 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Comparative Study of High-Recall Real-Time Semantic Segmentation Based on Swift Factorized Network
Jul 26, 2019
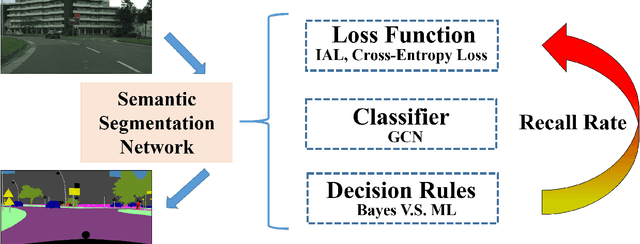
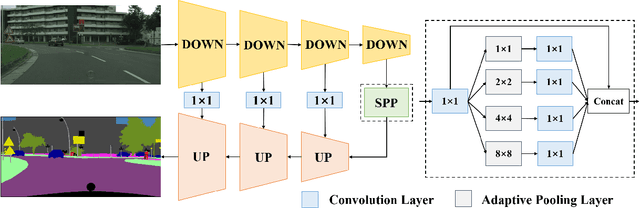
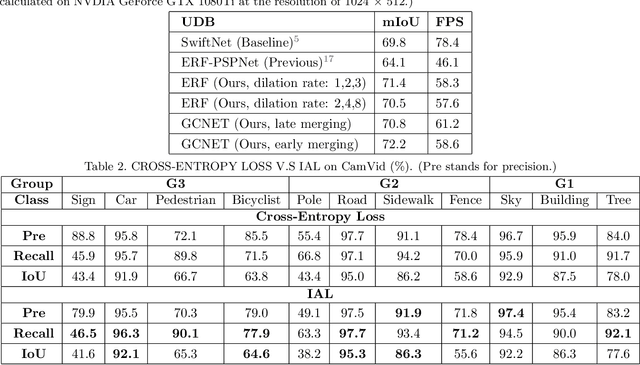
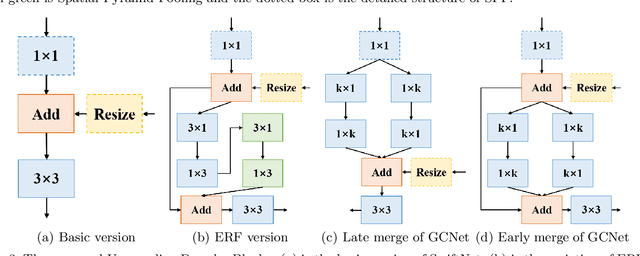
Semantic Segmentation (SS) is the task to assign a semantic label to each pixel of the observed images, which is of crucial significance for autonomous vehicles, navigation assistance systems for the visually impaired, and augmented reality devices. However, there is still a long way for SS to be put into practice as there are two essential challenges that need to be addressed: efficiency and evaluation criterions for practical application. For specific application scenarios, different criterions need to be adopted. Recall rate is an important criterion for many tasks like autonomous vehicles. For autonomous vehicles, we need to focus on the detection of the traffic objects like cars, buses, and pedestrians, which should be detected with high recall rates. In other words, it is preferable to detect it wrongly than miss it, because the other traffic objects will be dangerous if the algorithm miss them and segment them as safe roadways. In this paper, our main goal is to explore possible methods to attain high recall rate. Firstly, we propose a real-time SS network named Swift Factorized Network (SFN). The proposed network is adapted from SwiftNet, whose structure is a typical U-shape structure with lateral connections. Inspired by ERFNet and Global convolution Networks (GCNet), we propose two different blocks to enlarge valid receptive field. They do not take up too much calculation resources, but significantly enhance the performance compared with the baseline network. Secondly, we explore three ways to achieve higher recall rate, i.e. loss function, classifier and decision rules. We perform a comprehensive set of experiments on state-of-the-art datasets including CamVid and Cityscapes. We demonstrate that our SS convolutional neural networks reach excellent performance. Furthermore, we make a detailed analysis and comparison of the three proposed methods on the promotion of recall rate.
