 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Contrastive Learning Improves Critical Event Prediction in COVID-19 Patients
Jan 11, 2021
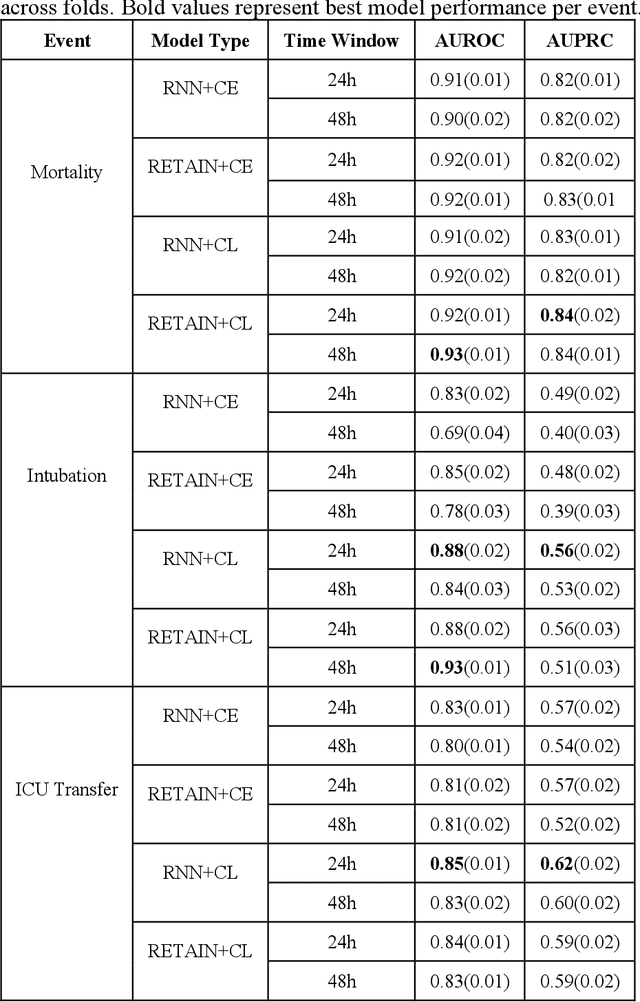
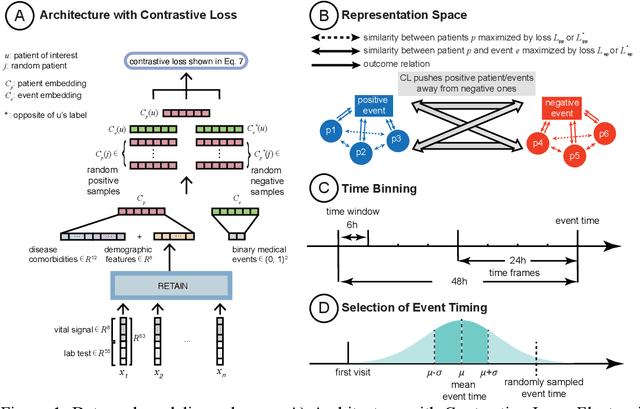
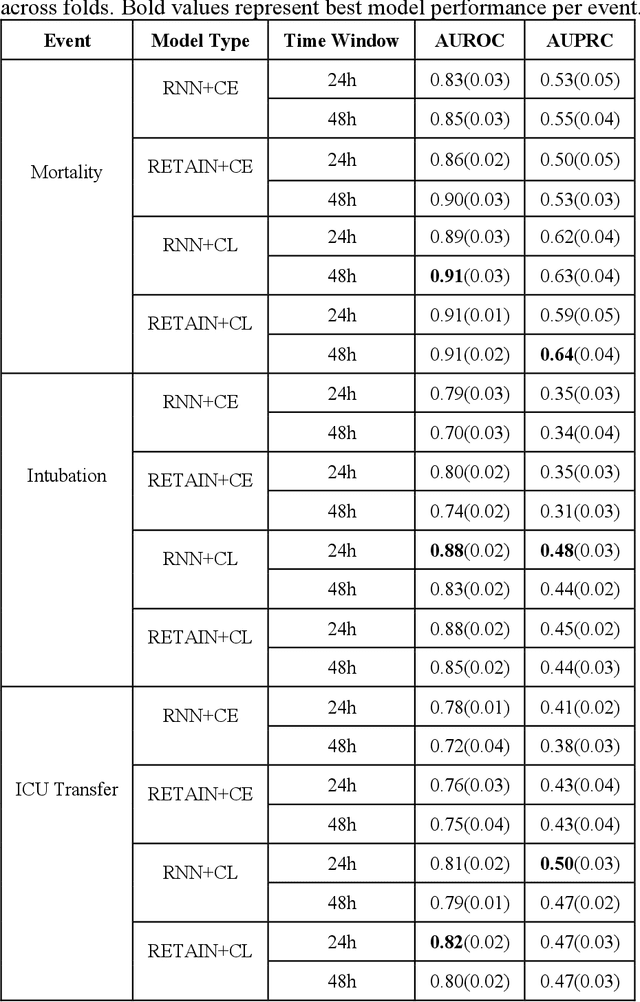
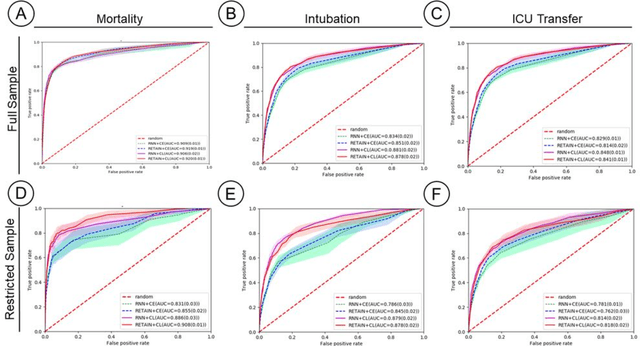
Machine Learning (ML) models typically require large-scale, balanced training data to be robust, generalizable, and effective in the context of healthcare. This has been a major issue for developing ML models for the coronavirus-disease 2019 (COVID-19) pandemic where data is highly imbalanced, particularly within electronic health records (EHR) research. Conventional approaches in ML use cross-entropy loss (CEL) that often suffers from poor margin classification. For the first time, we show that contrastive loss (CL) improves the performance of CEL especially for imbalanced EHR data and the related COVID-19 analyses. This study has been approved by the Institutional Review Board at the Icahn School of Medicine at Mount Sinai. We use EHR data from five hospitals within the Mount Sinai Health System (MSHS) to predict mortality, intubation, and intensive care unit (ICU) transfer in hospitalized COVID-19 patients over 24 and 48 hour time windows. We train two sequential architectures (RNN and RETAIN) using two loss functions (CEL and CL). Models are tested on full sample data set which contain all available data and restricted data set to emulate higher class imbalance.CL models consistently outperform CEL models with the restricted data set on these tasks with differences ranging from 0.04 to 0.15 for AUPRC and 0.05 to 0.1 for AUROC. For the