 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reward Biased Maximum Likelihood Estimation for Reinforcement Learning
Nov 22, 2020
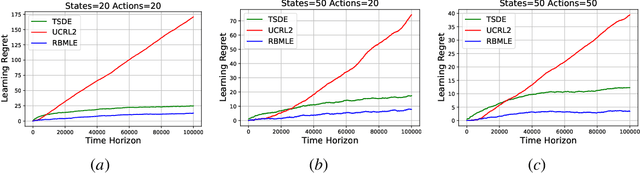
The Reward-Biased Maximum Likelihood Estimate (RBMLE) for adaptive control of Markov chains was proposed in (Kumar and Becker, 1982) to overcome the central obstacle of what is called the "closed-identifiability problem" of adaptive control, the "dual control problem" by Feldbaum (Feldbaum, 1960a,b), or the "exploration vs. exploitation problem". It exploited the key observation that since the maximum likelihood parameter estimator can asymptotically identify the closed-transition probabilities under a certainty equivalent approach (Borkar and Varaiya, 1979), the limiting parameter estimates must necessarily have an optimal reward that is less than the optimal reward for the true but unknown system. Hence it proposed a bias in favor of parameters with larger optimal rewards, providing a carefully structured solution to above problem. It thereby proposed an optimistic approach of favoring parameters with larger optimal rewards, now known as "optimism in the face of uncertainty." The RBMLE approach has been proved to be longterm average reward optimal in a variety of contexts including controlled Markov chains, linear quadratic Gaussian systems, some nonlinear systems, and diffusions. However, modern attention is focused on the much finer notion of "regret," or finite-time performance for all time, espoused by (Lai and Robbins, 1985). Recent analysis of RBMLE for multi-armed stochastic bandits (Liu et al., 2020) and linear contextual bandits (Hung et al., 2020) has shown that it has state-of-the-art regret and exhibits empirical performance comparable to or better than the best current contenders. Motivated by this, we examine the finite-time performance of RBMLE for reinforcement learning tasks of optimal control of unknown Markov Decision Processes. We show that it has a regret of $O(\log T)$ after $T$ steps, similar to state-of-art algorithms.
The SpaceNet Multi-Temporal Urban Development Challenge
Feb 23, 2021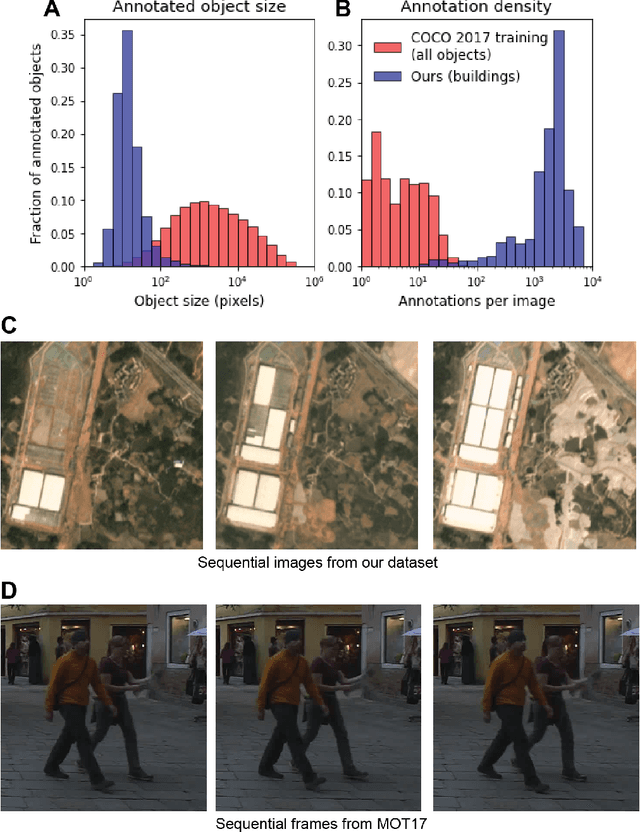



Building footprints provide a useful proxy for a great many humanitarian applications. For example, building footprints are useful for high fidelity population estimates, and quantifying population statistics is fundamental to ~1/4 of the United Nations Sustainable Development Goals Indicators. In this paper we (the SpaceNet Partners) discuss efforts to develop techniques for precise building footprint localization, tracking, and change detection via the SpaceNet Multi-Temporal Urban Development Challenge (also known as SpaceNet 7). In this NeurIPS 2020 competition, participants were asked identify and track buildings in satellite imagery time series collected over rapidly urbanizing areas. The competition centered around a brand new open source dataset of Planet Labs satellite imagery mosaics at 4m resolution, which includes 24 images (one per month) covering ~100 unique geographies. Tracking individual buildings at this resolution is quite challenging, yet the winning participants demonstrated impressive performance with the newly developed SpaceNet Change and Object Tracking (SCOT) metric. This paper details the top-5 winning approaches, as well as analysis of results that yielded a handful of interesting anecdotes such as decreasing performance with latitude.
