 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the Convergence and Optimality of Policy Gradient for Coherent Risk
Mar 04, 2021
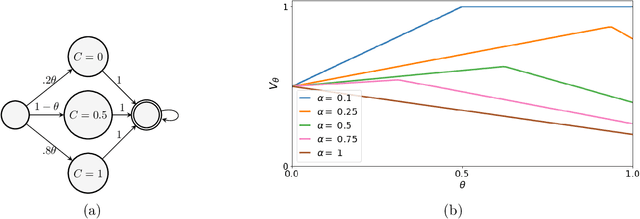

In order to model risk aversion in reinforcement learning, an emerging line of research adapts familiar algorithms to optimize coherent risk functionals, a class that includes conditional value-at-risk (CVaR). Because optimizing the coherent risk is difficult in Markov decision processes, recent work tends to focus on the Markov coherent risk (MCR), a time-consistent surrogate. While, policy gradient (PG) updates have been derived for this objective, it remains unclear (i) whether PG finds a global optimum for MCR; (ii) how to estimate the gradient in a tractable manner. In this paper, we demonstrate that, in general, MCR objectives (unlike the expected return) are not gradient dominated and that stationary points are not, in general, guaranteed to be globally optimal. Moreover, we present a tight upper bound on the suboptimality of the learned policy, characterizing its dependence on the nonlinearity of the objective and the degree of risk aversion. Addressing (ii), we propose a practical implementation of PG that uses state distribution reweighting to overcome previous limitations. Through experiments, we demonstrate that when the optimality gap is small, PG can learn risk-sensitive policies. However, we find that instances with large suboptimality gaps are abundant and easy to construct, outlining an important challenge for future research.
Deciding Fast and Slow: The Role of Cognitive Biases in AI-assisted Decision-making
Oct 15, 2020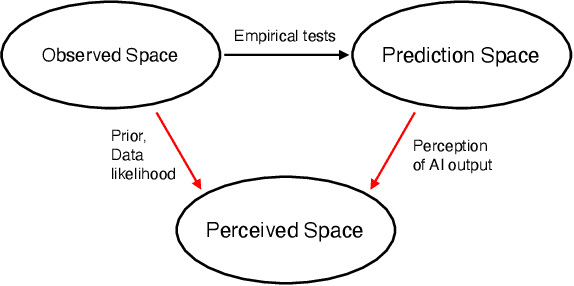
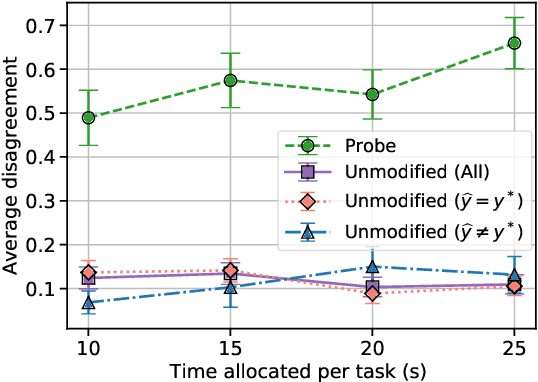
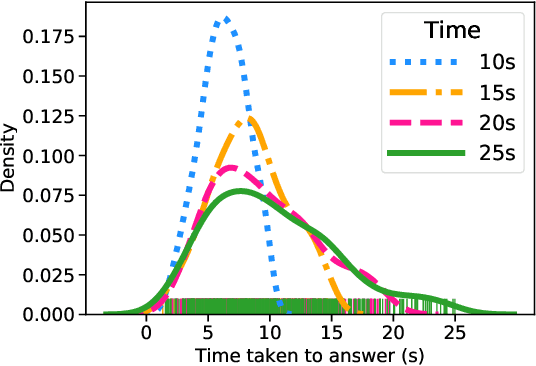
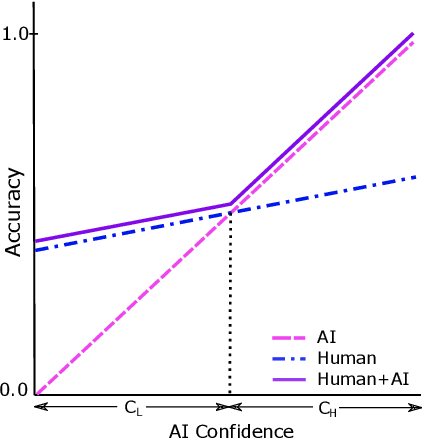
Several strands of research have aimed to bridge the gap between artificial intelligence (AI) and human decision-makers in AI-assisted decision-making, where humans are the consumers of AI model predictions and the ultimate decision-makers in high-stakes applications. However, people's perception and understanding is often distorted by their cognitive biases, like