 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Federated Depression Detection from Multi-SourceMobile Health Data
Feb 06, 2021

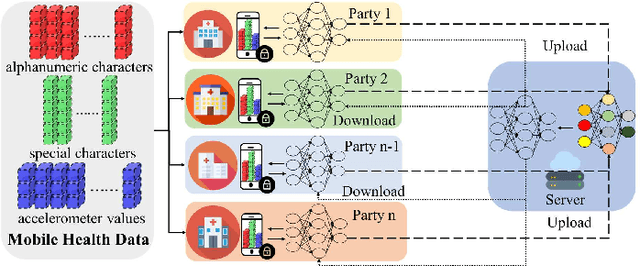
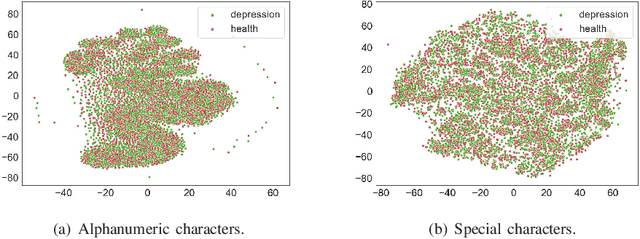
Depression is one of the most common mental illness problems, and the symptoms shown by patients are not consistent, making it difficult to diagnose in the process of clinical practice and pathological research.Although researchers hope that artificial intelligence can contribute to the diagnosis and treatment of depression, the traditional centralized machine learning needs to aggregate patient data, and the data privacy of patients with mental illness needs to be strictly confidential, which hinders machine learning algorithms clinical application.To solve the problem of privacy of the medical history of patients with depression, we implement federated learning to analyze and diagnose depression. First, we propose a general multi-view federated learning framework using multi-source data,which can extend any traditional machine learning model to support federated learning across different institutions or parties.Secondly, we adopt late fusion methods to solve the problem of inconsistent time series of multi-view data.Finally, we compare the federated framework with other cooperative learning frameworks in performance and discuss the related results.
Capture the Bot: Using Adversarial Examples to Improve CAPTCHA Robustness to Bot Attacks
Oct 30, 2020



To this date, CAPTCHAs have served as the first line of defense preventing unauthorized access by (malicious) bots to web-based services, while at the same time maintaining a trouble-free experience for human visitors. However, recent work in the literature has provided evidence of sophisticated bots that make use of advancements in machine learning (ML) to easily bypass existing CAPTCHA-based defenses. In this work, we take the first step to address this problem. We introduce CAPTURE, a novel CAPTCHA scheme based on adversarial examples. While typically adversarial examples are used to lead an ML model astray, to the best of our knowledge, CAPTURE is the first work to make a "good use" of such mechanisms. Our empirical evaluations show that CAPTURE can produce CAPTCHAs that are easy to solve by humans while at the same time, effectively thwarting ML-based bot solvers.
Resource Allocation in Multi-armed Bandit Exploration: Overcoming Nonlinear Scaling with Adaptive Parallelism
Oct 31, 2020
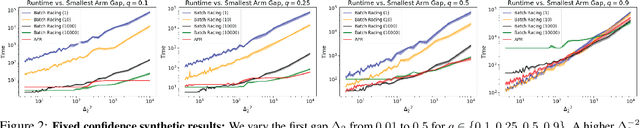
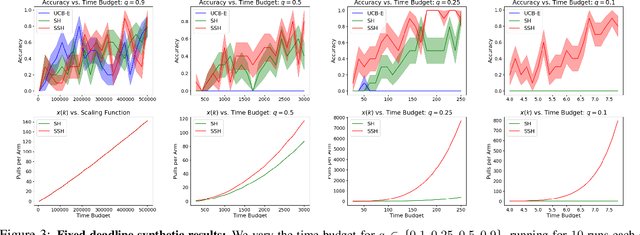
We study exploration in stochastic multi-armed bandits when we have access to a divisible resource, and can allocate varying amounts of this resource to arm pulls. By allocating more resources to a pull, we can compute the outcome faster to inform subsequent decisions about which arms to pull. However, since distributed environments do not scale linearly, executing several arm pulls in parallel, and hence less resources per pull, may result in better throughput. For example, in simulation-based scientific studies, an expensive simulation can be sped up by running it on multiple cores. This speed-up is, however, partly offset by the communication among cores and overheads, which results in lower throughput than if fewer cores were allocated to run more trials in parallel. We explore these trade-offs in the fixed confidence setting, where we need to find the best arm with a given success probability, while minimizing the time to do so. We propose an algorithm which trades off between information accumulation and throughout and show that the time taken can be upper bounded by the solution of a dynamic program whose inputs are the squared gaps between the suboptimal and optimal arms. We prove a matching hardness result which demonstrates that the above dynamic program is fundamental to this problem. Next, we propose and analyze an algorithm for the fixed deadline setting, where we are given a time deadline and need to maximize the success probability of finding the best arm. We corroborate these theoretical insights with an empirical evaluation.