restricted sample, only the CL model maintains proper clustering and is able to identify important features, such as pulse oximetry. CL outperforms CEL in instances of severe class imbalance, on three EHR outcomes with respect to three performance metrics: predictive power, clustering, and feature importance. We believe that the developed CL framework can be expanded and used for EHR ML work in general.
An Online Multilingual Hate speech Recognition System
Nov 24, 2020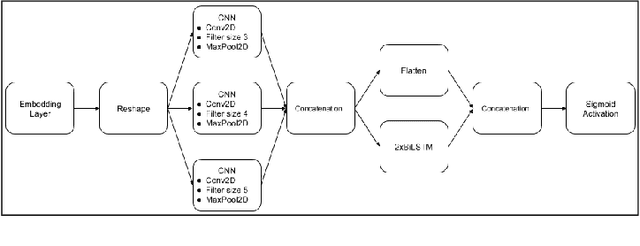
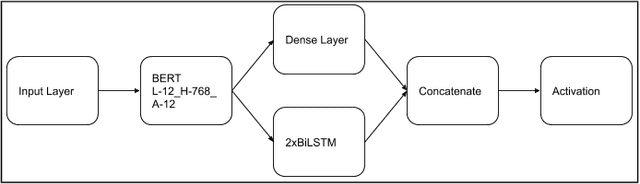

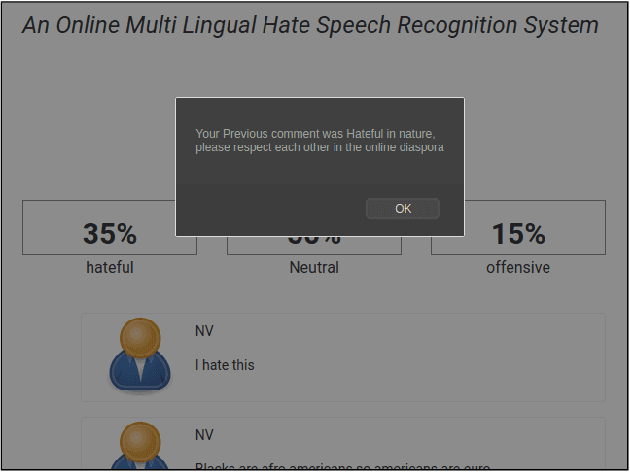
The exponential increase in the use of the Internet and social media over the last two decades has changed human interaction. This has led to many positive outcomes, but at the same time it has brought risks and harms. While the volume of harmful content online, such as hate speech, is not manageable by humans, interest in the academic community to investigate automated means for hate speech detection has increased. In this study, we analyse six publicly available datasets by combining them into a single homogeneous dataset and classify them into three classes, abusive, hateful or neither. We create a baseline model and we improve model performance scores using various optimisation techniques. After attaining a competitive performance score, we create a tool which identifies and scores a page with effective metric in near-real time and uses the same as feedback to re-train our model. We prove the competitive performance of our multilingual model on two langauges, English and Hindi, leading to comparable or superior performance to most monolingual models.
