 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reachability-based Trajectory Safeguard (RTS): A Safe and Fast Reinforcement Learning Safety Layer for Continuous Control
Nov 17, 2020
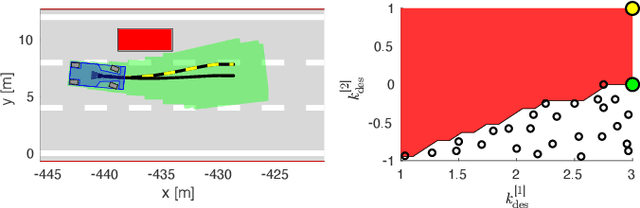
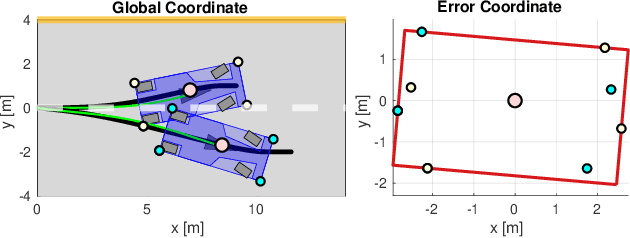
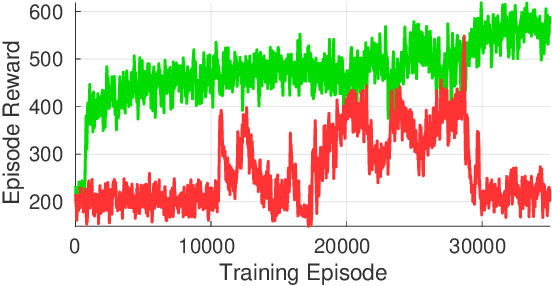
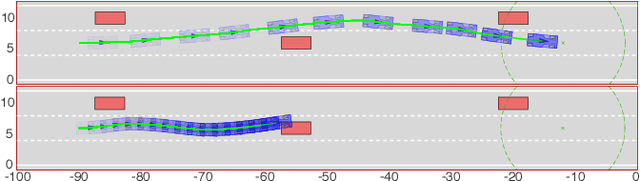
Reinforcement Learning (RL) algorithms have achieved remarkable performance in decision making and control tasks due to their ability to reason about long-term, cumulative reward using trial and error. However, during RL training, applying this trial-and-error approach to real-world robots operating in safety critical environment may lead to collisions. To address this challenge, this paper proposes a Reachability-based Trajectory Safeguard (RTS), which leverages trajectory parameterization and reachability analysis to ensure safety while a policy is being learned. This method ensures a robot with continuous action space can be trained from scratch safely in real-time. Importantly, this safety layer can still be applied after a policy has been learned. The efficacy of this method is illustrated on three nonlinear robot models, including a 12-D quadrotor drone, in simulation. By ensuring safety with RTS, this paper demonstrates that the proposed algorithm is not only safe, but can achieve a higher reward in a considerably shorter training time when compared to a non-safe counterpart.
Baseline Pruning-Based Approach to Trojan Detection in Neural Networks
Feb 09, 2021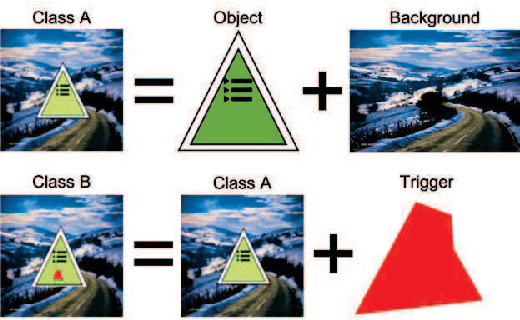
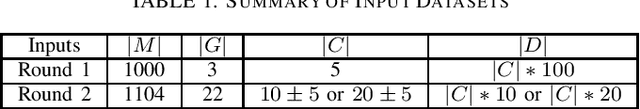
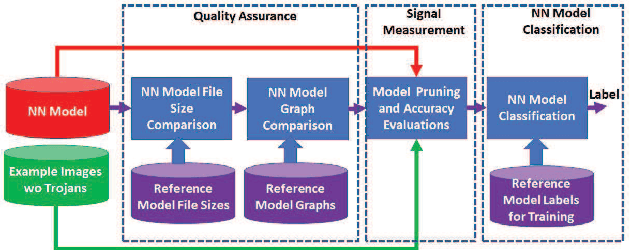

This paper addresses the problem of detecting trojans in neural networks (NNs) by analyzing systematically pruned NN models. Our pruning-based approach consists of three main steps. First, detect any deviations from the reference look-up tables of model file sizes and model graphs. Next, measure the accuracy of a set of systematically pruned NN models following multiple pruning schemas. Finally, classify a NN model as clean or poisoned by applying a mapping between accuracy measurements and NN model labels. This work outlines a theoretical and experimental framework for finding the optimal mapping over a large search space of pruning parameters. Based on our experiments using Round 1 and Round 2 TrojAI Challenge datasets, the approach achieves average classification accuracy of 69.73 % and 82.41% respectively with an average processing time of less than 60 s per model. For both datasets random guessing would produce 50% classification accuracy. Reference model graphs and source code are available from GitHub.