Sub-GMN: The Subgraph Matching Network Model
Apr 02, 2021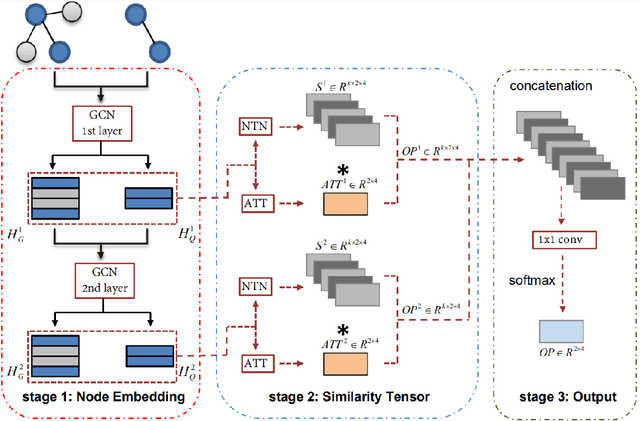


As one of the most fundamental tasks in graph theory, subgraph matching is a crucial task in many fields, ranging from information retrieval, computer vision, biology, chemistry and natural language processing. Yet subgraph matching problem remains to be an NP-complete problem. This study proposes an end-to-end learning-based approximate method for subgraph matching task, called subgraph matching network (Sub-GMN). The proposed Sub-GMN firstly uses graph representation learning to map nodes to node-level embedding. It then combines metric learning and attention mechanisms to model the relationship between matched nodes in the data graph and query graph. To test the performance of the proposed method, we applied our method on two databases. We used two existing methods, GNN and FGNN as baseline for comparison. Our experiment shows that, on dataset 1, on average the accuracy of Sub-GMN are 12.21\% and 3.2\% higher than that of GNN and FGNN respectively. On average running time Sub-GMN runs 20-40 times faster than FGNN. In addition, the average F1-score of Sub-GMN on all experiments with dataset 2 reached 0.95, which demonstrates that Sub-GMN outputs more correct node-to-node matches. Comparing with the previous GNNs-based methods for subgraph matching task, our proposed Sub-GMN allows varying query and data graphes in the test/application stage, while most previous GNNs-based methods can only find a matched subgraph in the data graph during the test/application for the same query graph used in the training stage. Another advantage of our proposed Sub-GMN is that it can output a list of node-to-node matches, while most existing end-to-end GNNs based methods cannot provide the matched node pairs.
HOT-VAE: Learning High-Order Label Correlation for Multi-Label Classification via Attention-Based Variational Autoencoders
Mar 09, 2021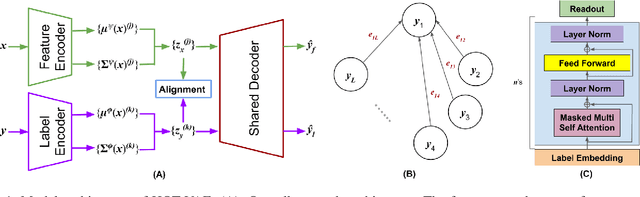
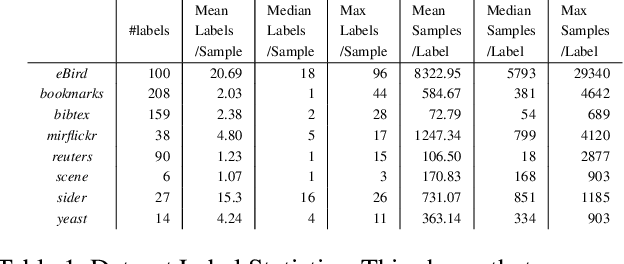
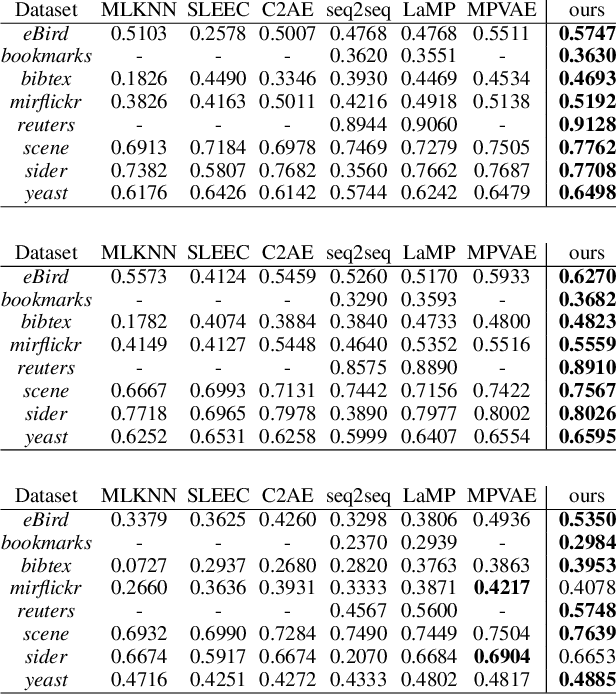
Understanding how environmental characteristics affect bio-diversity patterns, from individual species to communities of species, is critical for mitigating effects of global change. A central goal for conservation planning and monitoring is the ability to accurately predict the occurrence of species communities and how these communities change over space and time. This in turn leads to a challenging and long-standing problem in the field of computer science - how to perform ac-curate multi-label classification with hundreds of labels? The key challenge