 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning in Matrix Games can be Arbitrarily Complex
Mar 05, 2021
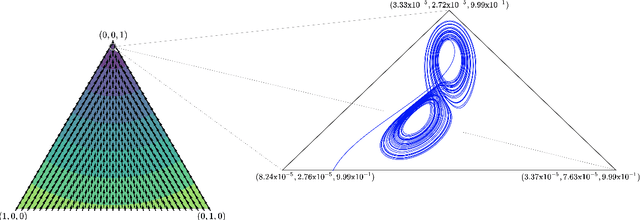
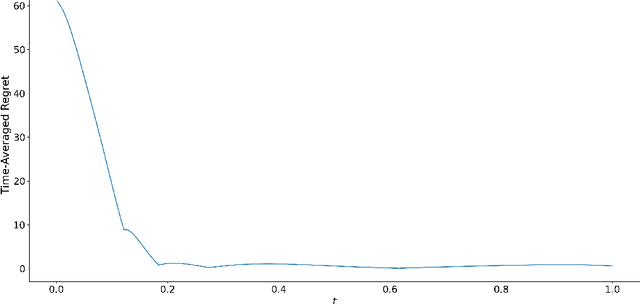
A growing number of machine learning architectures, such as Generative Adversarial Networks, rely on the design of games which implement a desired functionality via a Nash equilibrium. In practice these games have an implicit complexity (e.g. from underlying datasets and the deep networks used) that makes directly computing a Nash equilibrium impractical or impossible. For this reason, numerous learning algorithms have been developed with the goal of iteratively converging to a Nash equilibrium. Unfortunately, the dynamics generated by the learning process can be very intricate and instances of training failure hard to interpret. In this paper we show that, in a strong sense, this dynamic complexity is inherent to games. Specifically, we prove that replicator dynamics, the continuous-time analogue of Multiplicative Weights Update, even when applied in a very restricted class of games -- known as finite matrix games -- is rich enough to be able to approximate arbitrary dynamical systems. Our results are positive in the sense that they show the nearly boundless dynamic modelling capabilities of current machine learning practices, but also negative in implying that these capabilities may come at the cost of interpretability. As a concrete example, we show how replicator dynamics can effectively reproduce the well-known strange attractor of Lonrenz dynamics (the "butterfly effect") while achieving no regret.
Kalman filter based MIMO CSI phase recovery for COTS WiFi devices
Jan 15, 2021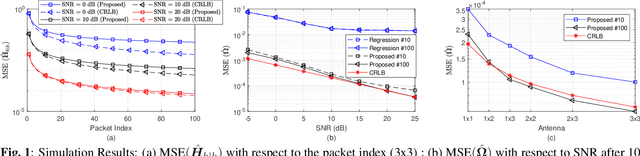

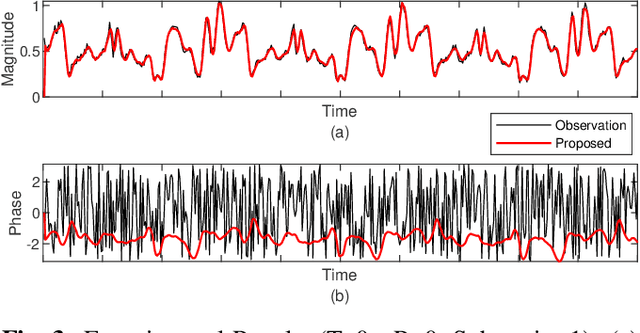
Recently channel state information (CSI) measurements from commercial multi input multi output (MIMO) WiFi systems have been ubiquitously used for different wireless sensing applications. However, the phase of the CSI realizations is usually distorted severely by phase errors due to the hardware impairments, which significantly reduce the sensing performance. In this paper, we directly utilize the modeling of the phase distortions caused by the hardware impairments and propose an adaptive CSI estimation approach based on Kalman filter (KF) with maximum a posteriori (MAP) estimation that considers the CSI from the previous time. The performance of the proposed algorithm is compared against the Cramer Rao lower bound (CRLB). Simulation and experimental results demonstrate that our approach can track the channel variations while eliminating the phase errors accurately.