Adaptive Autonomy in Human-on-the-Loop Vision-Based Robotics Systems
Mar 28, 2021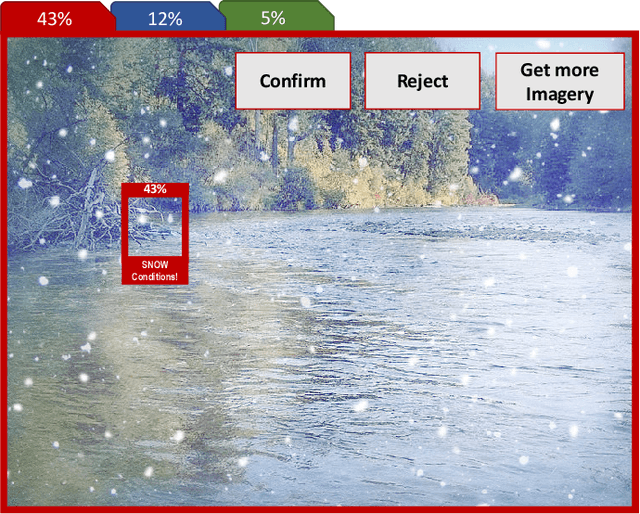
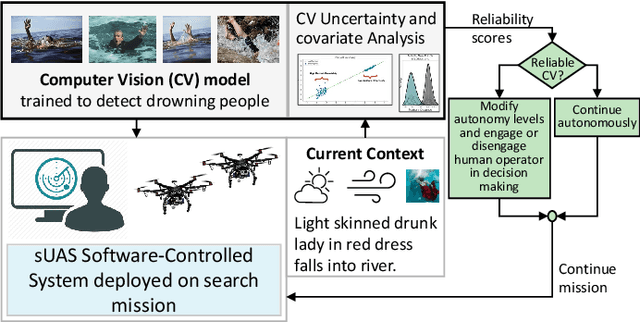
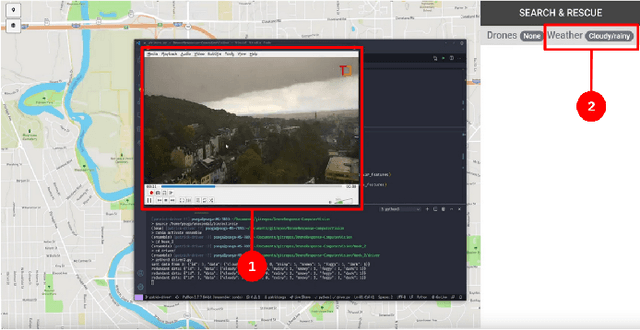

Computer vision approaches are widely used by autonomous robotic systems to sense the world around them and to guide their decision making as they perform diverse tasks such as collision avoidance, search and rescue, and object manipulation. High accuracy is critical, particularly for Human-on-the-loop (HoTL) systems where decisions are made autonomously by the system, and humans play only a supervisory role. Failures of the vision model can lead to erroneous decisions with potentially life or death consequences. In this paper, we propose a solution based upon adaptive autonomy levels, whereby the system detects loss of reliability of these models and responds by temporarily lowering its own autonomy levels and increasing engagement of the human in the decision-making process. Our solution is applicable for vision-based tasks in which humans have time to react and provide guidance. When implemented, our approach would estimate the reliability of the vision task by considering uncertainty in its model, and by performing covariate analysis to determine when the current operating environment is ill-matched to the model's training data. We provide examples from DroneResponse, in which small Unmanned Aerial Systems are deployed for Emergency Response missions, and show how the vision model's reliability would be used in addition to confidence scores to drive and specify the behavior and adaptation of the system's autonomy. This workshop paper outlines our proposed approach and describes open challenges at the intersection of Computer Vision and Software Engineering for the safe and reliable deployment of vision models in the decision making of autonomous systems.