of this problem is its exponential-sized output space with regards to the number of labels to be predicted.Therefore, it is essential to facilitate the learning process by exploiting correlations (or dependency) among labels. Previous methods mostly focus on modelling the correlation on label pairs; however, complex relations between real-world objects often go beyond second order. In this paper, we pro-pose a novel framework for multi-label classification, High-order Tie-in Variational Autoencoder (HOT-VAE), which per-forms adaptive high-order label correlation learning. We experimentally verify that our model outperforms the existing state-of-the-art approaches on a bird distribution dataset on both conventional F1 scores and a variety of ecological metrics. To show our method is general, we also perform empirical analysis on seven other public real-world datasets in several application domains, and Hot-VAE exhibits superior performance to previous methods.
Universal Undersampled MRI Reconstruction
Mar 09, 2021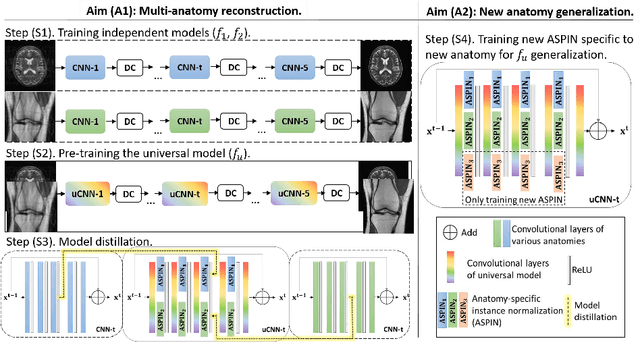
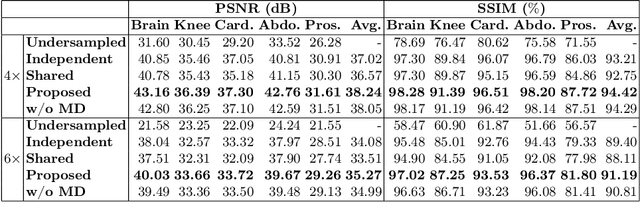

Deep neural networks have been extensively studied for undersampled MRI reconstruction. While achieving state-of-the-art performance, they are trained and deployed specifically for one anatomy with limited generalization ability to another anatomy. Rather than building multiple models, a universal model that reconstructs images across different anatomies is highly desirable for efficient deployment and better generalization. Simply mixing images from multiple anatomies for training a single network does not lead to an ideal universal model due to the statistical shift among datasets of various anatomies, the need to retrain from scratch on all datasets with the addition of a new dataset, and the difficulty in dealing with imbalanced sampling when the new dataset is further of a smaller size. In this paper, for the first time, we propose a framework to learn a universal deep neural network for undersampled MRI reconstruction. Specifically, anatomy-specific instance normalization is proposed to compensate for statistical shift and allow easy generalization to new datasets. Moreover, the universal model is trained by distilling knowledge from available independent models to further exploit representations across anatomies. Experimental results show the proposed universal model can reconstruct both brain and knee images with high image quality. Also, it is easy to adapt the trained model to new datasets of smaller size, i.e., abdomen, cardiac and prostate, with little effort and superior performance.