Segmenting Microcalcifications in Mammograms and its Applications
Feb 01, 2021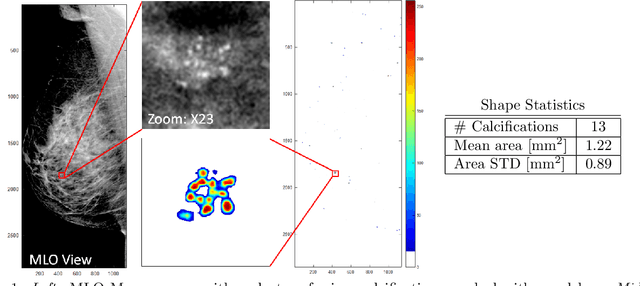
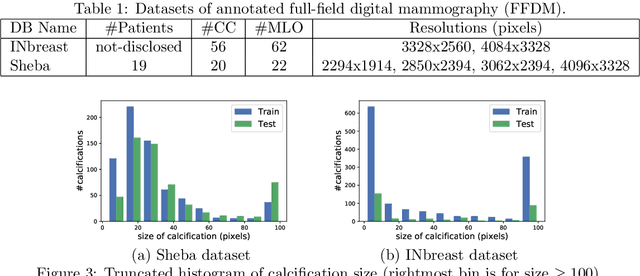
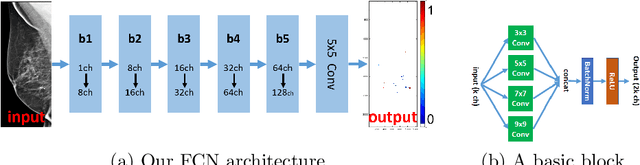

Microcalcifications are small deposits of calcium that appear in mammograms as bright white specks on the soft tissue background of the breast. Microcalcifications may be a unique indication for Ductal Carcinoma in Situ breast cancer, and therefore their accurate detection is crucial for diagnosis and screening. Manual detection of these tiny calcium residues in mammograms is both time-consuming and error-prone, even for expert radiologists, since these microcalcifications are small and can be easily missed. Existing computerized algorithms for detecting and segmenting microcalcifications tend to suffer from a high false-positive rate, hindering their widespread use. In this paper, we propose an accurate calcification segmentation method using deep learning. We specifically address the challenge of keeping the false positive rate low by suggesting a strategy for focusing the hard pixels in the training phase. Furthermore, our accurate segmentation enables extracting meaningful statistics on clusters of microcalcifications.
Fast Design Space Exploration of Nonlinear Systems: Part I
Apr 05, 2021
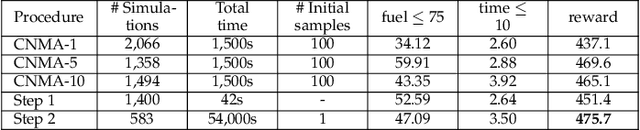
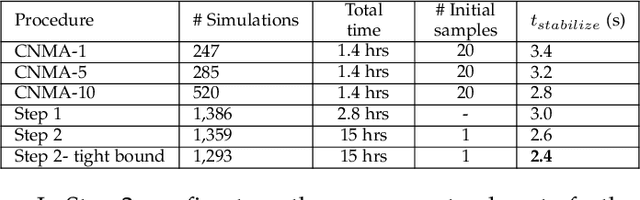
System design tools are often only available as blackboxes with complex nonlinear relationships between inputs and outputs. Blackboxes typically run in the forward direction: for a given design as input they compute an output representing system behavior. Most cannot be run in reverse to produce an input from requirements on output. Thus, finding a design satisfying a requirement is often a trial-and-error process without assurance of optimality. Finding designs concurrently satisfying multiple requirements is harder because designs satisfying individual requirements may conflict with each other. Compounding the hardness are the facts that blackbox evaluations can be expensive and sometimes fail to produce an output due to non-convergence of underlying numerical algorithms. This paper presents CNMA (Constrained optimization with Neural networks, MILP solvers and Active Learning), a new optimization method for blackboxes. It is conservative in the number of blackbox evaluations. Any designs it finds are guaranteed to satisfy all requirements. It is resilient to the failure of blackboxes to compute outputs. It tries to sample only the part of the design space relevant to solving the design problem, leveraging the power of neural networks, MILPs, and a new learning-from-failure feedback loop. The paper also presents parallel CNMA that improves the efficiency and quality of solutions over the sequential version, and tries to steer it away from local optima. CNMA's performance is evaluated for seven nonlinear design problems of 8 (2 problems), 10, 15, 36 and 60 real-valued dimensions and one with 186 binary dimensions. It is shown that CNMA improves the performance of stable, off-the-shelf implementations of Bayesian Optimization and Nelder Mead and Random Search by 1%-87% for a given fixed time and function evaluation budget. Note, that these implementations did not always return solutions.