Deep learning and high harmonic generation
Dec 18, 2020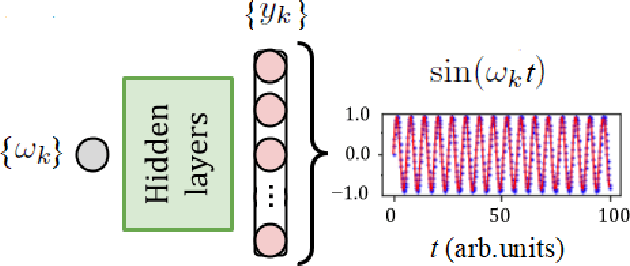
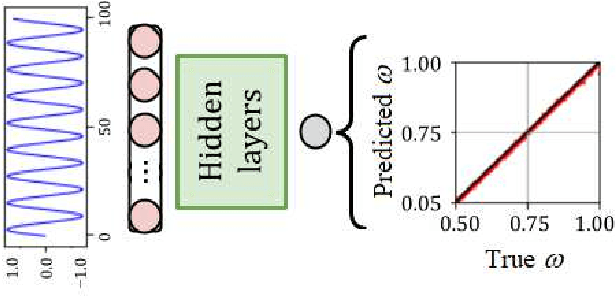
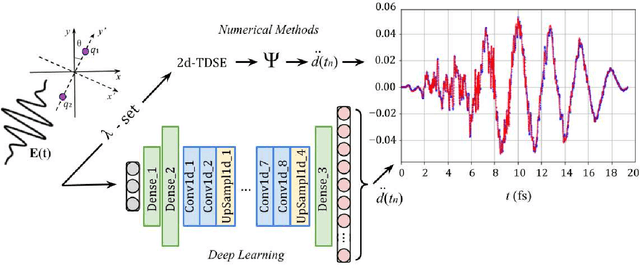
For the high harmonic generation problem, we trained deep convolutional neural networks to predict time-dependent dipole moments and spectra based on sets of randomly generated parameters (laser pulse intensity, internuclear distance, and molecules orientation). We also taught neural networks to solve the inverse problem - to determine parameters based on spectra or dipole moment data. The latter datasets can also be used to classify molecules by type: di- or triatomic, symmetric or asymmetric, wherein we can even rely on fairly simple fully connected neural networks.
tau-FPL: Tolerance-Constrained Learning in Linear Time
Jan 15, 2018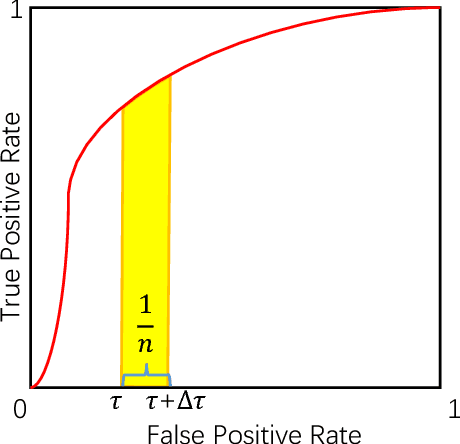


Learning a classifier with control on the false-positive rate plays a critical role in many machine learning applications. Existing approaches either introduce prior knowledge dependent label cost or tune parameters based on traditional classifiers, which lack consistency in methodology because they do not strictly adhere to the false-positive rate constraint. In this paper, we propose a novel scoring-thresholding approach, tau-False Positive Learning (tau-FPL) to address this problem. We show the scoring problem which takes the false-positive rate tolerance into accounts can be efficiently solved in linear time, also an out-of-bootstrap thresholding method can transform the learned ranking function into a low false-positive classifier. Both theoretical analysis and experimental results show superior performance of the proposed tau-FPL over existing approaches.