Geometric Exploration for Online Control
Oct 29, 2020We study the control of an \emph{unknown} linear dynamical system under general convex costs. The objective is minimizing regret vs. the class of disturbance-feedback-controllers, which encompasses all stabilizing linear-dynamical-controllers. In this work, we first consider the case of known cost functions, for which we design the first polynomial-time algorithm with $n^3\sqrt{T}$-regret, where $n$ is the dimension of the state plus the dimension of control input. The $\sqrt{T}$-horizon dependence is optimal, and improves upon the previous best known bound of $T^{2/3}$. The main component of our algorithm is a novel geometric exploration strategy: we adaptively construct a sequence of barycentric spanners in the policy space. Second, we consider the case of bandit feedback, for which we give the first polynomial-time algorithm with $poly(n)\sqrt{T}$-regret, building on Stochastic Bandit Convex Optimization.
Segmenting Microcalcifications in Mammograms and its Applications
Feb 01, 2021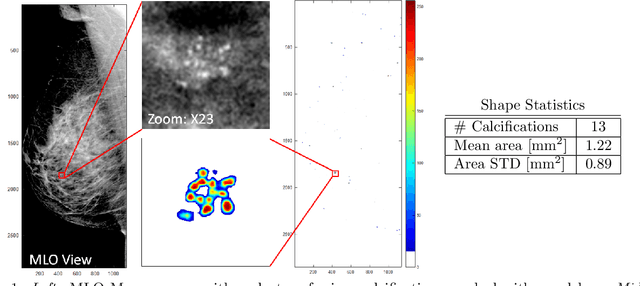
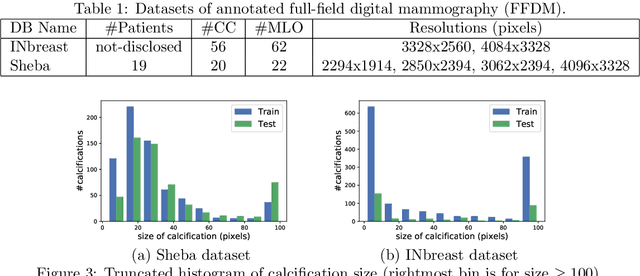
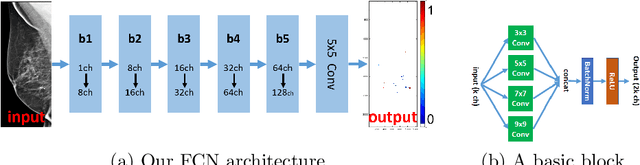

Microcalcifications are small deposits of calcium that appear in mammograms as bright white specks on the soft tissue background of the breast. Microcalcifications may be a unique indication for Ductal Carcinoma in Situ breast cancer, and therefore their accurate detection is crucial for diagnosis and screening. Manual detection of these tiny calcium residues in mammograms is both time-consuming and error-prone, even for expert radiologists, since these microcalcifications are small and can be easily missed. Existing computerized algorithms for detecting and segmenting microcalcifications tend to suffer from a high false-positive rate, hindering their widespread use. In this paper, we propose an accurate calcification segmentation method using deep learning. We specifically address the challenge of keeping the false positive rate low by suggesting a strategy for focusing the hard pixels in the training phase. Furthermore, our accurate segmentation enables extracting meaningful statistics on clusters of microcalcifications.
Federated Depression Detection from Multi-SourceMobile Health Data
Feb 06, 2021
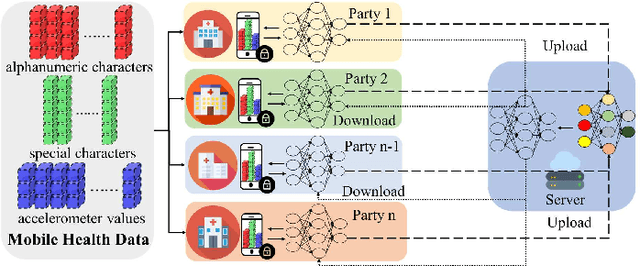
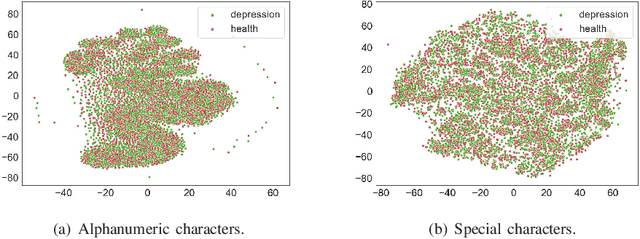
Depression is one of the most common mental illness problems, and the symptoms shown by patients are not consistent, making it difficult to diagnose in the process of clinical practice and pathological research.Although researchers hope that artificial intelligence can contribute to the diagnosis and treatment of depression, the traditional centralized machine learning needs to aggregate patient data, and the data privacy of patients with mental illness needs to be strictly confidential, which hinders machine learning algorithms clinical application.To solve the problem of privacy of the medical history of patients with depression, we implement federated learning to analyze and diagnose depression. First, we propose a general multi-view federated learning framework using multi-source data,which can extend any traditional machine learning model to support federated learning across different institutions or parties.Secondly, we adopt late fusion methods to solve the problem of inconsistent time series of multi-view data.Finally, we compare the federated framework with other cooperative learning frameworks in performance and discuss the related results.