confirmation bias, anchoring bias, availability bias, to name a few. In this work, we use knowledge from the field of cognitive science to account for cognitive biases in the human-AI collaborative decision-making system and mitigate their negative effects. To this end, we mathematically model cognitive biases and provide a general framework through which researchers and practitioners can understand the interplay between cognitive biases and human-AI accuracy. We then focus on anchoring bias, a bias commonly witnessed in human-AI partnerships. We devise a cognitive science-driven, time-based approach to de-anchoring. A user experiment shows the effectiveness of this approach in human-AI collaborative decision-making. Using the results from this first experiment, we design a time allocation strategy for a resource constrained setting so as to achieve optimal human-AI collaboration under some assumptions. A second user study shows that our time allocation strategy can effectively debias the human when the AI model has low confidence and is incorrect.
Geometric Exploration for Online Control
Oct 29, 2020We study the control of an \emph{unknown} linear dynamical system under general convex costs. The objective is minimizing regret vs. the class of disturbance-feedback-controllers, which encompasses all stabilizing linear-dynamical-controllers. In this work, we first consider the case of known cost functions, for which we design the first polynomial-time algorithm with $n^3\sqrt{T}$-regret, where $n$ is the dimension of the state plus the dimension of control input. The $\sqrt{T}$-horizon dependence is optimal, and improves upon the previous best known bound of $T^{2/3}$. The main component of our algorithm is a novel geometric exploration strategy: we adaptively construct a sequence of barycentric spanners in the policy space. Second, we consider the case of bandit feedback, for which we give the first polynomial-time algorithm with $poly(n)\sqrt{T}$-regret, building on Stochastic Bandit Convex Optimization.
ScrofaZero: Mastering Trick-taking Poker Game Gongzhu by Deep Reinforcement Learning
Feb 15, 2021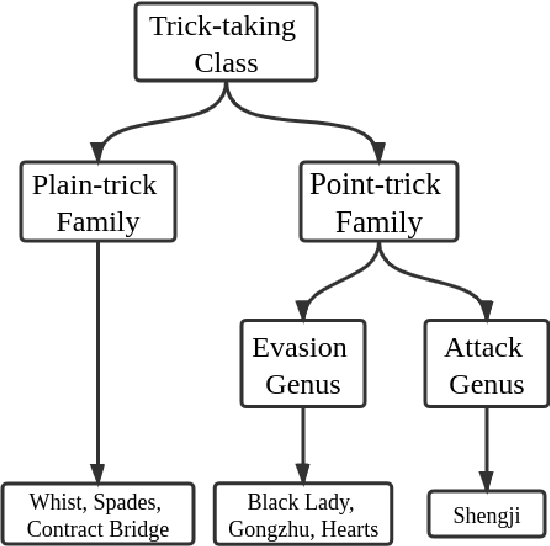