Dynamically Switching Human Prediction Models for Efficient Planning
Mar 13, 2021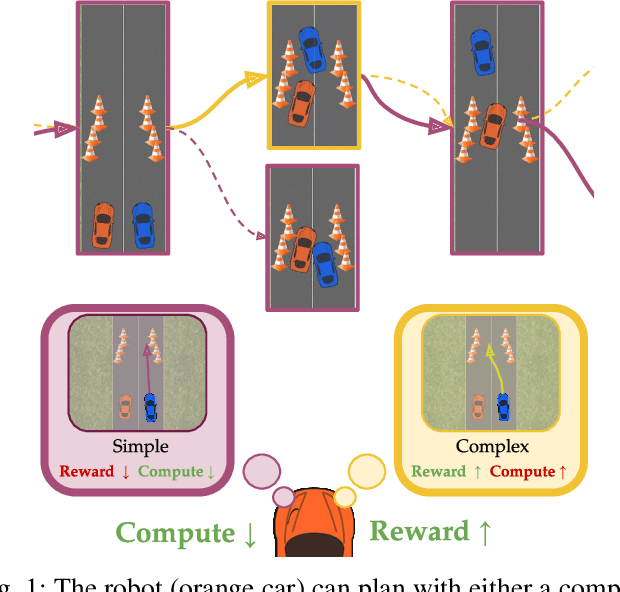
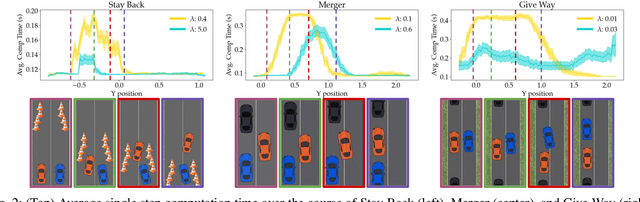
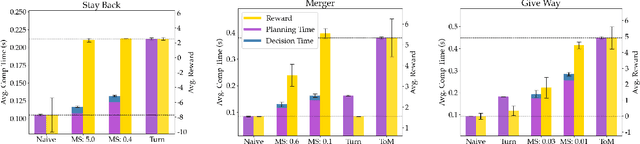
As environments involving both robots and humans become increasingly common, so does the need to account for people during planning. To plan effectively, robots must be able to respond to and sometimes influence what humans do. This requires a human model which predicts future human actions. A simple model may assume the human will continue what they did previously; a more complex one might predict that the human will act optimally, disregarding the robot; whereas an even more complex one might capture the robot's ability to influence the human. These models make different trade-offs between computational time and performance of the resulting robot plan. Using only one model of the human either wastes computational resources or is unable to handle critical situations. In this work, we give the robot access to a suite of human models and enable it to assess the performance-computation trade-off online. By estimating how an alternate model could improve human prediction and how that may translate to performance gain, the robot can dynamically switch human models whenever the additional computation is justified. Our experiments in a driving simulator showcase how the robot can achieve performance comparable to always using the best human model, but with greatly reduced computation.