Robust subgroup discovery
Mar 25, 2021



We introduce the problem of robust subgroup discovery, i.e., finding a set of interpretable descriptions of subsets that 1) stand out with respect to one or more target attributes, 2) are statistically robust, and 3) non-redundant. Many attempts have been made to mine either locally robust subgroups or to tackle the pattern explosion, but we are the first to address both challenges at the same time from a global perspective. First, we formulate a broad model class of subgroup lists, i.e., ordered sets of subgroups, for univariate and multivariate targets that can consist of nominal or numeric variables. This novel model class allows us to formalize the problem of optimal robust subgroup discovery using the Minimum Description Length (MDL) principle, where we resort to optimal Normalized Maximum Likelihood and Bayesian encodings for nominal and numeric targets, respectively. Notably, we show that our problem definition is equal to mining the top-1 subgroup with an information-theoretic quality measure plus a penalty for complexity. Second, as finding optimal subgroup lists is NP-hard, we propose RSD, a greedy heuristic that finds good subgroup lists and guarantees that the most significant subgroup found according to the MDL criterion is added in each iteration, which is shown to be equivalent to a Bayesian one-sample proportions, multinomial, or t-test between the subgroup and dataset marginal target distributions plus a multiple hypothesis testing penalty. We empirically show on 54 datasets that RSD outperforms previous subgroup set discovery methods in terms of quality and subgroup list size.
Learning High Fidelity Depths of Dressed Humans by Watching Social Media Dance Videos
Mar 04, 2021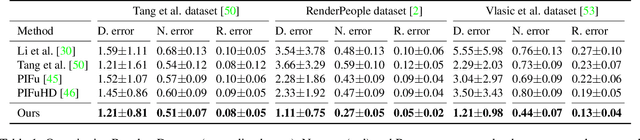
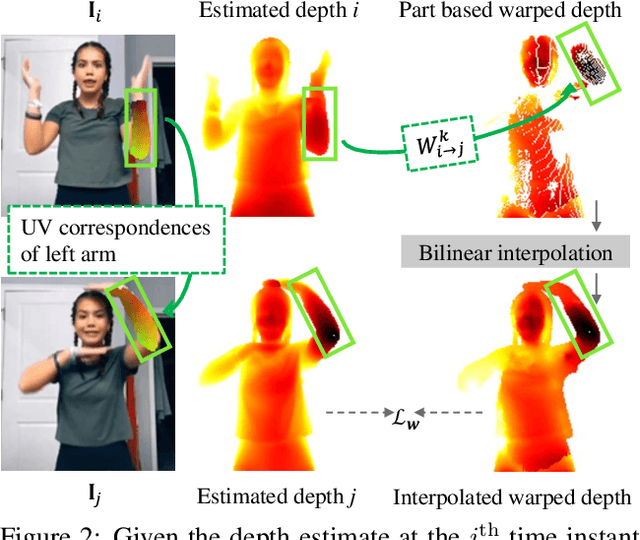
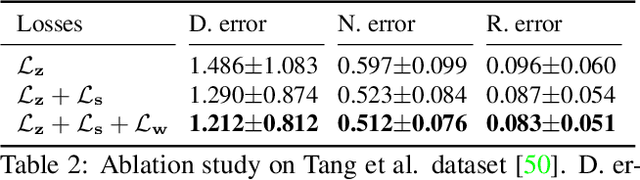

A key challenge of learning the geometry of dressed humans lies in the limited availability of the ground truth data (e.g., 3D scanned models), which results in the performance degradation of 3D human reconstruction when applying to real-world imagery. We address this challenge by leveraging a new data resource: a number of social media dance videos that span diverse appearance, clothing styles, performances, and identities. Each video depicts dynamic movements of the body and clothes of a single person while lacking the 3D ground truth geometry. To utilize these videos, we present a new method to use the local transformation that warps the predicted local geometry of the person from an image to that of another image at a different time instant. This allows self-supervision as enforcing a temporal coherence over the predictions. In addition, we jointly learn the depth along with the surface normals that are highly responsive to local texture, wrinkle, and shade by maximizing their geometric consistency. Our method is end-to-end trainable, resulting in high fidelity depth estimation that predicts fine geometry faithful to the input real image. We demonstrate that our method outperforms the state-of-the-art human depth estimation and human shape recovery approaches on both real and rendered images.