Sensing Volume Coverage of Robot Workspace using On-Robot Time-of-Flight Sensor Arrays for Safe Human Robot Interaction
Jul 03, 2019
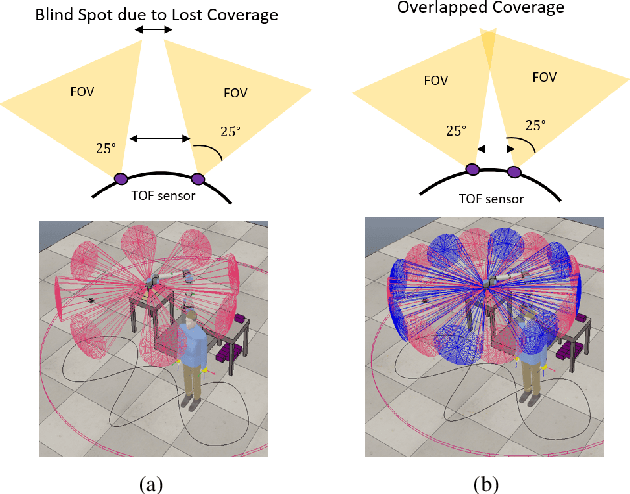
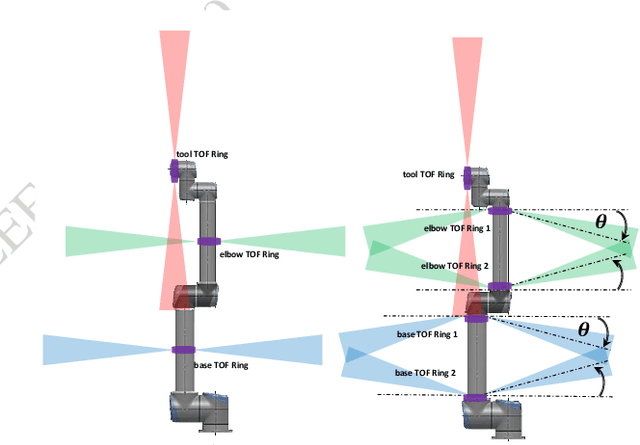

In this paper, an analysis of the sensing volume coverage of robot workspace as well as the shared human-robot collaborative workspace for various configurations of on-robot Time-of-Flight (ToF) sensor array rings is presented. A methodology for volumetry using octrees to quantify the detection/sensing volume of the sensors is proposed. The change in sensing volume coverage by increasing the number of sensors per ToF sensor array ring and also increasing the number of rings mounted on robot link is also studied. Considerations of maximum ideal volume around the robot workspace that a given ToF sensor array ring placement and orientation setup should cover for safe human robot interaction are presented. The sensing volume coverage measurements in this maximum ideal volume are tabulated and observations on various ToF configurations and their coverage for close and far zones of the robot are determined.
Video Sentiment Analysis with Bimodal Information-augmented Multi-Head Attention
Mar 09, 2021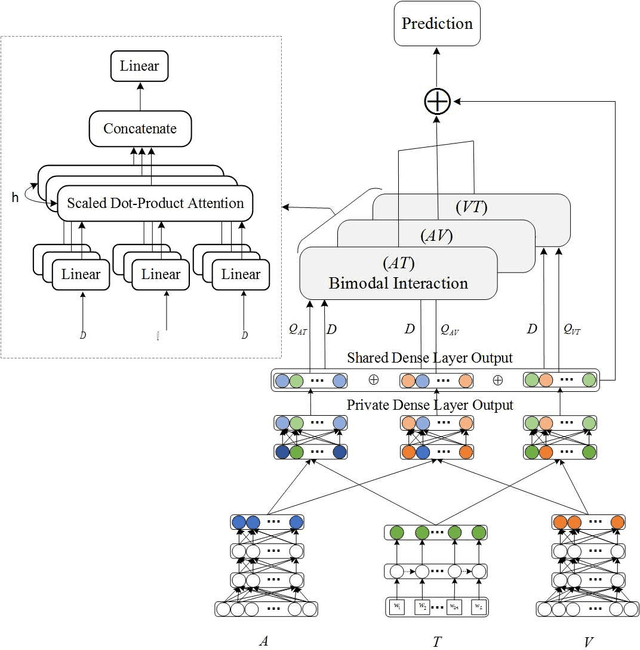
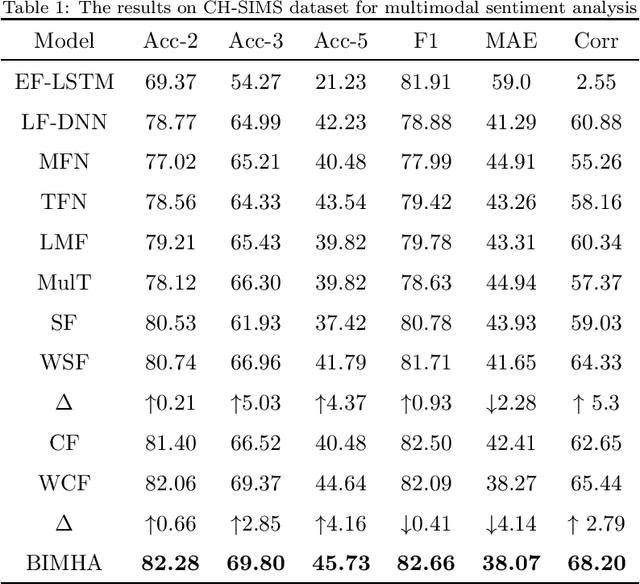
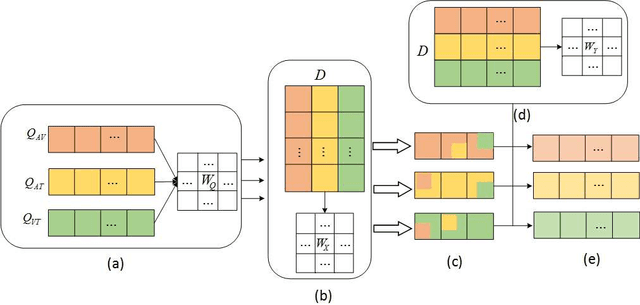
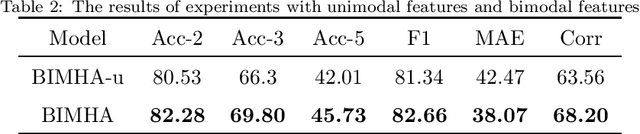
Sentiment analysis is the basis of intelligent human-computer interaction. As one of the frontier research directions of artificial intelligence, it can help computers better identify human intentions and emotional states so that provide more personalized services. However, as human present sentiments by spoken words, gestures, facial expressions and others which involve variable forms of data including text, audio, video, etc., it poses many challenges to this study. Due to the limitations of unimodal sentiment analysis, recent research has focused on the sentiment analysis of videos containing time series data of multiple modalities. When analyzing videos with multimodal data, the key problem is how to fuse these heterogeneous data. In consideration that the contribution of each modality is different, current fusion methods tend to extract the important information of single modality prior to fusion, which ignores the