Deep Learning for Real-time Gravitational Wave Detection and Parameter Estimation with LIGO Data
Dec 11, 2017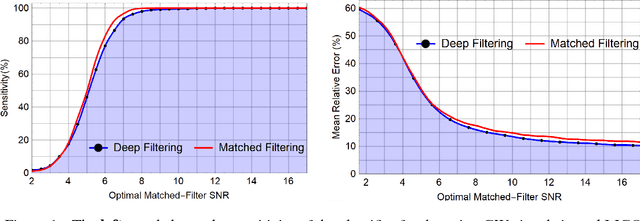
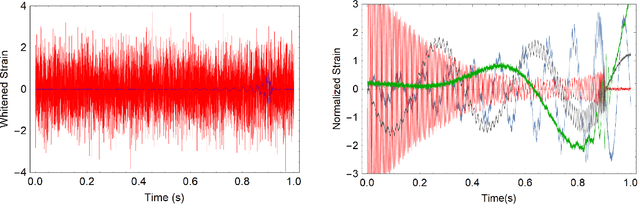
The recent Nobel-prize-winning detections of gravitational waves from merging black holes and the subsequent detection of the collision of two neutron stars in coincidence with electromagnetic observations have inaugurated a new era of multimessenger astrophysics. To enhance the scope of this emergent science, we proposed the use of deep convolutional neural networks for the detection and characterization of gravitational wave signals in real-time. This method, Deep Filtering, was initially demonstrated using simulated LIGO noise. In this article, we present the extension of Deep Filtering using real data from the first observing run of LIGO, for both detection and parameter estimation of gravitational waves from binary black hole mergers with continuous data streams from multiple LIGO detectors. We show for the first time that machine learning can detect and estimate the true parameters of a real GW event observed by LIGO. Our comparisons show that Deep Filtering is far more computationally efficient than matched-filtering, while retaining similar sensitivity and lower errors, allowing real-time processing of weak time-series signals in non-stationary non-Gaussian noise, with minimal resources, and also enables the detection of new classes of gravitational wave sources that may go unnoticed with existing detection algorithms. This approach is uniquely suited to enable coincident detection campaigns of gravitational waves and their multimessenger counterparts in real-time.
HyperMorph: Amortized Hyperparameter Learning for Image Registration
Jan 04, 2021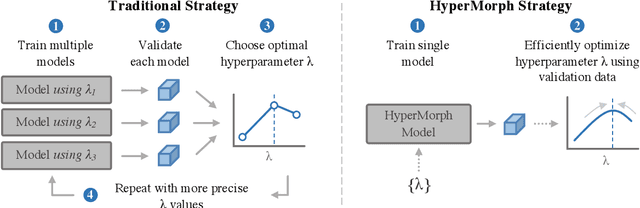

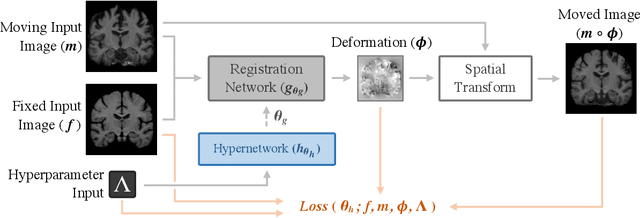
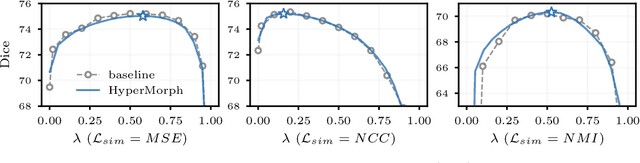
We present HyperMorph, a learning-based strategy for deformable image registration that removes the need to tune important registration hyperparameters during training. Classical registration methods solve an optimization problem to find a set of spatial correspondences between two images, while learning-based methods leverage a training dataset to learn a function that generates these correspondences. The quality of the results for both types of techniques depends greatly on the choice of hyperparameters. Unfortunately, hyperparameter tuning is time-consuming and typically involves training many separate models with various hyperparameter values, potentially leading to suboptimal results. To address this inefficiency, we introduce amortized hyperparameter learning for image registration, a novel strategy to learn the effects of hyperparameters on deformation fields. The proposed framework learns a hypernetwork that takes in an input hyperparameter and modulates a registration network to produce the optimal deformation field for that hyperparameter value. In effect, this strategy trains a single, rich model that enables rapid, fine-grained discovery of hyperparameter values from a continuous interval at test-time. We demonstrate that this approach can be used to optimize multiple hyperparameters considerably faster than existing search strategies, leading to a reduced computational and human burden and increased flexibility. We also show that this has several important benefits, including increased robustness to initialization and the ability to rapidly identify optimal hyperparameter values specific to a registration task, dataset, or even a single anatomical region - all without retraining the HyperMorph model. Our code is publicly available at http://voxelmorph.mit.edu.