Selecting Data Adaptive Learner from Multiple Deep Learners using Bayesian Networks
Aug 18, 2020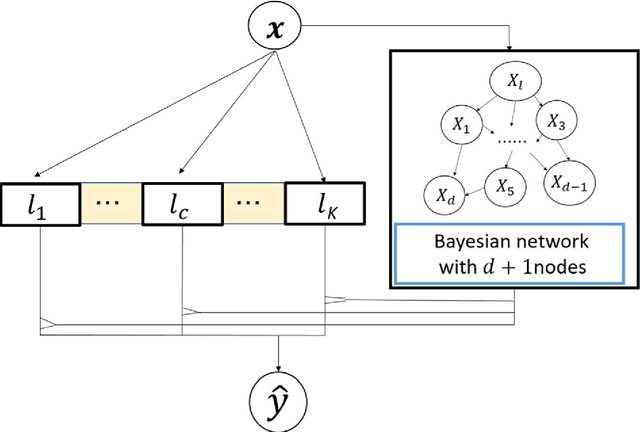
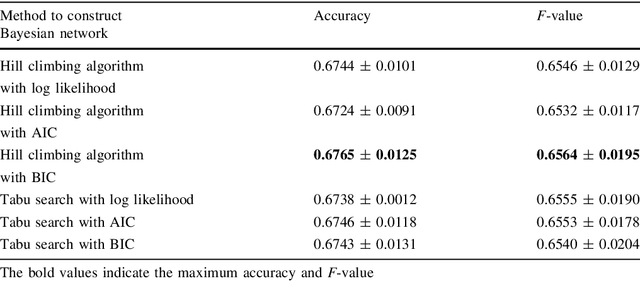
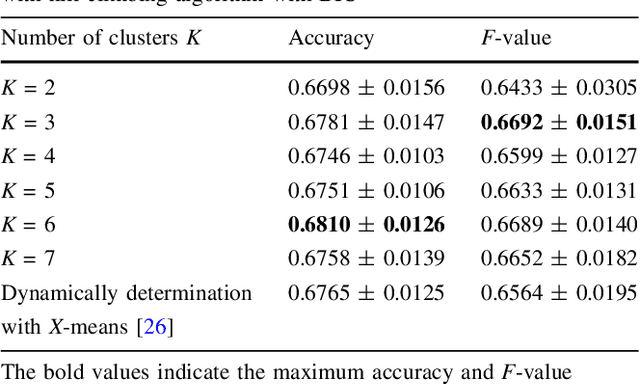
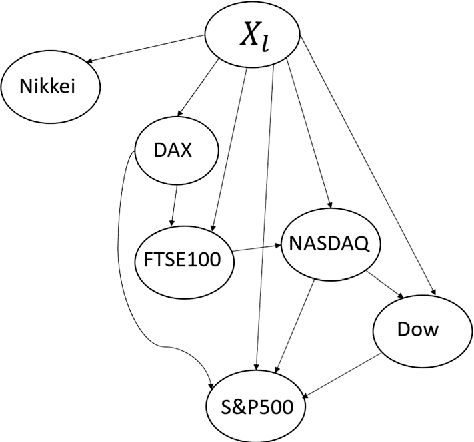
A method to predict time-series using multiple deep learners and a Bayesian network is proposed. In this study, the input explanatory variables are Bayesian network nodes that are associated with learners. Training data are divided using K-means clustering, and multiple deep learners are trained depending on the cluster. A Bayesian network is used to determine which deep learner is in charge of predicting a time-series. We determine a threshold value and select learners with a posterior probability equal to or greater than the threshold value, which could facilitate more robust prediction. The proposed method is applied to financial time-series data, and the predicted results for the Nikkei 225 index are demonstrated.