Learning Centric Wireless Resource Allocation for Edge Computing: Algorithm and Experiment
Oct 29, 2020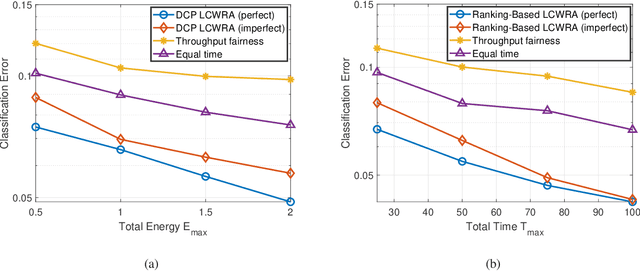
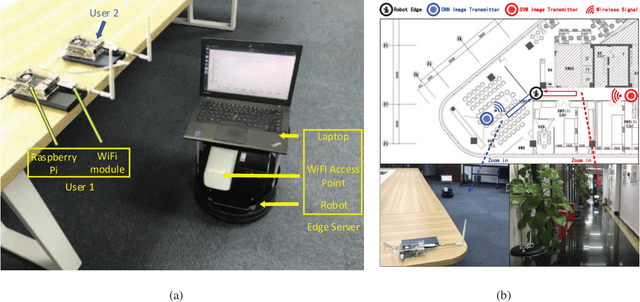

Edge intelligence is an emerging network architecture that integrates sensing, communication, computing components, and supports various machine learning applications, where a fundamental communication question is: how to allocate the limited wireless resources (such as time, energy) to the simultaneous model training of heterogeneous learning tasks? Existing methods ignore two important facts: 1) different models have heterogeneous demands on training data; 2) there is a mismatch between the simulated environment and the real-world environment. As a result, they could lead to low learning performance in practice. This paper proposes the learning centric wireless resource allocation (LCWRA) scheme that maximizes the worst learning performance of multiple classification tasks. Analysis shows that the optimal transmission time has an inverse power relationship with respect to the classification error. Finally, both simulation and experimental results are provided to verify the performance of the proposed LCWRA scheme and its robustness in real implementation.
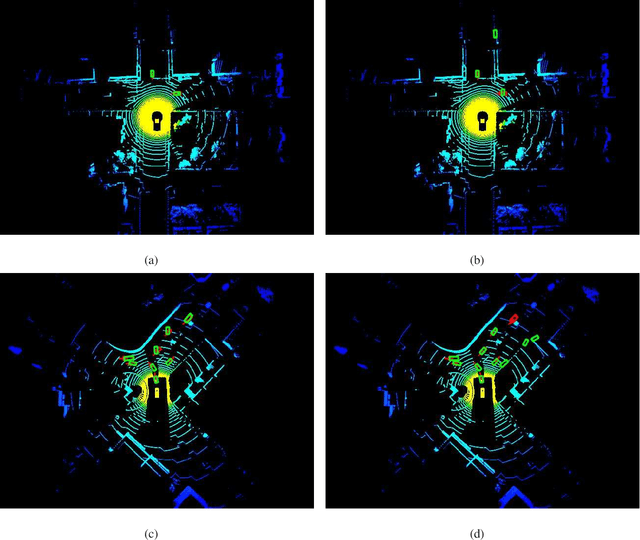
MAPFAST: A Deep Algorithm Selector for Multi Agent Path Finding using Shortest Path Embeddings