A Termination Criterion for Probabilistic PointClouds Registration
Oct 10, 2020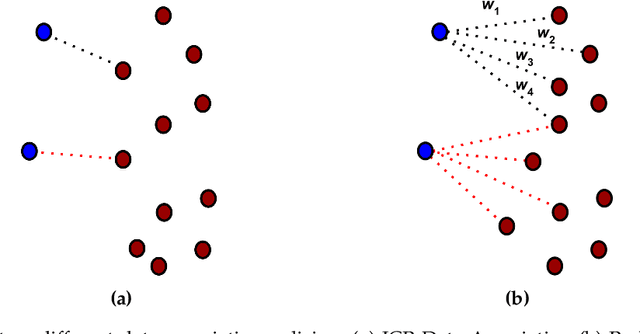
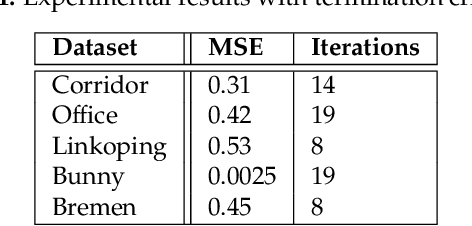
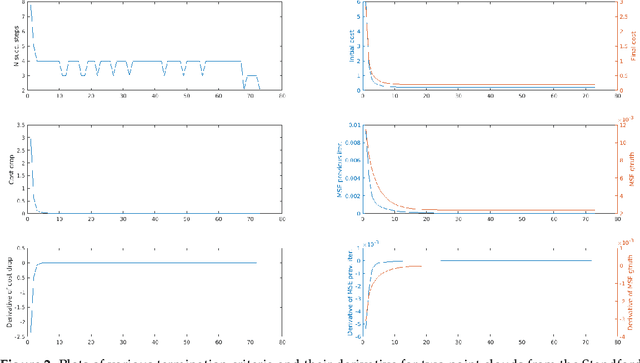
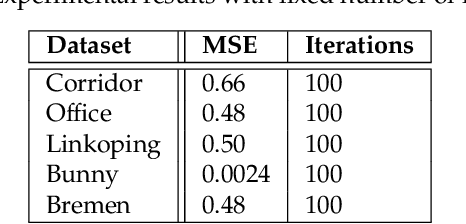
Probabilistic Point Clouds Registration (PPCR) is an algorithm that, in its multi-iteration version, outperformed state of the art algorithms for local point clouds registration. However, its performances have been tested using a fixed high number of iterations. To be of practical usefulness, we think that the algorithm should decide by itself when to stop, to avoid an excessive number of iterations and, therefore, wasting computational time. With this work, we compare different termination criterion on several datasets and prove that the chosen one produce very good results that are comparable to those obtained using a very high number of iterations while saving computational time.
Transient Information Adaptation of Artificial Intelligence: Towards Sustainable Data Processes in Complex Projects
Mar 27, 2021Large scale projects increasingly operate in complicated settings whilst drawing on an array of complex data-points, which require precise analysis for accurate control and interventions to mitigate possible project failure. Coupled with a growing tendency to rely on new information systems and processes in change projects, 90% of megaprojects globally fail to achieve their planned objectives. Renewed interest in the concept of Artificial Intelligence (AI) against a backdrop of disruptive technological innovations, seeks to enhance project managers cognitive capacity through the project lifecycle and enhance project excellence. However, despite growing interest there remains limited empirical insights on project managers ability to leverage AI for cognitive load enhancement in complex settings. As such this research adopts an exploratory sequential linear mixed methods approach to address unresolved empirical issues on transient adaptations of AI in complex projects, and the impact on cognitive load enhancement. Initial thematic findings from semi-structured interviews with domain experts, suggest that in order to leverage AI technologies and processes for sustainable cognitive load enhancement with complex data over time, project managers require improved knowledge and access to relevant technologies that mediate data processes in complex projects, but equally reflect application across different project phases. These initial findings support further hypothesis testing through a larger quantitative study incorporating structural equation modelling to examine the relationship between artificial intelligence and project managers cognitive load with project data in complex contexts.