Kalman filter based MIMO CSI phase recovery for COTS WiFi devices
Jan 15, 2021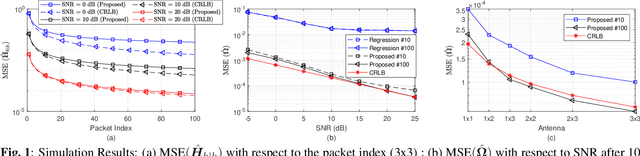

Recently channel state information (CSI) measurements from commercial multi input multi output (MIMO) WiFi systems have been ubiquitously used for different wireless sensing applications. However, the phase of the CSI realizations is usually distorted severely by phase errors due to the hardware impairments, which significantly reduce the sensing performance. In this paper, we directly utilize the modeling of the phase distortions caused by the hardware impairments and propose an adaptive CSI estimation approach based on Kalman filter (KF) with maximum a posteriori (MAP) estimation that considers the CSI from the previous time. The performance of the proposed algorithm is compared against the Cramer Rao lower bound (CRLB). Simulation and experimental results demonstrate that our approach can track the channel variations while eliminating the phase errors accurately.
Multimodal dynamics modeling for off-road autonomous vehicles
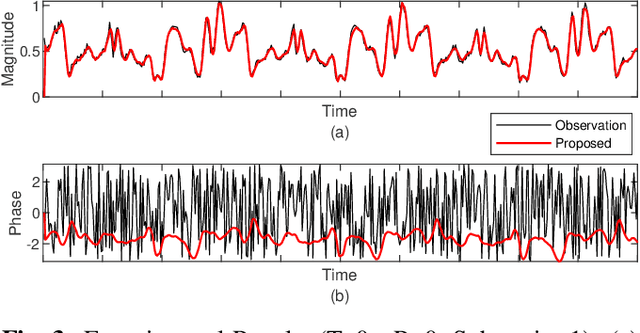
Nov 23, 2020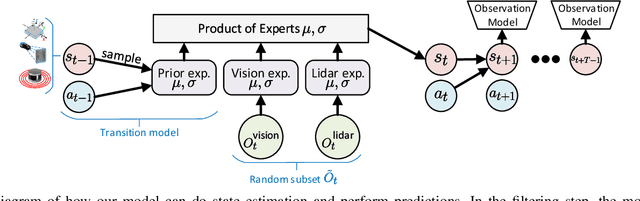

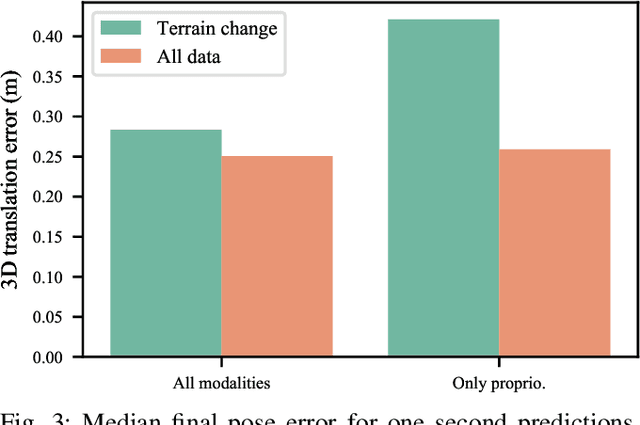

Dynamics modeling in outdoor and unstructured environments is difficult because different elements in the environment interact with the robot in ways that can be hard to predict. Leveraging multiple sensors to perceive maximal information about the robot's environment is thus crucial when building a model to perform predictions about the robot's dynamics with the goal of doing motion planning. We design a model capable of long-horizon motion predictions, leveraging vision, lidar and proprioception, which is robust to arbitrarily missing modalities at test time. We demonstrate in simulation that our model is able to leverage vision to predict traction changes. We then test our model using a real-world challenging dataset of a robot navigating through a forest, performing predictions in trajectories unseen during training. We try different modality combinations at test time and show that, while our model performs best when all modalities are present, it is still able to perform better than the baseline even when receiving only raw vision input and no proprioception, as well as when only receiving proprioception. Overall, our study demonstrates the importance of leveraging multiple sensors when doing dynamics modeling in outdoor conditions.