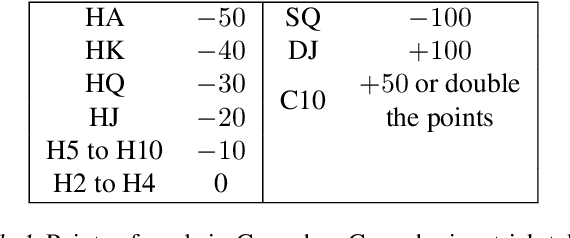
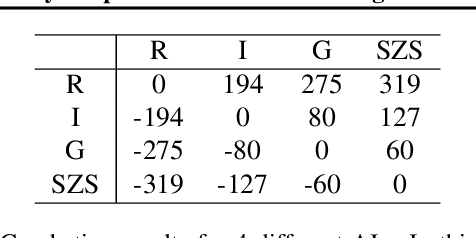
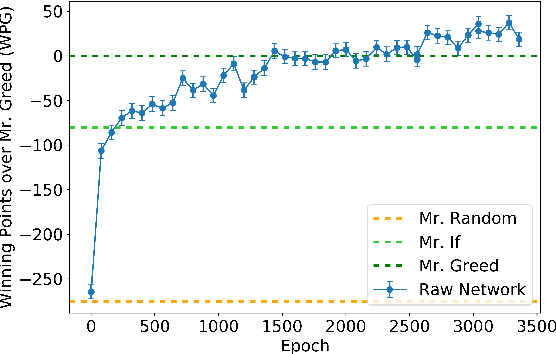
People have made remarkable progress in game AIs, especially in domain of perfect information game. However, trick-taking poker game, as a popular form of imperfect information game, has been regarded as a challenge for a long time. Since trick-taking game requires high level of not only reasoning, but also inference to excel, it can be a new milestone for imperfect information game AI. We study Gongzhu, a trick-taking game analogous to, but slightly simpler than contract bridge. Nonetheless, the strategies of Gongzhu are complex enough for both human and computer players. We train a strong Gongzhu AI ScrofaZero from \textit{tabula rasa} by deep reinforcement learning, while few previous efforts on solving trick-taking poker game utilize the representation power of neural networks. Also, we introduce new techniques for imperfect information game including stratified sampling, importance weighting, integral over equivalent class, Bayesian inference, etc. Our AI can achieve human expert level performance. The methodologies in building our program can be easily transferred into a wide range of trick-taking games.
MIcro-Surgical Anastomose Workflow recognition challenge report
Mar 24, 2021
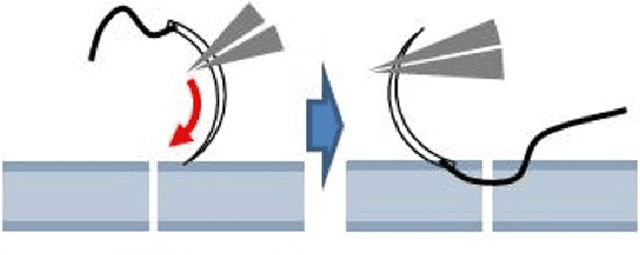
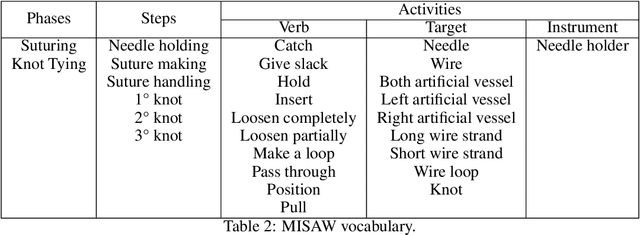
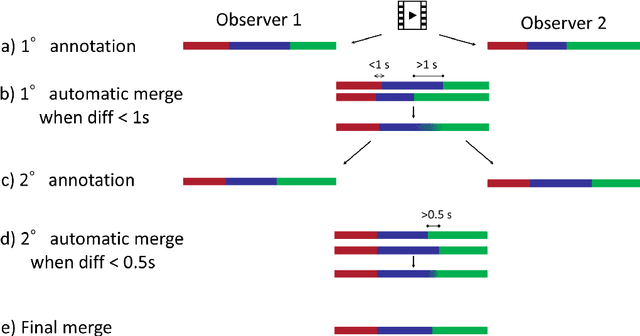
The "MIcro-Surgical Anastomose Workflow recognition on training sessions" (MISAW) challenge provided a data set of 27 sequences of micro-surgical anastomosis on artificial blood vessels. This data set was composed of videos, kinematics, and workflow annotations described at three different granularity levels: phase, step, and activity. The participants were given the option to use kinematic data and videos to develop workflow recognition models. Four tasks were proposed to the participants: three of them were related to the recognition of surgical workflow at three different granularity levels, while the last one addressed the recognition of all granularity levels in the same model. One ranking