Argument Mining Driven Analysis of Peer-Reviews
Dec 10, 2020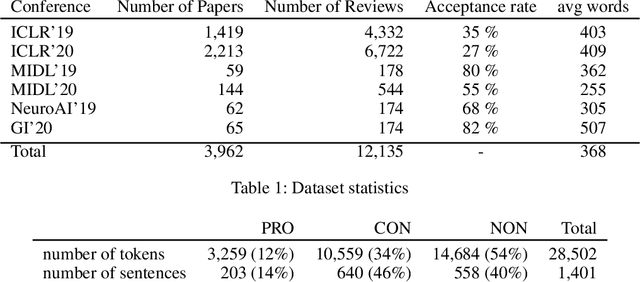
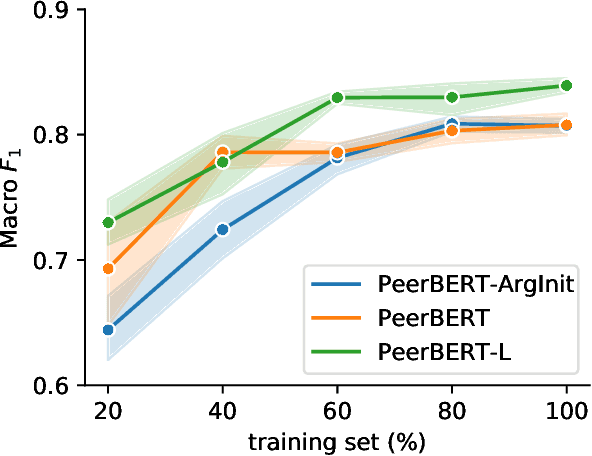
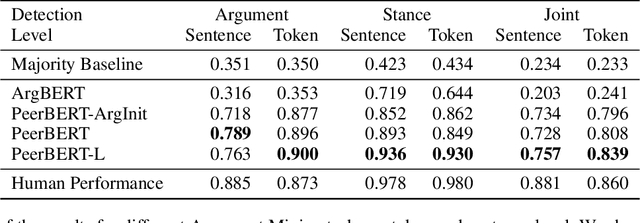
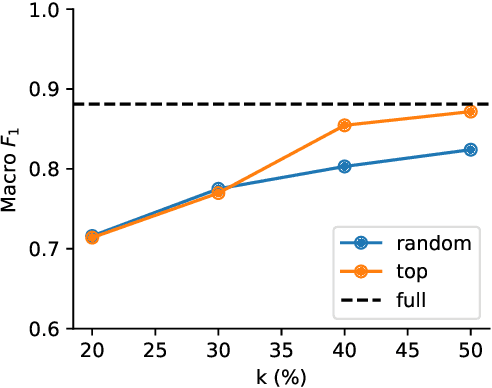
Peer reviewing is a central process in modern research and essential for ensuring high quality and reliability of published work. At the same time, it is a time-consuming process and increasing interest in emerging fields often results in a high review workload, especially for senior researchers in this area. How to cope with this problem is an open question and it is vividly discussed across all major conferences. In this work, we propose an Argument Mining based approach for the assistance of editors, meta-reviewers, and reviewers. We demonstrate that the decision process in the field of scientific publications is driven by arguments and automatic argument identification is helpful in various use-cases. One of our findings is that arguments used in the peer-review process differ from arguments in other domains making the transfer of pre-trained models difficult. Therefore, we provide the community with a new peer-review dataset from different computer science conferences with annotated arguments. In our extensive empirical evaluation, we show that Argument Mining can be used to efficiently extract the most relevant parts from reviews, which are paramount for the publication decision. The process remains interpretable since the extracted arguments can be highlighted in a review without detaching them from their context.