Ivy: Templated Deep Learning for Inter-Framework Portability
Feb 15, 2021

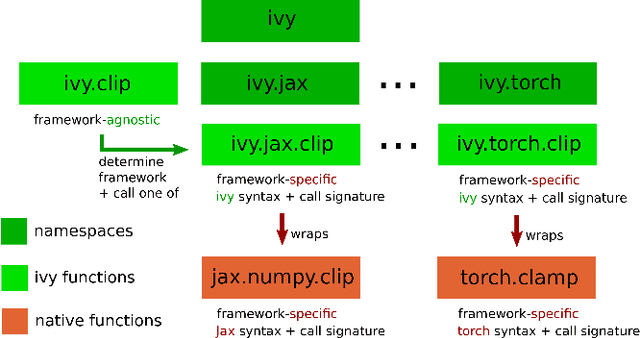

We introduce Ivy, a templated Deep Learning (DL) framework which abstracts existing DL frameworks such that their core functions all exhibit consistent call signatures, syntax and input-output behaviour. Ivy allows high-level framework-agnostic functions to be implemented through the use of framework templates. The framework templates act as placeholders for the specific framework at development time, which are then determined at runtime. The portability of Ivy functions enables their use in projects of any supported framework. Ivy currently supports TensorFlow, PyTorch, MXNet, Jax and NumPy. Alongside Ivy, we release four pure-Ivy libraries for mechanics, 3D vision, robotics, and differentiable environments. Through our evaluations, we show that Ivy can significantly reduce lines of code with a runtime overhead of less than 1% in most cases. We welcome developers to join the Ivy community by writing their own functions, layers and libraries in Ivy, maximizing their audience and helping to accelerate DL research through the creation of lifelong inter-framework codebases. More information can be found at https://ivy-dl.org.
Learning Whole-Image Descriptors for Real-time Loop Detection andKidnap Recovery under Large Viewpoint Difference
Apr 15, 2019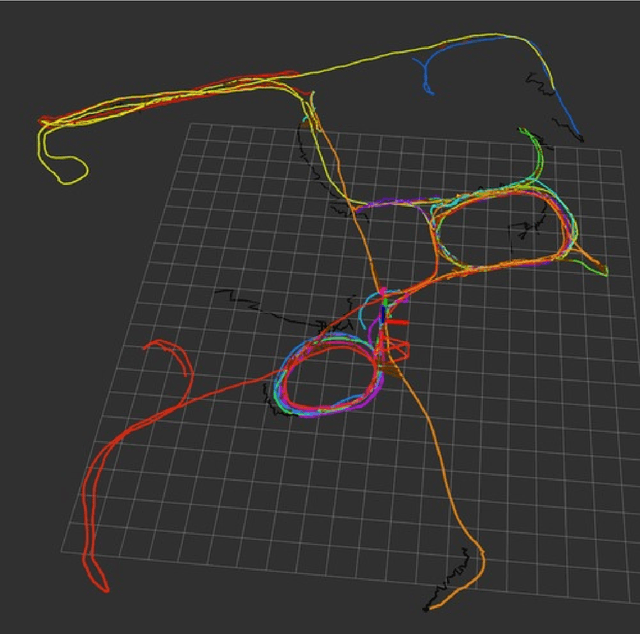
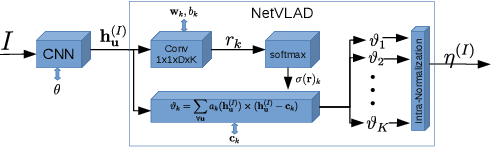
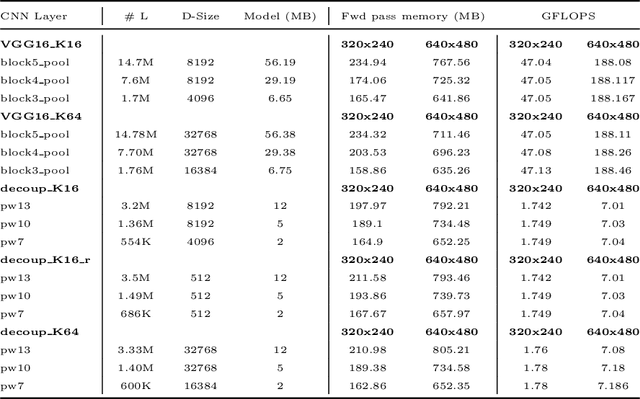
We present a real-time stereo visual-inertial-SLAM system which is able to recover from complicatedkidnap scenarios and failures online in realtime. We propose to learn the whole-image-descriptorin a weakly supervised manner based on NetVLAD and decoupled convolutions. We analyse thetraining difficulties in using standard loss formulations and propose an allpairloss and show itseffect through extensive experiments. Compared to standard NetVLAD, our network takes an orderof magnitude fewer computations and model parameters, as a result runs about three times faster.We evaluate the representation power of our descriptor on standard datasets with precision-recall.Unlike previous loop detection methods which have been evaluated only on fronto-parallel revisits,we evaluate the performace of our method with competing methods on scenarios involving largeviewpoint difference. Finally, we present the fully functional system with relative computation andhandling of multiple world co-ordinate system which is able to reduce odometry drift, recover fromcomplicated kidnap scenarios and random odometry failures. We open source our fully functional system as an add-on for the popular VINS-Fusion.