consistency and complementarity of bimodal interaction and has influences on the final decision. To solve this problem, a video sentiment analysis method using multi-head attention with bimodal information augmented is proposed. Based on bimodal interaction, more important bimodal features are assigned larger weights. In this way, different feature representations are adaptively assigned corresponding attention for effective multimodal fusion. Extensive experiments were conducted on both Chinese and English public datasets. The results show that our approach outperforms the existing methods and can give an insight into the contributions of bimodal interaction among three modalities.
Deep Bilateral Learning for Real-Time Image Enhancement
Aug 22, 2017
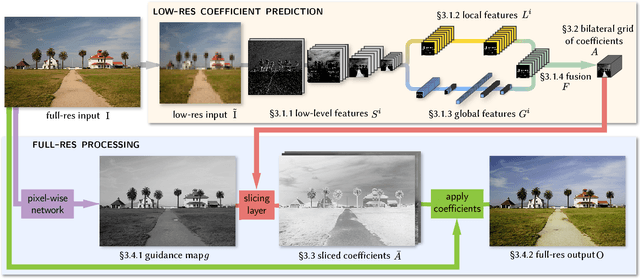
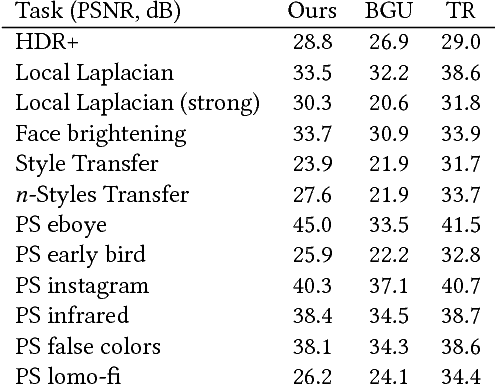

Performance is a critical challenge in mobile image processing. Given a reference imaging pipeline, or even human-adjusted pairs of images, we seek to reproduce the enhancements and enable real-time evaluation. For this, we introduce a new neural network architecture inspired by bilateral grid processing and local affine color transforms. Using pairs of input/output images, we train a convolutional neural network to predict the coefficients of a locally-affine model in bilateral space. Our architecture learns to make local, global, and content-dependent decisions to approximate the desired image transformation. At runtime, the neural network consumes a low-resolution version of the input image, produces a set of affine transformations in bilateral space, upsamples those transformations in an edge-preserving fashion using a new slicing node, and then applies those upsampled transformations to the full-resolution image. Our algorithm processes high-resolution images on a smartphone in milliseconds, provides a real-time viewfinder at 1080p resolution, and matches the quality of state-of-the-art approximation techniques on a large class of image operators. Unlike previous work, our model is trained off-line from data and therefore does not require access to the original operator at runtime. This allows our model to learn complex, scene-dependent transformations for which no reference implementation is available, such as the photographic edits of a human retoucher.