BERTSurv: BERT-Based Survival Models for Predicting Outcomes of Trauma Patients
Mar 19, 2021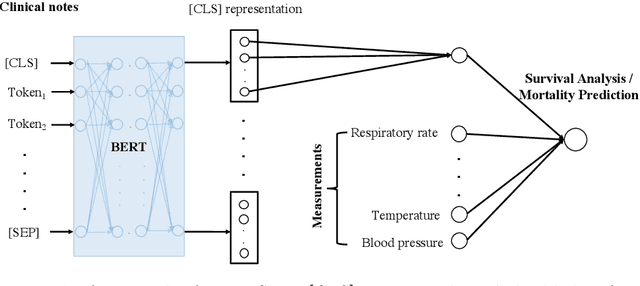
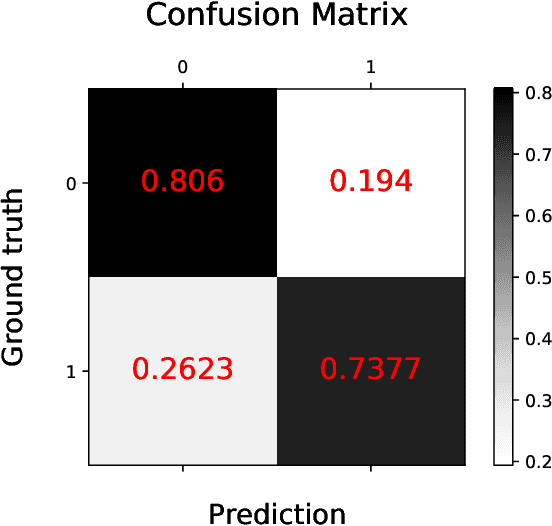
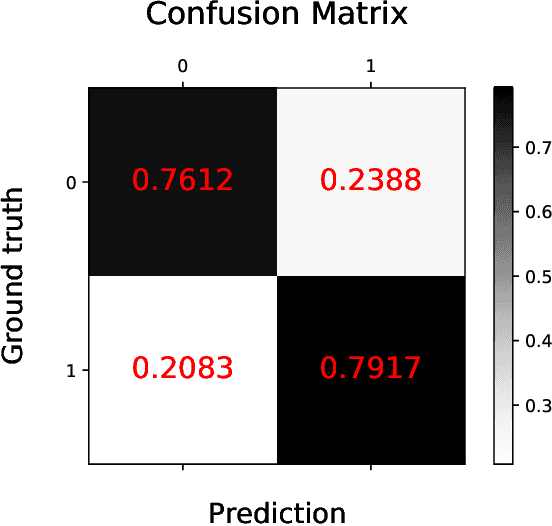
Survival analysis is a technique to predict the times of specific outcomes, and is widely used in predicting the outcomes for intensive care unit (ICU) trauma patients. Recently, deep learning models have drawn increasing attention in healthcare. However, there is a lack of deep learning methods that can model the relationship between measurements, clinical notes and mortality outcomes. In this paper we introduce BERTSurv, a deep learning survival framework which applies Bidirectional Encoder Representations from Transformers (BERT) as a language representation model on unstructured clinical notes, for mortality prediction and survival analysis. We also incorporate clinical measurements in BERTSurv. With binary cross-entropy (BCE) loss, BERTSurv can predict mortality as a binary outcome (mortality prediction). With partial log-likelihood (PLL) loss, BERTSurv predicts the probability of mortality as a time-to-event outcome (survival analysis). We apply BERTSurv on Medical Information Mart for Intensive Care III (MIMIC III) trauma patient data. For mortality prediction, BERTSurv obtained an area under the curve of receiver operating characteristic curve (AUC-ROC) of 0.86, which is an improvement of 3.6% over baseline of multilayer perceptron (MLP) without notes. For survival analysis, BERTSurv achieved a concordance index (C-index) of 0.7. In addition, visualizations of BERT's attention heads help to extract patterns in clinical notes and improve model interpretability by showing how the model assigns weights to different inputs.