was made for each task. We used the average application-dependent balanced accuracy (AD-Accuracy) as the evaluation metric. This takes unbalanced classes into account and it is more clinically relevant than a frame-by-frame score. Six teams, including a non-competing team, participated in at least one task. All models employed deep learning models, such as CNN or RNN. The best models achieved more than 95% AD-Accuracy for phase recognition, 80% for step recognition, 60% for activity recognition, and 75% for all granularity levels. For high levels of granularity (i.e., phases and steps), the best models had a recognition rate that may be sufficient for applications such as prediction of remaining surgical time or resource management. However, for activities, the recognition rate was still low for applications that can be employed clinically. The MISAW data set is publicly available to encourage further research in surgical workflow recognition. It can be found at www.synapse.org/MISAW
Lightweight Multi-Branch Network for Person Re-Identification
Jan 26, 2021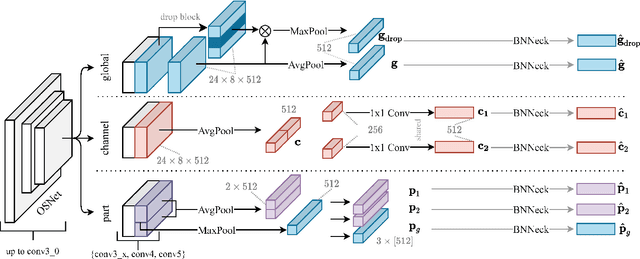
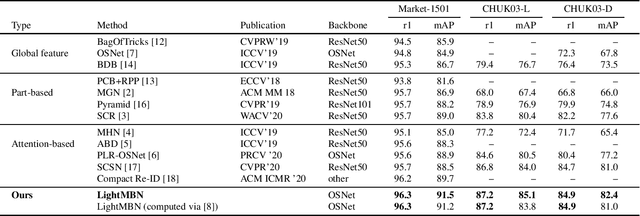
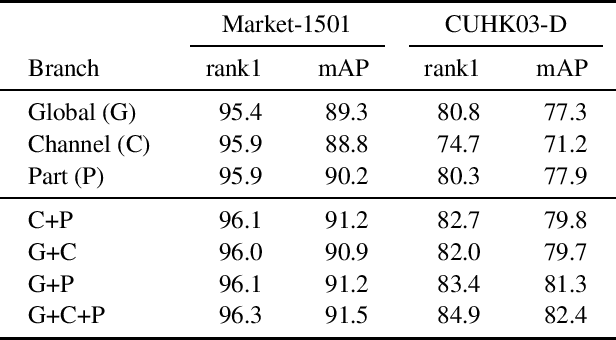
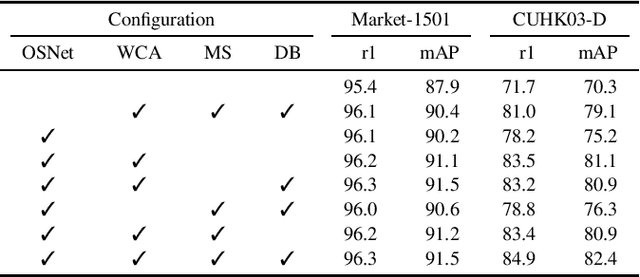
Person Re-Identification aims to retrieve person identities from images captured by multiple cameras or the same cameras in different time instances and locations. Because of its importance in many vision applications from surveillance to human-machine interaction, person re-identification methods need to be reliable and fast. While more and more deep architectures are proposed for increasing performance, those methods also increase overall model complexity. This paper proposes a lightweight network that combines global, part-based, and channel features in a unified multi-branch architecture that builds on the resource-efficient OSNet backbone. Using a well-founded combination of training techniques and design choices, our final model achieves state-of-the-art results on CUHK03 labeled, CUHK03 detected, and Market-1501 with 85.1% mAP / 87.2% rank1, 82.4% mAP / 84.9% rank1, and 91.5% mAP / 96.3% rank1, respectively.