Tree of Knowledge: an Online Platform for Learning the Behaviour of Complex Systems
Feb 27, 2021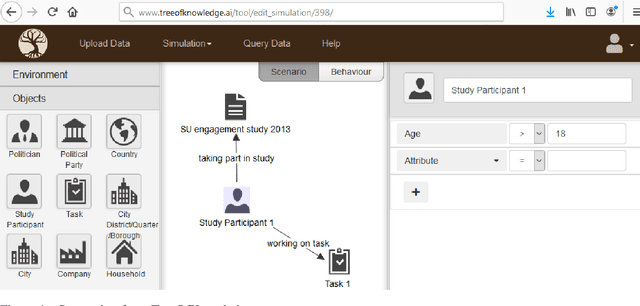
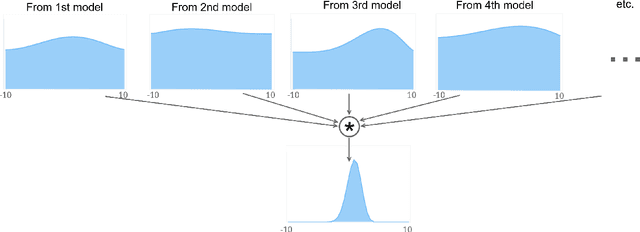

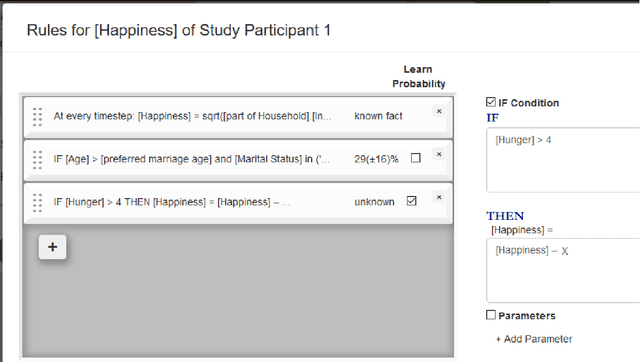
Many social sciences such as psychology and economics try to learn the behaviour of complex agents such as humans, organisations and countries. The current statistical methods used for learning this behaviour try to infer generally valid behaviour, but can only learn from one type of study at a time. Furthermore, only data from carefully designed studies can be used, as the phenomenon of interest has to be isolated and confounding factors accounted for. These restrictions limit the robustness and accuracy of insights that can be gained from social/economic systems. Here we present the online platform TreeOfKnowledge which implements a new methodology specifically designed for learning complex behaviours from complex systems: agent-based behaviour learning. With agent-based behaviour learning it is possible to gain more accurate and robust insights as it does not have the restriction of conventional statistics. It learns agent behaviour from many heterogenous datasets and can learn from these datasets even if the phenomenon of interest is not directly observed, but appears deep within complex systems. This new methodology shows how the internet and advances in computational power allow for more accurate and powerful mathematical models.