Atlas-ISTN: Joint Segmentation, Registration and Atlas Construction with Image-and-Spatial Transformer Networks
Dec 18, 2020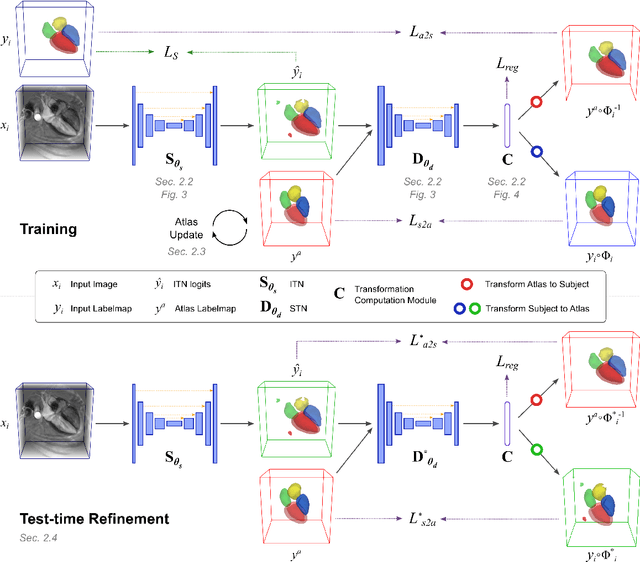
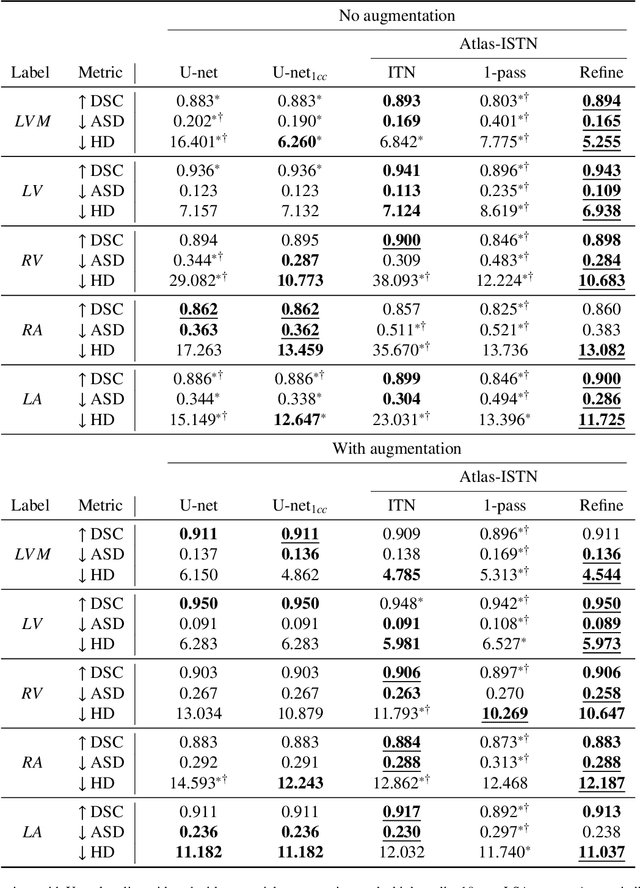
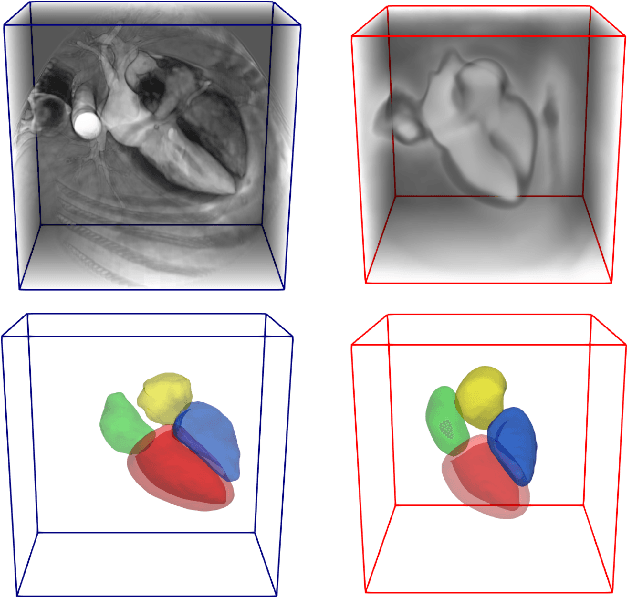
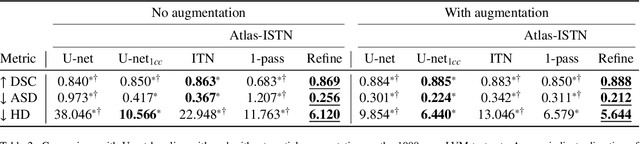
Deep learning models for semantic segmentation are able to learn powerful representations for pixel-wise predictions, but are sensitive to noise at test time and do not guarantee a plausible topology. Image registration models on the other hand are able to warp known topologies to target images as a means of segmentation, but typically require large amounts of training data, and have not widely been benchmarked against pixel-wise segmentation models. We propose Atlas-ISTN, a framework that jointly learns segmentation and registration on 2D and 3D image data, and constructs a population-derived atlas in the process. Atlas-ISTN learns to segment multiple structures of interest and to register the constructed, topologically consistent atlas labelmap to an intermediate pixel-wise segmentation. Additionally, Atlas-ISTN allows for test time refinement of the model's parameters to optimize the alignment of the atlas labelmap to an intermediate pixel-wise segmentation. This process both mitigates for noise in the target image that can result in spurious pixel-wise predictions, as well as improves upon the one-pass prediction of the model. Benefits of the Atlas-ISTN framework are demonstrated qualitatively and quantitatively on 2D synthetic data and 3D cardiac computed tomography and brain magnetic resonance image data, out-performing both segmentation and registration baseline models. Atlas-ISTN also provides inter-subject correspondence of the structures of interest, enabling population-level shape and motion analysis.
