 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exploiting Storage for Computing: Computation Reuse in Collaborative Edge Computing
Jan 08, 2024
Collaborative Edge Computing (CEC) is a new edge computing paradigm that enables neighboring edge servers to share computational resources with each other. Although CEC can enhance the utilization of computational resources, it still suffers from resource waste. The primary reason is that end-users from the same area are likely to offload similar tasks to edge servers, thereby leading to duplicate computations. To improve system efficiency, the computation results of previously executed tasks can be cached and then reused by subsequent tasks. However, most existing computation reuse algorithms only consider one edge server, which significantly limits the effectiveness of computation reuse. To address this issue, this paper applies computation reuse in CEC networks to exploit the collaboration among edge servers. We formulate an optimization problem that aims to minimize the overall task response time and decompose it into a caching subproblem and a scheduling subproblem. By analyzing the properties of optimal solutions, we show that the optimal caching decisions can be efficiently searched using the bisection method. For the scheduling subproblem, we utilize projected gradient descent and backtracking to find a local minimum. Numerical results show that our algorithm significantly reduces the response time in various situations.
GLOP: Learning Global Partition and Local Construction for Solving Large-scale Routing Problems in Real-time
Dec 13, 2023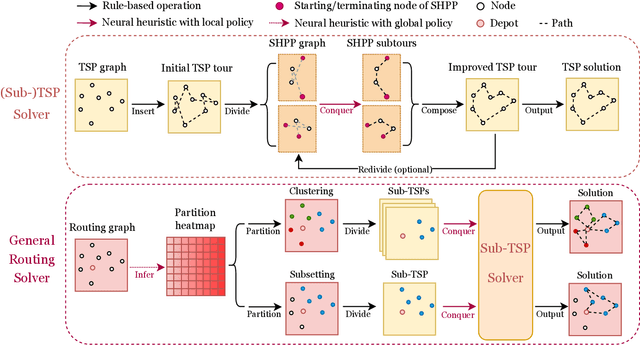
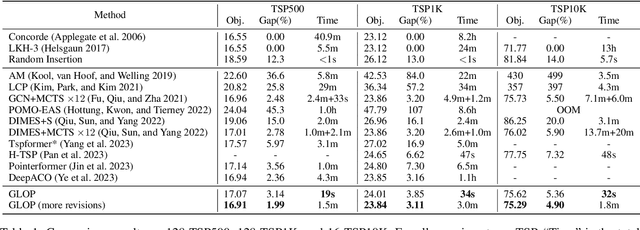
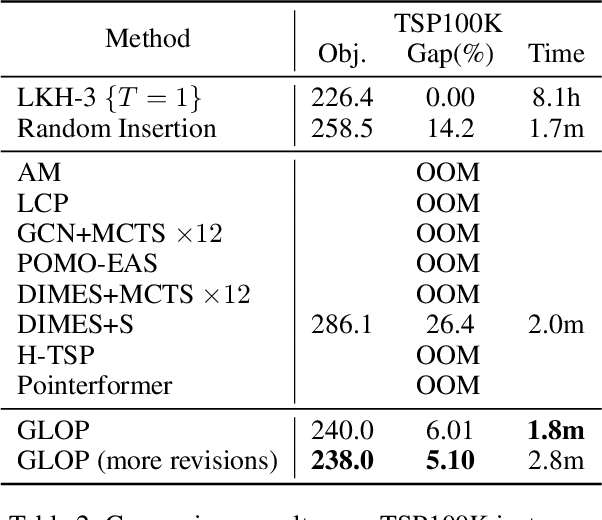
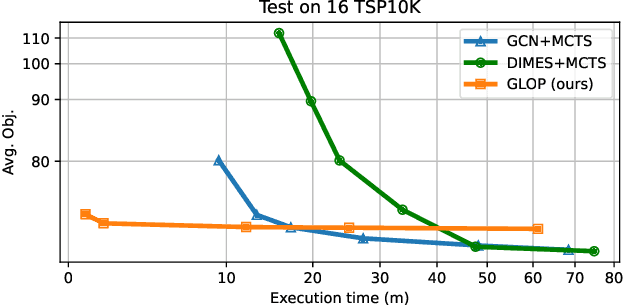
The recent end-to-end neural solvers have shown promise for small-scale routing problems but suffered from limited real-time scaling-up performance. This paper proposes GLOP (Global and Local Optimization Policies), a unified hierarchical framework that efficiently scales toward large-scale routing problems. GLOP partitions large routing problems into Travelling Salesman Problems (TSPs) and TSPs into Shortest Hamiltonian Path Problems. For the first time, we hybridize non-autoregressive neural heuristics for coarse-grained problem partitions and autoregressive neural heuristics for fine-grained route constructions, leveraging the scalability of the former and the meticulousness of the latter. Experimental results show that GLOP achieves competitive and state-of-the-art real-time performance on large-scale routing problems, including TSP, ATSP, CVRP, and PCTSP.