Progressive Batching for Efficient Non-linear Least Squares
Oct 21, 2020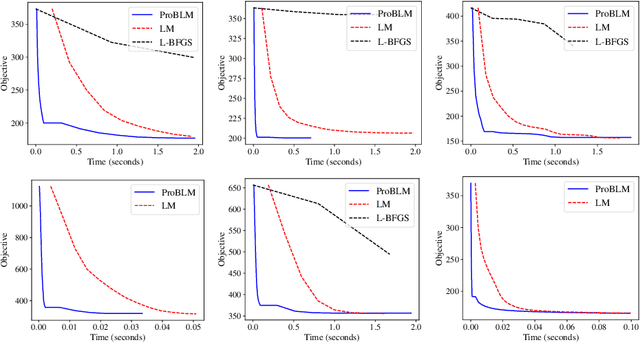
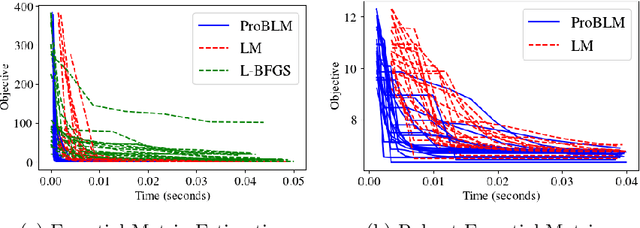
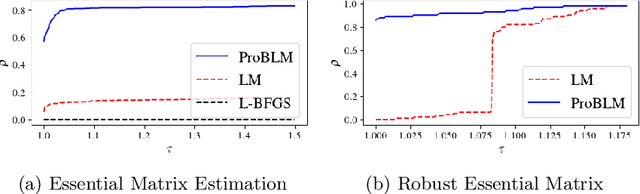
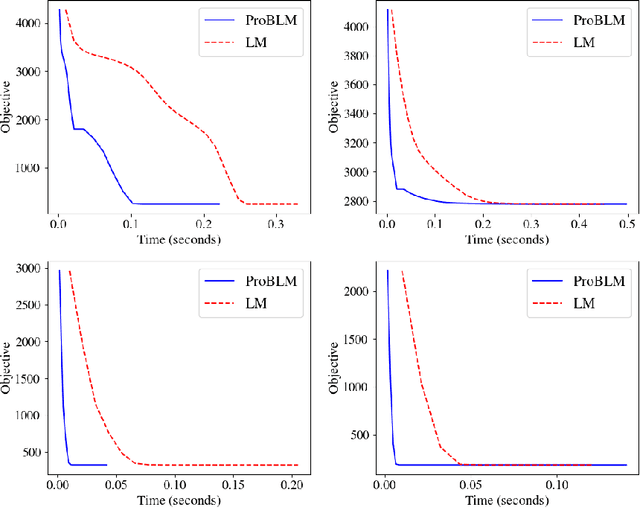
Non-linear least squares solvers are used across a broad range of offline and real-time model fitting problems. Most improvements of the basic Gauss-Newton algorithm tackle convergence guarantees or leverage the sparsity of the underlying problem structure for computational speedup. With the success of deep learning methods leveraging large datasets, stochastic optimization methods received recently a lot of attention. Our work borrows ideas from both stochastic machine learning and statistics, and we present an approach for non-linear least-squares that guarantees convergence while at the same time significantly reduces the required amount of computation. Empirical results show that our proposed method achieves competitive convergence rates compared to traditional second-order approaches on common computer vision problems, such as image alignment and essential matrix estimation, with very large numbers of residuals.