Online Structural Change-point Detection of High-dimensional Streaming Data via Dynamic Sparse Subspace Learning
Sep 29, 2020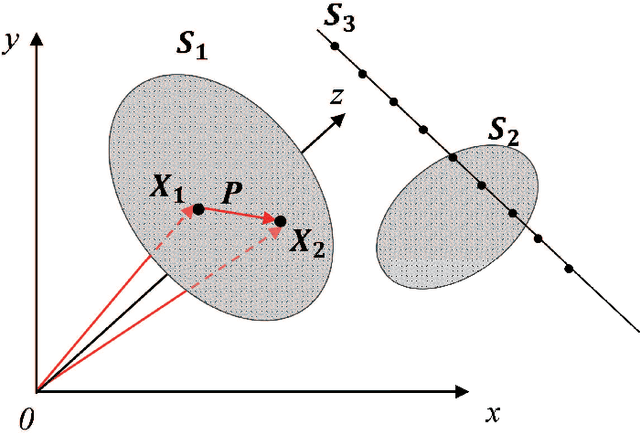
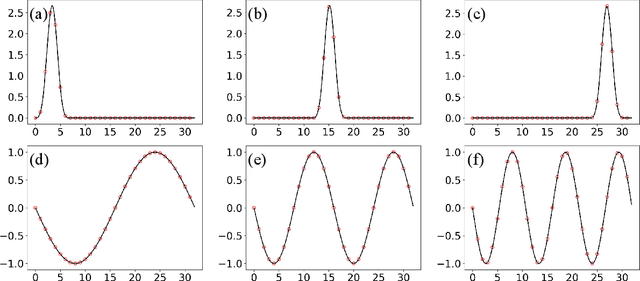
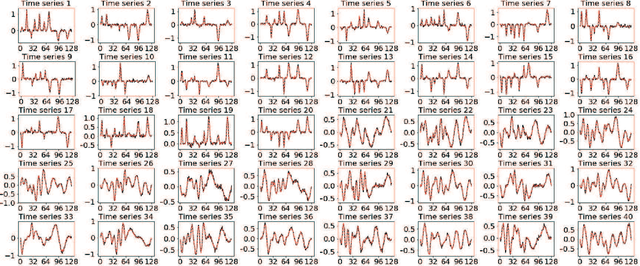
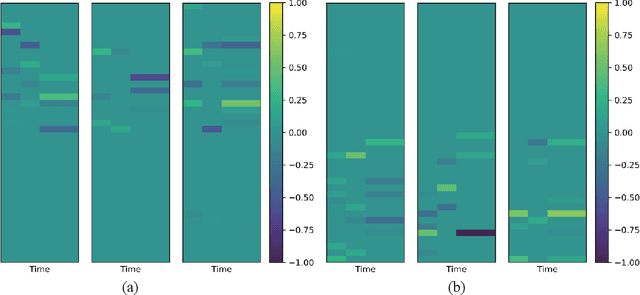
High-dimensional streaming data are becoming increasingly ubiquitous in many fields. They often lie in multiple low-dimensional subspaces, and the manifold structures may change abruptly on the time scale due to pattern shift or occurrence of anomalies. However, the problem of detecting the structural changes in a real-time manner has not been well studied. To fill this gap, we propose a dynamic sparse subspace learning (DSSL) approach for online structural change-point detection of high-dimensional streaming data. A novel multiple structural change-point model is proposed and it is shown to be equivalent to maximizing a posterior under certain conditions. The asymptotic properties of the estimators are investigated. The penalty coefficients in our model can be selected by AMDL criterion based on some historical data. An efficient Pruned Exact Linear Time (PELT) based method is proposed for online optimization and change-point detection. The effectiveness of the proposed method is demonstrated through a simulation study and a real case study using gesture data for motion tracking.