Combinatorial Bandits under Strategic Manipulations
Feb 25, 2021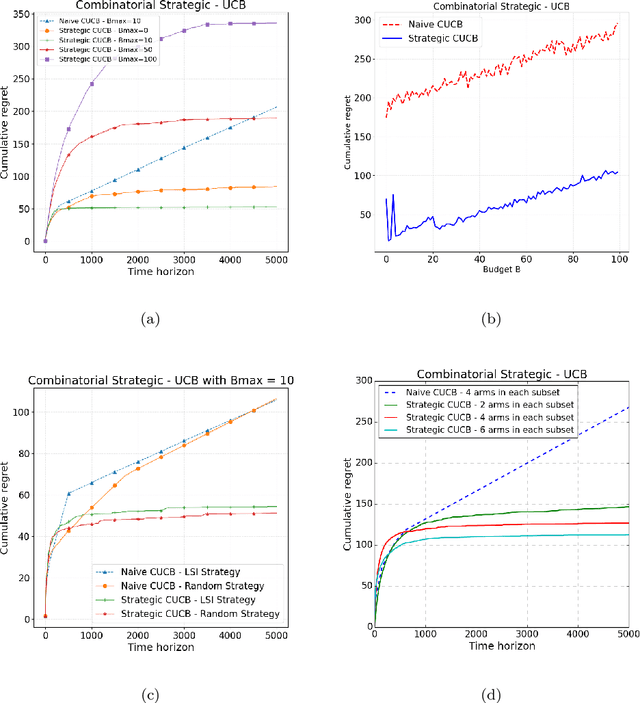
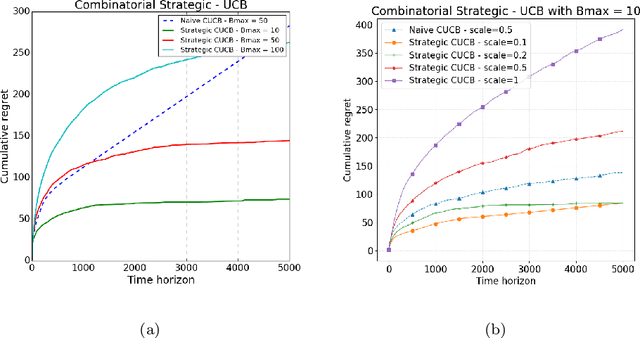
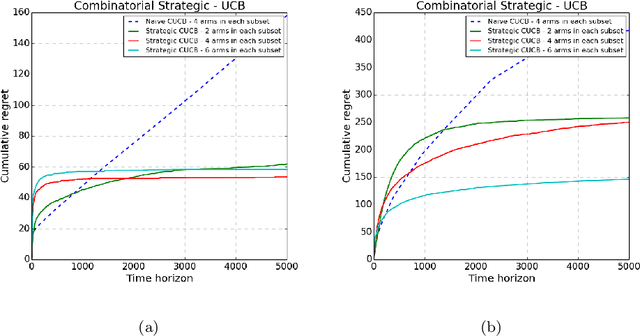
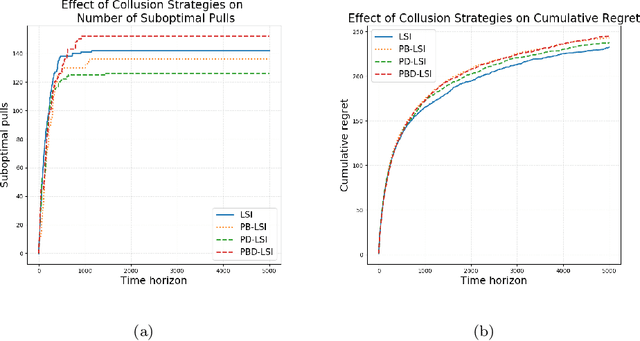
We study the problem of combinatorial multi-armed bandits (CMAB) under strategic manipulations of rewards, where each arm can modify the emitted reward signals for its own interest. Our setting elaborates a more realistic model of adaptive arms that imposes relaxed assumptions compared to adversarial corruptions and adversarial attacks. Algorithms designed under strategic arms gain robustness in real applications while avoiding being overcautious and hampering the performance. We bridge the gap between strategic manipulations and adversarial attacks by investigating the optimal colluding strategy among arms under the MAB problem. We then propose a strategic variant of the combinatorial UCB algorithm, which has a regret of at most $O(m\log T + m B_{max})$ under strategic manipulations, where $T$ is the time horizon, $m$ is the number of arms, and $B_{max}$ is the maximum budget. We further provide lower bounds on the strategic budgets for attackers to incur certain regret of the bandit algorithm. Extensive experiments corroborate our theoretical findings on robustness and regret bounds, in a variety of regimes of manipulation budgets.