Feb 24, 2021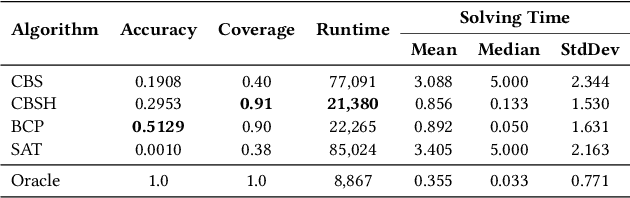
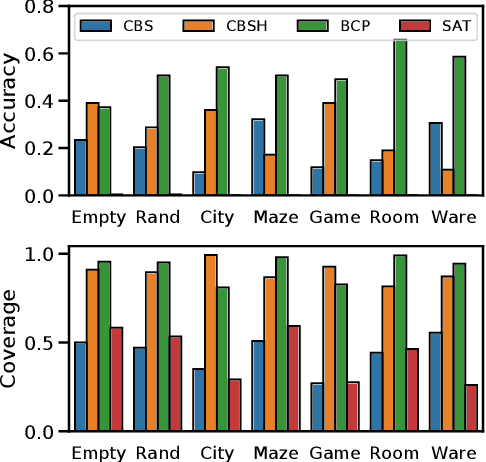
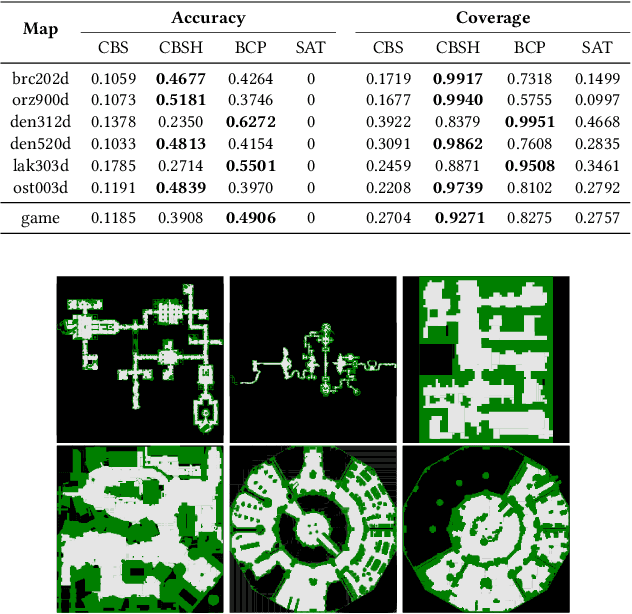
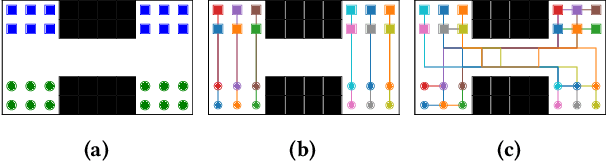
Solving the Multi-Agent Path Finding (MAPF) problem optimally is known to be NP-Hard for both make-span and total arrival time minimization. While many algorithms have been developed to solve MAPF problems, there is no dominating optimal MAPF algorithm that works well in all types of problems and no standard guidelines for when to use which algorithm. In this work, we develop the deep convolutional network MAPFAST (Multi-Agent Path Finding Algorithm SelecTor), which takes a MAPF problem instance and attempts to select the fastest algorithm to use from a portfolio of algorithms. We improve the performance of our model by including single-agent shortest paths in the instance embedding given to our model and by utilizing supplemental loss functions in addition to a classification loss. We evaluate our model on a large and diverse dataset of MAPF instances, showing that it outperforms all individual algorithms in its portfolio as well as the state-of-the-art optimal MAPF algorithm selector. We also provide an analysis of algorithm behavior in our dataset to gain a deeper understanding of optimal MAPF algorithms' strengths and weaknesses to help other researchers leverage different heuristics in algorithm designs.