FFD: Fast Feature Detector
Dec 01, 2020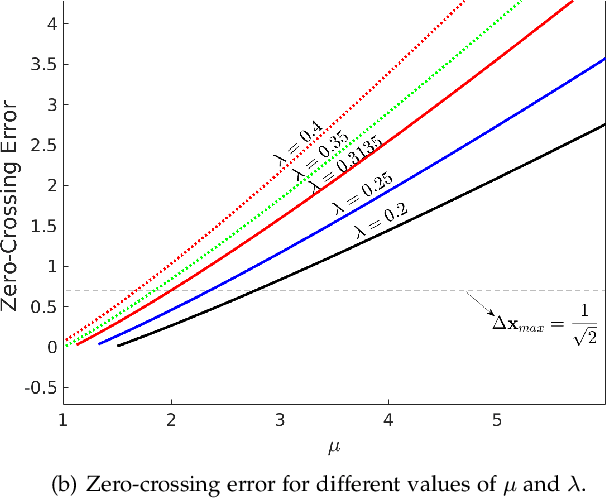
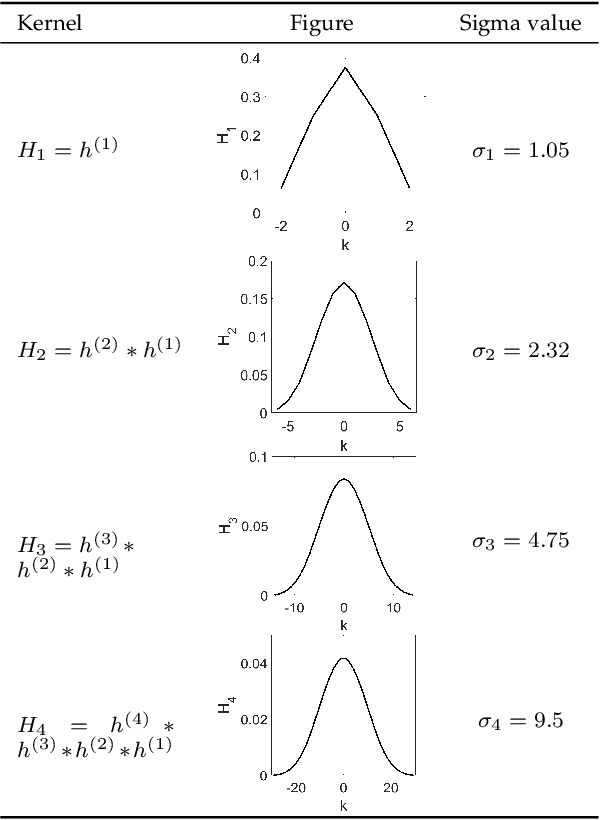
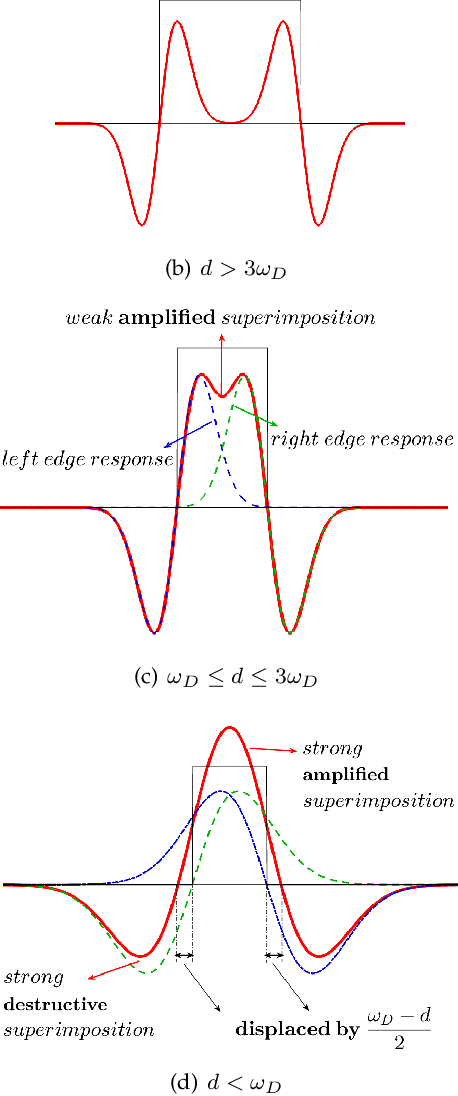

Scale-invariance, good localization and robustness to noise and distortions are the main properties that a local feature detector should possess. Most existing local feature detectors find excessive unstable feature points that increase the number of keypoints to be matched and the computational time of the matching step. In this paper, we show that robust and accurate keypoints exist in the specific scale-space domain. To this end, we first formulate the superimposition problem into a mathematical model and then derive a closed-form solution for multiscale analysis. The model is formulated via difference-of-Gaussian (DoG) kernels in the continuous scale-space domain, and it is proved that setting the scale-space pyramid's blurring ratio and smoothness to 2 and 0.627, respectively, facilitates the detection of reliable keypoints. For the applicability of the proposed model to discrete images, we discretize it using the undecimated wavelet transform and the cubic spline function. Theoretically, the complexity of our method is less than 5\% of that of the popular baseline Scale Invariant Feature Transform (SIFT). Extensive experimental results show the superiority of the proposed feature detector over the existing representative hand-crafted and learning-based techniques in accuracy and computational time. The code and supplementary materials can be found at~{\url{https://github.com/mogvision/FFD}}.
Free-Breathing Water, Fat, $R_2^{\star}$ and $B_0$ Field Mapping of the Liver Using Multi-Echo Radial FLASH and Regularized Model-based Reconstruction (MERLOT)
Jan 07, 2021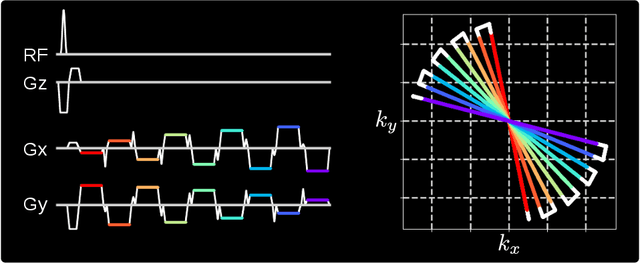
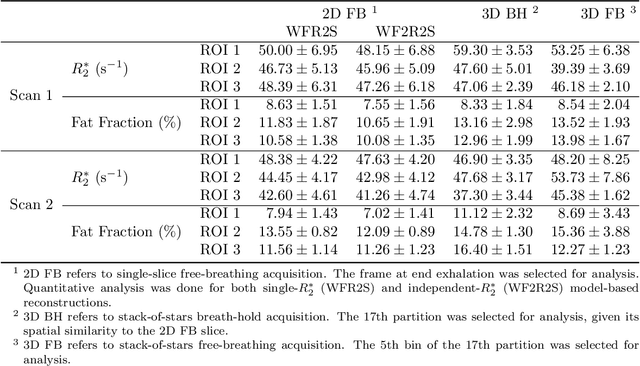