Dynamic Domain Adaptation for Efficient Inference
Mar 26, 2021
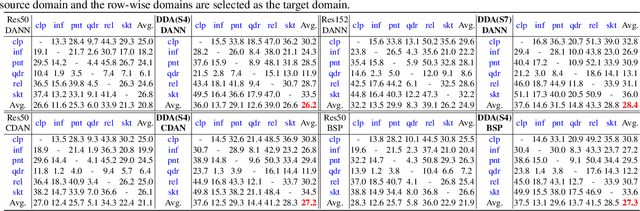
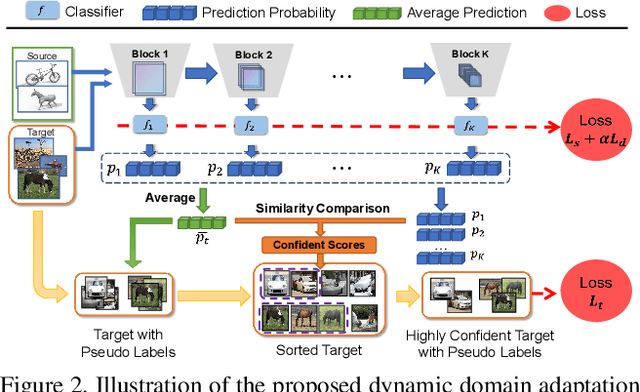

Domain adaptation (DA) enables knowledge transfer from a labeled source domain to an unlabeled target domain by reducing the cross-domain distribution discrepancy. Most prior DA approaches leverage complicated and powerful deep neural networks to improve the adaptation capacity and have shown remarkable success. However, they may have a lack of applicability to real-world situations such as real-time interaction, where low target inference latency is an essential requirement under limited computational budget. In this paper, we tackle the problem by proposing a dynamic domain adaptation (DDA) framework, which can simultaneously achieve efficient target inference in low-resource scenarios and inherit the favorable cross-domain generalization brought by DA. In contrast to static models, as a simple yet generic method, DDA can integrate various domain confusion constraints into any typical adaptive network, where multiple intermediate classifiers can be equipped to infer "easier" and "harder" target data dynamically. Moreover, we present two novel strategies to further boost the adaptation performance of multiple prediction exits: 1) a confidence score learning strategy to derive accurate target pseudo labels by fully exploring the prediction consistency of different classifiers; 2) a class-balanced self-training strategy to explicitly adapt multi-stage classifiers from source to target without losing prediction diversity. Extensive experiments on multiple benchmarks are conducted to verify that DDA can consistently improve the adaptation performance and accelerate target inference under domain shift and limited resources scenarios
Online Stochastic Gradient Descent Learns Linear Dynamical Systems from A Single Trajectory
Feb 23, 2021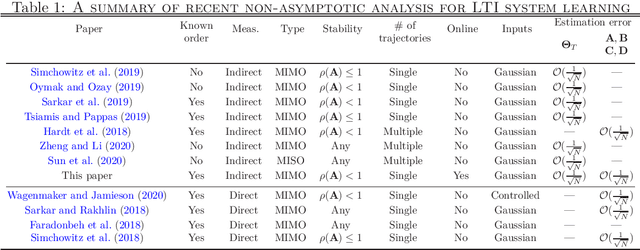
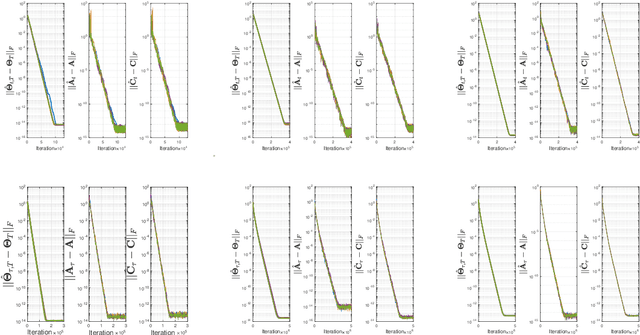
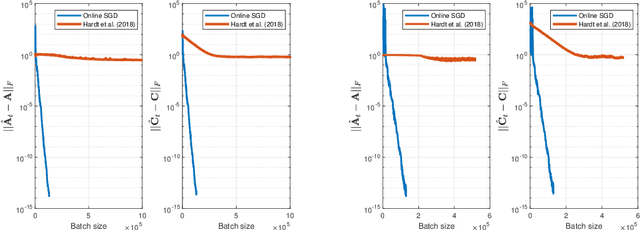
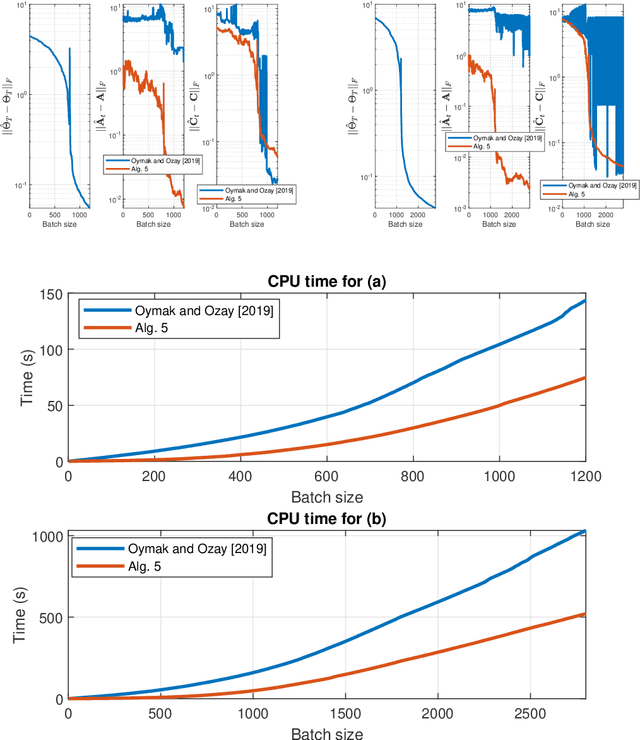
This work investigates the problem of estimating the weight matrices of a stable time-invariant linear dynamical system from a single sequence of noisy measurements. We show that if the unknown weight matrices describing the system are in Brunovsky canonical form, we can efficiently estimate the ground truth unknown matrices of the system from a linear system of equations formulated based on the transfer function of the system, using both online and offline stochastic gradient descent (SGD) methods. Specifically, by deriving concrete complexity bounds, we show that SGD converges linearly in expectation to any arbitrary small Frobenius norm distance from the ground truth weights. To the best of our knowledge, ours is the first work to establish linear convergence characteristics for online and offline gradient-based iterative methods for weight matrix estimation in linear dynamical systems from a single trajectory. Extensive numerical tests verify that the performance of the proposed methods is consistent with our theory, and show their superior performance relative to existing state of the art methods.