Octopus: A Framework for Cost-Quality-Time Optimization in Crowdsourcing
Aug 15, 2017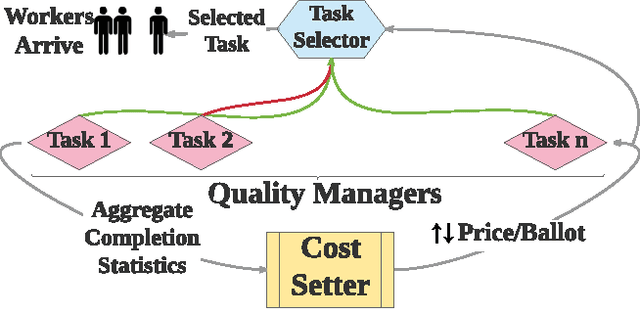

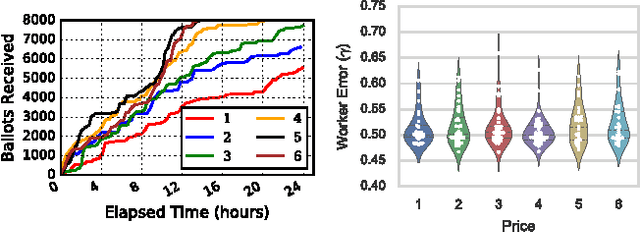
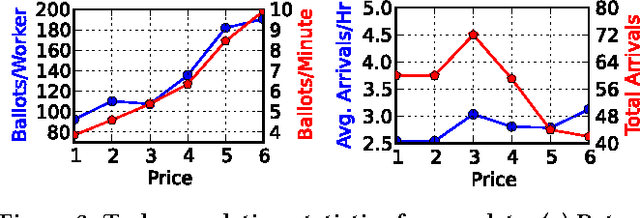
We present Octopus, an AI agent to jointly balance three conflicting task objectives on a micro-crowdsourcing marketplace - the quality of work, total cost incurred, and time to completion. Previous control agents have mostly focused on cost-quality, or cost-time tradeoffs, but not on directly controlling all three in concert. A naive formulation of three-objective optimization is intractable; Octopus takes a hierarchical POMDP approach, with three different components responsible for setting the pay per task, selecting the next task, and controlling task-level quality. We demonstrate that Octopus significantly outperforms existing state-of-the-art approaches on real experiments. We also deploy Octopus on Amazon Mechanical Turk, showing its ability to manage tasks in a real-world dynamic setting.
Track-Assignment Detailed Routing Using Attention-based Policy Model With Supervision
Oct 26, 2020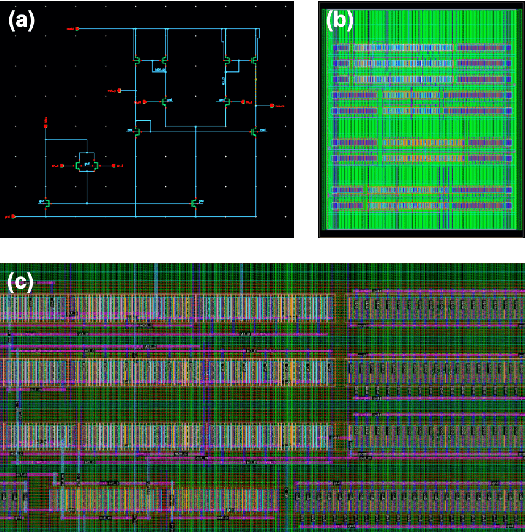
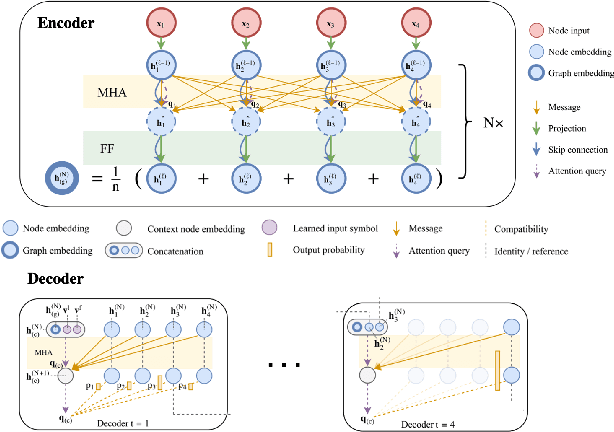
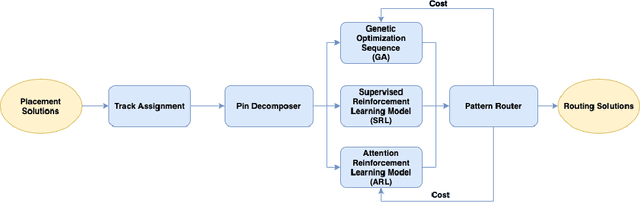
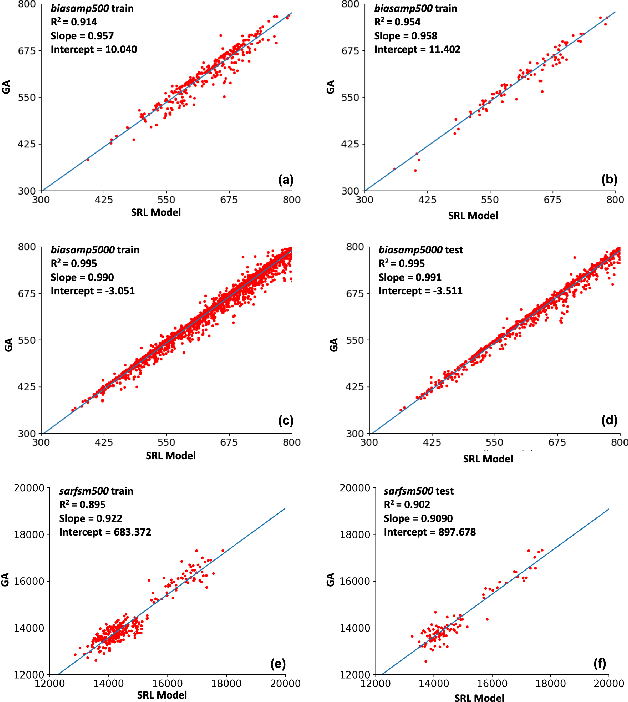
Detailed routing is one of the most critical steps in analog circuit design. Complete routing has become increasingly more challenging in advanced node analog circuits, making advances in efficient automatic routers ever more necessary. In this work, we propose a machine learning driven method for solving the track-assignment detailed routing problem for advanced node analog circuits. Our approach adopts an attention-based reinforcement learning (RL) policy model. Our main insight and advancement over this RL model is the use of supervision as a way to leverage solutions generated by a conventional genetic algorithm (GA). For this, our approach minimizes the Kullback-Leibler divergence