* 12 pages, 14 figures, Siggraph 2017
Posterior Meta-Replay for Continual Learning
Mar 01, 2021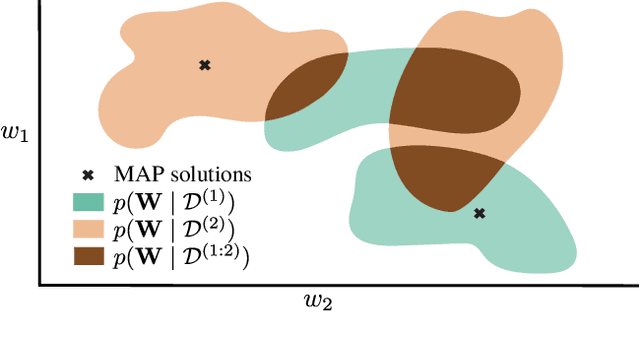
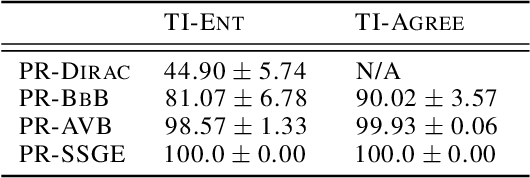
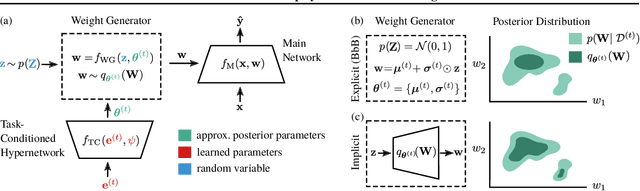
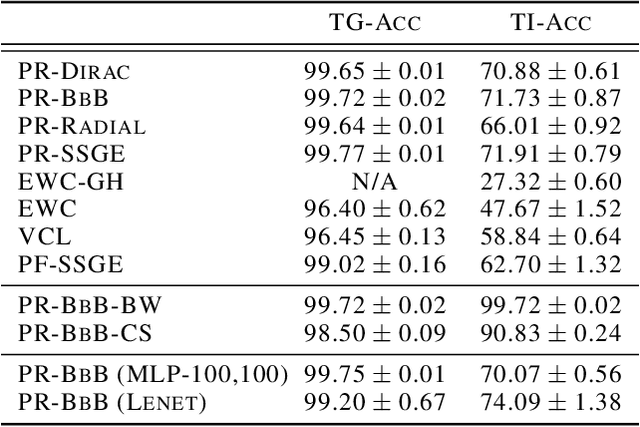
Continual Learning (CL) algorithms have recently received a lot of attention as they attempt to overcome the need to train with an i.i.d. sample from some unknown target data distribution. Building on prior work, we study principled ways to tackle the CL problem by adopting a Bayesian perspective and focus on continually learning a task-specific posterior distribution via a shared meta-model, a task-conditioned hypernetwork. This approach, which we term Posterior-replay CL, is in sharp contrast to most Bayesian CL approaches that focus on the recursive update of a single posterior distribution. The benefits of our approach are (1) an increased flexibility to model solutions in weight space and therewith less susceptibility to task dissimilarity, (2) access to principled task-specific predictive uncertainty estimates, that can be used to infer task identity during test time and to detect task boundaries during training, and (3) the ability to revisit and update task-specific posteriors in a principled manner without requiring access to past data. The proposed framework is versatile, which we demonstrate using simple posterior approximations (such as Gaussians) as well as powerful, implicit distributions modelled via a neural network. We illustrate the conceptual advance of our framework on low-dimensional problems and show performance gains on computer vision benchmarks.