SCEI: A Smart-Contract Driven Edge Intelligence Framework for IoT Systems
Mar 12, 2021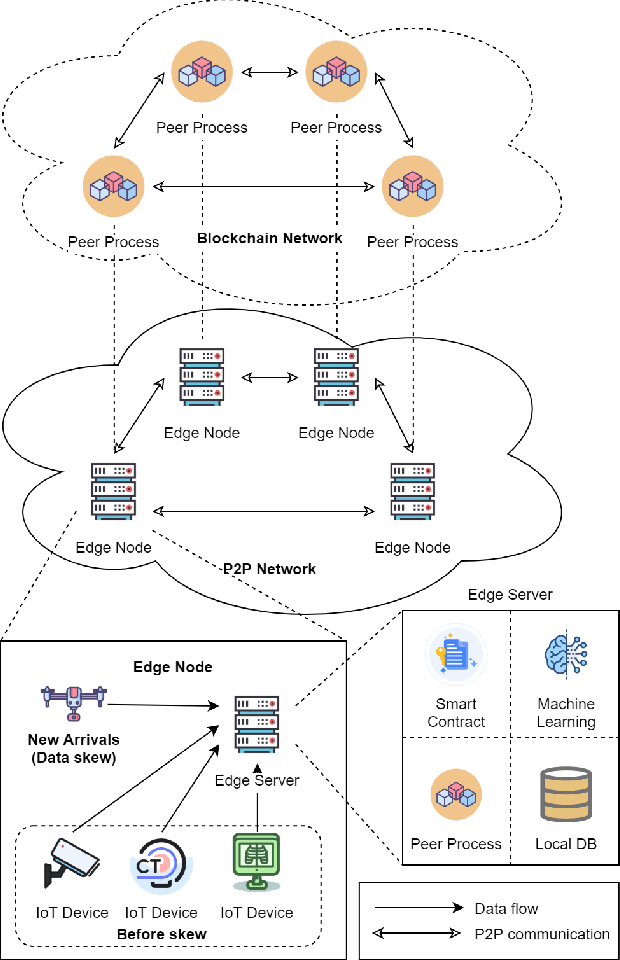
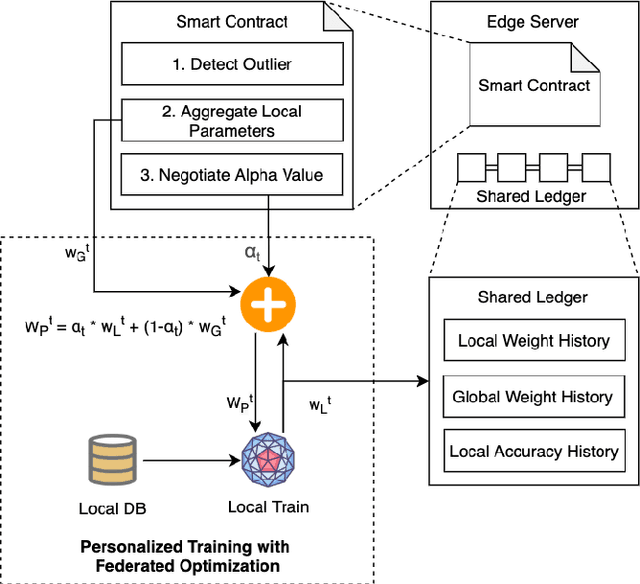
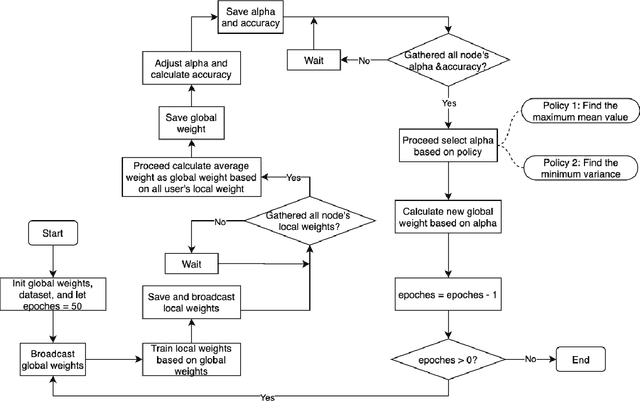
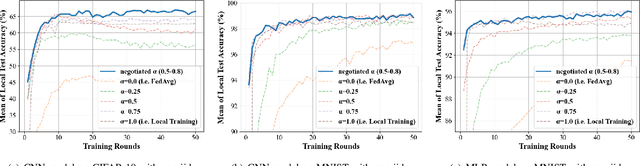
Federated learning (FL) utilizes edge computing devices to collaboratively train a shared model while each device can fully control its local data access. Generally, FL techniques focus on learning model on independent and identically distributed (iid) dataset and cannot achieve satisfiable performance on non-iid datasets (e.g. learning a multi-class classifier but each client only has a single class dataset). Some personalized approaches have been proposed to mitigate non-iid issues. However, such approaches cannot handle underlying data distribution shift, namely data distribution skew, which is quite common in real scenarios (e.g. recommendation systems learn user behaviors which change over time). In this work, we provide a solution to the challenge by leveraging smart-contract with federated learning to build optimized, personalized deep learning models. Specifically, our approach utilizes smart contract to reach consensus among distributed trainers on the optimal weights of personalized models. We conduct experiments across multiple models (CNN and MLP) and multiple datasets (MNIST and CIFAR-10). The experimental results demonstrate that our personalized learning models can achieve better accuracy and faster convergence compared to classic federated and personalized learning. Compared with the model given by baseline FedAvg algorithm, the average accuracy of our personalized learning models is improved by 2% to 20%, and the convergence rate is about 2$\times$ faster. Moreover, we also illustrate that our approach is secure against recent attack on distributed learning.