Learning and Real-time Classification of Hand-written Digits With Spiking Neural Networks
Nov 09, 2017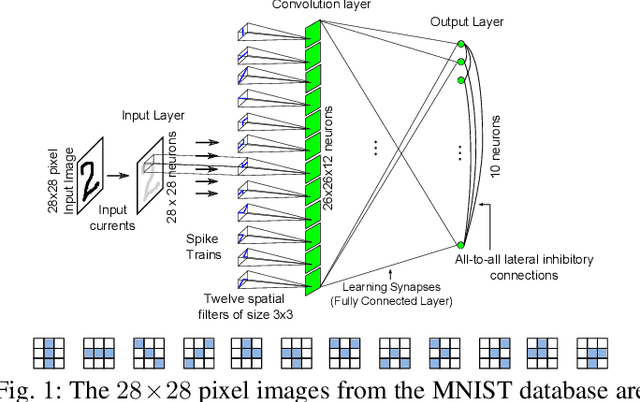
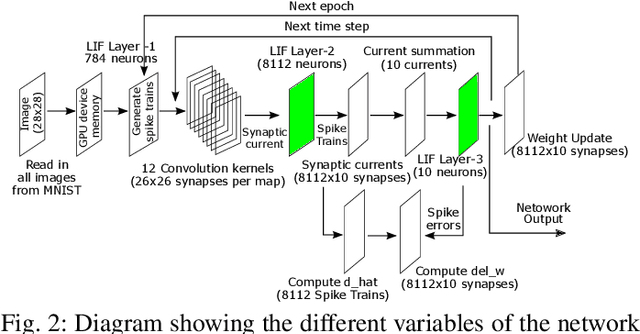
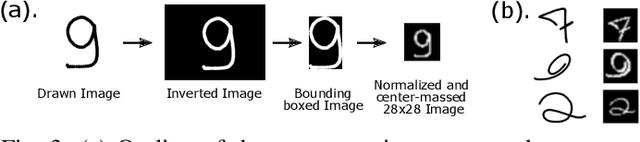
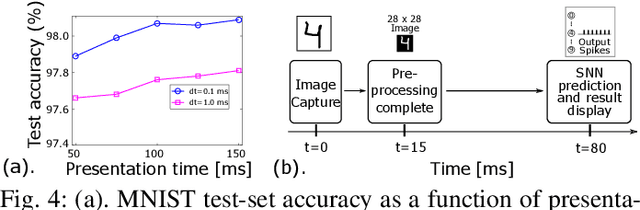
We describe a novel spiking neural network (SNN) for automated, real-time handwritten digit classification and its implementation on a GP-GPU platform. Information processing within the network, from feature extraction to classification is implemented by mimicking the basic aspects of neuronal spike initiation and propagation in the brain. The feature extraction layer of the SNN uses fixed synaptic weight maps to extract the key features of the image and the classifier layer uses the recently developed NormAD approximate gradient descent based supervised learning algorithm for spiking neural networks to adjust the synaptic weights. On the standard MNIST database images of handwritten digits, our network achieves an accuracy of 99.80% on the training set and 98.06% on the test set, with nearly 7x fewer parameters compared to the state-of-the-art spiking networks. We further use this network in a GPU based user-interface system demonstrating real-time SNN simulation to infer digits written by different users. On a test set of 500 such images, this real-time platform achieves an accuracy exceeding 97% while making a prediction within an SNN emulation time of less than 100ms.