A Topological Approach for Motion Track Discrimination
Feb 10, 2021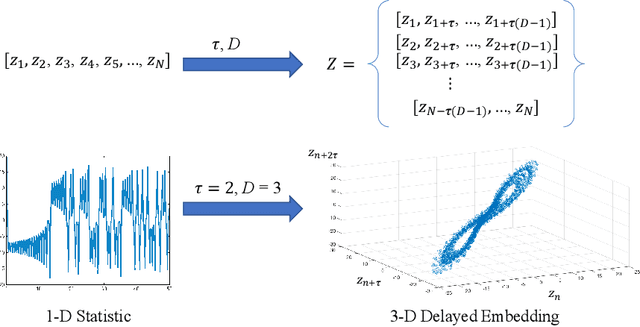
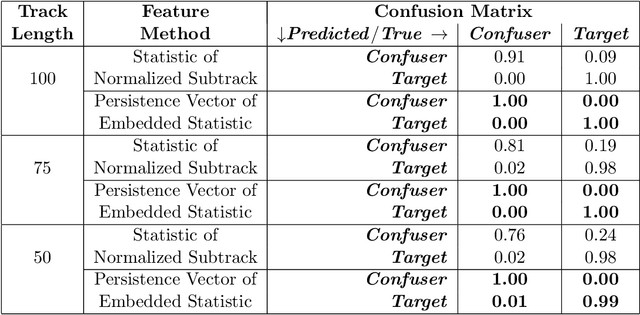
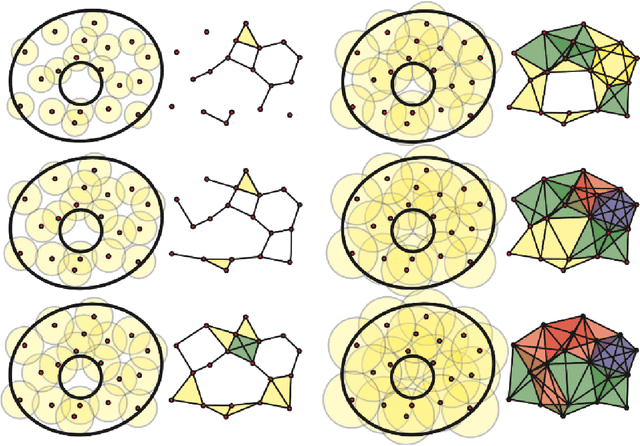
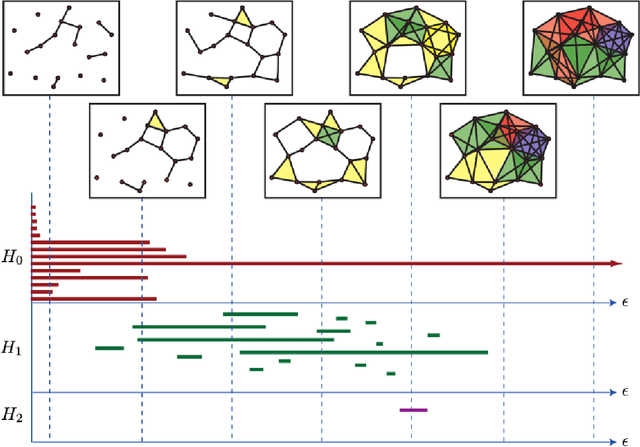
Detecting small targets at range is difficult because there is not enough spatial information present in an image sub-region containing the target to use correlation-based methods to differentiate it from dynamic confusers present in the scene. Moreover, this lack of spatial information also disqualifies the use of most state-of-the-art deep learning image-based classifiers. Here, we use characteristics of target tracks extracted from video sequences as data from which to derive distinguishing topological features that help robustly differentiate targets of interest from confusers. In particular, we calculate persistent homology from time-delayed embeddings of dynamic statistics calculated from motion tracks extracted from a wide field-of-view video stream. In short, we use topological methods to extract features related to target motion dynamics that are useful for classification and disambiguation and show that small targets can be detected at range with high probability.