InRanker: Distilled Rankers for Zero-shot Information Retrieval
Jan 12, 2024Despite multi-billion parameter neural rankers being common components of state-of-the-art information retrieval pipelines, they are rarely used in production due to the enormous amount of compute required for inference. In this work, we propose a new method for distilling large rankers into their smaller versions focusing on out-of-domain effectiveness. We introduce InRanker, a version of monoT5 distilled from monoT5-3B with increased effectiveness on out-of-domain scenarios. Our key insight is to use language models and rerankers to generate as much as possible synthetic "in-domain" training data, i.e., data that closely resembles the data that will be seen at retrieval time. The pipeline consists of two distillation phases that do not require additional user queries or manual annotations: (1) training on existing supervised soft teacher labels, and (2) training on teacher soft labels for synthetic queries generated using a large language model. Consequently, models like monoT5-60M and monoT5-220M improved their effectiveness by using the teacher's knowledge, despite being 50x and 13x smaller, respectively. Models and code are available at https://github.com/unicamp-dl/InRanker.
Using Natural Language Inference to Improve Persona Extraction from Dialogue in a New Domain
Jan 12, 2024While valuable datasets such as PersonaChat provide a foundation for training persona-grounded dialogue agents, they lack diversity in conversational and narrative settings, primarily existing in the "real" world. To develop dialogue agents with unique personas, models are trained to converse given a specific persona, but hand-crafting these persona can be time-consuming, thus methods exist to automatically extract persona information from existing character-specific dialogue. However, these persona-extraction models are also trained on datasets derived from PersonaChat and struggle to provide high-quality persona information from conversational settings that do not take place in the real world, such as the fantasy-focused dataset, LIGHT. Creating new data to train models on a specific setting is human-intensive, thus prohibitively expensive. To address both these issues, we introduce a natural language inference method for post-hoc adapting a trained persona extraction model to a new setting. We draw inspiration from the literature of dialog natural language inference (NLI), and devise NLI-reranking methods to extract structured persona information from dialogue. Compared to existing persona extraction models, our method returns higher-quality extracted persona and requires less human annotation.
Mutual Enhancement of Large Language and Reinforcement Learning Models through Bi-Directional Feedback Mechanisms: A Case Study
Jan 12, 2024Large Language Models (LLMs) have demonstrated remarkable capabilities for reinforcement learning (RL) models, such as planning and reasoning capabilities. However, the problems of LLMs and RL model collaboration still need to be solved. In this study, we employ a teacher-student learning framework to tackle these problems, specifically by offering feedback for LLMs using RL models and providing high-level information for RL models with LLMs in a cooperative multi-agent setting. Within this framework, the LLM acts as a teacher, while the RL model acts as a student. The two agents cooperatively assist each other through a process of recursive help, such as "I help you help I help." The LLM agent supplies abstract information to the RL agent, enabling efficient exploration and policy improvement. In turn, the RL agent offers feedback to the LLM agent, providing valuable, real-time information that helps generate more useful tokens. This bi-directional feedback loop promotes optimization, exploration, and mutual improvement for both agents, enabling them to accomplish increasingly challenging tasks. Remarkably, we propose a practical algorithm to address the problem and conduct empirical experiments to evaluate the effectiveness of our method.
Inferring Stellar Parameters from Iodine-Imprinted Keck/HIRES Spectra with Machine Learning
Jan 12, 2024The properties of exoplanet host stars are traditionally characterized through a detailed forward-modeling analysis of high-resolution spectra. However, many exoplanet radial velocity surveys employ iodine-cell-calibrated spectrographs, such that the vast majority of spectra obtained include an imprinted forest of iodine absorption lines. For surveys that use iodine cells, iodine-free "template" spectra must be separately obtained for precise stellar characterization. These template spectra often require extensive additional observing time to obtain, and they are not always feasible to obtain for faint stars. In this paper, we demonstrate that machine learning methods can be applied to infer stellar parameters and chemical abundances from iodine-imprinted spectra with high accuracy and precision. The methods presented in this work are broadly applicable to any iodine-cell-calibrated spectrograph. We make publicly available our spectroscopic pipeline, the Cannon HIRES Iodine Pipeline (CHIP), which derives stellar parameters and 15 chemical abundances from iodine-imprinted spectra of FGK stars and which has been set up for ease of use with Keck/HIRES spectra. Our proof-of-concept offers an efficient new avenue to rapidly estimate a large number of stellar parameters even in the absence of an iodine-free template spectrum.