A Lane-Changing Prediction Method Based on Temporal Convolution Network
Nov 01, 2020
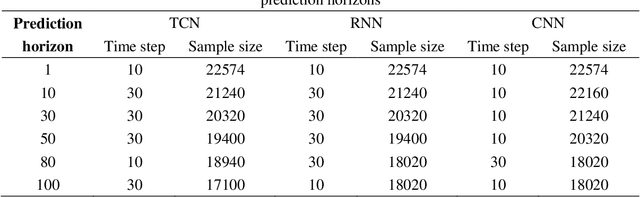
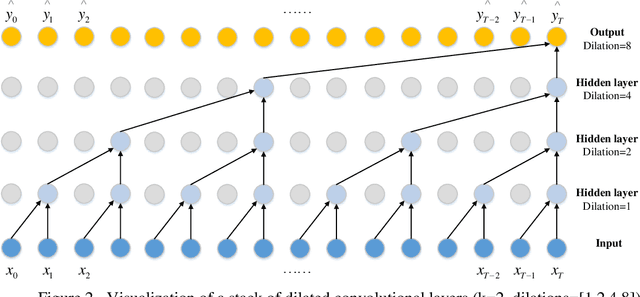
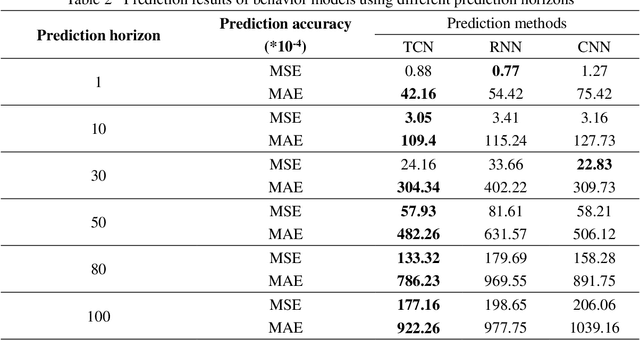
Lane-changing is an important driving behavior and unreasonable lane changes can result in potentially dangerous traffic collisions. Advanced Driver Assistance System (ADAS) can assist drivers to change lanes safely and efficiently. To capture the stochastic time series of lane-changing behavior, this study proposes a temporal convolutional network (TCN) to predict the long-term lane-changing trajectory and behavior. In addition, the convolutional neural network (CNN) and recurrent neural network (RNN) methods are considered as the benchmark models to demonstrate the learning ability of the TCN. The lane-changing dataset was collected by the driving simulator. The prediction performance of TCN is demonstrated from three aspects: different input variables, different input dimensions and different driving scenarios. Prediction results show that the TCN can accurately predict the long-term lane-changing trajectory and driving behavior with shorter computational time compared with two benchmark models. The TCN can provide accurate lane-changing prediction, which is one key information for the development of accurate ADAS.