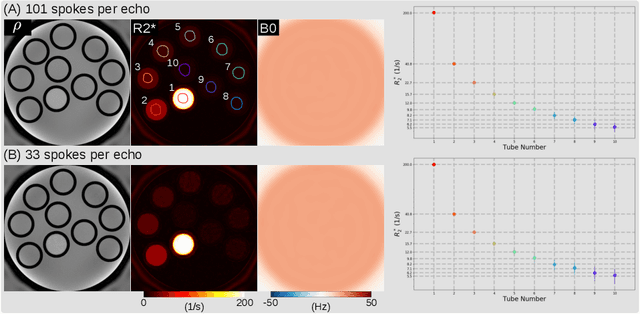
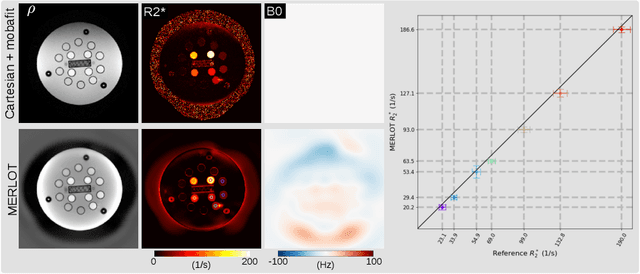
Purpose: To achieve free-breathing quantitative fat and $R_2^{\star}$ mapping of the liver using a generalized model-based iterative reconstruction, dubbed as MERLOT. Methods: For acquisition, we use a multi-echo radial FLASH sequence that acquires multiple echoes with different complementary radial spoke encodings. We investigate real-time single-slice and volumetric multi-echo radial FLASH acquisition. For the latter, the sampling scheme is extended to a volumetric stack-of-stars acquisition. Model-based reconstruction based on generalized nonlinear inversion is used to jointly estimate water, fat, $R_2^{\star}$, $B_0$ field inhomogeneity, and coil sensitivity maps from the multi-coil multi-echo radial spokes. Spatial smoothness regularization is applied onto the B 0 field and coil sensitivity maps, whereas joint sparsity regularization is employed for the other parameter maps. The method integrates calibration-less parallel imaging and compressed sensing and was implemented in BART. For the volumetric acquisition, the respiratory motion is resolved with self-gating using SSA-FARY. The quantitative accuracy of the proposed method was validated via numerical simulation, the NIST phantom, a water/fat phantom, and in in-vivo liver studies. Results: For real-time acquisition, the proposed model-based reconstruction allowed acquisition of dynamic liver fat fraction and $R_2^{\star}$ maps at a temporal resolution of 0.3 s per frame. For the volumetric acquisition, whole liver coverage could be achieved in under 2 minutes using the self-gated motion-resolved reconstruction. Conclusion: The proposed multi-echo radial sampling sequence achieves fast k -space coverage and is robust to motion. The proposed model-based reconstruction yields spatially and temporally resolved liver fat fraction, $R_2^{\star}$ and $B_0$ field maps at high undersampling factor and with volume coverage.
