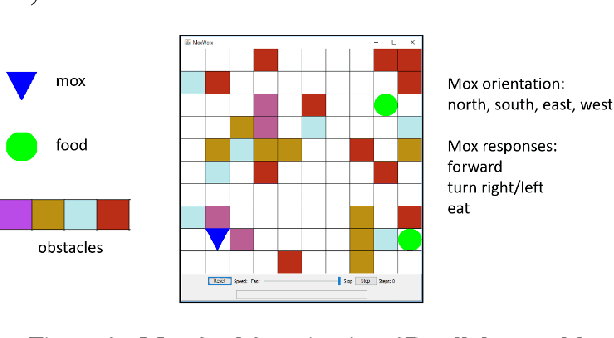
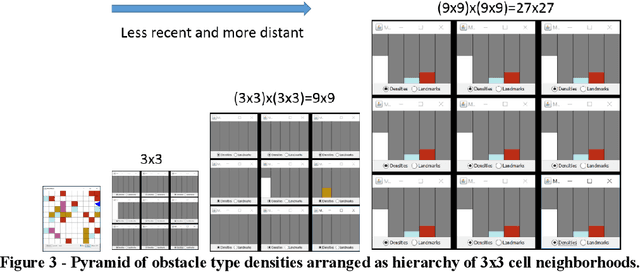
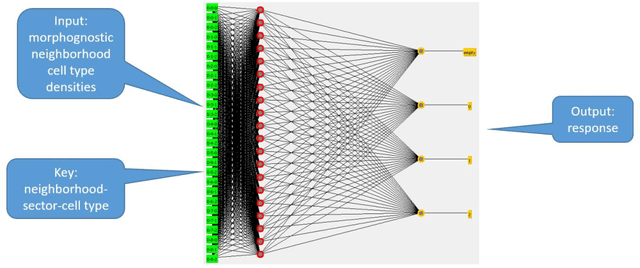
Artificial intelligence research to a great degree focuses on the brain and behaviors that the brain generates. But the brain, an extremely complex structure resulting from millions of years of evolution, can be viewed as a solution to problems posed by an environment existing in space and time. The environment generates signals that produce sensory events within an organism. Building an internal spatial and temporal model of the environment allows an organism to navigate and manipulate the environment. Higher intelligence might be the ability to process information coming from a larger extent of space-time. In keeping with nature's penchant for extending rather than replacing, the purpose of the mammalian neocortex might then be to record events from distant reaches of space and time and render them, as though yet near and present, to the older, deeper brain whose instinctual roles have changed little over eons. Here this notion is embodied in a model called morphognosis (morpho = shape and gnosis = knowledge). Its basic structure is a pyramid of event recordings called a morphognostic. At the apex of the pyramid are the most recent and nearby events. Receding from the apex are less recent and possibly more distant events. A morphognostic can thus be viewed as a structure of progressively larger chunks of space-time knowledge. A set of morphognostics forms long-term memories that are learned by exposure to the environment. A cellular automaton is used as the platform to investigate the morphognosis model, using a simulated organism that learns to forage in its world for food, build a nest, and play the game of Pong.