Multi-Loss Sub-Ensembles for Accurate Classification with Uncertainty Estimation
Oct 05, 2020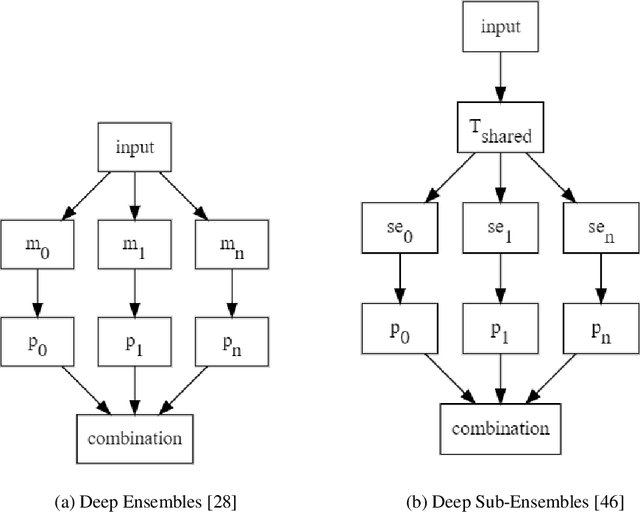
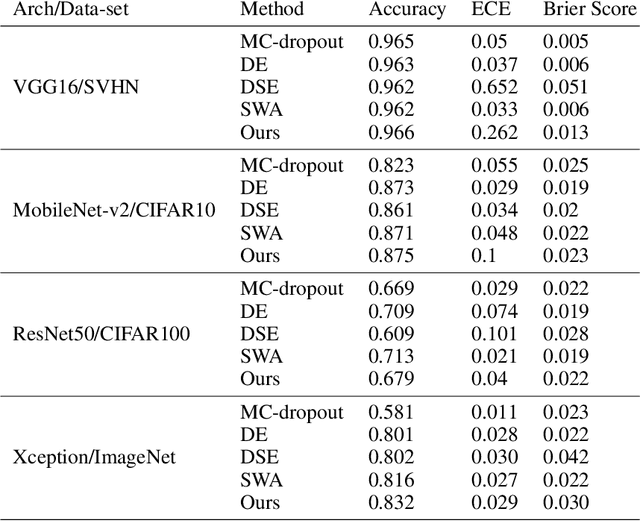
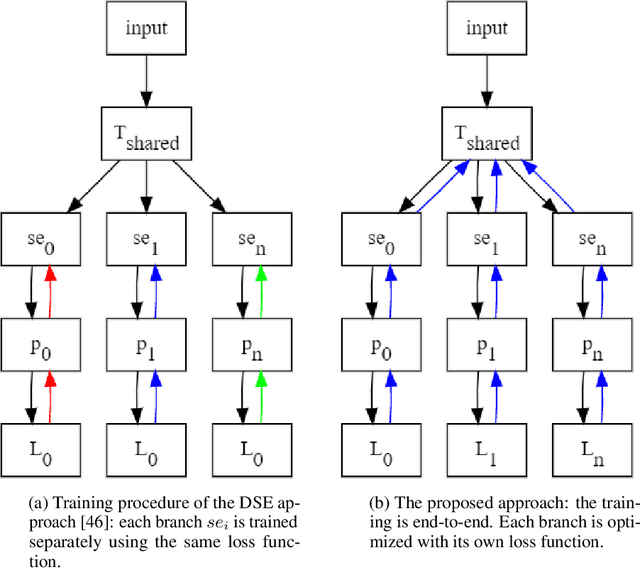
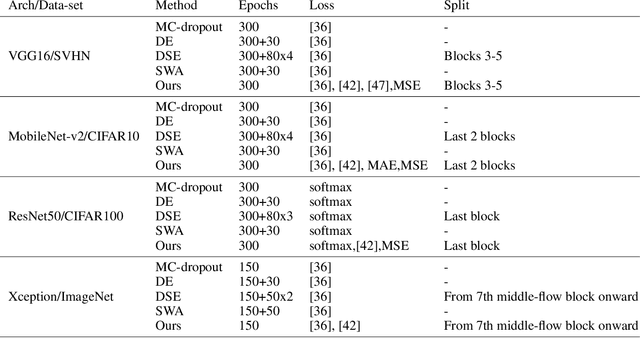
Deep neural networks (DNNs) have made a revolution in numerous fields during the last decade. However, in tasks with high safety requirements, such as medical or autonomous driving applications, providing an assessment of the models reliability can be vital. Uncertainty estimation for DNNs has been addressed using Bayesian methods, providing mathematically founded models for reliability assessment. These model are computationally expensive and generally impractical for many real-time use cases. Recently, non-Bayesian methods were proposed to tackle uncertainty estimation more efficiently. We propose an efficient method for uncertainty estimation in DNNs achieving high accuracy. We simulate the notion of multi-task learning on single-task problems by producing parallel predictions from similar models differing by their loss. This multi-loss approach allows one-phase training for single-task learning with uncertainty estimation. We keep our inference time relatively low by leveraging the advantage proposed by the Deep-Sub-Ensembles method. The novelty of this work resides in the proposed accurate variational inference with a simple and convenient training procedure, while remaining competitive in terms of computational time. We conduct experiments on SVHN, CIFAR10, CIFAR100 as well as Image-Net using different architectures. Our results show improved accuracy on the classification task and competitive results on several uncertainty measures.