Withholding aggressive treatments may not accelerate time to death among dying ICU patients
Aug 04, 2018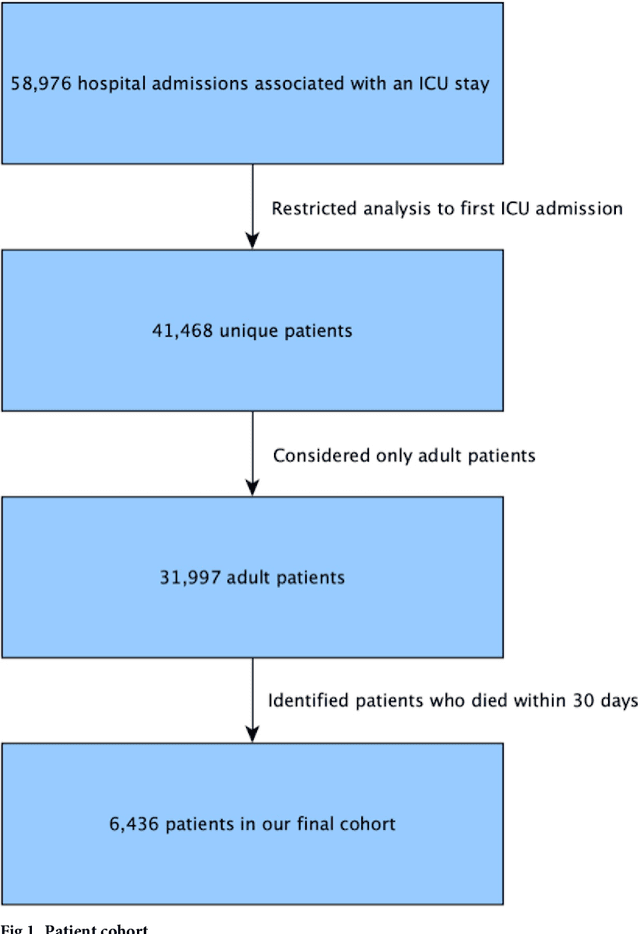
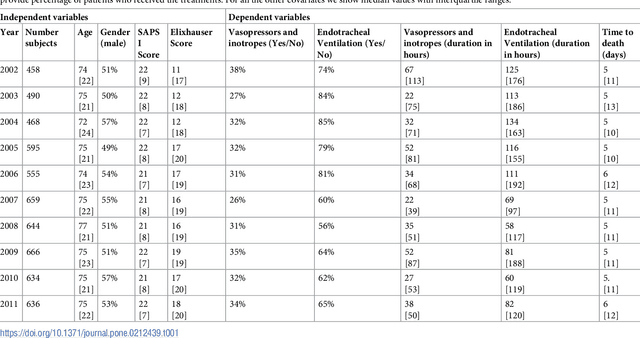
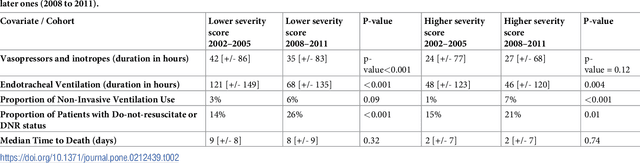
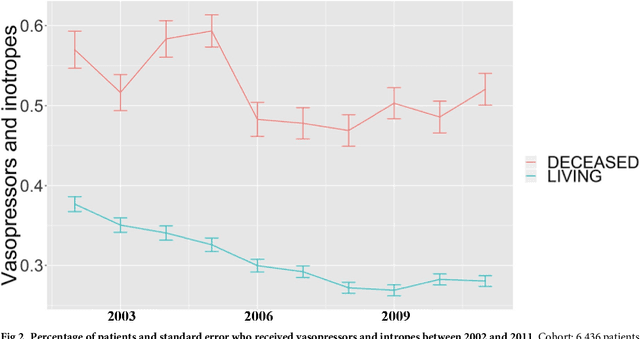
Critically ill patients may die despite aggressive treatment. In this study, we examine trends in the application of two such treatments over a decade, as well as the impact of these trends on survival durations in patients who die within a month of ICU admission. We considered observational data available from the MIMIC-III open-access ICU database, collected from June 2001 to October 2012: These data comprise almost 60,000 hospital admissions for a total of 38,645 unique adults. We explored two hypotheses: (i) administration of aggressive treatment during the ICU stay immediately preceding end-of-life would decrease over the study time period and (ii) time-to-death from ICU admission would also decrease due to the decrease in aggressive treatment administration. Tests for significant trends were performed and a p-value threshold of 0.05 was used to assess statistical significance. We found that aggressive treatments in this population were employed with decreasing frequency over the study period duration, and also that reducing aggressive treatments for such patients may not result in shorter times to death. The latter finding has implications for end of life discussions that involve the possible use or non-use of such treatments in those patients with very poor prognosis.