Rapid treatment planning for low-dose-rate prostate brachytherapy with TP-GAN
Mar 18, 2021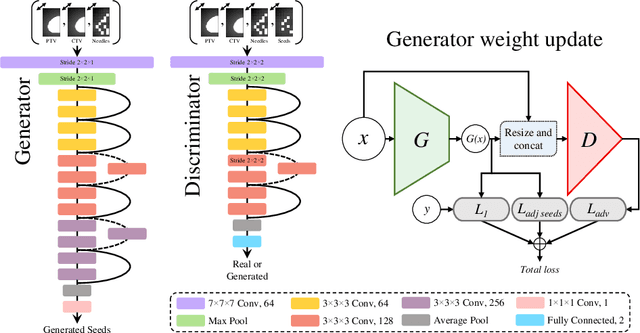
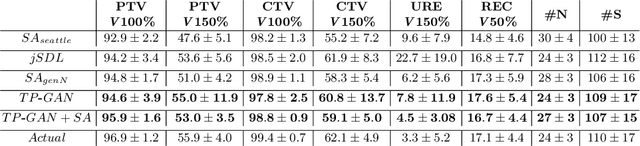

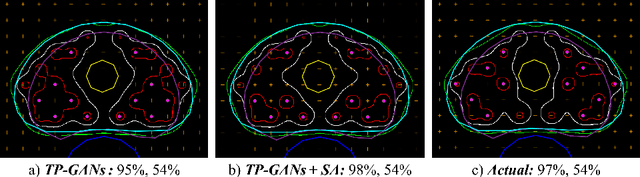
Treatment planning in low-dose-rate prostate brachytherapy (LDR-PB) aims to produce arrangement of implantable radioactive seeds that deliver a minimum prescribed dose to the prostate whilst minimizing toxicity to healthy tissues. There can be multiple seed arrangements that satisfy this dosimetric criterion, not all deemed 'acceptable' for implant from a physician's perspective. This leads to plans that are subjective to the physician's/centre's preference, planning style, and expertise. We propose a method that aims to reduce this variability by training a model to learn from a large pool of successful retrospective LDR-PB data (961 patients) and create consistent plans that mimic the high-quality manual plans. Our model is based on conditional generative adversarial networks that use a novel loss function for penalizing the model on spatial constraints of the seeds. An optional optimizer based on a simulated annealing (SA) algorithm can be used to further fine-tune the plans if necessary (determined by the treating physician). Performance analysis was conducted on 150 test cases demonstrating comparable results to that of the manual prehistorical plans. On average, the clinical target volume covering 100% of the prescribed dose was 98.9% for our method compared to 99.4% for manual plans. Moreover, using our model, the planning time was significantly reduced to an average of 2.5 mins/plan with SA, and less than 3 seconds without SA. Compared to this, manual planning at our centre takes around 20 mins/plan.