loss between the output from the RL policy model and a solution distribution obtained from the genetic solver. The key advantage of this approach is that the router can learn a policy in an offline setting with supervision, while improving the run-time performance nearly 100x over the genetic solver. Moreover, the quality of the solutions our approach produces matches well with those generated by GA. We show that especially for complex problems, our supervised RL method provides good quality solution similar to conventional attention-based RL without comprising run time performance. The ability to learn from example designs and train the router to get similar solutions with orders of magnitude run-time improvement can impact the design flow dramatically, potentially enabling increased design exploration and routability-driven placement.
Probabilistic Numeric Convolutional Neural Networks
Oct 21, 2020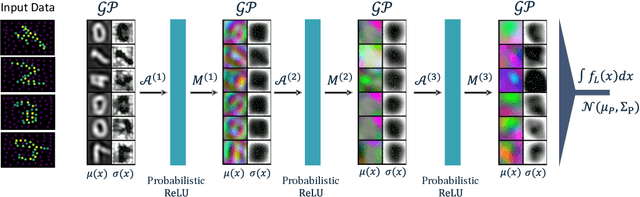

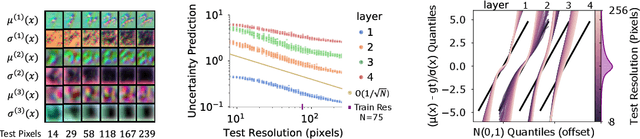
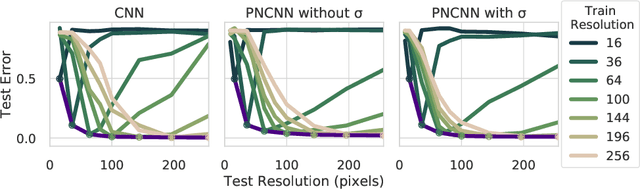
Continuous input signals like images and time series that are irregularly sampled or have missing values are challenging for existing deep learning methods. Coherently defined feature representations must depend on the values in unobserved regions of the input. Drawing from the work in probabilistic numerics, we propose Probabilistic Numeric Convolutional Neural Networks which represent features as Gaussian processes (GPs), providing a probabilistic description of discretization error. We then define a convolutional layer as the evolution of a PDE defined on this GP, followed by a nonlinearity. This approach also naturally admits steerable equivariant convolutions under e.g. the rotation group. In experiments we show that our approach yields a $3\times$ reduction of error from the previous state of the art on the SuperPixel-MNIST dataset and competitive performance on the medical time series dataset PhysioNet2012.