Mind Your Format: Towards Consistent Evaluation of In-Context Learning Improvements
Jan 12, 2024Large language models demonstrate a remarkable capability for learning to solve new tasks from a few examples. The prompt template, or the way the input examples are formatted to obtain the prompt, is an important yet often overlooked aspect of in-context learning. In this work, we conduct a comprehensive study of the template format's influence on the in-context learning performance. We evaluate the impact of the prompt template across models (from 770M to 70B parameters) and 4 standard classification datasets. We show that a poor choice of the template can reduce the performance of the strongest models and inference methods to a random guess level. More importantly, the best templates do not transfer between different setups and even between models of the same family. Our findings show that the currently prevalent approach to evaluation, which ignores template selection, may give misleading results due to different templates in different works. As a first step towards mitigating this issue, we propose Template Ensembles that aggregate model predictions across several templates. This simple test-time augmentation boosts average performance while being robust to the choice of random set of templates.
Graph Relation Distillation for Efficient Biomedical Instance Segmentation
Jan 12, 2024Instance-aware embeddings predicted by deep neural networks have revolutionized biomedical instance segmentation, but its resource requirements are substantial. Knowledge distillation offers a solution by transferring distilled knowledge from heavy teacher networks to lightweight yet high-performance student networks. However, existing knowledge distillation methods struggle to extract knowledge for distinguishing instances and overlook global relation information. To address these challenges, we propose a graph relation distillation approach for efficient biomedical instance segmentation, which considers three essential types of knowledge: instance-level features, instance relations, and pixel-level boundaries. We introduce two graph distillation schemes deployed at both the intra-image level and the inter-image level: instance graph distillation (IGD) and affinity graph distillation (AGD). IGD constructs a graph representing instance features and relations, transferring these two types of knowledge by enforcing instance graph consistency. AGD constructs an affinity graph representing pixel relations to capture structured knowledge of instance boundaries, transferring boundary-related knowledge by ensuring pixel affinity consistency. Experimental results on a number of biomedical datasets validate the effectiveness of our approach, enabling student models with less than $ 1\%$ parameters and less than $10\%$ inference time while achieving promising performance compared to teacher models.
NHANES-GCP: Leveraging the Google Cloud Platform and BigQuery ML for reproducible machine learning with data from the National Health and Nutrition Examination Survey
Jan 13, 2024Summary: NHANES, the National Health and Nutrition Examination Survey, is a program of studies led by the Centers for Disease Control and Prevention (CDC) designed to assess the health and nutritional status of adults and children in the United States (U.S.). NHANES data is frequently used by biostatisticians and clinical scientists to study health trends across the U.S., but every analysis requires extensive data management and cleaning before use and this repetitive data engineering collectively costs valuable research time and decreases the reproducibility of analyses. Here, we introduce NHANES-GCP, a Cloud Development Kit for Terraform (CDKTF) Infrastructure-as-Code (IaC) and Data Build Tool (dbt) resources built on the Google Cloud Platform (GCP) that automates the data engineering and management aspects of working with NHANES data. With current GCP pricing, NHANES-GCP costs less than $2 to run and less than $15/yr of ongoing costs for hosting the NHANES data, all while providing researchers with clean data tables that can readily be integrated for large-scale analyses. We provide examples of leveraging BigQuery ML to carry out the process of selecting data, integrating data, training machine learning and statistical models, and generating results all from a single SQL-like query. NHANES-GCP is designed to enhance the reproducibility of analyses and create a well-engineered NHANES data resource for statistics, machine learning, and fine-tuning Large Language Models (LLMs). Availability and implementation" NHANES-GCP is available at https://github.com/In-Vivo-Group/NHANES-GCP
Joint Extraction of Uyghur Medicine Knowledge with Edge Computing
Jan 13, 2024Medical knowledge extraction methods based on edge computing deploy deep learning models on edge devices to achieve localized entity and relation extraction. This approach avoids transferring substantial sensitive data to cloud data centers, effectively safeguarding the privacy of healthcare services. However, existing relation extraction methods mainly employ a sequential pipeline approach, which classifies relations between determined entities after entity recognition. This mode faces challenges such as error propagation between tasks, insufficient consideration of dependencies between the two subtasks, and the neglect of interrelations between different relations within a sentence. To address these challenges, a joint extraction model with parameter sharing in edge computing is proposed, named CoEx-Bert. This model leverages shared parameterization between two models to jointly extract entities and relations. Specifically, CoEx-Bert employs two models, each separately sharing hidden layer parameters, and combines these two loss functions for joint backpropagation to optimize the model parameters. Additionally, it effectively resolves the issue of entity overlapping when extracting knowledge from unstructured Uyghur medical texts by considering contextual relations. Finally, this model is deployed on edge devices for real-time extraction and inference of Uyghur medical knowledge. Experimental results demonstrate that CoEx-Bert outperforms existing state-of-the-art methods, achieving accuracy, recall, and F1 scores of 90.65\%, 92.45\%, and 91.54\%, respectively, in the Uyghur traditional medical literature dataset. These improvements represent a 6.45\% increase in accuracy, a 9.45\% increase in recall, and a 7.95\% increase in F1 score compared to the baseline.