Machine Learning-enhanced Realistic Framework for Real-time Seismic Monitoring -- The Winning Solution of the 2017 International Aftershock Detection Contest
Nov 21, 2019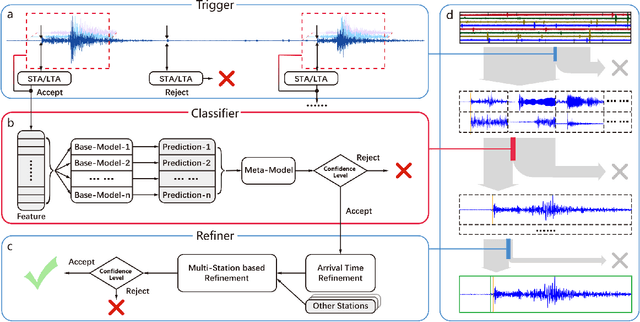
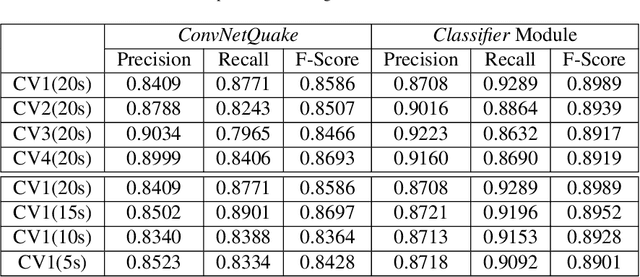
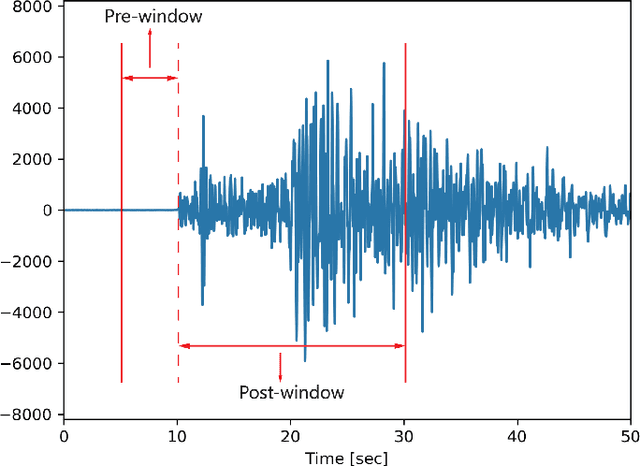
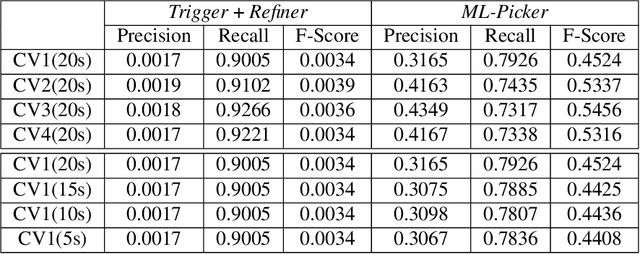
Identifying the arrival times of seismic P-phases plays a significant role in real-time seismic monitoring, which provides critical guidance for emergency response activities. While considerable research has been conducted on this topic, efficiently capturing the arrival times of seismic P-phases hidden within intensively distributed and noisy seismic waves, such as those generated by the aftershocks of destructive earthquakes, remains a real challenge since existing methods rely on laborious expert supervision. To this end, in this paper, we present a machine learning-enhanced framework, ML-Picker, for the automatic identification of seismic P-phase arrivals on continuous and massive waveforms. More specifically, ML-Picker consists of three modules, namely, Trigger, Classifier, and Refiner, and an ensemble learning strategy is exploited to integrate several machine learning classifiers. An evaluation of the aftershocks following the $M8.0$ Wenchuan earthquake demonstrates that ML-Picker can not only achieve the best identification performance but also identify 120% more seismic P-phase arrivals as complementary data. Meanwhile, experimental results also reveal both the applicability of different machine learning models for waveforms collected from different seismic stations and the regularities of seismic P-phase arrivals that might be neglected during manual inspection. These findings clearly validate the effectiveness, efficiency, flexibility and stability of ML-Picker. In particular, with the preliminary version of ML-Picker, we won the championship in the First Season and were the runner-up in the Finals of the 2017 International Aftershock Detection Contest hosted by the China Earthquake Administration, in which 1,143 teams participated from around the world.