Learning Asynchronous and Sparse Human-Object Interaction in Videos
Mar 03, 2021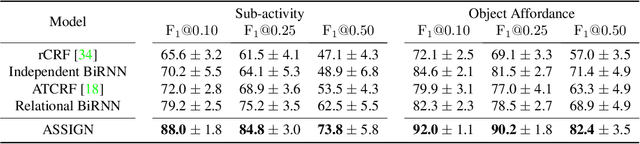
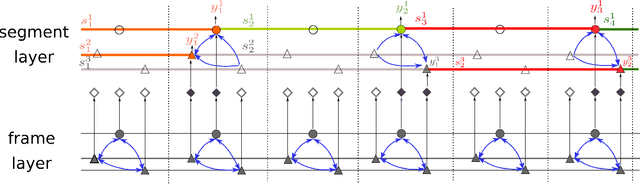
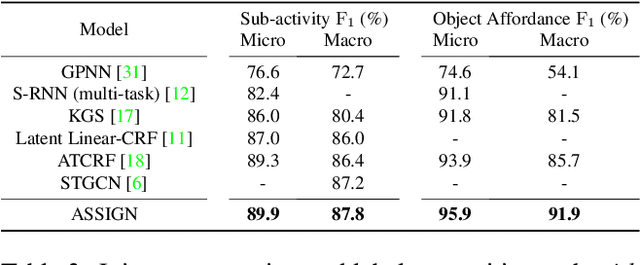
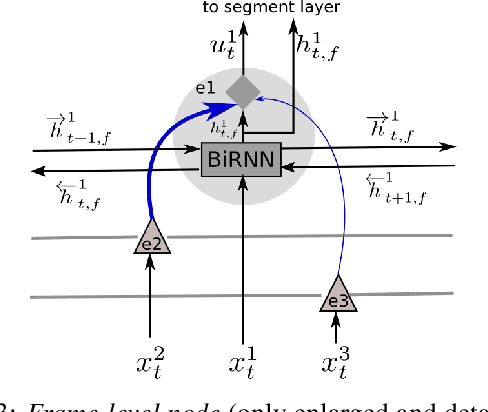
Human activities can be learned from video. With effective modeling it is possible to discover not only the action labels but also the temporal structures of the activities such as the progression of the sub-activities. Automatically recognizing such structure from raw video signal is a new capability that promises authentic modeling and successful recognition of human-object interactions. Toward this goal, we introduce Asynchronous-Sparse Interaction Graph Networks (ASSIGN), a recurrent graph network that is able to automatically detect the structure of interaction events associated with entities in a video scene. ASSIGN pioneers learning of autonomous behavior of video entities including their dynamic structure and their interaction with the coexisting neighbors. Entities' lives in our model are asynchronous to those of others therefore more flexible in adaptation to complex scenarios. Their interactions are sparse in time hence more faithful to the true underlying nature and more robust in inference and learning. ASSIGN is tested on human-object interaction recognition and shows superior performance in segmenting and labeling of human sub-activities and object affordances from raw videos. The native ability for discovering temporal structures of the model also eliminates the dependence on external segmentation that was previously mandatory for this task.